左值引用 VS 右值引用 —— 基础篇
手捧向日葵的花语 2024-08-23 14:05:02 阅读 89
1.左值 和 左值引用
1.1什么是左值?
左值是一个指代内存位置的表达式(如变量名、解引用的指针),这意味着左值拥有内存地址,是可以进行取地址操作的;
常见的左值如下:
<code>// ptr、*ptr、a、b都是左值
int main()
{
int* ptr = new int(1);
int a = 2;
const int b = 3;
return 0;
}
1.2什么是左值引用?
左值引用就是 对左值的引用,本质上就是 对左值取别名,我们可以通过这个别名来操作这个左值。常见的左值引用如下:
int main()
{
int*& rp = ptr;
int& rb = a;
//对const修饰的变量的引用需要加const
//避免权限放大
const int& rc = b;
int& rpv = *p;
return 0;
}
左值引用不仅可以引用左值,还可以引用右值,但是左值引用 引用右值的时候需要加 const
const int& ri = 10;
1.3为什么需要左值引用?
学习过C语言,我们都知道在函数传参时,我们可以选择传值传参和传址传参,但是传值传参和传址传参都具有一定的缺点;传值传参效率低,传址传参代码复杂。例如:
对于传值传参:形参是实参的一份临时拷贝,如果实参所占用的内存空间比较大,传值传参形成形参的时候,需要的时间和空间的开销比较大,会造成一定程度时间和空间的浪费,影响程序的执行效率;而且,传值传参的函数,在函数中修改形参,并不会影响实参,如果想要在该函数中修改实参,就需要传址传参。
传值传参代码:
#include <iostream>
void swap(int a, int b)
{
int temp = a;
a = b;
b = temp;
}
int main()
{
int a = 0;
int b = 1;
swap(a,b);
std::cout << "a = " << a << std::endl;
std::cout << "b = " << b << std::endl;
return 0;
}
// 程序运行结果:a = 0 b = 1
对于传址传参:顾名思义,传址传参就是把变量的地址传给形参,此时的形参也是一个地址,那么实参和形参都是指向同一个变量的指针,在函数内部就能通过指针来对外部的变量进行操作了;如果形参是一个一级指针还好,如果是二级指针甚至是大于二级的指针,操作起来只感觉头发不保!
传址传参代码:
#include <iostream>
void swap(int* pa, int* pb)
{
int temp = *pa;
*pa = *pb;
*pb = temp;
}
int main()
{
int a = 0;
int b = 1;
swap(&a,&b);
std::cout << "a = " << a << std::endl;
std::cout << "b = " << b << std::endl;
return 0;
}
// 程序直接结果为:a = 1 b = 0
所以C++中提出了 引用的概念,引用本质上就是对变量取别名,通过这个别名就可以操作这个变量,而不需要开辟额外的空间,克服了传值传参效率低的缺点;操作上简单便捷,相当于直接操作变量本身一样,克服了传址传参操作复杂的缺点。左值引用很好的解决了函数传参的问题,但是左值引用还有一些不能解决的问题…… 注:这里的引用是左值引用。
引用传参代码:
#include <iostream>
void swap(int& a, int &b)
{
int temp = a;
a = b;
b = temp;
}
int main()
{
int a = 0;
int b = 1;
swap(a,b);
std::cout << "a = " << a << std::endl;
std::cout << "b = " << b << std::endl;
return 0;
}
// 程序直接结果为:a = 1 b = 0
1.4左值引用不能解决的问题?
看下面这段程序:
#include <iostream>
#include <vector>
std::vector<std::vector<int> > func()
{
std::vector<std::vector<int> > ret;
return ret;
}
int main()
{
std::vector<std::vector<int> > result = func();
return 0;
}
main 函数中调用 func 函数,func 函数返回一个二维的 vector,这个二维的 vector 占用的空间可不小哦;如果传参返回的话,返回的并不是 ret,因为出了 func 函数的作用域 ret 就销毁了,无法返回给 main 函数中的 result;编译器在这里的做法是,在销毁 ret 变量之前,找一块空间,将 ret 作为 拷贝构造函数的参数,调用拷贝构造函数 形成一个临时变量,形成临时变量之后,ret 就销毁了,然后再将这个临时变量作为拷贝构造函数的参数 通过拷贝构造函数形成 result 变量;
这里进行了两次拷贝构造,拷贝的次数越多,程序的效率就越低,聪明的编译器会优化该过程,将两次拷贝构造优化为一次拷贝构造,减少了拷贝的次数,也就提升了程序的效率,如下图所示:

但是,终归还是要拷贝的,对于一些非常巨大的对象,拷贝的代价是非常大的,那是否可以通过左值引用返回呢? 在上面的程序中,不能通过左值引用返回,因为 ret 变量是 func 函数的局部变量,出了 func 函数的作用域就销毁了,将一个销毁的变量返回给外部,会导致不可预料的错误!!!
那是不是说出了函数作用域 不会销毁的变量,就可以通过 左值引用返回呢?是的!比如局部的静态变量,全局变量这种出了函数作用域还存在的变量,是可以通过左值引用返回的;这样一来避免了不必要的拷贝,提升了程序的效率。合法的左值引用返回 代码如下所示:
<code>#include <iostream>
#include <vector>
std::vector<std::vector<int> >& func()
{
// 静态的ret,出了作用域还存在,可以通过左值引用返回
static std::vector<std::vector<int> > ret;
return ret;
}
int main()
{
std::vector<std::vector<int> > result = func();
return 0;
}
对于局部的变量,出了作用域就销毁的变量,不能通过左值引用返回,左值引用并没有完全解决传值返回存在拷贝的问题;难道要眼睁睁的看着拷贝发生,看着程序效率变低吗?不,伟大的 C++ 大佬们绝不允许任何不必要的拷贝 拖住 C++ 程序的飞奔~ 于是利用右值引用创造了 右值引用的移动语义(移动构造和移动赋值) 来解决这种左值引用所不能解决的问题。
2.右值 和 右值引用
2.1什么是右值?
右值则与左值相反,它们表示的是临时的、匿名的值,通常不具有持久的存储位置,如字面常量、表达式返回值,函数返回的临时变量(这个不能是左值引用返回)。常见的右值如下:
#include <iostream>
int add(int x, int y)
{
int ret = x + y;
return ret;
}
int main()
{
int x = 1;
int y = 1;
// 以下几个都是常见的右值
10;
x + y;
add(x, y);
return 0;
}
2.2什么是右值引用?
右值引用就是对右值的引用,本质上就是对右值取别名;常见的右值引用如下:
#include <iostream>
int add(int x, int y)
{
int ret = x + y;
return ret;
}
int main()
{
int x = 1;
int y = 2;
// 以下几个都是对右值的右值引用
int&& rr1 = 10;
int&& rr2 = x + y;
int&& rr3 = add(x, y);
return 0;
}
右值引用不仅可以引用右值,还可以引用 std::move()之后的左值
int a = 1;
int&& ra = std::move(a);
2.3为什么需要右值引用?
你是否思考过这样一个问题,为什么有左值引用了还要右值引用呢?生活中,新事物的出现必然是为了解决旧事物所不能解决 or 解决的不够好的问题 or 并实现旧事物所不能实现的价值。 编程也是如此,前面我们说过,左值引用无法解决 函数返回临时的局部对象会发生不必要的拷贝的问题,所以C++11 做了进一步的努力,提供右值引用和移动语义解决 该问题。
总之,需要右值引用的主要原因是为了优化C++中资源的管理,特别是在处理大型对象、容器或资源密集型操作时。在C++11之前,C++标准库和用户定义的类通常只提供了拷贝构造函数和拷贝赋值运算符来管理资源的复制。然而,这种拷贝方式在处理临时对象或大量数据时可能会非常低效,因为它要求分配新的内存并复制所有资源。
2.4右值引用如何解决 左值引用所不能解决的问题的?
右值引用并不直接为解决 返回 临时的局部对象会发生不必要的拷贝问题做贡献,而是通过移动构造函数和移动赋值函数间接起作用;移动构造函数和移动赋值函数是移动语义的具体实现,实现移动语义的基础是右值引用。
2.4.1通过移动构造解决的问题
移动构造函数代码如下:
namespace sky
{
// 移动构造
string(sky::string&& s)
{
cout << "移动拷贝" << endl;
swap(s); // 通过交换窃取资源
}
}
拷贝构造函数中用 const 修饰的左值引用做参数,既可以接收左值,也可以接收右值(如果没实现移动构造的话)。移动构造函数的实现中,利用右值引用 引用右值做参数,自定义类型的右值又叫将亡值(马上就要销毁的右值),通过swap函数把将亡值的资源 “窃取” 过来,用来构造新的对象,避免了不必要拷贝,提高了程序的效率。
基于移动构造的优化:

不优化的情况下:返回局部的、非static的对象 ret,需要拷贝一个临时变量,因为 ret 是左值,所以会调用 拷贝构造函数 生成一个临时变量;result 接收sky::ToString(100) 的返回值的时候,其实是 用临时变量构造出 result 对象, 因为临时变量都是右值,所以会调用移动构造函数。优化的情况下:编译器对于上述情况会有两个优化点:1、隐式地调用 std::move() ,将 ret 识别成右值(将亡值);2、直接调用移动构造函数,将 ret 对象的资源窃取给 result 对象。整个过程只调用了一次移动构造,没有进行拷贝,提高了函数传值返回局部的、非static对象的效率。
2.4.2通过移动赋值解决的问题
同理:如果是将函数返回的局部的、非static的对象赋值给其他对象的话,同样存在拷贝的问题,但是可以通过右值引用的另一个移动语义—— 移动赋值 解决该问题。
移动赋值代码如下:
<code>sky::string& operator=(string&& s)
{
cout << "移动赋值" << endl;
swap(s);
return *this;
}
移动赋值通过 右值引用做参数,接收将亡值,通过swap函数交换二者的资源;由于交换了资源,将亡值对象销毁的时候还会帮助我们释放不需要的资源。整个过程并不涉及资源的拷贝和浪费,提高了程序的效率。相当于我们点了个外卖,外卖小哥把外卖送给我们的时候,请求人家帮忙扔个垃圾。
不提供移动赋值的情况下:
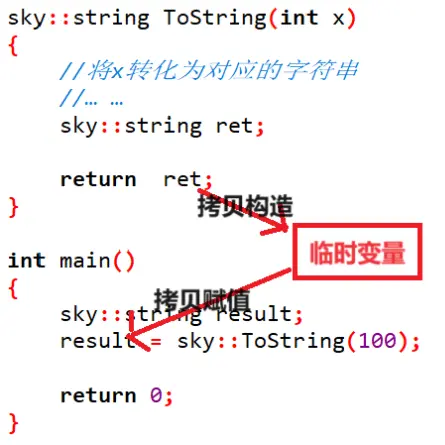
如果没有移动赋值的情况下,分别调用一次 拷贝构造 和 拷贝赋值,进行了两次构造,构造完之后,对象马上又销毁了,造成了不必要的浪费。
提供了移动赋值 但 编译器不优化的情况:
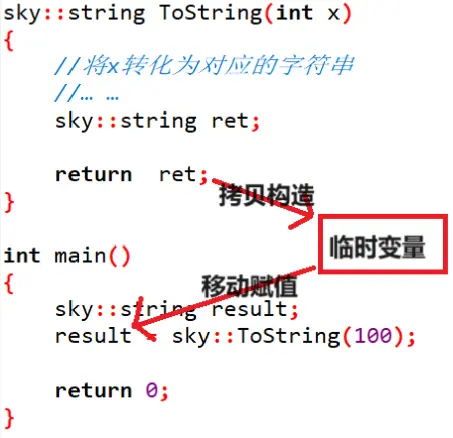
如果有移动赋值但编译器不优化,会调用一次 拷贝构造 和 移动赋值,ret 的资源拷贝形成临时变量之后又马上销毁,造成了不必要的拷贝。
提供了移动赋值 且 编译器优化的情况:
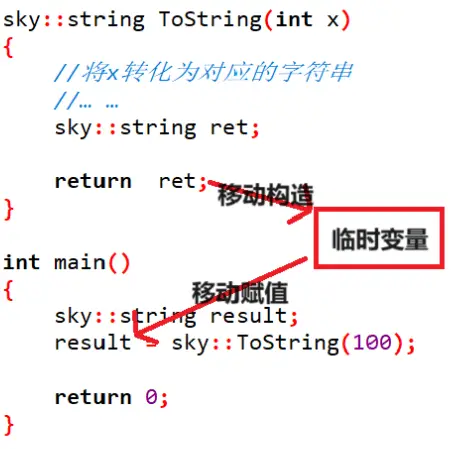
编译器识别到 ret 马上就要销毁了,于是将 ret 隐式地move()了一下,将其识别成右值,调用移动构造形成 临时变量,临时变量也是右值,于是调用移动赋值,与 result 对象进行资源的交换,并利用临时变量 销毁自己不需要的资源,一举两得。这个过程虽然生成了临时变量,但效率还是比较高的,因为,这个过程是通过移动构造和移动赋值进行的,相当于将一份资源进行了两次转移,并不涉及资源的拷贝。相当于我们让快递代拿小哥 帮我们把快递从快递站拿到宿舍楼一样。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。