【python】爬取杭州市二手房销售数据做数据分析【附源码】
Yan-英杰 2024-07-15 17:35:01 阅读 88
欢迎来到英杰社区

https://bbs.csdn.net/topics/617804998
一、背景
在数据分析和市场调研中,获取房地产数据是至关重要的一环。本文介绍了如何利用 Python 中的 requests、lxml 库以及 pandas 库,结合 XPath 解析网页信息,实现对链家网二手房销售数据的爬取,并将数据导出为 Excel 文件的过程。
二、效果图
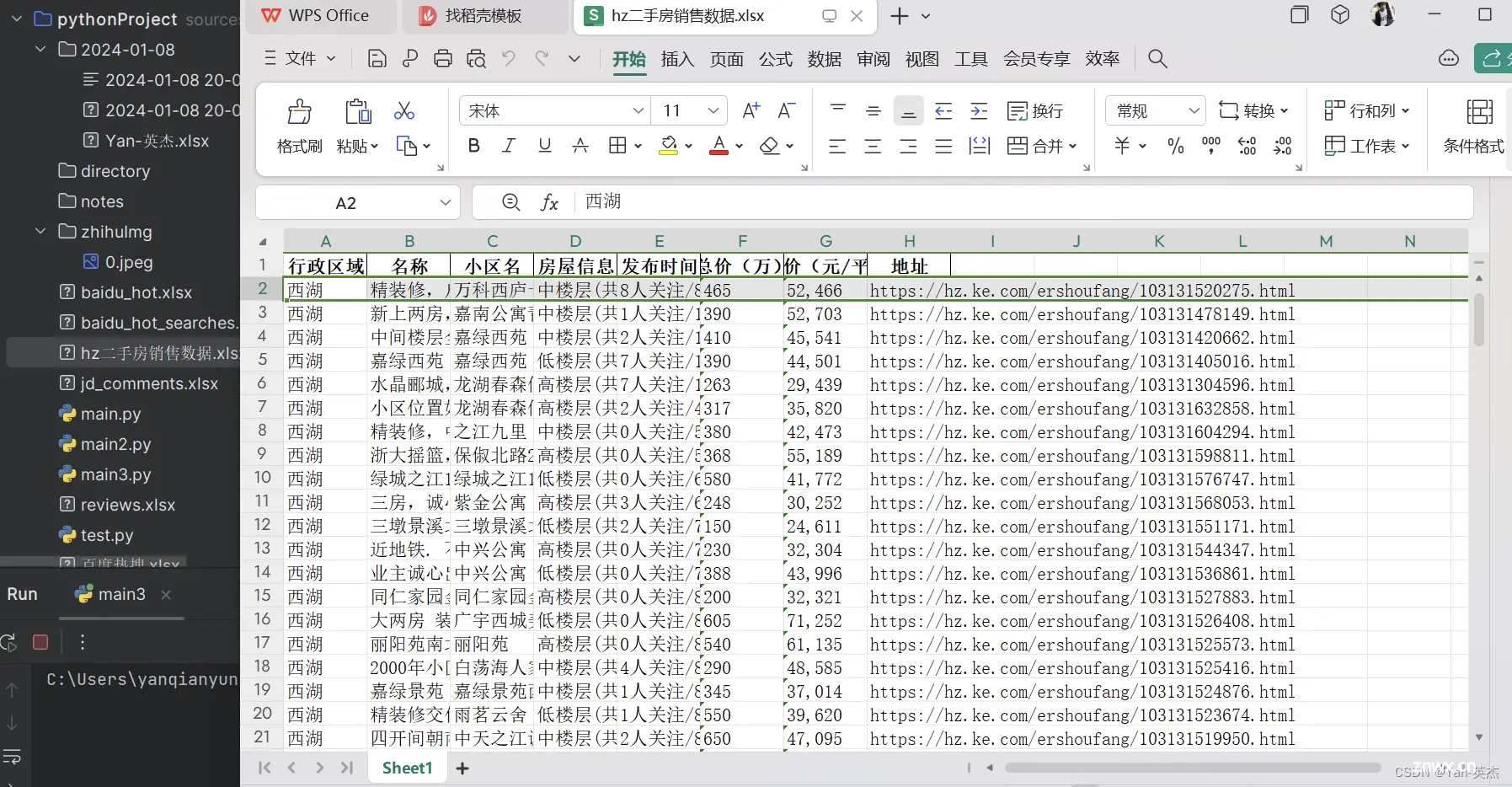
函数功能
<code>getAreasInfo(city): 该函数用于获取指定城市的各区域名称和链接信息,返回一个列表,包含区域名和链接。getSinglePageInfo(city, areaname, pathname): 该函数用于获取单页的二手房销售数据,包括房屋名称、小区名、房屋信息等,返回一个 DataFrame 对象。getSalesData(city): 该函数整合了前两个函数,遍历所有区域获取多页数据,并将结果保存为 Excel 文件。
数据保存
爬取的数据经过整理后,以 DataFrame 的形式存储,并最终通过 to_excel() 方法保存为 Excel 文件,便于后续分析和可视化展示。
三、代码讲解
import requests
from bs4 import BeautifulSoup
import pandas as pd
如果出现模块报错
进入控制台输入:建议使用国内镜像源
<code>pip install 模块名称 -i https://mirrors.aliyun.com/pypi/simple
我大致罗列了以下几种国内镜像源:
清华大学
https://pypi.tuna.tsinghua.edu.cn/simple
阿里云
https://mirrors.aliyun.com/pypi/simple/
豆瓣
https://pypi.douban.com/simple/
百度云
https://mirror.baidu.com/pypi/simple/
中科大
https://pypi.mirrors.ustc.edu.cn/simple/
华为云
https://mirrors.huaweicloud.com/repository/pypi/simple/
腾讯云
https://mirrors.cloud.tencent.com/pypi/simple/
首先,我们导入了必要的库:
import requests
from lxml import etree
import json
import pandas as pd
接下来是一些请求所需的头信息和 cookies:
cookies = {
# 这里是一些 cookie 信息
}
headers = {
# 这里是一些请求头信息
}
现在,我们定义了一个函数 getAreasInfo(city),用于获取各个区域的名称和链接:
def getAreasInfo(city):
# 发送请求,获取页面内容
# 从页面内容中提取区域名称和链接
return districts
然后是另一个函数 getSinglePageInfo(city, areaname, pathname),用于获取单页的二手房信息:
def getSinglePageInfo(city, areaname, pathname):
# 发送请求,获取页面内容
# 解析页面内容,提取所需的房屋信息
# 将提取的信息保存到 DataFrame 中
return df
接下来是主函数 getSalesData(city),用于获取整个城市的二手房销售数据并保存到 Excel 文件:
def getSalesData(city):
# 获取各区域信息
# 遍历各区域,调用 getSinglePageInfo() 函数获取数据
# 整合数据到 DataFrame 中
# 将 DataFrame 数据保存为 Excel 文件
最后,在 if __name__ == '__main__': 中,我们调用了 getSalesData('hz') 函数以执行爬取数据的操作。
四、完整代码:
import requests
from lxml import etree
import re
import json
import pandas as pd
cookies = {
'lianjia_uuid': 'd63243c2-9abd-4016-a428-7272d9bd4265',
'crosSdkDT2019DeviceId': '-5xmwrm-pv43pu-kiaob2z7e31vj11-vs7ndc7b3',
'select_city': '330100',
'digv_extends': '%7B%22utmTrackId%22%3A%22%22%7D',
'ke_uuid': 'bac7de379105ba27d257312d20f54a59',
'sensorsdata2015jssdkcross': '%7B%22distinct_id%22%3A%2218a8d4f86e46b6-0a2c26d29b1766-4f641677-2073600-18a8d4f86e5f7e%22%2C%22%24device_id%22%3A%2218a8d4f86e46b6-0a2c26d29b1766-4f641677-2073600-18a8d4f86e5f7e%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D',
'lianjia_ssid': '6734443f-a11a-49c9-989e-8c5d2dc51185',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
# 'Cookie': 'lianjia_uuid=d63243c2-9abd-4016-a428-7272d9bd4265; crosSdkDT2019DeviceId=-5xmwrm-pv43pu-kiaob2z7e31vj11-vs7ndc7b3; select_city=330100; digv_extends=%7B%22utmTrackId%22%3A%22%22%7D; ke_uuid=bac7de379105ba27d257312d20f54a59; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218a8d4f86e46b6-0a2c26d29b1766-4f641677-2073600-18a8d4f86e5f7e%22%2C%22%24device_id%22%3A%2218a8d4f86e46b6-0a2c26d29b1766-4f641677-2073600-18a8d4f86e5f7e%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; lianjia_ssid=6734443f-a11a-49c9-989e-8c5d2dc51185',
'Referer': 'https://hz.ke.com/ershoufang/pg2/',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"',code>
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
}
# 获取区的名称和路由
def getAreasInfo(city):
responseinit = requests.get(
f'https://{city}.ke.com/ershoufang', cookies=cookies, headers=headers)
html_text_init = etree.HTML(responseinit.text)
districts = [z for z in zip(html_text_init.xpath('//a[@class=" CLICKDATA"]/text()'),code>
html_text_init.xpath('//a[@class=" CLICKDATA"]/@href'))]code>
return districts
# 获取页面数据
def getSinglePageInfo(city, areaname, pathname):
response1 = requests.get(
f'https://{city}.ke.com{pathname}pg1/', cookies=cookies, headers=headers)
html_text1 = etree.HTML(response1.text)
# 获取页面总数
pageInfo = html_text1.xpath(
'//div[@class="page-box house-lst-page-box"]/@page-data')code>
# 数据较多,可以先设置2页,看看是否可以导出
# pageTotal = json.loads(pageInfo[0])['totalPage']
pageTotal = 2
title = []
position = []
house = []
follow = []
totalPrice = []
unitPrice = []
url = []
for i in range(1, pageTotal+1):
response = requests.get(
f'https://{city}.ke.com{pathname}pg{i}/', cookies=cookies, headers=headers)
html_text = etree.HTML(response.text)
ullist = html_text.xpath(
'//ul[@class="sellListContent"]//li[@class="clear"]')code>
for li in ullist:
liChildren = li.getchildren()[1]
# 名称
title.append(liChildren.xpath('./div[@class="title"]/a/text()')[0])code>
# url 地址
url.append(liChildren.xpath('./div[@class="title"]/a/@href')[0])code>
# 小区名称
position.append(liChildren.xpath(
'./div/div/div[@class="positionInfo"]/a/text()')[0])code>
# 房屋信息
houselis = liChildren.xpath(
'./div/div[@class="houseInfo"]/text()')code>
house.append([x.replace('\n', '').replace(' ', '')
for x in houselis][1])
# 上传时间
followlis = liChildren.xpath(
'./div/div[@class="followInfo"]/text()')code>
follow.append([x.replace('\n', '').replace(' ', '')
for x in followlis][1])
# 总价
totalPrice.append(liChildren.xpath(
'./div/div[@class="priceInfo"]/div[@class="totalPrice totalPrice2"]/span/text()')[0].strip())code>
# 单价
unitPrice.append(liChildren.xpath(
'./div/div[@class="priceInfo"]/div[@class="unitPrice"]/span/text()')[0].replace('元/平', ""))code>
return pd.DataFrame(dict(zip(['行政区域', '名称', '小区名', '房屋信息', '发布时间', '总价(万)', '单价(元/平)', '地址'],
[areaname, title, position, house, follow, totalPrice, unitPrice, url])))
def getSalesData(city):
districts = getAreasInfo(city)
dfInfos = pd.DataFrame()
for district in districts:
dfInfo = getSinglePageInfo(city, district[0], district[1])
dfInfos = pd.concat([dfInfos, dfInfo], axis=0)
dfInfos.to_excel(f'{city}二手房销售数据.xlsx', index=False)
if __name__ == '__main__':
getSalesData('hz')
pass
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。