【Web自动化测试】
一只雪球球 2024-08-29 11:03:02 阅读 86
怎么理解自动化测试?
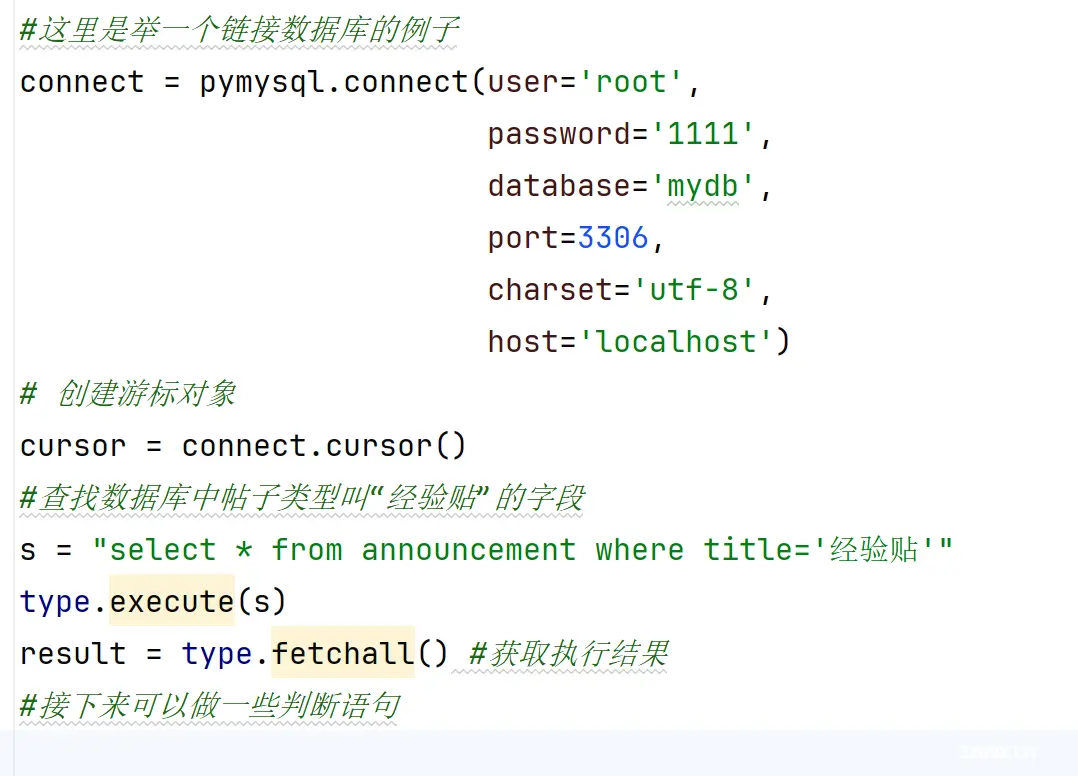
自动化测试的核心就是测试。将页面操作完成的代码完成以后,根据断言判断前端页面的提示信息是否符合预期,也要检查数据库中的数据是否变化。比如,新增一个帖子类型,预期前端页面提示“操作成功”,数据库也会新增一条记录。
前言
1.selenium自动化测试的三板斧:定位元素、交互元素、进行断言
2.八大定位策略:id、name、css、xpath、class_name、tag_name、link_text、partial_link_text
3.准备工作:下载python和pycharm,在终端输入命令:pip install webdriver-helper
4.什么是web自动化测试:使用自动化工具模拟用户与网页进行交互,用来验证网页的功能、性能、用户界面是否符合预期。
5.什么样的项目适合自动化测试:需求变动不频繁、项目周期长、需要回归测试
6.自动化脚本的编写步骤:导包->获取浏览器对象和url->查找并关闭元素->关闭浏览器
一.selenium-元素定位
1.元素定位:通过元素信息或元素层级结构来定位。
2.提问:什么是元素层级结构
html页面是由标签构成的,标签结构是:
<标签名 属性名1=“属性值1”属性名2=“属性值2” >文本</标签名>
3.为什么使用元素定位?
因为要使用web自动化操作元素,要先定位元素
4.定位元素时依赖什么?
①元素属性:id、name、class_name(元素的class属性)
②元素标签名称:tag_name(标签名称<标签名...>)
③超链接文本:link_text、partial_link_text
④元素路径:xpath
⑤选择器:css
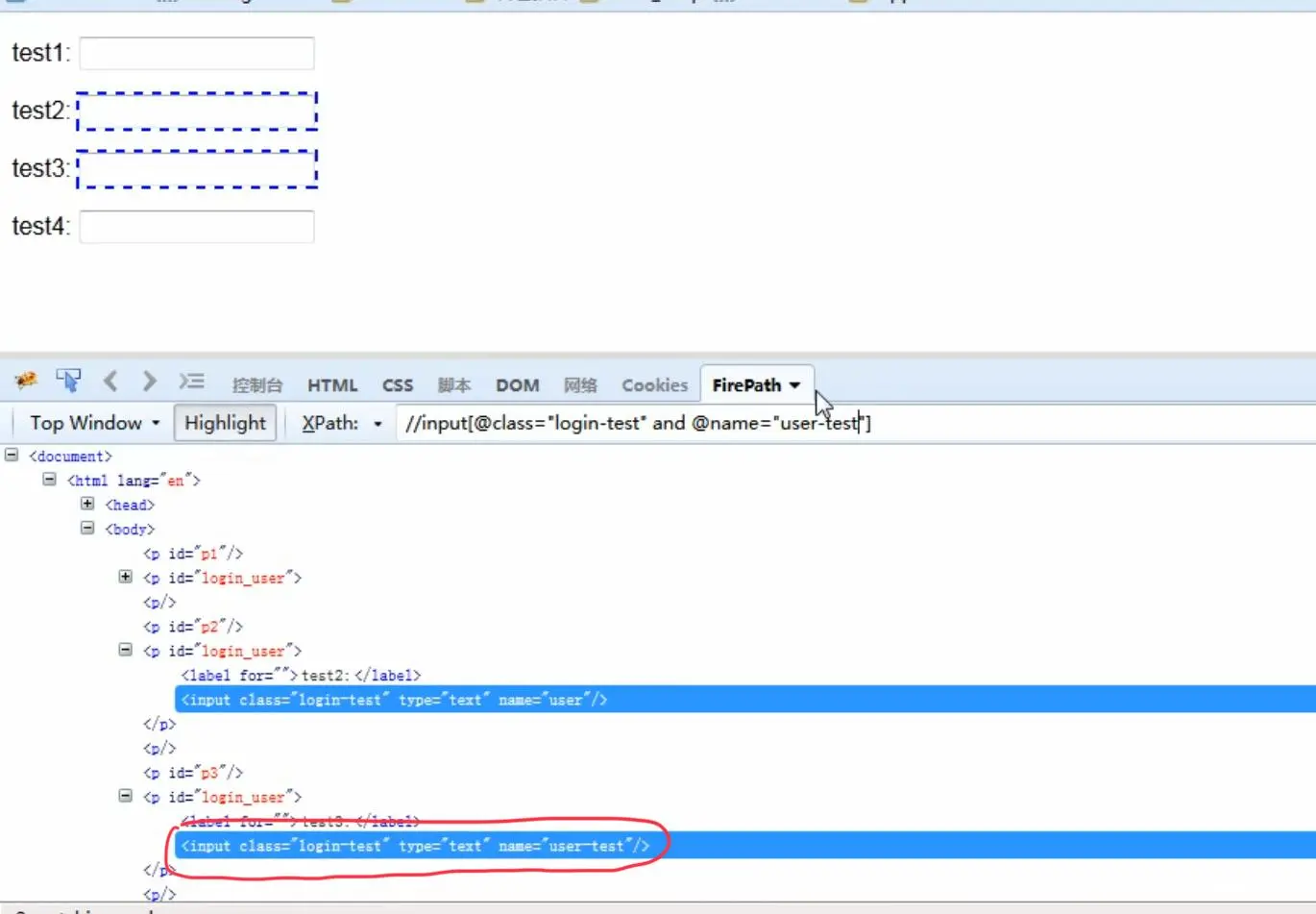
5.为什么常用的定位方法是xpath和css?
因为id、name、class依赖于元素的属性,如果元素没有这些属性就定位不了,tag_name只能找页面唯一的元素,link_text和partial_link_name只能定位超链接。
1.id定位
说明:元素有id属性且必须唯一
方法:driver.find_element(By.ID,'id')
ps:url中的路径’/‘是浏览器路径,’\‘是本地路径。
<code>from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('http://baidu.com')
sleep(3)
driver.quit()
username = driver.find_element(By.ID,'user')
2.name定位
说明:元素有name属性,可以重复。
方法:driver.find_element(By.NAME,'name')
#导包
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
#获取浏览器对象
driver = webdriver.chrome()
#获取url
url = ('http://baidu.com')
#通过name定位元素且输入数据
name = driver.find_element(By.NAME,'name').send_keys('admin')
password = driver.find_element(By.NAME,'password').send_keys('123')
#暂停3秒后关闭浏览器窗口
sleep(3)
driver.quit()
3.class_name定位
说明:是对class属性进行定位(html页面通过class属性来定义样式)
方法:driver.find_element(By.CLASS_NAME,'属性名')
#获取浏览器对象和网址
driver = webdriver.Chrome()
driver.get('http://localhost:8080/#/login')
#在输入框中输入用户名和密码
name = driver.find_element(By.CLASS_NAME,'el-input__inner').send_keys('admin')
sleep(6)
driver.quit()
4.tag_name定位(了解)
说明:对标签名称进行定位,标签名就是尖括号紧挨着的单词或字母。如果页面中有多个相同标签,默认返回第一个。
方法:driver.find_element(By.TAG_NAME,'标签名')
5.link_text和partial_link_text
说明:只能定义超链接标签,link_text是精准匹配。partial_link_text是精准或模糊匹配,当进行模糊匹配时,最好使用能代表唯一性的词,如果有多个值返回第一个。
方法:driver.find_element(By.LINK_TEXT,'链接文本')
6.XPath定位
说明:基于元素路径定位
方法:driver.find_element(By.XPATH,'路径')
定位策略:
①路径
绝对路径:以/开头
相对路径:以//开头,后面跟元素名称
②路径+属性
//input[@id='id值 ']
③路径+逻辑
//input[@id = ' ' and @属性 = ' 属性值']

④路径+层级
//*[@id = '父级id属性值 ' ]/input
input后面的内容可以删去

注:
一般更建议使用标签名而不是*,这样效率会快
无论是绝对路径还是相对路径,/后面都要跟标签名或*
能使用相对路径不使用绝对路径
⑤扩展
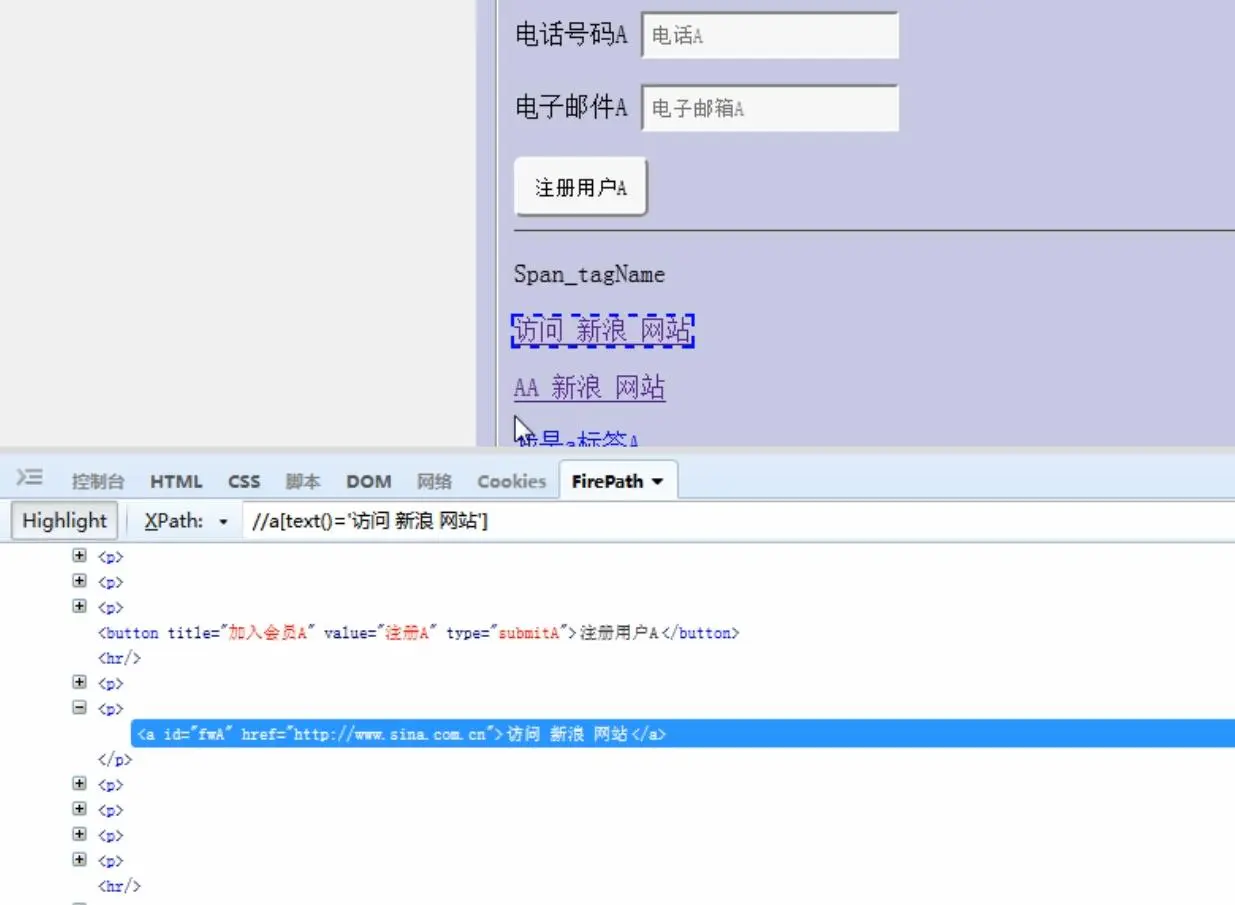
//*[text()='xxx'],定位文本内容为xxx的元素,一般是p标签、a标签
//*[contains(@属性,'属性值')],定位属性值中包含xxx的元素,contains是关键字不可修改
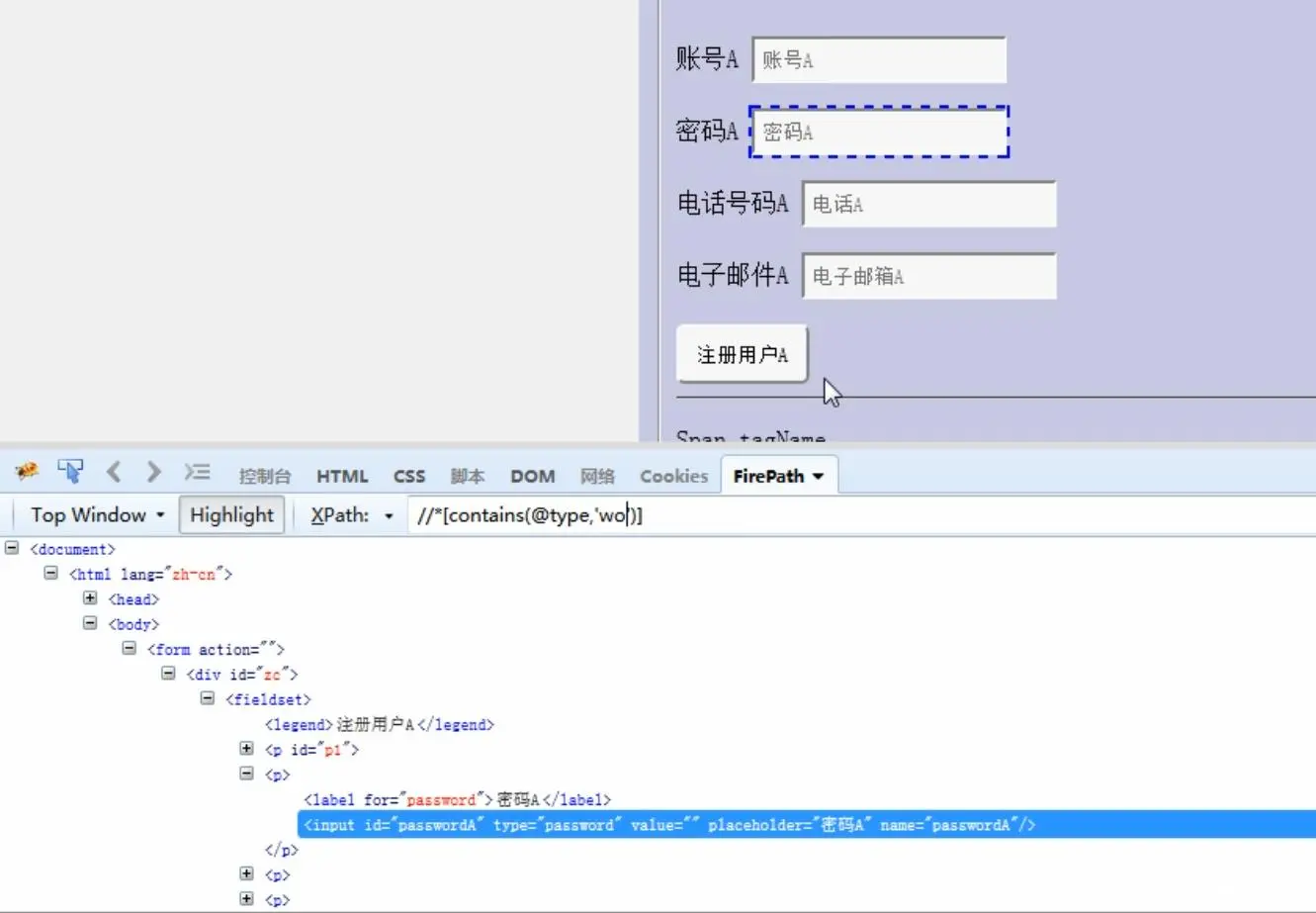
//*[starts-with(@属性,'属性值')],定位属性值中开头是xxx的元素,start-with是关键字不可修改
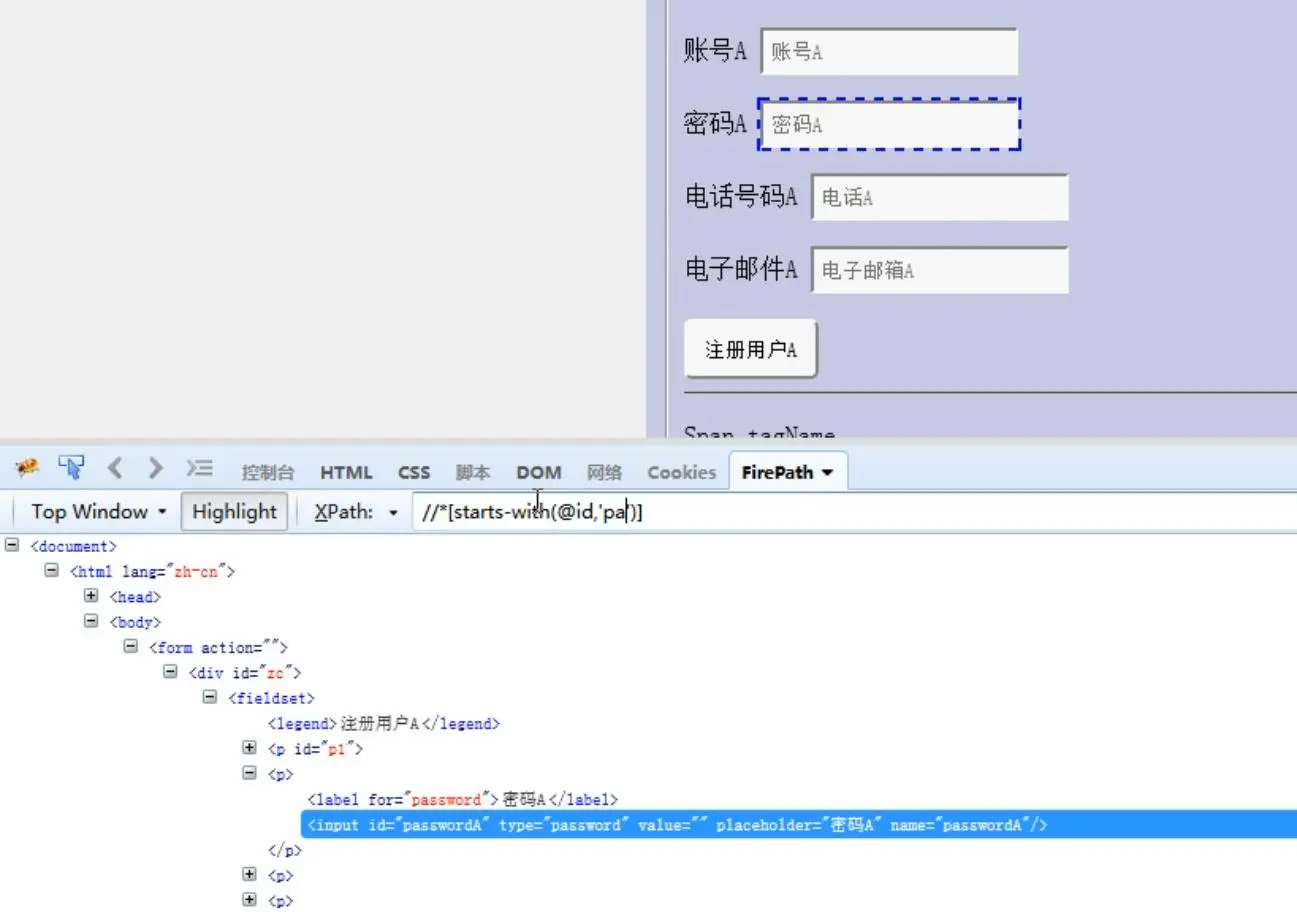
7.css定位
说明:css是一种语言,描述html页面的显示样式。使用css选择器来进行定位。
方法:driver.find_element(By.CSS_SELECTOR,' ')
常用策略:
①id选择:#id
②class选择器:.class
③属性选择器:[属性名='属性值']
④元素选择器:element
⑤层级选择器:p>input和p input(>必须是连续父子级,空格中间可以跨父级)
⑥扩展
input[type^='xx'],定位到以xx开头的元素
input[type$='xx'],定位到以xx结尾的元素
input[type*='xx'],定位到包含xx的元素
二.selenium-API操作
1.元素操作
1.为什么要学习元素操作?是为了模拟用户输入、删除、点击操作。
2.常用方法:
click() 单击元素
send_keys(value) 模拟输入
clear() 清除文本(可以用在“重新输入”这个要求中,也就是先清空再输入)
driver.maximize_window() 最大化浏览器窗口
driver.set_window_size(w,h) 设置窗口的大小,单位是像素
driver.set_window_position(x,y) 设置窗口的位置
driver.back() 后退
driver.forward() 前进
driver.refresh() 刷新
driver.title 获取当前页面title信息
driver.current_url 获取当前页面的url信息
driver.close() 关闭当前主窗口
driver.quit() 关闭driver对象启动的所有窗口
<code>#导包
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
def main():
#获取浏览器对象和url
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
#将浏览器最大化
driver.maximize_window()
sleep(2)
#设置固定大小(300,200)
driver.set_window_size(300,200)
sleep(2)
#移动窗口:320,150
driver.set_window_position(320,150)
sleep(2)
#重新让浏览器最大化
driver.maximize_window()
sleep(2)
#后退
driver.back()
sleep(2)
#前进
driver.forward()
sleep(2)
#关闭驱动对象
driver.quit()
if __name__ == "__main__":
main()
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
def main():
driver = webdriver.Chrome() #获取浏览器对象和url
driver.get("http://www.baidu.com")
driver.find_element(By.NAME,'wd').send_keys('蛋白质') #为了实现刷新操作,先在搜索框输入文本
sleep(3)
driver.refresh() #刷新
sleep(3)
title = driver.title #获取当前网页的title
print("当前页面的title是:",title)
url = driver.current_url #获取当前网页的url
print("当前网页的url是:",url)
driver.find_element(By.XPATH,'//*[@id="s-hotsearch-wrapper"]/div/a[1]/div').click() #为了实现关闭当前主窗口操作,先打开一个新网页code>
sleep(3)
driver.close() #只关闭当前主窗口(默认启动的页面)
sleep(3)
driver.quit() #quit关闭的是由driver启动的所有窗口
if __name__ == "__main__":
main()
2.元素信息获取
①为什么要获取页面元素信息:为了验证当前页面或元素的准确性
②常用方法
text 获取元素文本
size 获取元素大小
get_attribute() 获取元素属性值,括号里要带属性名
is_displayed 判断元素是否可见
is_selected 判断元素是否可见
is_enabled 判断元素是否可用
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
def main():
#获取浏览器页面和url
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
#获取搜索框的大小
size = driver.find_element(By.CSS_SELECTOR,'#kw').size
print("搜索框大小为:",size)
#获取超文本链接的内容
text = driver.find_element(By.XPATH,'//*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]').textcode>
print("超文本链接内容为:",text)
#获取超文本链接的属性
url = driver.find_element(By.XPATH,'//*[@id="s-top-left"]/a[1]').get_attribute("href")code>
print("超文本链接的属性值:",url)
#判断元素是否可见
display = driver.find_element(By.XPATH,'//*[@id="u"]/a[1]').is_displayed()code>
print("是否可见:",display)
#判断搜索按钮是否可用
enable = driver.find_element(By.XPATH,'//*[@id="su"]').is_enabled()code>
print("搜索按钮是否可用:",enable)
#判断用户协议是否被选中
driver.find_element(By.XPATH,'//*[@id="s-top-loginbtn"]').click()code>
sleep(3)
select = driver.find_element(By.XPATH,'//*[@id="s-top-loginbtn"]').is_selected()code>
print("用户协议是否被选中:",select)
if __name__ == "__main__":
main()

3.鼠标和键盘操作
①为什么使用模拟鼠标?为了满足html的鼠标效果。selenium框架中将对鼠标的操作方法都封装在ActionChains类中。
②常用方法
action = ActionChains(driver)
perform() 执行
action.context_click().perform() 模拟右键
action.double_click().perform() 模拟双击
action.move_to_element().perform() 模拟悬停
action.drag_and_drop(source,target).perform() 模拟拖拽
<code>from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
def main():
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
sleep(3)
#下面是模拟鼠标的操作
action = ActionChains(driver)
#在搜索框模拟右键,预期:出现粘贴选项
input = driver.find_element(By.ID,'kw')
action.context_click(input).perform()
sleep(2)
#在搜索框输入文本并模拟双击,预期:文本被选中
text = driver.find_element(By.ID,'kw').send_keys('三伏天')
sleep(2)
action.double_click(input).perform()
sleep(3)
#移动到相机图片上模拟悬停,预期:出现“按图片搜索”
button = driver.find_element(By.XPATH,'//*[@id="form"]/span[1]/span[1]')code>
action.move_to_element(button).perform()
sleep(2)
driver.quit()
if __name__ == "__main__":
main()
①为什么使用键盘?因为可以模拟键盘上一些按键或者组合键的输入。selenium框架把键盘的方法都封装在keys中。
②常用方法:
send_keys有三个作用:输入、发送、上传
send_keys(Keys.BACK_SPACE) 删除
send_keys(Keys.SPACE) 空格
send_keys(Keys.TAB) 制表键
send_keys(Keys.ENTER) 回车
send_keys(Keys.ESCAPE) 回退
send_keys(Keys.CONTROL,'a') 全选 ctrl+A
from time import sleep
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
def main():
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
sleep(2)
#在搜索框输入“hello”,暂停两秒后删除o
word = driver.find_element(By.ID,'kw')
word.send_keys("hello")
sleep(2)
word.send_keys(Keys.BACKSPACE)
sleep(2)
#全选操作
word.send_keys(Keys.CONTROL,'a')
sleep(2)
#剪切
word.send_keys(Keys.CONTROL,'x')
sleep(2)
#粘贴
word.send_keys(Keys.CONTROL,'v')
sleep(2)
driver.quit()
if __name__ == "__main__":
main()
3.元素等待
①什么是元素等待?
第一次没找到元素的时候,元素等待时长被激活。如果在指定时间内可以找到就继续执行代码,如果找不到,就报元素未找到异常。
②为什么设置元素等待?
为了防止抛出异常
③分类
隐式等待:
定位元素时,如果能直接找到就不会触发等待,如果到达指定最大时长还没找到就会触发等待,抛出元素不存在异常。
方法:driver.implicitly_wait(30) 一般设置等待时长为30s
注:
针对所有元素生效
为前置必写代码(1.获取浏览器对象,2.最大化浏览器 3.隐式等待)
显式等待:
抛出的是超时异常,用到WebDriverWait包
方法:
WebDriverWait(driver, timeout=10, poll_frequency = 0.5).until(lambda x : x.find_element(By.ID,' '))
timeout是超出时间
poll_frequency是访问频率,默认0.5秒
x是driver
一整个返回的是一个元素
注:对单个元素生效
4.窗口操作
4.1下拉框
说明:实例化select时,必须得是select标签元素。调用Selectl类下面的方法时,是通过索引、value属性值、显示文本去控制的,而不需要click事件。
方法:
select_by_index() 通过下标定位
select_by_value() 通过属性值定位
select_by_visible_text() 通过显示文本定位
步骤:
s = Select(element) 实例化
s.select_by_index()
或者 Select(driver.find_element(By.XPATH,' ')).select_by_index()
4.2弹出框
说明:对话框类型有alert警告框、confirm确认框、prompt提示框。如果不对对话框进行处理,就无法进行后续的操作。
步骤:
1.切换到对话框:driver.switch_to.alert
2.处理对话框
alert.text 获取文本
alert.accept 同意
alert.dismiss 取消
4.3滚动条
说明:在web自动化测试中,有一些场景比如需要拉到最底某些功能才可以用。selenium没有直接提供滚动条组件方法,而是使用js语句控制滚动条。
操作:
js = "window.scrollTo(0,10000)" 设置滚动条操作语句,0是左边距(水平滚动),10000是上边距(垂直滚动)
driver.excute_scripts(js)
rame
from selenium.webdriver.support.ui import Select
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
def main():
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
driver.get("https://www.springtour.com/")
sleep(3)
#设置滚动条
js = "window.scrollTo(0,10000)"
driver.execute_script(js)
sleep(3)
driver.quit()
if __name__ == "__main__":
main()
4.4frame表单切换(重点)
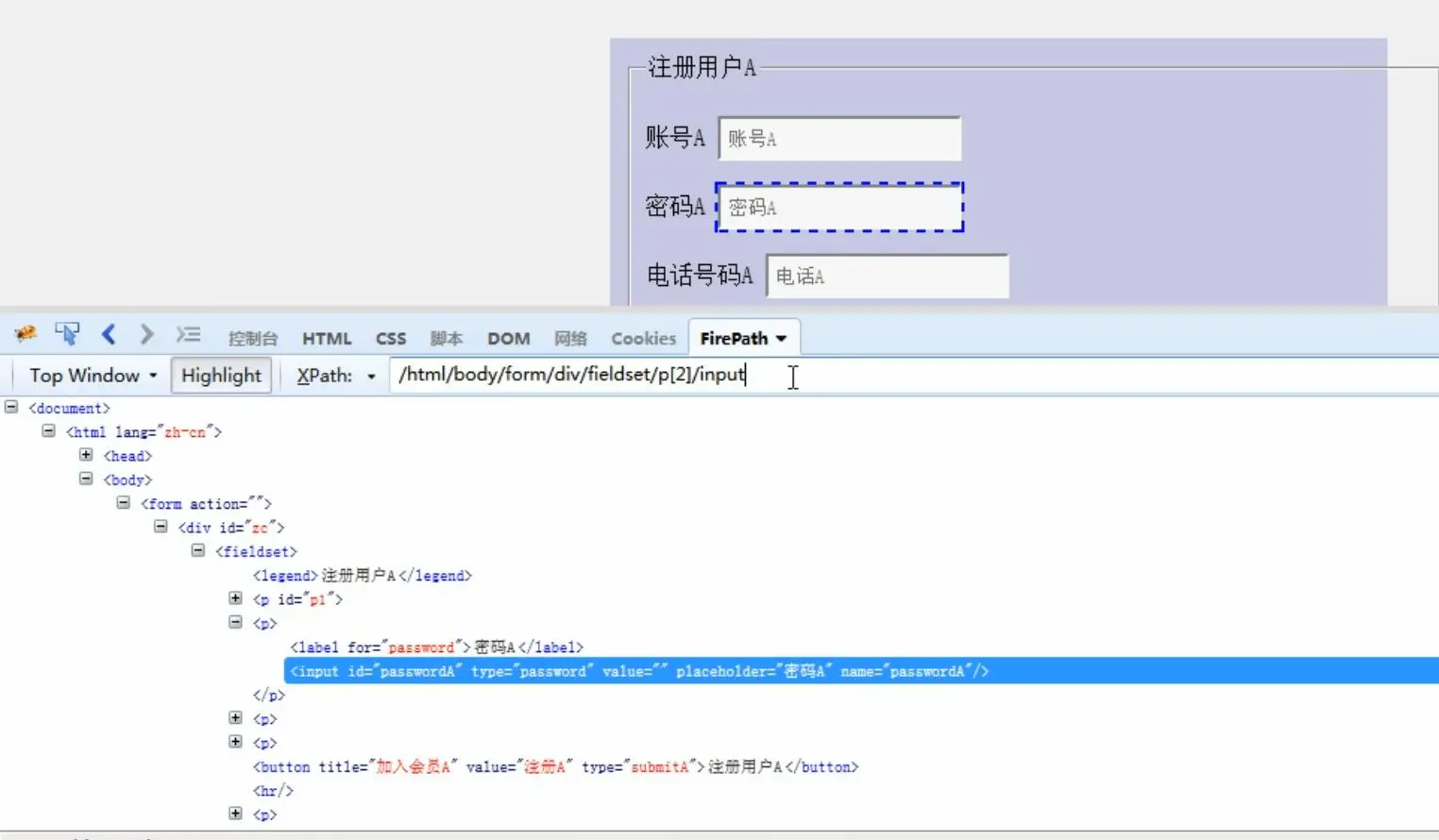
说明:frame是html中的一个框架,主要在当前页面中的某一区域显示另一页面元素。比如,一个网页中有三部分内容:注册页面、注册A页面、注册B页面。想通过自动化输入注册信息,发现卡在注册页面,A和B注册页面的信息输入不了。这是因为在源码中,注册页面可以直接找到user、id等元素,而A和B页面都没有userA和userB,怎么会定位的到呢?所以需要表单切换。
为什么要进行表单切换?因为当前页面没有frame表单元素信息,不切换找不到元素。
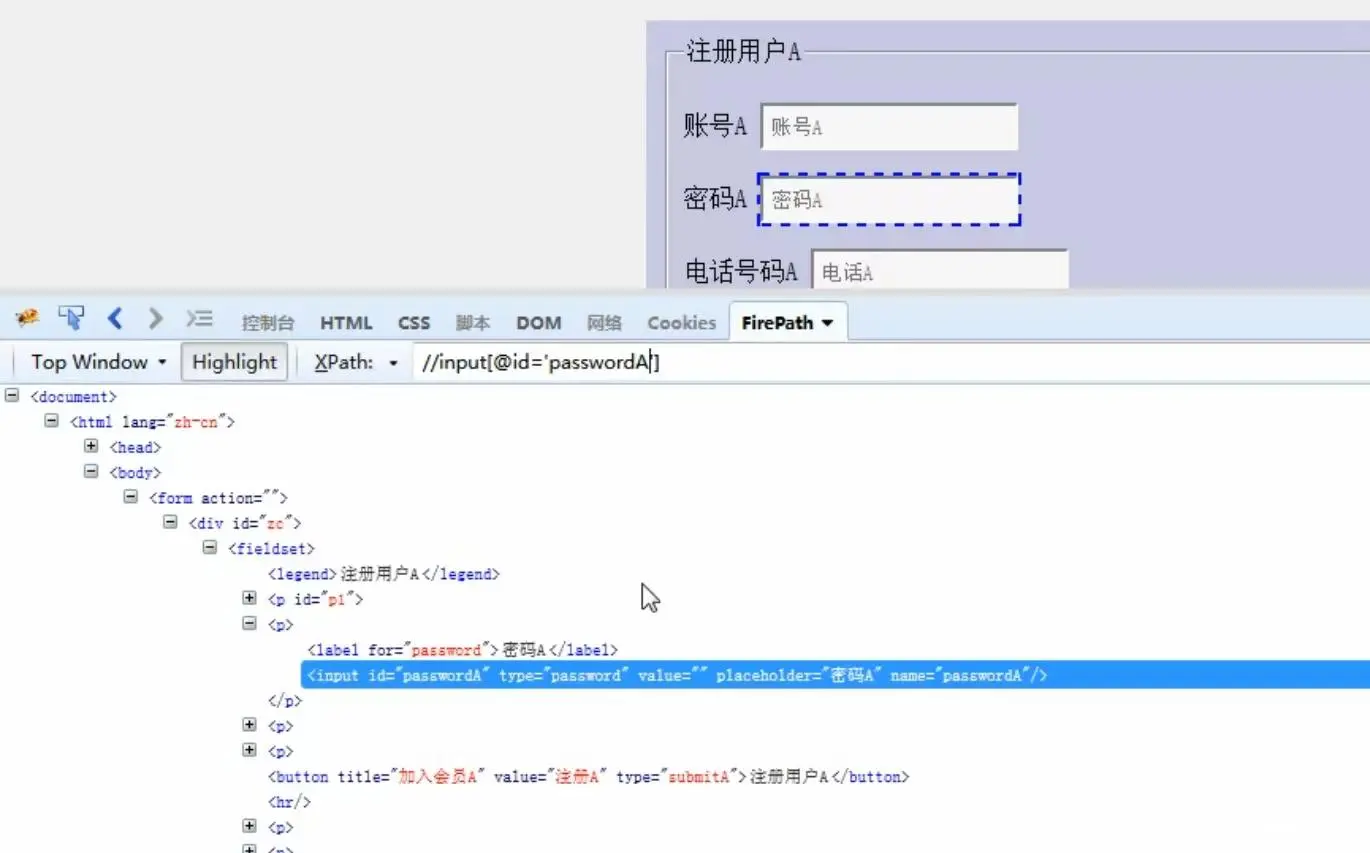
方法及步骤:
driver.switch_to.frame("id/name/element") 切换表单
driver.switch_to.default_content() 回主目录(不回主目录找不到表单信息)
4.5窗口切换(重点)
说明:想在跳转后的页面进行操作
方法及步骤:
handle = driver.current_window_handle 获取当前主窗口句柄
handles = driver.current_window_handles 获取所有页面的句柄
for h in handles:
if h != handle
driver.switch_to.window(h) 切换窗口
<code>from selenium.webdriver.support.ui import Select
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
def main():
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
#目标:打开百度首页,点击“新闻”跳转到新闻页面,在新闻页面进行登录操作
driver.get("https://www.baidu.com")
sleep(3)
#获得当前页面(driver启动的页面)的句柄
handle = driver.current_window_handle
print("当前窗口的句柄是:",handle)
#点击“新闻”跳转页面
driver.find_element(By.XPATH,'//*[@id="s-top-left"]/a[1]').click()code>
sleep(3)
# 获取所有页面句柄
handles = driver.window_handles
print("所有窗口的句柄是:", handles)
#遍历句柄,判断不是driver启动页面的句柄后,才可以进行登录操作
for h in handles:
if h != handle:
# 在跳转后的新闻页面点击“登录”按钮
driver.switch_to.window(h)
driver.find_element(By.XPATH, '//*[@id="passLog"]').click()code>
sleep(3)
driver.quit()
if __name__ == "__main__":
main()

4.6窗口截图
应用场景:失败截图,让错误更直观
方法:
driver.get_screenshot_as_file(imagepath)
imagepath是存储路径:./s.png 是保存在当前目录,../s.png是保存在上一级目录
driver.ger_screenshot_as_file("./%s.png"%(time.strftime("%Y_%m_%d %H_%M_%S")))
strftime是将时间转为字符串函数
<code>import time
from selenium.webdriver.support.ui import Select
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
def main():
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
driver.get("https://www.baidu.com")
sleep(3)
driver.get_screenshot_as_file("./%s.png"%(time.strftime("%Y_%m_%d %H_%M_%S")))
sleep(3)
driver.quit()
if __name__ == "__main__":
main()
4.6验证码
说明:随机生成的信息防止恶意请求,增加安全性。
方式:通过cookie(推荐)
提问:
什么是cookie?有什么作用?可以在哪里使用?
cookie是服务器生成的,用来在登录状态下标识一次对话的状态。浏览器自动记录cookie,在下一条请求时自动附加cookie信息。
通过cookie登录的方法及步骤:
driver.add_cookie({'name' : ' ','value':' cookie值'}) 需要提前获取cookie值
cookie = driver.get_cookies
print(cookie ) 打印所有的cookie信息
import time
from selenium.webdriver.support.ui import Select
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
def main():
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(10)
driver.get("https://www.baidu.com")
sleep(3)
#使用cookie登录百度
driver.add_cookie({'name':'BDUSS','value':'lzMWNETTNaS1BMd1daZFlvflQ0dmhRamdBaXhvNlV2VzAwcDRPaDktTWxxTHBtRUFBQUFBJCQAAAAAAQAAAAEAAACWyROIamllaGh3dwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACUbk2YlG5NmWU'})
sleep(2)
cookie = driver.get_cookies()
print(cookie)
driver.refresh()
sleep(3)
driver.quit()
if __name__ == "__main__":
main()

三.UnitTest框架
1.提问:什么是UnitTest框架?为什么使用这个框架?
UnitTest是python自带的单元测试框架。这个框架可以批量执行多个用例、有丰富的断言、自动生成报告。
2.核心要素有哪些:
testcase测试用例、testsuite测试套件、texttestrunner以文本形式运行测试用例、testloader批量执行测试用例,搜索指定文件夹内指定字母开头的文件、fixure固定装置,一个初始化时使用,一个结束时使用。
1.核心要素
①TestCase
步骤:
导包:import unittest
定义测试类:新建的测试类必须继承unittest.Testcase
定义测试方法:测试方法名以test开头
<code>#导包
import unittest
#编写求和函数
def add(x,y):
return x + y
#定义测试类
class Test01(unittest.TestCase):
#定义测试方法,以test开头
def test_add01(self):
result = add(1,1)
print("结果为:",result)
def test_add02(self):
result = add(2,1)
print("结果为:",result)
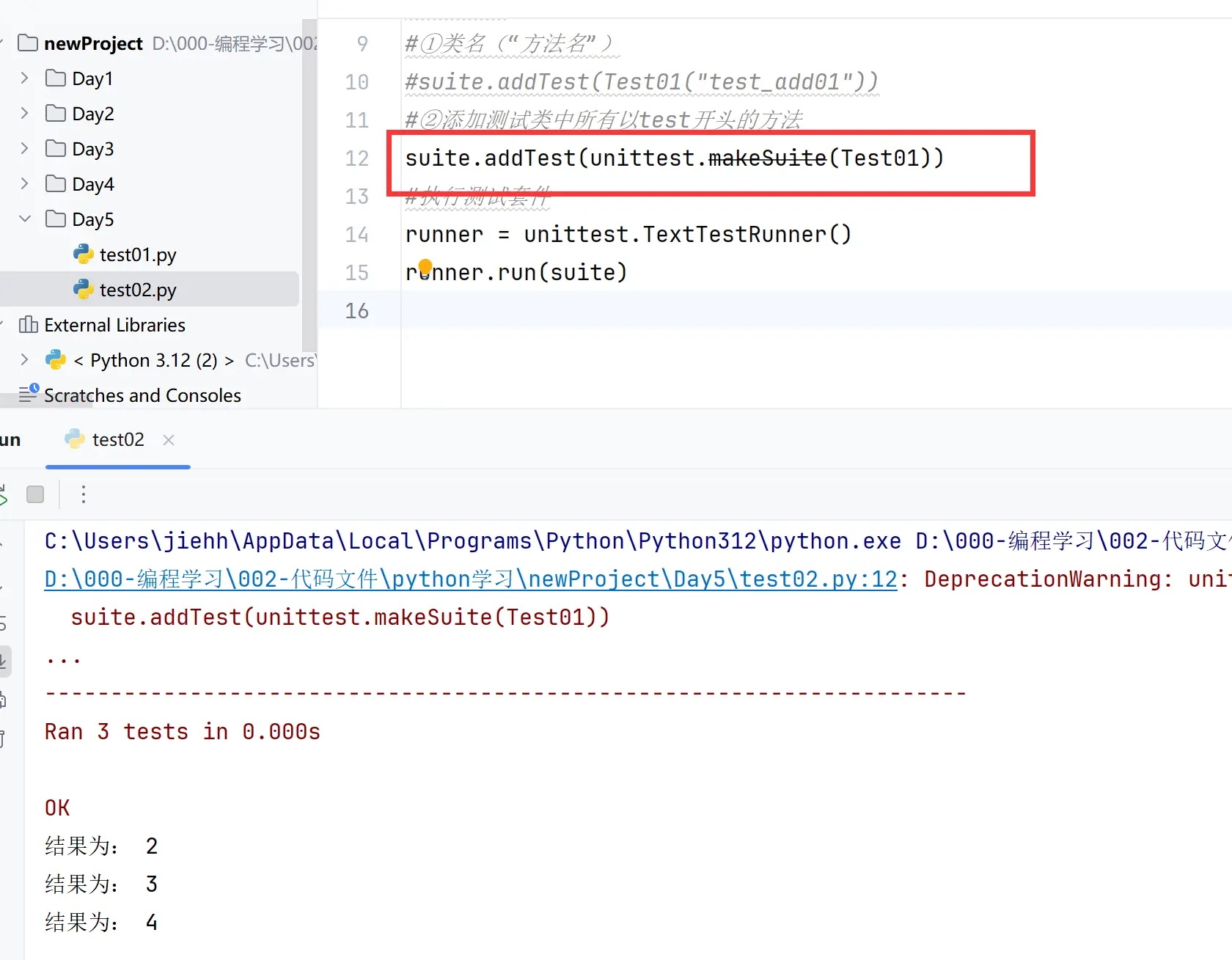
②TestSuite
步骤:
导包: import unittest
实例化:suite = unittest.TestSuite()
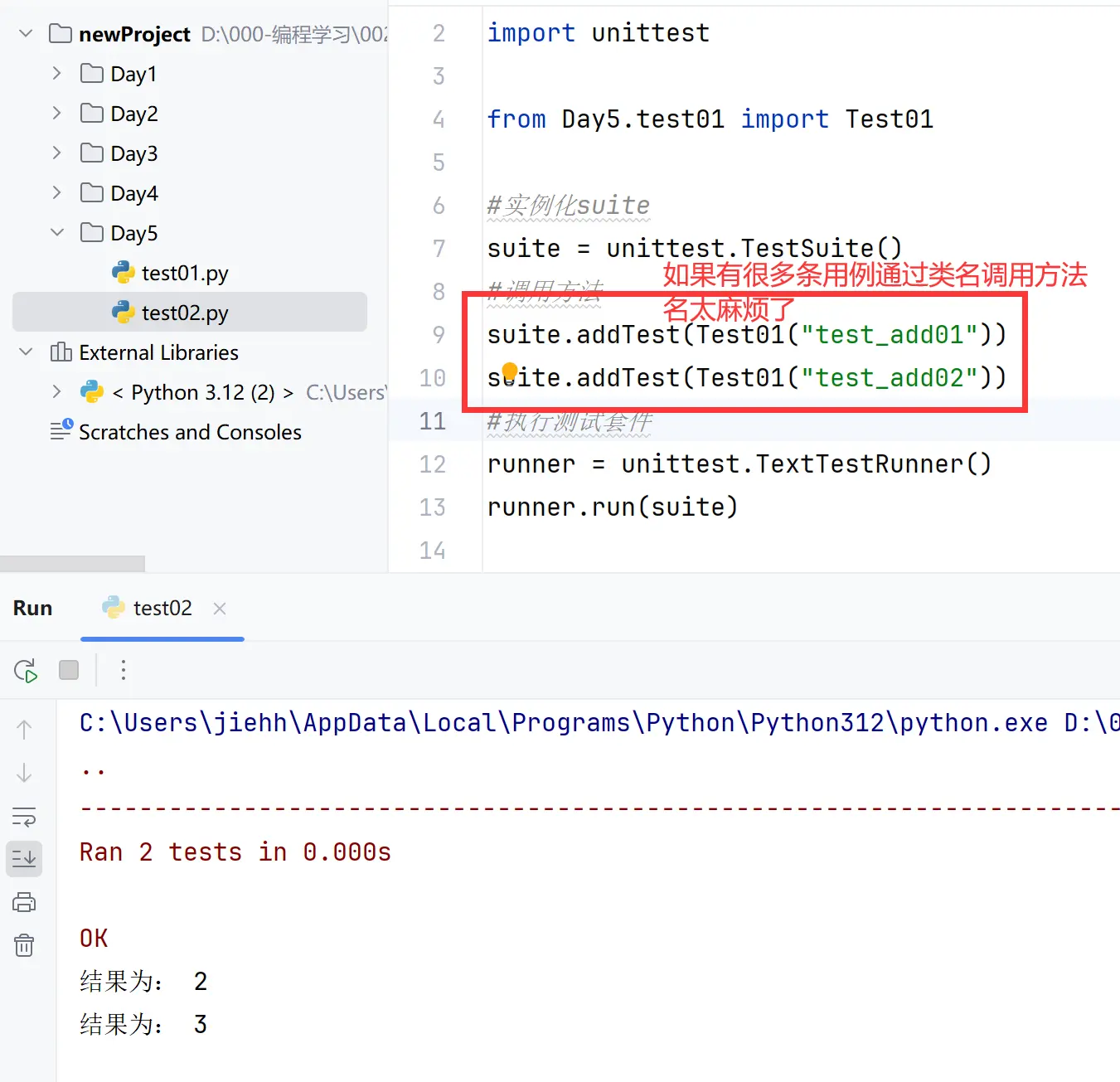
添加用例:
①suite.addTest(类名('方法名')) 添加指定类中的指定方法
②suite.addTest(unittest.makeSuite(类名)) 添加指定类中所有test开头的方法
执行:
runner = unittest.TextTestRunner()
runner.run(suite)
③TextTestRunner
作用:运行测试套件
步骤:
runner = unittest.TextTestRunner
runner.run(suite)
④TestLoader
操作步骤:
导包:import unittest
调用TestLoader():suite=unittest.TestLoader().discover("指定文件路径","指定字母开头的文件.py")
执行测试套件:unittest.TextTestRunner().run(suite)
TestSuite和TestLoader的对比:
相同点:都是测试套件
不同点:
①TestSuite:
②TestLoader:
⑤Fixure
说明:Fixure是两个函数,一个初始化函数def setup(),一个是结束函数def teardown()。可以同时使用也可以单独使用。
级别:
①函数级别:def setUp()/def tearDown()
特性:几个测试函数就执行几次
②类级别:def setUpclass()/def tearDownClass(),要添加索引@classmethod
特性:测试类执行之前执行一次,setupclass执行之后执行一次teardownclass
③模块级别:def setUpModule()/def teaDownModule()
特性:模块运行之前执行一次 setupmodule,运行之后执行一次teardownmodule
<code>import unittest
class Test(unittest.TestCase):
@classmethod
def setUpClass(cls):
print("setupclass执行")
@classmethod
def tearDownClass(cls):
print("teardownclass执行")
def setUp(self):
print("执行")
def test01(self):
print("test01执行")
def test02(self):
print("test02执行")
def tearDown(self):
print("结束")

2.断言
说明:判断执行结果是否符合预期结果
常用方法:
self.assertTrue(ex) 判断ex是否为真
self.assertIn(ex1,ex2) 判断ex2是否包含ex1
self.assertEqual(ex1,ex2) 判断两个字符串是否相等
<code>import unittest
class Test(unittest.TestCase):
def test01(self):
#断言是否为true
flag = True
self.assertTrue(flag)
#断言是否相等
self.assertEqual("hello","hello")
#断言后面字符串是否包含前一个字符串
self.assertIn("hello","hello,myallsf")
3.参数化
说明:什么是参数化?为什么要参数化?参数化的应用场景?
答:参数化就是根据需求动态获取数据的过程。参数化可以解决代码冗余的问题。可以应用在业务逻辑相同但测试数据不同的场景。
应用:
安装插件:pip install parameterized
导包:from parameterized import parameterized
修饰测试函数:@parameterized.expand([数据])
数据格式:
单个参数,类型为列表
多个参数,类型为列表嵌套元组
import unittest
from parameterized import parameterized
class Test(unittest.TestCase):
#写法1
@parameterized.expand(["1","2","3"])
def test_add_one(self,num):
print("num:",num)
#写法2
@parameterized.expand([(1,2,3),(4,5,6),(7,8,9)])
def test_add_more(self, a,b,result):
print("{}+{}={}:".format(a,b,result))
#写法3
def get_data(self):
return ([(1,2,3),(4,5,6),(7,8,9)])
@parameterized.expand(get_data())
def test_add_more(self,a,b,result):
print("{}+{}={}:".format(a,b,result))
4.跳过
说明:用于未完成或者条件不满足的测试用例和测试函数
方法:
@unittest.skip("说明"):适用于未完成的情况
@unittest.skipIf(条件,原因):适用于不满足测试条件的情况
import unittest
version = 30
class Test01(unittest.TestCase):
@unittest.skip("test01功能暂未完全实现")
def test01(self):
pass
@unittest.skipIf(version > 25,"如果版本大于25就跳过次用例")
def test02(self):
print("test02执行")
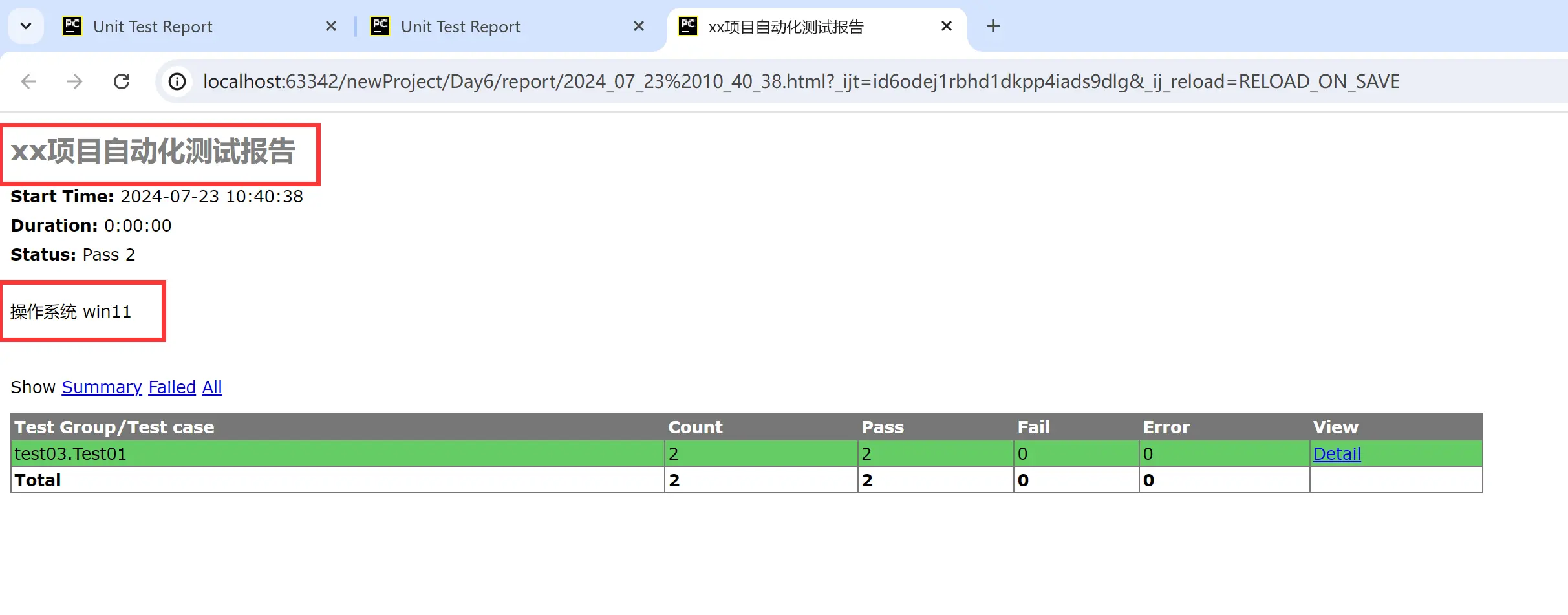
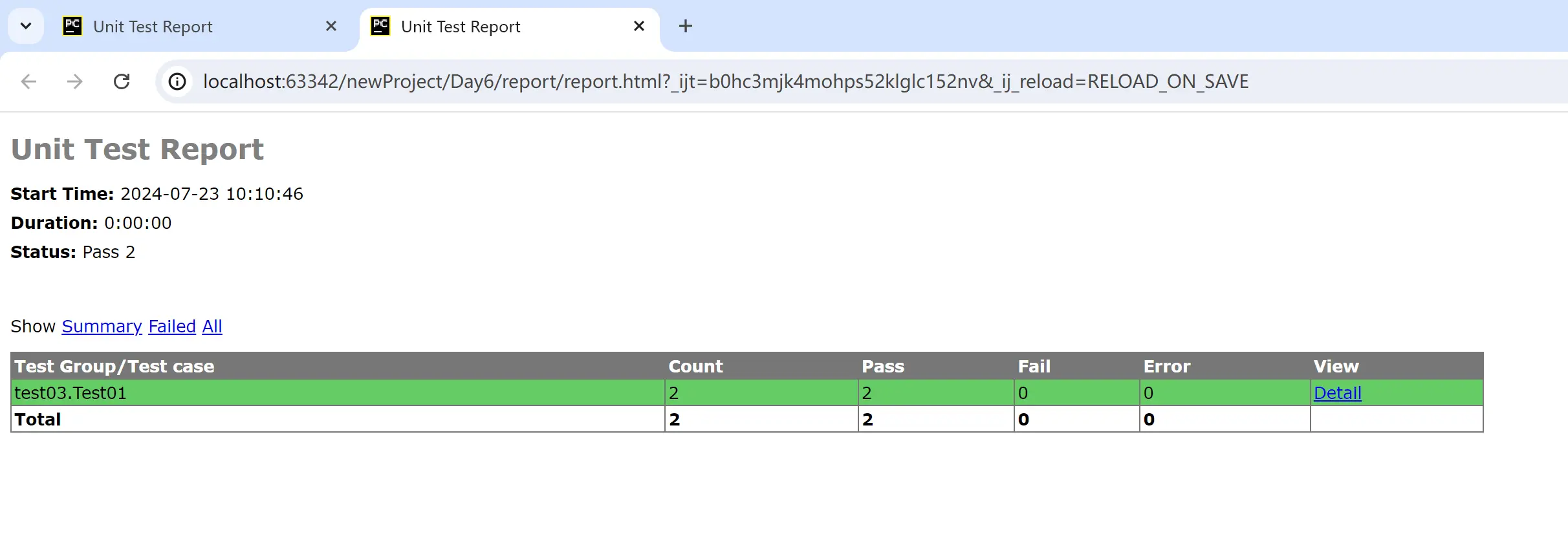
5.html报告
ps:文件流就是打开指定写入的文件
说明:测试用例执行完后,执行结果以html形式生成
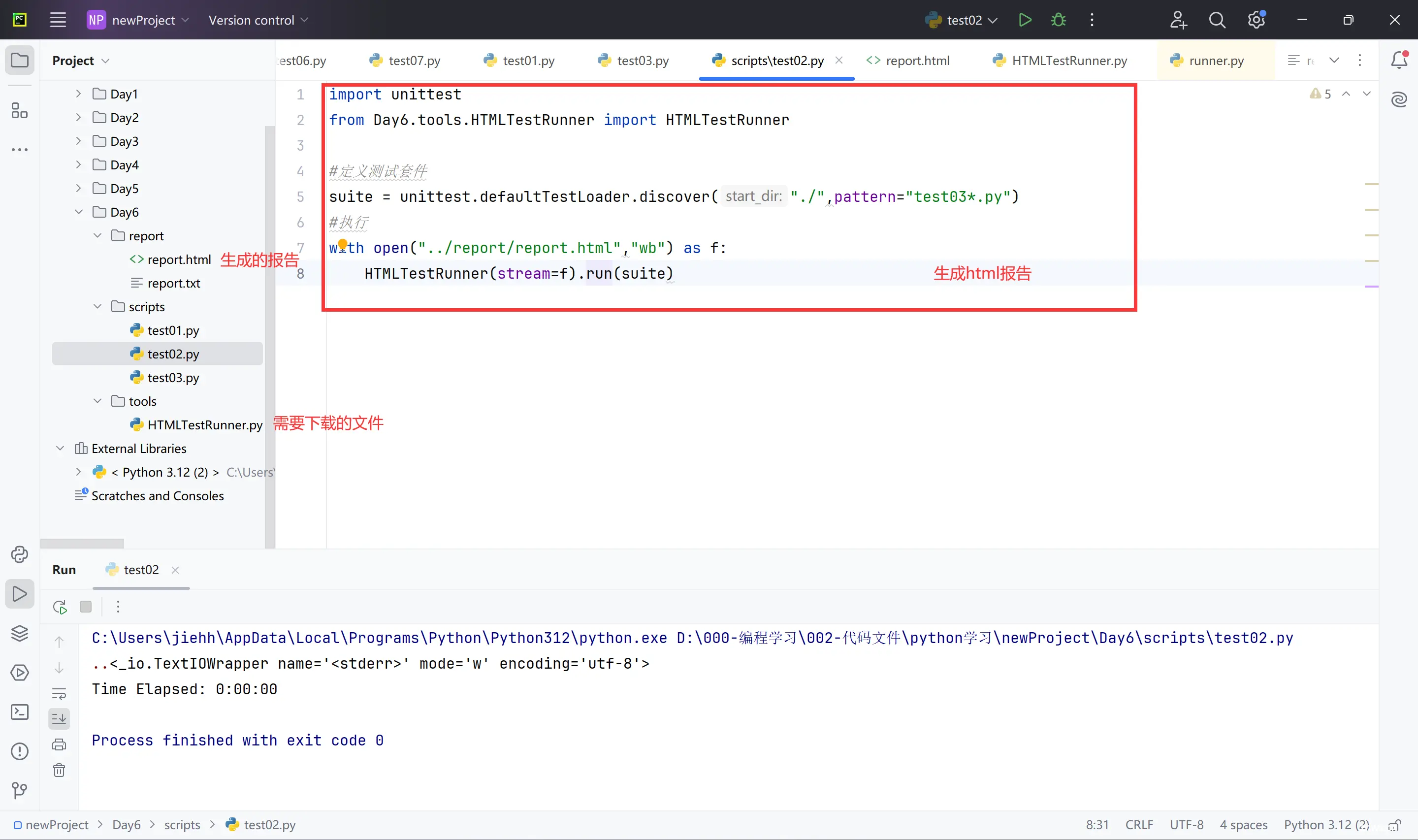
步骤:
①导包:from xx.HTMLTestRunner.py import HTMLTestRunner
②定义测试套件:suite = unittest.defaultTestLoader.discover(测试用例存放路径,"以字母开头的测试用例.py")
③定义报告存放路径:report_dir = "../xx/{}.html".format(time.srtftime("%Y_%m_%d %H_%M_%S"))
④获取报告文件流:
with open(report_dir,"wb") as f:
HTMLTestRunner(stream=f,verbosity=2,title="",description="").run(suite)


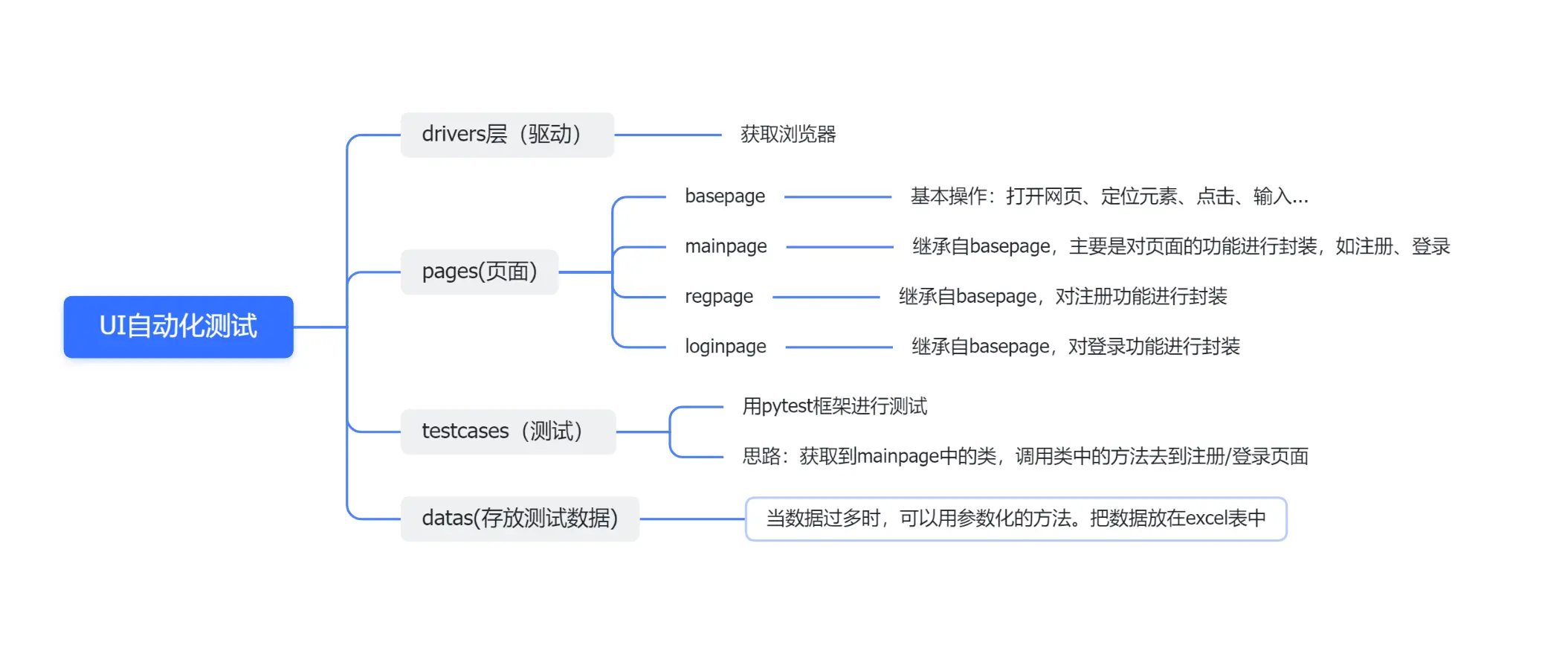
四.PO模式
说明:Page Object模式是将测试代码和业务代码进行分离。
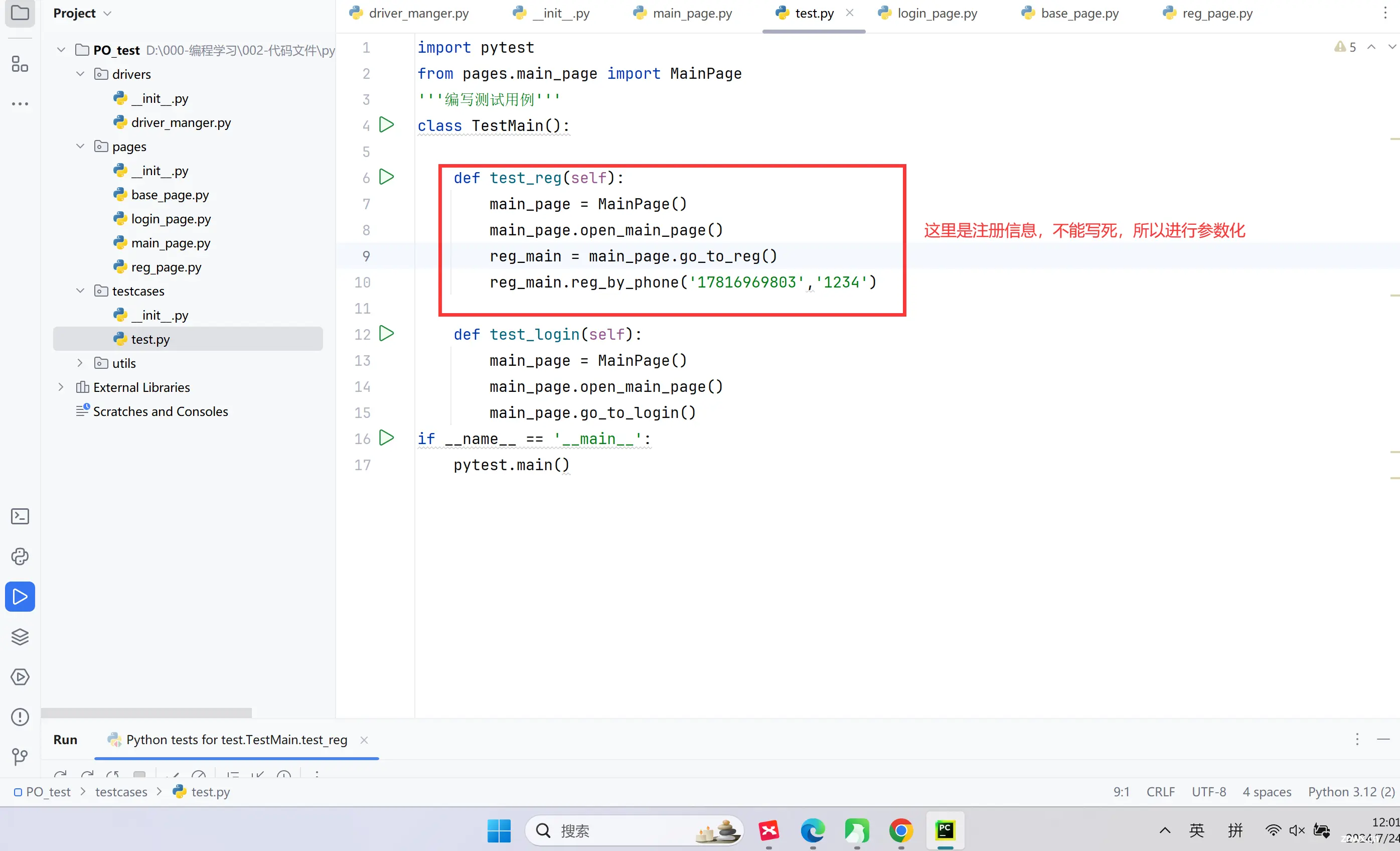
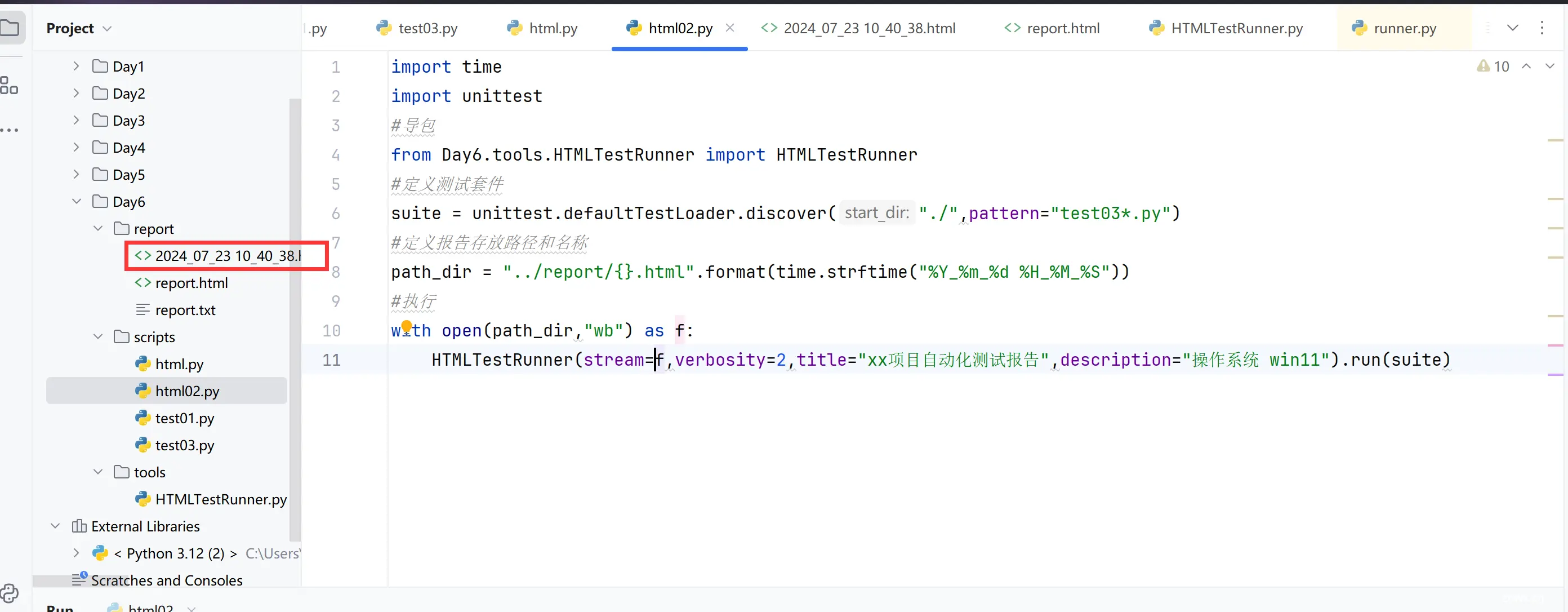
这样数据还是不好管理,应该封装成数据层:
创建data包->pip install pandas和pip install xlrd==2.0.1 ->使用excel来存放数据
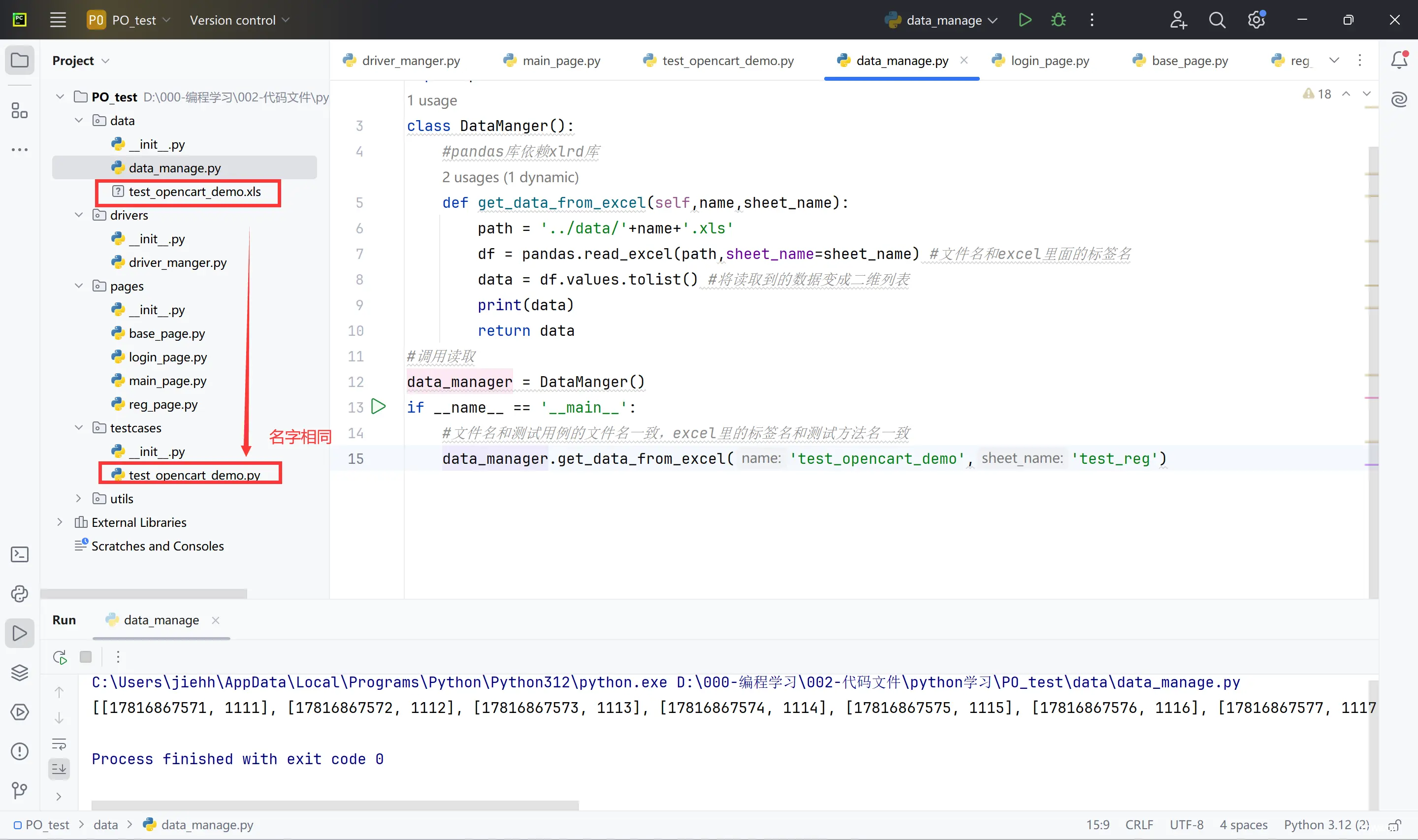
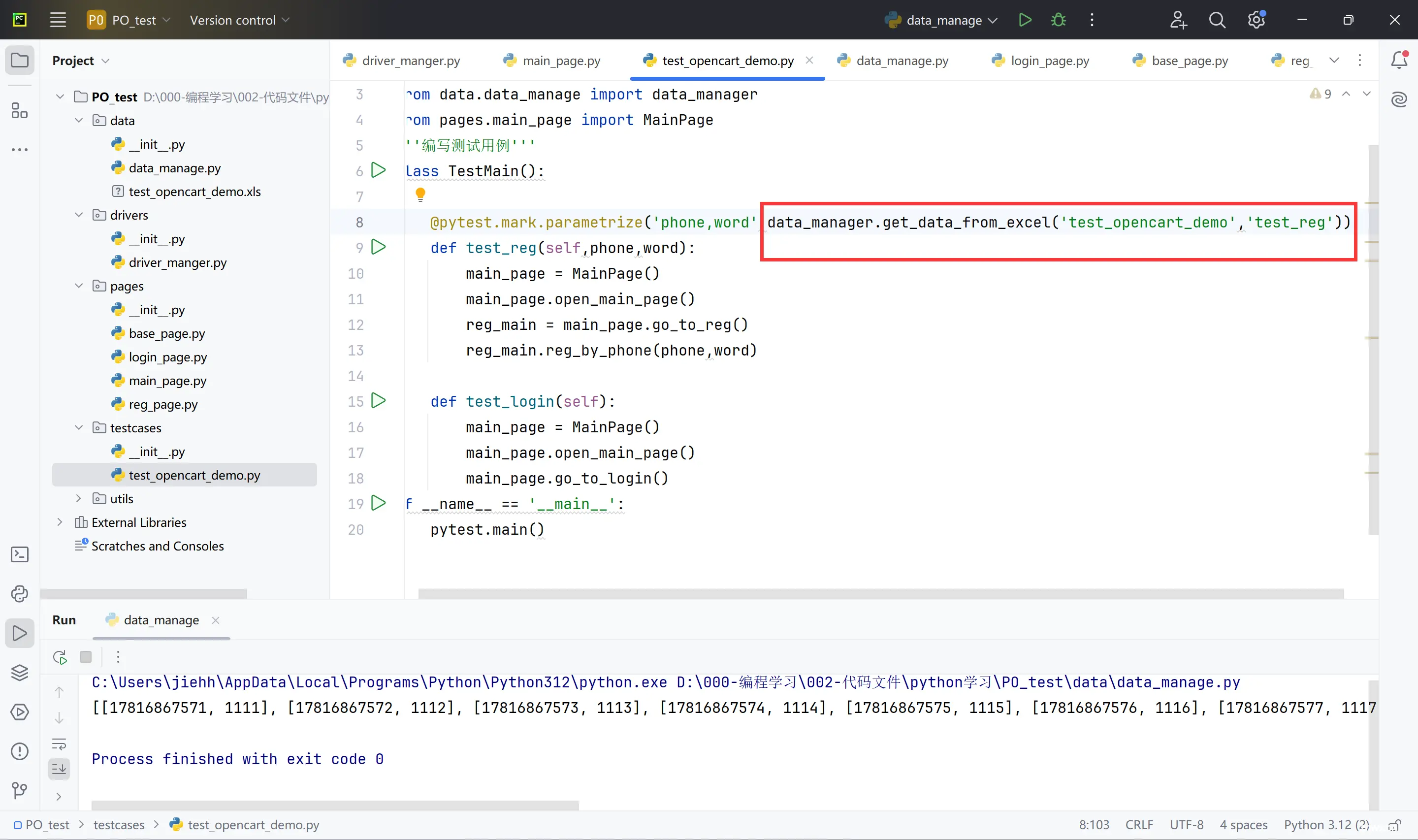
五.数据驱动
说明:
1.什么是数据驱动?
通过测试数据控制用例的执行,直接影响测试结果
最好是po模式+参数化
2.为什么要数据驱动?
将维护重点放在测试数据上,而不是测试脚本代码
3.数据驱动常用格式
json、xml、txt、excel、csv
1.json介绍
说明:
是一种纯文本格式,后缀.json
是一种轻量级数据交换格式
由键值对组成
花括号包含键值对,中括号包含数组,键值对直接用逗号分隔,键与值用冒号分隔
2 json格式转换
<code>'''将字典转换为json格式'''
#导包
import json
#定义字典
dic = {"name":"张三","age":12}
print("转换之前的数据类型:",type(dic))
#调用dumps()方法进行转换
dic2 = json.dumps(dic)
print("转换之后的数据类型:",type(dic2))
print(dic2)
print("--------------------------------")
'''将字符串转换为json格式'''
#定义字符串
str = '{"name":"张三","age":12}'
print("转换之前的数据类型:",type(str))
#调用loads()方法进行转换
str2 = json.loads(str)
print("转换之后的数据类型:",type(str2))
3.json读与写
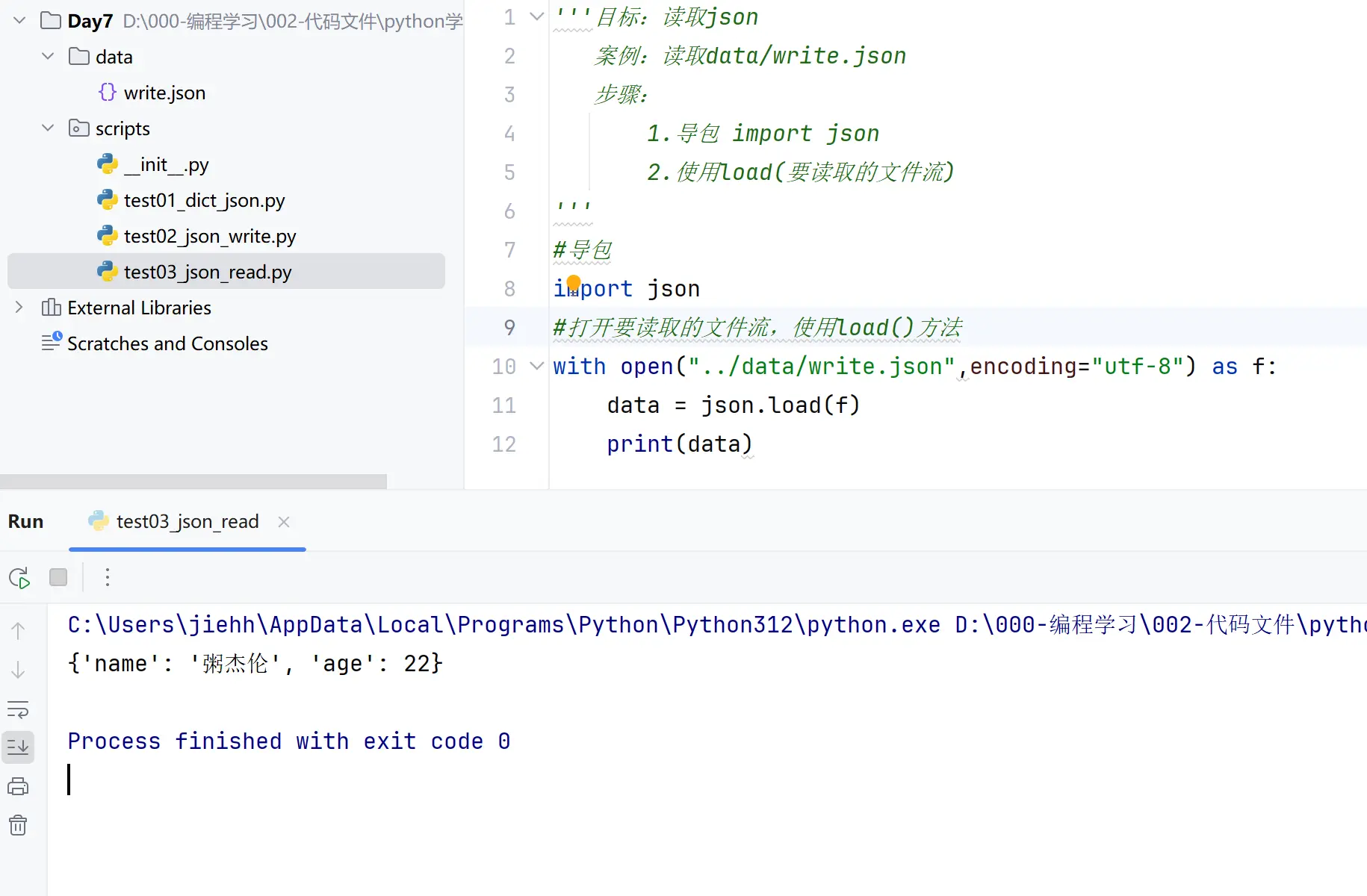
读
写(这里文件名取错了,应该是test02_json_write)
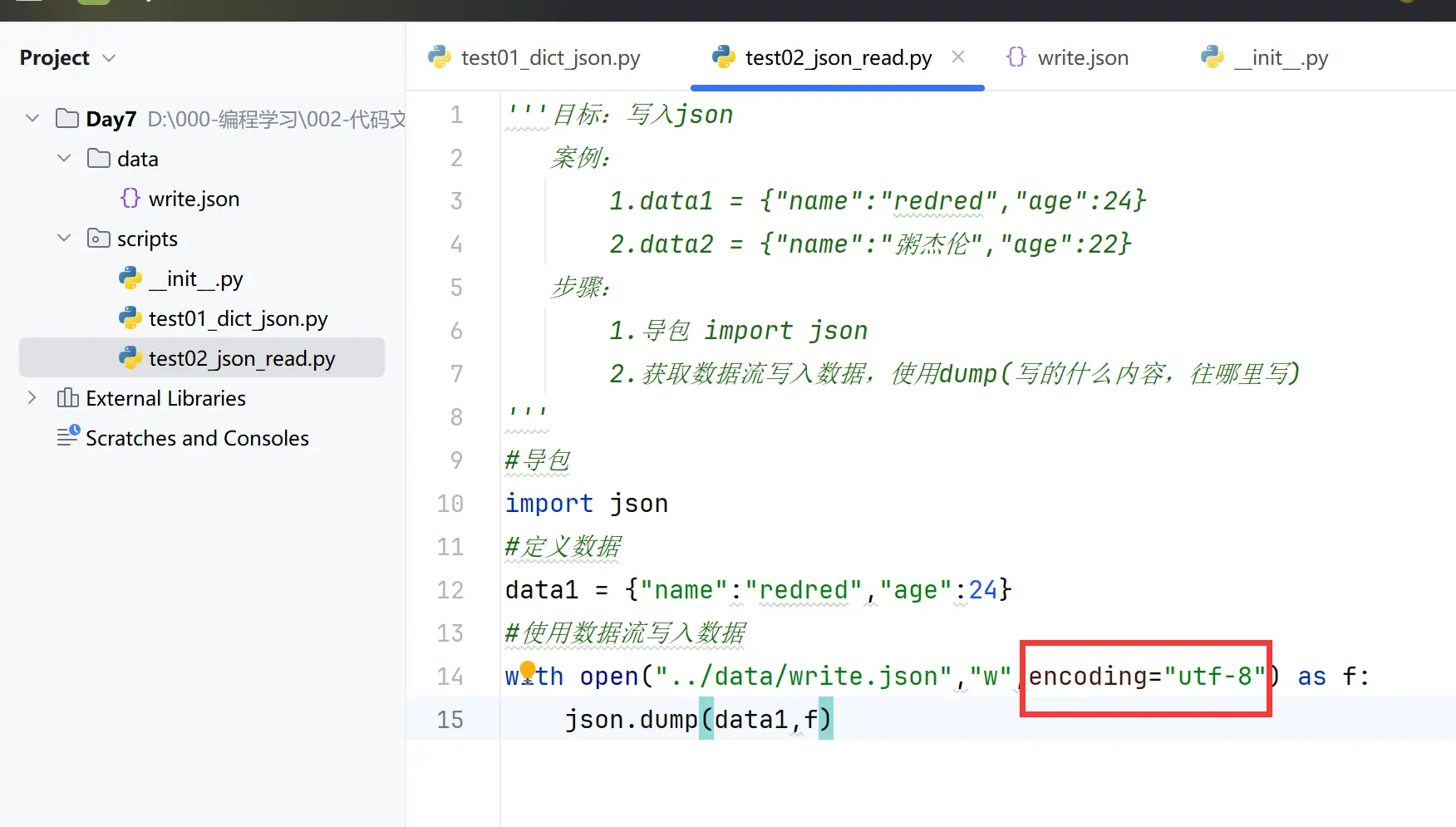
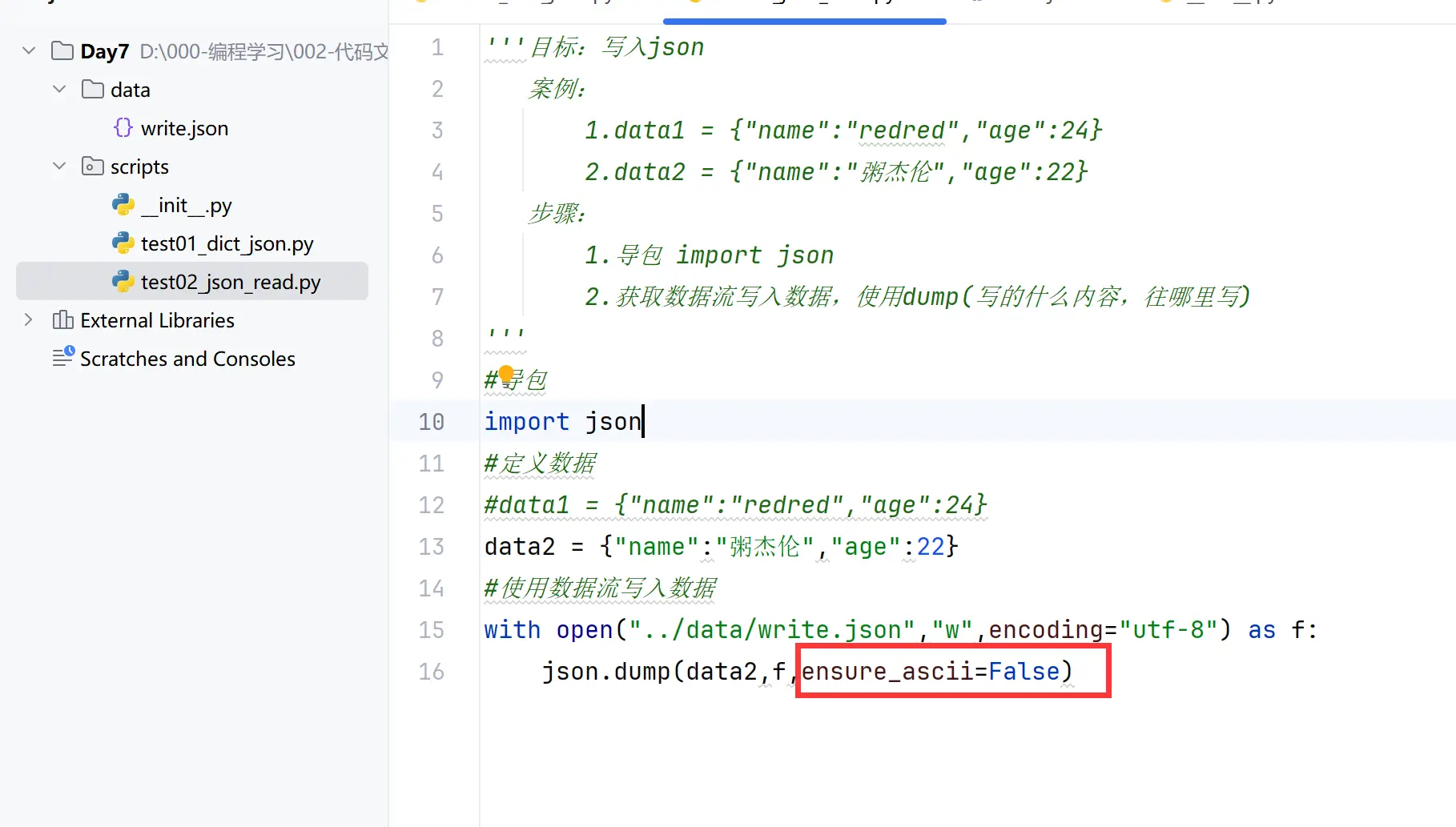
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。