Spark--一文了解WebUI
CSDN 2024-06-25 17:33:03 阅读 78
文章目录
前言一、认识Spark UI二、Jobs2.1 了解jobs2.2 关于job我们需要知道的小知识2.2.1 多个job可以并行执行吗2.2.2 job是如何划分的2.2.3 job detai中为什么有些stage可以被跳过(skipped)2.2.4 上游stage的Shuffle Write等于下游stage的 Shuffle Read2.2.5 job提交间隔较大
三、Stages3.1 了解stage3.2 关于stage我们需要知道的小知识3.2.1 有的stage名叫`Listing leaf files and directories for xxx paths`3.2.2 有的stage会显示xxtask failed,代表什么意思呢,为什么task失败stage不会失败呢3.2.3 为什么一般spill disk要小于spill memory3.2.4 为什么要序列化3.2.5 为什么tasks中有些 index 相同3.2.6 为什么Spill (memory)/(disk)大量溢出,怎么优化
四、Storage4.1 了解Storage4.2 关于stage我们需要知道的小知识4.2.1 StorageLevel都有哪些4.2.2 ache table有什么用,和broadcast有什么关系或者区别吗
五、Environment5.1 了解environment5.2 常用参数5.2.1 executor申请&并行度5.2.2 内存分配5.2.3 文件输入输出与合并5.2.4 mapjoin5.2.5 shuffle阶段5.2.6 推测执行5.2.7 谓词下推
六、Executors6.1 了解 executors6.2 关于 executors 我们需要知道的小知识6.2.1 executor和driver到底是什么东西?6.2.2 2.storage memory中的总内存数代表什么意思
七、SQL7.1 了解 sql7.2 关于 sql 我们需要知道的小知识7.2.1 可以判断join的方式,是SortMergeJoin还是broadcast join7.2.2 判断各类操作下,有没有数据和时间倾斜7.2.3 怀疑有数据膨胀时,可以定位分析7.2.4 检查分区过滤条件是否生效
八、Debug九、Streming
前言
日常工作中经常用到sparkui来排查一些问题,有些东西需要经常搜索,网上的文章有写的很棒的,也有写的一言难尽的,这里参考了其他大佬的文章,自己整体梳理了一下,方便自己使用,也希望能帮助到大家~
一、认识Spark UI
Spark UI是反映一个Spark作业执行情况的web页面,用户可以通过Spark UI观察Spark作业的执行状态,分析可能存在的问题。
官网
进入首页后,我们可以看到当前spark的版本号,比如我这里截图的就是3.0.2。

对于在运行的
可以搜索tracking URL,然后浏览器打开spark ui的这个url链接

对于已完成的
我们可以在任务日志中搜索application_,得到application_id,一般是application_167177XXXX801_100XXXX71这种,然后搜索就可以

不管是运行中还是已完成,都可以看到有几个模块,下面我们一起来看一下(运行中相比已完成会多一个Active Jobs)

二、Jobs
2.1 了解jobs
作业整体状况,可以观察各个job的运行情况。job的划分通常以action操作区分。
官方文档
transformation:返回RDD
比如从数据源生成一个新的RDD,从RDD生成一个新的RDD action:无返回值或者返回不是RDD
比如直接将RDDcache到内存中 需要注意的一点是所有的transformation都是采用的懒策略,就是如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发。

User
spark任务提交的用户,用以进行权限控制与资源分配。 Total Uptime
spark application总的运行时间从appmaster开始运行到结束的整体时间。
该时间不是所有job的执行时间之和(有并行的job,job与job之间也有时间间隔)也不是最后一个job的结束时间➖第一个job的提交时间(作业启动到job提交之前还有一些时间) Scheduling Mode
application中task任务的调度策略,Job Scheduling由参数spark.scheduler.mode来设置
可选的参数有FAIR和FIFO,默认是FIFO。可以并行的Job,FIFO是谁先提交谁先执行可以理解为JobId小的先执行。FAIR会根据权重决定哪个Job先执行 yarn的资源调度是针对集群中不同application间的,而spark scheduler mode则是针对application内部task set级别的资源分配 Completed Jobs:
已完成Job的基本信息,如想查看某一个Job的详细情况,可点击对应Job进行查看。 Active Jobs
正在运行的Job的基本信息。 Event Timeline
时间线会显示Executor加入和退出的时间点,以及job执行的起止时间。我们可以很方便看到哪些job已经运行完成,使用了多少Excutor,哪些失败,哪些正在运行。

点击 Completed Jobs → job描述里的链接 → 各job的明细


Status
job的执行状态(running, succeeded, failed)
Associated SQL Query
关联到sql页签的query id,点击可以跳到SQL页签具体的query
DAG Visualization
可以看到job的执行计划也就是DAG图有向无环图,显示该job下执行的stage的可视化图,其中顶点表示RDDs或DataFrames,边表示要应用于RDD的操作。

2.2 关于job我们需要知道的小知识
2.2.1 多个job可以并行执行吗
可以,常见的如多个表join,每读一个表可能是一个job,多个表就是多个job,可以并行执行(前提是资源足够)
2.2.2 job是如何划分的
job的划分没有太多的意义,可以不必关注,关注stage的划分更有意义。前面也有提到过,通常以action操作区分。
2.2.3 job detai中为什么有些stage可以被跳过(skipped)
skipped的stage代表是之前以前被其他stage执行过并落盘了,并不需要重新计算,可以直接使用之前的结果。
2.2.4 上游stage的Shuffle Write等于下游stage的 Shuffle Read
常识可以在作业执行时通过上游stage的Shuffle Write量 减去 下游stage的Shuffle Read量判断执行进度另外还可以通过这个常识判断task是否有数据倾,例如还剩1个task没执行完,但是Shuffle Read量与上游Shuffle Write量相差很大,那么这个正在执行的task很有可能是数据倾斜的task。
2.2.5 job提交间隔较大
Spark默认的job调度模式是FIFO,基本上前一个job执行完就会提交下一个job。但是也有两个job间隔比较久的例子。请注意:Spark UI只展示job信息,如果Driver在前一个job执行完成后执行其他代码,或者在对下一个job的提交进行预计算,这部分耗时是不会显示在UI上的,建议通过Driver的log判断具体原因。
三、Stages
3.1 了解stage
各个Stages的运行情况,非常重要。可以理解为一个job包含多个stage。每个stage下可以查看所有task的运行情况,可以观察数据倾斜、大量溢写等现象。stage的按照宽依赖划分

宽窄依赖

Stages页面会显示作业所有的stage信息,不区分stage属于哪个job。

点击详情中的链接可以跳转到对应的stage详情页面,如图:

Total time across all tasks
当前stage中所有task花费的时间和。
Locality Level Summary
不同本地化级别下的任务数本地化级别是指数据与计算间的关系,简单说计算越靠近数据本身,速度越快(移动存储不如移动计算),所以通常情况下,会把代码发送到数据所在节点,而不是把数据拉取到代码所在节点。有 5 个级别
PROCESS_LOCAL
进程本地化task与计算的数据在同一个JVM进程中这是最好的数据本地性级别,因为它避免了网络传输的开销。 NODE_LOCAL
节点本地化情况一:task要计算的数据是在同一个Worker的不同Executor进程中;情况二:task要计算的数据是在同一个Worker的磁盘上,或在 HDFS 上,恰好有 block 在同一个节点上。虽然这比PROCESS_LOCAL稍差,因为数据需要在同一节点内的不同进程之间传输,但它仍然避免了跨节点网络传输的开销。 RACK_LOCAL
机架本地化数据在同一机架的不同节点上情况一:task计算的数据在Worker2的Executor中;情况二:task计算的数据在Worker2的磁盘上。这比NODE_LOCAL稍差,因为数据需要在同一机架内的不同节点之间传输。 NO_PREF
无偏好 ANY
任意
Input Size/Records
输入的数据字节数大小/记录条数。读取数据表或者合并文件的stage才会有指真正读取的文件大小
如果表是分区表,则代表读取的分区文件大小。如果数据表有10个字段,只select了3个字段并发生了列裁剪,则Input表明是3个字段的存储大小。
Output Size/Records
输出的数据字节数大小/记录条数生成最终结果数据的stage才会有指真正输出到hdfs上的文件大小
如果结果数据是压缩的,则代表压缩后的大小
Shuffle Write Size/Records
为下一个依赖的stage提供输入数据,shuffle过程中通过网络传输的数据字节数/记录条数有shuffle过程中的“map”操作的stage才会有为了shuffle所准备的数据,未来会有其他的stage来读取,该部分数据会写到磁盘上。应该尽量减少shuffle的数据量及其操作次数,这是spark任务优化的一条基本原则。
Shuffle Read Size/Records
shuffle阶段读取的数据大小/记录条数
既包含executor本地的数据也包含从远程executor读取的数据。 有shuffle过程中的“reduce”操作的stage才会有
DAG Visualization
当前stage中包含的详细的tranformation操作流程图。
Show Additional Metrics:
当前stage中所有task的一些指标(每一指标项鼠标移动上去后会有对应解释信息)统计信息。选择后可以在Summary Metrics中看到所有task的统计信息
Event Timeline:
以条形图+不同颜色的方式描述了各个task的不同动作下的耗时
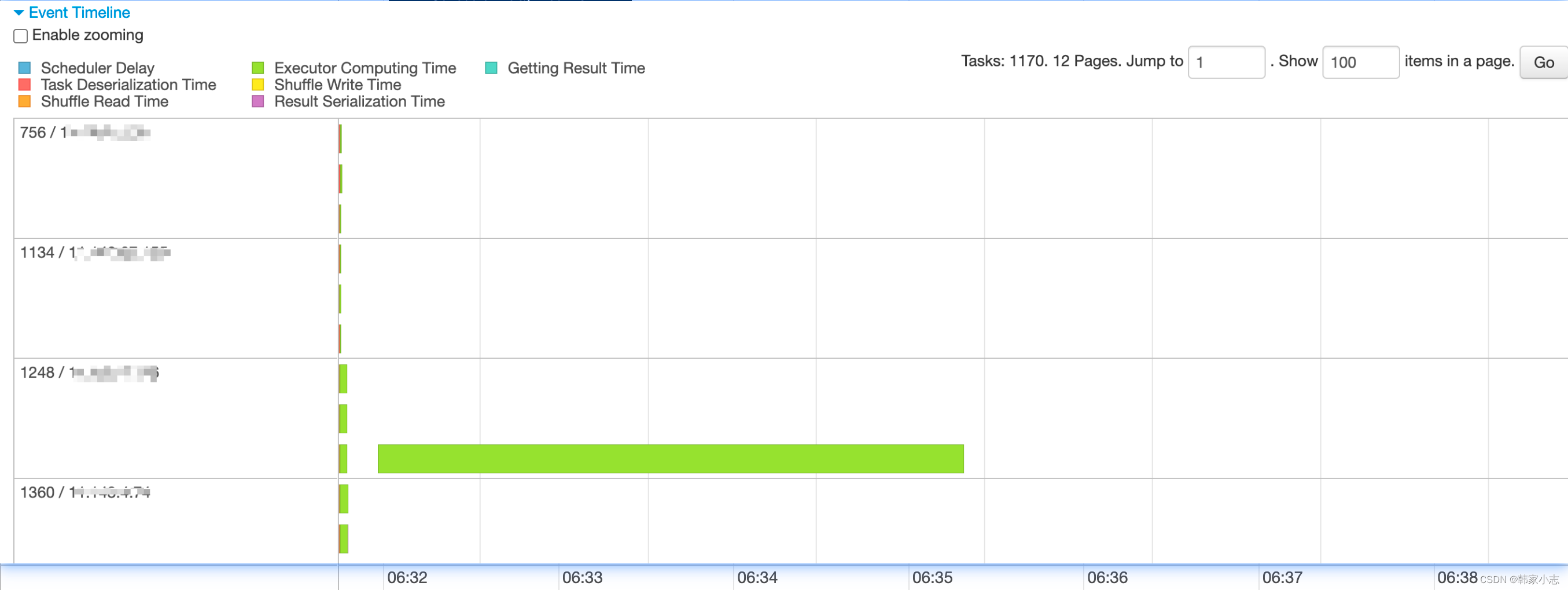
鼠标浮动到某个条形图上,可以看到该task具体的各项时间。
Scheduler delay is the time the task waits to be scheduled for execution.(调度延迟,sparkui上说如果调度延迟过长可以考虑减少task的大小或者结果的大小。)Executor Computing Time: 表示Task 执行时间,但不包含读取数据后的反序列化时间,和结果的序列化时间。Getting result time is the time that the driver spends fetching task results from workers.(driver获取结果的时间,我们的ETL中几乎没有结果需要返回driver的情况,可以不关注)Task Deserialization Time:Time spent deserializing the task closure on the executor, including the time to read the broadcasted task.(从远端或广播读取到的数据进行反序列化的时间)Shuffle Write Time :shuffle前进行shuffle写的时间Shuffle Read Time :shuffle时从远端读取数据的时间Result serialization time is the time spent serializing the task result on a executor before sending it back to the driver.(结果序列化的时间)一个“健康”的task,时间应该绝大部分花在绿色的Executor Computing Time上。如果发现其他的时间占用过多,则需要考虑是否有性能问题。
Summary Metrics for xxxx Completed Tasks
所有task的统计信息

重点关注下面几个指标
Duration
task的执行时长,如果不同task之间的Duration差异过大,或者某个task的Duration过长,需要重点看看,可能是倾斜引起。 Input Size / Records
task的输入数据量,如果不同task之间的Input Size差异过大,考虑是否有输入的数据倾斜。 Shuffle Read Size / Records
task的shuffle read数据量,如果不同task之间的shuffle read差异过大,考虑是否有shuffle的输入数据倾斜 Shuffle Write Size / Records
task的shuffle write数据量,如果不同task之间的shuffle erite差异过大,考虑是否有shuffle的输出数据倾斜(数据膨胀) Shuffle Read Blocked Time
task在读取数据是的阻塞时长,也是目前非rss任务经常出现的过长的问题,该时间过长可以考虑迁移到rss上 Spill (memory)/(disk)
task 溢出的数量,memory指的是溢出前没有序列化的大小,disk指的是序列化为字节码的大小,也是占用磁盘的空间大小。最好是控制task不要产生溢出,大量溢出会消耗大量的时间 GC Time
task运行时垃圾回收的时间,越短越好,如果过大,考虑是不是task中处理了大对象比如复合类型的字段或者超长的string字段。
Aggregated Metrics by Executor:
将task运行的指标信息按excutor做聚合后的统计信息,并可查看某个Excutor上任务运行的日志信息。

Tasks
当前stage中所有任务运行的明细信息,是与Event Timeline中的信息对应的文字展示(可以点击某个task查看具体的任务日志)。
3.2 关于stage我们需要知道的小知识
3.2.1 有的stage名叫Listing leaf files and directories for xxx paths

spark 作业在启动前会从文件系统中查询数据的元数据并将其缓存到内存中元数据包括一个 partition 的列表和文件的一些统计信息(路径,文件大小,是否为目录,备份数,块大小,定义时间,访问时间,数据块位置信息)。一旦数据缓存后,在后续的查询中,表的 partition 就可以在内存中进行下推,得以快速的查询。将元数据缓存在内存中虽然提供了很好的性能,但在 spark 加载所有表分区的元数据之前,会阻塞查询。对于大型分区表,递归的扫描文件系统以发现初始查询文件的元数据可能会花费数分钟。后来,spark在读取数据时会先判断分区的数量,如果分区数量小于等于spark.sql.sources.parallelPartitionDiscovery.threshold (默认32),则使用 driver 循环读取文件元数据,如果分区数量大于该值,则会启动一个 spark job,并发的处理元数据信息(每个分区下的文件使用一个task进行处理)。分区数量很多意味着 Listing leaf files task 的任务会很多,分区里的文件数量多意味着每个 task 的负载高。
3.2.2 有的stage会显示xxtask failed,代表什么意思呢,为什么task失败stage不会失败呢

某些stage除了会显示总的task数,执行成功task数和killed task数,还会显示failed task数failed task数量就代表该stage中执行失败的task数量。为什么task失败而stage不会失败,是因为spark有一系列的重试机制来为分布式下大量任务的容错。
1)application层面的容错:spark.yarn.maxAppAttempts
代表一个app会最多执行几次,如果设置的是3就代表失败后会重试2次,如设置的是1,即不会重试。 2)executor层面的容错:spark.yarn.max.executor.failures
代表一个executor连续执行失败几次会被中止报错信息:Final app status: FAILED, exitCode: 11, (reason: Max number of executor failures (200) reached) 3)stage层面的容错:spark.stage.maxConsecutiveAttempts
代表一个stage连续执行失败几次会被中止 4)task层面的容错:spark.task.maxFailures
代表一个task连续执行失败几次会被中止 5)某些动作层面的容错
比如spark.shuffle.io.maxRetries、spark.rpc.numRetries、spark.rpc.retry.wait、spark.rpc.askTimeout、spark.rpc.lookupTimeout用来容错shuffle时的io异常和rpc通信的异常
shuffle拉取数据的时候,有可能连接的那台机器正在gc,响应不了,所以拉取shuffle-io有重试,还可以设置重试的间隔等等spark中,相互通信,基本上都是rpc发送,举个例子,一个task处理完了,通过spark内置的RPC框架往endpoint发送处理完了的消息,RPC的服务端,拿到这个消息做一个后续的处理,这之间的通信也需要有重试等机制,如果处理的数据量比较大,应该适当增加上述参数的时间 类似的参数非常多,可以在spark参数中搜索attempt、failures、retries等看到
3.2.3 为什么一般spill disk要小于spill memory
因为一个java的对象、字符串、集合类型在内存中为了更快的访问,都存储了超量的信息。比如一个对象需要存储,对象头存储信息,和对齐填充,一般来说即使是一个空对象,也需要占用对象头12-20字节。而序列化之后则不用存储这些内容。另外序列化也是一个重新的编码,也会起到“压缩”的效果
3.2.4 为什么要序列化
两个进程在进行远程通信时,都会以二进制序列的形式在网络上传送。无论是何种类型的数据,发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
3.2.5 为什么tasks中有些 index 相同

3.2.6 为什么Spill (memory)/(disk)大量溢出,怎么优化
可以看下这篇文章
四、Storage
4.1 了解Storage
持久化数据的存储情况,比如说cache,persist。如果job在执行时持久化(persist)/缓存(cache)了一个RDD,那么RDD的信息可以在这个选项卡中查看。点击某个RDD即可查看该RDD缓存的详细信息,包括缓存在哪个Executor中,使用的block情况,RDD上分区(partitions)的信息以及存储RDD的主机的地址。注意: Storage页面只在运行时显示, 作业结束后是不会展示任何信息的。

点击具体的rdd后,可以看到详细信息

4.2 关于stage我们需要知道的小知识
4.2.1 StorageLevel都有哪些
大致分为内存对象、内存和磁盘、内存序列化、内存和磁盘序列化、磁盘、双副本、堆外内存。通常情况下,在内存对象和内存序列化访问速度最快。
4.2.2 ache table有什么用,和broadcast有什么关系或者区别吗
首先cache table和broadcast join并没有绝对的关系。cache table是把数据缓存在内存(绝大部分情况)或本地磁盘上
适用的场景主要是缓存一段“反复使用的逻辑的结果”。比如我们经常写的with xxx as是把一段逻辑封装成一个虚拟表,但是真正在计算时,多次引用会多次触发这段逻辑计算,所以只是写起来精简,但执行上并没有一次运行多次复用。使用了cache table则能把这段逻辑的结果进行缓存,后面代码在引用时不会重新计算这段逻辑生成结果,实现了一次计算多次复用。有时我们使用create [temporary] table来固话一段逻辑的结果也可以实现类似的效果,只不过cache table大多在内存中,访问速度会非常快,非常适合内存中的迭代计算。 由于cache table多是缓存在内存中,数据量一般很小,很大概率会小于参数spark.sql.autoBroadcastJoinThreshold设置的值,因而触发了自动的广播。
五、Environment
5.1 了解environment
程序的环境变量,主要用来查看参数有没设置对。

比如参数后面用中文“;”而不是英文“;”
比如参数的“=”两边有空格
比如参数写错误
在Environment页面依然能够看到这个参数,但实际上参数是不生效的

hive参数官方文档spark参数官方文档hadoop参数官方文档
5.2 常用参数
5.2.1 executor申请&并行度
一般需要大数量下,需要提升任务并行度时可以考虑修改这些参数spark.dynamicAllocation.enabled
是否开启动态资源分配,平台默认开启,同时强烈建议用户不要关闭。理由:开启动态资源分配后,Spark可以根据当前作业的负载动态申请和释放资源。 spark.dynamicAllocation.maxExecutors
开启动态资源分配后,同一时刻,最多可申请的executor个数。当在Spark UI中观察到task较多时,可适当调大此参数,保证task能够并发执行完成,缩短作业执行时间。但同时申请过多的executor会带来资源使用的开销,所以要多方面考虑来设置 spark.dynamicAllocation.minExecutors
和maxExecutors相反,此参数限定了某一时刻executor的最小个数。默认设置为2,即在任何时刻,作业都会保持至少有3个及以上的executor存活,保证任务可以迅速调度。部分小任务有时会出现申请不到资源而一直等待,可以尝试设置该参数为1,减少pending的概率 spark.dynamicAllocation.initialExecutors
初始化的时候的executor数量,仅在动态资源分配时生效 spark.executor.instances
初始化的时候的executor数量,动态和非动态资源分配均生效 spark.executor.cores
单个executor上可以同时运行的task数。Spark中的task调度在线程上,该参数决定了一个executor上可以并行执行几个task。这几个task共享同一个executor的内存·(spark.executor.memory+spark.yarn.executor.memoryOverhead)。适当提高该参数的值,可以有效增加程序的并行度,让作业执行的更快,但会使executor端的日志变得不易阅读,同时增加executor内存压力,容易出现OOM所以一般需要配合的增加executor的内存。在作业executor端出现OOM时,如果不能增大spark.executor.memory,可以适当降低该值。该参数是executor的并发度,和spark.dynamicAllocation.maxExecutors配合,可以提高整个作业的并发度。
5.2.2 内存分配
一般出现了内存溢出,可以考虑修改这些参数spark.executor.memory
executor用于缓存数据、代码执行的堆内存以及JVM运行时需要的内存。当executor端由于OOM时,多数是由于spark.executor.memory设置较小引起的。该参数一般可以根据表中单个文件的大小进行估计,但是如果是压缩表如ORC,则需要对文件大小乘以2 ~ 3倍,这是由于文件解压后所占空间要增长2~3倍。 spark.yarn.executor.memoryOverhead
Spark运行还需要一些堆外内存,直接向系统申请,如数据传输时的netty等。Spark根据spark.executor.memory+spark.yarn.executor.memoryOverhead的值向RM申请一个容器,当executor运行时使用的内存超过这个限制时,会被yarn kill掉。最大值是16GB spark.driver.memory
driver使用内存大小, 根据作业的大小可以适当增大或减小此值。一般有大表的广播可以考虑增加这个数值 spark.yarn.driver.memoryOverhead
spark.driver.memory * 0.1,并且不小于384m类似于spark.yarn.executor.memoryOverhead,即Driver Java进程的off-heap内存 spark.memory.fraction
存储+执行内存占节点总内存的大小。 spark.memory.storageFraction
内存模型中存储内存占存储+执行内存的比例,由于在同一内存管理下可以动态的占用,该参数保持不变即可 spark.sql.windowExec.buffer.spill.threshold
当用户的SQL中包含窗口函数时,并不会把一个窗口中的所有数据全部读进内存,而是维护一个缓存池,当池中的数据条数大于该参数表示的阈值时,spark将数据写到磁盘。该参数如果设置的过小,会导致spark频繁写磁盘如果设置过大则一个窗口中的数据全都留在内存,有OOM的风险。但是,为了实现快速读入磁盘的数据,spark在每次读磁盘数据时,会保存一个1M的缓存。举例:当spark.sql.windowExec.buffer.spill.threshold为10时,如果一个窗口有100条数据,则spark会写9((100 - 10)/10)次磁盘,在读的时候,会创建9个磁盘reader,每个reader会有一个1M的空间做缓存,也就是说会额外增加9M的空间。当某个窗口中数据特别多时,会导致写磁盘特别频繁,就会占用很大的内存空间作缓存。因此如果观察到executor的日志中存在大量“spilling data because number of spilledRecords crossed the threshold”日志,则可以考虑适当调大该参数。
5.2.3 文件输入输出与合并
当出现map端数据倾斜,map端由于小文件启动大量task,或者结果生成大量小文件时,可以考虑修改这些参数spark.hadoop.hive.exec.orc.split.strategy
BI策略以文件为粒度进行split划分;ETL策略会将文件进行切分,多个stripe组成一个split;HYBRID策略为:当文件的平均大小大于hadoop最大split值(默认256M)时使用ETL策略,否则使用BI策略。该参数只对orc格式生效。注意:当ETL策略生效时,如果输入文件的数量以及每个文件的stripe数量过多,有可能会导致driver压力过大,出现长时间计算不出task数量,甚至OOM的情况。当BI策略生效时,也有可能会出现输入数据倾斜。 spark.hadoop.mapreduce.input.fileinputformat.split.minsize、spark.hadoop.mapreduce.input.fileinputformat.split.maxsize
map端输入文件的切分和合并参数,可以把小文件进行合并,大文件进行切割这两个参数控制了单个文件的切分和合并大小,跨文件、跨分区不行maxsize控制了split的最大值,minsize控制了最小值 spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version
文件提交算法MapReduce-4815 详细介绍了 fileoutputcommitter 的原理version=2 是批量按照目录进行提交,version=1是一个个的按照文件提交。设置 version=2 可以极大的节省文件提交至hdfs的时间,减轻nn压力。 spark.sql.adaptive.shuffle.targetPostShuffleInputSize
开启spark.sql.adaptive.enabled后,最后一个stage在进行动态合并partition时,会根据shuffle read的数据量除以该参数设置的值来计算合并后的partition数量。所以增大该参数值会减少partition数量,反之会增加partition数量。注意:对于shuffle read数据量很大,但是落地文件数很小无法很好的处理,例如:小表left join大表 spark.sql.mergeSmallFileSize
与 hive.merge.smallfiles.avgsize 类似,写入hdfs后小文件合并的阈值。如果生成的文件平均大小低于该参数配置,则额外启动一轮stage进行小文件的合并 spark.sql.targetBytesInPartitionWhenMerge
与hive.merge.size.per.task 类似,当额外启动一轮stage进行小文件的合并时,会根据该参数的值和input数据量共同计算出partition数量
5.2.4 mapjoin
想使用自动mapjoin时,需要考虑的参数spark.sql.autoBroadcastJoinThreshold
当执行join时,小表被广播的阈值。当被设置为-1,则禁用广播。表大小需要从 Hive Metastore 中获取统计信息。该参数设置的过大会对driver和executor都产生压力。注意,由于我们的表大部分为ORC压缩格式,解压后的数据量3-5倍甚至10倍 spark.sql.statistics.fallBackToHdfs
当从Hive Metastore中没有获取到表的统计信息时,返回到hdfs查看其存储文件大小,如果低于spark.sql.autoBroadcastJoinThreshold依然可以走mapjoin。 spark.sql.broadcastTimeout
在broadCast join时 ,广播等待的超时时间
5.2.5 shuffle阶段
spark.sql.shuffle.partitions
reduce阶段(shuffle read)的数据分区,分区数越多,启动的task越多(1:1),“一般”来说速度会变快,同时生成的文件数也会越多。个人建议一个partition保持在256mb左右的大小就好 spark.sql.adaptive.enabled
是否开启调整partition功能,如果开启,spark.sql.shuffle.partitions设置的partition可能会被合并到一个reducer里运行。平台默认开启,同时强烈建议开启。理由:更好利用单个executor的性能,还能缓解小文件问题。 spark.sql.adaptive.shuffle.targetPostShuffleInputSize
开启spark.sql.adaptive.enabled后,最后一个stage在进行动态合并partition时,会根据shuffle read的数据量除以该参数设置的值来计算合并后的partition数量。所以增大该参数值会减少partition数量,反之会增加partition数量。注意:对于shuffle read数据量很大,但是落地文件数很小无法很好的处理,例如:小表left join大表 spark.sql.adaptive.minNumPostShufflePartitions
开启spark.sql.adaptive.enabled后,合并之后保底会生成的分区数 spark.shuffle.service.enabled
启用外部shuffle服务,这个服务会安全地保存shuffle过程中,executor写的磁盘文件,因此executor即使挂掉也不要紧,必须配合spark.dynamicAllocation.enabled属性设置为true,才能生效,而且外部shuffle服务必须进行安装和启动,才能启用这个属性 spark.reducer.maxSizeInFlight
同一时刻一个reducer可以同时拉取的数据量大小 spark.reducer.maxReqsInFlight
同一时刻一个reducer可以同时产生的请求数 spark.reducer.maxBlocksInFlightPerAddress
同一时刻一个reducer向同一个上游executor最多可以拉取的数据块数 spark.reducer.maxReqSizeShuffleToMem
shuffle请求的文件块大小 超过这个参数值,就会被强行落盘,防止一大堆并发请求把内存占满,社区版默认Long.MaxValue spark.shuffle.io.connectionTimeout
客户端超时时间,超过该时间会fetchfailed spark.shuffle.io.maxRetries
shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
5.2.6 推测执行
spark.speculation
spark推测执行的开关,作用同hive的推测执行。(注意:如果task中有向外部存储写入数据,开启推测执行则可能向外存写入重复的数据,要根据情况选择是否开启) spark.speculation.interval
开启推测执行后,每隔多久通过checkSpeculatableTasks方法检测是否有需要推测式执行的tasks spark.speculation.quantile
当成功的Task数超过总Task数的spark.speculation.quantile时(社区版默认75%),再统计所有成功的Tasks的运行时间,得到一个中位数,用这个中位数乘以spark.speculation.multiplier(社区版默认1.5)得到运行时间门限,如果在运行的Tasks的运行时间超过这个门限,则对它启用推测。如果资源充足,可以适当减小spark.speculation.quantile和spark.speculation.multiplier的值 spark.speculation.multiplier
解释见上面spark.speculation.quantile
5.2.7 谓词下推
spark.sql.parquet.filterPushdown
parquet格式下的谓词下推开关 spark.sql.orc.filterPushdown
orc格式下的谓词下推开关(此处有疑惑,尝试关闭后发现还是下推了) spark.sql.hive.metastorePartitionPruning
当为true,spark sql的谓语将被下推到hive metastore中,更早的消除不匹配的分区(此处有疑惑,尝试关闭后发现还是下推了)
六、Executors
6.1 了解 executors
展示了executor和driver的一些统计信息和明细信息
汇总信息包括内存、磁盘、cpu的使用量,任务执行时间、GC时间,成功、失败、完成的task数量,以及输入输出的数据量等内容。明细信息除了和汇总信息相同的内容,还有每个executor和driver的日志信息。 需要注意的是,这个页面中显示的内存使用和executor状态信息都是瞬时值,任务在执行过程中会一直变化,任务执行结束内存指标都会清零。

6.2 关于 executors 我们需要知道的小知识
6.2.1 executor和driver到底是什么东西?
executor和driver并不是物理上的机器,而是宿主在机器上的跑在jvm上的进程,这点从address也可以看出(机器名+端口号)
6.2.2 2.storage memory中的总内存数代表什么意思
storage memory,虽然名字看起来是存储内存的大小,但实际上由于spark1.6之后已经实现了统一内存管理(即执行内存和存储内存使用同一个统一内存)所以storage memory实际上是统一内存的大小,是sparkSQL中我们设置spark.executor.memory和spark.memory.fraction,在jvm中能够被用来计算和存储的内存。如下图红圈部分是storage memory的范围。

七、SQL
7.1 了解 sql
Spark sql才有,展示sql的执行情况。
可以查看SQL执行计划的细节,它提供了SQL查询的DAG以及显示Spark如何优化已执行的SQL查询的查询计划。

每个色块代表了一种算子
鼠标在算子的色块上悬停,可以看到更为详细的信息每个算子都会展示一些matrics,基本上也是见名知意的,方便排查问题SQL Metrics

色块代表什么呢
Scan
扫描表 ColumnarToRowFilter
sql中的过滤操作(where 过滤)当然,不能直接对应sql中的where,因为查询优化器会将SQL语句转换成物理执行计划,这个过程中可能修改或者重新移动filters Project
sql中的投影操作(select 选择列) HashAggregate
表示数据聚合一般成对出现,一般会被 exchange (shuffle,在集群上移动数据) 隔开
第一个执行节点本地的数据进行局部聚合第二个将各个分区的数据进一步进行聚合计算 Exchange
在集群上移动数据 UnionBroadcastHashJoin
广播方式进行hashjoin BroadcastExchangeBroadcastHashJoin(BHJ)
BHJ总是伴随着BroadcastExchange,这个代表着广播shuffle-数据将会收集到driver端并且会被传播到需要的executor上。 SortMergeJoinShuffleHashJoin
最下面有个detail,可以查看sql执行计划,包括Parsed Logical Plan、Analyzed Logical Plan、Optimized Logical Plan、Physical Plan

7.2 关于 sql 我们需要知道的小知识
7.2.1 可以判断join的方式,是SortMergeJoin还是broadcast join

7.2.2 判断各类操作下,有没有数据和时间倾斜

7.2.3 怀疑有数据膨胀时,可以定位分析

7.2.4 检查分区过滤条件是否生效

八、Debug
错误诊断信息及不同类型Executor的时间线图方便用户查看任务执行期间申请的Executor数量requestedTotalExecutors
当前时间点已经提交申请的executor个数,包括已申请到的 numExistingExecutors 和 未申请到的numPendingExecutors numExistingExecutors
当前时间点已经申请到的executor个数包括 空闲待回收的executorsPendingToRemove 和 正在执行任务的 executorsActive numPendingExecutors
当前时间点已经提交申请,未申请到等待资源的executor个数 executorsPendingToRemove
当前时间点等待回收的executor个数 executorsPendingLossReason
丢失的executors个数,常见原因如资源抢占强制kill掉 executorsActive
当前时间点有任务在执行的executor个数
九、Streming
Spark streaming作业才有,展示每个阶段的执行情况。暂不深究。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。