国内外大模型生态发展报告!
cnblogs 2024-06-23 08:09:13 阅读 66
很多同学只知类似Check GPT或者说对国内的一些比较了解,对国外的不太了解,所以在这总结。
1 大模型的发展
左表
| 名称 | 参数 | 特点 | 发布时间 |
|---|---|---|---|
| GPT-2 | 15亿 | 英文底模,开源 | 2019年 |
| Google T5 | 110亿 | 多任务微调, 开源 | 2019年 |
| GPT-3.5 | 1750亿 | 人工反馈微调 | 2022年 |
| Meta OPT | 1750亿 | 英文底模, 开源 | 2022年 |
| LLaMA | 70亿~650亿 | 最受欢迎的开源模型之一 | 2023年 |
| GPT-4 | 1.8万亿 | 史上最强大模型 | 2023年 |
| Vicuna-13B | 130亿 | 开源聊天机器人 | 2023年 |
| Falcon | 400亿 | 阿联酋先进技术研究委员会 | 2023年 |
| Claude 1.3 | 未公开 | Anthropic研发,注重安全和可靠性 | 2023年 |
| PaLM 2 | 未公开 | Google最新大模型 | 2023年 |
| Mistral | 7B, 13B | 强调性能和效率 | 2023年 |
| GPT-4-turbo | 未公开 | OpenAI更高效版本 | 2023年 |
| Claude 2 | 未公开 | 改进的上下文理解和任务执行能力 | 2023年 |
| LLaMA 2 | 70亿, 130亿, 700亿 | Meta开源的改进版本,商用更自由 | 2023年 |
| Gemini | 未公开 | Google的多模态AI模型 | 2023年 |
| Claude 3 | 未公开 | Anthropic的最新版本,包括Opus、Sonnet和Haiku | 2024年 |
| GPT-4o | 未公开 | OpenAI的GPT-4升级版 | 2024年 |
| Gemini Pro | 未公开 | Google Gemini的升级版 | 2024年 |
右表
| 名称 | 参数 | 特点 | 发布时间 |
|---|---|---|---|
| 百川智能 | 70亿 | 王小川, 开源 | 2023年 |
| 文心一言 | 2600亿 | 中文语料85% | 2023年 |
| 通义千问 | 70亿~700亿 | 总体相当GPT-3 | 2023年 |
| ChatGLM6B | 60亿 | 10B以下最强中文开源 | 2023年 |
| 腾讯混元 | 超千亿 | 腾讯出品多模态 | 2023年 |
| MOSS | 160亿 | 多插件, 开源 | 2023年 |
| Aquila | 70亿~330亿 | 首个中文数据合规 | 2023年 |
| PolyLM | 130亿 | 对亚洲语言友好 | 2023年 |
| 讯飞星火 | 未公开 | 科大讯飞出品,多模态 | 2023年 |
| ChatGLM2-6B | 60亿 | ChatGLM升级版,更强性能 | 2023年 |
| 天工 | 未公开 | 昆仑万维与奇点智源合作 | 2023年 |
| 360智脑 | 未公开 | 360公司出品 | 2023年 |
| MiniMax | 未公开 | 前百度高管创立 | 2023年 |
| ChatGLM3 | 60亿,130亿 | 更强的多轮对话能力 | 2024年 |
| 文心一言4.0 | 未公开 | 百度升级版,多模态增强 | 2024年 |
| 通义千问2.0 | 未公开 | 阿里云升级版 | 2024年 |
| 腾讯混元2.0 | 未公开 | 腾讯升级版 | 2024年 |
Google T5 -> GPT-3 -> GLM130B -> LLaMa -> GPT-4 -> Falcon -> GPT-4v
发展角度,LLM最早基本在2017年左右,其实最早所有的LLM都是基于谷歌的Transformer架构设计。2017年谷歌发布它的T5模型,后续不断有新的这样LLM衍生出来。包括GPT-2、GPT-3、GLM-130B以Facebook为代表的这个开源的LaMa,还有后来GPT-4及中东的科研机构开发的这个FanCL及最新GPT4,包括多模态模型。
更多 LLM 官网,请访问编程严选网-导航:
2 国外与国内大模型
表格左边主要是国外的一些常见LLM,右边是国内厂商。
发布时间看,海外比我们要早些,能够叫得上的或用的比较多的都是在2023年才开始发布。
3 参数与模型能力
先看国外的,第一个GPT-2大概15亿的参数。
参数是啥?
LLM的所谓参数,代表一个模型的复杂程度,参数越大,也就说它需要的容量空间,它需要的算力也就越大,那相应的能力就越强。
参数越小,它需要的算力就越小,能力相对较弱,能力强弱,主要通过它的回答或提炼问题的能力,就能看出来。
谷歌T5大概有110亿的参数,特点就是它可以实现多任务的一个微调,它是开源的。GPT主要是OpenAI的,GPT-3.5出来后,市面震惊,因为它的效果非常好,但是我们可以看到它的参数也是非常可怕,达到1750亿。所以说它的需要的算力非常多,它就能支持人工反馈的微调。
随后就是Meta公司即Facebook,就它也出品了,它的模型大概1750亿,底模是英文的。
底模是啥?
大模型预训练时,有个预训练过程,需要大量语料,如大量用英文材料,那底模就是英文,那它在它基础上做英文的一些问题回答,效果较好。
LLaMA也叫羊驼,https://www.alpacaml.com/:
目前比较主流的一个开源模型,目前开源里参数较大,效果较好的,最受欢迎的开源LLM之一。 GPT4最新出,但它最新的参数没变化,但底模数量会较大。GPT-4我们看到它的参数达到1.8万亿,号称史上最强。
比如说GPT的底模里有中文语料,所以它足够大,涵盖基本所有互联网知识,GPT-3.5截止2021年之前互联网知识,4把知识库呢更新到2023年。所以它涵盖的语言种类比较多。
再看右边国内的。
首先百川智能,王小川搞的,参数70亿,相当于羊驼水平。
百度文心一言就相对比较大,百度搞AI投入还是比较大的,参数2600亿,中文语料占到85%。
阿里通义千问参数在70~700亿之间,总体能力相当于GPT-3,国内还是稍差。
GLM-6B大概60亿的参数,清华大学的团队。目前国内或国际100亿以下最强中文开源模型,100亿参数窗口之下效果最好的目前是它,真的不错。
腾讯混元,具体参数没公布,大概超千亿,支持多模态。
多模态啥意思?
不光有文字文本生成,还有图像生成,文到图图到文啊等等就是各种模态支持。它的底模或者它的预训练更复杂,不光可能训练文字,还训练图片,支持多插件的开源模型。
基本上各有特点,但国内有两大特点:
- 时间稍晚,基本到2023年发布
- 中文支持相对的都比海外的这些模型好很多
商用角度,开源模型其实不太理想,LaMa不支持商用,但GLM都可商用,包括百川、FanCL都可商用。
4 大模型的生态
百模大战,千模大战多模型大战,就是由OpenAI引爆。
Hugging Face,抱脸,相当于AI界GitHub。很多开源模型可以找到:
可见整个LLM发展生态繁荣。
5 清华团队在PupilFace的主页
ChatGLM就是清华团队的,他们在PupilFace上面的一个主页。我们可以看到他们的作品。
已创建的LMs(Large Models,大型模型),LLM像ChatGLM、WebGLM 130B等,还有一些相应工具,包括预训练的这些图训练的神经网络。https://huggingface.co/THUDM/chatglm3-6b:
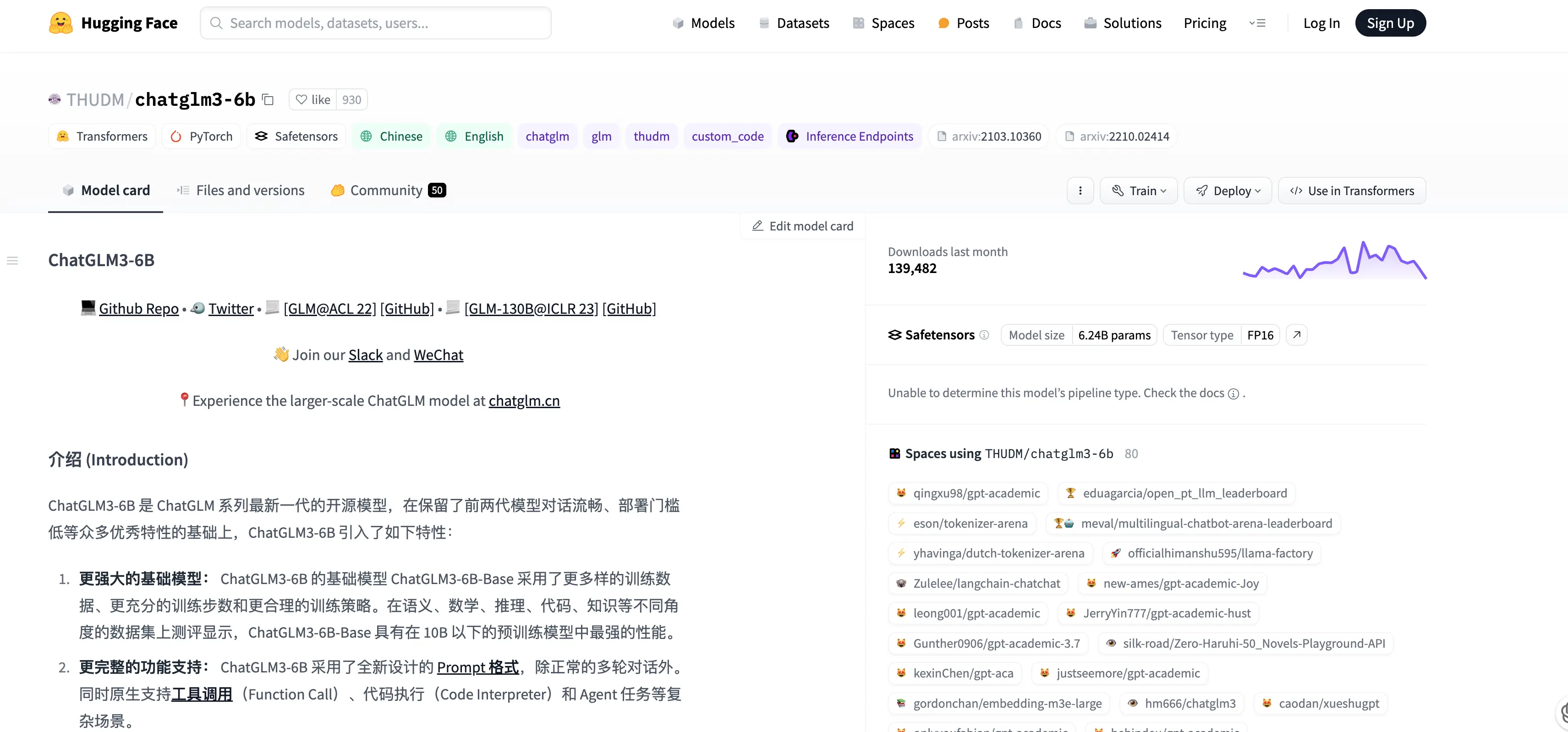
可以看到它的6B(6 billion,60亿参数),32K(可能指模型的某种配置或版本),然后包括7B(7 billion,70亿参数),13B(13 billion,130亿参数)。最强130B(130 billion,1300亿参数)。
整个大模型确实非常多,每个模型都有自己的特色。
6 商用许可
| 大模型名称 | 参数 | 是否可商用 |
|---|---|---|
| ChatGLM | 6B, 1T | 可商用 |
| ChatGLM2 | 6B, 1T | 可商用 |
| LLaMA | 7B, 13B, 33B, 65B, 1T | 不可商用 |
| LLaMA2 | 7B, 13B, 33B, 65B, 2T | 可商用 |
| BLOOM | 1B7, 7B1, 176B-MT, 1.5T | 可商用 |
| Baichuan | 7B, 13B, 1.2T, 1.4T | 可商用 |
| Falcon | 7B, 40B, 1.5T | 可商用 |
| Qwen | 7B, 7B-Chat, 2.2T | 可商用 |
| Aquila | 7B, 7B-Chat | 可商用 |
| Mistral | 7B, 13B | 可商用 |
| Gemma | 2B, 7B | 可商用 |
| Claude | 未公开 | 不可商用 |
| GPT-4 | 未公开 | 不可商用 |
| PaLM 2 | 未公开 | 不可商用 |
| Gemini | 未公开 | 不可商用 |
| BERT | 110M, 340M | 可商用 |
| RoBERTa | 125M, 355M | 可商用 |
| T5 | 60M, 220M, 770M, 3B, 11B | 可商用 |
| Gopher | 280B | 不可商用 |
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都技术专家,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&优惠券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
- LLM应用开发
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
- 编程严选网
本文由博客一文多发平台 OpenWrite 发布!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。