[NodeJS] NodeJS运行原理简记
cnblogs 2024-07-08 14:41:00 阅读 91
NodeJS是一个基于V8引擎和libuv的JavaScript运行时,适用于轻量级和高效的数据密集型Web应用。其单线程、非阻塞IO模型依赖事件循环和线程池管理异步任务。使用NodeJS开发需避免阻塞主线程,正确处理事件和错误。
NodeJS的基本组成
NodeJS是JavaScript运行时,主要由V8引擎和libuv组成,其中V8使用 javascript 和 c++ 编写,而libuv是纯 c++ 编写的,二者都是开源的。
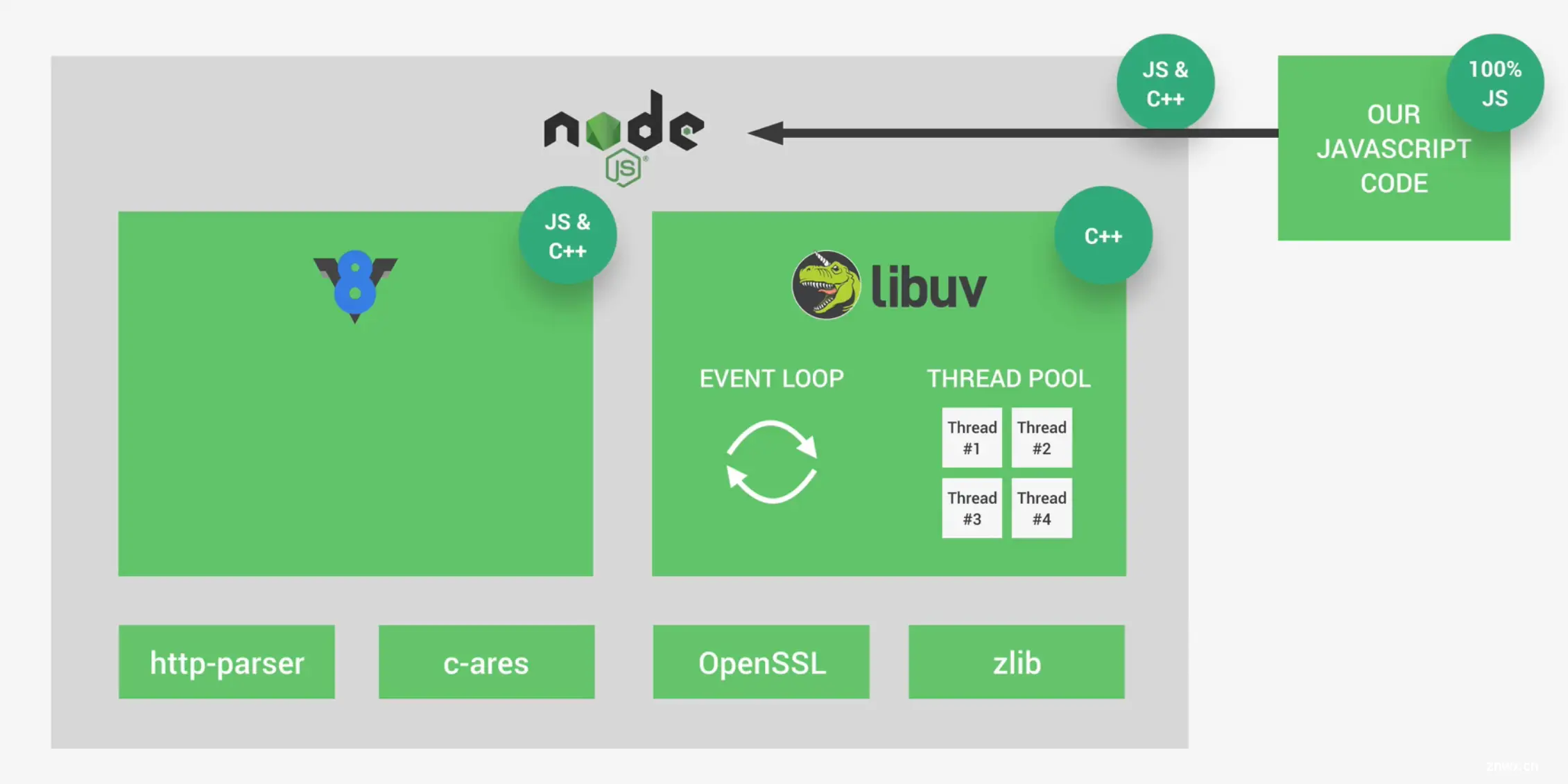
V8引擎用于将 javascript 代码转换为计算机可以执行的机器码;
而libuv则负责完成异步IO、与操作系统交互(文件系统和网络模块)、事件循环、线程池等等。
Node还有其它模块:
- http-parser:用于解析http;
- c-ares:用于处理DNS请求;
- OpenSSL:用于加密和安全编程;
- zlib:与压缩有关。
总而言之,NodeJS相当于Javascript和操作系统之间的一个抽象层,为开发人员提供了API,使得开发人员可以编写纯JavaScript代码来操控操作系统。
NodeJS的特点
- 单线程,基于事件驱动的非阻塞IO模型,使得NodeJS非常轻量级和高效;
- 适用于需要快速且可扩展的数据密集型Web应用程序,例如:
- 带有数据库的API(最好是像MongoDB这样的NoSQL数据库);
- 数据流式传输
- 实时聊天应用
- 服务端Web应用(例如使用Pug这种模板引擎的模式)
- 不适用于CPU密集型的服务端处理任务,例如图像处理、视频转换、文件压缩等等。
NodeJS程序的工作流程
NodeJS工作在单线程中,在开发后端服务的时候,应该时刻注意不要阻塞这个线程。
在启动NodeJS进程之后,主线程的工作流程如下:
- 初始化程序 initialize program
- 执行顶层代码 execute top-level code
- 获取依赖模块 require modules
- 注册回调事件 register event callbacks
- 启动事件循环 start event loop
事件循环是整个Node应用的核心,只能应付简单的任务,开销较大的任务不能在事件循环中执行,否则会阻塞主线程(对于后端服务来说是致命的)。
开销较大的任务实际上会被卸载到libuv提供的线程池中执行,线程池默认的数量是4,可以配置,至多128个。(配置项是process.env.UV_THREADPOLL_SIZE)
如何卸载任务和卸载哪些任务到线程池是由Node处理的,与开发人员无关。会被卸载到线程池执行的任务是计算开销比较大的,比如:
- 文件系统API
- 与密码学相关的API
- 与压缩有关的操作
- DNS查询
事件循环:
Node中的事件循环分为多个阶段,每个阶段都有对应的回调队列,每次到达一个阶段,会执行队列里的任务。
当队列被清空或者执行一定数量的任务后,则会进入下一个阶段。
具体流程如下:
详细的总结可以看官方文档:Node.js — The Node.js Event Loop (nodejs.org)
或者可以看我之前写的一篇博客:[NodeJS] NodeJS事件循环 - feixianxing - 博客园 (cnblogs.com)
graph TD;
start-->timers;
timers==>pending[pending callbacks];
pending==>idle[idle, prepare];
idle==>poll[poll callbacks];
poll==>check;
check==>close[close callbacks];
close==>if[Any pending timers or I/O tasks?];
if-->|YES|timers;
if-->|NO|exit[exit program];
incoming[incoming: connections, data, etc.]-.->poll
对于刚开始尝试使用NodeJS开发后端应用的前端开发人员来说,使用NodeJS编写服务端代码有以下注意事项:
在回调函数中使用
fs、crypto、zlib的API都应该使用异步的,因为这时已经进入事件循环阶段了,不能阻塞;而在顶层同步代码的范围内,则可以根据情况选择同步或者异步API。案例:有一个接口,它的响应与一个较大的文件有关,而这个文件的内容是不变的。假如每次请求都去异步地读取这个文件内容,然后再返回的话,其实很耗费时间,可以考虑在启动服务器的时候就同步/异步的读取文件内容保存到一个变量里,后续每次请求只需要拿变量的数据就OK了(其实就是做了个缓存,不需要每次请求都去磁盘找内容,在服务启动的时候就把内容先读到内存了)。
不要执行复杂的计算(即时间复杂度高的算法);
谨慎处理复杂对象的JSON序列化;
不要使用复杂的正则表达式;
将耗时任务卸载给线程池或者使用
child.processes;
总结:核心思想就是不要阻塞主线程,因为来自所有用户的所有请求都通过主线程处理,一旦阻塞基本上服务就废了。
事件驱动架构
NodeJS提供了一个events模块,其中有一个类是EventEmitter,这个类是NodeJS事件驱动架构的核心,很多其它NodeJS的核心类都继承了这个类。
http模块中的 server 就是继承了EventEmitter,因此有相关的 on 方法:
const server = http.createServer();
server.on('request', (req, res)=>{
console.log('Request received');
res.end('Request received');
});
EventEmitter是基于发布/订阅模式设计的:
- 发布者
Emitters通过emit方法发布指定名称的事件; - 订阅者
Listeners通过on方法订阅指定名称的事件并注册回调函数。
简单地介绍发布/订阅模式:发布者和订阅者之间是松散耦合的,它们互相不知道对方的存在,仅通过中间的消息代理进行通信。
EventEmitter使用指南:
限制监听器数量:一个事件如果有太多监听器会占用大量内存。可以使用
setMaxListeners方法来控制最大监听器数量。const EventEmitter = require('events');const emitter = new EventEmitter();emitter.setMaxListeners(10); // 设置最大监听器数量为10正确处理错误:始终提供错误监听器以捕获和优雅地处理错误;如果没有监听错误事件,
emit('error')会抛出异常,并打印调用堆栈,结束进程。移除不再使用的监听器:在不再需要时清理监听器,以释放资源。
使用描述性的事件名称:使用有意义且描述性的事件名称,使代码更加可读和易于维护。
参考
[1] B站 NodeJS 教学视频
[2] Events | Node.js v22.4.0 Documentation
[3] Node.js——The Node.js Event Loop
[4] [NodeJS] NodeJS事件循环 - feixianxing - 博客园
[5] geeks for geeks: What is EventEmitter in Node.js ?
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。