深入理解Prometheus: Kubernetes环境中的监控实践
cnblogs 2024-06-27 10:39:00 阅读 53
在这篇文章中,我们深入探讨了Prometheus在Kubernetes环境中的应用,涵盖了从基础概念到实战应用的全面介绍。内容包括Prometheus的架构、数据模型、PromQL查询语言,以及在Kubernetes中的集成方式、监控策略、告警配置和数据可视化技巧。此外,还包括针对不同监控场景的实战指导和优化建议。
关注【TechLeadCloud】,分享互联网架构、云服务技术的全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人

一、Prometheus简介
Prometheus, 作为一个开源系统监控和警报工具包,自从2012年诞生以来,已经成为云原生生态系统中不可或缺的组成部分。
Prometheus的核心概念
Prometheus的设计初衷是为了应对动态的云环境中的监控挑战。它采用了多维数据模型,其中时间序列数据由metric name和一系列的键值对(即标签)标识。这种设计使得Prometheus非常适合于存储和查询大量的监控数据,特别是在微服务架构的环境中。
与传统监控工具不同,Prometheus采用的是主动拉取(pull)模式来收集监控指标,即定期从配置好的目标(如HTTP端点)拉取数据。这种方式简化了监控配置,并使得Prometheus能够更灵活地适应各种服务的变化。
此外,Prometheus的另一个显著特点是其强大的查询语言PromQL。PromQL允许用户通过简洁的表达式来检索和处理时间序列数据,支持多种数学运算、聚合操作和时间序列预测等功能。
Prometheus的架构特点
Prometheus的架构设计独特且具有高度的灵活性。它主要包括以下几个组件:
- 数据收集组件(Prometheus Server):负责数据的收集、存储和查询处理。
- 客户端库(Client Libraries):用于各种语言和应用程序,方便集成监控指标。
- 推送网关(Pushgateway):适用于短期作业,可将指标推送至Prometheus。
- 数据可视化组件(如Grafana):与Prometheus集成,用于数据的可视化展示。
Prometheus的存储机制是另一个亮点。它采用了时间序列数据库来存储数据,这种数据库优化了时间序列数据的读写效率。尽管Prometheus提供了一定的持久化机制,但它的主要设计目标还是在于可靠性和实时性,而不是长期数据存储。
在现代云服务中的作用
Prometheus在微服务架构中尤为重要。随着容器化和微服务的普及,传统的监控系统往往难以应对频繁变化的服务架构和动态的服务发现需求。Prometheus的设计正好适应了这种环境,它能够有效地监控成千上万的端点,及时反馈系统状态,并支持快速的故障检测和定位。
综上所述,Prometheus不仅仅是一个监控工具,更是微服务环境中不可或缺的基础设施组件。通过其高效的数据收集、强大的查询能力和灵活的架构设计,Prometheus为现代云服务提供了强大的监控和警报能力,成为了云原生生态系统中的一个关键角色。
二、Prometheus组成
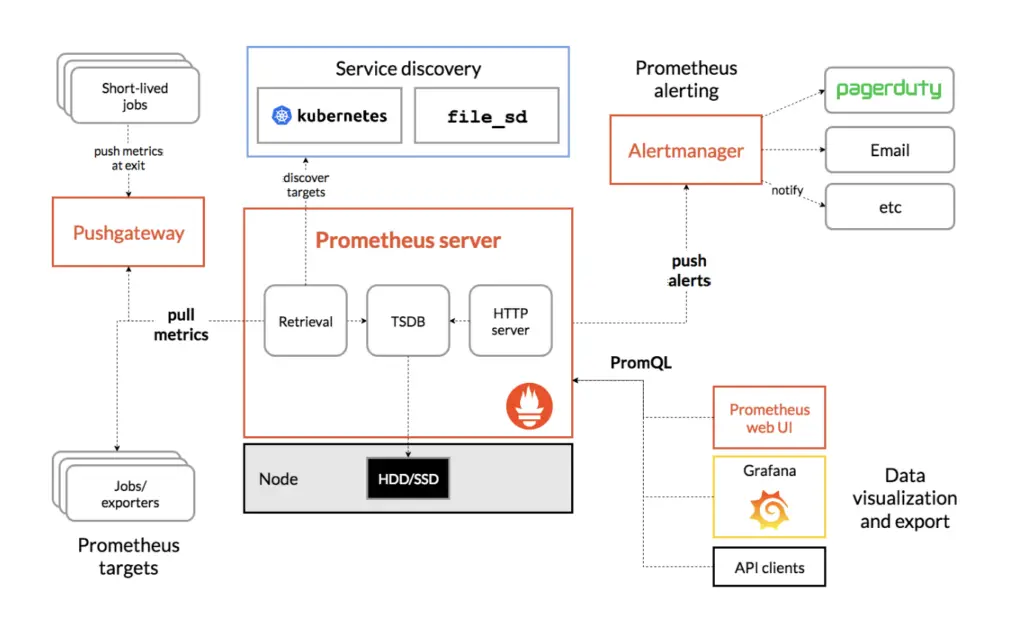
Prometheus架构与组件
Prometheus的架构设计独特,涵盖了从数据采集到存储、查询及警报的全过程。核心组件包括:
1. Prometheus Server
Prometheus Server是整个架构的核心,它负责数据的收集(通过拉取模式)、存储和处理时间序列数据。Server内部由几个关键组件构成:
- 数据采集器(Retrieval):负责从配置的目标中拉取监控数据。
- 时间序列数据库(TSDB):用于存储拉取的监控数据。
- PromQL引擎:处理所有的查询请求。
2. 客户端库
Prometheus提供了多种语言的客户端库,如Go、Java、Python等,允许用户在自己的服务中导出指标。
3. 推送网关(Pushgateway)
对于那些不适合或不能直接被Prometheus Server拉取数据的场景(如批处理作业),Pushgateway作为一个中间层允许这些作业将数据推送至此。
4. 导出器(Exporters)
对于不能直接提供Prometheus格式指标的服务,Exporters可以用来导出这些服务的指标,例如:Node exporter、MySQL exporter等。
5. Alertmanager
用于处理由Prometheus Server发送的警报,支持多种通知方式,并且可以对警报进行分组、抑制和静默等处理。
Prometheus的数据模型
Prometheus的数据模型是理解其功能的关键。在Prometheus中,所有的监控数据都被存储为时间序列,每个时间序列都由唯一的metric name和一系列的标签(键值对)来标识。
1. Metric Types
Prometheus支持多种类型的指标,包括:
- Counter:一个累加值,常用于表示请求数、任务完成数等。
- Gauge:可以任意增减的值,常用于表示温度、内存使用量等。
- Histogram:用于表示观测值的分布,如请求持续时间。
- Summary:与Histogram类似,但提供更多的统计信息。
2. 时间序列数据
每个时间序列由metric name和一系列标签唯一确定。标签使得Prometheus非常适合于处理多维度的监控数据,为用户提供了丰富的查询能力。
PromQL:Prometheus查询语言
PromQL是Prometheus的强大查询语言,它允许用户执行复杂的数据查询和聚合操作。PromQL的关键特点包括:
- 支持多种类型的查询,包括即时查询、范围查询等。
- 支持多种数据聚合操作,如sum、avg、histogram_quantile等。
- 能够处理不同时间序列之间的数学运算。
PromQL的高级特性使得用户能够从庞大的监控数据中提取出有价值的信息,并进行深入的性能分析。
Prometheus的数据采集
Prometheus采用主动拉取(pull)模式来采集监控数据。这意味着Prometheus Server会定期从配置的目标(如HTTP端点)拉取数据。这种方式与传统的被动推送(push)模式相比,具有以下优势:
- 简化了监控配置,因为所有的配置都集中在Prometheus Server端。
- 提高了监控的可靠性,因为Server端可以控制采集频率和重试逻辑。
Prometheus的存储机制
Prometheus使用自带的时间序列数据库来存储监控数据。这个数据库专门为处理时间序列数据而优化,具有高效的数据压缩和快速的查询能力。然而,Prometheus的存储并不适用于长期数据存储。对于需要长期存储监控数据的场景,通常需要与其他外部存储系统(如Thanos或Cortex)集成。
Prometheus的监控和警报
监控和警报是Prometheus的核心功能之一。Prometheus允许用户定义复杂的警报规则,并在规则被触发时发送通知。Alertmanager作为警报的管理组件,支持多种通知方式,包括邮件、Webhook、Slack等。
三、Kubernetes与Prometheus的集成
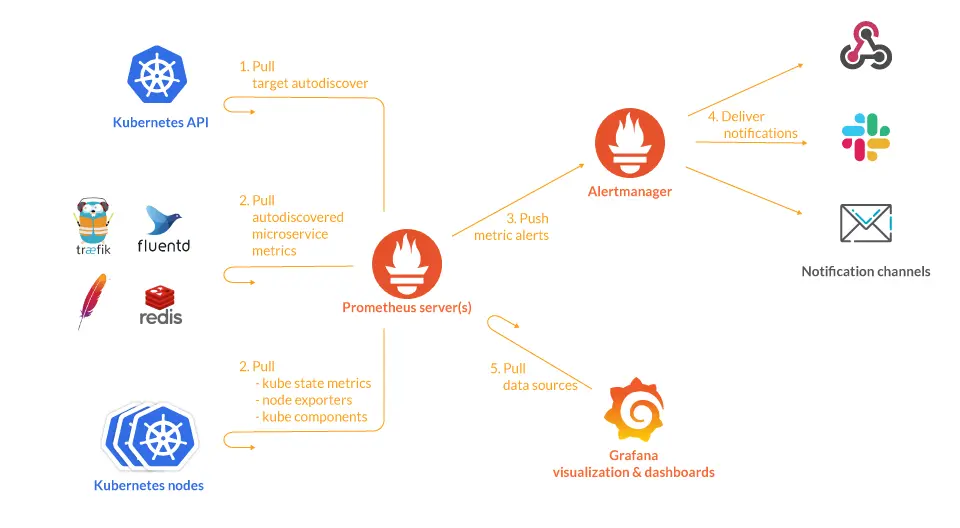
在这一部分中,我们将深入探讨如何将Prometheus与Kubernetes(K8s)集成,以便实现对Kubernetes集群的有效监控。我们将从集成的基本概念开始,探索Prometheus在Kubernetes环境中的部署方式,以及如何配置和使用Prometheus来监控Kubernetes集群。
Kubernetes简介
在深入Prometheus与Kubernetes的集成之前,首先简要回顾一下Kubernetes的核心概念。Kubernetes是一个开源的容器编排平台,用于自动化容器的部署、扩展和管理。它提供了高度的可扩展性和灵活性,使得它成为微服务和云原生应用的理想选择。
核心组件
- 控制平面(Control Plane):集群管理相关的组件,如API服务器、调度器等。
- 工作节点(Nodes):运行应用容器的机器。
- Pods:Kubernetes的基本运行单位,可以容纳一个或多个容器。
部署Prometheus到Kubernetes
将Prometheus部署到Kubernetes中,主要涉及到以下几个步骤:
1. 使用Helm Chart
Helm是Kubernetes的包管理工具,类似于Linux的apt或yum。通过Helm,可以快速部署Prometheus。Prometheus的Helm chart包括了所有必要的Kubernetes资源定义,如Deployments、Services和ConfigMaps。
# 示例:使用Helm部署Prometheus
helm install stable/prometheus --name my-prometheus --namespace monitoring
2. 配置服务发现
为了监控Kubernetes集群中的节点和服务,Prometheus需要配置适当的服务发现机制。Kubernetes服务发现使Prometheus能够自动发现集群中的服务和Pods。
# 示例:Prometheus配置文件中的服务发现部分
scrape_configs:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
3. 设置RBAC规则
由于Prometheus需要访问Kubernetes API来发现服务,因此需要配置相应的RBAC(基于角色的访问控制)规则,以赋予Prometheus所需的权限。
# 示例:Kubernetes RBAC配置
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources: ["nodes", "services", "endpoints", "pods"]
verbs: ["get", "list", "watch"]
监控Kubernetes集群
一旦Prometheus成功部署到Kubernetes,并配置了服务发现,它就可以开始监控Kubernetes集群了。监控的关键点包括:
1. 监控节点和Pods
Prometheus可以收集关于Kubernetes节点和Pods的各种指标,如CPU和内存使用情况、网络流量等。
2. 监控Kubernetes内部组件
除了标准的节点和Pods监控,Prometheus还可以监控Kubernetes的内部组件,如etcd、API服务器、调度器等。
3. 自定义监控指标
对于Kubernetes中运行的应用,可以通过Prometheus的客户端库来导出自定义的监控指标,从而实现对应用的细粒度监控。
Prometheus与Kubernetes的高级集成
随着集群的增长和应用的复杂化,对监控系统的要求也会随之提高。Prometheus与Kubernetes的集成可以进一步扩展,以适应更复杂的监控需求。例如,使用Prometheus Operator可以简化和自动化监控配置的管理。Prometheus Operator定义了一系列自定义资源定义(CRD),如ServiceMonitor,这些CRD可以更为灵活和动态地配置Prometheus监控目标。
配置Prometheus监控Kubernetes
配置Prometheus以监控Kubernetes涉及多个方面,确保监控覆盖到集群的各个组件,并且能够提供实时的反馈和预警。
1. 采集Kubernetes指标
Kubernetes暴露了丰富的指标,可以通过Prometheus收集,这些指标包括节点性能、资源使用情况等。配置Prometheus采集这些指标,需要在Prometheus的配置文件中指定Kubernetes的API作为数据源。
# 示例:配置Prometheus采集Kubernetes指标
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
2. 监控Kubernetes API服务器
Kubernetes API服务器是集群的核心,监控其性能和健康状态对于维护集群稳定性至关重要。通过配置Prometheus,可以收集API服务器的响应时间、请求量等关键指标。
3. 使用ServiceMonitor管理监控目标
在使用Prometheus Operator时,ServiceMonitor资源可以用来更加灵活地管理监控目标。通过定义ServiceMonitor,可以自动发现并监控符合特定标签规则的服务。
# 示例:使用ServiceMonitor定义监控目标
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-service
spec:
selector:
matchLabels:
app: example-app
endpoints:
- port: web
Prometheus在Kubernetes中的高可用性部署
随着监控的重要性日益增加,确保Prometheus在Kubernetes中的高可用性(HA)也变得至关重要。
1. 多副本部署
在Kubernetes中部署多个Prometheus副本,可以提高服务的可用性。通过配置StatefulSet和Persistent Volume,可以保证Prometheus的数据持久性和一致性。
2. 负载均衡和服务发现
使用Kubernetes的负载均衡和服务发现机制,可以确保流量在多个Prometheus副本之间正确分配,并保持监控系统的稳定性。
监控Kubernetes集群的最佳实践
为了最大化Prometheus在Kubernetes中的效能,遵循以下最佳实践至关重要:
1. 精细化监控指标
选择适当的指标进行监控,避免数据过载。重点关注那些对系统性能和健康状况最为关键的指标。
2. 利用标签和注释
充分利用Kubernetes的标签和注释功能,以组织和管理监控目标。这样可以更容易地过滤和查询相关指标。
3. 定期审查和调整告警规则
随着系统的发展和变化,定期审查和调整告警规则是必要的,以确保告警的准确性和及时性。
四、Prometheus监控与告警实战
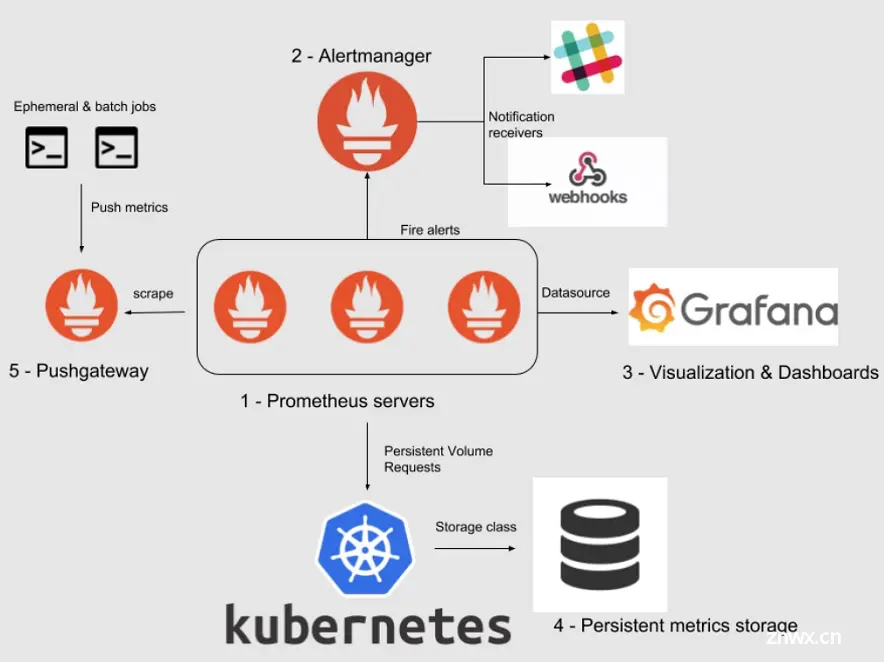
在这一部分中,我们将深入探讨如何在实际环境中应用Prometheus进行监控和告警,包括设置监控指标、配置告警规则、集成告警通知系统,以及进行监控数据的可视化。
监控策略的设定
有效的监控始于明智地选择和配置监控指标。在Prometheus中,监控策略的设定包括以下关键方面:
1. 确定监控目标
明确监控的关键组件,如服务器、数据库、应用程序等。对于每个组件,确定哪些指标是关键的,如CPU使用率、内存占用、网络流量等。
2. 配置指标收集
使用Prometheus的配置文件或客户端库来收集这些关键指标。例如,对于一个Web服务,可以收集HTTP请求的数量、响应时间等。
# 示例:配置Prometheus监控Web服务
scrape_configs:
- job_name: 'web-service'
static_configs:
- targets: ['localhost:9090']
3. 自定义指标
对于特定的业务逻辑或应用程序性能,可以使用Prometheus的客户端库来定义和导出自定义指标。
告警规则的配置
在监控系统中,告警是及时响应问题的关键。在Prometheus中,告警规则的配置包括:
1. 定义告警规则
使用PromQL定义告警条件。例如,如果某个服务的响应时间超过预设阈值,则触发告警。
# 示例:告警规则定义
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
2. 设置告警的持续时间
确定告警条件持续多久后触发告警。这可以防止短暂的指标波动导致的误报。
3. 配置告警标签和注释
通过设置标签和注释来分类告警,并提供更多告警详情,以帮助快速定位问题。
Alertmanager的集成和配置
Alertmanager负责处理由Prometheus发送的告警,并将告警通知发送到不同的接收器,如邮件、Slack等。
1. 配置告警路由
根据告警的严重性和类型配置不同的告警路由,确保告警信息能被正确地发送到相应的处理人或团队。
# 示例:Alertmanager告警路由配置
route:
group_by: ['alertname', 'severity']
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
receiver: 'team-X-mails'
2. 集成多种通知方式
配置不同的通知方式,如邮件、Slack、Webhook等,以适应不同团队的需求。
3. 告警的抑制和静默
在某些情况下,可以配置告警的抑制规则来避免冗余告警,或设置告警静默,以在维护期间停止告警通知。
监控数据的可视化
数据的可视化是监控系统的重要组成部分,它可以帮助团队更直观地理解系统的状态和性能。
1. 使用Grafana集成Prometheus
Grafana是一个流行的开源仪表板工具,可以与Prometheus集成,提供丰富的数据可视化功能。通过Grafana,可以创建实时的监控仪表板,展示关键指标的趋势、分布等。
2. 构建仪表板
在Grafana中构建仪表板,选择合适的图表类型来展示不同的监控指标。可以根据需要创建多个仪表板,针对不同的用户或团队展示相关的监控数据。
3. 设置仪表板告警
Grafana也支持基于仪表板指标的告警功能。可以在Grafana中设置告警规则,并配置告警通知。
实际监控场景应用
实际监控场景中,Prometheus的应用需要根据具体的业务需求和环境进行调整。以下是一些常见的监控场景应用:
1. 微服务监控
在微服务架构中,Prometheus可以监控每个服务的性能和健康状态。通过收集服务响应时间、错误率等指标,可以及时发现和定位问题。
2. 数据库性能监控
对于数据库服务,重要的监控指标包括查询响应时间、事务吞吐量、连接数等。Prometheus可以帮助识别数据库性能瓶颈和潜在的问题。
3. 容器和Kubernetes集群监控
在容器化环境中,Prometheus可以监控容器的资源使用情况,以及Kubernetes集群的整体健康状态,包括节点健康、Pod状态等。
告警优化策略
为了提高告警的有效性和准确性,需要采用一些优化策略:
1. 动态告警阈值
根据历史数据和业务周期性波动,动态调整告警阈值,可以减少误报和漏报。
2. 相关性分析
通过分析不同告警之间的相关性,可以识别出根本原因,防止同一问题产生大量冗余告警。
3. 告警收敛
对于由同一根本原因引起的多个告警,可以将它们合并为一个综合告警,以简化问题的响应和处理。
监控数据的深入分析
除了基本的监控和告警,深入分析监控数据可以提供更多洞察,帮助优化系统性能和资源使用。
1. 长期趋势分析
通过分析长期的监控数据,可以识别系统的性能趋势,预测未来的资源需求,从而进行更有效的容量规划。
2. 异常检测
利用Prometheus收集的数据进行异常检测,可以及时发现系统的异常行为,甚至在问题发生前采取预防措施。
3. 故障诊断
通过详细的监控数据和日志,可以快速定位故障发生的原因,缩短故障恢复时间。
高级数据可视化技巧
高级的数据可视化技巧可以帮助更直观地理解监控数据,包括:
1. 复合图表
使用复合图表显示相关指标的对比和关联,如将CPU使用率和内存使用率在同一图表中展示。
2. 仪表板模板
创建可重用的仪表板模板,可以快速部署到不同的监控场景,提高监控设置的效率。
3. 交互式探索
利用Grafana的交互式探索功能,可以动态地调整查询参数,深入分析特定的监控数据。
关注【TechLeadCloud】,分享互联网架构、云服务技术的全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。