【LangChain系列】实战案例3:深入LangChain源码,你不知道的WebResearchRetriever与RAG联合之力
AI-入门 2024-10-01 12:03:01 阅读 61
0. 环境准备
要想成功运行本文所示的代码,需要做一下准备。
0.1 获取Google API key
首先,需要获取一个 Google API key。
(1)打开链接,登录你的Google账号(没有Google账号的请自行注册):
console.cloud.google.com/apis/api/cu…
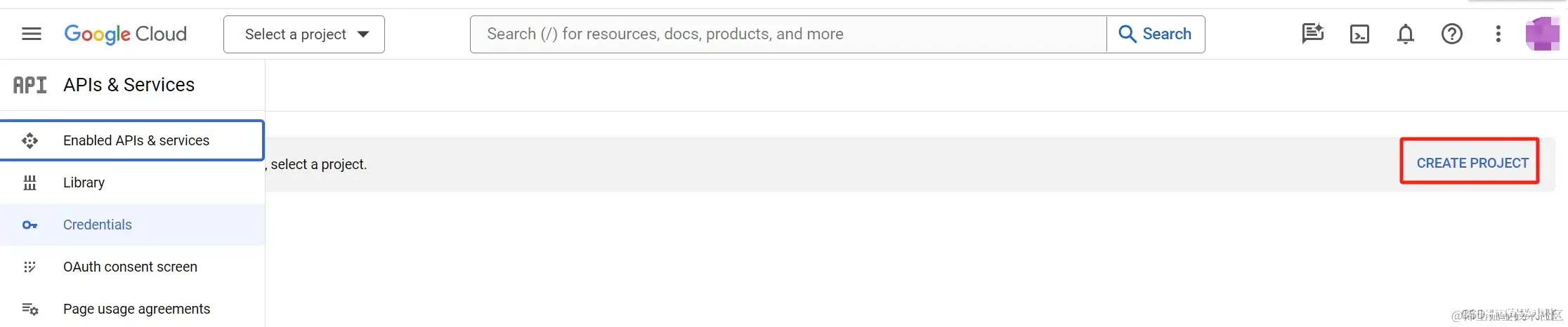
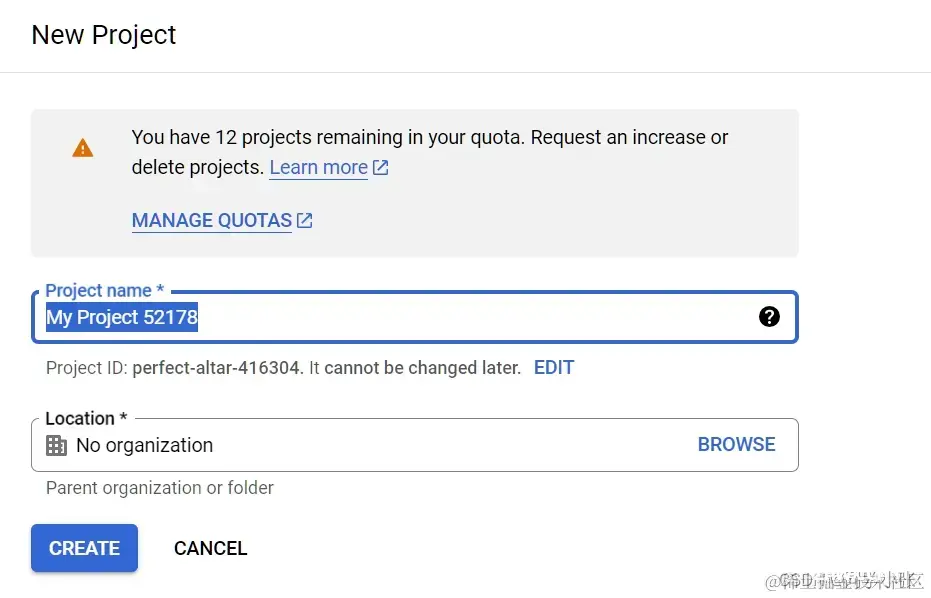
(2)创建一个Project
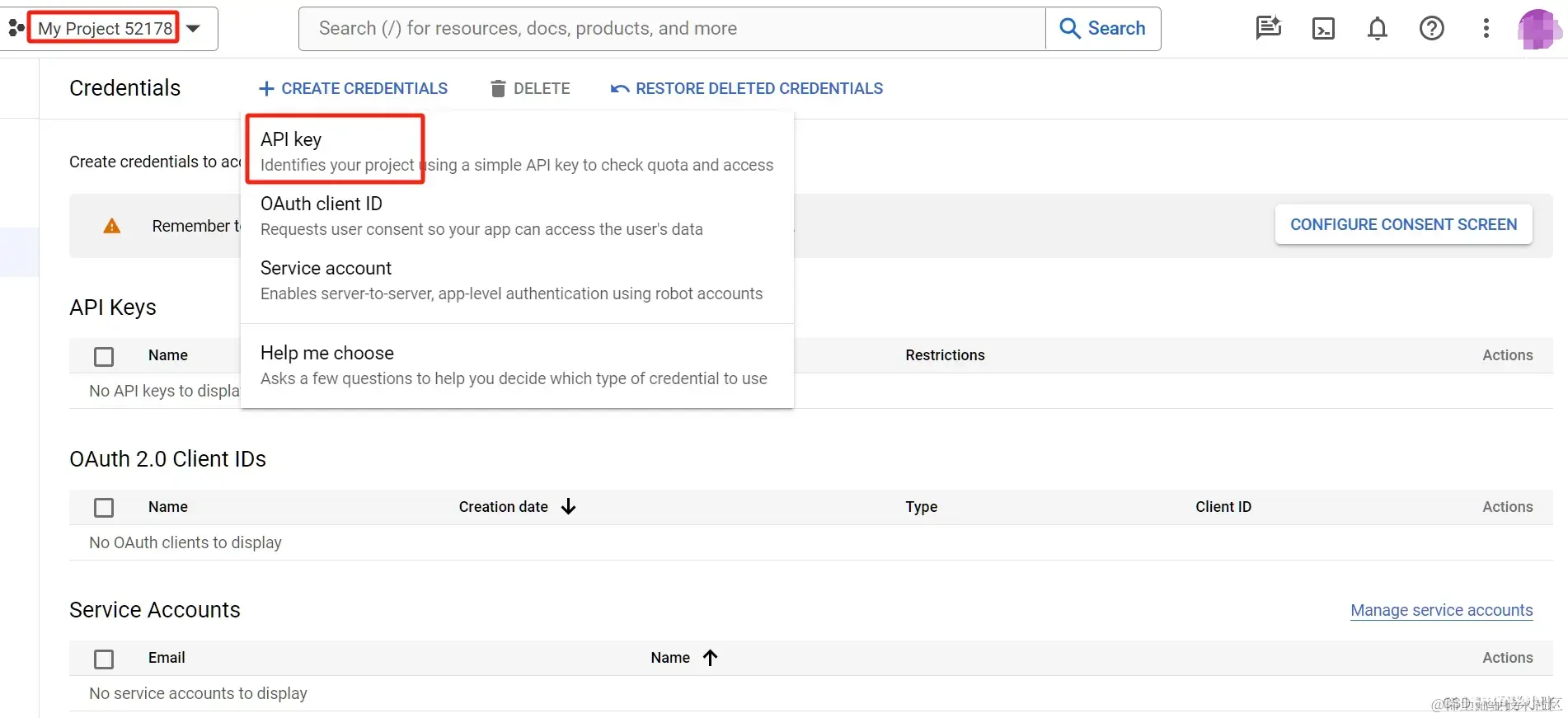
(3)在你创建的 Project 页面(创建完后会自动跳转),点 API key,创建API key即可
(4)配置API key到你的代码中:将这个

API key放到你的程序 .env 文件中作为环境变量加载。
<code>python
代码解读
复制代码GOOGLE_API_KEY = "YOUR GOOGLE API KEY"
0.2 获取 Google CSE ID
(1)登录链接,创建一个新的 Search Engine
programmablesearchengine.google.com/
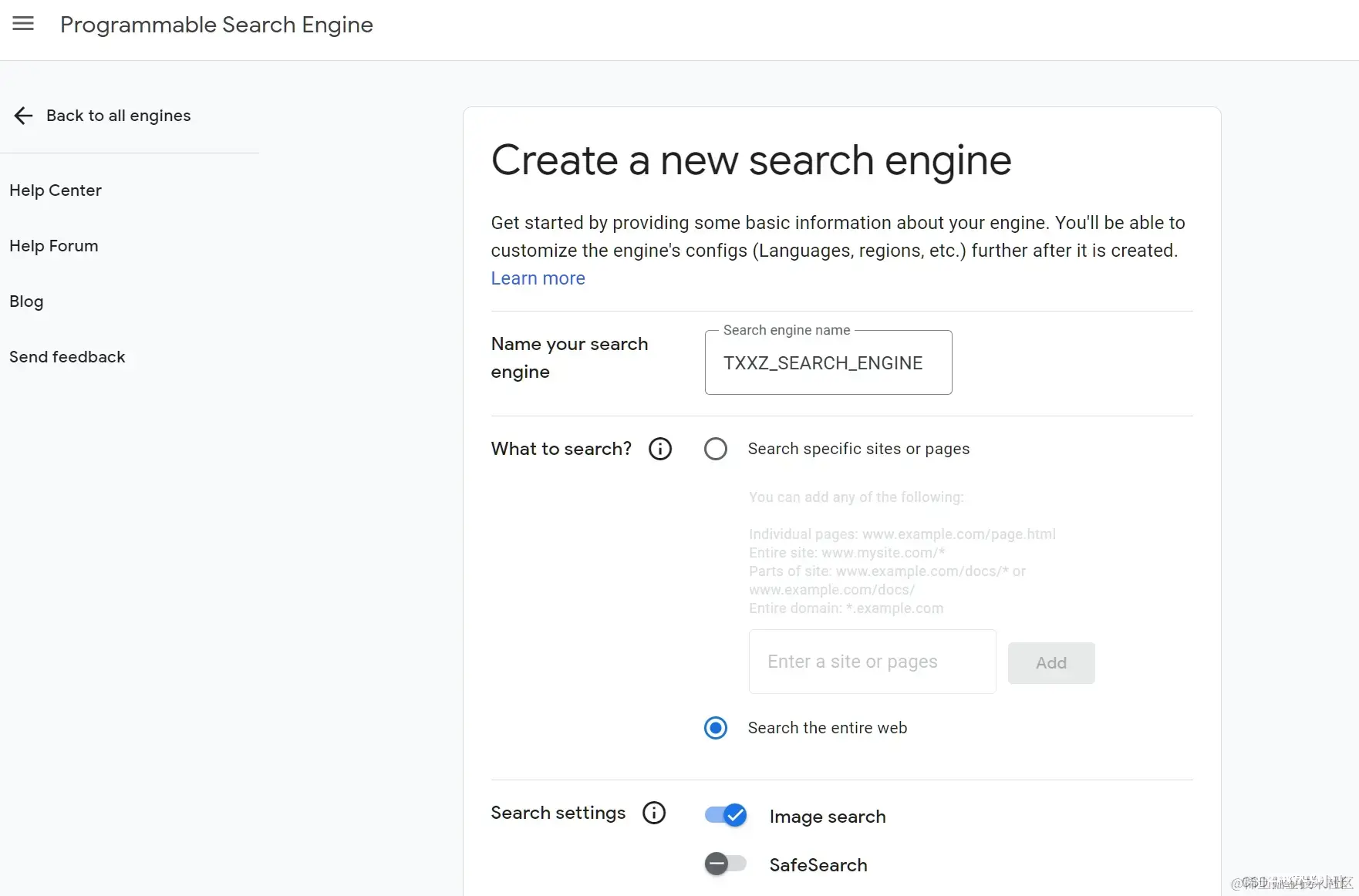
(2)创建完后,Search engine ID 即为所需的 CSE ID。
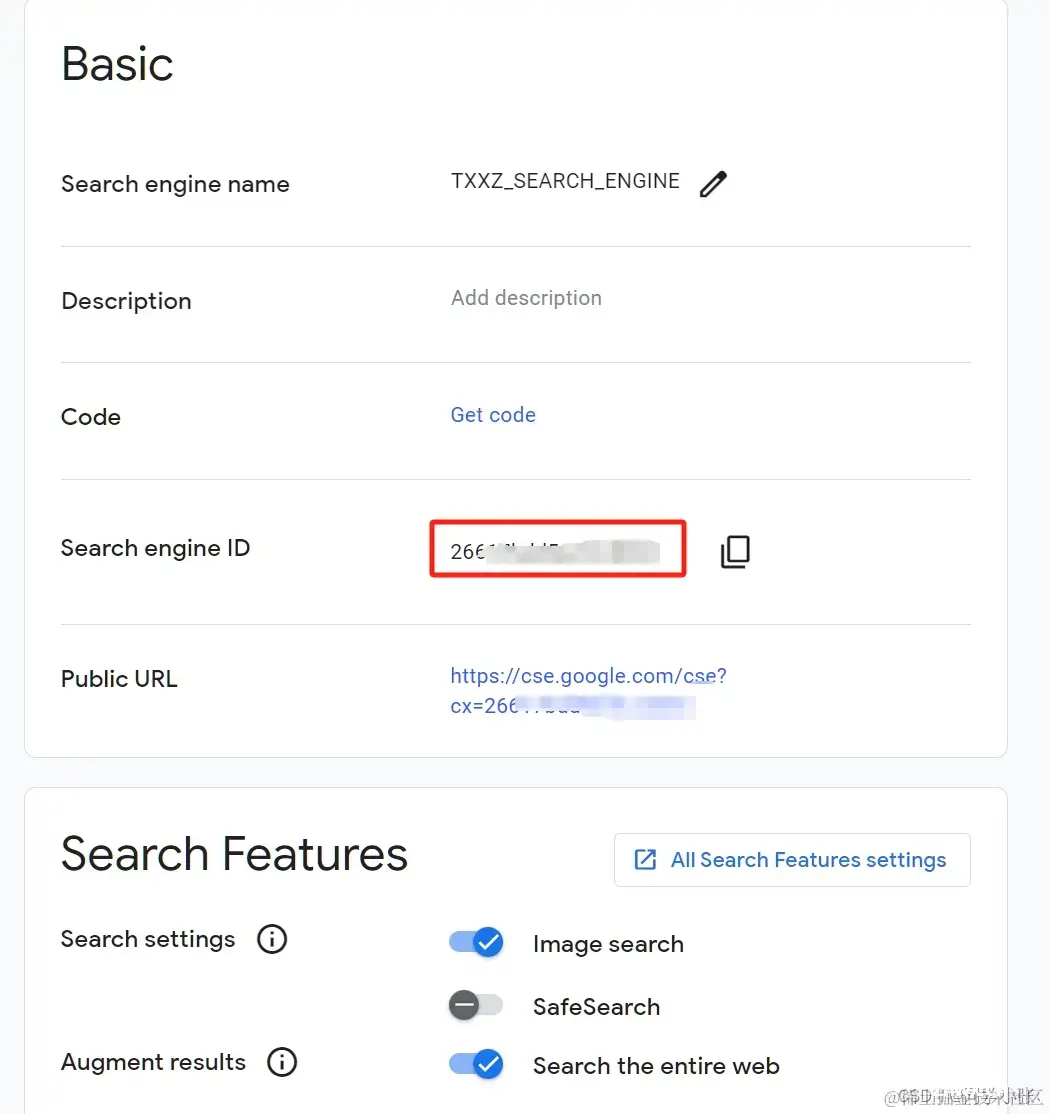
(3)配置 CSE ID 到你的代码中:将这个 CSE ID 放到你的程序 .env 文件中作为环境变量加载。
<code>python
代码解读
复制代码GOOGLE_CSE_ID = "xxxxxxx"
0.3 安装依赖Python包
我的安装以下两个基本就够了,因为之前安装过 langchain、openai之类的。
python代码解读复制代码pip install google-api-core==2.11.1
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple google-api-python-client==2.95.0
完整的安装依赖参考:
python代码解读复制代码streamlit==1.25.0
langchain==0.0.244
chromadb==0.4.3
openai==0.27.8
html2text==2020.1.16
google-api-core==2.11.1
google-api-python-client==2.95.0
google-auth==2.22.0
google-auth-httplib2==0.1.0
googleapis-common-protos==1.59.1
tiktoken==0.4.0
faiss-cpu==1.7.4
1. 完整代码及解释
1.1 完整代码
python代码解读复制代码from langchain.retrievers.web_research import WebResearchRetriever
from langchain_community.utilities import GoogleSearchAPIWrapper
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Vectorstore
vectorstore = Chroma(
embedding_function=OpenAIEmbeddings(), persist_directory="./chroma_db_oai"code>
)
# LLM
llm = ChatOpenAI(temperature=0)
# Search
search = GoogleSearchAPIWrapper()
# Initialize
web_research_retriever = WebResearchRetriever.from_llm(
vectorstore=vectorstore, llm=llm, search=search
)
# Run
import logging
logging.basicConfig()
logging.getLogger("langchain.retrievers.web_research").setLevel(logging.INFO)
from langchain.chains import RetrievalQAWithSourcesChain
user_input = "How do LLM Powered Autonomous Agents work?"
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm, retriever=web_research_retriever
)
result = qa_chain({ "question": user_input})
print(result)
1.2 代码研读
1.2.1 WebResearchRetriever
首先是代码中最重要的一个封装类:WebResearchRetriever。
它的使用方式如下:
python代码解读复制代码# Initialize
web_research_retriever = WebResearchRetriever.from_llm(
vectorstore=vectorstore, llm=llm, search=search
)
接收三个主要参数:
向量数据库:用来存储网页数据llm检索引擎,这里的检索引擎 必须是 Google Search API
python代码解读复制代码class WebResearchRetriever(BaseRetriever):
"""`Google Search API` retriever."""
search: GoogleSearchAPIWrapper = Field(..., description="Google Search API Wrapper")code>
再看下其构造过程:from_llm 函数
python代码解读复制代码def from_llm(
cls,
vectorstore: VectorStore,
llm: BaseLLM,
search: GoogleSearchAPIWrapper,
prompt: Optional[BasePromptTemplate] = None,
num_search_results: int = 1,
text_splitter: RecursiveCharacterTextSplitter = RecursiveCharacterTextSplitter(
chunk_size=1500, chunk_overlap=150
),
) -> "WebResearchRetriever":
"""Initialize from llm using default template.
Args:
vectorstore: Vector store for storing web pages
llm: llm for search question generation
search: GoogleSearchAPIWrapper
prompt: prompt to generating search questions
num_search_results: Number of pages per Google search
text_splitter: Text splitter for splitting web pages into chunks
Returns:
WebResearchRetriever
"""
if not prompt:
QUESTION_PROMPT_SELECTOR = ConditionalPromptSelector(
default_prompt=DEFAULT_SEARCH_PROMPT,
conditionals=[
(lambda llm: isinstance(llm, LlamaCpp), DEFAULT_LLAMA_SEARCH_PROMPT)
],
)
prompt = QUESTION_PROMPT_SELECTOR.get_prompt(llm)
# Use chat model prompt
llm_chain = LLMChain(
llm=llm,
prompt=prompt,
output_parser=QuestionListOutputParser(),
)
return cls(
vectorstore=vectorstore,
llm_chain=llm_chain,
search=search,
num_search_results=num_search_results,
text_splitter=text_splitter,
)
这个函数用来初始化 WebResearchRetriever,除了上面说的三个主要参数外,其额外提供了默认的Prompt模板,text_splitter,QuestionListOutputParser等Retriever过程所需的工具和内容。
默认的Prompt模板内容如下:
python代码解读复制代码DEFAULT_SEARCH_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an assistant tasked with improving Google search \code>
results. Generate THREE Google search queries that are similar to \
this question. The output should be a numbered list of questions and each \
should have a question mark at the end: {question}""",
)
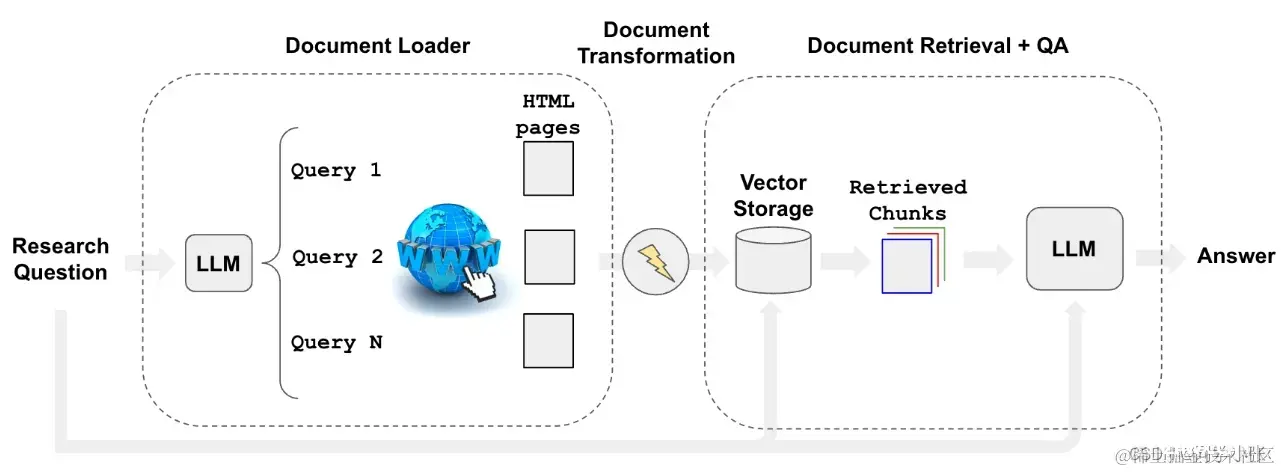
从这个Prompt大致可以看出WebResearchRetriever的工作过程:
(1)根据用户的问题,利用大模型将该问题转化为3个与用户问题相近的Google搜索语句
(2)利用 Google CSE 搜索这几个问题,会得到一系列相关 URL
(3)利用上篇文章我们爬取网页内容的方法,将每个URL中的文本抓取出来
(4)对抓取出来的文本进行分块,向量存储(WebResearchRetriever的工作到这里就结束了)
(5)然后就是其它模块使用RAG的流程:用户提问 —> 查询向量数据库 —> 大模型回答问题
整体流程示意图如下:
(1)-(4)步骤的源码如下,可以对照着看一下:
<code>python代码解读复制代码def _get_relevant_documents(
self,
query: str,
*,
run_manager: CallbackManagerForRetrieverRun,
) -> List[Document]:
"""Search Google for documents related to the query input.
Args:
query: user query
Returns:
Relevant documents from all various urls.
"""
# Get search questions
logger.info("Generating questions for Google Search ...")
result = self.llm_chain({ "question": query})
logger.info(f"Questions for Google Search (raw): { result}")
questions = result["text"]
logger.info(f"Questions for Google Search: { questions}")
# Get urls
logger.info("Searching for relevant urls...")
urls_to_look = []
for query in questions:
# Google search
search_results = self.search_tool(query, self.num_search_results)
logger.info("Searching for relevant urls...")
logger.info(f"Search results: { search_results}")
for res in search_results:
if res.get("link", None):
urls_to_look.append(res["link"])
# Relevant urls
urls = set(urls_to_look)
# Check for any new urls that we have not processed
new_urls = list(urls.difference(self.url_database))
logger.info(f"New URLs to load: { new_urls}")
# Load, split, and add new urls to vectorstore
if new_urls:
loader = AsyncHtmlLoader(new_urls, ignore_load_errors=True)
html2text = Html2TextTransformer()
logger.info("Indexing new urls...")
docs = loader.load()
docs = list(html2text.transform_documents(docs))
docs = self.text_splitter.split_documents(docs)
self.vectorstore.add_documents(docs)
self.url_database.extend(new_urls)
# Search for relevant splits
# TODO: make this async
logger.info("Grabbing most relevant splits from urls...")
docs = []
for query in questions:
docs.extend(self.vectorstore.similarity_search(query))
# Get unique docs
unique_documents_dict = {
(doc.page_content, tuple(sorted(doc.metadata.items()))): doc for doc in docs
}
unique_documents = list(unique_documents_dict.values())
return unique_documents
1.2.2 GoogleSearchAPIWrapper
这是 Google CSE 检索API的封装类。
python代码解读复制代码class GoogleSearchAPIWrapper(BaseModel):
"""Wrapper for Google Search API."""
1.2.3 RetrievalQAWithSourcesChain
这是 LangChain 内封装的问答QA链,提问-给出答案,并带有答案来源Sources.
对检索到的文档进行问答,并引用其来源。当您希望答案响应在文本响应中具有来源时,请使用此选项。
使用方法:
python代码解读复制代码qa_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm, retriever=web_research_retriever
)
接收两个参数:
llm:大模型retriver:检索器
其源码定义如下:
python代码解读复制代码class RetrievalQAWithSourcesChain(BaseQAWithSourcesChain):
"""Question-answering with sources over an index."""
retriever: BaseRetriever = Field(exclude=True)
"""Index to connect to."""
reduce_k_below_max_tokens: bool = False
"""Reduce the number of results to return from store based on tokens limit"""
max_tokens_limit: int = 3375
"""Restrict the docs to return from store based on tokens,
enforced only for StuffDocumentChain and if reduce_k_below_max_tokens is to true"""
2. 总结
本文我们主要学习了利用 LangChain进行网络文档 + RAG 的使用,重点看了 LangChain中WebResearchRetriever的封装和实现原理。里面虽然使用的Google搜索,在国内有诸多限制,但是里面的实现思路是值得借鉴的:
(1)找到与用户问题相关的网页
用户提问转换为相似的搜索语句通过检索API找到相关的网页URL
(2)文本获取与存储
爬取URL文本内容分割文本并向量存储
(3)使用以上相关内容进行RAG增强检索,回答用户问题
大模型资源分享
针对所有自学遇到困难的同学,我为大家系统梳理了大模型学习的脉络,并且分享这份LLM大模型资料:其中包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等。😝有需要的小伙伴,可以扫描下方二维码免费领取↓↓↓

一、全套 AGI 大模型学习路线
AI 大模型时代的精彩学习之旅:从根基铸就到前沿探索,牢牢掌握人工智能核心技能!
二、640 套 AI 大模型报告合集
此套涵盖 640 份报告的精彩合集,全面涉及 AI 大模型的理论研究、技术实现以及行业应用等诸多方面。无论你是科研工作者、工程师,还是对 AI 大模型满怀热忱的爱好者,这套报告合集都将为你呈上宝贵的信息与深刻的启示。

三、AI 大模型经典 PDF 书籍
伴随人工智能技术的迅猛发展,AI 大模型已然成为当今科技领域的一大热点。这些大型预训练模型,诸如 GPT-3、BERT、XLNet 等,凭借其强大的语言理解与生成能力,正在重塑我们对人工智能的认知。而以下这些 PDF 书籍无疑是极为出色的学习资源。

阶段 1:AI 大模型时代的基础认知
目标:深入洞悉 AI 大模型的基本概念、发展历程以及核心原理。
内容
:
L1.1 人工智能概述与大模型起源探寻。L1.2 大模型与通用人工智能的紧密关联。L1.3 GPT 模型的辉煌发展历程。L1.4 模型工程解析。L1.4.1 知识大模型阐释。L1.4.2 生产大模型剖析。L1.4.3 模型工程方法论阐述。L1.4.4 模型工程实践展示。L1.5 GPT 应用案例分享。
阶段 2:AI 大模型 API 应用开发工程
目标:熟练掌握 AI 大模型 API 的运用与开发,以及相关编程技能。
内容
:
L2.1 API 接口详解。L2.1.1 OpenAI API 接口解读。L2.1.2 Python 接口接入指南。L2.1.3 BOT 工具类框架介绍。L2.1.4 代码示例呈现。L2.2 Prompt 框架阐释。L2.2.1 何为 Prompt。L2.2.2 Prompt 框架应用现状分析。L2.2.3 基于 GPTAS 的 Prompt 框架剖析。L2.2.4 Prompt 框架与 Thought 的关联探讨。L2.2.5 Prompt 框架与提示词的深入解读。L2.3 流水线工程阐述。L2.3.1 流水线工程的概念解析。L2.3.2 流水线工程的优势展现。L2.3.3 流水线工程的应用场景探索。L2.4 总结与展望。
阶段 3:AI 大模型应用架构实践
目标:深刻理解 AI 大模型的应用架构,并能够实现私有化部署。
内容
:
L3.1 Agent 模型框架解读。L3.1.1 Agent 模型框架的设计理念阐述。L3.1.2 Agent 模型框架的核心组件剖析。L3.1.3 Agent 模型框架的实现细节展示。L3.2 MetaGPT 详解。L3.2.1 MetaGPT 的基本概念阐释。L3.2.2 MetaGPT 的工作原理剖析。L3.2.3 MetaGPT 的应用场景探讨。L3.3 ChatGLM 解析。L3.3.1 ChatGLM 的特色呈现。L3.3.2 ChatGLM 的开发环境介绍。L3.3.3 ChatGLM 的使用示例展示。L3.4 LLAMA 阐释。L3.4.1 LLAMA 的特点剖析。L3.4.2 LLAMA 的开发环境说明。L3.4.3 LLAMA 的使用示例呈现。L3.5 其他大模型介绍。
阶段 4:AI 大模型私有化部署
目标:熟练掌握多种 AI 大模型的私有化部署,包括多模态和特定领域模型。
内容
:
L4.1 模型私有化部署概述。L4.2 模型私有化部署的关键技术解析。L4.3 模型私有化部署的实施步骤详解。L4.4 模型私有化部署的应用场景探讨。
学习计划:
阶段 1:历时 1 至 2 个月,构建起 AI 大模型的基础知识体系。阶段 2:花费 2 至 3 个月,专注于提升 API 应用开发能力。阶段 3:用 3 至 4 个月,深入实践 AI 大模型的应用架构与私有化部署。阶段 4:历经 4 至 5 个月,专注于高级模型的应用与部署。

上一篇: 前端(Vue)全屏 screenfull 通用解决方案及原理分析
下一篇: Windows Edge浏览器对Web Authentication API的支持分析与实践应用
本文标签
你不知道的WebResearchRetriever与RAG联合之力 【LangChain系列】实战案例3:深入LangChain源码
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。