带你一文搞懂CNN以及图像识别(Python)
JOYCE_Leo16 2024-06-16 15:05:02 阅读 74
文章目录
一、卷积神经网络简介
二、卷积神经网络的“卷积”
1. 卷积运算的原理
2. 卷积运算的作用
三、卷积神经网络
1. 卷积层(CONV)
2. 池化层(Pooling)
3. 全连接层(FC)
4. 示例:经典CNN的构建(Lenet-5)
四、CNN图像分类-keras
一、卷积神经网络简介
卷积神经网络(Convolution Neural Networks,CNN)是一类包含卷积计算的前馈神经网络,是基于图像任务的平移不变性(图像识别的对象在不同位置有相同的含义)设计的,擅长应用于图像处理等任务。在图像处理中,图像数据具有非常高的维数(高维的RGB矩阵表示),因此训练一个标准的前馈网络来识别图像将需要成千上万的输入神经元,除了显而易见的高计算量,还可能导致许多与神经网络中的维数灾难相关的问题。

对于高维图像数据,卷积神经网络利用了卷积核池化层,能够高效提取图像的重要“特征”,再通过后面的全连接层处理“压缩的图像信息”及输出结果。对比标准的全连接网络,卷积神经网络的模型参数大大减少了。
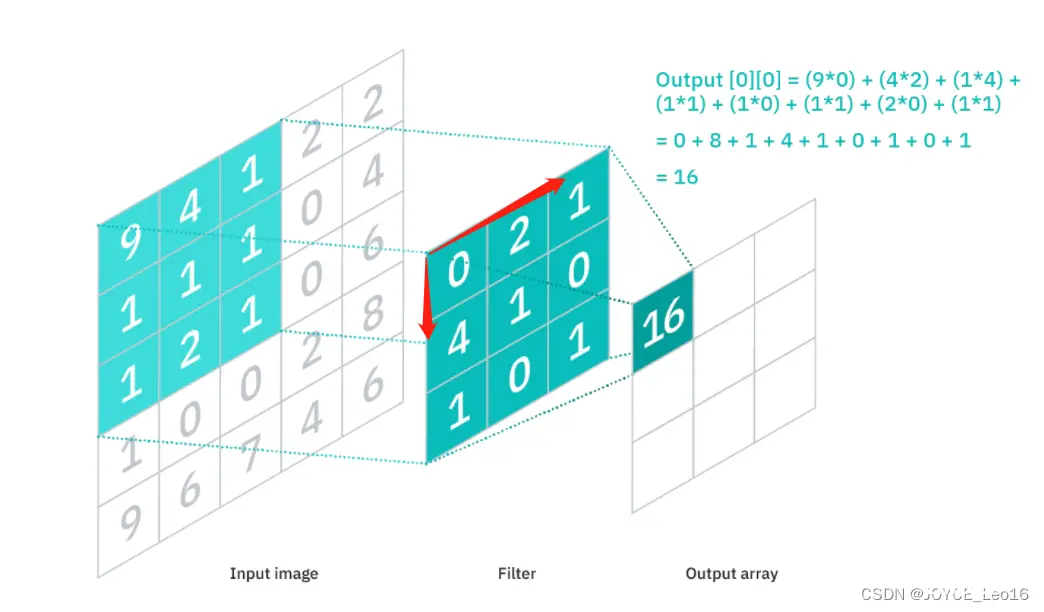
二、卷积神经网络的“卷积”
1. 卷积运算的原理
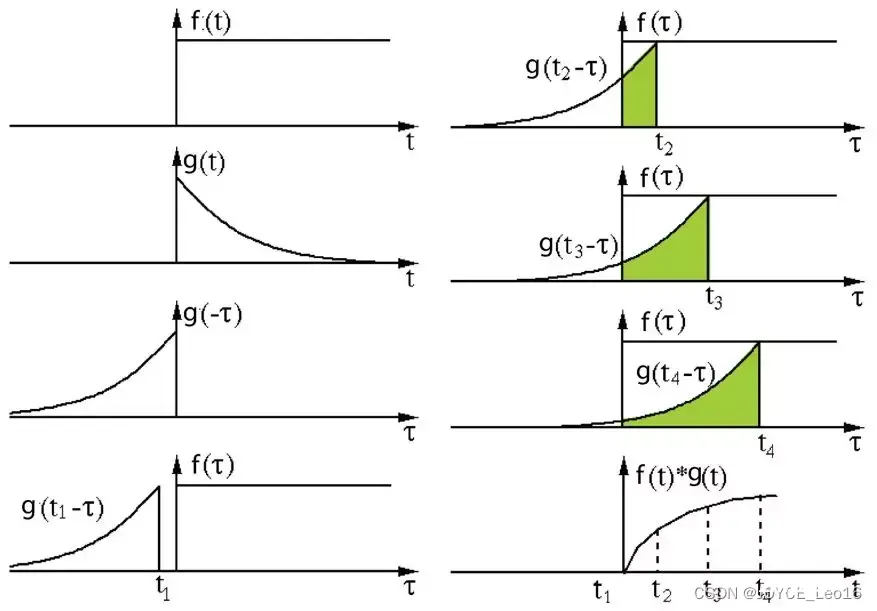
在信号处理、图像处理和其他工程/科学领域,卷积都是一种使用广泛的技术,卷积神经网络(CNN)这种模型架构就得名于卷积计算。但是,深度学习领域的“卷积”本质上是信号/图像处理领域内的互相关(cross-correlation),互相关与卷积实际上还是有些差异的。卷积是分析数学中一种重要的运算。简单定义f,g是可积分的函数,两者的卷积运算如下:
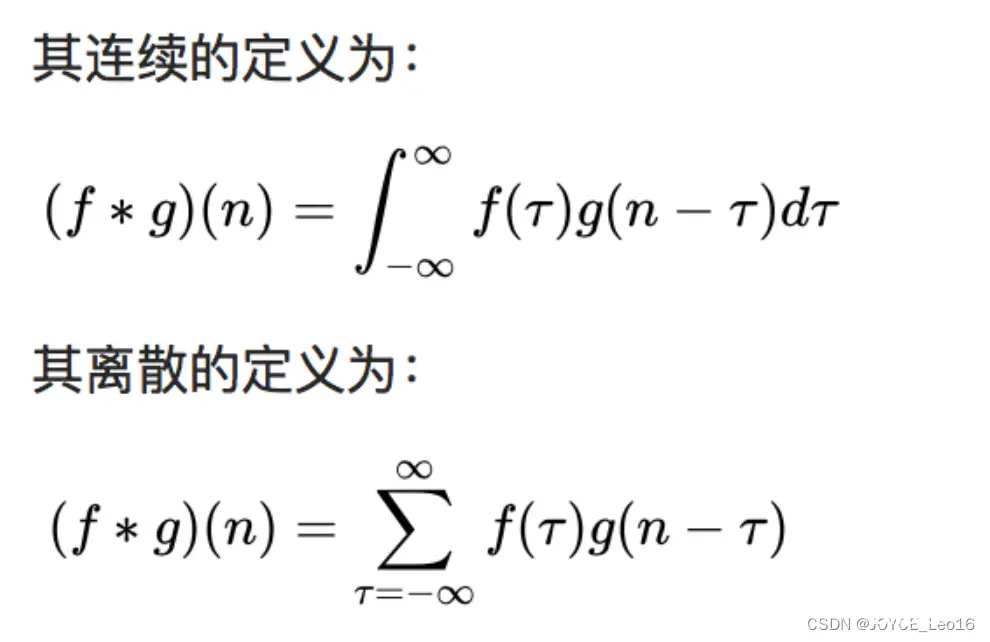
其定义是两个函数中一个函数(g)经过反转和位移后再相乘得到的积的积分。如下图,函数g是过滤器,它被反转后再沿水平轴滑动。在每一个位置,我们都计算 f 和反转后的 g 之间相交区域的面积。这个相交区域的面积就是特定位置处的卷积值。

互相关是两个函数之间的滑动点积或滑动内积。互相关中的过滤器不经过发转,而是直接滑过函数f,f与 g之间的交叉区域即是互相关。
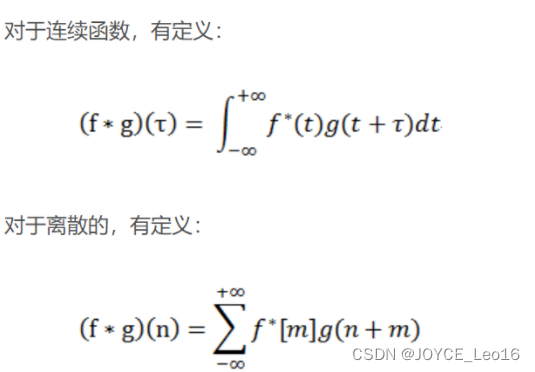
下图展示了卷积与互相关运算过程,相交区域的面积变化的差异:
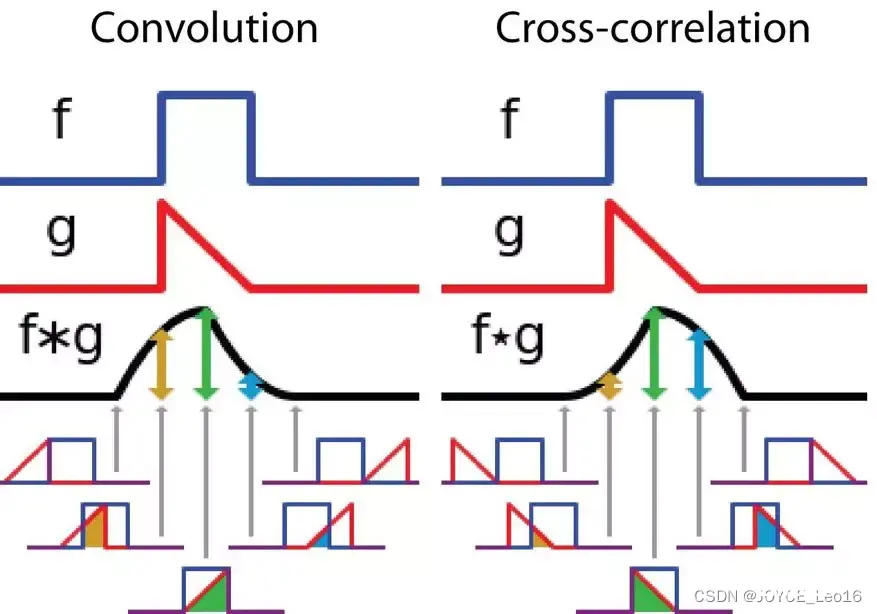
在卷积神经网络中,卷积中的过滤器不经过反转。严格来说,这是离散形式的互相关运算,本质上是执行逐元素乘法和求和。但两者的效果是一致的,因为过滤器的权重参数是在训练阶段学习到的,经过训练后,学习得到的过滤器看起来就会像是反转后的函数。
2. 卷积运算的作用
CNN通过设计的卷积核(convolution filter,也称为kernel)与图片做卷积运算(平移卷积核去逐步做乘积并求和)。

如下示例设计一个(特定参数)的3x3的卷积核:
让它去跟图片做卷积,卷积的具体过程是:
用这个卷积核去覆盖原始图片;覆盖一块跟卷积核一样大的区域之后,对应元素相乘,然后求和;计算一个区域之后,就向其他区域挪动(假设步长是1),继续计算;直到把原图片的每一个角落都覆盖到为止。
可以发现,通过特定的filter,让它去跟图片做卷积,就可以提取出图片中的某些特征,比如边界特征。
进一步的,我们可以借助庞大的数据,足够深的神经网络,使用反向传播算法让机器去自动学习这些卷积核参数,不同卷积核提取特征也是不一样的,就能够提取出局部的、更深层次和更全局的特征以应用于决策。
卷积运算的本质性总结:过滤器(g)对图片(f)执行逐步的乘法并求和,以提取特征的过程。卷积过程的可视化可访问:CNN Explainer或者GitHub - vdumoulin/conv_arithmetic: A technical report on convolution arithmetic in the context of deep learning
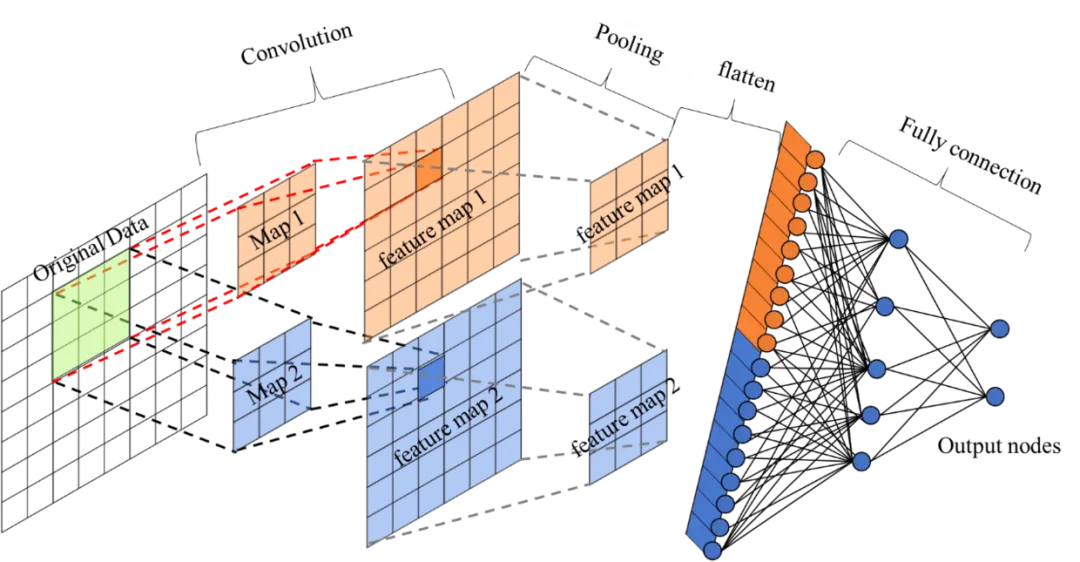
三、卷积神经网络
卷积神经网络通常由3个部分构成:卷积层,池化层,全连接层。简单来说,卷积层负责提取图像中的局部及全局特征;池化层用来大幅降低参数量级(降维);全连接层用来处理“压缩的图像信息”并输出结果。
1. 卷积层(CONV)
(1)卷积层基本属性
卷积层主要功能是动态地提取图像特征,由滤波器filters和激活函数构成。一般要设置的超参数包括filters的数量、大小、步长,激活函数类型,以及padding是“valid”还是“same”。
卷积核大小(Kernel):直观理解就是一个滤波矩阵,普遍使用的卷积核大小是3x3、5x5等。在达到相同感受野的情况下,卷积核越小,所需要的参数和计算量越小。卷积核大小必须大于1才有提升感受野的作用,而大小为偶数的卷积核即使对称地加padding也不能保证输入feature map尺寸和输出feature map尺寸不变(假设 n 为输入宽度,d 为padding个数,m 为卷积核宽度,在步长为1的情况下,如果保持输出的宽度仍为 n,公式n+2d-m+1=n,得出m=2d+1,需要是奇数),所以一般都用3作为卷积核大小。卷积核数据:主要还是根据实际情况调整,一般都取2的整数次方,数目越多计算量越大,相应模型拟合能力越强。步长(Stride):卷积核遍历特征图时每步移动的像素,如步长为1则每次移动1个像素,步长为2则每次移动2个像素(即跳过1个像素),以此类推。步长越小,提取的也在会更精细。填充(Padding):处理特征图边界的方式,一般有两种,一种是“Valid”,对边界外完全不填充,只对输入像素执行卷积操作,这样会使输出特征图像尺寸变得更小,且边缘信息容易丢失;另一种是“same”,对边界外进行填充(一般填充为0),再次执行卷积操作,这样可使输出特征图的尺寸与输入特征图的尺寸一致,边缘信息也可以多次计算。通道(Channel):卷积层的通道数(层数),如彩色图像一般都是RGB三个通道(channel)。激活函数:主要还是根据实际验证,通常选择Relu。
另外的,卷积的类型除了标准卷积,还演变出了反卷积、可分离卷积、分组卷积等各种类型,可以自行验证。
(2)卷积层的特点
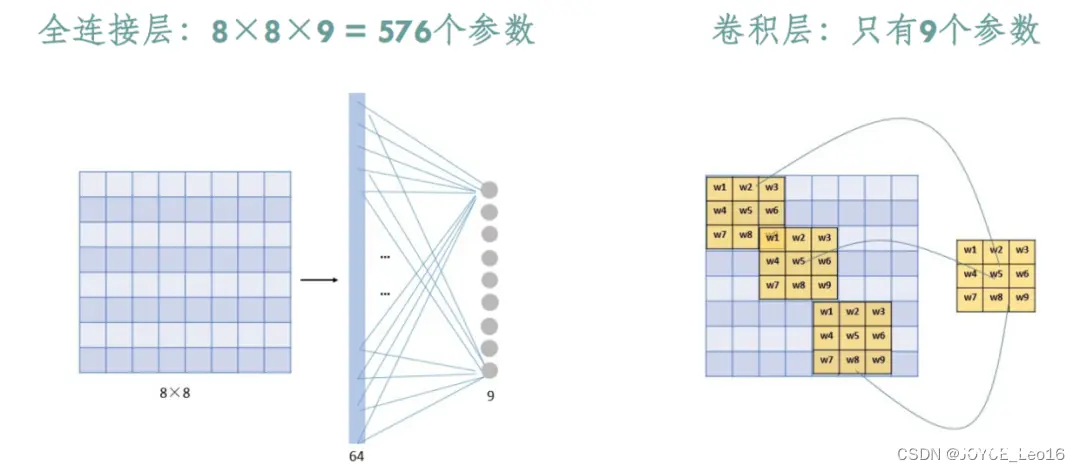
通过卷积运算的介绍,可以发现卷积层有两个主要特点:局部连接(稀疏连接)和权值共享。
局部连接:就是卷积层的节点仅仅和其前一层的部分节点相连接,只用来学习局部区域特征。(局部连接感知结构的理念来源于动物视觉的皮层结构,其指的是动物视觉的神经元在感知外界物体的过程中起作用的只有一部分神经元)。权值共享:同一卷积核会和输入图片的不同区域作卷积,来检测相同的特征,卷积核上面的权重参数是空间共享的,使得参数量大大减少。

由于局部连接(稀疏连接)和权值共享的特点,使得CNN具有仿射的不变性(平移、缩放等线性变换)。
2. 池化层(Pooling)
池化层可对提取到的特征信息进行降维,一方面使特征图变小,简化网络计算复杂度;另一方面进行特征压缩,提取主要特征,增加平移不变性,减少过拟合风险。但其实池化更多程度上是一种计算性能的一个妥协,强硬地压缩特征的同时也损失了一部分信息,所以现在的网络比较少用池化层或者使用优化后的如SoftPool。
池化层设定的超参数,包括池化层的类型是Max还是Average(Average对背景保留更好,Max对纹理提取更好),窗口大小以及步长等。如下的MaxPooling,采用了一个2x2的窗口,并取步长stride=2,提取出各个窗口的max值特征(Average Pooling就是平均值)。
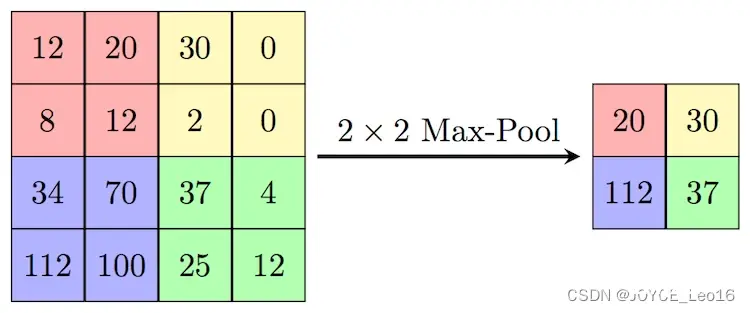
3. 全连接层(FC)
在经过数次卷积和池化后,我们最后会先将多维的图像数据进行压缩“扁平化”,也就是把[height, width, channel]的数据压缩成长度为height x width x channel的一维数组,然后再与全连接层连接(这也就是传统全连接网络层,每一个单元都和前一层的每一个单元相连接,需要设定的超参数主要是神经元的数量,以及激活函数类型),通过全连接层处理“压缩的图像信息”并输出结果。
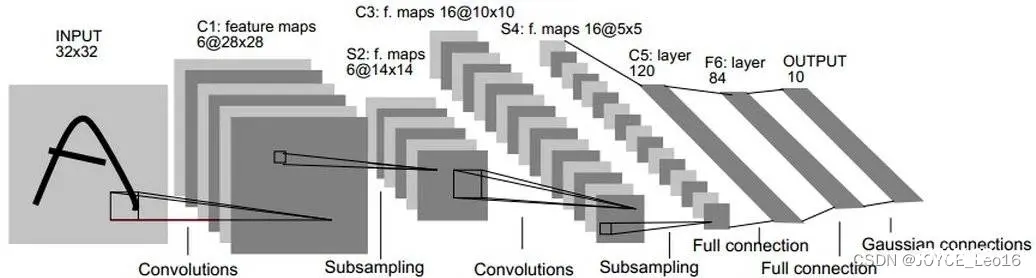
4. 示例:经典CNN的构建(Lenet-5)
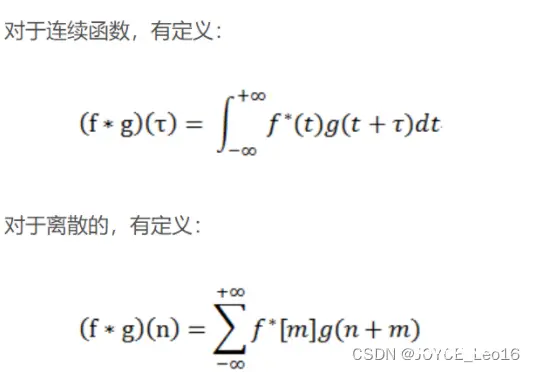
LeNet-5 是由Yann LeCun设计于1998年,是最早的卷积神经网络之一。它是针对灰度图进行训练的,输入图像大小为32321,不包含输入层的情况下共有7层。下面逐层介绍LeNet-5结构:
(1)C1-卷积层
第一层是卷积层,用于过滤噪音,提取关键特征。使用5*5大小的过滤器6个,步长s=1,padding=0。
(2)S2-采样层(平均池化层)
第二层是平均池化层,利用了图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量通四海保留有用信息,降低网络训练参数及模型的过拟合程度。使用2*2大小的过滤器,步长s=2,padding=0。池化层只有一组超参数pool_size和步长strides,没有需要学习的模型参数。
(3)C3-卷积层
第三层使用5*5大小的过滤器16个,步长s=1,padding=0。
(4)S4-下采样层(平均池化层)
第四层使用2*2大小的过滤器,步长s=2,padding=0。没有需要学习的参数。
(5)C5-卷积层
第五层是卷积层,有120个5*5的单元,步长s=1,padding=0。
(6)F6-全连接层
有84个单元。每个单元与F5层的全部120个单元之间进行全连接。
(7)Output-输出层
Output层也是全连接层,采用RFB网络的连接方式(现在主要由Softmax取代,如下示例代码),共有10个节点,分别代表数字0到9(因为Lenet用于输出识别数字的),如果节点 i 的输出值为0,则网络识别的结果是数字 i。
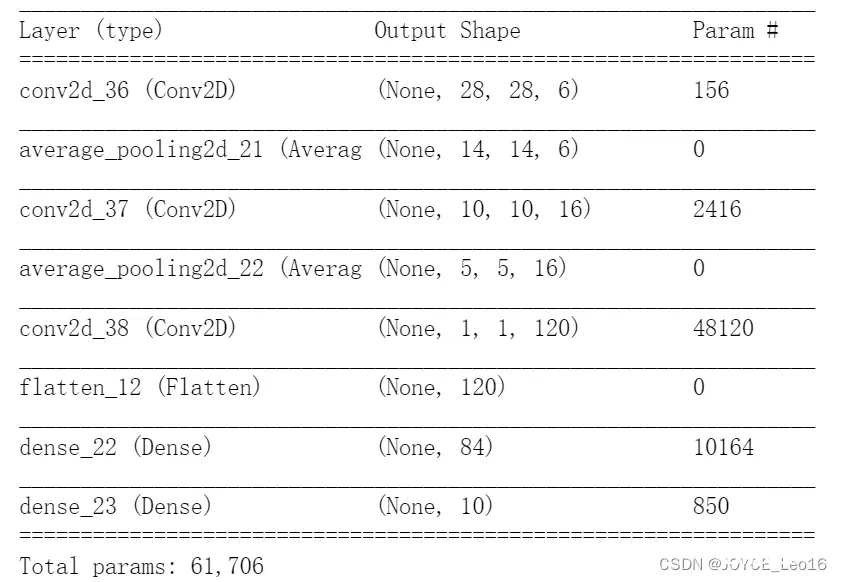
如下Keras复现Lenet-5:

from keras.models import Sequentialfrom keras import layers le_model = keras.Sequential()le_model.add(layers.Conv2D(6, kernel_size=(5, 5), strides=(1, 1), activation='tanh', input_shape=(32,32,1), padding="valid"))le_model.add(layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'))le_model.add(layers.Conv2D(16, kernel_size=(5, 5), strides=(1, 1), activation='tanh', padding='valid'))le_model.add(layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2), padding='valid'))le_model.add(layers.Conv2D(120, kernel_size=(5, 5), strides=(1, 1), activation='tanh', padding='valid'))le_model.add(layers.Flatten())le_model.add(layers.Dense(84, activation='tanh'))le_model.add(layers.Dense(10, activation='softmax'))
四、CNN图像分类-keras
(以keras实现经典的CIFAR10图像数据集的分类为例,代码:https://github.com/aialgorithm/Blog)
训练集输入数据的样式为:(50000, 32, 32, 3)对应 (样本数, 图像高度, 宽度, RGB彩色图像通道为3)
from keras.datasets import cifar10from keras.preprocessing.image import ImageDataGeneratorfrom keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activation, Flattenfrom keras.layers import Conv2D, MaxPooling2Dimport kerasimport os# 数据,切分为训练和测试集(x_train, y_train), (x_test, y_test) = cifar10.load_data()print('x_train shape:', x_train.shape)print(x_train.shape[0], 'train samples')print(x_test.shape[0], 'test samples')
展示数据集,共有10类图像:
# 展示数据集import matplotlib.pyplot as pltclass_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']plt.figure(figsize=(10,10))for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(x_train[i]) # The CIFAR labels happen to be arrays, # which is why you need the extra index plt.xlabel(class_names[y_train[i][0]])plt.show()

数据及标签预处理
# 将标签向量转换为二值矩阵。num_classes = 10 #图像数据有10个实际标签类别y_train = keras.utils.to_categorical(y_train, num_classes)y_test = keras.utils.to_categorical(y_test, num_classes)print(y_train.shape, 'ytrain')# 图像数据归一化x_train = x_train.astype('float32')x_test = x_test.astype('float32')x_train /= 255x_test /= 255 构造卷积神经网络:输入层→多组卷积及池化层→全连接网络→softmax多分类输出层。(如下图部分网络结构)
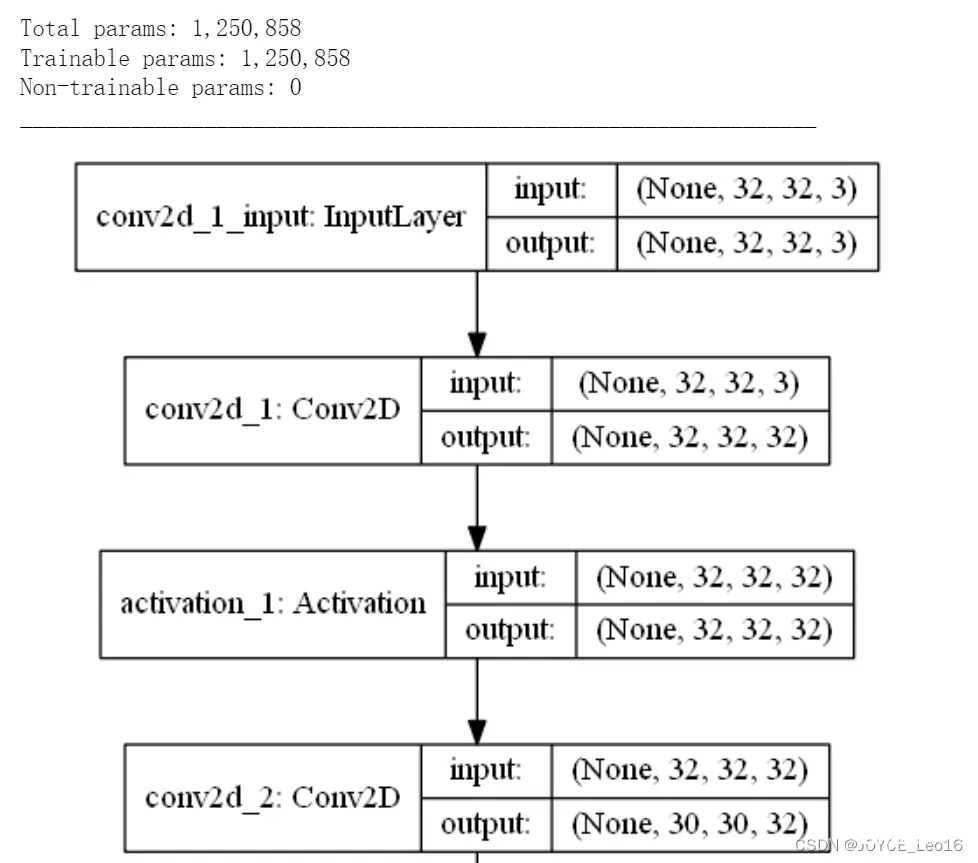
model = Sequential()# 图像输入形状(32, 32, 3) 对应(image_height, image_width, color_channels) model.add(Conv2D(32, (3, 3), padding='same', input_shape=(32, 32, 3)))model.add(Activation('relu'))model.add(Conv2D(32, (3, 3)))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.25))# 卷积、池化层输出都是一个三维的(height, width, channels)# 越深的层中,宽度和高度都会收缩model.add(Conv2D(64, (3, 3), padding='same'))model.add(Activation('relu'))model.add(Conv2D(64, (3, 3)))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Dropout(0.25))# 3 维展平为 1 维 ,输入全连接层model.add(Flatten())model.add(Dense(512))model.add(Activation('relu'))model.add(Dropout(0.5))model.add(Dense(num_classes)) # CIFAR数据有 10 个输出类,以softmax输出多分类model.add(Activation('softmax')) 模型编译:设定RMSprop优化算法;设定分类损失函数。
# 初始化 RMSprop 优化器opt = keras.optimizers.rmsprop(lr=0.001, decay=1e-6)# 模型编译:设定RMSprop 优化算法;设定分类损失函数;model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy']) 模型训练:简单验证5个epochs
batch_size = 64epochs = 5 history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test), shuffle=True) 模型评估:测试集accuracy:0.716,可见训练/测试集整体的准确率都不太高(欠拟合),可以增加epoch数、模型调优验证效果。
附 卷积神经网络优化方法(tricks):
超参数优化:可以用随机搜索、贝叶斯优化。推荐分布式超参数调试框架Keras Tuner包括了常用的优化方法。
数据层面:数据增强广泛用于图像任务,效果提升大。常用有图像样本变换、mixup等。更多优化方法具体可见:https://arxiv.org/pdf/1812.01187.pdf
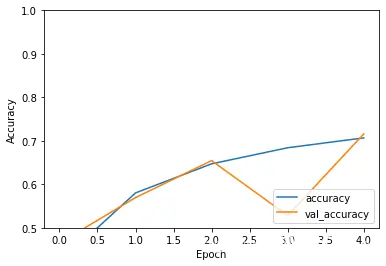
# 保存模型和权重num_predictions = 20save_dir = os.path.join(os.getcwd(), 'saved_models')model_name = 'keras_cifar10_trained_model.h5'if not os.path.isdir(save_dir): os.makedirs(save_dir)model_path = os.path.join(save_dir, model_name)model.save(model_path)print('Saved trained model at %s ' % model_path)# 评估训练模型scores = model.evaluate(x_test, y_test, verbose=1)print('Test loss:', scores[0])print('Test accuracy:', scores[1])plt.plot(history.history['accuracy'], label='accuracy')plt.plot(history.history['val_accuracy'], label = 'val_accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.ylim([0.5, 1])plt.legend(loc='lower right')plt.show()
参考:算法进阶
https://github.com/aialgorithm/Blog
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。