Stable Diffusion WebUI 1.10.0来了(附SD3模型)
我算是程序猿 2024-10-16 17:03:01 阅读 56
前几天 AUTOMATIC1111 发布了Stable Diffusion WebUI 1.10,我也在第一时间将云环境的镜像升级到了最新版本,有兴趣的同学可以去体验下,目前已经发布到了AutoDL
这篇文章集中给大家介绍下SD WebUI 1.10的新功能和各项改进。
SD3可以扫描下方,免费获取

正式支持SD3
SD3开源发布有段时间了,ComfyUI最先提供了支持,SD WebUI迟迟没有支持,其实 AUTOMATIC1111 很早就提供了SD3的WebUI开发版,只是没有正式发布。1.10 版本正式支持了SD3。
使用方式和SD1.5、SDXL模型一样,选择SD3的模型,点击生成就可以了。注意采样器目前只支持 Euler,选择其它采样器效果很差。
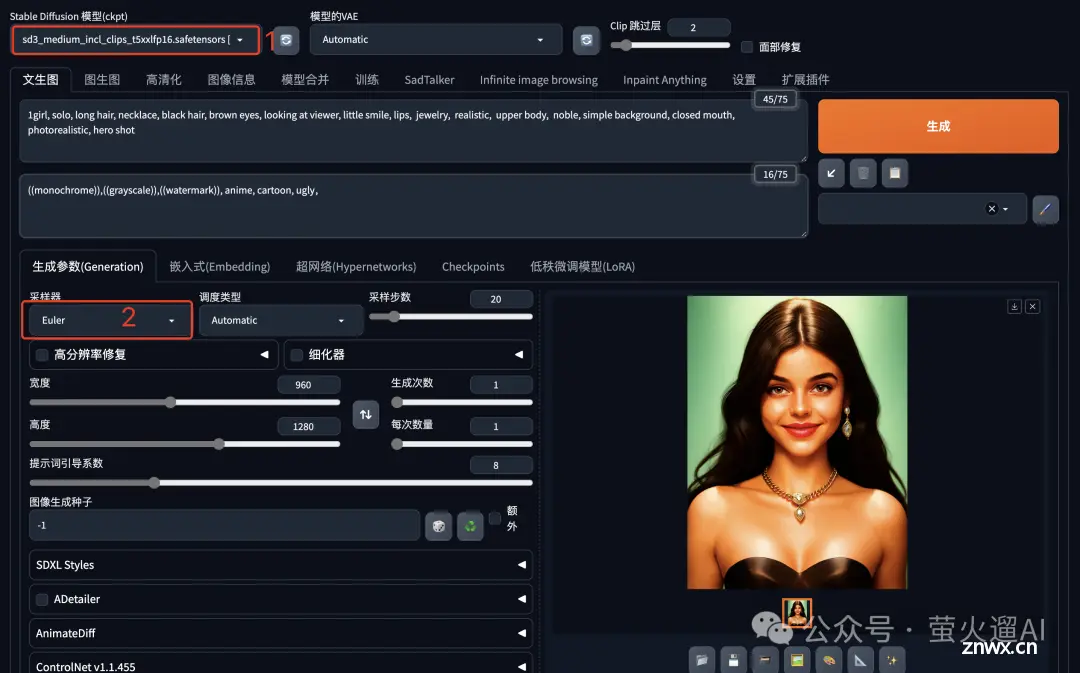
另外SD3引入了新的文本编码器,出图效果更好,但是占用的显存也很可观,所以默认没有开启。显存不差钱的同学可以在设置中打开,操作步骤如下图所示。

SD3的发展并不顺利,前期因为授权协议的问题被C站封掉,又因为生成人体畸形的问题被大家疯狂吐槽,目前社区的支持正在逐步推进,真正大范围铺开可能还需要比较长的一段时间,毕竟SD1.5还是能满足很多用户的需求。
新增采样调度器
Stable Diffusion WebUI 1.10 引入了几个新的采样调度器。
Align Your Steps
适合 SDXL 和 SD 1.5,使用交大步长时的推荐插值方法。与Karras、Exponential的对比,搭配祖先采样器时表现更为明显。

KL Optimal
和 Align Your Steps 类似,基于同样的理论基础。

Normal、DDIM和Simple
从 ComfyUI 移植过来的调度器。

Beta
在去噪的开始和结束阶段花费更多时间以提高图像质量,效果和Uniform差不多,但是比Uniform更稳定。采样步数较少时效果不佳,增加至20以上时,效果稳定。
新增采样器
增加新的采样器DDIM CFG++,它是从DDIM改进而来的,主要变化是使用无条件噪声来指导去噪,而不是条件噪声。CFG++ 解决了低指导尺度的问题,提高了文本到图像的质量和可逆性。

跳过CFG
CFG在采样的前期步骤(高噪声水平)明显有害,在采样的后期步骤(低噪声水平)基本不必要,只有在中间才是有益的。在采样的早期步骤跳过CFG可以提高样本的多样性、图像质量,在某些情况下还可以更快地收敛。
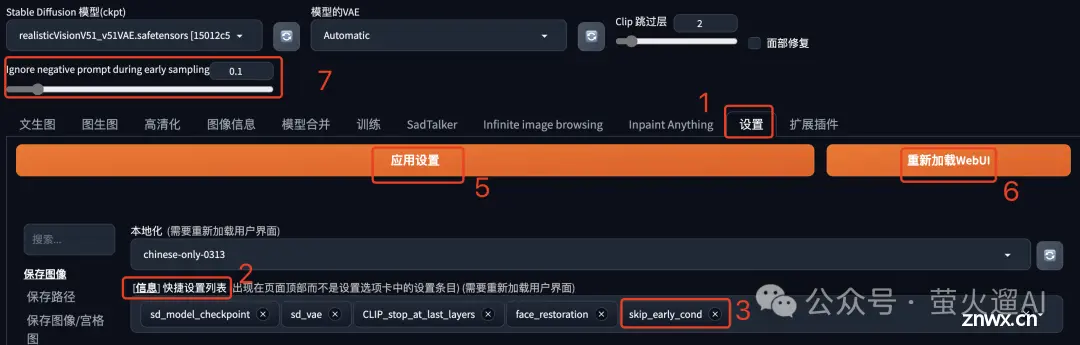
按照下图中的步骤即可在页面顶部打开一个跳过CFG的开关,大家按照需要设置就可以了。
其它更多内容
次要更新:
添加 <code>--models-dir 选项来指定模型目录。([#15742])允许移动用户使用两指按压打开上下文菜单。([#15682])Infotext:为捆绑的 Textual Inversion 添加 LoRA 名称作为 TI (Textual Inversion) 哈希值。([#15679])下载模型后检查其哈希值以防止下载损坏。([#15602])更多扩展标签过滤选项。([#15627])保存 AVIF 时使用 JPEG 的质量设置。([#15610])添加文件名模式:[basename]。([#15978])添加选项以在 SDXL 上为 CLIP L 启用 clip 跳过。([#15992])选项:在生成过程中防止屏幕休眠。([#16001])图像查看器中的 ToggleLivePreview 按钮。([#16065])移除在重新加载和快速滚动时的 UI 闪烁。([#16153])选项:禁用将按钮日志保存到 log.csv。([#16242])
扩展和 API:
添加 process_before_every_sampling 钩子。([#15984])在无效的采样器错误时返回 HTTP 400 代替 404。([#16140])
性能:
[性能 1/6] 禁用 use_checkpoint。([#15803])[性能 2/6] 用 PyTorch 原生操作替换 einops.rearrange。([#15804])[性能 4/6] 预计算 is_sdxl_inpaint 标记。([#15806])[性能 5/6] 防止不必要的额外网络偏置备份。([#15816])[性能 6/6] 添加 --precision half 选项以避免推理期间的类型转换。([#15820])[性能] LDM 优化补丁。([#15824])[性能] 将 sigmas 保持在 CPU 上。([#15823])仅在所有步骤完成后检查 U-Net 中的 NaN 值。添加选项以在图像生成时运行 PyTorch 分析器。
Bug 修复:
修复无全面 Infotext 的网格。([#15958])功能:LoRA 部分更新优先于完整更新。([#15943])修复在某些情况下文件扩展名具有额外的点号。([#15893])修复模型初始加载循环中的错误。([#15600])允许 API 中使用旧的采样器名称。([#15656])更多旧采样器调度兼容性。([#15681])修复 Hypertile XYZ。([#15831])XYZ CSV skipinitialspace 选项。([#15832])修复 mps 和 xpu 上的软 Inpainting,torch_utils.float64。([#15815])修复不在主分支时的扩展更新。([#15797])更新 pickle 安全文件名。在 webui-assets CSS 中使用相对路径。([#15757])创建虚拟环境时,在 webui.bat/webui.sh 中升级 pip。([#15750])修复 AttributeError。([#15738])在 launch_utils 中使用 script_path 作为 webui 根目录。([#15705])修复额外批处理模式 P 透明度。([#15664])在 CSS 中使用 Gradio 主题颜色。([#15680])修复在提示输入框内拖拽文本。([#15657])为 .mjs 文件添加正确的 MIME 类型。([#15654])QOL 项目:更干净地处理 SD 模型、LoRAs 和嵌入的元数据问题。([#15632])用 wslpath 和 explorer.exe 替换 wsl-open。([#15968])修复 SDXL Inpaint。([#15976])多尺寸网格。([#15988])修复预览替换。([#16118])可能修复权重分解中的错误缩放。([#16151])确保在 Mac 和 Linux 上使用来自虚拟环境的 Python。([#16116])如果同时可用,则优先使用 Python 3.10 而不是 Python 3(带回退)。([#16092])停止生成额外内容。([#16085])修复 SD2 加载。([#16078], [#16079])修复用于高分辨率修复的不同 LoRA 的 Infotext LoRA 哈希值。([#16062])修复采样器调度自动修正警告。([#16054])移除在重新加载和快速滚动时的 UI 闪烁。([#16153])修复放大逻辑。([#16239])[bug] 在非任务操作时不破坏进度条(添加 wrap_gradio_call_no_job)。([#16202])修复 OSError: cannot write mode P as JPEG。([#16194])
其他:
修复变更日志编号 #15883 -> #15882。([#15907])重载 UI 背景颜色 --background-fill-primary。([#15864])对 Intel 和 ARM Macs 使用不同的 PyTorch 版本。([#15851])XYZ 重写。([#15836])滚动扩展表格以适应溢出。([#15830])img2img 批量上传方法。([#15817])例行工作:根据变更日志同步 v1.8.0 包。([#15783])添加 AVIF MIME 类型支持。([#15739])更新 imageviewer.js。([#15730])no-referrer。([#15641]).gitignore 中忽略 trace.json。([#15980])将 spandrel 升级至 0.3.4。([#16144])废弃 --max-batch-count。([#16119])文档:更新 bug_report.yml。([#16102])维护 Python 3.9 用户的项目兼容性,无需升级要求。([#16088], [#16169], [#16192])更新 ARM Macs 上的 PyTorch 至 2.3.1。([#16059])移除已废弃的设置 dont_fix_second_order_samplers_schedule。([#16061])例行工作:修复拼写错误。([#16060])在控制台日志中使用 shlex.join 合并启动参数。([#16170])激活虚拟环境的 .bat 文件。([#16231])为 img2img 中的调整大小选项添加 ID。([#16218])更新 Linux 安装指南。([#16178])强健的 sysinfo。([#16173])在粘贴 Inpaint 时不要发送图像大小。([#16180])修复 MacOS 上嘈杂的 DS_Store 文件。([#16166])
这里直接将该软件分享出来给大家吧~

1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。
2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。
3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。
4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!

本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。