【python】实战:大批量数据的处理和拟合
cnblogs 2024-08-23 15:09:00 阅读 54
@
目录
- 完整项目源码
- 任务介绍
- 第一小问
- 读取数据
- 数据补完
- 模型一的建立与分析
- 概述
- 标准化
- 处理相同时刻的数据
- 模型二的建立与分析
- 第二小问
- 数据分布
- 数据处理
- 第三小问
- 计算疗法的得分
- 个性化处理
完整项目源码
本项目开源
任务介绍
- 本题为2006年高教社杯全国大学生数学建模竞赛B题:
艾滋病是当前人类社会最严重的瘟疫之一,从1981年发现以来的20多年间,它已经吞噬了近3000万人的生命。
艾滋病的医学全名为“获得性免疫缺损综合症”,英文简称AIDS,它是由艾滋病毒(医学全名为“人体免疫缺损病毒”, 英文简称HIV)引起的。这种病毒破坏人的免疫系统,使人体丧失抵抗各种疾病的能力,从而严重危害人的生命。人类免疫系统的CD4细胞在抵御HIV的入侵中起着重要作用,当CD4被HIV感染而裂解时,其数量会急剧减少,HIV将迅速增加,导致AIDS发作。
艾滋病治疗的目的,是尽量减少人体内HIV的数量,同时产生更多的CD4,至少要有效地降低CD4减少的速度,以提高人体免疫能力。
迄今为止人类还没有找到能根治AIDS的疗法,目前的一些AIDS疗法不仅对人体有副作用,而且成本也很高。许多国家和医疗组织都在积极试验、寻找更好的AIDS疗法。
现在得到了美国艾滋病医疗试验机构ACTG公布的两组数据。 ACTG320(见附件1)是同时服用zidovudine(齐多夫定),lamivudine(拉美夫定)和indinavir(茚地那韦)3种药物的300多名病人每隔几周测试的CD4和HIV的浓度(每毫升血液里的数量)。193A(见附件2)是将1300多名病人随机地分为4组,每组按下述4种疗法中的一种服药,大约每隔8周测试的CD4浓度(这组数据缺HIV浓度,它的测试成本很高)。4种疗法的日用药分别为:600mg zidovudine或400mg didanosine(去羟基苷),这两种药按月轮换使用;600 mg zidovudine加2.25 mg zalcitabine(扎西他滨);600 mg zidovudine加400 mg didanosine;600 mg zidovudine加400 mg didanosine,再加400 mg nevirapine(奈韦拉平)。
请你完成以下问题:
(1)利用附件1的数据,预测继续治疗的效果,或者确定最佳治疗终止时间(继续治疗指在测试终止后继续服药,如果认为继续服药效果不好,则可选择提前终止治疗)。
(2)利用附件2的数据,评价4种疗法的优劣(仅以CD4为标准),并对较优的疗法预测继续治疗的效果,或者确定最佳治疗终止时间。
(3)艾滋病药品的主要供给商对不发达国家提供的药品价格如下:600mg zidovudine 1.60美元,400mg didanosine 0.85美元,2.25 mg zalcitabine 1.85美元,400 mg nevirapine 1.20美元。如果病人需要考虑4种疗法的费用,对(2)中的评价和预测(或者提前终止)有什么改变。
附件下载地址
第一小问
读取数据
打开附件1:(以下只展示了极小部分的数据)
同时服用3种药物(zidovudine, lamivudine,indinavir)的300多名病人每隔几周测试的CD4和HIV的浓度。
第1列是病人编号,第2列是测试CD4的时刻(周),第3列是测得的CD4(乘以0.2个/ul),第4列是测试HIV的时刻(周),第5列是测得的HIV(单位不详)。
PtIDCD4DateCD4CountRNADateVLoad
23424017805.5
23424422843.9
23424812684.7
2342425171254
234244099405
2342501405.3
可以看到数据排列的方式非常整齐,这使得我们可以快速按行读取数据。首先,删掉文本的非数据部分:(以下只展示了极小部分的数据)
2349605705.3
23496420243.9
2349692.6
2349629236292.7
2349639260393.5
2351601405.6
2351642743.4
2351687282.4
23516240
2351642237422.5
23517074
23517592
235179157
2351726181
2351808504.8
2351836032.3
2351879873.9
235182454243.7
在按行读取之前,还有一个比较关键的问题:有的数据是缺失的,且只有编号23496缺失第2、3列数据。因此,制定以下读取策略:
'''
Created by Han Xu
email:736946693@qq.com
'''
total=[]
f=open("附件1纯数据.txt",encoding="utf-8",mode="r")code>
lastID=""code>
currentID=""code>
for line in f:
lineData=line.split()
currentID = float(lineData[0])
CD4Date = -1
CD4Count = -1
RNADate = -1
VLoad = -1
if (len(lineData) == 5):
CD4Date = float(lineData[1])
CD4Count = float(lineData[2])
RNADate = float(lineData[3])
VLoad = float(lineData[4])
else:
if (lineData[0] == "23496"):
RNADate = float(lineData[1])
VLoad = float(lineData[2])
else:
CD4Date = float(lineData[1])
CD4Count = float(lineData[2])
new_data={"CD4Date":CD4Date,"CD4Count":CD4Count,"RNADate":RNADate,"VLoad":VLoad}
if(currentID!=lastID):
individual = {"id": None, "data": []}
individual["id"] = currentID
individual["data"].append(new_data)
total.append(individual)
else:
total[len(total)-1]["data"].append(new_data)
lastID = currentID
在以上部分中,建立了一个名为total的列表,列表中每个元素是这样的:
print(total[0])
{'id': 23424.0, 'data': [{'CD4Date': 0.0, 'CD4Count': 178.0, 'RNADate': 0.0, 'VLoad': 5.5}, {'CD4Date': 4.0, 'CD4Count': 228.0, 'RNADate': 4.0, 'VLoad': 3.9}, {'CD4Date': 8.0, 'CD4Count': 126.0, 'RNADate': 8.0, 'VLoad': 4.7}, {'CD4Date': 25.0, 'CD4Count': 171.0, 'RNADate': 25.0, 'VLoad': 4.0}, {'CD4Date': 40.0, 'CD4Count': 99.0, 'RNADate': 40.0, 'VLoad': 5.0}]}
这样,我们就完成了附件1的数据的读取
数据补完
在所给数据中,有不少的数据是缺失的,为了尽可能地利用数据,利用拉格朗日线性插值法对空缺数据进行补充。方法如下:
$$
y=y_{k} \times \frac{x-x_{k+1}}{x_{k}-x_{k+1}}+y_{k+1} \times \frac{x-x_{k}}{x_{k+1}-x_{k}}
$$
2351687282.4
23516240
2351642237422.5
举例而言,在如上的数据中,要补全编号23516个体的第3、4列数据,则:先指定x=24
$$
y=?,y_{k}=2.4,y_{k+1}=2.5 \
x_{k}=8,x_{k+1}=42
$$
可以轻松计算出预测的y值。
详细的代码在源码的repairData.py中。
模型一的建立与分析
概述
首先,根据文本中的大量数据,拟定针对CD4浓度和VLoad浓度分别拟合出关于时间t的函数,此为总体方针。CD4浓度越大越好,VLoad浓度越小越好。为了统筹两条函数曲线,可以对VLoad浓度进行取负,然后将二者相加。当然,必须要先将数据标准化才可以相加。
标准化
在所给的数据文本中,CD4Date数据(第三列)的极差非常大,而且VLoad数据的单位也不确定。因此,首先要对数据进行标准化处理。这里采用Z-score 标准化:
对于样本 $X$ 中的每个特征:
$$
X_{normalized} = \frac{(X - \mu)}{\sigma}
$$
其中,$\mu$ 是该特征的平均值,$\sigma$ 是该特征的标准差。
标准化的代码在源码的dataProcessing.py中。
处理相同时刻的数据
读取完数据后,注意到,在文本中,有很多的数据具有相同的时刻t,如下:
23424017805.5
2342501405.3
23426010104.5
2342701005.3
拟针对具有相同时刻t的数据组$(x,y_{1}),(x,y_{2}),(x,y_{3}),(x,y_{4})$,求出其平均值$(x,y_{average})$,然后进行拟合。
此部分的代码在源码的dataProcessing.py中。
模型二的建立与分析
在模型一中,拟合方法是,直接对具有相同时刻t的数据组$(x,y_{1}),(x,y_{2}),(x,y_{3}),(x,y_{4})$,求出其平均值$(x,y_{average})$。然而,在拟合过程中,这些具有相同时刻t的数据组,和孤立的数据,起到同样的拟合作用。也就是说,它们的重要程度是相同的。但是,具有相同时刻t的数据组显然要比孤立的数据要更加精确。因此,模型一的拟合是不合理的。
出于以上考虑,现使用一种创新性的数据处理办法,使得在拟合时,体现出具有相同时刻t的数据组的重要性,方法如下:
假如有如下数据组:$(x,y_{1}),(x,y_{2}),(x,y_{3}),(x,y_{4})$,它们的x数据是相同的。首先,先求出其y值的均值,$(x,y_{average})$。然后,尝试增加其数据密度,要求其在拟合时起到更加显著的作用。原数据组样本容量为4,然后确定x的数量级,以小于n个x的数量级为基准,对数据组中每个坐标的x添加偏置offset,使得数据组中每个坐标的x都各不相同但差别极小可以忽略不计。
举例而言,假如有数据组$(1,1),(1,2),(1,3),(1,4)$,按照以上方法,可以获得数据组$(0.9998,2.5),(0.9999,2.5),(1.0001,2.5),(1.0002,2.5)$
这种方法的代码在源码的dataProcessing.py中。
接下来同样进行拟合。然后把拟合好的曲线进行融合,结果如下:
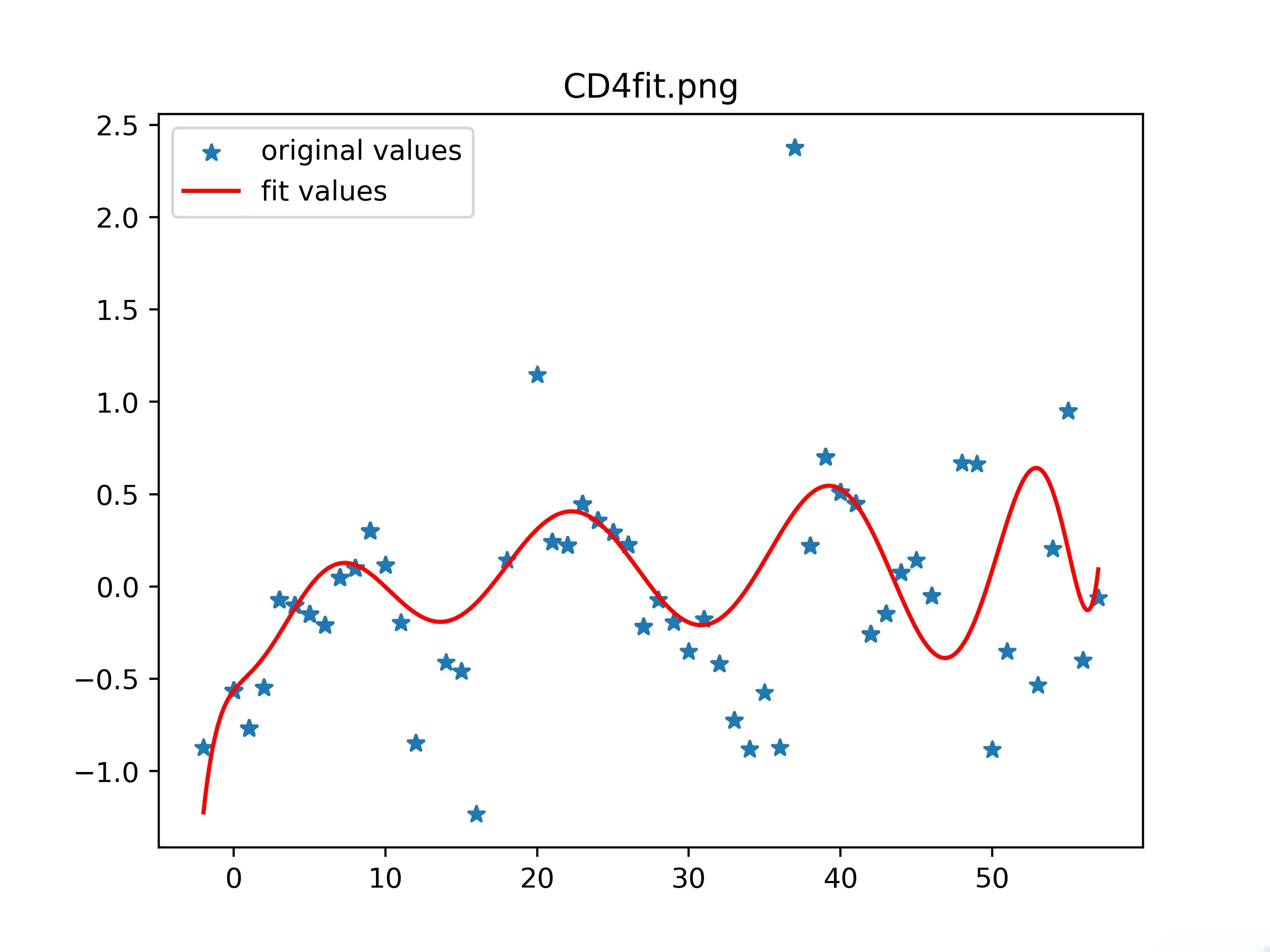
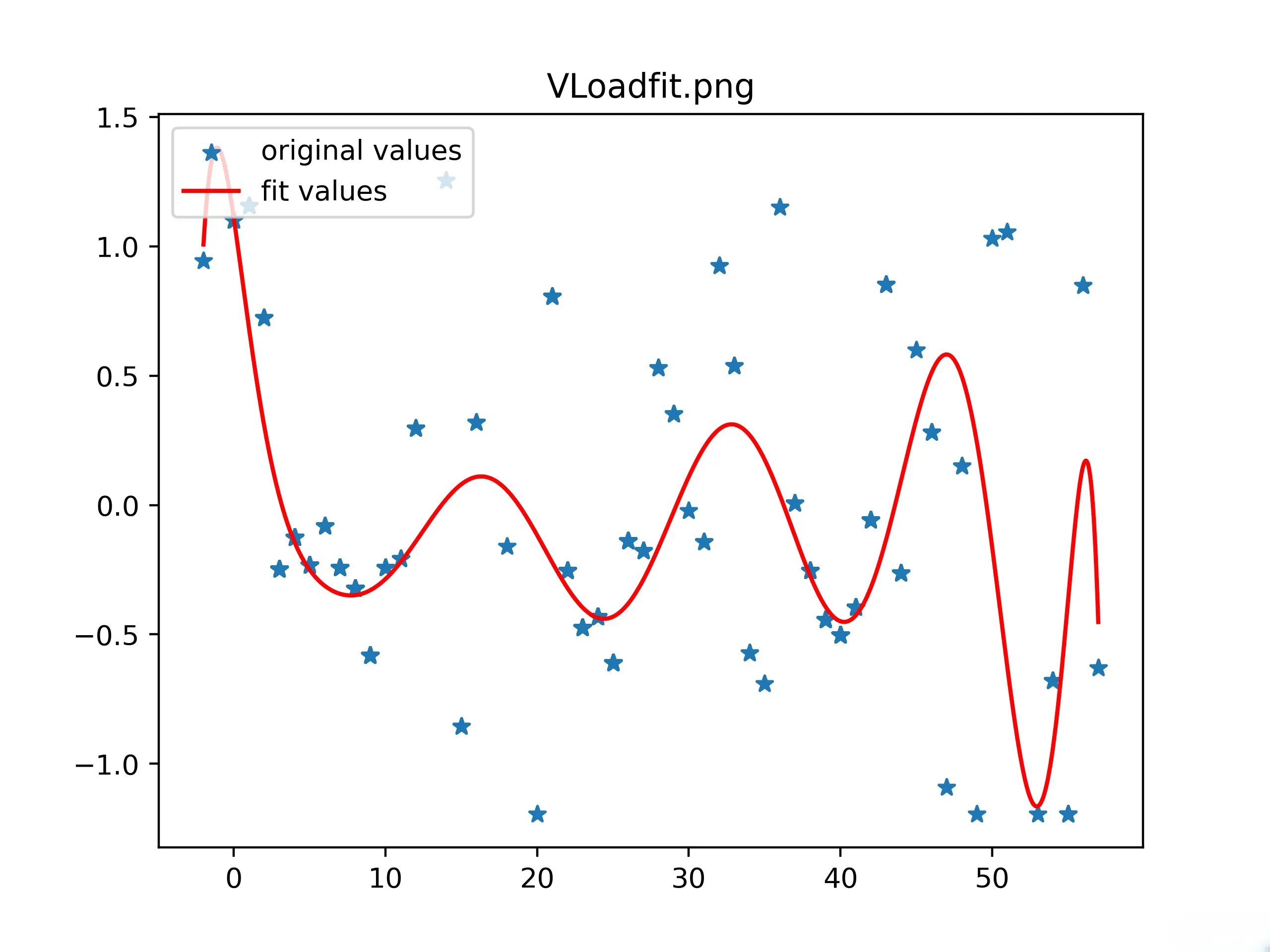
此部分代码在在源码的combine2func.py中
第二小问
数据分布
首先,附件2文本中的数据是这样的:(以下只展示了极小部分的数据)
1300多名病人按照4种疗法服药大约每隔8周测试的CD4浓度。
第1列是病人编号,第2列是4种疗法的代码:
1 = 600mg zidovudine 与400mg didanosine按月轮换使用;
2 = 600mg zidovudine 加2.25mg zalcitabine;
3 = 600mg zidovudine 加400mg didanosine;
4 = 600mg zidovudine 加400mg didanosine 加400mg nevirapine。
第3列是病人年龄,第4列是测试CD4的时刻(周),第5列是测得的CD4,取值log(CD4+1).
ID 疗法 年龄 时间 Log(CD4 count+1)
1236.427103.1355
1236.42717.57143.0445
1236.427115.57142.7726
1236.427123.57142.8332
1236.427132.57143.2189
1236.4271403.0445
2447.846703.0681
2447.846783.8918
2447.8467163.9703
2447.8467233.6109
2447.846730.71433.3322
2447.8467393.0910
3160.287503.7377
4336.596904.1190
4336.59697.14294.1109
4336.596916.14294.7095
4336.596932.42862.8332
5135.94803.5835
5135.94883.4340
5135.948163.4340
5135.948243.7136
5135.948323.0445
5135.948402.3979
由于病人的年龄差别较大,且不同年龄的病人的抵抗力差别也比较大,因此,将病人按照年龄划分为4个样本组:14~25岁、25~35岁、36~45岁、45岁以上。
此外,可以发现CD4浓度的测试时间集中在以下几个时间段:第0周、第7~9周、第15~17周、第23~25周、第31~33周、第38周以上。因此,基于测量时刻,对每个样本组划分出若干个数据组。
读取数据的代码在源码的readDataTxt2.py中。
数据处理
首先,针对一个数据组$(x_{1},y_{1}),(x_{2},y_{2}),(x_{3},y_{3}),(x_{4},y_{4})$,求出其平均值$(x_{average},y_{average})$,由于针对时间t分成了6个数据组,因此会得到6个数据点。
接下来,为了描绘CD4浓度的变化,对这六个点,相邻的两点y值做减法,最终得到5个点,然后用这5个点进行拟合。下面展示一个年龄组的拟合结果:
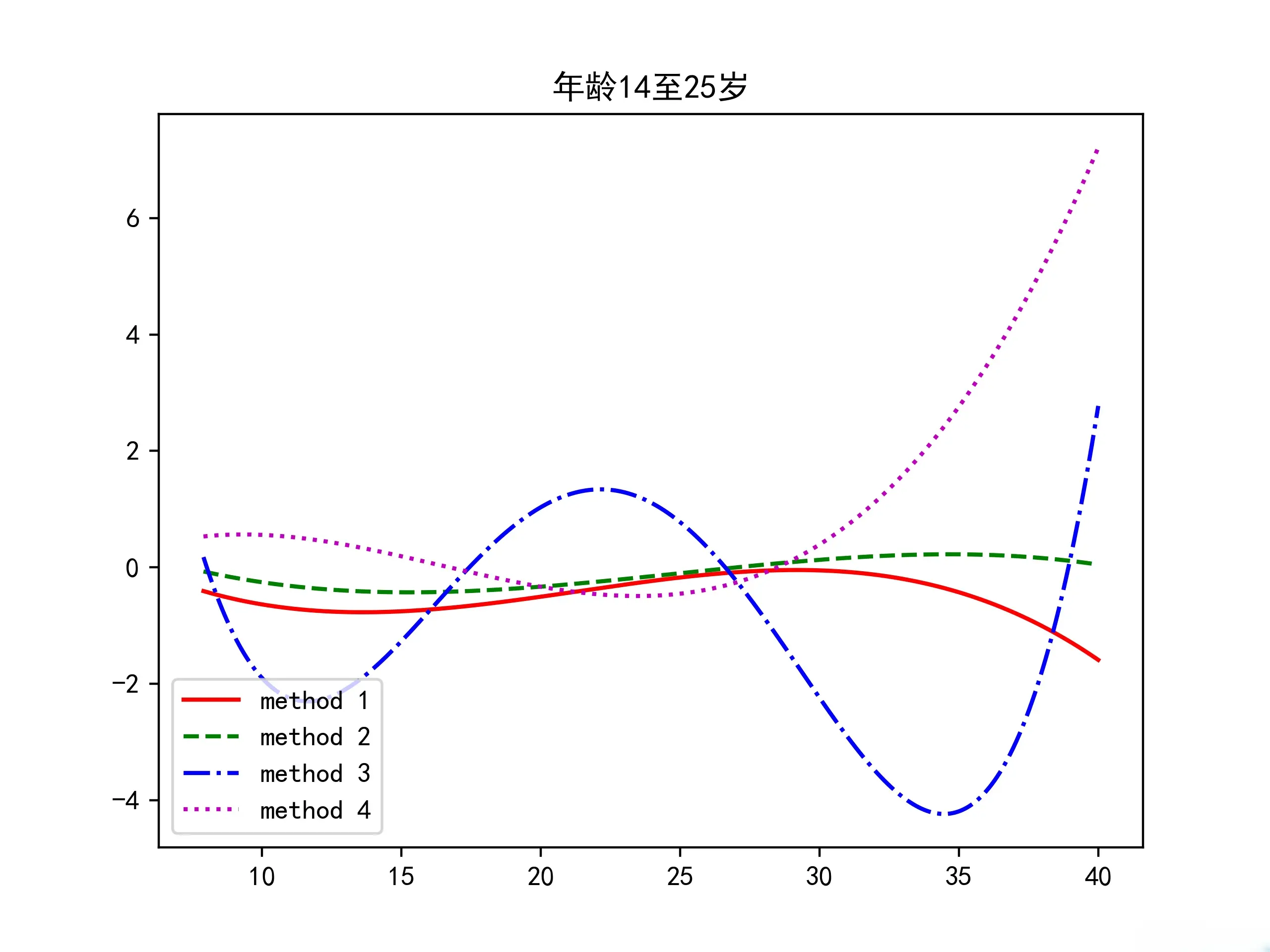
此部分的代码在源码的Task2_fit.py中。
第三小问
计算疗法的得分
在第二小问中,我们拟合出了CD4浓度变化量的函数曲线。对于某种疗法的某个病人来说,CD4浓度变化量大于0且越大,表明CD4增加得越多,说明该疗法越有效。而当CD4浓度变化量小于或等于0且越小时,说明该疗法对于病人是没有效果甚至是有副作用的,因此对于疗法失效,且另作统计为疗法的失效率,记为$Q$。我们对得到的的数据进行统计,利用以下公式:
- CD4浓度变化量数据组:$\left { D_{1},D_{2},...,D_{N} \right }$,根据拟合得到的函数生成数据
- 平均值:$D_{average}=\frac{1}{n} \sum_{i=1}^{n}{D_{i}}$
- 标准差:$\sigma$
- 失效率:$q=\frac{N}{n},N为数据组\left { D_{1},D_{2},...,D_{N} \right }中小于或等于0的个数$
根据以上分析,我们计算每个疗法的得分:$g=D_{average} \times (1-q)^{2} \div \sigma$
个性化处理
如果病人考虑到四种疗法的费用,结合自身的经济承受能力来选择疗法。我们引入了价格因素r,其中p是疗法所需的费用,r是病人对费用的敏感指数。由于个人经济承受能力的不同,每个人对费用的敏感程度是不同的。因此,我们在模型中引入了费用敏感指数,费用敏感指数越大,说明病人对费用越敏感。当r=0(即$p{r}=1$)时,价格因素不起作用,病人对费用不敏感,表示病人只追求最好的治疗效果,无论付出多大的费用。当r=1(即$p=p$)时,价格因素对病人选择的疗法有较大的影响,此时病人会折中考虑费用和疗效。
综合考虑效果和费用的共同作用,对刚刚得到的疗法得分进行如下处理,来评价疗法的优劣:$U=g \div p^{r}$
计算最终得分的代码在源码的Task3.py中。
本文由博客一文多发平台 OpenWrite 发布!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。