【Python】探索 TensorFlow:构建强大的机器学习模型
技术无疆 2024-10-04 15:35:01 阅读 68

TensorFlow 是一个开源的深度学习框架,由 Google 开发,广泛应用于机器学习和人工智能领域。自从 2015 年推出以来,它已成为研究人员、开发者和数据科学家们不可或缺的工具。TensorFlow 提供了灵活、高效的工具集,可以帮助我们构建、训练和部署复杂的神经网络模型。
本文将介绍 TensorFlow 的核心功能、基本架构及其在构建神经网络时的优势,并展示如何使用 TensorFlow 构建一个简单的神经网络模型。


⭕️宇宙起点
🎬 TensorFlow 简介🔨 TensorFlow 的核心架构核心概念TensorFlow 2.0 的改进
📦 使用 TensorFlow 构建简单的神经网络环境准备构建模型代码解析训练结果
🥇 TensorFlow 的优势♨️ 示例代码1. 基本的 Tensor 操作2. 创建一个简单的线性回归模型3. 使用 Keras 构建更复杂的神经网络4. 使用 TensorBoard 进行可视化
🧱 应用场景1. 图像分类与对象检测2. 自然语言处理(NLP)3. 时间序列预测4. 推荐系统5. 生成模型
📥 下载地址💬 结语📒 参考文献

🎬 TensorFlow 简介
TensorFlow 是一个强大的开源软件库,用于数据流图的数值计算,特别是用于机器学习和深度学习。它允许开发者轻松构建和训练复杂的神经网络模型。TensorFlow 的核心是一个使用数据流图的计算引擎,这些图在图中的节点(称为“张量”)之间流动。


🔨 TensorFlow 的核心架构
TensorFlow 的核心是“张量”(Tensor)和“计算图”(Computation Graph)。张量是一种多维数组或矩阵,用于表示数据,而计算图是由一系列操作节点组成的有向图,其中每个节点表示一个数学运算。TensorFlow 的独特之处在于它能够自动处理图的执行(即数据流),并支持 GPU 加速,从而提高模型的训练速度。
核心概念
张量 (Tensor): 数据的基本单位,可以是标量、向量、矩阵或更高维的数组。计算图 (Computation Graph): 描述计算过程的图,节点表示操作,边表示张量在操作之间的流动。会话 (Session): 计算图的执行环境,用来评估图中的节点。自动微分 (Auto-Differentiation): TensorFlow 会自动计算梯度,以便进行反向传播,优化模型参数。
TensorFlow 2.0 的改进
TensorFlow 2.0 引入了许多改进,最显著的是对 Eager Execution 的支持。Eager Execution 使得计算图的执行更加动态和直观,用户可以像执行 Python 代码一样逐步运行每个操作,而不必先定义完整的计算图。
此外,Keras 已经集成到 TensorFlow 中,作为其高层 API,使得构建模型更加简单。这些改进使得 TensorFlow 更易于使用,同时保留了其灵活性和扩展性。

📦 使用 TensorFlow 构建简单的神经网络

下面我们将使用 TensorFlow 2.0 中的 Keras API 来构建一个简单的神经网络,来解决一个经典的二分类问题:识别手写数字。
环境准备
首先,确保你已经安装了 TensorFlow:
<code>pip install tensorflow
构建模型
我们将使用经典的 MNIST 数据集,它包含 60000 个训练样本和 10000 个测试样本,每个样本是一个 28x28 像素的灰度图像,代表手写数字。
import tensorflow as tf
from tensorflow.keras import layers, models
# 加载 MNIST 数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 归一化数据
x_train, x_test = x_train / 255.0, x_test / 255.0
# 构建模型
model = models.Sequential([
layers.Flatten(input_shape=(28, 28)), # 将 28x28 图像展平成 1D
layers.Dense(128, activation='relu'), # 全连接层,128 个神经元code>
layers.Dropout(0.2), # Dropout 层,防止过拟合
layers.Dense(10, activation='softmax') # 输出层,10 个类别,使用 softmax 激活函数code>
])
# 编译模型
model.compile(optimizer='adam',code>
loss='sparse_categorical_crossentropy',code>
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5)
# 评估模型
model.evaluate(x_test, y_test)
代码解析
加载数据:我们使用 tf.keras.datasets.mnist.load_data() 函数加载 MNIST 数据集,并将数据归一化至 [0, 1] 之间,以加快训练速度。构建模型:我们构建了一个简单的顺序模型(Sequential),首先将 28x28 的图像展平,然后通过一个具有 128 个神经元的全连接层,再通过 Dropout 层防止过拟合,最后输出 10 个类别。编译模型:我们使用 Adam 优化器和稀疏的分类交叉熵作为损失函数,并监控模型的准确率。训练与评估:我们通过 5 个 epoch 对模型进行训练,并使用测试集评估模型的表现。
训练结果
经过 5 个 epoch 后,你应该能够看到模型在测试集上的准确率大约在 98% 左右。尽管这是一个简单的模型,但它在解决手写数字识别问题上已经表现出色。

🥇 TensorFlow 的优势
TensorFlow 的强大之处不仅仅体现在它的灵活性和扩展性,还体现在它的广泛生态系统中。以下是 TensorFlow 的一些主要优势:
跨平台支持:TensorFlow 可以在 CPU、GPU、TPU 上运行,并支持从移动设备到服务器的各种平台。高效的分布式计算:它可以轻松地在多个 GPU 或机器上分布式训练大规模模型。自动微分和优化:TensorFlow 提供了强大的自动微分功能,帮助研究人员轻松实现复杂的模型优化。丰富的社区和工具:TensorFlow 拥有一个活跃的社区,并提供了大量的工具,如 TensorBoard(用于可视化)、TensorFlow Hub(用于预训练模型的复用)等。


♨️ 示例代码
下面我们将添加一些示例代码,以帮助你更好地理解 TensorFlow 的使用方式。
1. 基本的 Tensor 操作
在 TensorFlow 中,张量是数据的基本单位。我们可以像操作 NumPy 数组一样操作张量。下面的代码展示了如何创建和操作张量:
<code>import tensorflow as tf
# 创建一个张量
a = tf.constant([[1, 2], [3, 4]])
b = tf.constant([[5, 6], [7, 8]])
# 张量相加
c = tf.add(a, b)
# 张量乘法
d = tf.matmul(a, b)
# 打印结果
print("Tensor a:\n", a)
print("Tensor b:\n", b)
print("Tensor c (a + b):\n", c)
print("Tensor d (a * b):\n", d)
输出:
Tensor a:
[[1 2]
[3 4]]
Tensor b:
[[5 6]
[7 8]]
Tensor c (a + b):
[[ 6 8]
[10 12]]
Tensor d (a * b):
[[19 22]
[43 50]]
2. 创建一个简单的线性回归模型
线性回归是最基础的机器学习模型之一。我们可以使用 TensorFlow 来实现一个简单的线性回归模型。假设我们有一些点 (x, y),并且希望找到一条直线使得其尽可能接近这些点。
import numpy as np
import tensorflow as tf
# 生成模拟数据
x_train = np.array([1.0, 2.0, 3.0, 4.0, 5.0], dtype=np.float32)
y_train = np.array([2.0, 4.1, 6.1, 8.0, 10.1], dtype=np.float32)
# 定义模型参数
W = tf.Variable(0.0)
b = tf.Variable(0.0)
# 线性模型
def linear_model(x):
return W * x + b
# 损失函数 (均方误差)
def loss_fn(y_true, y_pred):
return tf.reduce_mean(tf.square(y_true - y_pred))
# 优化器
optimizer = tf.optimizers.SGD(learning_rate=0.01)
# 训练步骤
def train_step(x, y):
with tf.GradientTape() as tape:
predictions = linear_model(x)
loss = loss_fn(y, predictions)
gradients = tape.gradient(loss, [W, b])
optimizer.apply_gradients(zip(gradients, [W, b]))
return loss
# 训练模型
epochs = 100
for epoch in range(epochs):
loss = train_step(x_train, y_train)
if (epoch + 1) % 10 == 0:
print(f"Epoch { epoch+1}, Loss: { loss.numpy()}")
# 查看最终的 W 和 b
print(f"W: { W.numpy()}, b: { b.numpy()}")
输出示例:
Epoch 10, Loss: 0.006312242154985666
Epoch 20, Loss: 0.002522232998162508
...
Epoch 100, Loss: 0.0003904151357933879
W: 2.016185760498047, b: -0.029788054525852203
通过这段代码,你可以看到如何使用 TensorFlow 实现一个简单的线性回归模型,并使用梯度下降法来优化模型的参数。
3. 使用 Keras 构建更复杂的神经网络
TensorFlow 的 Keras API 让我们能够快速构建复杂的神经网络模型。接下来,我们展示如何使用 Keras 构建一个卷积神经网络(CNN)来进行图像分类。
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# 加载 CIFAR-10 数据集
(x_train, y_train), (x_test, y_test) = datasets.cifar10.load_data()
# 数据归一化
x_train, x_test = x_train / 255.0, x_test / 255.0
# 构建卷积神经网络模型
model = models.Sequential([
# 第一层卷积层
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),code>
layers.MaxPooling2D((2, 2)),
# 第二层卷积层
layers.Conv2D(64, (3, 3), activation='relu'),code>
layers.MaxPooling2D((2, 2)),
# 第三层卷积层
layers.Conv2D(64, (3, 3), activation='relu'),code>
# 展平层
layers.Flatten(),
# 全连接层
layers.Dense(64, activation='relu'),code>
layers.Dense(10) # 输出层,10个类别
])
# 打印模型结构
model.summary()
# 编译模型
model.compile(optimizer='adam',code>
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(f"Test accuracy: { test_acc}")
在这个示例中,我们使用 CIFAR-10 数据集来训练一个简单的卷积神经网络。网络包含三个卷积层和两个最大池化层,最后通过全连接层输出结果。训练 10 个 epoch 后,你将看到模型在测试集上的表现。
4. 使用 TensorBoard 进行可视化
TensorBoard 是 TensorFlow 提供的强大可视化工具,可以帮助我们直观地查看训练过程、模型结构和性能指标。
import tensorflow as tf
import datetime
# 设置 TensorBoard 日志目录
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# 使用回调函数训练模型,并保存日志
model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test), callbacks=[tensorboard_callback])
# 启动 TensorBoard
# 在命令行中运行以下命令,打开 TensorBoard:
# tensorboard --logdir=logs/fit
通过这段代码,你可以生成训练日志并在 TensorBoard 中可视化训练过程。

🧱 应用场景
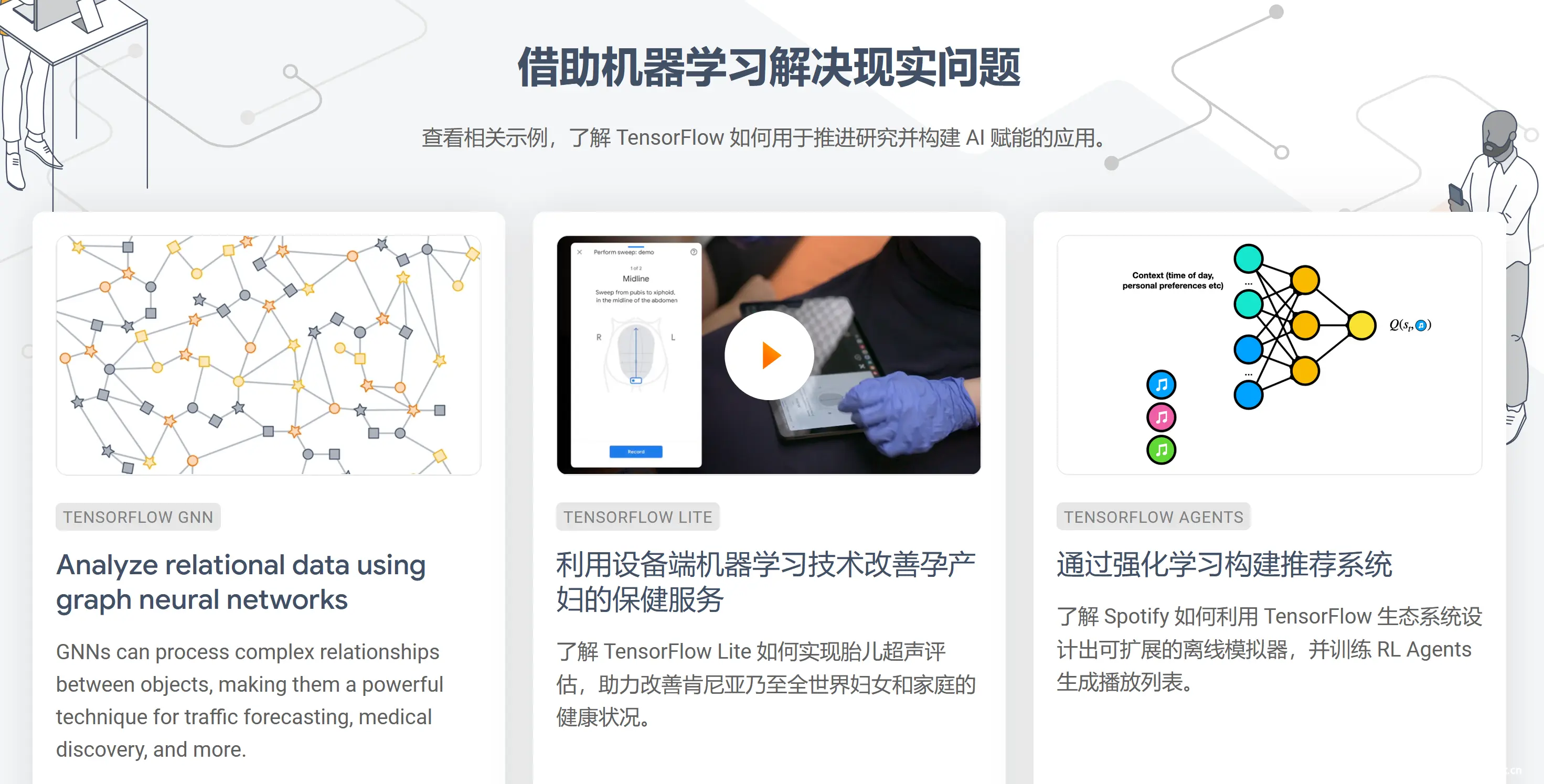
TensorFlow 已经在多个领域中得到了广泛应用。它的灵活性和扩展性使得研究人员和开发人员可以轻松地构建复杂的机器学习模型,并将其部署到生产环境中。以下是 TensorFlow 在不同领域中的一些常见应用场景:
1. 图像分类与对象检测
图像分类是 TensorFlow 最常见的应用之一。借助卷积神经网络(CNN)以及预训练模型(如 ResNet、Inception 等),我们可以轻松构建精确的图像分类器。
应用场景:
自动驾驶汽车:用于识别道路标志、行人、车辆等物体,帮助自动驾驶汽车进行决策。医疗影像分析:在医学图像(如 X 光片、MRI)中检测病变,如癌症细胞或肺部病变。安全监控:自动检测监控视频中的可疑行为或异常事件。
示例代码:
使用 TensorFlow Hub 加载预训练模型进行图像分类:
<code>import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 加载预训练的 MobilenetV2 模型
model = tf.keras.Sequential([
hub.KerasLayer("https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/4", input_shape=(224, 224, 3))
])
# 加载和预处理图像
generator = ImageDataGenerator(rescale=1./255)
image = generator.flow_from_directory('path_to_images', target_size=(224, 224))
# 预测
predictions = model.predict(image)
print(predictions)
2. 自然语言处理(NLP)
TensorFlow 在自然语言处理领域中也有着重要应用。通过基于递归神经网络(RNN)、长短期记忆网络(LSTM)、Transformer 等模型,我们可以解决文本分类、情感分析、机器翻译等问题。
应用场景:
情感分析:用于分析社交媒体上的用户评论或反馈,了解情感倾向(正面、负面或中立)。语音识别:通过将音频数据转换为文本,广泛应用于语音助手(如 Google Assistant、Siri)。文本生成与翻译:生成合成文本,或通过自动翻译模型进行跨语言转换。
示例代码:
以下代码展示了如何使用 TensorFlow 中的 Transformer 模型进行文本翻译:
import tensorflow as tf
import tensorflow_text as text # 必须安装 tensorflow-text
import tensorflow_hub as hub
# 加载预训练的文本翻译模型
translator = hub.load("https://tfhub.dev/google/translate_en_es/2")
# 翻译英文句子到西班牙语
sentence = "TensorFlow is a powerful tool for machine learning."
translated_text = translator(sentence)
print(translated_text)
3. 时间序列预测
TensorFlow 也广泛应用于时间序列分析,如金融市场预测、天气预报、销售预测等。通过 LSTM 或 GRU 等模型,我们可以处理时间相关的数据并进行未来趋势预测。
应用场景:
股票价格预测:根据历史股票数据,预测未来的股票价格趋势。能源消耗预测:根据历史能源使用情况,预测未来的能耗需求。疾病传播建模:根据历史病例数据,预测疾病传播的潜在趋势。
示例代码:
使用 LSTM 进行时间序列预测:
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
# 模拟时间序列数据
time = np.arange(0, 100, 0.1)
data = np.sin(time)
# 构建 LSTM 模型
model = tf.keras.Sequential([
layers.LSTM(50, return_sequences=True, input_shape=(None, 1)),
layers.LSTM(50),
layers.Dense(1)
])
# 编译模型
model.compile(optimizer='adam', loss='mse')code>
# 训练模型
model.fit(data[:-10].reshape(-1, 1, 1), data[1:-9].reshape(-1, 1), epochs=10)
# 预测未来数据
predictions = model.predict(data[-10:].reshape(-1, 1, 1))
print(predictions)
4. 推荐系统
推荐系统已经成为电子商务、流媒体平台和社交媒体的核心组件。通过 TensorFlow,我们可以基于用户的历史行为、偏好等信息构建个性化推荐系统。
应用场景:
电商产品推荐:根据用户浏览、购买的商品,推荐可能感兴趣的其他商品。电影推荐:根据用户观看历史和评分,推荐类似电影或电视节目。社交平台内容推荐:根据用户的社交网络和互动行为,推荐感兴趣的帖子或朋友。
示例代码:
使用 TensorFlow 实现一个简单的协同过滤推荐系统:
import tensorflow as tf
import tensorflow_recommenders as tfrs
import tensorflow_datasets as tfds
# 加载和预处理数据
ratings = tfds.load("movielens/100k-ratings", split="train")code>
# 创建模型
class MovieLensModel(tfrs.Model):
def __init__(self):
super().__init__()
embedding_dim = 32
# 用户和电影的嵌入
self.user_embeddings = tf.keras.Sequential([
tf.keras.layers.StringLookup(vocabulary=ratings["user_id"]),
tf.keras.layers.Embedding(embedding_dim)
])
self.movie_embeddings = tf.keras.Sequential([
tf.keras.layers.StringLookup(vocabulary=ratings["movie_id"]),
tf.keras.layers.Embedding(embedding_dim)
])
# 任务
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=ratings.batch(128).map(self.movie_embeddings)
)
)
def compute_loss(self, features, training=False):
user_embeddings = self.user_embeddings(features["user_id"])
movie_embeddings = self.movie_embeddings(features["movie_id"])
return self.task(user_embeddings, movie_embeddings)
# 训练模型
model = MovieLensModel()
model.compile(optimizer=tf.keras.optimizers.Adam(0.001))
model.fit(ratings.batch(128), epochs=5)
5. 生成模型
TensorFlow 在生成模型(如生成对抗网络 GANs)领域也有大量应用,可以用于图像生成、文本生成、甚至音乐创作。
应用场景:
图像生成:从噪声中生成逼真的图像,广泛用于增强现实、艺术创作等领域。语音生成:合成逼真的语音,应用于语音助手、语音转换等。文本生成:用于生成新的文本段落,如写作助手、代码生成等。
示例代码:
使用 GAN 生成手写数字(基于 MNIST 数据集):
import tensorflow as tf
from tensorflow.keras import layers
# 生成器模型
def make_generator_model():
model = tf.keras.Sequential([
layers.Dense(256, activation='relu', input_shape=(100,)),code>
layers.Reshape((16, 16, 1)),
layers.Conv2DTranspose(128, kernel_size=3, strides=2, padding='same', activation='relu'),code>
layers.Conv2DTranspose(64, kernel_size=3, strides=2, padding='same', activation='relu'),code>
layers.Conv2D(1, kernel_size=3, padding='same', activation='sigmoid')code>
])
return model
# 判别器模型
def make_discriminator_model():
model = tf.keras.Sequential([
layers.Conv2D(64, kernel_size=3, strides=2, padding='same', input_shape=(28, 28, 1)),code>
layers.LeakyReLU(),
layers.Flatten(),
layers.Dense(1)
])
return model
# 初始化模型
generator = make_generator_model()
discriminator = make_discriminator_model()
# 编译和训练模型(省略具体训练流程)

📥 下载地址
TensorFlow 最新版 下载地址

💬 结语
TensorFlow 被广泛应用于多个领域,如计算机视觉、自然语言处理、时间序列分析、推荐系统、生成模型等。它的灵活性使得开发者能够构建不同类型的深度学习模型,解决复杂的实际问题。无论是学术研究还是工业应用,TensorFlow 都提供了全面的支持。
📒 参考文献
TensorFlow 官网TensorFlow GitHub仓库


声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。