ZooKeeper 入门教程
codechen8848 2024-10-23 10:09:00 阅读 75
ZooKeeper(动物园管理者)简称 ZK,一个分布式的,开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现,是 Hadoop 和 Hbase 的重要组件。
0. 前言
文章已经收录到 GitHub 个人博客项目,欢迎 Star:
<code>https://github.com/chenyl8848/chenyl8848.github.io
或者访问网站,进行在线浏览:
https://chenyl8848.github.io/
1. ZooKeeper 简介
ZooKeeper(动物园管理者)简称 ZK,一个分布式的,开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现,是 Hadoop 和 Hbase 的重要组件。ZooKeeper 使用 Java 所编写,但是支持 Java 和 C 两种编程语言。

应用场景:
- 分布式微服务注册中心:Dubbo 框架、Spring Cloud 框架
- 集群管理:Hadoop Hbase 组件
- 分布式锁
关注微信公众号:【Java陈序员】,获取开源项目分享、AI副业分享、超200本经典计算机电子书籍等。
2. ZooKeeper 内存数据模型
2.1 模型结构
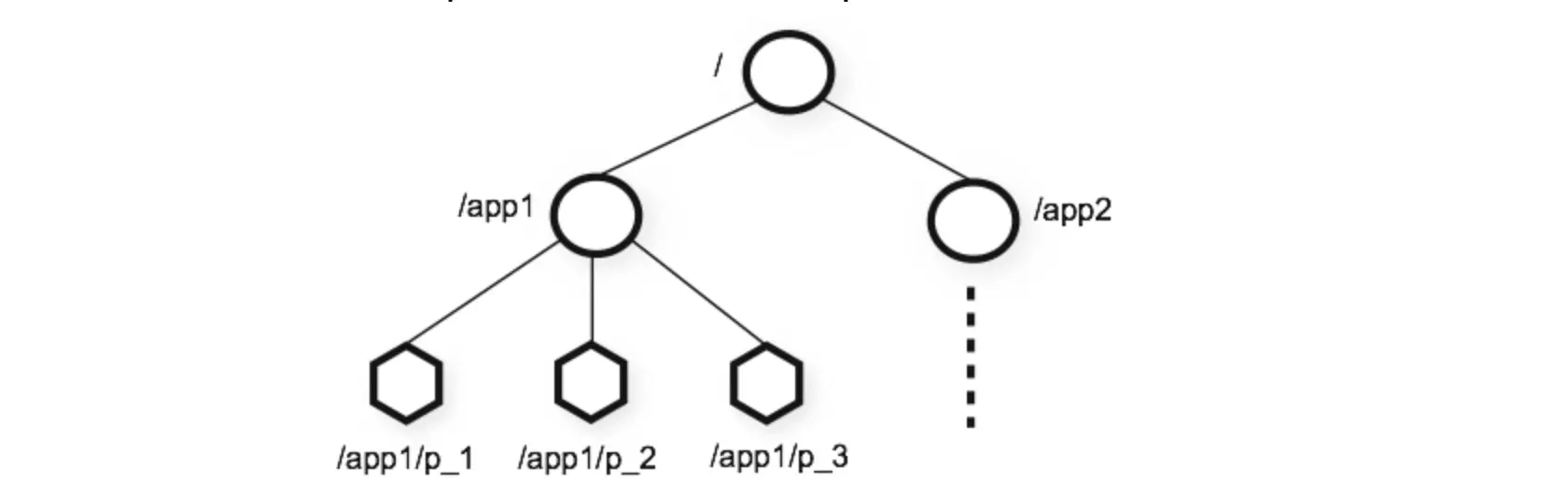
2.2 模型的特点
- 每个子目录如 <code>/node1 都被称作一个
znode(节点),这个znode是被它所在的路径唯一标识 znode可以有子节点目录,并且每个znode可以存储数据znode是有版本的,每个znode中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据znode可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端
3. 节点的分类
3.1 持久节点(PERSISTENT)
指在节点创建后,就一直存在,直到有删除操作来主动删除这个节点 —— 不会因为创建该节点的客户端会话失效而消失。
3.2 持久顺序节点(PERSISTENT_SEQUENTIAL)
这类节点的基本特性和上面的节点类型是一致的。额外的特性是,在 ZooKeeper 中,每个父节点会为他的第一级子节点维护一份时序,会记录每个子节点创建的先后顺序。基于这个特性,在创建子节点的时候,可以设置这个属性,那么在创建节点过程中,ZooKeeper 会自动为给定节点名加上一个数字后缀,作为新的节点名。这个数字后缀的范围是整型的最大值。
3.3 临时节点(EPHEMERAL)
和持久节点不同的是,临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。注意,这里提到的是会话失效,而非连接断开。另外,在临时节点下面不能创建子节点。
3.4 临时顺序节点(EPHEMERAL_SEQUENTIAL)
具有临时节点特点,额外的特性是,每个父节点会为他的第一级子节点维护一份时序,这点和持久顺序节点类似。
4. 安装
4.1 Linux 系统安装
# 1.安装 JDK 并配置环境变量&下载 ZooKeeper 安装包
-https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.6.2/apache-zookeeper-3.6.2-bin.tar.gz
# 2.下载安装包上传到 Linux 服务器中,并解压缩
-tar -zxvf zookeeper-3.4.12.tar.gz
# 3.重命名安装目录
-mv zookeeper-3.4.12 zk
# 4.配置 zoo.cfg 配置文件
-1.修改 ZooKeeper 的 conf 目录下的 zoo_simple.cfg,修改完后,重命名为zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/zookeeper/zkdata
clientPort=2181
# 5.启动 ZooKeeper
-在 ZooKeeper 的 bin 目录下,运行 zkServer.sh
./bin/zkServer.sh start /usr/zookeeper/conf/zoo.cfg
# 6.使用 jps 查看启动是否成功
# 7.启动客户端连接到 ZooKeeper
- ./bin/zkCli.sh -server 192.168.0.220:2181
注意:可以通过./bin/zkCli.shhelp查看客户端所有可以执行的指令
4.2 Docker 安装 ZooKeeper
# 1.获取 ZooKeeper 的镜像
- docker pull zookeeper:3.4.14
# 2.启动 ZooKeeper 服务
- docker run --name zk -p 2181:2181 -d zookeeper:3.4.14
5. 客户端基本指令
# 1.ls path 查看特定节点下面的子节点
# 2.create path data 创建一个节点。并给节点绑定数据(默认是持久性节点)
- create path data 创建持久节点(默认是持久节点)
- create -s path data 创建持久性顺序节点
-create -epath data 创建临时性节点(注意:临时节点不能含有任何子节点)
-create -e -s pathdata 创建临时顺序节点(注意:临时节点不能含有任何子节点)
# 3.stat path 查看节点状态
# 4.set path data 修改节点数据
# 5.ls2 path 查看节点下孩子和当前节点的状态
# 6.history 查看操作历史
# 7.get path 获得节点上绑定的数据信息
# 8.delete path 删除节点(注意:删除节点不能含有子节点)
# 9.rmr path 递归删除节点(注意:会将当前节点下所有节点删除)
# 10.quit 退出当前会话(会话失效)
6. 节点监听机制 watch
客户端可以监测 znode 节点的变化。znode 节点的变化会触发相应的事件,然后清除对该节点的监测。
当监测一个 znode 节点时候,Zookeeper 会发送通知给监测节点。一个 Watch 事件是一个一次性的触发器,当被设置了 Watch 的数据和目录发生了改变的时候,则服务器将这个改变发送给设置了 Watch 的客户端以便通知它们。
# 1.ls /path true 监听节点目录的变化
# 2.get /path true监听节点数据的变化
7.Java 操作 ZooKeeper
7.1 创建项目引入依赖
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.10</version>
</dependency>
7.2 获取 ZooKeeper 客户端对象
private ZkClient zkClient;
/**
* 获取zk客户端连接
*/
@Before
public void Before() {
// 参数1:服务器的ip和端口
// 参数2:会话的超时时间
// 参数3:回话的连接时间
// 参数4:序列化方式
zkClient = new ZkClient("192.168.28.132:2181", 30000, 60000, new SerializableSerializer());
}
/**
* 关闭资源
*/
@After
public void after(){
zkClient.close();
}
7.3 常用 API
- 创建节点
/**
* 创建节点
*/
@Test
public void testCreateNode() {
//第一中创建方式 返回创建节点的名称
String nodeName = zkClient.create("/node5", "lisi", CreateMode.PERSISTENT);
zkClient.create("/node6", "zhangsan", CreateMode.PERSISTENT_SEQUENTIAL);
zkClient.create("/node7", "王五", CreateMode.EPHEMERAL);
zkClient.create("/node8", "xiaozhang", CreateMode.EPHEMERAL_SEQUENTIAL);
//第二种创建方式 不会返回创建节点的名称
zkClient.createPersistent("/node1", "持久数据");
zkClient.createPersistentSequential("/node1/aa", "持久数据顺序节点");
zkClient.createEphemeral("/node2", "临时节点");
zkClient.createEphemeralSequential("/node1/bb", "临时顺序节点");
}
- 删除节点
/**
* 删除节点
*/
@Test
public void testDeleteNode() {
// 删除没有子节点的节点 返回值:是否删除成功
boolean delete = zkClient.delete("/node1");
// 递归删除节点信息 返回值:是否删除成功
boolean recursive = zkClient.deleteRecursive("/node1");
}
- 查看节点的子节点
/**
* 查询节点
*/
@Test
public void testFindNodes() {
// 获取指定路径的节点信息
// 返回值:为当前节点的子节点信息
List<String> children = zkClient.getChildren("/");
for (String child : children) {
System.out.println(child);
}
}
- 查看当前节点的数据
注意:如果出现:
org.I0Itec.zkclient.exception.ZkMarshallingError: java.io.StreamCorruptedException: invalid stream header: 61616161. 异常的原因是:在 Shell 中的数据序列化方式和 Java 代码中使用的序列化方式不一致,因此要解决这个问题只需要保证序列化一致即可。
/**
* 获取节点的数据
*
*/
@Test
public void testFindNodeData() {
Object readData = zkClient.readData("/node3");
System.out.println(readData);
}
- 查看当前节点的数据并获取状态信息
/**
* 获取数据以及当前节点的状态信息
*/
@Test
public void testFindNodeDataAndStat() {
Stat stat = new Stat();
Object readData = zkClient.readData("/node60000000024", stat);
System.out.println(readData);
System.out.println(stat);
}
- 修改节点数据
/**
* 修改节点数据
*/
@Test
public void testUpdateNodeData() {
zkClient.writeData("/node60000000024", new User("121", "name", "xxx"));
}
- 监听节点数据的变化
/**
* 监听节点数据的变化
*/
@Test
public void testOnNodeDataChange() throws IOException {
zkClient.subscribeDataChanges("/node60000000024", new IZkDataListener() {
// 当节点的值在修改时,会自动调用这个方法 将当前修改节点的名字,和节点变化之后的数据传递给方法
public void handleDataChange(String nodeName, Object result) throws Exception {
System.out.println(nodeName);
System.out.println(result);
}
// 当节点的值被删除的时候,会自动调用这个方法,会将节点的名字已参数形式传递给方法
public void handleDataDeleted(String nodename) throws Exception {
System.out.println("节点的名字:" + nodename);
}
});
//阻塞客户端
System.in.read();
}
- 监听节点目录的变化
/**
* 监听节点的变化
*/
@Test
public void testOnNodesChange() throws IOException {
zkClient.subscribeChildChanges("/node60000000024", new IZkChildListener() {
// 当节点的发生变化时,会自动调用这个方法
// 参数1:父节点名称
// 参数2:父节点中的所有子节点名称
public void handleChildChange(String nodeName, List<String> list) throws Exception {
System.out.println("父节点名称:" + nodeName);
System.out.println("发生变更后字节孩子节点名称:");
for (String name : list) {
System.out.println(name);
}
}
});
// 阻塞客户端
System.in.read();
}
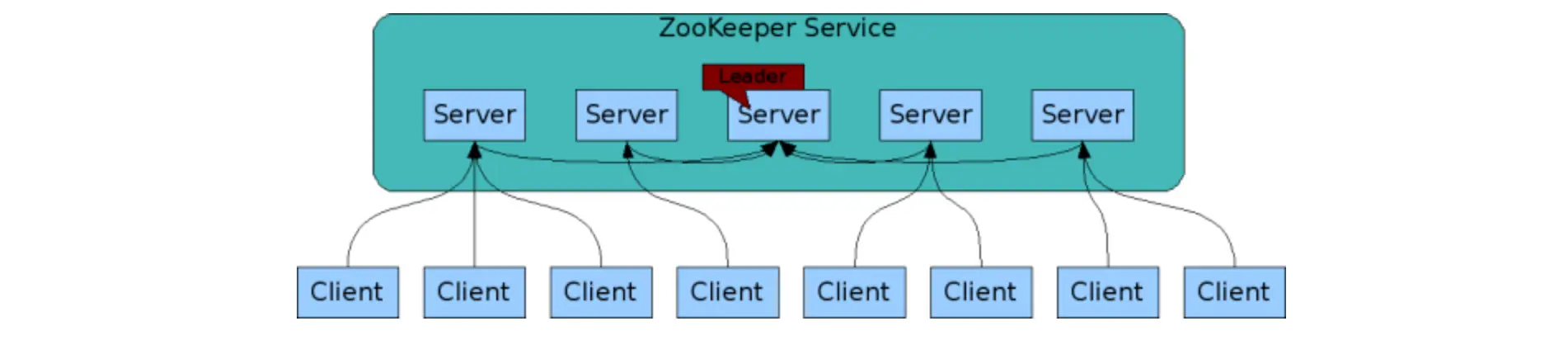
8. ZooKeeper 的集群
8.1 集群(Cluster)
# 1.集群(Cluster)
- 集合同一种软件服务的多个节点同时提供服务
# 2.集群解决问题
- 单节点的并发访问的压力问题
- 单节点故障问题(如硬件老化、自然灾害等)
8.2 集群架构
8.3 集群搭建
<code># 1.创建三个 dataDir
- mkdir zkdata1 zkdata2 zkdata3
# 2.分别在三个dataDir目录下面myid文件
-touch ./zkdata1/myid
myid 的内容是 服务器的 表示 1|2|3
# 3.在 /conf 目录下创建三个 ZooKeeper 配置文件,分别为 zoo1.cfg、zoo2.cfg、zoo3.cfg
-zoo1.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata1
clientPort=3001
server.1=10.15.0.5:3002:3003
server.2=10.15.0.5:4002:4003
server.3=10.15.0.5:5002:5003
- zoo2.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata2
clientPort=4001
server.1=10.15.0.5:3002:3003
server.2=10.15.0.5:4002:4003
server.3=10.15.0.5:5002:5003
- zoo3.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/root/zkdata3
clientPort=5001
server.1=10.15.0.5:3002:3003
server.2=10.15.0.5:4002:4003
server.3=10.15.0.5:5002:5003
解释:
1.server.X: x为服务器的唯一标识。
2.192.168.0.220: 服务器所在的ip地址
3.3002: 数据同步使用的端口号
4.3003: 选举使用的端口号
# 4.分别启动各个 ZooKeeper 服务器
- ./bin/zkServer.sh start /usr/zookeeper/conf/zoo1.cfg
- ./bin/zkServer.sh start /usr/zookeeper/conf/zoo2.cfg
- ./bin/zkServer.sh start /usr/zookeeper/conf/zoo3.cfg
# 5.查看各个 ZooKeeper 服务器的角色信息
- ./bin/zkServer.sh status /usr/zookeeper/conf/zoo1.cfg
# 6.客户端连接任意 ZooKeeper 服务器进行节点操作
- ./bin/zkCli.sh -server 192.168.0.220:3001
# 7.停止特定 ZooKeeper 服务器
- ./bin/zkServer.sh stop /usr/zookeeper/conf/zoo1.cfg
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。