实现语音合成的三种方法:HTML5 Web Speech 、speak-tts、百度语音合成
芭拉拉小魔仙 2024-10-09 13:03:01 阅读 60
1. 使用HTML5 Web Speech API
1.1 使用方法
<code>window.speechSynthesis 是HTML5 Web Speech API的一部分,是浏览器原生提供的文本转语音功能。它允许开发者在网页上通过JavaScript调用,将文本转换为语音进行播放。
https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Speech_API
示例代码:
<template>
<div>
<button @click="speakVoice('测试语音播放')">播放语音</button>code>
</div>
</template>
<script setup lang="ts">code>
const voices = ref<SpeechSynthesisVoice[]>([]);
//语音播报
const speakVoice = (msg:any) => { -- -->
window.speechSynthesis.cancel();
try {
initVoices().then(()=>{
//实例化播报内容
var instance = new SpeechSynthesisUtterance();
instance.text = msg; // 文字内容: 测试内容
instance.lang = "zh-CN"; // 使用的语言:中文
instance.volume = 1; // 声音音量:1
instance.rate = 1.5; // 语速:1
instance.pitch = 1; // 音高:1
//instance.voice = null; // 某人的声音
//let voices = window.speechSynthesis.getVoices();
instance.voice = voices.value.filter(function (voice) {
return voice.localService == true && voice.lang == 'zh-CN'
})[0]
// instance.voice = window.speechSynthesis.getVoices()[0];//选中第一个语音包
instance.addEventListener("end", () => { });// 监听播报完成状态,播完可以做些其它处理
console.log(instance)
window.speechSynthesis.speak(instance)
})
} catch (error) {
console.log(error)
}
}
// 初始化语音列表
async function initVoices() {
if (!window.speechSynthesis) {
console.error('Speech synthesis is not supported in this browser.');
return;
}
// 获取当前的声音列表
voices.value = window.speechSynthesis.getVoices();
// 监听语音变化 Chrome允许使用远程服务器进行语音合成,而SpeechSynthesis向谷歌服务器请求语音列表。要解决此问题,您需要等待语音将被加载,然后再次请求它们。
speechSynthesis.onvoiceschanged = () => {
voices.value = window.speechSynthesis.getVoices();
};
// 等待语音列表加载完成
await new Promise<void>((resolve) => {
if (voices.value.length > 0) {
resolve();
} else {
const intervalId = setInterval(() => {
const newVoices = window.speechSynthesis.getVoices();
if (newVoices.length > 0) {
voices.value = newVoices;
clearInterval(intervalId);
resolve();
}
}, 1000);
}
});
}
//语音暂停
const beQuiet = () => {
console.log('语音播报停止')
window.speechSynthesis.cancel();
}
onMounted(()=>{
//初始化
initVoices();
})
</script>
1.2 优缺点
优点:
原生支持:无需安装任何外部库或插件,主流现代浏览器均支持。功能丰富:支持多种语言和音频设置,可以自定义语音风格、发音调整、语速、音量等。应用广泛:适用于网站辅助阅读、语音导航、语音消息提示等多种场景。
缺点:
浏览器兼容性:不完全兼容IE浏览器,需要额外的兼容处理。语音包限制:语音包的选择和质量可能受到浏览器和操作系统的限制。
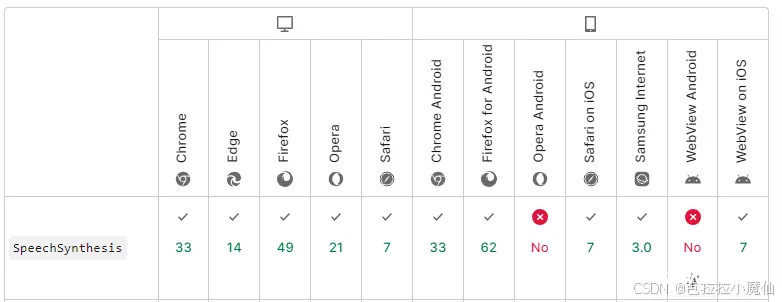
2. 使用<code>speak-tts
speak-tts是一个基于浏览器SpeechSynthesis API的封装库,它提供了更加丰富的功能和更好的兼容性处理。
2.1使用方法
步骤 1: 安装speak-tts
首先,你需要在你的Vue 3项目中安装speak-tts。在你的项目根目录下,通过npm或yarn来安装:
npm install speak-tts
# 或者
yarn add speak-tts
步骤 2: 在Vue组件中引入speak-tts
然后,在你的Vue组件中引入speak-tts并使用它。以下是一个Vue 3组件的示例,展示了如何设置并使用speak-tts。
<template>
<div>
<textarea v-model="textToSpeak" placeholder="Enter text to speak"></textarea>code>
<button @click="speakText">Speak Text</button>code>
</div>
</template>
<script lang="ts">code>
import { defineComponent, ref } from 'vue';
import SpeakTTS from 'speak-tts';
export default defineComponent({
setup() {
const textToSpeak = ref('');
let speech: SpeakTTS | null = null;
const initSpeech = async () => {
try {
speech = new SpeakTTS();
await speech.init({
volume: 1,
lang: 'en-US',
rate: 1,
pitch: 1,
splitSentences: true,
});
} catch (error) {
console.error('Failed to initialize SpeakTTS:', error);
}
};
const speakText = async () => {
if (!speech) {
await initSpeech();
}
try {
await speech.speak({
text: textToSpeak.value,
queue: true,
listeners: {
onstart: () => console.log('Start speaking'),
onend: () => console.log('End speaking'),
onerror: (error) => console.error('Error during speaking:', error),
},
});
} catch (error) {
console.error('Failed to speak text:', error);
}
};
return { textToSpeak, speakText };
},
});
</script>
<style scoped>
/* Add your styles here */
</style>
解释
模板部分:包含一个文本域用于输入要转换的文字,和一个按钮来触发语音播放。
设置部分:
使用ref来响应式地存储文本和SpeakTTS实例。initSpeech函数用于初始化SpeakTTS实例,设置默认的音量、语言、语速和音调等。speakText函数用于播放文本。如果SpeakTTS实例未初始化,则先调用initSpeech。然后使用speak方法播放文本,并附加了一些监听器来处理开始、结束和错误事件。
3. 使用百度语音合成API
百度语音合成(Text-to-Speech, TTS)是一项强大的服务,它能够将文本转换成流畅的语音输出。
3.1使用方法
步骤 1: 注册百度AI开放平台账号并获取API Key
首先,你需要在百度AI开放平台注册一个账号,并创建应用以获取API Key和Secret Key。这些密钥将用于认证你的请求,从而使用百度语音合成服务。
步骤 2: 安装必要的库
在Vue 3项目中,你可能需要使用axios或fetch来发送HTTP请求。这里我们使用axios作为示例。首先,你需要安装axios:
npm install axios
# 或者
yarn add axios
步骤 3: 创建Vue 3组件
在你的Vue 3项目中,创建一个新的组件用于处理语音合成的逻辑。
组件模板
<template>
<div>
<textarea v-model="textToSynthesize" placeholder="Enter text to synthesize"></textarea>code>
<button @click="synthesizeText">Synthesize Text</button>code>
<audio ref="audioElement" controls></audio>code>
</div>
</template>
组件脚本
在<script>标签中,使用TypeScript定义组件的逻辑。
<script lang="ts">code>
import { -- --> defineComponent, ref, onMounted } from 'vue';
import axios from 'axios';
export default defineComponent({
setup() {
const textToSynthesize = ref('');
const audioElement = ref<HTMLAudioElement | null>(null);
const synthesizeText = async () => {
if (!textToSynthesize.value.trim()) {
alert('Please enter some text to synthesize.');
return;
}
try {
// 配置API请求参数
const accessToken = 'YOUR_ACCESS_TOKEN'; // 从百度AI开放平台获取
const baseUrl = 'https://aip.baidubce.com/oauth/2.0/token';
const ttsUrl = 'https://aip.baidubce.com/rest/2.0/tts/v1/text_to_speech';
// 这一步通常是先获取access token,但为简化示例,我们假设已经拥有
// 在实际应用中,你需要请求一个token接口,并在请求TTS时使用它
// 构造TTS请求体
const params = {
text: textToSynthesize.value,
lan: 'zh', // 语言,这里使用中文
spd: 5, // 语速,可以是1-9,数字越大语速越快
pit: 5, // 音调,可以是0-9,数字越大声音越尖
vol: 5, // 音量,可以是0-15,数字越大音量越大
per: 4, // 发音人选择, 0为女声,1为男声,3为情感合成-度逍遥,4为情感合成-度丫丫
cue_text: '', // 提示音文本,用于在合成语音前给用户一个提示
aue: 'mp3', // 音频编码格式,这里使用mp3
token: accessToken,
};
// 发送请求到百度TTS API
const response = await axios.post(ttsUrl, params, {
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
},
paramsSerializer: params => {
return Object.keys(params)
.map(key => `${ encodeURIComponent(key)}=${ encodeURIComponent(params[key])}`)
.join('&');
},
responseType: 'blob', // 响应类型为blob,用于下载音频文件
});
// 处理响应并播放音频
const url = URL.createObjectURL(new Blob([response.data]));
if (audioElement.value) {
audioElement.value.src = url;
audioElement.value.play();
}
} catch (error) {
console.error('Error during synthesizing text:', error);
alert('Failed to synthesize text.');
}
};
return { textToSynthesize, audioElement, synthesizeText };
},
});
</script>
注意:上述代码示例中,YOUR_ACCESS_TOKEN应替换为你从百度AI开放平台获取的实际API Key。在实际应用中,你还需要处理token的获取和刷新逻辑,因为token有一定的有效期。
3.2优缺点
优点:
专业性强:百度语音合成API基于百度强大的语音识别和语音合成技术,提供了高质量的语音合成服务。其音色自然、语速可调、发音准确,适用于多种场景。丰富的功能:百度语音合成API支持多种语言、音色选择、语速调节等功能,可以满足不同用户的需求。同时,它还提供了API接口和SDK等多种接入方式,方便开发者集成和使用。稳定性高:作为专业的语音合成服务,百度语音合成API具有较高的稳定性和可靠性。它可以在高并发、大流量的场景下保持稳定的性能表现。文档和支持完善:百度为开发者提供了详细的API文档和技术支持,帮助开发者快速上手并解决问题。
缺点:
依赖外部服务:使用百度语音合成API需要依赖百度的服务器进行语音合成处理。这可能导致在网络状况不佳或百度服务器出现故障时无法使用或功能受限。成本考虑:虽然百度语音合成API提供了免费试用和付费服务两种模式,但对于需要高频次、大量使用的场景来说,成本可能会成为一个考虑因素。集成复杂度:与Web Speech API相比,集成百度语音合成API可能需要更多的配置和代码编写工作。这可能会增加开发者的工作量和时间成本。
综上所述,HTML5 Web Speech API和百度语音合成API在实现语音合成方面各有其优缺点。在选择时需要根据自己的具体需求和场景来综合考虑。如果需要快速、简便地实现基本的语音合成功能,并且不特别关注语音质量和音色选择等方面的问题,那么可以选择HTML5 Web Speech API;如果需要更高质量的语音合成服务、丰富的功能选项以及更好的稳定性和可靠性,那么可以考虑使用百度语音合成API。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。