基于用户画像及协同过滤算法的音乐推荐系统,采用Django框架、bootstrap前端,MySQL数据库
CSDN 2024-09-10 10:03:02 阅读 77
研究背景
随着互联网和移动设备的普及,音乐流媒体服务成为人们获取音乐的主要方式。这些平台如Spotify、Apple Music和网易云音乐等,提供了海量的音乐资源,使用户能够随时随地聆听各种类型的音乐。然而,如何在海量的音乐资源中快速找到符合用户偏好的音乐,成为了音乐流媒体服务面临的重要挑战。
音乐推荐系统应运而生,它利用数据挖掘和机器学习技术,分析用户的行为和偏好,自动推荐可能感兴趣的音乐作品。用户画像和协同过滤算法是音乐推荐系统中两种常见且有效的方法。
用户画像是通过收集和分析用户的个人信息、行为数据、社交网络等,构建出用户的偏好模型。通过用户画像,可以准确地了解用户的音乐喜好、收听习惯等,为个性化推荐提供数据支持。用户画像不仅可以提高推荐的准确性,还能增强用户体验,使推荐结果更符合用户的实际需求。
协同过滤算法是一种基于用户行为数据的推荐算法。它分为基于用户的协同过滤和基于物品的协同过滤两种。基于用户的协同过滤通过寻找相似用户,推荐这些相似用户喜欢的音乐;而基于物品的协同过滤则通过寻找相似的音乐作品,推荐用户可能喜欢的音乐。协同过滤算法通过分析用户的历史行为,能够有效地挖掘用户潜在的兴趣,为用户提供个性化的音乐推荐。
在技术实现方面,本文选择了Django框架作为后端开发工具。Django是一个高效、灵活的Python Web框架,具有强大的数据处理和集成能力,能够快速构建和部署Web应用。前端采用Bootstrap框架,它是一个简洁、直观、强大的前端开发框架,使开发者能够轻松创建响应式、移动设备友好的Web页面。在数据库方面,选择了MySQL数据库。MySQL是一种高性能、可靠、开源的关系型数据库管理系统,广泛应用于各种Web应用中。
本文将通过构建一个基于Django框架的音乐推荐系统,结合用户画像和协同过滤算法,提供个性化的音乐推荐服务。系统将收集用户的基本信息和音乐收听记录,生成用户画像,并利用协同过滤算法进行音乐推荐。前端采用Bootstrap框架,提供友好的用户界面和交互体验。MySQL数据库用于存储用户信息和音乐数据,保证数据的高效存取和管理。
通过本研究,我们希望能够提高音乐推荐系统的准确性和用户满意度,帮助用户在海量的音乐资源中找到符合其偏好的音乐作品。同时,本文的研究也为其他领域的推荐系统提供参考和借鉴。
研究现状
随着数字音乐产业的快速发展,音乐推荐系统成为流媒体平台的重要组成部分。为了提升用户体验,许多研究和开发工作集中在如何提高推荐系统的准确性和实时性上。当前,基于用户画像和协同过滤算法的音乐推荐系统在学术界和工业界均得到了广泛应用和研究。
用户画像技术通过收集和分析用户的多维度数据,如人口统计信息、历史行为、社交网络关系等,构建出用户的个性化特征模型。近年来,随着大数据技术和深度学习的进步,用户画像技术在精度和实时性上得到了显著提升。例如,阿里巴巴的推荐系统通过多维度用户画像和实时计算,实现了高度个性化的推荐服务 。此外,Netflix等公司也在利用深度学习技术对用户画像进行建模,从而提升推荐的精确度和用户满意度 。
协同过滤算法是推荐系统中应用最广泛的方法之一。它主要分为基于用户的协同过滤和基于物品的协同过滤两类。基于用户的协同过滤通过寻找相似用户,推荐这些相似用户喜欢的内容;而基于物品的协同过滤则通过寻找相似的物品,推荐用户可能喜欢的内容。近年来,矩阵分解技术和神经网络技术的引入,使协同过滤算法在推荐效果和计算效率上有了显著提升 。例如,Google 的推荐系统采用了矩阵分解和深度神经网络相结合的方法,提高了推荐的精度和实时性 。
在技术实现方面,Django框架作为后端开发的首选工具,因其高效、灵活和安全的特性,得到了广泛应用。Django 提供了丰富的内置功能,如ORM(对象关系映射)、认证系统和管理界面,使开发者能够快速构建和部署复杂的Web应用 。许多学术研究和工业项目都采用Django框架实现推荐系统,例如,一些高校的研究项目通过Django实现了个性化的学习资源推荐系统 。
在前端技术方面,Bootstrap框架以其简洁、直观、响应式设计成为前端开发的热门选择。Bootstrap 提供了丰富的UI组件和强大的CSS框架,使开发者能够轻松创建美观、用户友好的Web界面 。在推荐系统的研究和开发中,Bootstrap 被广泛用于构建用户界面,提升用户体验。
MySQL数据库作为一种高性能、可靠的关系型数据库管理系统,广泛应用于推荐系统的数据存储和管理。MySQL 具有高效的查询性能和灵活的扩展性,能够处理大量的用户数据和音乐数据 。在学术界和工业界,MySQL 常被用于实现推荐系统的数据层,例如,一些大规模的电子商务推荐系统采用MySQL存储用户行为数据和推荐结果 。
主要研究内容
本研究主要聚焦于开发一个基于用户画像及协同过滤算法的音乐推荐系统,系统将采用Django框架、Bootstrap前端以及MySQL数据库。具体研究内容包括以下几个方面:
1. 用户画像构建
通过收集用户的基本信息、音乐收听记录及社交网络数据,构建多维度的用户画像。用户画像的构建将利用大数据分析技术,结合用户的行为特征和偏好,为个性化推荐奠定基础。
2. 协同过滤算法实现
实现基于用户的协同过滤和基于物品的协同过滤两种算法。基于用户的协同过滤通过分析相似用户的行为数据进行推荐;基于物品的协同过滤则通过分析相似音乐作品的特征进行推荐。两种算法的结合能够提高推荐的准确性和多样性。
3. Django框架开发
使用Django框架进行后端开发,实现用户数据的管理、推荐算法的调用以及推荐结果的生成。Django的ORM功能将用于与MySQL数据库的交互,确保数据存取的高效性和安全性。
4. Bootstrap前端设计
采用Bootstrap框架设计前端界面,实现响应式设计,确保在不同设备上的良好用户体验。前端界面将展示推荐结果,并提供用户交互功能,如评分和反馈,进一步优化推荐效果。
5. 系统集成与测试
将各部分功能集成,构建完整的推荐系统,并进行系统测试和性能优化。通过用户测试和反馈,不断改进推荐算法和用户界面,提升系统的实用性和用户满意度。
通过以上研究内容,旨在构建一个高效、准确、用户友好的音乐推荐系统,满足用户个性化的音乐需求。
前端主要代码
<code><!DOCTYPE html>
<html lang="en">code>
<head>
<meta charset="UTF-8">code>
<title>{% block title %}{% endblock %}</title>
<link rel="stylesheet" href="/static/css/bootstrap.css">code>
<script src="/static/js/jquery.min.js"></script>code>
{% block head %}{% endblock %}
</head>
<body>
<div class="container">code>
<nav class="navbar navbar-expand-lg navbar-light bg-light">code>
<a class="navbar-brand" href="/">音乐推荐系统</a>code>
<button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarSupportedContent" aria-controls="navbarSupportedContent" aria-expanded="false" aria-label="Toggle navigation">code>
<span class="navbar-toggler-icon"></span>code>
</button>
<div class="collapse navbar-collapse" id="navbarSupportedContent">code>
<ul class="navbar-nav mr-auto">code>
<li class="nav-item">code>
<a class="nav-link" href="/">全部音乐</a>code>
</li>
<li class="nav-item">code>
<a class="nav-link" href="/recommend">推荐音乐</a>code>
</li>
<li class="nav-item">code>
<a class="nav-link" href="/play">正在播放</a>code>
</li>
{% if request.user.is_authenticated %}
<li class="nav-item">code>
<a class="nav-link" href="/user">用户中心</a>code>
</li>
<li class="nav-item">code>
<a class="nav-link" href="/logout">注销</a>code>
</li>
{% else %}
<li class="nav-item">code>
<a class="nav-link" href="/sign_in">登录</a>code>
</li>
<li class="nav-item">code>
<a class="nav-link" href="/sign_up">注册</a>code>
</li>
{% endif %}
<li class="nav-item">code>
<a class="nav-link" href="/admin">管理后台</a>code>
</li>
</ul>
<form class="form-inline my-2 my-lg-0" method="get" action="/search">code>
<input class="form-control mr-sm-2" type="search" placeholder="输入歌曲名称搜索" aria-label="Search" name="keyword">code>
<button class="btn btn-outline-success my-2 my-sm-0" type="submit" name="action" value="song_name">搜歌曲</button>code>
<button class="btn btn-outline-primary my-2 my-sm-0 ml-2" type="submit" name="action" value="artist_name">搜歌手</button>code>
</form>
</div>
</nav>
{% block alert %}
{% if messages %}
{% for message in messages %}
{% if message.tags != 'console' %}
<div class="alert alert-{ { message.tags }} mt-3" role="alert">code>
{ { message }}
</div>
{% endif %}
{% endfor %}
{% endif %}
{% endblock %}
{% block body %}{% endblock %}
<div class="card">code>
<div class="card-body">code>
<p class="card-text text-center">Copyright @ MusicRecommend</p>code>
</div>
<div class="card-footer text-center">2024</div>code>
</div>
{% block footer %}{% endblock %}
</div>
</body>
</html>
后端主要代码
def build_df():
data = []
for user_profile in UserProfile.objects.all():
for like_music in user_profile.likes.all():
data.append([user_profile.user.id, like_music.pk, 1])
for dislike_music in user_profile.dislikes.all():
data.append([user_profile.user.id, dislike_music.pk, 0])
return pd.DataFrame(data, columns=['userID', 'itemID', 'rating'])
def build_predictions(df: pd.DataFrame, user: User):
userId = user.id
profile = UserProfile.objects.filter(user=user)
if profile.exists():
profile_obj: UserProfile = profile.first()
else:
return []
# 先构建训练集,用SVD训练,再把所有评分过的歌曲放到测试集里,
# 接着把测试集的数据通过训练的算法放到结果集里
reader = Reader(rating_scale=(0, 1))
data = Dataset.load_from_df(df[['userID', 'itemID', 'rating']], reader)
# 构建训练集
trainset = data.build_full_trainset()
# 构建算法并训练 e.g有限邻算法
algo = SVD()
# 数据拟合
algo.fit(trainset)
# 取出当前所有有人评分过的歌曲
subsets = df[['itemID']].drop_duplicates()
# 测试集
testset = []
for row in subsets.iterrows():
testset.append([userId, row[1].values[0], 0])
#通过测试集构建预测集
predictions = algo.test(testset, verbose=True)
result_set = []
user_like = profile_obj.likes.all()
user_dislike = profile_obj.dislikes.all()
for item in predictions:
prediction: Prediction = item
if prediction.est > 0.99:
music = Music.objects.get(pk=prediction.iid)
# 去重,不推荐用户已经喜欢的 或不喜欢的音乐
if music in user_like:
continue
if music in user_dislike:
continue
result_set.append(music)
if len(result_set) == 0:
messages.error(current_request, '你听的歌太少了,多听点歌再来吧~')
return result_set
运行效果
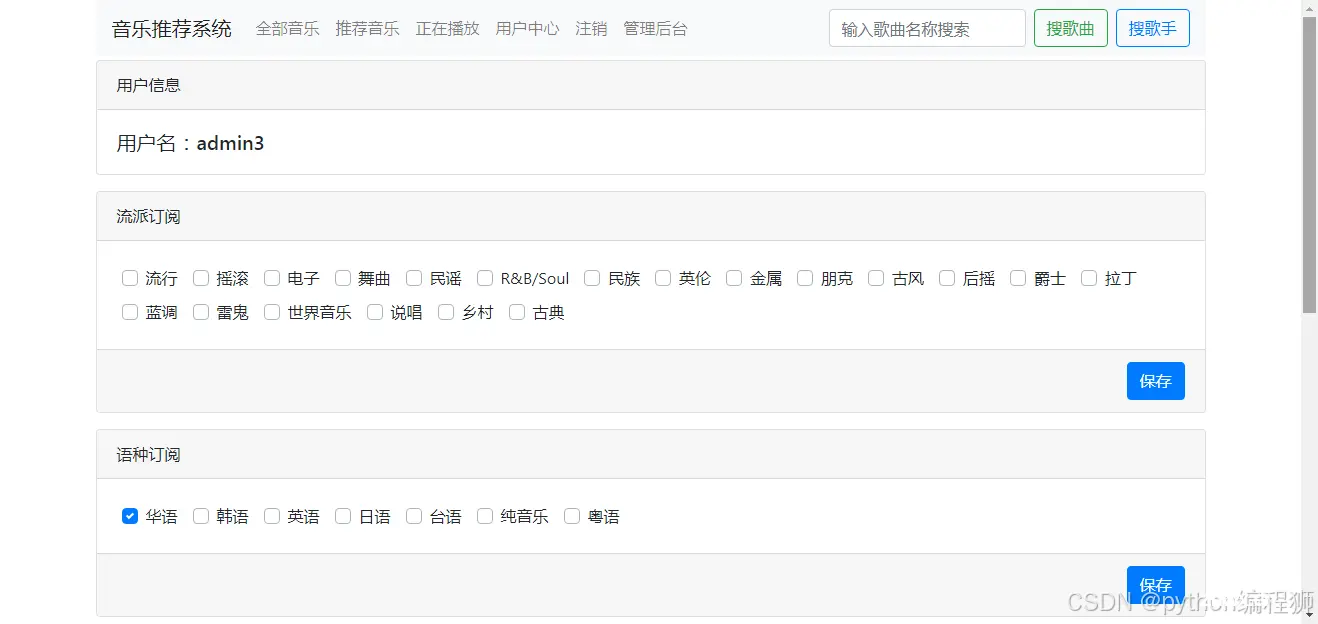
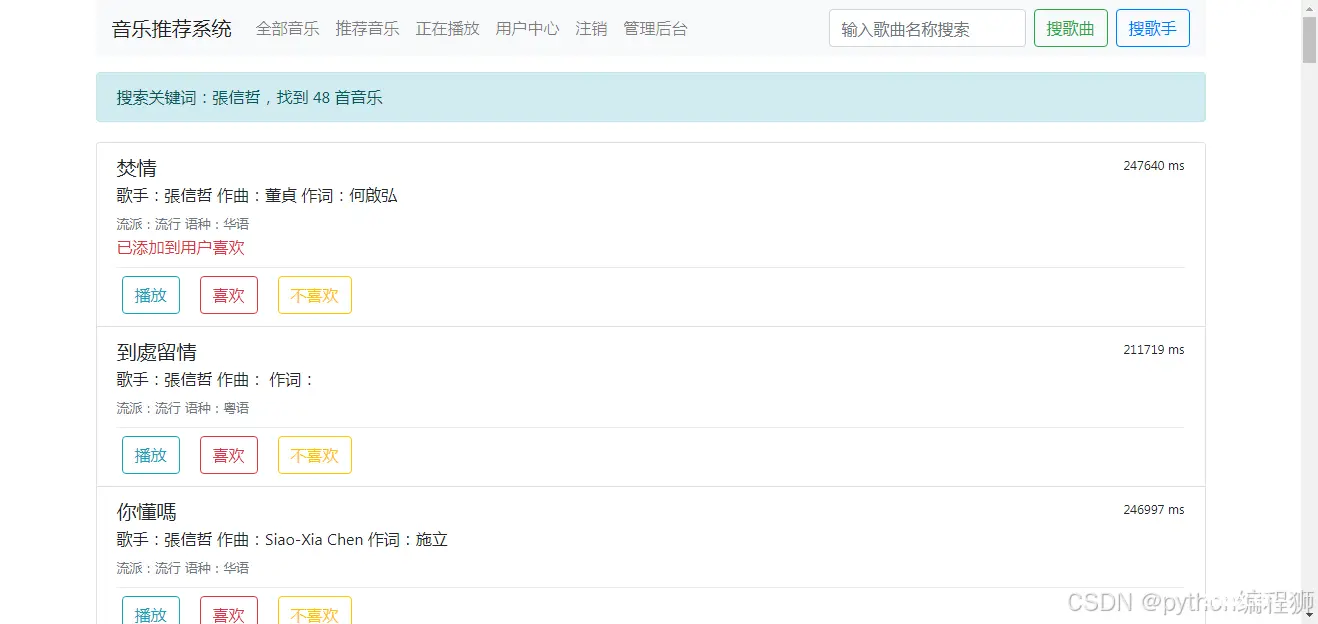



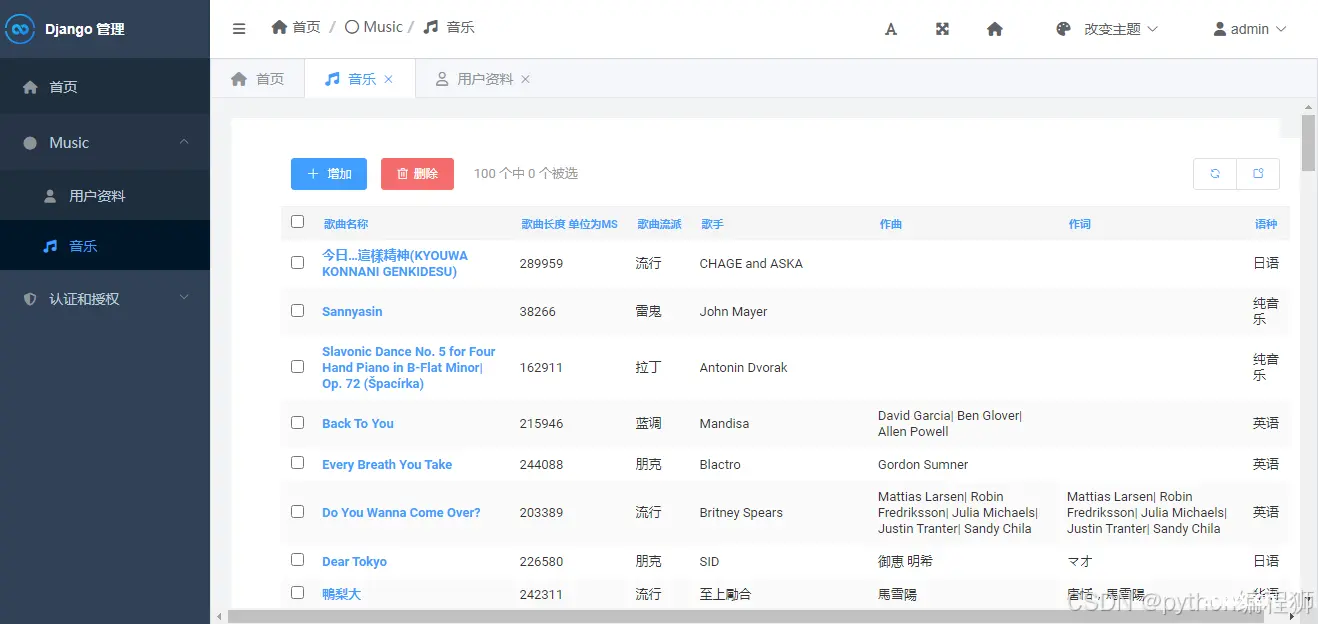


有需要代码的后台联系,白嫖勿扰
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。