Java 同步锁性能的最佳实践:从理论到实践的完整指南
张彦峰ZYF 2024-08-15 14:05:03 阅读 86
目录
一、同步锁性能分析
(一)性能验证说明
1. 使用同步锁的代码示例
2. 不使用同步锁的代码示例
3. 结果与讨论
(二)案例初步优化分析说明
1. 使用AtomicInteger原子类尝试优化分析
2. 对AtomicInteger原子类进一步优化
3. 结论说明(LongAdder原理理解体会)
二、回顾Java锁优化
(一)synchronized 关键字
1. monitor 锁的实现原理
2.分级锁
偏向锁(Biased Locking)
轻量级锁
重量级锁
3. 锁升级一览
(二)concurrent 包里面的 Lock
1. 锁机制基于线程而不是基于调用(可重入锁)
2. Lock 主要方法
lock()
unlock()
tryLock()
tryLock(long timeout, TimeUnit unit)
lockInterruptibly()
3. 读写锁ReentrantReadWriteLock
基本内容说明
性能验证说明
4.乐观读取、悲观读取和写入的机制:StampedLock
基本内容说明
性能验证说明
5. 公平锁与非公平锁
synchronized关键字 vs Lock接口
功能验证
(三)Java 中两种加锁方式对比和建议
三、锁的优化手段
(一)减少锁的粒度
(二)减少锁持有时间
(三)锁分级
(四)锁分离
(五)锁消除
(六)乐观锁
(七)无锁
参考文章
干货分享,感谢您的阅读!
在多线程编程中,锁是保证线程安全的重要手段之一,但如何选择合适的锁并进行优化,一直是我们面临的挑战。本博客探讨Java中同步锁的性能分析与优化之路,从使用同步锁和不使用同步锁的性能对比入手,逐步展开对锁的优化手段和技术原理的解析,帮助读者更好地理解和应用Java中的锁机制。
一、同步锁性能分析
同步锁在多线程编程中是保证线程安全的重要工具,其性能开销一直是不可忽视的存在。
(一)性能验证说明
为了直观说明我们可以直接先准备两个Java代码用例,我们通过高并发环境下的计数器递增操作来对比使用同步锁和不使用同步锁的性能差异。
1. 使用同步锁的代码示例
使用<code>ReentrantLock来保护对共享资源(counter)的访问,确保同一时间只有一个线程可以对计数器进行操作。具体代码如下:
package org.zyf.javabasic.thread.lock.opti;
import java.util.concurrent.locks.ReentrantLock;
/**
* @program: zyfboot-javabasic
* @description: 使用了ReentrantLock来保护对共享资源(counter)的访问,确保同一时间只有一个线程可以对计数器进行操作。
* @author: zhangyanfeng
* @create: 2024-06-05 22:54
**/
public class SyncLockExample {
private static int counter = 0;
private static final ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
long startTime = System.currentTimeMillis();
Thread[] threads = new Thread[100];
for (int i = 0; i < 100; i++) {
threads[i] = new Thread(new IncrementWithLock());
threads[i].start();
}
for (Thread thread : threads) {
thread.join();
}
long endTime = System.currentTimeMillis();
System.out.println("Time with lock: " + (endTime - startTime) + " ms");
}
static class IncrementWithLock implements Runnable {
@Override
public void run() {
for (int i = 0; i < 1000000; i++) {
lock.lock();
try {
counter++;
} finally {
lock.unlock();
}
}
}
}
}
2. 不使用同步锁的代码示例
不使用任何同步机制,直接操作共享资源。具体代码如下:
package org.zyf.javabasic.thread.lock.opti;
/**
* @program: zyfboot-javabasic
* @description: 不使用任何同步机制,直接操作共享资源。
* @author: zhangyanfeng
* @create: 2024-06-05 22:55
**/
public class NoSyncLockExample {
private static int counter = 0;
public static void main(String[] args) throws InterruptedException {
long startTime = System.currentTimeMillis();
Thread[] threads = new Thread[100];
for (int i = 0; i < 100; i++) {
threads[i] = new Thread(new IncrementWithoutLock());
threads[i].start();
}
for (Thread thread : threads) {
thread.join();
}
long endTime = System.currentTimeMillis();
System.out.println("Time without lock: " + (endTime - startTime) + " ms");
}
static class IncrementWithoutLock implements Runnable {
@Override
public void run() {
for (int i = 0; i < 1000000; i++) {
counter++;
}
}
}
}
3. 结果与讨论
运行以上代码,我当前的机器上可以直观的看到
使用同步锁的时间: 1314 ms不使用同步锁的时间: 20 ms
从结果中可以明显看出,同步锁会带来显著的性能开销。同步锁的存在增加了线程间的等待时间和上下文切换的开销,从而降低了程序的整体运行效率。所以在使用锁时,对锁的优化使用是必不可少的。
(二)案例初步优化分析说明
在开始讲解一些常用的优化手段的时候,我们先就现在这个用例来谈谈可能我们一般可以想到的直观优化手段。
1. 使用AtomicInteger原子类尝试优化分析
Java的java.util.concurrent.atomic包提供了一些原子类,可以在并发编程中避免显式加锁。最简单的我们可以使用AtomicInteger来替代显式的锁。
package org.zyf.javabasic.thread.lock.opti;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @program: zyfboot-javabasic
* @description: 使用AtomicInteger来替代显式的锁
* @author: zhangyanfeng
* @create: 2024-06-05 23:07
**/
public class AtomicExample {
private static AtomicInteger counter = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
long startTime = System.currentTimeMillis();
Thread[] threads = new Thread[100];
for (int i = 0; i < 100; i++) {
threads[i] = new Thread(new IncrementAtomic());
threads[i].start();
}
for (Thread thread : threads) {
thread.join();
}
long endTime = System.currentTimeMillis();
System.out.println("Time with AtomicInteger: " + (endTime - startTime) + " ms");
}
static class IncrementAtomic implements Runnable {
@Override
public void run() {
for (int i = 0; i < 1000000; i++) {
counter.incrementAndGet();
}
}
}
}
理论上这样优化后性能上必会上升,但实际上运行后其耗时为 6714 ms,性能反而变差了。这里其实我们之前的博客中也有讲过,其主要的原因有两个:
原子类的开销:AtomicInteger的incrementAndGet方法虽然是无锁的,但它依赖于底层的CAS(Compare-And-Swap)操作。CAS操作虽然是无锁的,但在高并发情况下,多个线程同时尝试更新同一个变量时,CAS操作可能会频繁地失败并重试,从而导致性能下降。相比之下,ReentrantLock在某些情况下可能反而表现更好,尤其是在锁争用不是特别激烈的时候。高并发下的内存争用:在高并发情况下,多个线程同时访问和修改共享变量会导致内存争用。这种争用在使用AtomicInteger时表现得更为明显,因为每次操作都需要与主内存同步,可能会导致缓存一致性协议的开销。
2. 对AtomicInteger原子类进一步优化
我们可以尝试以下方法来进一步优化:
减少线程数量:在本示例中,我们使用了100个线程同时访问共享变量,这可能导致过多的上下文切换和争用。可以尝试减少线程数量,看看性能是否有所改善。使用更高效的同步机制:可以尝试使用其他同步机制,如LongAdder或ConcurrentLinkedQueue等,这些工具在高并发场景下通常表现更好。
这里我们直接用LongAdder验证,具体代码如下:
package org.zyf.javabasic.thread.lock.opti;
import java.util.concurrent.atomic.LongAdder;
/**
* @program: zyfboot-javabasic
* @description: LongAdder在高并发情况下比AtomicInteger有更好的性能
* @author: zhangyanfeng
* @create: 2024-06-05 23:26
**/
public class LongAdderExample {
private static LongAdder counter = new LongAdder();
public static void main(String[] args) throws InterruptedException {
long startTime = System.currentTimeMillis();
Thread[] threads = new Thread[100];
for (int i = 0; i < 100; i++) {
threads[i] = new Thread(new IncrementLongAdder());
threads[i].start();
}
for (Thread thread : threads) {
thread.join();
}
long endTime = System.currentTimeMillis();
System.out.println("Time with LongAdder: " + (endTime - startTime) + " ms");
}
static class IncrementLongAdder implements Runnable {
@Override
public void run() {
for (int i = 0; i < 1000000; i++) {
counter.increment();
}
}
}
}
运行后发现这个时候的耗时基本在204 ms,优化还是很明显的。
3. 结论说明(LongAdder原理理解体会)
在实际应用中,选择合适的优化方法需要根据具体的业务逻辑和并发需求进行权衡和调整。这里我们针对LongAdder的优化进行说明一下,它是基于了 CAS 分段锁的思想实现的。线程去读写一个 LongAdder 类型的变量时,流程如下:
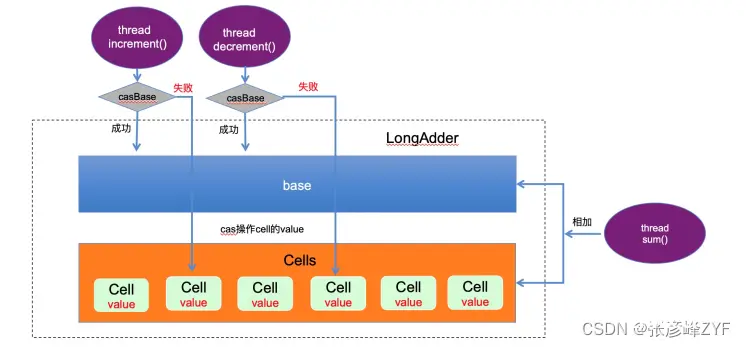
基于 Unsafe 提供的 CAS 操作 +valitale 去实现的。在 LongAdder 的父类 Striped64 中维护着一个 base 变量和一个 cell 数组,当多个线程操作一个变量的时候,先会在这个 base 变量上进行 cas 操作,当它发现线程增多的时候,就会使用 cell 数组。比如当 base 将要更新的时候发现线程增多(也就是调用 casBase 方法更新 base 值失败),那么它会自动使用 cell 数组,每一个线程对应于一个 cell ,在每一个线程中对该 cell 进行 cas 操作,这样就可以将单一 value 的更新压力分担到多个 value 中去,降低单个 value 的 “热度”,同时也减少了大量线程的空转,提高并发效率,分散并发压力。这种分段锁需要额外维护一个内存空间 cells ,不过在高并发场景下,这点成本几乎可以忽略。
我觉得可以把 LongAdder 想象成一个超市收银台系统:
<code>base 变量:一个主收银台,所有顾客最开始都会排队在这里付款。cell 数组:多个备用收银台,当主收银台忙不过来时,顾客会被分配到不同的备用收银台去付款。
这样做的好处是,当有大量顾客(高并发)时,大家不会都挤在一个收银台前,避免了长时间的等待,提高了结账效率。
二、回顾Java锁优化
Java 中的 synchronized 关键字和 java.util.concurrent.locks 包中的 Lock 接口(如 ReentrantLock)是两种常见的加锁方式,它们各有优缺点,针对这两种锁,JDK 自身做了很多的优化,它们的实现方式也是不同的。我们不妨进行简单的回顾一下。
(一)synchronized 关键字
synchronized 关键字给代码或者方法上锁时,都有显示或者隐藏的上锁对象。当一个线程试图访问同步代码块时,它首先必须得到锁,而退出或抛出异常时必须释放锁(注意是 synchronized 关键字的内置机制,由 Java 语言和 JVM 自动管理。我们在使用 synchronized 关键字时,无需手动编写获取和释放锁的代码,synchronized 会自动处理这些细节)。
给普通方法加锁时:锁定对象是实例对象 (this)。相同实例的 synchronized 方法之间是串行的,不同实例之间则不会互相影响。
给静态方法加锁时:锁定对象是类的 Class 对象。所有实例共享同一个类锁,因此静态 synchronized 方法在所有实例上都是串行的。
给代码块加锁时:可以指定任意对象作为锁。锁的粒度更细,可以针对不同的对象分别加锁,灵活控制并发。
synchronized 的实现依赖于 JVM 和操作系统的原语,如监视器锁和信号量。JVM 在执行同步块时,会插入相应的加锁和解锁指令。
1. monitor 锁的实现原理
synchronized 关键字在 Java 字节码中通过监视器(Monitor)指令来实现。具体来说,当 Java 编译器编译包含 synchronized 关键字的代码时,会在相应的位置插入 monitorenter 和 monitorexit 指令。JVM 在运行这些字节码时,会负责管理锁的获取和释放。
对于同步实例方法,编译器在字节码中并不会显式插入 monitorenter 和 monitorexit 指令。相反,它会在方法的访问标志(access flag)中添加 ACC_SYNCHRONIZED 标志。JVM 在调用该方法时会自动获取实例的监视器锁,并在方法返回或抛出异常时自动释放锁。对于同步静态方法,编译器同样会在方法的访问标志中添加 ACC_SYNCHRONIZED 标志。JVM 在调用该方法时会自动获取类的监视器锁,并在方法返回或抛出异常时自动释放锁。对于同步代码块,编译器会在进入同步块时插入 monitorenter 指令,在退出同步块时插入 monitorexit 指令。这些指令用于显式地获取和释放指定的锁对象。
现在我们直观的验证一下:
package org.zyf.javabasic.thread.lock.opti;
/**
* @program: zyfboot-javabasic
* @description: 同步方法和同步代码块的示例类,以及它们在字节码中的表现。
* @author: zhangyanfeng
* @create: 2024-06-06 07:56
**/
public class SynchronizedExample {
private int count = 0;
private final Object lock = new Object();
// 同步实例方法
public synchronized void increment() {
count++;
}
// 同步静态方法
public static synchronized void staticIncrement() {
// 静态方法体
}
// 同步代码块
public void blockIncrement() {
synchronized (lock) {
count++;
}
}
}
可以使用 javap -c SynchronizedExample 命令查看字节码如下:
public synchronized void increment();
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: aload_0
1: getfield #2 // Field count:I
4: iconst_1
5: iadd
6: aload_0
7: swap
8: putfield #2 // Field count:I
11: return
public static synchronized void staticIncrement();
flags: ACC_PUBLIC, ACC_STATIC, ACC_SYNCHRONIZED
Code:
stack=0, locals=0, args_size=0
0: return
public void blockIncrement();
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: aload_0
1: getfield #3 // Field lock:Ljava/lang/Object;
4: dup
5: astore_1
6: monitorenter
7: aload_0
8: dup
9: getfield #2 // Field count:I
12: iconst_1
13: iadd
14: putfield #2 // Field count:I
17: aload_1
18: monitorexit
19: goto 27
22: astore_2
23: aload_1
24: monitorexit
25: aload_2
26: athrow
27: return
Exception table:
from to target type
7 19 22 any
22 25 22 any
正如我们上面总结的一样,整体来说:
使用 ACC_SYNCHRONIZED 标志,JVM 自动处理锁的获取和释放。使用 monitorenter 和 monitorexit 指令显式处理锁的获取和释放,确保在正常退出和异常退出时都能正确释放锁。
这两者虽然显示效果不同,但他们都是通过 monitor 来实现同步的。当一个线程进入一个同步块或同步方法时,它会尝试获取与该对象关联的 Monitor。如果 Monitor 已经被其他线程持有,当前线程将会阻塞,直到 Monitor 被释放。
虽然具体实现可能会根据不同的 JVM 实现有所差异,但通常可以用以下示意来表示 Monitor 的结构:
Monitor {
Thread owner; // 当前持有锁的线程
int recursionCount; // 递归计数器
List<Thread> entryList; // 进入列表,等待获取锁的线程队列
List<Thread> waitSet; // 等待列表,调用 wait() 方法等待的线程队列
List<Thread> exitList; // 退出列表,等待退出的线程队列(可能的实现)
}
锁相关主要的流程如下:

初始状态:多个线程尝试进入同步代码块或方法,所有线程首先进入 <code>EntryList 队列。这些线程处于“Waiting for monitor entry”状态( jstack 命令可查看)。
获取锁的过程:某个线程成功获取 Monitor 后,_owner 变量设置为当前线程,表示该线程持有锁。Monitor 的 _count 计数器自增 1,表示锁被持有的次数。
等待和释放锁:持有 Monitor 的线程调用 wait() 方法时,会释放锁,并进入 WaitSet 队列。释放锁后,_owner 变量恢复为 null,_count 计数器自减 1。线程状态变为“in Object.wait()”,等待被其他线程唤醒。
执行完成释放锁:持有 Monitor 的线程执行完同步代码块或方法时,会释放锁。释放锁后,_owner 变量恢复为 null,_count 计数器自减 1。
唤醒等待的线程:线程调用 notify() 或 notifyAll() 方法时,会唤醒 WaitSet 中的一个或多个线程。被唤醒的线程重新进入 EntryList 队列,等待再次获取 Monitor 锁。
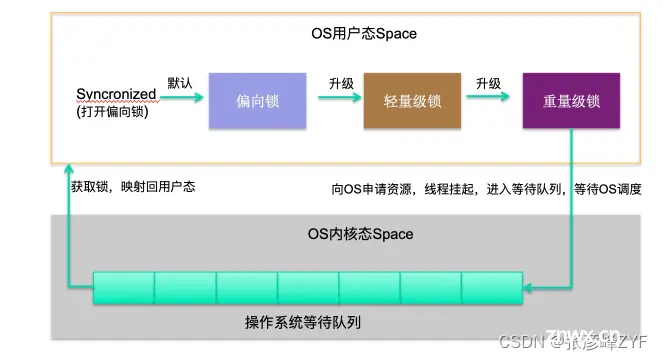
2.分级锁
在 JDK 1.8 中,synchronized 关键字的性能得到了显著提升,这主要得益于 JVM 对锁机制进行了一系列优化:锁的分级及其优化路径(大体可以按照下面的路径进行升级:偏向锁 — 轻量级锁 — 重量级锁,锁只能升级,不能降级,所以一旦升级为重量级锁,就只能依靠操作系统进行调度)。
要想了解锁升级的过程,需要先看一下对象在内存里的结构。
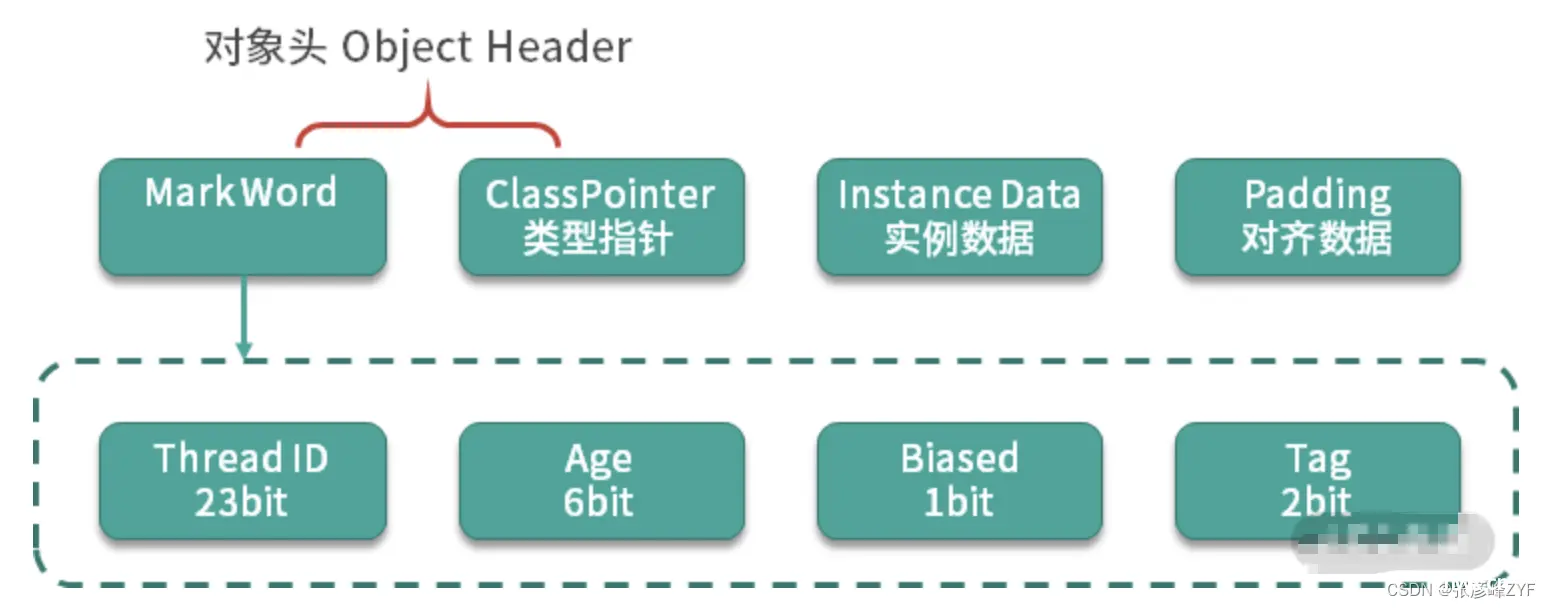
在 Java 中,对象的内存布局中包含了 <code>MarkWord、Class Pointer、Instance Data 和 Padding 等部分。而锁的升级过程主要与对象头的 MarkWord 有关。
要知道MarkWord 是对象头中用于存储对象的运行时信息的。在 64 位 JVM 中,MarkWord 的长度为 64 位。在 32 位 JVM 中,MarkWord 的长度为 32 位(如上图)。
偏向锁(Biased Locking)
单线程高效使用锁:在只有一个线程使用锁的情况下,偏向锁效率最高。获取锁:第一个线程访问同步块时,会检查对象头 Mark Word 的标志位 Tag 是否为 01。如果是,线程将自己的线程 ID 写入 Mark Word,锁进入偏向锁状态。撤销偏向锁:当其他线程尝试获取锁时,如果 Mark Word 中的线程 ID 不匹配,偏向锁会被撤销,升级为轻量级锁。适合单线程场景,高效。
轻量级锁
自旋锁获取:参与竞争的线程会在自己的线程栈中生成一个 LockRecord (LR),通过 CAS(自旋)的方式,将锁对象头中的 Mark Word 设置为指向自己的 LR 的指针。设置成功的线程获得锁。自旋失败:如果自旋多次失败,锁会升级为重量级锁。适合短期竞争,自旋获取锁。
重量级锁
系统调度:重量级锁会导致线程挂起,进入操作系统内核态,等待操作系统调度,然后再映射回用户态。系统调用的开销很高,锁的膨胀到重量级锁就意味着性能下降。激烈竞争:如果共享变量竞争激烈,锁会迅速膨胀为重量级锁。如果并发竞争严重,可以使用 -XX:-UseBiasedLocking 禁用偏向锁,可能会有一些性能提升。适合长期竞争,但性能开销大。
3. 锁升级一览
(二)concurrent 包里面的 Lock
<code>synchronized 是 Java 提供的最基本的同步机制,通过简单易用的语法确保线程安全。然而,随着并发需求的复杂化,Java 的并发包 (java.util.concurrent) 提供了更多高级和高效的并发工具,如 ReentrantLock、ReadWriteLock、Atomic 类等,来应对更复杂的并发场景。在实际开发中,应根据具体情况选择合适的同步机制。现在我们聚焦在Lock进行分析。
1. 锁机制基于线程而不是基于调用(可重入锁)
“这种锁机制基于线程而不是基于调用” 的意思是说,当一个线程持有锁时,它可以在同一个线程的不同调用链中多次获取同一把锁,而不会被阻塞或引发死锁。这是因为锁是跟线程关联的,而不是跟调用栈关联的。
假设有一个对象 example,它有三个同步方法 a、b 和 c,每个方法都被 synchronized 关键字修饰:
package org.zyf.javabasic.thread.lock.opti;
/**
* @program: zyfboot-javabasic
* @description: 锁机制基于线程而不是基于调用
* @author: zhangyanfeng
* @create: 2024-06-07 19:04
**/
public class LockExample {
public synchronized void a() {
System.out.println("In method a");
b(); // 调用 b 方法
}
public synchronized void b() {
System.out.println("In method b");
c(); // 调用 c 方法
}
public synchronized void c() {
System.out.println("In method c");
}
public static void main(String[] args) {
LockExample example = new LockExample();
example.a();
}
}
在 main 方法中,我们调用了 example.a()。在 a 方法内部,又调用了 b 方法,而 b 方法内部又调用了 c 方法。这种调用关系如下:
example.a()
-> example.b()
-> example.c()
当线程调用 example.a() 时,由于 a 方法是同步方法,线程必须先获得对象 example 的锁。在 a 方法内部,线程调用 example.b()。虽然 b 方法也是同步方法,但是由于当前线程已经持有了 example 对象的锁,所以它可以继续执行,不需要再次获取锁。类似地,在 b 方法内部,线程调用 example.c() 时,也不需要再次获取锁。
这个过程中锁是跟线程关联的,而不是跟每次调用关联的。一个线程持有锁之后,可以在它的调用栈中多次获取同一把锁,而不需要重新获取锁,也不会被阻塞。
如果 Java 的锁机制不是基于线程的,而是基于每次调用的,那么在上面的示例中,线程在调用 b 方法时会尝试再次获取 example 对象的锁,但是由于它已经持有这个锁,这将导致死锁。因此,基于线程的锁机制(即可重入锁)避免了这种情况,使得一个线程在持有锁时,可以多次获取同一把锁。Java 的 ReentrantLock 类也支持可重入性,将以上synchronized替换成其效果也是一样的。
像上面这样,在并发编程中,可重入锁(Reentrant Lock)指的是一个线程可以多次获得同一把锁。可重入锁的作用在于避免线程死锁,当一个线程已经持有了一个锁,再次请求该锁时可以直接获取,而无需再次等待。这种锁机制基于线程而不是基于调用。
2. Lock 主要方法
在 Java 的并发编程中,Lock 接口提供了比 synchronized 更加灵活和强大的锁机制。Lock 与 synchronized 的使用方法不同,它需要手动加锁,然后在 finally 中解锁。
Lock 接口是基于 AQS(AbstractQueuedSynchronizer)实现的,而 AQS 又依赖于 volatile 和 CAS(Compare-And-Swap)操作来实现线程的同步控制。其中AQS基本原理可见文章从ReentrantLock理解AQS的原理及应用总结,我们这里暂时增加一张原文图片进行体会理解:
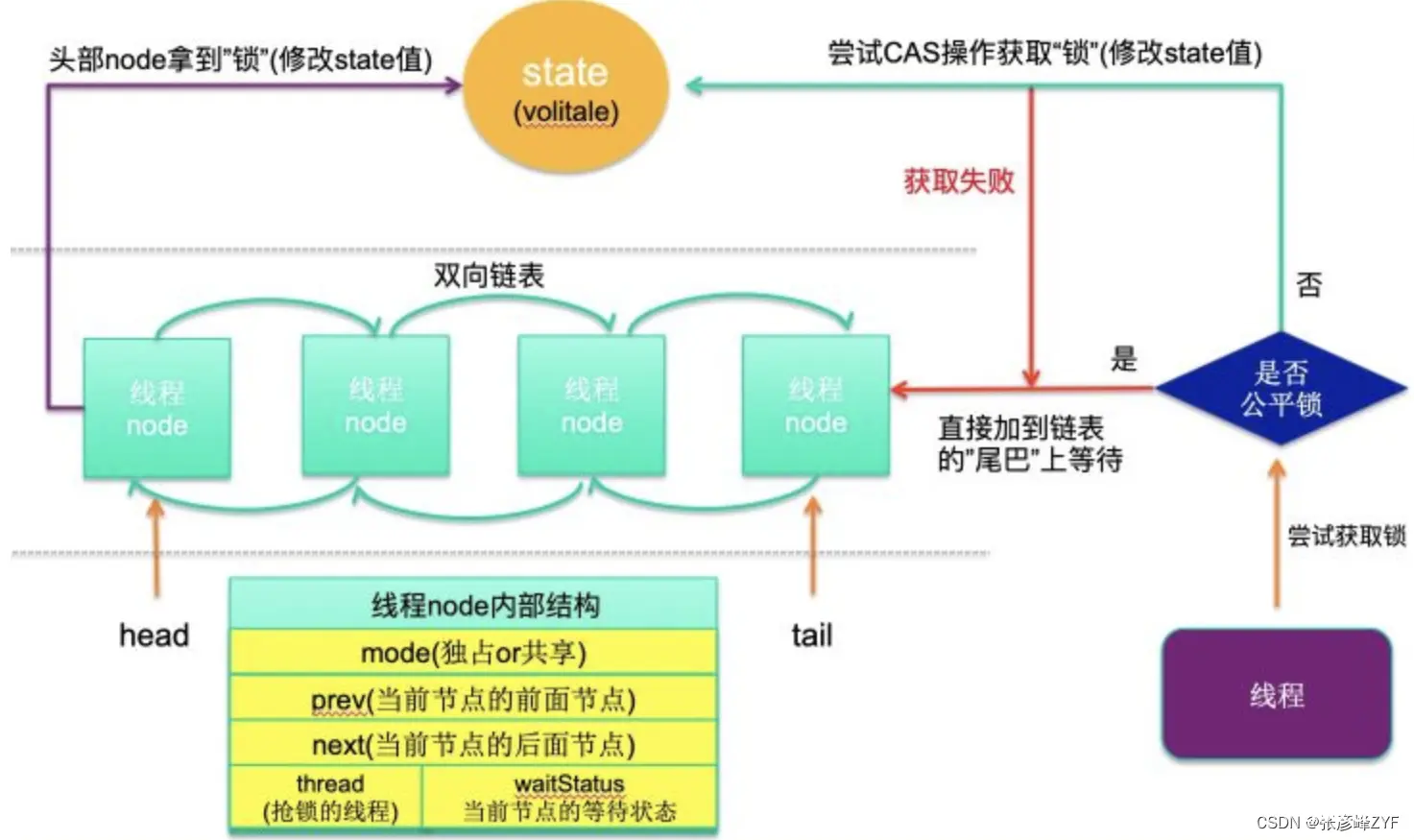
现在我们来看一下几个关键方法:
lock()
获取锁。如果锁已经被其他线程持有,则当前线程将被阻塞,直到获取到锁。和 synchronized 没什么区别,如果获取不到锁,都会被阻塞;
<code>lock.lock();
try {
// critical section
} finally {
lock.unlock();
}
unlock()
释放锁。通常在 finally 块中调用,以确保锁在使用之后总是被释放。重申需要手动加锁,然后在 finally 中解锁,在 finally 中解锁,在 finally 中解锁。
tryLock()
尝试获取锁。如果锁可用,则获取锁并返回 true,否则返回 false。该方法不会阻塞线程。
if (lock.tryLock()) {
try {
// critical section
} finally {
lock.unlock();
}
} else {
// handle lock not acquired
}
tryLock(long timeout, TimeUnit unit)
尝试在给定的时间范围内获取锁。如果在指定时间内获取到锁,则返回 true,否则返回 false。
if (lock.tryLock(1, TimeUnit.SECONDS)) {
try {
// critical section
} finally {
lock.unlock();
}
} else {
// handle lock not acquired
}
lockInterruptibly()
获取锁,但与 lock() 不同的是,这个方法允许响应中断。如果线程在等待锁的过程中被中断,则抛出 InterruptedException。
try {
lock.lockInterruptibly();
try {
// critical section
} finally {
lock.unlock();
}
} catch (InterruptedException e) {
// handle interrupt
}
平时开发中建议在需要及时响应的业务场景下使用带超时时间的 tryLock 方法。基本建议如下:
普通场景:使用 lock() 方法即可,确保线程安全。高并发、及时响应场景:使用带超时时间的 tryLock 方法,保证服务的高可用性和快速响应能力。
3. 读写锁ReentrantReadWriteLock
在高并发场景下,对于一些业务来说,使用 Lock 这种粗粒度的锁可能会导致性能瓶颈。例如,对于一个 HashMap,如果业务场景是读多写少,给读操作加上和写操作一样的锁会大大降低效率。因为在这种情况下,读操作会频繁发生,而每次读操作都被迫等待写锁的释放,这样就大大降低了系统的吞吐量。
为了解决这类问题,我们可以使用 ReentrantReadWriteLock(一种读写分离的锁机制)。ReentrantReadWriteLock 提供了两种锁:读锁(ReadLock)和写锁(WriteLock),其核心思想是将读操作和写操作分离开来,从而提高系统的并发性能。
基本内容说明
读锁:允许多个线程同时获取读锁,进行并发读操作。读锁之间是共享的,多个读线程可以同时读取而不会相互阻塞。写锁:只有一个线程可以获取写锁,进行写操作。写锁之间是互斥的,写线程会阻塞其他写线程。读写互斥:读操作和写操作之间是互斥的,当一个线程持有写锁时,其他线程不能获取读锁。这样保证了数据的一致性和线程安全。
性能验证说明
为了更直观地对比 ReentrantReadWriteLock 在读多写少场景中的性能优势,我们可以编写一个性能测试用例,比较使用 ReentrantReadWriteLock 和 ReentrantLock 的性能差异。
private static final int NUM_OPERATIONS = 10000;
private static final int NUM_THREADS = 10;
public static void main(String[] args) throws InterruptedException {
// Test with ReentrantLock
long startTime = System.currentTimeMillis();
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < NUM_OPERATIONS / NUM_THREADS; j++) {
reentrantLock.lock();
try {
map.put("key" + j, "value" + j);
} finally {
reentrantLock.unlock();
}
}
});
}
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
long endTime = System.currentTimeMillis();
System.out.println("ReentrantLock Write Time: " + (endTime - startTime) + " ms");
// Test with ReentrantReadWriteLock
startTime = System.currentTimeMillis();
for (int i = 0; i < NUM_THREADS; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < NUM_OPERATIONS / NUM_THREADS; j++) {
writeLock.lock();
try {
map.put("key" + j, "value" + j);
} finally {
writeLock.unlock();
}
}
});
}
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
endTime = System.currentTimeMillis();
System.out.println("ReentrantReadWriteLock Write Time: " + (endTime - startTime) + " ms");
}
运行结果如下:
ReentrantLock 的写入时间为 63 ms;ReentrantReadWriteLock 的写入时间为 32 ms
这个结果看起来ReentrantReadWriteLock 的写入时间比 ReentrantLock 要快,这表明在这种情况下,读写分离的锁确实能够提高性能。
4.乐观读取、悲观读取和写入的机制:StampedLock
StampedLock 是在 Java 8 中引入的,它提供了一种乐观读取、悲观读取和写入的机制,可以比 ReentrantReadWriteLock 更高效地支持读写分离。StampedLock 不支持重入,因此在使用时需要特别注意避免死锁的情况。
基本内容说明
StampedLock 主要有三种锁模式:
写锁(writeLock):与普通的互斥锁类似,一次只能被一个线程持有。当一个线程持有写锁时,任何其他线程试图获取写锁或者悲观读锁都会被阻塞。悲观读锁(readLock):与 ReentrantReadWriteLock 中的读锁类似,用于读取共享数据。当一个线程持有悲观读锁时,其他线程试图获取写锁的请求会被阻塞,但不会阻塞其他悲观读锁的获取请求。乐观读锁(tryOptimisticRead):是一种乐观的读取模式,允许多个线程同时访问共享数据,不会阻塞其他线程的写入操作。但在使用乐观读锁时,需要通过 validate 方法来验证读取操作是否有效。
通过合理地选择锁模式,可以使 StampedLock 在某些情况下比传统的读写锁更高效。
性能验证说明
使用 StampedLock 和 ReentrantReadWriteLock 来实现读写分离,并比较它们的性能:
package org.zyf.javabasic.thread.lock.opti;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
import java.util.concurrent.locks.StampedLock;
/**
* @program: zyfboot-javabasic
* @description: 使用 StampedLock 和 ReentrantReadWriteLock 来实现读写分离,并比较它们的性能。
* @author: zhangyanfeng
* @create: 2024-06-07 22:35
**/
public class StampedLockVsReentrantReadWriteLock {
private static final int NUM_THREADS = 200;
private static final int NUM_OPERATIONS = 5000000;
private static volatile int sharedVariable = 0;
public static void main(String[] args) throws InterruptedException {
long start, end;
// Test with StampedLock
StampedLock stampedLock = new StampedLock();
start = System.currentTimeMillis();
Thread[] stampedLockWriteThreads = new Thread[NUM_THREADS];
Thread[] stampedLockReadThreads = new Thread[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; i++) {
stampedLockWriteThreads[i] = new Thread(() -> {
for (int j = 0; j < NUM_OPERATIONS; j++) {
long stamp = stampedLock.writeLock();
try {
sharedVariable++;
} finally {
stampedLock.unlockWrite(stamp);
}
}
});
stampedLockWriteThreads[i].start();
stampedLockReadThreads[i] = new Thread(() -> {
for (int j = 0; j < NUM_OPERATIONS; j++) {
long stamp = stampedLock.readLock();
try {
int value = sharedVariable;
} finally {
stampedLock.unlockRead(stamp);
}
}
});
stampedLockReadThreads[i].start();
}
for (Thread thread : stampedLockWriteThreads) {
thread.join();
}
for (Thread thread : stampedLockReadThreads) {
thread.join();
}
end = System.currentTimeMillis();
System.out.println("StampedLock Write and Read Time: " + (end - start) + " ms");
// Test with ReentrantReadWriteLock
ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock();
Lock writeLock = rwLock.writeLock();
Lock readLock = rwLock.readLock();
start = System.currentTimeMillis();
Thread[] rwLockWriteThreads = new Thread[NUM_THREADS];
Thread[] rwLockReadThreads = new Thread[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; i++) {
rwLockWriteThreads[i] = new Thread(() -> {
for (int j = 0; j < NUM_OPERATIONS; j++) {
writeLock.lock();
try {
sharedVariable++;
} finally {
writeLock.unlock();
}
}
});
rwLockWriteThreads[i].start();
rwLockReadThreads[i] = new Thread(() -> {
for (int j = 0; j < NUM_OPERATIONS; j++) {
readLock.lock();
try {
int value = sharedVariable;
} finally {
readLock.unlock();
}
}
});
rwLockReadThreads[i].start();
}
for (Thread thread : rwLockWriteThreads) {
thread.join();
}
for (Thread thread : rwLockReadThreads) {
thread.join();
}
end = System.currentTimeMillis();
System.out.println("ReentrantReadWriteLock Write and Read Time: " + (end - start) + " ms");
}
}
运行结果如下:
StampedLock 的写入和读取时间为 21200 ms;ReentrantReadWriteLock 的写入和读取时间为 26779 ms
结果来看StampedLock 的性能优于 ReentrantReadWriteLock。StampedLock 在这种情况下的表现更好,这与其内部实现机制有关。StampedLock 使用乐观读锁来提高并发性,而 ReentrantReadWriteLock 使用悲观读锁。在适当的情况下,StampedLock 能够更高效地支持读写分离,这通常在读操作远远多于写操作的情况下更为明显。
5. 公平锁与非公平锁
非公平锁允许在释放锁时不考虑等待队列中的其他线程的情况,新的线程可以立即争抢锁。这种情况下,可能存在某些线程总是无法获取锁的情况,造成线程饥饿。
相反,公平锁确保等待时间最长的线程会被优先选择来获取锁,这样每个线程都有机会获取到锁,避免了饥饿现象。在公平锁中,线程按照请求锁的顺序进入队列,并按顺序获取锁。
synchronized关键字 vs Lock接口
在Java中,synchronized关键字使用的是非公平锁,而在Lock接口的实现类中,可以通过构造函数来选择使用公平锁或非公平锁。
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
公平锁的实现需要维护一个有序的等待队列,因此在多核场景下,可能会降低吞吐量。这个在一开始讲Lock的时候我们就已经提过了,这里图在放一下:
功能验证
<code>package org.zyf.javabasic.thread.lock.opti;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @program: zyfboot-javabasic
* @description: 比较非公平锁和公平锁的性能
* @author: zhangyanfeng
* @create: 2024-06-08 00:07
**/
public class LockPerformanceComparison {
private static final int NUM_THREADS = 10;
private static final int NUM_ITERATIONS = 1000000;
private static final Lock unfairLock = new ReentrantLock();
private static final Lock fairLock = new ReentrantLock(true); // 公平锁
public static void main(String[] args) {
System.out.println("Unfair Lock Performance Test");
testLock(unfairLock);
System.out.println("Fair Lock Performance Test");
testLock(fairLock);
}
private static void testLock(Lock lock) {
long startTime = System.currentTimeMillis();
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < NUM_ITERATIONS; j++) {
lock.lock();
try {
// 模拟一些计算或任务
Math.pow(Math.random(), Math.random());
} finally {
lock.unlock();
}
}
});
}
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long endTime = System.currentTimeMillis();
System.out.println("Execution Time: " + (endTime - startTime) + " ms");
}
}
运行结果如下:
Unfair Lock Performance Test:Execution Time: 3338 msFair Lock Performance Test:Execution Time: 26218 ms
可以看到非公平锁(Unfair Lock)的性能明显优于公平锁(Fair Lock)。这是因为公平锁需要维护一个有序的等待队列,以确保线程按照它们的请求顺序获得锁。相比之下,非公平锁允许线程在锁可用时立即获取锁,而不考虑它们的请求顺序,因此效率更高。
在实际应用中,如果不需要严格的线程调度顺序,通常会选择使用非公平锁来获得更好的性能。
(三)Java 中两种加锁方式对比和建议
| 类别 | Synchronized | Lock |
|---|---|---|
| 实现方式 | monitor | AQS |
| 底层细节 | JVM优化 | Java API |
| 分级锁 | 是 | 否 |
| 功能特性 | 单一 | 丰富 |
| 锁分离 | 无 | 读写锁 |
| 锁超时 | 无 | 带超时时间的 tryLock |
| 可中断 | 否 | lockInterruptibly |
Lock 的功能是比 Synchronized 多的,能够对线程行为进行更细粒度的控制。但如果只是用最简单的锁互斥功能,建议直接使用 Synchronized,有两个原因:
Synchronized 的编程模型更加简单,更易于使用Synchronized 引入了偏向锁,轻量级锁等功能,能够从 JVM 层进行优化,同时JIT 编译器也会对它执行一些锁消除动作。
三、锁的优化手段
Java 中有两种加锁的方式:一种就是常见的synchronized 关键字,另外一种,就是使用 concurrent 包里面的 Lock。针对这两种锁,JDK 自身做了很多的优化,它们的实现方式也是不同的。这个在上文中已经讲了很多,我们体会的已经比较深了,现在站在巨人的肩膀上总结一下优化的一般思路:减少锁的粒度、减少锁持有的时间、锁分级、锁分离 、锁消除、乐观锁、无锁等。

(一)减少锁的粒度
锁粒度(Lock Granularity)指的是锁定的资源范围大小。锁的粒度越大,意味着锁定的资源范围越广,可能会导致更多的线程阻塞等待锁的释放;锁的粒度越小,意味着锁定的资源范围越窄,可以减少线程的阻塞和等待时间。
减少锁粒度是指通过细化锁的范围和控制的资源,来减少线程之间的冲突和竞争,从而提高并发性和系统性能。
假设我们有一个大型整数数组,多个线程需要同时对该数组进行读写操作。我们可以将数组分成多个段,每个段使用一个独立的锁,从而允许不同线程并行访问不同段的数据。
先看使用单个锁的 <code>SingleLockArray:使用一个全局锁来保护整个数组。所有线程在访问数组时都需要获取这把锁,因此会导致更多的锁竞争和阻塞。
package org.zyf.javabasic.thread.lock.opti;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @program: zyfboot-javabasic
* @description: 使用一个全局锁来保护整个数组。所有线程在访问数组时都需要获取这把锁,因此会导致更多的锁竞争和阻塞。
* @author: zhangyanfeng
* @create: 2024-06-08 01:02
**/
public class SingleLockArray {
private static final int ARRAY_SIZE = 10000;
private final int[] array = new int[ARRAY_SIZE];
private final Lock lock = new ReentrantLock();
public void increment(int index) {
lock.lock();
try {
array[index]++;
} finally {
lock.unlock();
}
}
public int get(int index) {
lock.lock();
try {
return array[index];
} finally {
lock.unlock();
}
}
}
在看使用分段锁的 SegmentLockArray:将数组分成多个段,每个段使用一个独立的锁。这样,当多个线程访问不同段的数据时,可以并行执行,而不会相互阻塞。
package org.zyf.javabasic.thread.lock.opti;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @program: zyfboot-javabasic
* @description: 将数组分成多个段,每个段使用一个独立的锁。这样,当多个线程访问不同段的数据时,可以并行执行,而不会相互阻塞
* @author: zhangyanfeng
* @create: 2024-06-08 01:06
**/
public class SegmentLockArray {
private static final int NUM_SEGMENTS = 10;
private static final int SEGMENT_SIZE = 1000;
private static final int ARRAY_SIZE = NUM_SEGMENTS * SEGMENT_SIZE;
private final int[] array = new int[ARRAY_SIZE];
private final Lock[] locks = new ReentrantLock[NUM_SEGMENTS];
public SegmentLockArray() {
for (int i = 0; i < NUM_SEGMENTS; i++) {
locks[i] = new ReentrantLock();
}
}
public void increment(int index) {
int segment = index / SEGMENT_SIZE;
locks[segment].lock();
try {
array[index]++;
} finally {
locks[segment].unlock();
}
}
public int get(int index) {
int segment = index / SEGMENT_SIZE;
locks[segment].lock();
try {
return array[index];
} finally {
locks[segment].unlock();
}
}
}
进行验证说明
package org.zyf.javabasic.thread.lock.opti;
import java.util.concurrent.ThreadLocalRandom;
/**
* @program: zyfboot-javabasic
* @description: 对比
* @author: zhangyanfeng
* @create: 2024-06-08 01:07
**/
public class LockArrayPerComparison {
private static final int NUM_SEGMENTS = 10;
private static final int SEGMENT_SIZE = 1000;
private static final int ARRAY_SIZE = NUM_SEGMENTS * SEGMENT_SIZE;
public static void main(String[] args) throws InterruptedException {
SegmentLockArray array = new SegmentLockArray();
int numThreads = 100;
Thread[] threads = new Thread[numThreads];
// Writing threads
for (int i = 0; i < numThreads / 2; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
int index = ThreadLocalRandom.current().nextInt(ARRAY_SIZE);
array.increment(index);
}
});
}
// Reading threads
for (int i = numThreads / 2; i < numThreads; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
int index = ThreadLocalRandom.current().nextInt(ARRAY_SIZE);
array.get(index);
}
});
}
long startTime = System.currentTimeMillis();
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
thread.join();
}
long endTime = System.currentTimeMillis();
System.out.println("Execution Time with Segment Locks: " + (endTime - startTime) + " ms");
// Compare with single lock
SingleLockArray singleLockArray = new SingleLockArray();
Thread[] singleLockThreads = new Thread[numThreads];
// Writing threads
for (int i = 0; i < numThreads / 2; i++) {
singleLockThreads[i] = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
int index = ThreadLocalRandom.current().nextInt(ARRAY_SIZE);
singleLockArray.increment(index);
}
});
}
// Reading threads
for (int i = numThreads / 2; i < numThreads; i++) {
singleLockThreads[i] = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
int index = ThreadLocalRandom.current().nextInt(ARRAY_SIZE);
singleLockArray.get(index);
}
});
}
startTime = System.currentTimeMillis();
for (Thread thread : singleLockThreads) {
thread.start();
}
for (Thread thread : singleLockThreads) {
thread.join();
}
endTime = System.currentTimeMillis();
System.out.println("Execution Time with Single Lock: " + (endTime - startTime) + " ms");
}
}
运行结果如下:
Execution Time with Segment Locks: 94 msExecution Time with Single Lock: 40 ms
可以看到使用分段锁的 SegmentLockArray 的执行时间明显优于使用单个锁的 SingleLockArray,特别是在高并发的场景下。这样,通过减少锁粒度,我们可以显著提高系统的并发性能。
(二)减少锁持有时间
通过让锁资源尽快地释放,减少锁持有的时间,其他线程可更迅速地获取锁资源,进行其他业务的处理。
我们使用两个计数器类,一个是未优化的版本,另一个是优化后的版本。
未优化的版本(UnoptimizedCounter):具体代码如下展示,在锁定的代码块中进行了模拟的工作(Thread.sleep(1)),导致锁的持有时间较长,从而增加了锁竞争和线程阻塞的时间。
package org.zyf.javabasic.thread.lock.opti;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @program: zyfboot-javabasic
* @description: 未优化的版本
* @author: zhangyanfeng
* @create: 2024-06-08 01:22
**/
public class UnoptimizedCounter {
private int count = 0;
private final Lock lock = new ReentrantLock();
public void increment() {
lock.lock();
try {
// Simulate some work that doesn't need to be locked
Thread.sleep(1);
count++;
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public int getCount() {
lock.lock();
try {
return count;
} finally {
lock.unlock();
}
}
}
优化后的版本(OptimizedCounter):将模拟的工作(`Thread.sleep(1))移到了锁定代码块之外。锁的持有时间大幅减少,锁定代码块仅包含了必要的操作(count++),减少了锁竞争和线程阻塞的时间,从而提高了系统的并发性能。
package org.zyf.javabasic.thread.lock.opti;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @program: zyfboot-javabasic
* @description: 优化后的版本
* @author: zhangyanfeng
* @create: 2024-06-08 01:23
**/
public class OptimizedCounter {
private int count = 0;
private final Lock lock = new ReentrantLock();
public void increment() {
try {
// Simulate some work that doesn't need to be locked
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
public int getCount() {
lock.lock();
try {
return count;
} finally {
lock.unlock();
}
}
}
我们将通过创建多个线程对这两个计数器进行并发操作,并测量它们的执行时间:
package org.zyf.javabasic.thread.lock.opti;
/**
* @program: zyfboot-javabasic
* @description: LockPerformanceTest
* @author: zhangyanfeng
* @create: 2024-06-08 01:24
**/
public class LockTimePerformanceTest {
private static final int NUM_THREADS = 10;
private static final int NUM_ITERATIONS = 1000;
public static void main(String[] args) throws InterruptedException {
System.out.println("UnoptimizedCounter Performance Test");
UnoptimizedCounter unoptimizedCounter = new UnoptimizedCounter();
testCounterPerformance(unoptimizedCounter);
System.out.println("OptimizedCounter Performance Test");
OptimizedCounter optimizedCounter = new OptimizedCounter();
testCounterPerformance(optimizedCounter);
}
private static void testCounterPerformance(Object counter) throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
long startTime = System.currentTimeMillis();
for (int i = 0; i < NUM_THREADS; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < NUM_ITERATIONS; j++) {
if (counter instanceof UnoptimizedCounter) {
((UnoptimizedCounter) counter).increment();
} else if (counter instanceof OptimizedCounter) {
((OptimizedCounter) counter).increment();
}
}
});
threads[i].start();
}
for (Thread thread : threads) {
thread.join();
}
long endTime = System.currentTimeMillis();
System.out.println("Execution Time: " + (endTime - startTime) + " ms");
if (counter instanceof UnoptimizedCounter) {
System.out.println("Final count (Unoptimized): " + ((UnoptimizedCounter) counter).getCount());
} else if (counter instanceof OptimizedCounter) {
System.out.println("Final count (Optimized): " + ((OptimizedCounter) counter).getCount());
}
}
}
运行结果如下:
UnoptimizedCounter Performance Test:Execution Time: 12656 msOptimizedCounter Performance Test:Execution Time: 1254 ms
优化后的版本(OptimizedCounter)应该会显示更短的执行时间,从而验证了减少锁持有时间对性能的优化效果。
(三)锁分级
JVM中的锁分级机制主要包括偏向锁、轻量级锁和重量级锁。这些锁的分级和升级是为了在不同的线程竞争情况下,尽可能地减少锁的开销和提升性能。
锁的升级过程是不可逆的,即从偏向锁到轻量级锁,再到重量级锁。如果一个锁已经升级为重量级锁,即使之后的竞争减少,也不会降级回轻量级锁或偏向锁。这样做是为了简化JVM的实现,避免复杂的锁降级逻辑带来的额外开销。
这个在上文第二部分的开头就已经讲过了。
(四)锁分离
锁分离是一种针对不同类型操作进行区分的优化技术,通过使用不同的锁来分别处理读操作和写操作,来提高并发性能。读写锁(ReentrantReadWriteLock)就是一种典型的锁分离技术的实现。锁分离的核心思想在于,读操作和写操作对资源的影响不同,可以采用不同的锁策略来优化性能。
其优化版本StampedLock 的性能优于 ReentrantReadWriteLock,StampedLock 使用乐观读锁来提高并发性,而 ReentrantReadWriteLock 使用悲观读锁。在适当的情况下,StampedLock 能够更高效地支持读写分离,这通常在读操作远远多于写操作的情况下更为明显。
具体验证代码在上方第二部分的Lock中已经给出了样例,请使用中自行选择。
(五)锁消除
锁消除(Lock Elimination)是指 JVM 通过分析代码的运行范围,判断出某些锁在多线程环境下没有竞争,因此可以去掉这些锁操作。这个过程是由 JVM 在运行时通过即时编译器(JIT 编译器)和逃逸分析来决定的。
逃逸分析(Escape Analysis)是锁消除的关键技术。它分析对象的作用范围,判断对象是否会逃逸出方法或线程。如果某个对象只在方法内部使用,并且不会逃逸出这个方法,则认为这个对象是线程私有的,锁操作就没有实际意义,可以消除。
考虑以下两个字符串拼接的示例:
package org.zyf.javabasic.thread.lock.opti;
/**
* @program: zyfboot-javabasic
* @description: 两个字符串拼接的示例
* @author: zhangyanfeng
* @create: 2024-06-08 01:49
**/
public class LockEliminationExample {
public static void main(String[] args) {
long startTime;
long endTime;
// Test with StringBuffer
startTime = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
concatenateStringBuffer("Hello", "World");
}
endTime = System.currentTimeMillis();
System.out.println("StringBuffer Execution Time: " + (endTime - startTime) + " ms");
// Test with StringBuilder
startTime = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
concatenateStringBuilder("Hello", "World");
}
endTime = System.currentTimeMillis();
System.out.println("StringBuilder Execution Time: " + (endTime - startTime) + " ms");
}
public static String concatenateStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
public static String concatenateStringBuilder(String s1, String s2) {
StringBuilder sb = new StringBuilder();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
}
StringBuffer 和 StringBuilder 都用于字符串拼接,但 StringBuffer 是线程安全的,通过内部使用的同步机制(锁)来保证线程安全,而 StringBuilder 则是非线程安全的,没有同步机制。
当 JVM 通过逃逸分析发现 StringBuffer 对象没有逃逸出方法时,就会将其锁操作消除,从而使得它的性能和 StringBuilder 接近。
(六)乐观锁
乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作(例如报错或者自动重试)
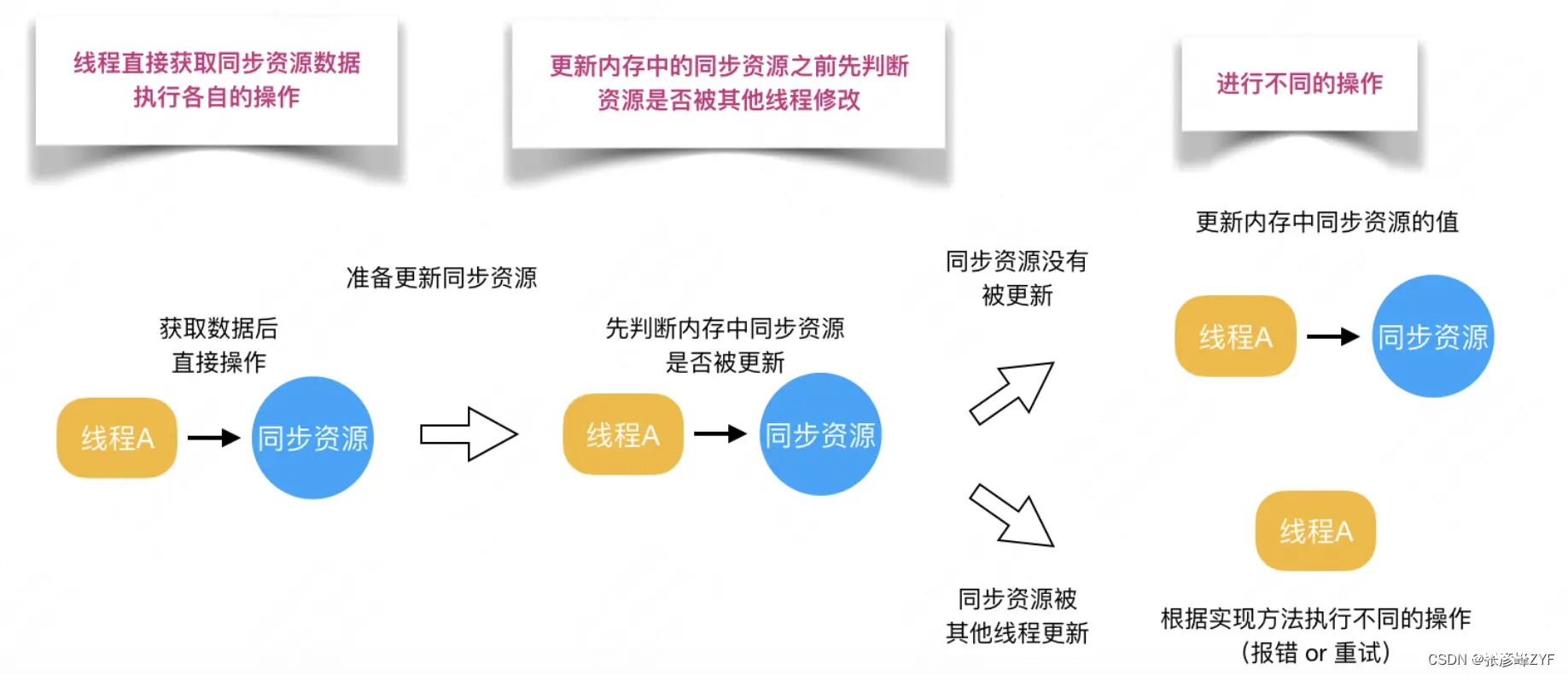
在Java中是通过使用无锁编程来实现,最常采用的是CAS算法,Java原子类中的递增操作就通过CAS自旋实现的。具体的理论和使用验证可见:Java中常用的锁总结与理解
当然最直接的可见:超越并发瓶颈:CAS与乐观锁的智慧应用
(七)无锁
无锁队列是一种在多线程环境下访问共享资源的方式,它不会阻塞其他线程的执行。在 Java 中,最典型的无锁队列实现是 ConcurrentLinkedQueue,它使用CAS(Compare and Swap)指令来处理对数据的并发访问。CAS指令是一种非阻塞的原子操作,不会引起上下文切换和线程调度,因此是一种非常轻量级的多线程同步机制。
ConcurrentLinkedQueue的实现基于CAS机制,它将队列的入队和出队等操作拆分为更细粒度的步骤,进一步减小了CAS控制的范围,提高了并发性能。与之相对应的是阻塞队列LinkedBlockingQueue,它内部使用锁机制来实现同步,因此性能没有无锁队列高。
除了ConcurrentLinkedQueue外,还有一种无锁队列框架叫做Disruptor,它是一个无锁、有界的队列框架,具有极高的性能。Disruptor使用RingBuffer、无锁和缓存行填充等技术来实现高效的并发访问,适用于极高并发的场景,比如日志、消息等中间件。尽管Disruptor的编程模型相对复杂,但在需要极致性能的场景下,可以取代传统的阻塞队列。
参考文章
Java synchronized 关键字(3)-JVM 重量级锁 Monitor 的实现_jvm中monitor的实现原理-CSDN博客
JAVA多线程学习-------monitor所实现原理_java objectmonitor 原理-CSDN博客
Monitor工作原理&synchronized锁膨胀过程及其优化_rom monitor软件的工作原理-CSDN博客
synchronized底层monitor原理_synchronized monitor原理-CSDN博客
https://zhuanlan.zhihu.com/p/581418806
https://juejin.cn/post/7131739806156980232
https://www.51cto.com/article/743092.html
浅谈一下Java中的几种JVM级别的锁_java_脚本之家
聊聊 Java 的几把 JVM 级锁_jvm层次的锁都有哪些-CSDN博客
https://www.cnblogs.com/wzj4858/p/8215369.html
Java基础-2、并发_分段锁的原理,锁力度减小的思考-CSDN博客
JAVA锁机制-可重入锁,可中断锁,公平锁,读写锁,自旋锁_可中断锁实现原理-CSDN博客
Java中的线程和锁机制_第三 提供的接 审核threadlocal,synchronized等锁机制以及线程池等技术的底-CSDN博客
ReentrantReadWriteLock读写锁-CSDN博客
读写锁ReentrantReadWriteLock&StampLock详解_reentrantreadwritelock和stampedlock-CSDN博客
https://www.cnblogs.com/xiaoxi/p/9140541.html
ReentrantReadWriteLock.ReadLock (Java 2 Platform SE 5.0)
深入理解读写锁ReentrantReadWriteLock_读写锁会产生什么问题-CSDN博客
Java并发编程学习篇3_读写锁ReadWriteLock、阻塞队列BlockingQueue、同步队列SynchronousQueue、线程池(三大方法、七大参数、四种拒绝策略、原生方式创建线程池)_reentrantreadwrihtlock有队列吗-CSDN博客
StampedLock (Java Platform SE 8 )
StampedLock Class (Java.Util.Concurrent.Locks) | Microsoft Learn
https://www.cnblogs.com/myworld7/p/12332911.html
StampedLock (Java SE 19 & JDK 19 [build 1])
https://www.cnblogs.com/zhujiqian/p/16898222.html
开放平台
一文搞懂ReentrantLock的公平锁和非公平锁_ReentrantLock_Ayue、_InfoQ写作社区
Java多线程 -- 公平锁和非公平锁的一些思考-阿里云开发者社区
码农会锁,ReentrantLock之公平锁讲解和实现 | HeapDump性能社区
滑动验证页面
深入剖析 ReentrantLock 公平锁与非公平锁源码实现 - AIQ
13 案例分析:多线程锁的优化
https://blog.51cto.com/panyujie/5478573
Synchronize锁优化手段有哪些_牛客博客
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。