【Python】详解pandas库中pd.merge函数与代码示例
CSDN 2024-07-19 10:05:02 阅读 75

😎 作者介绍:我是程序员洲洲,一个热爱写作的非著名程序员。CSDN全栈优质领域创作者、华为云博客社区云享专家、阿里云博客社区专家博主。
🤓 同时欢迎大家关注其他专栏,我将分享Web前后端开发、人工智能、机器学习、深度学习从0到1系列文章。
🌼 同时洲洲已经建立了程序员技术交流群,如果您感兴趣,可以私信我加入社群,可以直接vx联系(文末有名片)v:bdizztt
🖥 随时欢迎您跟我沟通,一起交流,一起成长、进步!点此也可获得联系方式~
本文目录
前言一、pd.merge()函数简介二、代码场景示例示例1:基于单个键的内连接示例2:基于多个键的外连接示例3:使用索引进行合并示例4:处理重复的列名
三、实战案例1、基础数据2、传入的on的参数是列表3、Merge method组合4、传入indicator参数5、index为链接键6、sort对链接的键值进行排序
注意事项总结
前言
在数据科学和分析领域,经常需要处理来自不同源的数据集,并将它们合并为一个统一的数据结构以进行进一步的分析。Pandas库中的pd.merge()函数提供了一种灵活的方式来合并两个或多个DataFrame,类似于SQL中的JOIN操作。本文将详细介绍pd.merge()函数的用法,并通过多个代码示例展示其在不同场景下的应用。
一、pd.merge()函数简介
pd.merge()函数用于根据一个或多个键将不同的数据集合并成一个DataFrame。它非常类似于SQL中的JOIN操作。
<code>pd.merge(left, right, how='inner', on=None, left_on=None, code>
right_on=None,left_index=False, right_index=False,
sort=True,suffixes=('_x', '_y'), copy=True,
indicator=False,validate=None)
参数含义说明如下:
left: 拼接的左侧DataFrame对象right: 拼接的右侧DataFrame对象on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。left_on:左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。right_on: 左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。left_index: 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 对于具有MultiIndex(分层)的DataFrame,级别数必须与右侧DataFrame中的连接键数相匹配。right_index: 与left_index功能相似。how: One of ‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。'outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。sort: 按字典顺序通过连接键对结果DataFrame进行排序。 默认为True,设置为False将在很多情况下显着提高性能。suffixes: 用于重叠列的字符串后缀元组。 默认为(‘x’,’ y’)。copy: 始终从传递的DataFrame对象复制数据(默认为True),即使不需要重建索引也是如此。indicator:将一列添加到名为_merge的输出DataFrame,其中包含有关每行源的信息。 _merge是分类类型,并且对于其合并键仅出现在“左”DataFrame中的观察值,取得值为left_only,对于其合并键仅出现在“右”DataFrame中的观察值为right_only,并且如果在两者中都找到观察点的合并键,则为left_only。
二、代码场景示例
示例1:基于单个键的内连接
假设有两个DataFrame,df1和df2,它们有一个共同的列’key’:
import pandas as pd
# 创建两个示例DataFrame
df1 = pd.DataFrame({ 'key': ['A', 'B', 'C'], 'value': [1, 2, 3]})
df2 = pd.DataFrame({ 'key': ['A', 'B', 'D'], 'value2': [4, 5, 6]})
# 使用'key'列进行合并
result = pd.merge(df1, df2, on='key')code>
print(result)
示例2:基于多个键的外连接
使用left_on和right_on参数基于多个列进行合并:
# 扩展示例DataFrame
df1 = pd.DataFrame({ 'key1': ['K0', 'K1', 'K2'], 'key2': ['K0', 'K1', 'K2'], 'value': [1, 2, 3]})
df2 = pd.DataFrame({ 'key1': ['K0', 'K1', 'K1'], 'key2': ['K0', 'K0', 'K0'], 'value2': [4, 5, 6]})
# 使用how='outer'进行外连接code>
result = pd.merge(df1, df2, how='outer', left_on=['key1', 'key2'], right_on=['key1', 'key2'])code>
print(result)
示例3:使用索引进行合并
使用DataFrame的索引作为合并键:
# 假设df1和df2的索引可以用于合并
df1 = pd.DataFrame({ 'value': [1, 2, 3]}, index=['A', 'B', 'C'])
df2 = pd.DataFrame({ 'value2': [4, 5, 6]}, index=['A', 'B', 'D'])
# 使用索引进行合并
result = pd.merge(df1, df2, left_index=True, right_index=True)
print(result)
示例4:处理重复的列名
当两个DataFrame有重复的列名但不是合并键时,可以使用suffixes参数:
df1 = pd.DataFrame({ 'value': [1, 2, 3], 'key': ['A', 'B', 'C']})
df2 = pd.DataFrame({ 'value2': [4, 5, 6], 'key': ['A', 'B', 'D']})
# 使用suffixes区分重复的列名
result = pd.merge(df1, df2, on='key', suffixes=('_left', '_right'))code>
print(result)
三、实战案例
1、基础数据
import pandas as pd
left = pd.DataFrame({ 'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({ 'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on='key')code>
# on参数传递的key作为连接键
result
Out[4]:
A B key C D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K2 C2 D2
3 A3 B3 K3 C3 D3
2、传入的on的参数是列表
left = pd.DataFrame({ 'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({ 'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.merge(left, right, on=['key1', 'key2'])
# 同时传入两个Key,此时会进行以['key1','key2']列表的形式进行对应,left的keys列表是:[['K0', 'K0'],['K0', 'K1'],['K1', 'K0'],['K2', 'K1']],
left的keys列表是:[['K0', 'K0'],['K1', 'K0'],['K1', 'K0'],['K2', 'K0']],因此会有1个['K0', 'K0']、2个['K1', 'K0']对应。
result
Out[6]:
A B key1 key2 C D
0 A0 B0 K0 K0 C0 D0
1 A2 B2 K1 K0 C1 D1
2 A2 B2 K1 K0 C2 D2
3、Merge method组合
需要注意:如果组合键没有出现在左表或右表中,则连接表中的值将为NA。
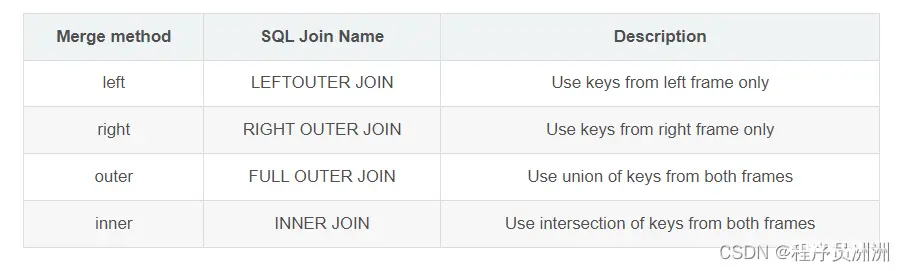
<code>result = pd.merge(left, right, how='left', on=['key1', 'key2'])code>
# Use keys from left frame only
result
Out[34]:
A B key1 key2 C D
0 A0 B0 K0 K0 C0 D0
1 A1 B1 K0 K1 NaN NaN
2 A2 B2 K1 K0 C1 D1
3 A2 B2 K1 K0 C2 D2
4 A3 B3 K2 K1 NaN NaN
result = pd.merge(left, right, how='right', on=['key1', 'key2'])code>
# Use keys from right frame only
result
Out[36]:
A B key1 key2 C D
0 A0 B0 K0 K0 C0 D0
1 A2 B2 K1 K0 C1 D1
2 A2 B2 K1 K0 C2 D2
3 NaN NaN K2 K0 C3 D3
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])code>
# Use intersection of keys from both frames
result
Out[38]:
A B key1 key2 C D
0 A0 B0 K0 K0 C0 D0
1 A1 B1 K0 K1 NaN NaN
2 A2 B2 K1 K0 C1 D1
3 A2 B2 K1 K0 C2 D2
4 A3 B3 K2 K1 NaN NaN
5 NaN NaN K2 K0 C3 D3
-----------------------------------------------------
left = pd.DataFrame({ 'A' : [1,2], 'B' : [2, 2]})
right = pd.DataFrame({ 'A' : [4,5,6], 'B': [2,2,2]})
result = pd.merge(left, right, on='B', how='outer')code>
result
Out[40]:
A_x B A_y
0 1 2 4
1 1 2 5
2 1 2 6
3 2 2 4
4 2 2 5
5 2 2 6
4、传入indicator参数
merge接受参数指示符。 如果为True,则将名为_merge的Categorical类型列添加到具有值的输出对象:

<code>df1 = pd.DataFrame({ 'col1': [0, 1], 'col_left':['a', 'b']})
df2 = pd.DataFrame({ 'col1': [1, 2, 2],'col_right':[2, 2, 2]})
pd.merge(df1, df2, on='col1', how='outer', indicator=True)code>
Out[44]:
col1 col_left col_right _merge
0 0.0 a NaN left_only
1 1.0 b 2.0 both
2 2.0 NaN 2.0 right_only
3 2.0 NaN 2.0 right_only
指标参数也将接受字符串参数,在这种情况下,指标函数将使用传递的字符串的值作为指标列的名称。
pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column')code>
Out[45]:
col1 col_left col_right indicator_column
0 0.0 a NaN left_only
1 1.0 b 2.0 both
2 2.0 NaN 2.0 right_only
3 2.0 NaN 2.0 right_only
5、index为链接键
需要同时设置left_index= True 和 right_index= True,或者left_index设置的同时,right_on指定某个Key。总的来说就是需要指定left、right链接的键,可以同时是key、index或者混合使用。
left = pd.DataFrame({ 'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=['K0', 'K1', 'K2'])
....:
right = pd.DataFrame({ 'C': ['C0', 'C2', 'C3'],
....: 'D': ['D0', 'D2', 'D3']},
....: index=['K0', 'K2', 'K3'])
....:
# 只有K0、K2有对应的值
pd.merge(left,right,how= 'inner',left_index=True,right_index=True)
Out[51]:
A B C D
K0 A0 B0 C0 D0
K2 A2 B2 C2 D2
left = pd.DataFrame({ 'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'key': ['K0', 'K1', 'K0', 'K1']})
right = pd.DataFrame({ 'C': ['C0', 'C1'],
'D': ['D0', 'D1']},
index=['K0', 'K1'])
result = pd.merge(left, right, left_on='key', right_index=True, how='left', sort=False)code>
# left_on='key', right_index=Truecode>
result
Out[54]:
A B key C D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K0 C0 D0
3 A3 B3 K1 C1 D1
6、sort对链接的键值进行排序
紧接着上一例,设置sort= True
result = pd.merge(left, right, left_on='key', right_index=True, how='left', sort=True)code>
result
Out[57]:
A B key C D
0 A0 B0 K0 C0 D0
2 A2 B2 K0 C0 D0
1 A1 B1 K1 C1 D1
3 A3 B3 K1 C1 D1
注意事项
合并方式:根据数据的需求选择合适的合并方式(‘inner’, ‘outer’, ‘left’, ‘right’)。
数据一致性:确保合并键的数据类型在两个DataFrame中是一致的。
索引使用:如果使用索引作为合并键,确保索引是有意义的,且在两个DataFrame中都是唯一的。
性能问题:对于大型DataFrame,合并操作可能会消耗较多资源,考虑优化数据或使用数据库处理。
重复列名:使用suffixes参数来区分合并后重复的列名。
总结
📝Hello,各位看官老爷们好,我已经建立了CSDN技术交流群,如果你很感兴趣,可以私信我加入我的社群。
📝社群中不定时会有很多活动,例如每周都会包邮免费送一些技术书籍及精美礼品、学习资料分享、大厂面经分享、技术讨论谈等等。
📝社群方向很多,相关领域有Web全栈(前后端)、人工智能、机器学习、自媒体副业交流、前沿科技文章分享、论文精读等等。
📝不管你是多新手的小白,都欢迎你加入社群中讨论、聊天、分享,加速助力你成为下一个大佬!
📝想都是问题,做都是答案!行动起来吧!欢迎评论区or后台与我沟通交流,也欢迎您点击下方的链接直接加入到我的交流社群!~ 跳转链接社区~

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。