大模型【Qwen2-7B本地部署(WEB版)】(windows)
略知12 2024-07-23 14:33:22 阅读 70
大模型系列文章目录
Qwen2-7B本地部署(WEB版)
前言
大模型是截止2024年上半年最强的AI,Qwen2是刚出来的号称国内最强开源大模型。这是大模型系列的第一篇文章,旨在快速部署看看最近出来的大模型效果怎么样,效果ok的话就微调自己的GPTs了。
一、Ollama下载安装
进入官网点击Download选择Windos,点击Download for Windows (Preview),这里fq会快很多默认安装
二、Qwen2下载安装
1.下载Qwen2
进入官方教程:https://qwen.readthedocs.io/zh-cn/latest/getting_started/installation.html先在最下面点击效率评估,看下各个模型占的显存,选择适合自己的,比如我的显卡是4070,有12G显存,我选择的模型就是Qwen2-7B-Instruct GPTQ-Int4
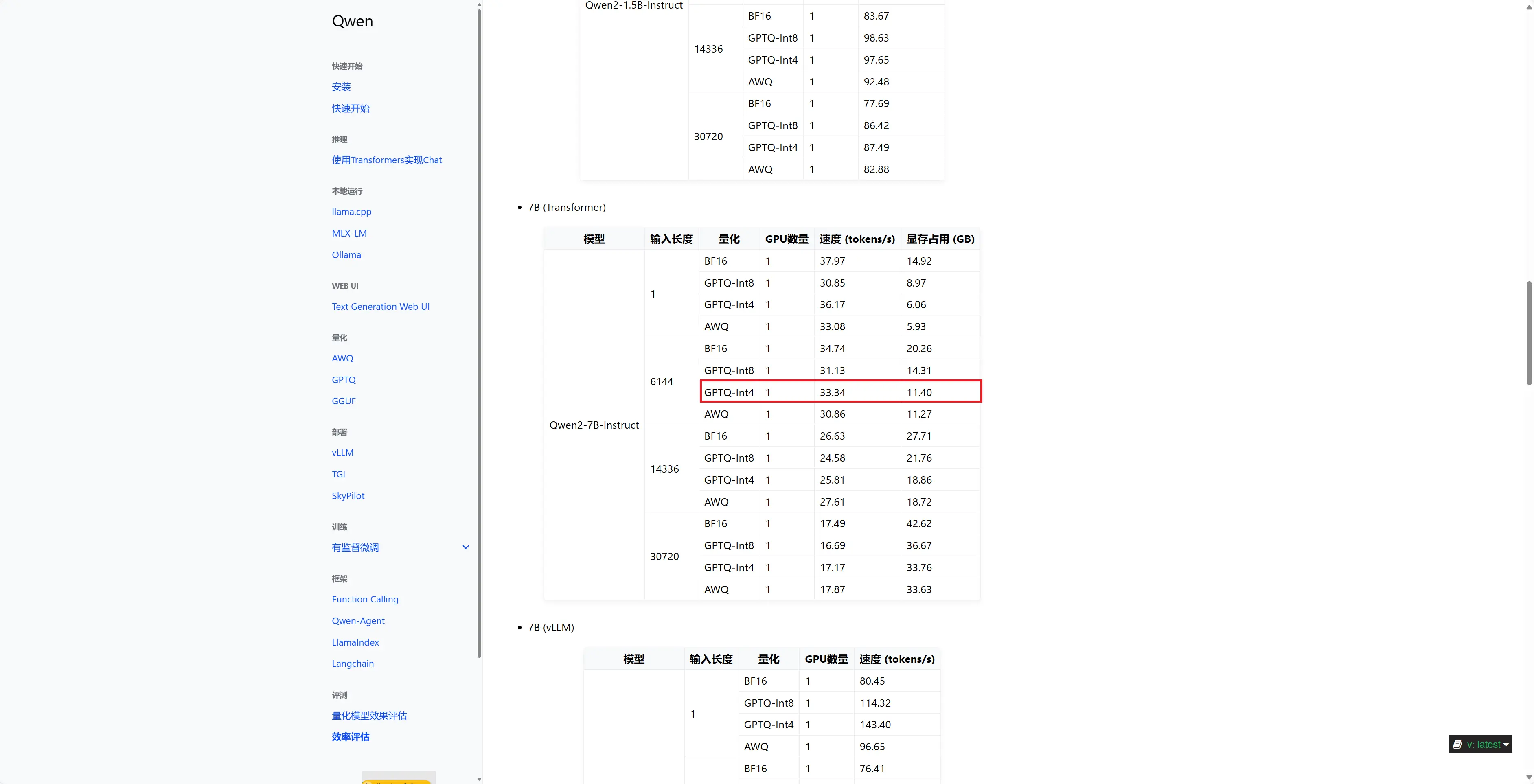
进入下载链接会看到不同的后缀,q”+ 用于存储权重的位数(精度)+ 特定变体,数字越大性能越强。数字越大,精度越高,k是在所有的attention和feed_forward张量上将精度提升2位,m是在一半的attention和feed_forward张量上将精度提升2位。根据自己的需求选择模型,我这里直接选了q8。
2.运行Qwen2
新建一个文件夹,自己取个英文名(qwen),把qwen2-7b-instruct-q8_0.gguf移到文件夹里。在文件夹里新建一个名为Modelfile的文件,里面填
<code>FROM ./qwen2-7b-instruct-q8_0.gguf
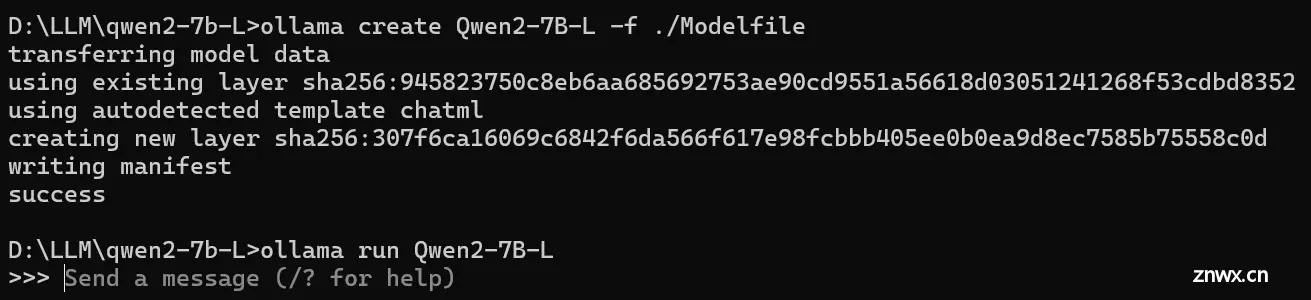
然后用命令行通过ollama创建Qwen2-7B模型:
ollama create Qwen2-7B -f ./Modelfile
出现success代表创建成功
运行,输入命令
ollama run Qwen2-7B
出现对话框就可以聊天啦
如果要看本地有哪些大模型:ollama list
如果要删除这个模型的话:ollama rm xxx
如果要看运行了哪些大模型:ollama ps
但是在dos中聊天总感觉在上世纪的聊天方式一样,所以为了找到GPT的感觉,接下来我们继续在web中实现。
三、Node.js
1.Node.js下载安装
进入Node官网下载Node,安装验证node的版本:
<code>node -v
v20以上就没问题
下载ollama-webui代码进入ollama-webui文件夹,设置国内镜像源提速:
npm config set registry http://mirrors.cloud.tencent.com/npm/
安装Node.js依赖:
npm install
如果报错说要audit,则依次进行即可:
npm audit
npm audit fix
启动Web界面:
npm run dev
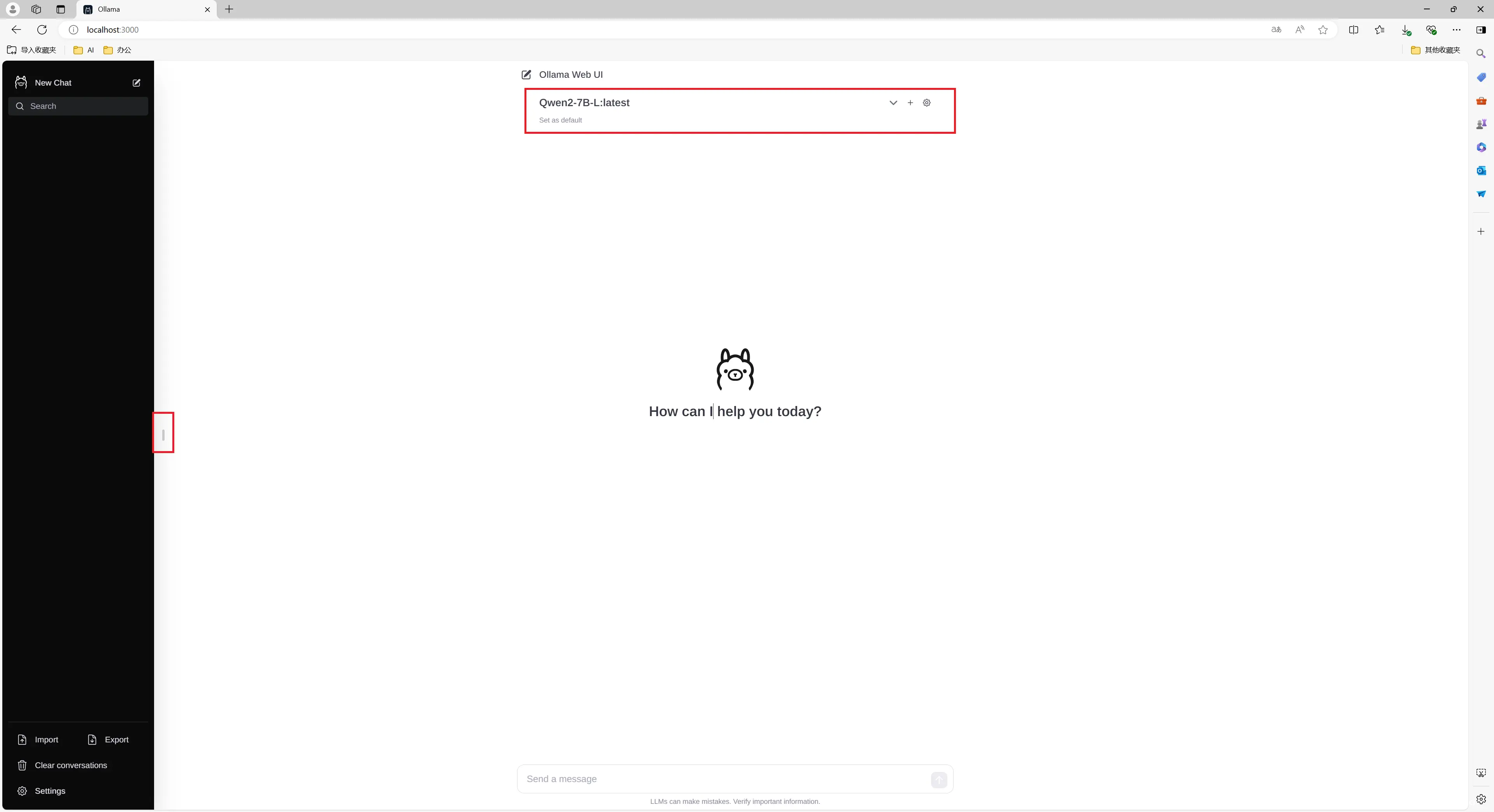
打开Web页面,选择你的模型即可开始对话:
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。