R语言绘制列线图构建(以二分类Logistic为例)超详细
宽嘴鱼汤 2024-06-12 16:35:08 阅读 54
浅谈二分类回归模型
COX回归分析不少见,但是简单异性的以二分类结局进行的回归分析更多,由于研究设计的研究便行,也是初次投稿的小白们比较理想的选择对象,二者的过程基本相似,但所用函数略有区别,从浅到深,先以二分类结局的Logistic回归为例,讲解一下
案例数据说明
有一组102例患者,来分析6个变量(old+bedridden time +EN + Probiotics + Albumin + Antibacterials)对是否发生某个并发症的影响。此处并发症是否发生是个二分类变量,就简单命名GROUP。
构建列线图
Mydata<-read.csv(file.choose() ,header = TRUE, fileEncoding = "GBK") # 假如数据读取失败,显示多节段字符数串有误,可使用此命令,Mydata是我自己随意命名的文件名,输入时只需随意取个英文名就行,其他的不用更改summary(Mydata) ##初步查看我的数据install.packages("Hmisc") ##安装程辑包--有的话可以忽略install.packages("rms") ##安装程辑包--有的话可以忽略library(Hmisc) ##加载Hmisc包与rms包library(rms)dd<-datadist(Mydata) #开始打包数据,注意Mydata改为自己取得名字options(datadist="dd") #此处命令不用自己更改,直输f_lrm <-lrm(GROUP~old+bedridden.time +EN+Probiotics+Albumin+Antibacterials , data=Mydata) #构建回归方程,使用lrm()函数构建二元LR,这里面的方程式就是结局~变量A+变量B+...,后面data来自自己命名的这个文件啦summary(f_lrm) #查看回归方程的结果par(mgp=c(1.6,0.6,0),mar=c(5,5,3,1)) ##设置画布的命令,这里面的参数都可以调,不过我用的还算顺手,这几个数字不调也行哦,要是最后呈现的结果中有几个指标的轴线不好看,就适当更改下map里面的数字,随便调看看nomogram <- nomogram(f_lrm,fun=function(x)1/(1+exp(-x)), ##回归方程 fun.at = c(0.01,0.05,0.2,0.5,0.9,0.99), funlabel = "Prob of 结局", ##风险轴刻度,结局是我的结局 conf.int = F, #每个得分的置信度区间 abbrev = F) #是否用简称代表因子变量plot(nomogram) #输出图片,右边plots可见列线图模型
喏 在右侧的plot能看见列线图
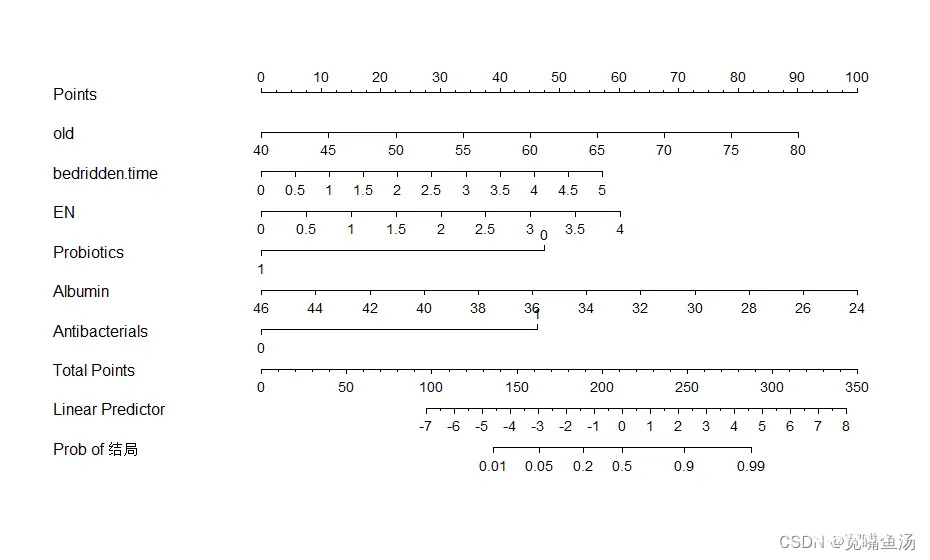
构建列线图中的注意bug集锦
从R的输出结果里看,对应上面的命令,各种bug会在结果中提示出来,挨个看看。我的bug主要是在方程构建出了问题,没注意到字符串转化带来的影响。 我用的是read.csv() 来导入文件,其中,file是一个带分隔符的文本文件,options是控制如何处理数据的选项,我的数据集转为csv格式后,里面变量仍是bedridden time,中间是空格,但导入到R后,显示的是 bedridden.time 我没注意,还是按照csv文件里的变量名称来,故而模型构造出错(变量用中文也没问题)

> Mydata<-read.csv(file.choose() ,header = TRUE, + fileEncoding = "GBK") > View(Mydata)> summary(Mydata) #在下面的结果中可以看见自己数据的基本呈现情况 GROUP old bedridden.time EN Probiotics Min. :0.0000 Min. :43.05 Min. :0.020 Min. :0.0300 Min. :0.0000 1st Qu.:0.0000 1st Qu.:53.81 1st Qu.:1.535 1st Qu.:0.8575 1st Qu.:0.0000 Median :0.0000 Median :62.85 Median :2.185 Median :1.5800 Median :0.0000 Mean :0.4412 Mean :60.97 Mean :2.121 Mean :1.5215 Mean :0.3627 3rd Qu.:1.0000 3rd Qu.:67.77 3rd Qu.:2.710 3rd Qu.:2.0500 3rd Qu.:1.0000 Max. :1.0000 Max. :79.17 Max. :4.780 Max. :3.6700 Max. :1.0000 Albumin Antibacterials Min. :24.60 Min. :0.0000 1st Qu.:31.48 1st Qu.:0.0000 Median :34.80 Median :1.0000 Mean :35.03 Mean :0.6471 3rd Qu.:38.69 3rd Qu.:1.0000 Max. :45.70 Max. :1.0000 > dd<-datadist(Mydata) #开始打包数据> options(datadist="dd") #一直到这里都很顺畅,但是在下面的回归模型中就出了问题> f_lrm <-lrm(GROUP~old+bedridden time +EN+Probiotics+Albumin+Antibacterials错误: unexpected symbol在"f_lrm <-lrm(GROUP~old+bedridden time"里 ##系统提示我在回归方程中,bedridden time 没有这个玩意。一般提示这种情况,就要回头查看自己数据变量名称,最简单粗暴的方法是在summary(Mydata)结果里面,就发现不对了。改一改就是> f_lrm <-lrm(GROUP~old+bedridden.time +EN+Probiotics+Albumin+Antibacterials+ , data=Mydata) #构建回归方程,使用lrm()函数构建二元LR> summary(f_lrm) #查看回归方程的结果 Effects Response : GROUP Factor Low High Diff. Effect S.E. Lower 0.95 Upper 0.95 old 53.8080 67.77 13.9620 1.911400 0.59957 0.736300 3.08660 Odds Ratio 53.8080 67.77 13.9620 6.762800 NA 2.088200 21.90200 bedridden.time 1.5350 2.71 1.1750 0.815420 0.40518 0.021276 1.60960 Odds Ratio 1.5350 2.71 1.1750 2.260100 NA 1.021500 5.00060 EN 0.8575 2.05 1.1925 1.090200 0.48099 0.147460 2.03290 Odds Ratio 0.8575 2.05 1.1925 2.974800 NA 1.158900 7.63630 Probiotics 0.0000 1.00 1.0000 -2.879300 0.83749 -4.520800 -1.23790 Odds Ratio 0.0000 1.00 1.0000 0.056171 NA 0.010880 0.29000 Albumin 31.4820 38.69 7.2075 -1.989600 0.57477 -3.116100 -0.86305 Odds Ratio 31.4820 38.69 7.2075 0.136750 NA 0.044329 0.42187 Antibacterials 0.0000 1.00 1.0000 2.808000 0.85382 1.134500 4.48140 Odds Ratio 0.0000 1.00 1.0000 16.576000 NA 3.109700 88.36000 > nomogram <- nomogram(f_lrm,fun=function(x)1/(1+exp(-x)), ##回归方程+ fun.at = c(0.01,0.05,0.2,0.5,0.9,0.99), + funlabel = "Prob of 结局", ##风险轴刻度,结局是我的结局+ conf.int = F, #每个得分的置信度区间+ abbrev = F) #是否用简称代表因子变量> plot(nomogram) #输出图片,右边plots可见列线图模型,到这里结果就出来了
最后,如果你的列线图出现某个指标的线很短、或者结局那一栏的数据挤在一块不好看,刨除数据本身问题,这都是可以改的。
一个是在画布设置那里,还有一个是在列线图模型参数设置那里
par(mgp=c(1.6,0.6,0),mar=c(5,5,3,1)) ##设置画布的命令,更改它会有意想不到的惊喜nomogram <- nomogram(f_lrm,fun=function(x)1/(1+exp(-x)), ##回归方程,不动它 fun.at = c(0.01,0.05,0.2,0.5,0.9,0.99), ##此处可以更改,改的就是列线图proud of 结局 概率值,可以直接删除某个数字,也可以自己补充。 funlabel = "Prob of 结局", ##风险轴刻度,可以改为的名字 conf.int = F, #每个得分的置信度区间 abbrev = F) #是否用简称代表因子变量
fun.at = c(0.01,0.05,0.2,0.7,0.9,0.99), 这里的数据我自己随便改了两下对着看就能看出差别啦


是不是上面的一组结局预测概率显示的要更好看呢?尽管会有人建议说把图片向左侧拉,图片的数字就会呈比例拉大了,但这情况是图片变得很长,长宽比例不协调,也不是最佳的解决办法
后续还有列线图的模型验证教程,记得点赞收藏观看唷
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。