C#使用PaddleOCR进行图片文字识别✨
mingupup 2024-07-05 14:05:02 阅读 52
PaddlePaddle介绍✨
PaddlePaddle(飞桨)是百度开发的深度学习平台,旨在为开发者提供全面、灵活的工具集,用于构建、训练和部署各种深度学习模型。它具有开放源代码、高度灵活性、可扩展性和分布式训练等特点。PaddlePaddle支持端到端的部署,可以将模型轻松应用于服务器、移动设备和边缘设备。此外,PaddlePaddle拥有丰富的预训练模型库,涵盖图像分类、目标检测、语义分割等常见任务。社区支持和生态系统完善,为开发者提供了丰富的教程、文档和示例代码,助力深度学习模型的开发和应用。
PaddleOCR介绍✨
PaddleOCR是基于飞桨(PaddlePaddle)深度学习框架开发的开源光学字符识别(OCR)工具。它提供了端到端的OCR解决方案,支持文本检测、文本识别以及关键点检测等功能。PaddleOCR具有高度灵活性和可扩展性,可以适应多种场景下的文本识别需求,包括身份证识别、车牌识别、表格识别等。通过预训练的模型,PaddleOCR能够实现高精度的文本检测和识别,同时支持多语言文本识别,包括中文、英文等。此外,PaddleOCR还提供了丰富的API接口和模型库,方便开发者快速集成和部署OCR功能,助力各种应用场景下的文本识别任务。

PaddleSharp介绍✨
PaddleSharp是一个基于C#语言封装的飞桨(PaddlePaddle)深度学习框架的库。它为C#开发者提供了在熟悉的环境中利用飞桨强大功能的能力。PaddleSharp支持构建、训练和部署各种深度学习模型,包括图像分类、目标检测、语义分割等任务。该库提供了丰富的功能和工具,包括模型构建、预训练模型加载、高性能计算支持等。通过PaddleSharp,开发者可以利用飞桨底层计算库实现高性能的深度学习计算,有效地利用GPU或CPU资源。总体而言,PaddleSharp为C#开发者提供了一个便捷的工具,使他们能够在C#环境中轻松应用飞桨的深度学习功能。
Winform界面设计✨
Winform界面设计如下:
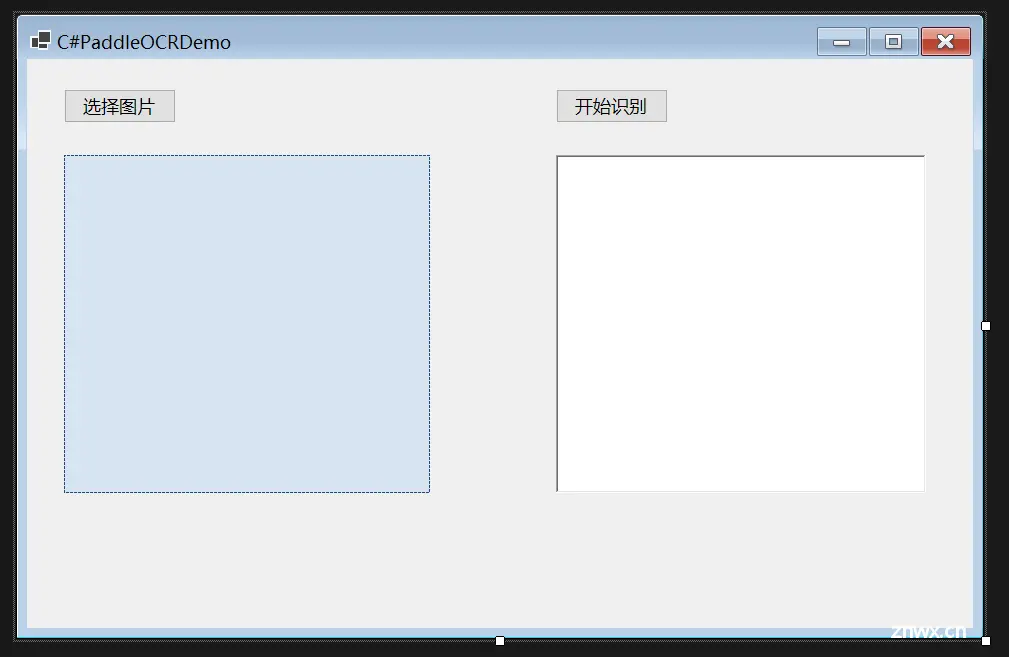
就两个按钮一个富文本框一个PictureBox。
步骤✨
安装对应的Nuget

进行图片文字识别
使用的代码也比较简单:
<code>FullOcrModel model = LocalFullModels.ChineseV3;
using (PaddleOcrAll all = new PaddleOcrAll(model, PaddleDevice.Mkldnn())
{
AllowRotateDetection = true, /* 允许识别有角度的文字 */
Enable180Classification = false, /* 允许识别旋转角度大于90度的文字 */
})
{
// Load local file by following code:
using (Mat src2 = Cv2.ImRead(selectedPicture))
{
PaddleOcrResult result = all.Run(src2);
richTextBox1.Text = result.Text;
}
}
FullOcrModel model = LocalFullModels.ChineseV3;
这行代码创建了一个FullOcrModel对象,该对象表示PaddleOCR的模型。LocalFullModels.ChineseV3是一个预训练的模型,专门用于识别中文字符。
using (PaddleOcrAll all = new PaddleOcrAll(model, PaddleDevice.Mkldnn())
{
AllowRotateDetection = true, /* 允许识别有角度的文字 */
Enable180Classification = false, /* 允许识别旋转角度大于90度的文字 */
})
这段代码创建了一个PaddleOcrAll对象,该对象用于运行OCR模型并获取识别结果。PaddleDevice.Mkldnn()表示使用Intel的MKL-DNN库来加速计算。
AllowRotateDetection = true表示允许识别有角度的文字,即使文字并不完全水平,也能被识别。
Enable180Classification = false表示不允许识别旋转角度大于90度的文字,如果文字旋转的角度过大,可能无法被正确识别。
using关键字用于确保PaddleOcrAll对象在不再需要时能被正确地释放,避免内存泄漏。
using (Mat src2 = Cv2.ImRead(selectedPicture))
这行代码使用OpenCV的ImRead函数读取指定路径的图片文件,返回一个Mat对象,该对象是OpenCV用于表示图像的类。selectedPicture是图片文件的路径。using关键字确保Mat对象在不再需要时能被正确地释放,避免内存泄漏。
PaddleOcrResult result = all.Run(src2);
这行代码将读取的图片传递给PaddleOCR模型进行文字识别。all.Run(src2)会运行OCR模型并返回识别结果,结果被存储在PaddleOcrResult对象中。
PaddleOcrResult是一个record,属性有Regions与Text:
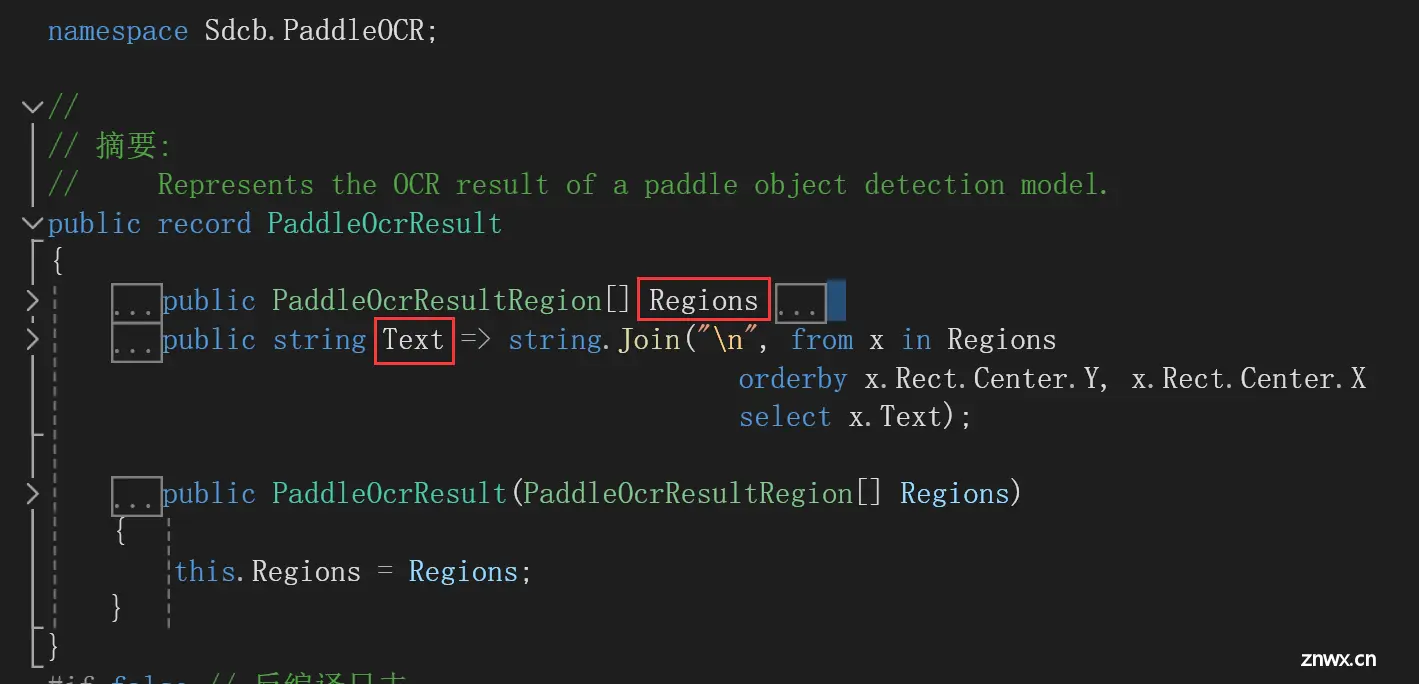
本示例的Regins如下所示:
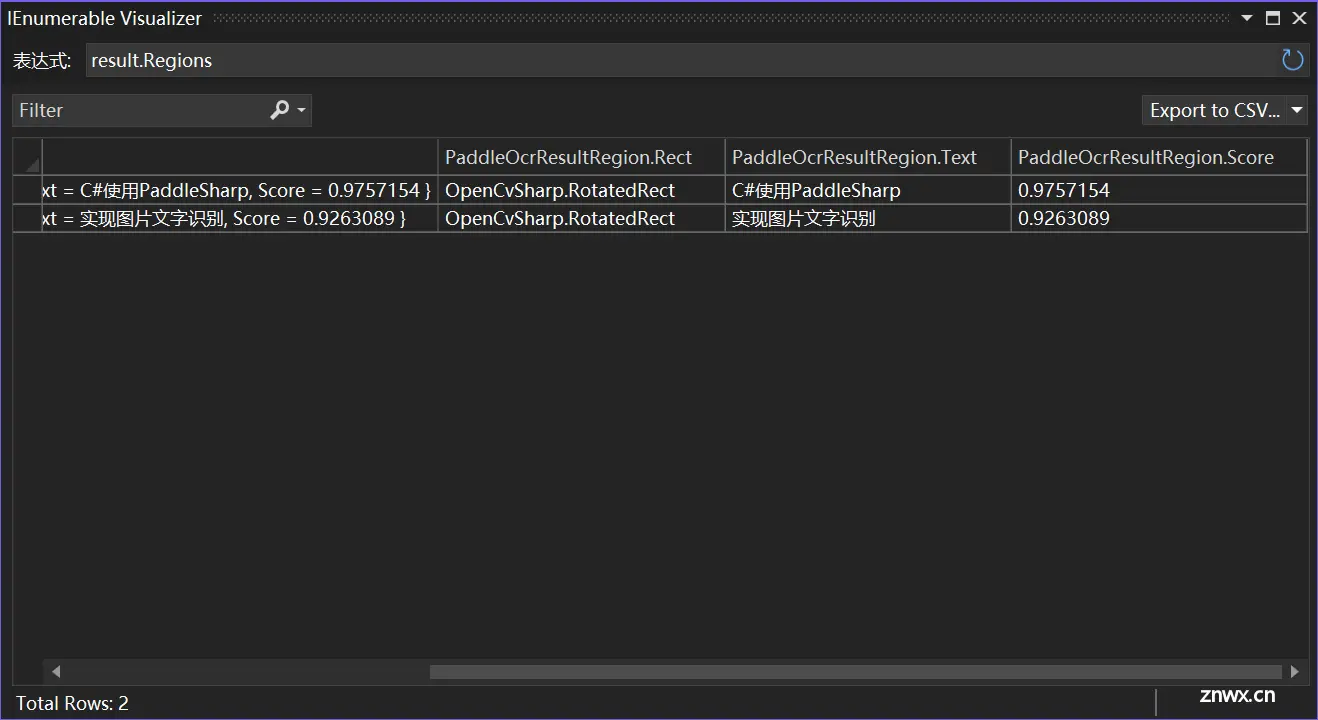
本示例的Text如下所示:
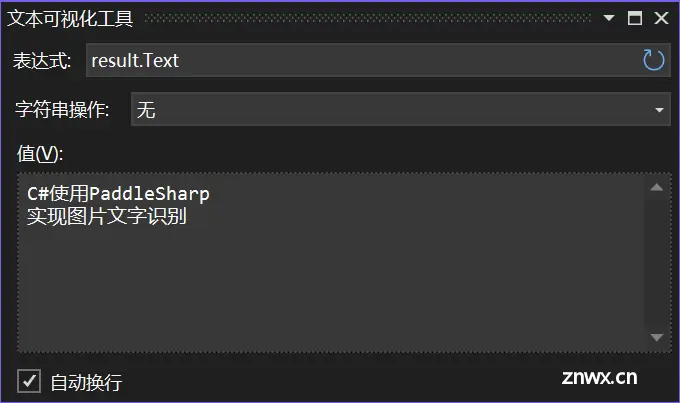
本示例的效果如下图所示:

本示例全部代码:
<code>using OpenCvSharp;
using Sdcb.PaddleInference;
using Sdcb.PaddleOCR.Models.Local;
using Sdcb.PaddleOCR.Models;
using Sdcb.PaddleOCR;
using System.Diagnostics;
namespace PaddleSharpDemo
{
public partial class Form1 : Form
{
string selectedPicture;
public Form1()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e)
{
OpenFileDialog openFileDialog = new OpenFileDialog();
openFileDialog.Filter = "Image Files(*.BMP;*.JPG;*.GIF;*.PNG)|*.BMP;*.JPG;*.GIF;*.PNG|All files (*.*)|*.*";
openFileDialog.FilterIndex = 1;
openFileDialog.Multiselect = false;
if (openFileDialog.ShowDialog() == DialogResult.OK)
{
selectedPicture = openFileDialog.FileName;
MessageBox.Show($"您选中的图片路径为:{ selectedPicture}");
// 使用Image类加载图片
Image image = Image.FromFile(selectedPicture);
// 让PictureBox完全显示图片
pictureBox1.SizeMode = PictureBoxSizeMode.Zoom;
// 将图片显示在PictureBox中
pictureBox1.Image = image;
}
else
{
MessageBox.Show("您本次没有选择任何图片!!!");
}
}
private void button2_Click(object sender, EventArgs e)
{
FullOcrModel model = LocalFullModels.ChineseV3;
using (PaddleOcrAll all = new PaddleOcrAll(model, PaddleDevice.Mkldnn())
{
AllowRotateDetection = true, /* 允许识别有角度的文字 */
Enable180Classification = false, /* 允许识别旋转角度大于90度的文字 */
})
{
// Load local file by following code:
using (Mat src2 = Cv2.ImRead(selectedPicture))
{
PaddleOcrResult result = all.Run(src2);
richTextBox1.Text = result.Text;
}
}
}
}
}
PaddleOCR的命令行使用与Python脚本使用✨
我选择PaddleSharp的原因是想在C#中应用中直接使用,如果你不熟悉C#,可以选择在命令行或者Python脚本中使用PaddleOCR。
具体安装过程官网上有教程,其他人也出了很多教程,我这里就不重复说了,就简单演示一下命令行与Python脚本的使用。
命令行使用
命令:
paddleocr --image_dir ./封面.png --use_angle_cls true --use_gpu false
效果:
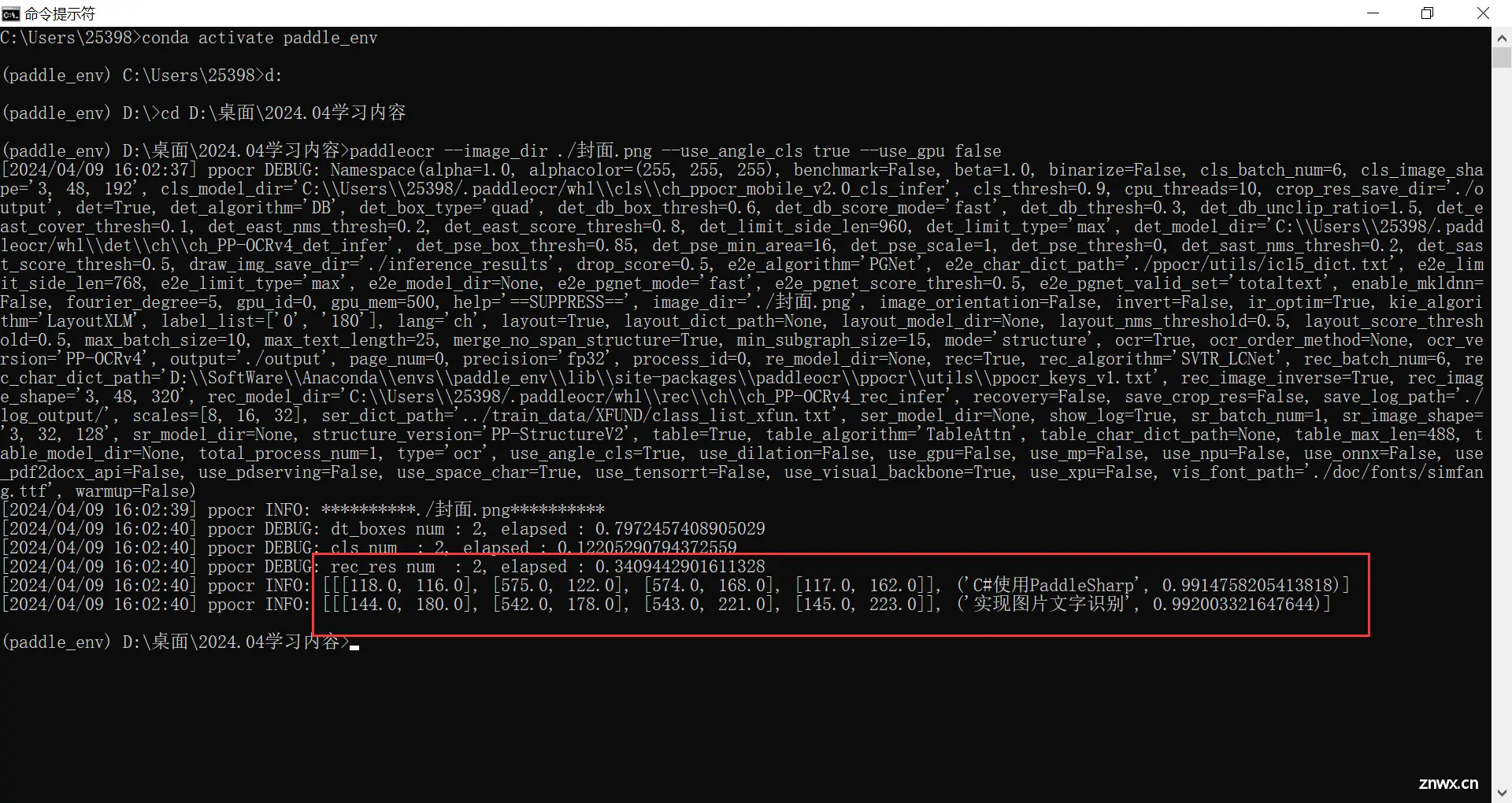
Python脚本使用
Python脚本如下所示:
<code>from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memorycode>
img_path = 'D:\\桌面\\2024.04学习内容\\封面.png'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')code>
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
效果如下所示:

生成的图片如下所示:

总结✨
之前分享过Spire.OCR做图片文字识别,但是识别准确率不及PaddleOCR,并且Spire.OCR还不是开源的,因此如果在使用C#的过程中遇到OCR的需求可以尝试使用PaddleOCR,以上就是本期的分享,希望对你有所帮助。
参考✨
1、PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices) (github.com)
2、[sdcb/PaddleSharp: .NET/C# binding for Baidu paddle inference library and PaddleOCR (github.com)](
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。