深入解析Java中的ForkJoinPool:分而治之,并行处理的利器
码到三十五 2024-08-21 16:05:02 阅读 58
❃博主首页 :
「码到三十五」
,同名公众号 :「码到三十五」,wx号 : 「liwu0213」
☠博主专栏 :
<mysql高手>
<elasticsearch高手>
<源码解读>
<java核心>
<面试攻关>
♝博主的话 :
搬的每块砖,皆为峰峦之基;公众号搜索「码到三十五」关注这个爱发技术干货的coder,一起筑基
在Java的并发编程领域,随着多核处理器的普及,如何高效利用这些核心成为了一个重要议题。ForkJoinPool,作为Java 7引入的一个并发工具类,正是为了解决这个问题而生。本文将详细介绍ForkJoinPool的工作原理、使用方式以及最佳实践,帮助Java工程师更好地理解和运用这一强大工具。
目录
一、ForkJoinPool概述二、ForkJoinPool的工作原理2.1. 分治算法的应用2.2. 工作窃取算法2.3. 任务的拆分与合并2.4. 线程池的管理
三、使用ForkJoinPooll实现并行数组求和步骤1:定义任务类步骤2:使用ForkJoinPool执行任务
四、ForkJoinPool的优势五、最佳实践六、总结
一、ForkJoinPool概述
ForkJoinPool是Java并发包java.util.concurrent中的一个类,它提供了一个工作窃取算法的实现,能够高效地处理大量可以被拆分成较小子任务的任务。与传统的ExecutorService不同,ForkJoinPool特别适合于递归或分治算法的场景,在这些场景中,一个大任务可以被拆分成多个小任务并行处理,然后再将结果合并。
二、ForkJoinPool的工作原理
ForkJoinPool作为Java中的并行处理框架,其工作原理基于分治算法和工作窃取算法。下面将更深入地探讨其内部机制。
2.1. 分治算法的应用
ForkJoinPool的核心思想是分治算法。分治算法是一种将大问题拆分成小问题,递归地解决小问题,然后将这些小问题的解决方案组合起来解决原始大问题的策略。在ForkJoinPool中,这种策略被用于并行处理任务。
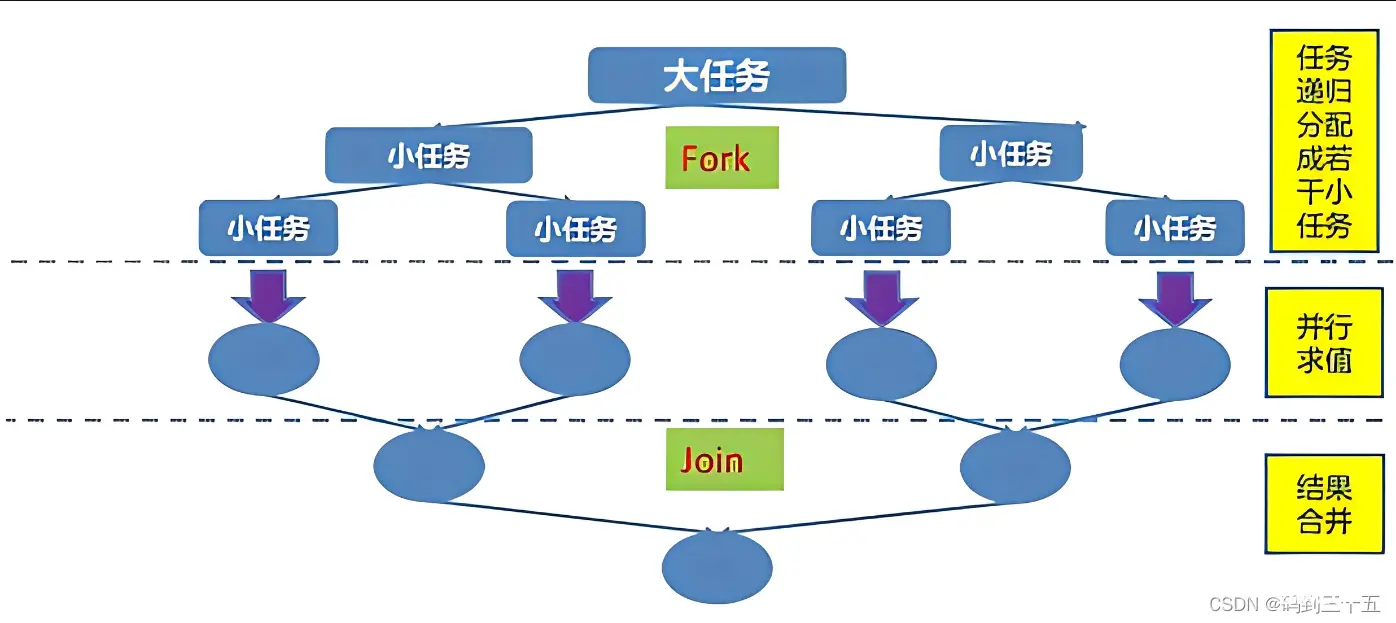
当一个大任务提交给ForkJoinPool时,它首先会被拆分成多个小任务。这些小任务是相互独立的,可以并行执行。ForkJoinPool中的工作线程会不断地从任务队列中取出这些小任务进行处理。当一个小任务处理完成后,其结果会被合并到其他小任务的结果中,最终得到大任务的处理结果。
2.2. 工作窃取算法
为了平衡各个工作线程之间的工作负载,ForkJoinPool采用了工作窃取算法。每个工作线程都有自己的任务队列,当某个线程完成了自己队列中的所有任务时,它会尝试从其他线程的队列中窃取任务来执行。
工作窃取算法的实现基于双端队列(Deque)。每个工作线程都有一个双端队列来存储待处理的任务。当线程需要执行新任务时,它会将任务放入队列的头部(top),并以LIFO(后进先出)的顺序处理队列中的任务。这样,最近添加的任务会优先被执行。
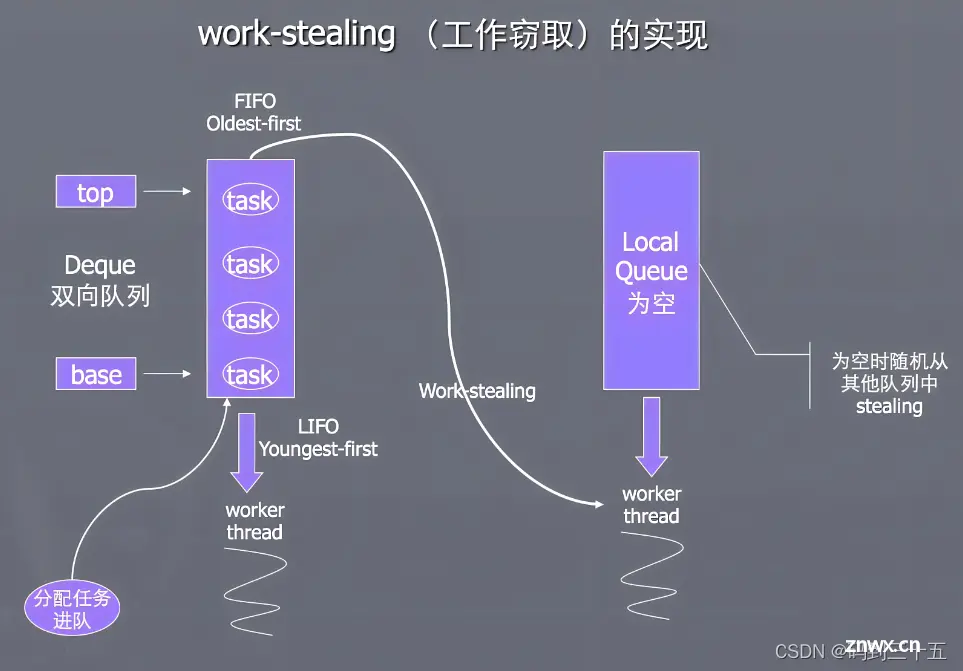
同时,当某个线程尝试窃取其他线程的任务时,它会从目标线程的队列的尾部(base)窃取任务。这种窃取方式是FIFO(先进先出)的,也就是说被窃取的任务是队列中等待时间最长的任务。这种机制有助于减少线程间的竞争,提高CPU的利用率。
2.3. 任务的拆分与合并
在ForkJoinPool中,任务的拆分和合并是通过继承自RecursiveAction或RecursiveTask的类来实现的。开发者需要实现compute方法来定义任务的处理逻辑。当一个大任务被拆分成多个小任务时,这些小任务会被提交到ForkJoinPool中并行执行。当所有小任务都执行完成后,它们的结果会被合并起来得到大任务的处理结果。
这个过程是递归的,也就是说每个小任务还可以继续被拆分成更小的任务并行执行。这种递归拆分和合并的方式使得ForkJoinPool能够处理非常复杂和庞大的任务。
2.4. 线程池的管理
ForkJoinPool内部维护了一组工作线程(ForkJoinWorkerThread)来执行任务。这些线程的数量可以根据需要进行调整。默认情况下,ForkJoinPool中的线程数量等于处理器的核心数。但是,在实际应用中,可以根据任务的特性和系统的负载情况调整线程池的大小。
ForkJoinPool还提供了一些其他的管理功能,如任务的取消、异常处理等。通过这些功能,我们可以更好地控制和管理并行处理的过程。
三、使用ForkJoinPooll实现并行数组求和
假设我们有一个非常大的整数数组,需要计算数组中所有元素的和。由于数组很大,如果采用单线程的方式逐个遍历数组元素进行求和,效率会非常低。这时,我们可以使用ForkJoinPool来并行处理这个任务。
步骤1:定义任务类
首先,我们需要定义一个继承自RecursiveTask的类来表示求和任务。RecursiveTask是ForkJoinPool中用于有返回值的任务的基类。在这个类中,我们需要实现compute方法来定义任务的处理逻辑。
<code>import java.util.concurrent.RecursiveTask;
public class ArraySumTask extends RecursiveTask<Long> {
private static final int THRESHOLD = 1000; // 阈值,当数组长度小于等于该值时,采用普通方式求和
private final int[] array;
private final int low, high;
public ArraySumTask(int[] array) {
this(array, 0, array.length);
}
private ArraySumTask(int[] array, int low, int high) {
this.array = array;
this.low = low;
this.high = high;
}
@Override
protected Long compute() {
if (high - low <= THRESHOLD) {
// 数组长度小于等于阈值,采用普通方式求和
long sum = 0;
for (int i = low; i < high; i++) {
sum += array[i];
}
return sum;
} else {
// 数组长度大于阈值,拆分任务并递归处理
int mid = low + (high - low) / 2;
ArraySumTask leftTask = new ArraySumTask(array, low, mid);
ArraySumTask rightTask = new ArraySumTask(array, mid, high);
leftTask.fork(); // 拆分左半部分任务并异步执行
rightTask.fork(); // 拆分右半部分任务并异步执行
return leftTask.join() + rightTask.join(); // 等待左右两部分任务处理完成并合并结果
}
}
}
在上面的代码中,我们定义了一个ArraySumTask类来表示求和任务。在compute方法中,我们首先判断数组的长度是否小于等于一个预设的阈值(这里设为1000)。如果小于等于阈值,就采用普通的方式遍历数组元素进行求和。否则,我们将数组拆分为左右两部分,并分别创建新的ArraySumTask对象来表示这两个子任务。然后,我们调用fork方法将这两个子任务提交到ForkJoinPool中异步执行。最后,我们调用join方法等待这两个子任务处理完成,并将它们的结果合并起来返回。
步骤2:使用ForkJoinPool执行任务
接下来,我们可以使用ForkJoinPool来执行这个求和任务。
首先,我们需要创建一个ForkJoinPool对象,并将求和任务提交给它执行。然后,我们可以调用Future对象的get方法来获取任务的处理结果。但是在这个案例中,由于我们的任务类继承自RecursiveTask,我们可以直接调用任务对象的join方法来获取结果,而无需使用Future对象。
import java.util.concurrent.ForkJoinPool;
import java.util.Random;
public class ForkJoinPoolExample {
public static void main(String[] args) throws Exception {
int[] array = new int[1000000]; // 创建一个包含100万个元素的数组
Random random = new Random();
for (int i = 0; i < array.length; i++) {
array[i] = random.nextInt(100); // 随机生成数组元素的值
}
ForkJoinPool pool = new ForkJoinPool(); // 创建ForkJoinPool对象(默认使用处理器的核心数作为线程池大小)
ArraySumTask task = new ArraySumTask(array); // 创建求和任务对象并传入数组作为参数(这里也可以传入数组的一部分作为参数来实现更细粒度的拆分)
Long sum = pool.invoke(task); // 提交任务并等待处理完成(也可以使用submit方法提交任务并获取一个Future对象来异步获取结果)
System.out.println("Sum: " + sum); // 输出结果(这里应该输出数组中所有元素的和)
pool.shutdown(); // 关闭ForkJoinPool(释放资源)
}
}
四、ForkJoinPool的优势
高效利用多核处理器:ForkJoinPool通过工作窃取算法和并行处理机制,能够充分利用多核处理器的性能,提高程序的并发处理能力。
简化并发编程:使用ForkJoinPool可以简化并发编程的复杂性,开发者只需要关注任务的拆分和合并逻辑,而无需关心线程的创建、管理和调度等细节。
适用于分治算法:ForkJoinPool特别适合于处理可以被拆分成较小子任务的大任务,如递归算法、排序算法、图算法等。
五、最佳实践
合理划分任务:为了充分发挥ForkJoinPool的性能优势,需要合理划分任务的大小和粒度。任务过大会导致拆分和合并的开销增加,任务过小则可能导致线程调度的开销增加。
避免任务间的依赖:在使用ForkJoinPool时,应尽量避免任务间的依赖关系。如果任务之间存在依赖,可能会导致某些线程长时间等待其他线程的处理结果,从而降低并发性能。
调整线程池大小:ForkJoinPool的默认线程池大小等于处理器的核心数。在实际应用中,可以根据任务的特性和系统的负载情况调整线程池的大小,以获得最佳的性能表现。
六、总结
ForkJoinPool是Java并发编程中的一个强大工具,它提供了一种高效的方式来处理可以被拆分成较小子任务的大任务。通过合理使用ForkJoinPool,我们可以充分利用多核处理器的性能,提升程序的并发处理能力。然而,在使用ForkJoinPool时,我们也需要注意任务的划分、依赖关系以及线程池大小的调整等问题,以确保获得最佳的性能提升。
–
关注公众号获取更多技术干货 !

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。