python入门教程(非常详细!3w+ 文字)
cnblogs 2024-08-19 14:09:00 阅读 82
先序: 学习编程语言要先学个轮廓,刚开始只用学核心的部分,一些细节、不常用的内容先放着,现用现查即可;把常用的东西弄熟练了在慢慢补充。
1、 安装 Python 解释器
为什么需要安装 Python
Python 语言本身是由解释器执行的,因此你需要在你的计算机上安装 Python 解释器。这个解释器会将你编写的 Python 代码翻译成计算机能够理解和执行的机器码。
1. 下载 Python 安装包
- <li>打开 Python 官方网站 Python 下载页面,选择合适的版本(通常推荐最新的稳定版本)。
- 点击下载按钮,下载适合 Windows 系统的安装包。
2. 安装 Python
- 找到下载的安装包,双击运行。
- 重要步骤:在安装界面的底部勾选 "Add Python to PATH"(将 Python 添加到系统环境变量)。
- 选择 "Customize installation"(自定义安装),可以选择默认设置或根据需要修改安装选项。
- 安装完成后,会弹出 "Setup was successful" 的提示。
3. 验证安装
- 打开命令提示符(按 <code>Win+R 键,输入
cmd,回车)。li> - 输入以下命令查看 Python 版本:
python --version如果看到 Python 版本信息,说明安装成功。
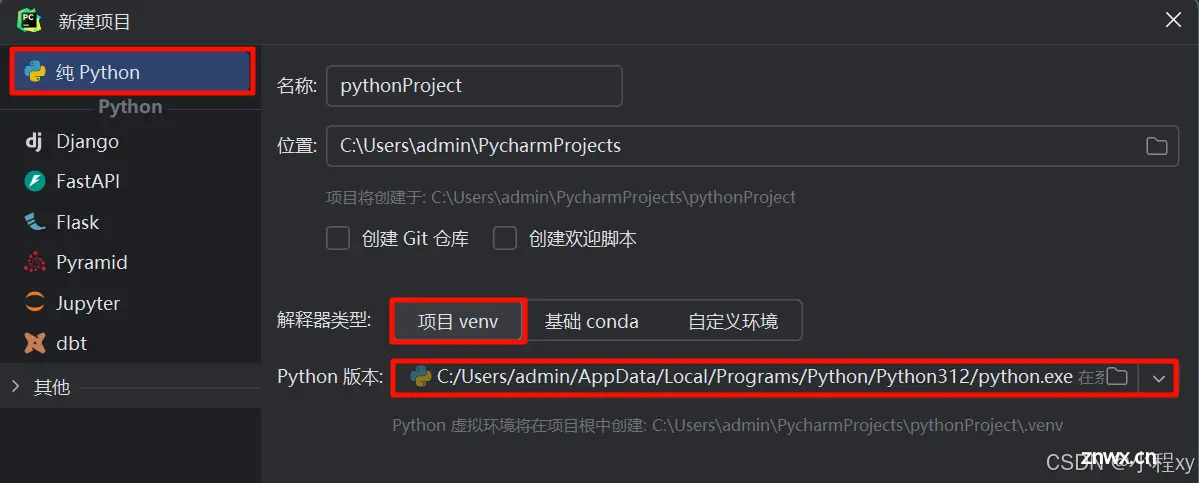
4.创建一个py项目
2、语法基础
1. 变量
在 Python 中,变量可以存储不同类型的数据。常见的数据类型如下:
| 类型 | 描述 | 举例 |
|---|---|---|
| int | 整数 | 123 |
| float | 浮点数 | 1.23, 1.24e5 |
| str | 字符串 | "python" |
| bool | 布尔值 | True, False |
| list | 列表 | [1, 2, 3] |
| tuple | 元组 | (1, 2, 3) |
| set | 集合 | |
| dict | 字典 |
变量的使用示例:
<code>width = 20
width = "none"# 可以更改类型
height = 12.3
name = "yxc"
my_name = name
flag = True
a, b, c = 1, 'a', 3.0 # 同时给多个变量赋值
a, b = b, a # 交换 a b 的值
注意:int 支持高精度,没有大小限制。
2. 运算符
Python 支持多种运算符,用于执行各种运算操作。
示例:
A = 10
B = 20
# 常用运算符及其描述
print(A + B) # 加法,结果为30, 字符串类型的相加是字符串拼接到一起
print(A - B) # 减法,结果为-10
print(A * B) # 乘法,结果为200
print(B / A) # 除法,结果为2.0
print(B // A) # 整除,结果为2
print(B % A) # 取模,结果为0
print(A ** B) # 乘方,结果为1e20
# 复合运算符
A += B # 等价于 A = A + B
A -= B # 等价于 A = A - B
A *= B # 等价于 A = A * B
A /= B # 等价于 A = A / B
A //= B # 等价于 A = A // B
A %= B # 等价于 A = A % B
A **= B # 等价于 A = A ** B
注意:除法和取模运算中,当除以0时程序会报异常。
3. 表达式
Python 支持常见的四则运算,并在整数与浮点数混合运算时自动进行类型转换。
示例:
x = 2 + 3
y = (x + 1.0) * 5
print(x + y) # 输出结果为30.0
# int()、float()、str()等函数强制转换类型。
s = "123.0"
a = float(s)
b = int(a)
s2 = "The value is " + str(b)
print(s, a, b, s2) # 输出 '123.0 123.0 123 The value is 123'
4. 输入
1. input
使用 input() 函数可以从用户那里获得输入。返回值类型为字符串,可以使用 split()、map()、int() 等函数进行处理。
示例:
a, b = map(int, input().split()) # 读入两个以空格隔开的字符, 并把它们转换成 int 类型赋值给 a、b
print(a + b) # 计算两个数的和
stdin.readlines() 是 Python 中用于从标准输入(通常是键盘输入)读取多行数据的函数。它一次性读取所有输入的行,并将其存储在一个列表中,其中每一行作为列表中的一个元素。
2. readlines读入
stdin.readlines() 会读取用户输入的所有行,返回一个包含这些行的列表,每一行作为列表中的一个字符串元素,直到遇到文件结束符。
import sys
# 从标准输入中读取所有行
lines = sys.stdin.readlines()
# 打印每一行
for line in lines:
print(line.strip()) # .strip() 用于去掉每行末尾的换行符
调用 strip() 是为了去掉行末的换行符,这样输出的内容就不会多出额外的空行。
适用场景
- 从文件中读取多行数据:如果需要从文件或标准输入读取多行数据并存储在列表中进行处理时,
stdin.readlines()非常有用。 - 处理批量输入:当需要批量处理输入数据时,可以使用
stdin.readlines()读取所有输入,然后逐行处理。
5. 输出
使用 print() 函数可以输出多个变量,默认用空格隔开,且行末会默认添加回车。如果想自定义行末字符,可以添加 end 参数。
示例:
a, b, c = 1, 2, 'x'
print(a, b, c, end='!') # 输出 '1 2 x!'code>
print(a)# 默认有换行 输出 1 (后面有换行)
print(b, end=' ') # 输出 2 (后面后一个空格)code>
print(c)# 输出 3
保留小数位数:
x = 12.34567
print("x = " + str(round(x, 1))) # 保留1位小数,输出 'x = 12.3'
print("x = " + str(round(x, 3))) # 保留3位小数,输出 'x = 12.346'
格式化输出字符串:
x = 12.34567
y = 12
print("x = %.1f" % x) # 保留1位小数,输出 'x = 12.3'
print("x = %.3f" % (x * y)) # 保留3位小数,输出 'x = 148.148'
print("x = %f, y = %d" % (x, y)) # 输出 'x = 12.345670, y = 12'
%s :字符串(`str`)
%d :整数(`int`)
%f :浮点数(`float`)
%x :十六进制整数(`int`)
6. 其它函数
例如,使用 sqrt 函数计算平方根:
from math import sqrt # 引入开根号函数
x = 2
y = sqrt(x)
print(y) # 输出 '1.4142135623730951'
3、判断语句
在 Python 中,常见的判断语句有 if、elif 和 else。这些语句允许我们根据条件的真假来执行不同的代码块。以下是 Python 判断语句的基本用法和示例。
1. 基本语法
if condition:
# 当条件为真时执行的代码块
elif another_condition:
# 当另一个条件为真时执行的代码块
else:
# 当以上所有条件都不满足时执行的代码块
2. 示例
2.1 简单的 if 语句
age = 18
if age >= 18:
print("You are an adult.")
# 等价于上面那个
if not age < 18:
print("You are an adult.")
2.2 if 和 else 语句
age = 16
if age >= 18:
print("You are an adult.")
else:
print("You are a minor.")
2.3 if、elif 和 else 语句
score = 85
if score >= 90:
print("Grade: A")
elif score >= 80: # elif 相当于是 else if
print("Grade: B")
else:
print("Grade: F")
3. 条件表达式
除了使用 if 语句进行判断,Python 还支持使用条件表达式(又称三元运算符, 相当于 c ++ 的 ... : ... ? ... )来简化简单的条件判断。其语法如下:
value_if_true if condition else value_if_false
示例:
age = 18
status = "adult" if age >= 18 else "minor"
print(status) # 输出 "adult"
4. 使用布尔运算符
在条件判断中,可以使用布尔运算符来组合多个条件。常见的布尔运算符有 and、or 和 not。
not 运算符示例:
is_student = False
if not is_student:
print("You need to pay full price.")
else:
print("You get a discount.")
5. 比较运算符
在条件判断中,经常会使用比较运算符来比较数值或其他数据类型。常见的比较运算符有:
==:等于!=:不等于>:大于<:小于>=:大于等于<=:小于等于
6. match 语句(Python 3.10 及以上版本)
Python 3.10 引入了新的 match 语句,用于模式匹配。它类似于其他语言中的 switch 语句,但功能更强大。match 语句允许你根据对象的结构和内容来进行匹配。
基本语法
match value:
case pattern1:
# 当 value 匹配 pattern1 时执行的代码块
case pattern2:
# 当 value 匹配 pattern2 时执行的代码块
case _:
# 默认情况下执行的代码块,相当于 'default' 或 'else'
# 默认只匹配第一个满足条件的case, 之后的case不再匹配, 相当于C++的switch case后加上break
示例
def http_status(status):
match status:
case 200:
return "OK"
case 404:
return "Not Found"
case 500:
return "Internal Server Error"
case _:
return "Unknown Status"
print(http_status(200)) # 输出 "OK"
print(http_status(404)) # 输出 "Not Found"
print(http_status(999)) # 输出 "Unknown Status"
7. pass 语句
pass 语句是一个占位符,用于在语法上需要一个语句但实际上不做任何事情的地方。通常在定义空函数、类或循环时使用。
示例
if a > 5 :
pass # 这里什么也不写的话, 执行会报错, 写上 pass 的话不报错
else
print("a <= 5")
4、循环语句
for 循环
for 循环用于遍历序列(如列表、元组、字符串)或其他可迭代对象。在 Python 中,for 循环与其他语言的不同之处在于它遍历的是可迭代对象的元素,而不是基于计数器的循环。
语法
for element in iterable:
# do something with element
示例
# 遍历列表
numbers = [1, 2, 3, 4, 5]
for number in numbers:
print(number)
# 遍历字符串
for letter in "Python":
print(letter)
for in range
基本语法
for i in range(start, stop, step):
# 代码块
start(可选):循环的起始值,默认为0。stop:循环的结束值(不包括该值)。step(可选):步长,默认为1。
示例
1. 基本用法
遍历从 0 到 4 的数字:
for i in range(5):
print(i)
2. 指定起始值
遍历从 2 到 5 的数字:
for i in range(2, 6):
print(i)
3. 指定步长
每次循环增加 2,遍历从 1 到 9 的数字:
for i in range(1, 10, 2):
print(i)
while 循环
while 循环在给定条件为真时重复执行目标语句。循环会在条件为假时终止。
语法
while condition:
# do something
示例
# 计数循环
count = 0
while count < 5:
print(count)
count += 1
循环控制语句
Python 提供了几种控制循环行为的语句,包括 break,continue 和 else。
break 语句
break 语句用于终止循环。它会跳出当前的循环块,不再执行循环剩余的迭代。
for i in range(10):
if i == 5:
break
print(i)
# 输出: 0 1 2 3 4
continue 语句
continue 语句跳过当前代码块迭代的剩余部分,并继续下一次迭代。
for i in range(10):
if i % 2 == 0:
continue
print(i)
# 输出: 1 3 5 7 9
else 子句
在循环中,else 子句在循环正常结束时执行(即没有被 break 终止)。
for i in range(5):
print(i)
else:
print("循环正常结束")
# 输出:
# 0
# 1
# 2
# 3
# 4
# 循环正常结束
如果循环被 break 终止,则 else 子句不会执行。
for i in range(5):
if i == 3:
break
print(i)
else:
print("循环正常结束")
# 输出:
# 0
# 1
# 2
嵌套循环
你可以在一个循环内部使用另一个循环,这就是嵌套循环。常见的使用场景包括遍历二维数组或矩阵。
# 示例:打印乘法表
for i in range(1, 10):
for j in range(1, 10):
print(f"{i} * {j} = {i * j}", end="\t")code>
print()
for 循环中的 enumerate 和 zip
enumerate 函数可以在遍历序列时同时得到索引和值。
names = ["Alice", "Bob", "Charlie"]
for index, name in enumerate(names):
print(index, name)
# 输出:
# 0 Alice
# 1 Bob
# 2 Charlie
zip 函数可以并行遍历多个可迭代对象。
names = ["Alice", "Bob", "Charlie"]
scores = [85, 92, 78]
for name, score in zip(names, scores):
print(f"{name} scored {score}")
# 输出:
# Alice scored 85
# Bob scored 92
# Charlie scored 78
5、列表
Python 列表(List)是最常用的数据结构之一。它是一个有序的、可变的序列,可以包含任意类型的元素。由于其灵活性,列表在日常编程中非常常见。
1. 列表的定义与创建
列表使用方括号 [] 定义,元素之间用逗号 , 分隔。
# 创建一个空列表
empty_list = []
# 创建一个包含整数的列表
int_list = [1, 2, 3, 4, 5]
# 创建一个包含字符串的列表
str_list = ["apple", "banana", "cherry"]
# 创建一个混合类型的列表
mixed_list = [1, "apple", 3.14, True]
2. 访问列表元素
列表中的元素通过索引访问,索引从 0 开始。也可以使用负索引从列表末尾访问元素。
fruits = ["apple", "banana", "cherry"]
# 访问第一个元素
first_fruit = fruits[0] # 输出: apple
# 访问最后一个元素
last_fruit = fruits[-1] # 输出: cherry
3. 修改列表元素
列表是可变的,因此可以直接修改列表中的元素。
fruits = ["apple", "banana", "cherry"]
# 修改第二个元素
fruits[1] = "blueberry"
print(fruits) # 输出: ['apple', 'blueberry', 'cherry']
4. 列表的遍历
可以使用 for 循环来遍历列表中的元素。
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
for i in range(0, 3)
print(fruit[i])
输出:
apple
banana
cherry
5. 常用方法
Python 提供了多种方法向列表中添加元素。
append():在列表末尾添加元素。fruits = ["apple", "banana"]fruits.append("cherry")print(fruits) # 输出: ['apple', 'banana', 'cherry']insert():在指定位置插入元素。fruits = ["apple", "banana"]fruits.insert(1, "blueberry")print(fruits) # 输出: ['apple', 'blueberry', 'banana']extend():将另一个列表的所有元素添加到当前列表中。fruits = ["apple", "banana"]more_fruits = ["cherry", "date"]fruits.extend(more_fruits)print(fruits) # 输出: ['apple', 'banana', 'cherry', 'date']remove():删除指定值的第一个匹配项。fruits = ["apple", "banana", "cherry"]fruits.remove("banana")print(fruits) # 输出: ['apple', 'cherry']pop():删除指定索引位置的元素,并返回该元素。若不指定索引,则默认删除最后一个元素。fruits = ["apple", "banana", "cherry"]last_fruit = fruits.pop()print(last_fruit) # 输出: cherryprint(fruits) # 输出: ['apple', 'banana']clear():清空列表,保留列表对象但删除所有元素。fruits = ["apple", "banana", "cherry"]fruits.clear()print(fruits) # 输出: []reverse():反转列表。fruits = ["apple", "banana", "cherry"]fruits.reverse()print(fruits) # 输出: ["cherry", "banana", "apple"]del语句:可以删除特定索引处的元素或整个列表。fruits = ["apple", "banana", "cherry"]del fruits[1]print(fruits) # 输出: ['apple', 'cherry']
6. 列表的切片
切片允许你获取列表的一个子集或修改列表中的部分元素。
[startIndex] : [endIndex] : [step] : 从起始下标到结束下表截取, 步长是 step
numbers = [0, 1, 2, 3, 4, 5, 6]
# 获取索引 2 到 4 的元素(不包括索引 5)
subset = numbers[2:5]
print(subset) # 输出: [2, 3, 4]
# 修改索引 3 到 5 的元素
numbers[3:6] = [7, 8, 9]
print(numbers) # 输出: [0, 1, 2, 7, 8, 9, 6]
# 将列表倒序
b = a[::-1]
7. 列表的排序
在 Python 中,列表排序是一项非常常用的操作。Python 提供了几种方法来对列表进行排序,主要包括 sort() 方法和 sorted() 函数。这两者都有各自的特点和适用场景。
1. 使用 sort() 方法
sort() 方法会直接对原列表进行排序(就地排序),不会生成新的列表。这个方法有两个常用参数:
key:用于指定一个函数,该函数用于提取元素的排序键。reverse:布尔值,若为True,则列表将按降序排序,默认值为False(升序排序)。
示例
# 简单的升序排序
numbers = [5, 2, 9, 1, 5, 6]
numbers.sort()
print(numbers) # 输出: [1, 2, 5, 5, 6, 9]
# 降序排序
numbers.sort(reverse=True)
print(numbers) # 输出: [9, 6, 5, 5, 2, 1]
# 使用 key 参数按字符串长度排序
words = ["apple", "banana", "cherry", "date"]
words.sort(key=len)
print(words) # 输出: ['date', 'apple', 'banana', 'cherry']
2. 使用 sorted() 函数
sorted() 函数不会改变原列表,而是返回一个新列表,原列表保持不变。它的参数和 sort() 方法相同,也可以指定 key 和 reverse 参数。
示例
# 使用 sorted() 函数进行排序
numbers = [3, 1, 4, 1, 5, 9]
sorted_numbers = sorted(numbers)
print(sorted_numbers) # 输出: [1, 1, 3, 4, 5, 9]
print(numbers) # 原列表不变: [3, 1, 4, 1, 5, 9]
# 按照字母的倒序排序
sorted_words = sorted(words, reverse=True)
print(sorted_words) # 输出: ['date', 'cherry', 'banana', 'apple']
3. 自定义排序规则
可以通过 key 参数自定义排序规则。key 参数接收一个函数,这个函数对每个列表元素进行处理,并返回一个用于比较的值。可以结合 lambda 函数使用。
示例:按字符串的最后一个字母排序
words = ["grape", "apple", "banana", "cherry"]
# 按照最后一个字母排序
sorted_words = sorted(words, key=lambda word: word[-1])
print(sorted_words) # 输出: ['banana', 'grape', 'apple', 'cherry']
8. 列表的其他常用操作
len():获取列表长度(元素个数)。fruits = ["apple", "banana", "cherry"]print(len(fruits)) # 输出: 3in和not in:检查列表中是否包含某个元素。fruits = ["apple", "banana", "cherry"]print("banana" in fruits) # 输出: Trueprint("grape" not in fruits) # 输出: True列表拼接:可以使用
+操作符将两个列表拼接成一个新列表。fruits = ["apple", "banana"]more_fruits = ["cherry", "date"]all_fruits = fruits + more_fruitsprint(all_fruits) # 输出: ['apple', 'banana', 'cherry', 'date']列表复制:使用
copy()方法或切片语法。fruits = ["apple", "banana", "cherry"]copy_fruits = fruits.copy() # 或者 fruits[:]print(copy_fruits) # 输出: ['apple', 'banana', 'cherry']
9、Python 列表推导式
列表推导式(List Comprehension)是一种简洁且强大的语法,用于生成新的列表。它让你可以用一行代码来创建一个基于已有列表的过滤、变换后的新列表,语法上非常简洁且易读。
1. 基本语法
[expression for item in iterable if condition]
expression:要执行的表达式,决定了每个元素在新列表中的形式。item:从可迭代对象中取出的元素。iterable:一个可迭代对象,如列表、元组、字符串等。condition(可选):一个可选的条件过滤器。只有满足此条件的元素才会包含在生成的列表中。
示例
生成一个包含 0 到 9 的列表:
numbers = [x for x in range(10)]
print(numbers)
# 输出: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
6、Python 字符串详解
1. 字符串的定义与创建
Python 中的字符串可以用单引号 ' 或双引号 " 来定义。三引号 ''' 或 """ 可以用于定义多行字符串。
# 使用单引号
single_quote_str = 'Hello, World!'
# 使用双引号
double_quote_str = "Hello, World!"
# 使用三引号定义多行字符串
multi_line_str = '''This is a
multi-line string.'''
2. 字符串的基本操作
2.1 连接
使用 + 操作符可以连接多个字符串。
greeting = "Hello"
name = "Alice"
message = greeting + ", " + name + "!"
print(message) # 输出: Hello, Alice!
2.2 重复
使用 * 操作符可以重复字符串。
repeated_str = "Ha" * 3
print(repeated_str) # 输出: HaHaHa
2.3 索引
可以使用索引访问字符串中的单个字符。索引从 0 开始,也可以使用负索引从末尾访问字符。
text = "Python"
first_char = text[0] # 输出: 'P'
last_char = text[-1] # 输出: 'n'
2.4 切片
通过切片可以获取字符串的子字符串。
text = "Python"
substring = text[1:4] # 输出: 'yth'
2.5 长度
使用 len() 函数可以获取字符串的长度。
text = "Python"
length = len(text) # 输出: 6
2.6 查看字符的ascll码
- 使用
ord()函数可以获取字符的 ASCII 码。 - 使用
chr()函数可以获取 ASCII 码对应的字符。
3. 字符串的常用方法
Python 提供了丰富的字符串方法来操作和处理字符串。
3.1 lower() 和 upper()
转换字符串的大小写。
text = "Hello, World!"
lower_text = text.lower() # 输出: 'hello, world!'
upper_text = text.upper() # 输出: 'HELLO, WORLD!'
3.2 strip()
去除字符串两端的空白字符(或其他指定字符)。
text = " Hello, World! "
stripped_text = text.strip() # 输出: 'Hello, World!'
3.3 split()
将字符串拆分成一个列表,默认按空格拆分。
text = "Hello, World!"
words = text.split() # 输出: ['Hello,', 'World!']
可以指定分隔符:
text = "apple,banana,cherry"
fruits = text.split(',') # 输出: ['apple', 'banana', 'cherry']
3.4 join()
将列表中的元素连接成一个字符串。
words = ['Hello', 'World']
joined_text = ' '.join(words) # 输出: 'Hello World'
3.5 find() 和 replace()
find()返回子字符串在字符串中第一次出现的索引,如果未找到则返回-1。text = "Hello, World!"index = text.find('World') # 输出: 7rfind()返回子字符串在字符串中最后一次出现的索引,如果未找到则返回-1。text = "Hello, World!"index = text.find('World') # 输出: 7replace()用新字符串替换字符串中的旧子字符串。text = "Hello, World!"new_text = text.replace('World', 'Python') # 输出: 'Hello, Python!'
3.6 startswith() 和 endswith()
检查字符串是否以指定的前缀或后缀开头或结尾。
text = "Hello, World!"
print(text.startswith("Hello")) # 输出: True
print(text.endswith("!")) # 输出: True
4. 字符串的格式化
在 Python 中,格式化字符串允许你在字符串中插入变量的值。有几种方法可以实现格式化,其中常见的有:
- 百分号格式化 (
%) str.format()方法- f-strings (格式化字符串字面量)
1. 百分号格式化 (%)
使用 % 运算符来格式化字符串,是 Python 的老式方法。常见的占位符包括:
%s:字符串(str)%d:整数(int)%f:浮点数(float)%x:十六进制整数(int)
示例
name = "Alice"
age = 30
height = 5.6
# 使用 % 格式化字符串
formatted_str = "Name: %s, Age: %d, Height: %.1f" % (name, age, height)
print(formatted_str) # 输出: Name: Alice, Age: 30, Height: 5.6
2. str.format() 方法
使用 str.format() 方法来格式化字符串,比 % 更灵活,支持更复杂的格式化选项。
常见的占位符
{}:默认插入位置{0}:按索引插入{name}:按变量名插入{:.2f}:控制浮点数的显示精度
示例
name = "Bob"
age = 25
height = 6.1
# 使用 str.format() 格式化字符串
formatted_str = "Name: {}, Age: {}, Height: {:.1f}".format(name, age, height)
print(formatted_str) # 输出: Name: Bob, Age: 25, Height: 6.1
3. f-strings (格式化字符串字面量)
f-strings 是 Python 3.6 引入的功能,它提供了更简洁的格式化方式。通过在字符串前加 f,你可以直接在字符串中嵌入变量表达式。
示例
name = "Carol"
age = 28
height = 5.9
# 使用 f-strings 格式化字符串
formatted_str = f"Name: {name}, Age: {age}, Height: {height:.1f}"
print(formatted_str) # 输出: Name: Carol, Age: 28, Height: 5.9
5. 字符串的不可变性
字符串是不可变的,这意味着一旦创建,就不能修改其内容。任何试图修改字符串的操作,实际上都会创建一个新的字符串。
text = "Hello"
text[0] = "h" # 这会导致错误,因为字符串是不可变的
要“修改”字符串,可以通过切片和连接的方式创建一个新的字符串。
text = "Hello"
new_text = "h" + text[1:] # 输出: 'hello'
6. 字符串的常见操作与技巧
6.1 反转字符串
使用切片反转字符串。
text = "Python"
reversed_text = text[::-1]
print(reversed_text) # 输出: 'nohtyP'
6.2 检查字符串是否为数字
使用 isdigit() 方法。
text = "12345"
print(text.isdigit()) # 输出: True
text = "123a5"
print(text.isdigit()) # 输出: False
6.3 去除字符串中的特定字符
可以使用 str.replace() 方法。
text = "Hello, World!"
new_text = text.replace(",", "")
print(new_text) # 输出: 'Hello World!'
7. 字符串跟列表的不同之一
字符串赋值是深拷贝, 列表赋值时浅拷贝
a = [1, 2]
b = a
b[0] = 99
print(a, b) # 输出 [99, 2] [99, 2]
a = "hello"
b = a
b = "world"
print(a, b) # 输出 hello world
7、函数
在 Python 中,函数是组织代码的基本单元,它将一段可复用的代码封装起来,可以通过函数名来调用。Python 的函数可以带参数,也可以返回值,函数的定义和调用都非常灵活。
1. 函数的定义
Python 使用 def 关键字定义函数,语法如下:
def function_name(parameters):
"""docstring (optional): 函数的文档字符串,用于描述函数功能"""
# 函数体
return value # 可选的返回值
示例:
def greet(name):
"""输出问候语"""
print(f"Hello, {name}!")
greet("Alice") # 输出: Hello, Alice!
函数相当于变量, 可以重新赋值
b = greet
greet = "change"
b("World") # 输出:Hello, World!
print(greet) # 输出 change
2. 函数的调用
定义函数后,可以通过函数名加上圆括号来调用函数。如果函数有参数,需要在调用时传递参数。
greet("Bob") # 调用 greet 函数,输出: Hello, Bob!
3. 函数的参数
3.1 位置参数
函数参数根据位置传递,顺序很重要。
def add(a, b):
return a + b
result = add(3, 5) # 位置参数调用
print(result) # 输出: 8
3.2 关键字参数
在调用函数时,可以通过参数名来指定参数,这样顺序就不重要了。
result = add(b=3, a=5) # 关键字参数调用
print(result) # 输出: 8
3.3 默认参数
在定义函数时,可以为参数指定默认值。如果调用时不传递该参数,则使用默认值。
def greet(name="Guest"):code>
print(f"Hello, {name}!")
greet() # 使用默认参数,输出: Hello, Guest!
greet("Carol") # 输出: Hello, Carol!
3.4 可变参数 (*args 和 **kwargs)
- <li>
**kwargs用于接收任意数量的关键字参数,类型为字典。
*args 用于接收任意数量的位置参数,类型为元组。 def func(*args, **kwargs):
print("args:", args)
print("kwargs:", kwargs)
func(1, 2, 3, a=10, b=20)
# 输出:
# args: (1, 2, 3)
# kwargs: {'a': 10, 'b': 20}
4. 返回值
函数可以返回值,使用 return 语句。如果不使用 return,函数会返回 None。
def square(x):
return x * x
result = square(4) # 返回值赋给变量
print(result) # 输出: 16
5. 作用域
- 局部变量:在函数内部定义的变量,只在函数内有效。
- 全局变量:在函数外部定义的变量,在整个脚本中有效。
x = 10 # 全局变量
def func():
x = 5 # 局部变量
print(x) # 输出: 5
func()
print(x) # 输出: 10
使用 global 关键字可以在函数内修改全局变量。
def func():
global x
x = 5
func()
print(x) # 输出: 5
6. Lambda 函数
Lambda 函数是匿名函数,用于定义简单的、一次性使用的函数。
# 定义一个复杂的 lambda 函数,接受三个参数,并根据条件返回最大值
max_value = lambda a, b, c: a if a > b else b if b > c else c
# 调用 lambda 函数
result = max_value(10, 20, 15)
print(result) # 输出: 20
7. 函数的文档字符串
使用三引号(""")可以为函数添加文档字符串(docstring),描述函数的功能。
def add(a, b):
"""返回两个数的和"""
return a + b
print(add.__doc__) # 输出: 返回两个数的和
8、Python 元组概述
元组(Tuple)是 Python 中的一种内置数据结构,用于存储多个元素。与列表类似,元组也可以存储不同类型的数据,但与列表不同的是,元组一旦创建后就不能修改,这意味着元组是不可变的。
元组与列表的区别
- 可变性:元组不可变,列表可变。
- 性能:由于不可变性,元组在使用中比列表更为高效,特别是在需要频繁读操作的场景下。
- 用途:元组常用于作为函数参数、返回值、数据结构的键等场景,而列表更多用于需要修改数据的场景。
1. 元组的定义与创建
1.1. 使用圆括号创建元组
元组使用圆括号 () 来定义,元素之间用逗号分隔。即使元组只有一个元素,也要在元素后面加上逗号,否则不会被识别为元组。
# 创建一个包含多个元素的元组
my_tuple = (1, 2, 3, "hello")
# 创建一个空元组
empty_tuple = ()
# 创建一个只有一个元素的元组,注意逗号
single_element_tuple = (5,)
1.2. 省略圆括号
Python 允许在定义元组时省略圆括号,直接用逗号分隔元素即可。
my_tuple = 1, 2, 3, "hello"
2. 元组的访问与操作
2.1. 访问元组元素
可以使用索引来访问元组中的元素,索引从 0 开始。负索引可以从末尾开始访问元素。
my_tuple = (10, 20, 30, 40)
# 访问第一个元素
print(my_tuple[0]) # 输出: 10
# 访问最后一个元素
print(my_tuple[-1]) # 输出: 40
2.2. 元组的切片操作
元组支持切片操作,用于访问子元组。切片语法为 start:end:step,其中 start 是起始索引,end 是结束索引(不包括 end),step 是步长(可选)。
my_tuple = (0, 1, 2, 3, 4, 5)
# 访问从索引 1 到 3 的元素
print(my_tuple[1:4]) # 输出: (1, 2, 3)
# 访问从索引 2 开始的所有元素
print(my_tuple[2:]) # 输出: (2, 3, 4, 5)
# 以步长 2 访问元素
print(my_tuple[::2]) # 输出: (0, 2, 4)
3. 元组的不可变性
元组是不可变的,这意味着一旦创建了元组,其元素不能被修改、添加或删除。
my_tuple = (10, 20, 30)
# 尝试修改元组中的元素会导致错误
# my_tuple[0] = 100 # 会引发 TypeError
# 尝试删除元组中的元素也会导致错误
# del my_tuple[0] # 会引发 TypeError
4. 元组的常见操作
尽管元组是不可变的,但有一些常见操作可以应用于元组。
4.1. 连接与重复
- 连接:可以使用
+操作符连接两个元组,生成一个新的元组。 - 重复:可以使用
*操作符重复元组中的元素。
tuple1 = (1, 2, 3)
tuple2 = (4, 5, 6)
# 连接元组
combined_tuple = tuple1 + tuple2
print(combined_tuple) # 输出: (1, 2, 3, 4, 5, 6)
# 重复元组
repeated_tuple = tuple1 * 2
print(repeated_tuple) # 输出: (1, 2, 3, 1, 2, 3)
4.2. 成员检查
可以使用 in 和 not in 操作符检查某个元素是否在元组中。
my_tuple = (1, 2, 3, 4)
print(2 in my_tuple) # 输出: True
print(5 not in my_tuple) # 输出: True
4.3. 元组的遍历
可以使用 for 循环遍历元组中的所有元素。
my_tuple = ("apple", "banana", "cherry")
for item in my_tuple:
print(item)
# 输出:
# apple
# banana
# cherry
5. 元组的解包
元组可以进行解包操作,将元组中的元素赋值给对应数量的变量。
my_tuple = (1, 2, 3)
# 解包元组
a, b, c = my_tuple
print(a, b, c) # 输出: 1 2 3
# 结合*操作符进行部分解包
a, *b = my_tuple
print(a, b) # 输出: 1 [2, 3]
6. 元组的内置函数
Python 提供了一些内置函数来操作元组:
len():返回元组的长度(元素个数)。max()和min():返回元组中的最大值和最小值(元素必须是可比较的)。sum():对元组中的元素求和(元素必须是数字)。index():返回某个元素在元组中的索引。count():返回某个元素在元组中出现的次数。
my_tuple = (1, 2, 3, 2, 1)
print(len(my_tuple)) # 输出: 5
print(max(my_tuple)) # 输出: 3
print(min(my_tuple)) # 输出: 1
print(sum(my_tuple)) # 输出: 9
print(my_tuple.index(2)) # 输出: 1
print(my_tuple.count(1)) # 输出: 2
9、集合
集合(Set)是 Python 中的一种内置数据类型,用于存储多个元素。与列表和元组不同,集合中的元素是无序且不重复的。集合主要用于去重和集合运算,如并集、交集和差集等。
1. 集合的定义与创建
1.1. 使用花括号创建集合
可以使用花括号 {} 创建集合,元素之间用逗号分隔。
# 创建一个包含多个元素的集合
my_set = {1, 2, 3, "hello"}
# 创建一个空集合
empty_set = set() # 注意:不能使用 {} 创建空集合,那是创建空字典的语法
1.2. 使用 set() 函数创建集合
可以使用 set() 函数将其他可迭代对象(如 列表、元组 )转换为集合。
# 从列表创建集合
my_set = set([1, 2, 3, 3, 4])
print(my_set) # 输出: {1, 2, 3, 4},去除了重复元素
2. 集合的基本操作
2.1. 添加与删除元素
add():向集合添加单个元素。update():向集合添加多个元素,可以传入可迭代对象。remove()和discard():从集合中删除指定元素。remove()在元素不存在时会引发KeyError,而discard()不会。pop():随机删除并返回集合中的一个元素。clear():清空集合中的所有元素。
my_set = {1, 2, 3}
# 添加元素
my_set.add(4)
print(my_set) # 输出: {1, 2, 3, 4}
# 添加多个元素
my_set.update([5, 6])
print(my_set) # 输出: {1, 2, 3, 4, 5, 6}
# 删除元素
my_set.remove(2)
print(my_set) # 输出: {1, 3, 4, 5, 6}
# 删除不存在的元素不会引发错误
my_set.discard(10)
print(my_set) # 输出: {1, 3, 4, 5, 6}
# 随机删除元素
removed_element = my_set.pop()
print(removed_element) # 输出: 被删除的元素
print(my_set) # 输出: 剩余的集合元素
# 清空集合
my_set.clear()
print(my_set) # 输出: set(),空集合
3. 集合的集合运算
集合支持多种常见的集合运算,如并集、交集、差集和对称差集。
3.1. 并集
union()或|:返回两个集合的并集,即所有元素的集合。
set1 = {1, 2, 3}
set2 = {3, 4, 5}
# 并集
print(set1.union(set2)) # 输出: {1, 2, 3, 4, 5}
print(set1 | set2) # 输出: {1, 2, 3, 4, 5}
3.2. 交集
intersection()或&:返回两个集合的交集,即共有元素的集合。
# 交集
print(set1.intersection(set2)) # 输出: {3}
print(set1 & set2) # 输出: {3}
3.3. 差集
difference()或-:返回一个集合中有而另一个集合中没有的元素。
# 差集
print(set1.difference(set2)) # 输出: {1, 2}
print(set1 - set2) # 输出: {1, 2}
3.4. 对称差集
symmetric_difference()或^:返回两个集合中不相同的元素组成的集合。
# 对称差集
print(set1.symmetric_difference(set2)) # 输出: {1, 2, 4, 5}
print(set1 ^ set2) # 输出: {1, 2, 4, 5}
4. 集合的其他操作
4.1. 判断子集与超集
子集和超集是互为对称的概念,但它们之间的区别在于关注的方向不同。
子集关注的是“较小”集合相对于“较大”集合的包含关系:如果集合 (B) 的所有元素都在集合 (A) 中,那么 (B) 是 (A) 的子集。
超集关注的是“较大”集合相对于“较小”集合的包含关系:如果集合 (A) 包含了集合 (B) 的所有元素,那么 (A) 是 (B) 的超集。
issubset():判断一个集合是否为另一个集合的子集。issuperset():判断一个集合是否为另一个集合的超集。
set1 = {1, 2, 3}
set2 = {1, 2}
print(set2.issubset(set1)) # 输出: True,set2 是 set1 的子集
print(set1.issuperset(set2)) # 输出: True,set1 是 set2 的超集
4.2. 判断集合相等
可以使用 == 判断两个集合是否相等,即它们的元素是否完全一致。
set1 = {1, 2, 3}
set2 = {3, 2, 1}
print(set1 == set2) # 输出: True
4.3. 成员检查
可以使用 in 和 not in 检查某个元素是否在集合中。
my_set = {1, 2, 3}
print(1 in my_set) # 输出: True
print(4 not in my_set) # 输出: True
5. 集合的应用场景
- 去重:集合最常见的用途是去除重复元素。
- 集合运算:集合提供了强大的集合运算功能,适用于需要计算交集、并集、差集的场景。
- 元素检查:集合查找元素的时间复杂度为 O(1),适合用于大量元素的快速查找。
10、字典
字典(Dictionary)是 Python 中一种内置的数据类型,用于存储键值对(key-value pairs)。字典是一种可变的、无序的集合,主要用于根据键快速查找对应的值。
1. 字典的定义与创建
1.1. 使用花括号创建字典
可以使用花括号 {} 创建字典,键值对之间用冒号 : 分隔,多个键值对之间用逗号分隔。
# 创建一个包含多个键值对的字典
my_dict = {
"name": "Alice",
"age": 30,
"city": "New York"
}
# 创建一个空字典
empty_dict = {}
1.2. 使用 dict() 函数创建字典
可以使用 dict() 函数通过其他可迭代对象(如列表的元组)创建字典。
# 从键值对的元组列表创建字典
my_dict = dict([("name", "Alice"), ("age", 30), ("city", "New York")])
# 从关键字参数创建字典
my_dict = dict(name="Alice", age=30, city="New York")code>
2. 字典的基本操作
2.1. 访问字典中的值
通过键访问字典中的值。如果键不存在,会引发 KeyError 异常。
my_dict = {"name": "Alice", "age": 30}
# 访问字典中的值
print(my_dict["name"]) # 输出: Alice
# 访问不存在的键会引发 KeyError
# print(my_dict["gender"]) # 引发 KeyError
可以使用 get() 方法访问字典中的值,如果键不存在,则返回 None 或指定的默认值。
# 使用 get() 方法访问字典中的值
print(my_dict.get("name")) # 输出: Alice
print(my_dict.get("gender", "Not Found")) # 输出: Not Found
2.2. 添加与修改键值对
可以通过赋值操作添加新的键值对或修改已有的键值对。
my_dict = {"name": "Alice", "age": 30}
# 添加新的键值对
my_dict["city"] = "New York"
# 修改已有的键值对
my_dict["age"] = 31
print(my_dict) # 输出: {'name': 'Alice', 'age': 31, 'city': 'New York'}
2.3. 删除键值对
使用 del 关键字或 pop() 方法删除键值对。pop() 方法返回被删除的值。
可以用 in 或 not in 判断是否含有该 key, del 删除不存在的 key 会报错
my_dict = {"name": "Alice", "age": 30, "city": "New York"}
# 使用 del 删除键值对
del my_dict["city"]
# 使用 pop() 删除键值对并获取其值
age = my_dict.pop("age")
print(my_dict) # 输出: {'name': 'Alice'}
print(age) # 输出: 30
2.4. 清空字典
使用 clear() 方法清空字典中的所有键值对。
my_dict = {"name": "Alice", "age": 30}
my_dict.clear()
print(my_dict) # 输出: {}
3. 字典的常用方法
keys(): 返回字典中所有键的视图对象。values(): 返回字典中所有值的视图对象。items(): 返回字典中所有键值对的视图对象。update(): 用另一个字典或键值对更新当前字典。
my_dict = {"name": "Alice", "age": 30}
# 获取所有键
print(my_dict.keys()) # 输出: dict_keys(['name', 'age'])
# 获取所有值
print(my_dict.values()) # 输出: dict_values(['Alice', 30])
# 获取所有键值对
print(my_dict.items()) # 输出: dict_items([('name', 'Alice'), ('age', 30)])
# 更新字典
my_dict.update({"city": "New York", "age": 31})
print(my_dict) # 输出: {'name': 'Alice', 'age': 31, 'city': 'New York'}
4. 字典的遍历
可以使用 for 循环遍历字典的键、值或键值对。
my_dict = {"name": "Alice", "age": 30}
# 遍历字典的键
for key in my_dict:
print(key)
# 遍历字典的值
for value in my_dict.values():
print(value)
# 遍历字典的键值对
for key, value in my_dict.items():
print(f"{key}: {value}")
5. 字典的特性
- 无序:字典中的键值对没有顺序。在 Python 3.7 及更高版本中,字典保持插入顺序。
- 键的唯一性:字典中的键是唯一的,不能重复。如果重复插入相同的键,后插入的值会覆盖之前的值。
- 键的不可变性:字典的键必须是不可变的数据类型,例如字符串、整数、元组等。列表和其他可变类型不能作为字典的键。
6. 应用场景
- 快速查找:字典提供 O(1) 时间复杂度的查找操作,适用于需要快速检索数据的场景。
- 存储关联数据:字典非常适合用于存储关联数据,例如数据库的记录、配置项等。
11、类
Python中的类(Class)是面向对象编程的核心概念之一。类定义了一个对象的结构和行为,允许我们创建具有相同属性和方法的多个实例(对象)。
1. 类的定义
在Python中,使用class关键字来定义一个类。类的名字通常遵循大驼峰命名法(每个单词的首字母大写),以便与函数名或变量名区分开来。以下是一个简单的类定义示例:
class Animal:
pass # 空类,暂不定义任何属性或方法
2. 类的构造函数
类的构造函数是指在创建对象时自动调用的特殊方法。在Python中,构造函数使用__init__方法定义。构造函数通常用于初始化对象的属性。下面是一个包含构造函数的类定义示例:
class Animal:
def __init__(self, name, species):
self.name = name # 实例属性
self.species = species # 实例属性
在上面的例子中,__init__方法接受name和species两个参数,并将它们赋值给对象的实例属性self.name和self.species。
3. 创建对象(实例化)
类定义完成后,可以通过调用类的名称来创建对象。这个过程称为实例化。实例化时会自动调用类的构造函数,并返回一个类的实例:
dog = Animal("Buddy", "Dog")
print(dog.name) # 输出: Buddy
print(dog.species) # 输出: Dog
4. 类的方法
类的方法是定义在类内部的函数。方法的第一个参数通常是self,它指向类的实例本身,从而允许方法访问和修改实例属性。以下是一个带有方法的类示例:
class Animal:
def __init__(self, name, species):
self.name = name
self.species = species
def speak(self):
return f"{self.name} says hello!"
你可以通过类的实例来调用方法:
dog = Animal("Buddy", "Dog")
print(dog.speak()) # 输出: Buddy says hello!
5. 类属性与实例属性
- 实例属性:定义在
__init__方法中的属性,每个实例独有。 - 类属性:定义在类体内部但不在
__init__方法中的属性,所有实例共享。
class Animal:
kingdom = "Animalia" # 类属性
def __init__(self, name, species):
self.name = name # 实例属性
self.species = species # 实例属性
可以通过类名或实例来访问类属性:
print(Animal.kingdom) # 输出: Animalia
dog = Animal("Buddy", "Dog")
print(dog.kingdom) # 输出: Animalia
6. 继承
Python支持类的继承机制,即一个类可以继承另一个类的属性和方法。继承允许我们重用代码并构建层次化的类结构。以下是继承的示例:
class Dog(Animal): # Dog类继承Animal类
def __init__(self, name, breed):
super().__init__(name, "Dog") # 调用父类的构造函数
self.breed = breed # 新增属性
def speak(self):
return f"{self.name} says woof!"
在这个例子中,Dog类继承了Animal类,并重写了speak方法。super().__init__(name, "Dog")调用父类的构造函数来初始化name和species属性。
7. 多态
多态是指同一方法在不同对象上表现出不同的行为。通过继承和方法重写,多态在Python中得以实现。例如:
class Cat(Animal):
def speak(self):
return f"{self.name} says meow!"
animals = [Dog("Buddy", "Golden Retriever"), Cat("Whiskers")]
for animal in animals:
print(animal.speak())
输出将分别调用Dog和Cat的speak方法:
Buddy says woof!
Whiskers says meow!
8. 封装与私有化
封装是将对象的状态(属性)和行为(方法)隐藏在类内部,外部不能直接访问类的内部状态。Python通过在属性名前加上双下划线__来实现属性的私有化:
class Animal:
def __init__(self, name, species):
self.__name = name # 私有属性
def get_name(self):
return self.__name # 通过方法访问私有属性
在外部代码中,无法直接访问私有属性:
dog = Animal("Buddy", "Dog")
print(dog.__name) # 抛出 AttributeError 错误
print(dog.get_name()) # 输出: Buddy
9. 类与静态方法
- 类方法:使用
@classmethod装饰器定义,第一个参数为cls,表示类本身。 - 静态方法:使用
@staticmethod装饰器定义,不需要传入self或cls。
class Animal:
population = 0
def __init__(self, name, species):
self.name = name
self.species = species
Animal.population += 1
@classmethod
def get_population(cls):
return cls.population
@staticmethod
def is_animal(thing):
return isinstance(thing, Animal)
调用类方法和静态方法:
dog = Animal("Buddy", "Dog")
cat = Animal("Whiskers", "Cat")
print(Animal.get_population()) # 输出: 2
print(Animal.is_animal(dog)) # 输出: True
10. 魔法方法
Python的类中有一些特殊方法被称为魔法方法(Magic Methods),它们以双下划线开头和结尾,提供了一种定制类行为的方式。常见的魔法方法有:
__str__:定义对象的字符串表示。
示例:
class Animal:
def __str__(self):
return f"{self.name} the {self.species}"
# str(dog) 时会调用上面的方法
12、异常
1. 什么是异常?
异常(Exception)是指程序在运行时遇到的错误情况,这些错误会导致程序的正常执行流程被中断。常见的异常包括除零错误、索引超出范围错误等。
例如,以下代码会抛出ZeroDivisionError异常:
print(10 / 0) # 抛出ZeroDivisionError: division by zero
2. 异常的基本处理:try...except
为了防止程序因异常而崩溃,可以使用try...except语句来捕获并处理异常。try块中的代码会尝试执行,如果出现异常,except块中的代码会被执行:
try:
print(10 / 0)
except ZeroDivisionError:
print("不能除以零!")
上面的代码会捕获ZeroDivisionError并输出"不能除以零!"而不是崩溃。
3. 捕获多个异常
可以使用多个except块来捕获不同类型的异常,也可以在一个except块中同时捕获多个异常:
try:
lst = [1, 2, 3]
print(lst[5])
except IndexError:
print("索引超出范围!")
except ZeroDivisionError:
print("不能除以零!")
或者:
try:
result = 10 / 0
except (ZeroDivisionError, IndexError):
print("出现了除零或索引错误")
4. 获取异常信息
可以使用except块的as关键字获取异常对象,从而访问异常的详细信息:
try:
print(10 / 0)
except ZeroDivisionError as e:
print(f"发生异常: {e}")
输出将为:"发生异常: division by zero"。
5. else和finally块
else块:当try块中的代码没有发生异常时,else块中的代码会被执行。
try:
result = 10 / 2
except ZeroDivisionError:
print("不能除以零!")
else:
print(f"结果是: {result}")
finally块:无论是否发生异常,finally块中的代码都会被执行,通常用于释放资源或执行清理操作。
try:
file = open("example.txt", "r")
content = file.read()
except FileNotFoundError:
print("文件未找到!")
finally:
file.close()
print("文件已关闭")
6. 抛出异常
在Python中,你可以使用raise语句手动抛出异常。抛出异常时可以提供异常信息:
def check_positive(number):
if number < 0:
raise ValueError("数字必须为正数!")
return number
try:
check_positive(-5)
except ValueError as e:
print(e)
输出:"数字必须为正数!"
7. 自定义异常
你可以通过继承Exception类来自定义异常,以处理特定的错误情况:
class NegativeNumberError(Exception):
pass
def check_positive(number):
if number < 0:
raise NegativeNumberError("数字不能为负数!")
return number
try:
check_positive(-5)
except NegativeNumberError as e:
print(e)
8. 常见的内置异常
Python提供了许多内置异常,用于表示常见的错误情况。以下是一些常见的内置异常:
ValueError:传递给函数的参数值无效。TypeError:操作或函数应用于错误类型的对象。IndexError:尝试访问超出序列范围的索引。KeyError:尝试访问字典中不存在的键。FileNotFoundError:尝试打开不存在的文件。IOError:输入/输出操作失败。ZeroDivisionError:除法或取余操作中,除数为零。
13、包管理
Python的包管理和虚拟环境管理是开发过程中非常重要的部分。通过正确地使用这些工具,可以有效地组织项目、管理依赖,并避免不同项目之间的依赖冲突。
1. 什么是包?
在Python中,包(Package)是一种组织模块的方式。一个包实际上是一个包含__init__.py文件的目录,这个文件可以是空的,也可以包含包的初始化代码。包通常用于将相关的模块分组,以便更好地组织代码。
示例
假设有一个名为my_package的包,结构如下:
my_package/
__init__.py
module1.py
module2.py
可以使用以下方式导入包中的模块:
from my_package import module1
import my_package.module2
2. 包管理工具:pip
pip是Python的包管理工具,用于安装、更新、和卸载Python包。pip从Python包索引(PyPI)中下载和管理包。
2.1 安装包
可以使用pip install命令来安装包:
pip install requests
这会安装requests库及其依赖项。
2.2 更新包
使用pip install --upgrade可以更新已安装的包:
pip install --upgrade requests
2.3 卸载包
使用pip uninstall命令可以卸载已安装的包:
pip uninstall requests
2.4 查看已安装的包
使用pip list命令可以查看当前环境中已安装的所有包:
pip list
文章到这里就结束了
上一篇: 【开发环境】Mac 安装 Visual Studio Code ② ( 装 C/C++ 扩展 | 安装配置 Code Runner 扩展插件 | 运行 C 语言程序 )
下一篇: 自定义数据类型
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。