前端文件上传识别文件类型的几种方法,快看你是哪个?
QD_ANJING 2024-06-23 17:33:04 阅读 78
在我们的日常开发过程中,我们会经常接触到一些文件上传的事情,其中在前端这边识别识别文件类型的是非常常见的功能,例如来限制文件上传的类型,接下来我们来了解一下最常见的几种方式。
通过文件扩展名判断类型
最简单快捷的方法就是 hiyaJavaScript 获取文件名的扩展名,对比扩展名来判断文件类型,如下代码所示:
<!DOCTYPE html><html lang="en"> <head> <meta charset="UTF-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>文件类型识别</title> </head> <body> <h2>文件类型识别</h2> <input type="file" id="fileInput" /> <p id="fileType">文件类型</p> <script> document .getElementById("fileInput") .addEventListener("change", function (event) { const file = event.target.files[0]; if (!file) { document.getElementById("fileType").textContent = "没有文件被选中"; return; } const fileName = file.name; const extensionIndex = fileName.lastIndexOf("."); let fileType; if (extensionIndex === -1 || extensionIndex === 0) { fileType = "未知"; } else { fileType = fileName.substring(extensionIndex + 1); } document.getElementById("fileType").textContent = "文件类型: " + fileType; }); </script> </body></html>
当然 JavaScript 这方面的代码你也可以这样子实现,看你需求:
document .getElementById("fileInput") .addEventListener("change", function (event) { const file = event.target.files[0]; if (!file) { document.getElementById("fileType").textContent = "没有文件被选中"; return; } let fileType = file.type; if (!fileType) { const fileNameParts = file.name.split("."); const extension = fileNameParts[fileNameParts.length - 1]; if (extension === "md") { fileType = "text/markdown"; } } document.getElementById("fileType").textContent = "文件类型: " + fileType; });
上传一个文件,文件的类型被输出出来了:

仅通过文件扩展名来判断类型存在安全和准确性风险,因为它可能被恶意用户篡改以上传危险文件,且不能可靠地反映文件的真实内容,同时还无法识别没有扩展名的文件。
通过 MIME 类型判断
当我们使用 HTML 的 <input type="file"> 标签时,可以通过文件的 type 属性获取 MIME 类型:
document .getElementById("fileInput") .addEventListener("change", function (event) { const file = event.target.files[0]; if (!file) { document.getElementById("fileType").textContent = "没有文件被选中"; return; } document.getElementById("fileType").textContent = "文件类型: " + file.type; });
这段代码为文件输入元素添加了一个 change 事件监听器。当用户选择文件后,会触发这个事件。事件处理函数会获取用户选中的文件,并显示它的 MIME 类型。

MIME(多用途互联网邮件扩展,Multi-purpose Internet Mail Extensions)最初是为了改进电子邮件中的文件传输而设计的,但它的使用范围已经扩展到互联网的其他领域。MIME 定义了一系列的数据类型和数据格式,用于在网络上交换数据。
但是 MIME 类型有时可能不准确或为空。

使用 FileReader 读取文件内容
FileReader 是 HTML5 提供的 API,可以用来读取文件的内容,通过读取文件内容的一部分,可以更准确地判断文件类型:
<!DOCTYPE html><html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>读取文件内容</title> </head> <body> <input type="file" id="fileInput" /> <div id="fileContent">文件类型</div> <script> document .getElementById("fileInput") .addEventListener("change", function (event) { const file = event.target.files[0]; if (!file) { document.getElementById("fileContent").textContent = "没有文件被选中"; return; } const reader = new FileReader(); reader.onloadend = function (e) { const arr = new Uint8Array(e.target.result).subarray(0, 4); let header = ""; for (let i = 0; i < arr.length; i++) { header += arr[i].toString(16).padStart(2, "0"); } let fileType = "未知"; switch (header) { case "89504e47": fileType = "图片 (PNG)"; break; case "47494638": fileType = "图片 (GIF)"; break; case "ffd8ffe0": case "ffd8ffe1": case "ffd8ffe2": fileType = "图片 (JPEG)"; break; case "25504446": fileType = "文档 (PDF)"; break; // 更多文件类型... default: fileType = "未知"; } document.getElementById("fileContent").textContent = "文件类型: " + fileType; }; reader.onerror = function () { document.getElementById("fileContent").textContent = "文件读取出错"; }; reader.readAsArrayBuffer(file); }); </script> </body></html>
在上面的代码中读取了文件的前四个字节来判断文件类型。它包含了用于标识文件格式的特定模式或“魔术数字”。

HTML5 File API
使用 HTML5 File API 可以读取用户在浏览器中选择的文件的信息,包括文件类型。这个 API 提供了一个标准的方式来获取关于文件的信息,如文件名、大小以及 MIME 类型。
document .getElementById("fileInput") .addEventListener("change", function (event) { const file = event.target.files[0]; if (!file) { document.getElementById("fileInfo").textContent = "没有选择文件"; return; } const fileInfo = `文件名: ${file.name}<br>文件大小: ${file.size} 字节<br>文件类型: ${file.type}`; document.getElementById("fileInfo").innerHTML = fileInfo; });
最终输出效果如下图所示:

装 X 必备,WebAssembly
使用 WebAssembly (WASM) 对文件进行识别通常涉及到较为复杂的操作,因为你需要将文件处理逻辑编译为 WASM 模块,然后在 JavaScript 中调用这个模块来处理文件。
第一步,我们以 C 为例子,接下来我们编写一个 C 代码,如下:
#include <string.h>#include <emscripten.h>// 检查 PNGint is_png(const unsigned char *buffer) { const unsigned char png_signature[8] = {0x89, 'P', 'N', 'G', 0x0D, 0x0A, 0x1A, 0x0A}; return memcmp(buffer, png_signature, 8) == 0;}// 检查 JPEGint is_jpeg(const unsigned char *buffer) { return buffer[0] == 0xFF && buffer[1] == 0xD8 && buffer[2] == 0xFF;}// 检查 GIFint is_gif(const unsigned char *buffer) { return strncmp((const char *)buffer, "GIF", 3) == 0;}// 检查 PDFint is_pdf(const unsigned char *buffer) { return strncmp((const char *)buffer, "%PDF-", 5) == 0;}// 主函数,用于检测文件类型EMSCRIPTEN_KEEPALIVEint check_file_type(const unsigned char *buffer, int length) { if (is_pdf(buffer)) { return 1; } else if (is_png(buffer)) { return 2; } else if (is_jpeg(buffer)) { return 3; } else if (is_gif(buffer)) { return 4; } return 0; // 未知类型}
在上面的这些代码中,通过比较输入流的前 8 个字节与这个序列来判断是否为某个文件。
代码编写完成之后,我们要在终端执行一行命令如下所示:
emcc index.c -s WASM=1 -o index.js -s EXPORTED_FUNCTIONS='["_check_file_type", "_malloc", "_free"]' -s EXTRA_EXPORTED_RUNTIME_METHODS='["ccall", "cwrap"]'
最终会生成这两个文件:
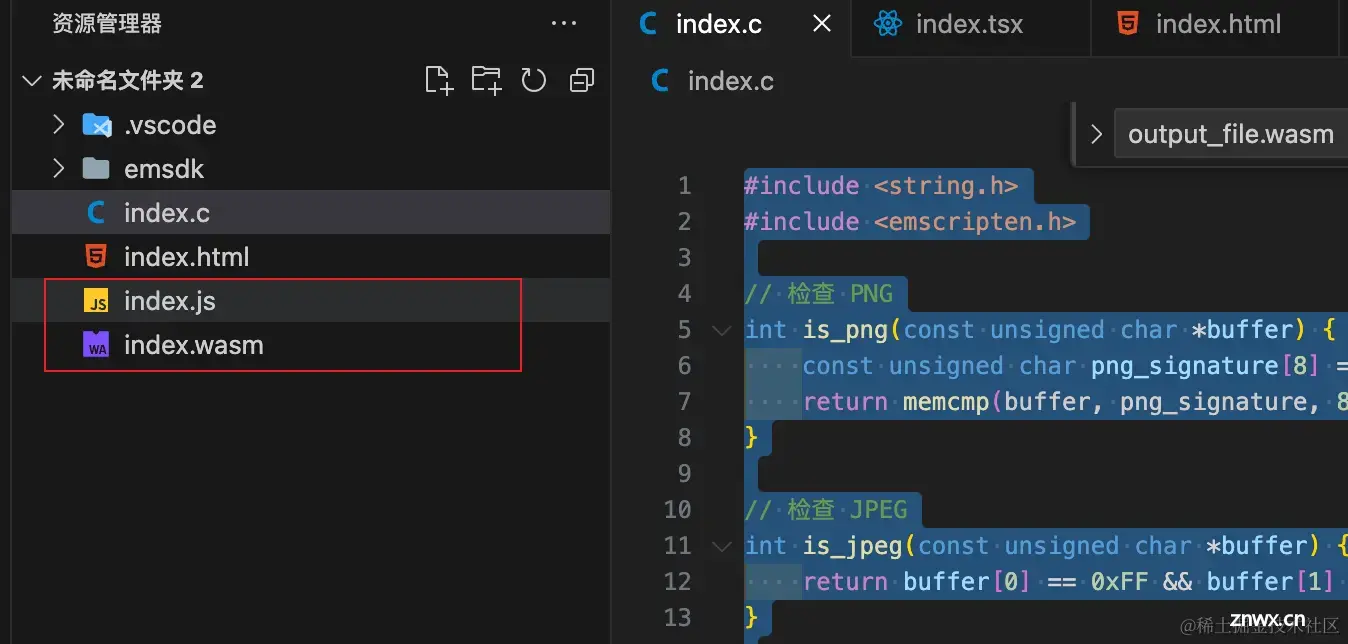
这个时候我们就可以在我们前端中使用了,编写如下代码:
<!DOCTYPE html><html lang="en"> <head> <meta charset="UTF-8" /> <title>文件类型识别</title> <script src="./index.js"></script> </head> <body> <input type="file" id="fileInput" /> <script> const fileInput = document.getElementById("fileInput"); Module.onRuntimeInitialized = () => { fileInput.addEventListener("change", (event) => { const file = event.target.files[0]; if (!file) { return; } const reader = new FileReader(); reader.onload = (e) => { const buffer = new Uint8Array(e.target.result); // 分配内存并将数据复制到 WebAssembly 的内存空间 const dataPtr = Module._malloc(buffer.length); Module.HEAPU8.set(buffer, dataPtr); // 调用 WebAssembly 函数 const fileType = Module.ccall( "check_file_type", // C 函数名 "number", // 返回值类型 ["number", "number"], // 参数类型 [dataPtr, buffer.length] // 参数 ); // 输出文件类型到控制台 console.log("文件类型 ID:", fileType); // 释放内存 Module._free(dataPtr); }; reader.readAsArrayBuffer(file); }); }; </script> </body></html>
这样,我们就可以根据不同的 id 来返回不同的文件类型了:
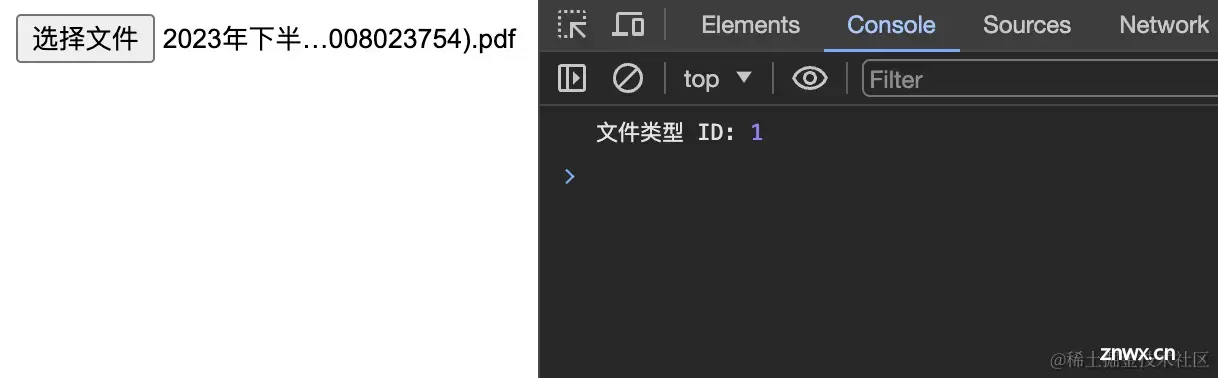
通过以上步骤,我们实现了一个使用 WebAssembly 来识别文件类型并在浏览器控制台上输出结果的功能。
总结
除了这些之外,我们还可以使用第三方库 file-type 来实现文件类型检测,这里我们就不再进行 demo 演示了,感兴趣的可以去官方文档中进行查阅。
另外最近对脚手架的仓库代码进行了重构,之后会越来越规范,规模会越来越大,感兴趣的小伙伴可以加入来一起开发,春招没有项目的朋友也可以以此作为春招的项目:
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。