Python酷库之旅-第三方库Pandas(074)
CSDN 2024-08-14 16:35:04 阅读 89
目录
一、用法精讲
301、pandas.Series.dt.components属性
301-1、语法
301-2、参数
301-3、功能
301-4、返回值
301-5、说明
301-6、用法
301-6-1、数据准备
301-6-2、代码示例
301-6-3、结果输出
302、pandas.Series.dt.to_pytimedelta方法
302-1、语法
302-2、参数
302-3、功能
302-4、返回值
302-5、说明
302-6、用法
302-6-1、数据准备
302-6-2、代码示例
302-6-3、结果输出
303、pandas.Series.dt.total_seconds方法
303-1、语法
303-2、参数
303-3、功能
303-4、返回值
303-5、说明
303-6、用法
303-6-1、数据准备
303-6-2、代码示例
303-6-3、结果输出
304、pandas.Series.str.capitalize方法
304-1、语法
304-2、参数
304-3、功能
304-4、返回值
304-5、说明
304-6、用法
304-6-1、数据准备
304-6-2、代码示例
304-6-3、结果输出
305、pandas.Series.str.casefold方法
305-1、语法
305-2、参数
305-3、功能
305-4、返回值
305-5、说明
305-6、用法
305-6-1、数据准备
305-6-2、代码示例
305-6-3、结果输出
二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



一、用法精讲
301、pandas.Series.dt.components属性
301-1、语法
<code># 301、pandas.Series.dt.components属性
pandas.Series.dt.components
Return a Dataframe of the components of the Timedeltas.
Returns:
DataFrame
301-2、参数
无
301-3、功能
从一个时间序列对象中提取项的各个部分,如年份、月份、日、小时、分钟、秒、毫秒、微秒、纳秒等。
301-4、返回值
返回一个DataFrame,其中每一列代表时间序列的一个组成部分。
301-5、说明
使用场景:
301-5-1、财务数据分析:在金融数据分析中,通常需要对日期进行分解,以便按年、月、日、季度等进行聚合和分析。例如,按季度计算股票平均价格。
301-5-2、运营数据分析:在运营数据分析中,可以根据时间的不同组成部分对数据进行拆分和聚合。例如,按周统计网站访问量。
301-5-3、机器学习中的特征工程:在机器学习的特征工程中,时间序列数据的不同组成部分可以作为特征,以提高模型的性能。例如,构建包含时间特征的机器学习数据集。
301-5-4、物流和供应链管理:在物流和供应链管理中,可以根据时间的不同组成部分优化运输和库存管理。例如,根据小时分析仓库入库量。
301-5-5、电商数据分析:在电商平台的数据分析中,可以根据时间的不同组成部分分析销售趋势和用户行为。例如,按月统计商品销售量。
301-6、用法
301-6-1、数据准备
无
301-6-2、代码示例
# 301、pandas.Series.dt.components属性
# 301-1、按季度计算股票平均价格
import pandas as pd
# 创建示例数据
date_range = pd.date_range(start='2024-01-01', periods=100, freq='D')code>
stock_prices = pd.Series(range(100), index=date_range)
df = pd.DataFrame({'date': date_range, 'price': stock_prices})
# 提取日期各部分
df['quarter'] = df['date'].dt.quarter
# 按季度计算平均价格
quarterly_avg_price = df.groupby('quarter')['price'].mean()
print(quarterly_avg_price, end='\n\n')code>
# 301-2、按周统计网站访问量
import pandas as pd
# 创建示例数据
date_range = pd.date_range(start='2024-01-01', periods=30, freq='D')code>
visit_counts = pd.Series(range(30), index=date_range)
df = pd.DataFrame({'date': date_range, 'visits': visit_counts})
# 提取日期各部分
df['week'] = df['date'].dt.isocalendar().week
# 按周统计访问量
weekly_visits = df.groupby('week')['visits'].sum()
print(weekly_visits, end='\n\n')code>
# 301-3、构建包含时间特征的机器学习数据集
import pandas as pd
# 创建示例数据
date_range = pd.date_range(start='2024-01-01', periods=50, freq='h')code>
values = pd.Series(range(50), index=date_range)
df = pd.DataFrame({'datetime': date_range, 'value': values})
# 提取日期时间各部分
df['year'] = df['datetime'].dt.year
df['month'] = df['datetime'].dt.month
df['day'] = df['datetime'].dt.day
df['hour'] = df['datetime'].dt.hour
df['weekday'] = df['datetime'].dt.weekday
print(df.head(), end='\n\n')code>
# 301-4、根据小时分析仓库入库量
import pandas as pd
# 创建示例数据
date_range = pd.date_range(start='2024-01-01', periods=24, freq='h')code>
inbound_quantities = pd.Series(range(24), index=date_range)
df = pd.DataFrame({'datetime': date_range, 'quantity': inbound_quantities})
# 提取时间各部分
df['hour'] = df['datetime'].dt.hour
# 按小时统计入库量
hourly_inbound = df.groupby('hour')['quantity'].sum()
print(hourly_inbound, end='\n\n')code>
# 301-5、按月统计商品销售量
import pandas as pd
# 创建示例数据
date_range = pd.date_range(start='2024-01-01', periods=100, freq='D')code>
sales_quantities = pd.Series(range(100), index=date_range)
df = pd.DataFrame({'date': date_range, 'sales': sales_quantities})
# 提取日期各部分
df['month'] = df['date'].dt.month
# 按月统计销售量
monthly_sales = df.groupby('month')['sales'].sum()
print(monthly_sales, end='\n\n')code>
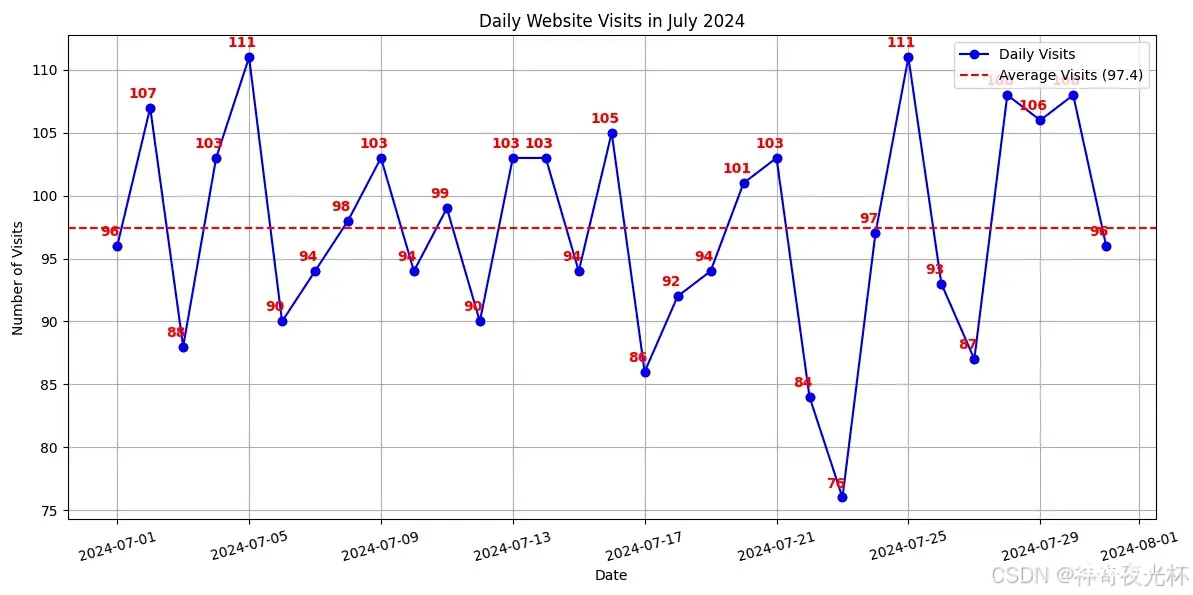
# 301-6、网站每日访问量分析(可视化)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 生成日期范围
date_range = pd.date_range(start='2024-07-01', end='2024-07-31', freq='D')code>
# 模拟每日访问量数据
np.random.seed(42)
visits = np.random.poisson(lam=100, size=len(date_range))
# 创建数据框
df = pd.DataFrame({'date': date_range, 'visits': visits})
print(df.head())
# 设置图形大小
plt.figure(figsize=(12, 6))
# 绘制时间序列图
plt.plot(df['date'], df['visits'], marker='o', linestyle='-', color='b', label='Daily Visits')code>
plt.scatter(df['date'], df['visits'], color='red') # 设置数据点为红色code>
# 添加标题和标签
plt.title('Daily Website Visits in July 2024')
plt.xlabel('Date')
plt.ylabel('Number of Visits')
plt.xticks(rotation=15)
plt.grid(True)
# 添加平均线
average_visits = df['visits'].mean()
plt.axhline(y=average_visits, color='r', linestyle='--', label=f'Average Visits ({average_visits:.1f})')code>
# 添加图例
plt.legend()
# 显示图形
plt.tight_layout()
# 显示数据标签并设置为红色
for i in range(len(df)):
plt.annotate(text=str(df['visits'][i]), xy=(df['date'][i], df['visits'][i]),
xytext=(-5, 5), textcoords='offset points', ha='center', va='bottom', color='red', fontweight='bold')code>
plt.show()
301-6-3、结果输出
# 301、pandas.Series.dt.components属性
# 301-1、按季度计算股票平均价格
# quarter
# 1 45.0
# 2 95.0
# Name: price, dtype: float64
# 301-2、按周统计网站访问量
# week
# 1 21
# 2 70
# 3 119
# 4 168
# 5 57
# Name: visits, dtype: int64
# 301-3、构建包含时间特征的机器学习数据集
# datetime value year month day hour weekday
# 2024-01-01 00:00:00 2024-01-01 00:00:00 0 2024 1 1 0 0
# 2024-01-01 01:00:00 2024-01-01 01:00:00 1 2024 1 1 1 0
# 2024-01-01 02:00:00 2024-01-01 02:00:00 2 2024 1 1 2 0
# 2024-01-01 03:00:00 2024-01-01 03:00:00 3 2024 1 1 3 0
# 2024-01-01 04:00:00 2024-01-01 04:00:00 4 2024 1 1 4 0
# 301-4、根据小时分析仓库入库量
# hour
# 0 0
# 1 1
# 2 2
# 3 3
# 4 4
# 5 5
# 6 6
# 7 7
# 8 8
# 9 9
# 10 10
# 11 11
# 12 12
# 13 13
# 14 14
# 15 15
# 16 16
# 17 17
# 18 18
# 19 19
# 20 20
# 21 21
# 22 22
# 23 23
# Name: quantity, dtype: int64
# 301-5、按月统计商品销售量
# month
# 1 465
# 2 1305
# 3 2325
# 4 855
# Name: sales, dtype: int64
# 301-6、网站每日访问量分析(可视化)
# 见图1
# date visits
# 0 2024-07-01 96
# 1 2024-07-02 107
# 2 2024-07-03 88
# 3 2024-07-04 103
# 4 2024-07-05 111
图1:
302、pandas.Series.dt.to_pytimedelta方法
302-1、语法
<code># 302、pandas.Series.dt.to_pytimedelta方法
pandas.Series.dt.to_pytimedelta()
Return an array of native datetime.timedelta objects.
Python’s standard datetime library uses a different representation timedelta’s. This method converts a Series of pandas Timedeltas to datetime.timedelta format with the same length as the original Series.
Returns:
numpy.ndarray
Array of 1D containing data with datetime.timedelta type.
302-2、参数
无
302-3、功能
用于将pandas.Series对象中的时间差(Timedelta)数据转换为Python的datetime.timedelta对象。
302-4、返回值
返回一个pandas.Series对象,其中的每一个元素都是一个datetime.timedelta对象。
302-5、说明
使用场景:
302-5-1、与其他库兼容:某些库或函数可能不直接支持pandas的Timedelta类型,但可以接受标准Python的timedelta类型。在这种情况下,可以使用to_pytimedelta()进行转换。
302-5-2、标准化处理:在数据分析中,如果你需要将时间差数据传递给其他只接受Python原生数据类型的工具或函数(例如自定义代码、第三方库等),使用to_pytimedelta()可以确保数据格式的一致性。
302-5-3、调试和测试:在调试代码时,可能需要将pandas的Timedelta对象转换为Python标准库的timedelta对象,以便更容易地验证和比较结果。
302-6、用法
302-6-1、数据准备
无
302-6-2、代码示例
# 302、pandas.Series.dt.to_pytimedelta方法
# 302-1、与其他库兼容
import pandas as pd
# 创建一个包含时间差的Series
timedelta_series = pd.Series(pd.to_timedelta(['1 days', '2 days', '3 days']))
# 将Series转换为Python的timedelta对象
pytimedelta_series = timedelta_series.dt.to_pytimedelta()
# 例如,假设你有一个自定义的函数需要标准的timedelta对象
def custom_function(timedeltas):
for delta in timedeltas:
print(f"Processed timedelta: {delta}")
custom_function(pytimedelta_series)
print('\n')
# 302-2、标准化处理
import pandas as pd
from datetime import timedelta
# 创建一个包含时间差的Series
timedelta_series = pd.Series(pd.to_timedelta(['10 hours', '5 hours', '8 hours']))
# 将Series转换为Python的timedelta对象
pytimedelta_series = timedelta_series.dt.to_pytimedelta()
# 使用标准Python的timedelta对象
total_duration = sum(pytimedelta_series, timedelta())
print(f"Total duration: {total_duration}", end='\n\n')code>
# 302-3、调试和测试
import pandas as pd
# 创建一个包含时间差的 Series
timedelta_series = pd.Series(pd.to_timedelta(['1 days 2 hours', '3 days 4 hours']))
# 将 Series 转换为 Python 的 timedelta 对象
pytimedelta_series = timedelta_series.dt.to_pytimedelta()
# 假设你要验证转换后的结果
for original, converted in zip(timedelta_series, pytimedelta_series):
print(f"Original timedelta: {original}, Converted timedelta: {converted}")
302-6-3、结果输出
# 302、pandas.Series.dt.to_pytimedelta方法
# 302-1、与其他库兼容
# Processed timedelta: 1 day, 0:00:00
# Processed timedelta: 2 days, 0:00:00
# Processed timedelta: 3 days, 0:00:00
# 302-2、标准化处理
# Total duration: 23:00:00
# 302-3、调试和测试
# Original timedelta: 1 days 02:00:00, Converted timedelta: 1 day, 2:00:00
# Original timedelta: 3 days 04:00:00, Converted timedelta: 3 days, 4:00:00
303、pandas.Series.dt.total_seconds方法
303-1、语法
# 303、pandas.Series.dt.total_seconds方法
pandas.Series.dt.total_seconds(*args, **kwargs)
Return total duration of each element expressed in seconds.
This method is available directly on TimedeltaArray, TimedeltaIndex and on Series containing timedelta values under the .dt namespace.
Returns:
ndarray, Index or Series
When the calling object is a TimedeltaArray, the return type is ndarray. When the calling object is a TimedeltaIndex, the return type is an Index with a float64 dtype. When the calling object is a Series, the return type is Series of type float64 whose index is the same as the original.
303-2、参数
303-2-1、*args(可选):其他位置参数,为后续扩展功能做预留。
303-2-2、**kwargs(可选):其他关键字参数,为后续扩展功能做预留。
303-3、功能
用于将Timedelta对象的时间差转换为秒数,该功能特别适用于时间差数据的处理与分析。
303-4、返回值
返回一个浮点数,表示时间差的总秒数,对于Series对象,返回一个包含总秒数的Series。
303-5、说明
使用场景:
303-5-1、计算总秒数:假设你有一个pandas.Series对象,其中包含多个时间差数据,你可以使用该方法将其转换为秒数
303-5-2、数据分析:在数据分析中,可能需要将时间差转换为秒数以便进行统计分析,例如,计算平均时间差。
303-5-3、转换为其他单位:将时间差数据转换为秒数后,可以方便地进行其他单位的转换,例如,小时或分钟。
303-6、用法
303-6-1、数据准备
无
303-6-2、代码示例
# 303、pandas.Series.dt.total_seconds方法
# 303-1、计算总秒数
import pandas as pd
# 创建一个包含时间差的Series
timedelta_series = pd.Series(pd.to_timedelta(['1 days 2 hours', '3 days 4 hours']))
# 计算总秒数
seconds_series = timedelta_series.dt.total_seconds()
print(seconds_series, end='\n\n')code>
# 303-2、数据分析
import pandas as pd
# 创建一个包含时间差的Series
timedelta_series = pd.Series(pd.to_timedelta(['10 minutes', '20 minutes', '30 minutes']))
# 计算总秒数
seconds_series = timedelta_series.dt.total_seconds()
# 计算平均时间差(以秒为单位)
average_seconds = seconds_series.mean()
print(f"Average duration in seconds: {average_seconds}", end='\n\n')code>
# 303-3、转换为其他单位
import pandas as pd
# 创建一个包含时间差的Series
timedelta_series = pd.Series(pd.to_timedelta(['2 hours', '3.5 hours', '1 hour 45 minutes']))
# 计算总秒数
seconds_series = timedelta_series.dt.total_seconds()
# 转换为小时
hours_series = seconds_series / 3600
print(hours_series)
303-6-3、结果输出
# 303、pandas.Series.dt.total_seconds方法
# 303-1、计算总秒数
# 0 93600.0
# 1 273600.0
# dtype: float64
# 303-2、数据分析
# Average duration in seconds: 1200.0
# 303-3、转换为其他单位
# 0 2.00
# 1 3.50
# 2 1.75
# dtype: float64
304、pandas.Series.str.capitalize方法
304-1、语法
# 304、pandas.Series.str.capitalize方法
pandas.Series.str.capitalize()
Convert strings in the Series/Index to be capitalized.
Equivalent to str.capitalize().
Returns:
Series or Index of object.
304-2、参数
无
304-3、功能
用于将字符串中的每个元素的首字母大写,其余字母小写,这对于标准化文本数据中的字符串格式非常有用。
304-4、返回值
返回一个新的Series对象,其中每个字符串的首字母被大写化,其余字母则转为小写。
304-5、说明
无
304-6、用法
304-6-1、数据准备
无
304-6-2、代码示例
# 304、pandas.Series.str.capitalize方法
# 304-1、基本使用
import pandas as pd
# 创建包含字符串的Series
string_series = pd.Series(['hello world', 'python programming', 'data science'])
# 首字母大写
capitalized_series = string_series.str.capitalize()
print(capitalized_series, end='\n\n')code>
# 304-2、处理含有多单词的字符串
import pandas as pd
# 创建包含多单词字符串的Series
string_series = pd.Series(['machine learning', 'deep learning', 'natural language processing'])
# 首字母大写
capitalized_series = string_series.str.capitalize()
print(capitalized_series, end='\n\n')code>
# 304-3、处理不同类型的字符串
import pandas as pd
# 创建包含各种字符串的 Series
string_series = pd.Series(['123abc', 'FOO', 'bar123'])
# 首字母大写
capitalized_series = string_series.str.capitalize()
print(capitalized_series)
304-6-3、结果输出
# 304、pandas.Series.str.capitalize方法
# 304-1、基本使用
# 0 Hello world
# 1 Python programming
# 2 Data science
# dtype: object
# 304-2、处理含有多单词的字符串
# 0 Machine learning
# 1 Deep learning
# 2 Natural language processing
# dtype: object
# 304-3、处理不同类型的字符串
# 0 123abc
# 1 Foo
# 2 Bar123
# dtype: object
305、pandas.Series.str.casefold方法
305-1、语法
# 305、pandas.Series.str.casefold方法
pandas.Series.str.casefold()
Convert strings in the Series/Index to be casefolded.
Equivalent to str.casefold().
Returns:
Series or Index of object
305-2、参数
无
305-3、功能
用于将字符串中的每个元素转换为小写形式,具备更强的Unicode比较能力,它在文本处理时提供了一种比常规小写转换更为强大的方法,尤其是在处理不同语言和区域的字符时。
305-4、返回值
返回一个新的Series对象,其中每个字符串元素都被转换为小写,适用于多种语言字符。
305-5、说明
无
305-6、用法
305-6-1、数据准备
无
305-6-2、代码示例
# 305、pandas.Series.str.casefold方法
# 305-1、基本使用
import pandas as pd
# 创建包含字符串的Series
string_series = pd.Series(['Hello World', 'Python Programming', 'Data Science'])
# 使用casefold转换为小写
casefolded_series = string_series.str.casefold()
print(casefolded_series, end='\n\n')code>
# 305-2、处理特殊字符
import pandas as pd
# 创建包含特殊字符的Series
string_series = pd.Series(['Sträßchen', 'ß', 'Öl', 'Äpfel'])
# 使用casefold转换为小写
casefolded_series = string_series.str.casefold()
print(casefolded_series, end='\n\n')code>
305-6-3、结果输出
# 305、pandas.Series.str.casefold方法
# 305-1、基本使用
# 0 hello world
# 1 python programming
# 2 data science
# dtype: object
# 305-2、处理特殊字符
# 0 strässchen
# 1 ss
# 2 öl
# 3 äpfel
# dtype: object
二、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。