Rust项目的代码组织
cnblogs 2024-08-04 12:39:00 阅读 73
学习一种编程语言时,常常优先关注在语言的语法和标准库上,希望能够尽快用上新语言来开发,
我自己学习新的开发语言时也是这样。
不过,想用一种新的语言去开发实际的项目,或者自己做点小工具的话,除了语言本身之外,
了解它在项目中如何组织代码也是至关重要的。
毕竟在实际项目中,不可能像学习语言时那样,常常只有一个代码文件。
本文主要介绍<code>Rust语言中常见的代码组织方式,我用Rust的时间也不长,不当之处,敬请指正。
1. 管理代码的单元
Rust在语言层面提供了3个代码管理单元,分别是:
module:模块,类似于其他语言中的命名空间,一般是封装了某个具体功能的实现。crate:Rust编译的最小单元,每个crate中有一个Cargo.toml文件来配置crate相关信息,一个`crate`可以是一个库也可以是一个二进制。package:一个package可以视为一个项目,cargo new命令创建的就是package。
这三者的关系是一个package可以包含多个crate,一个crate可以包含多个module。
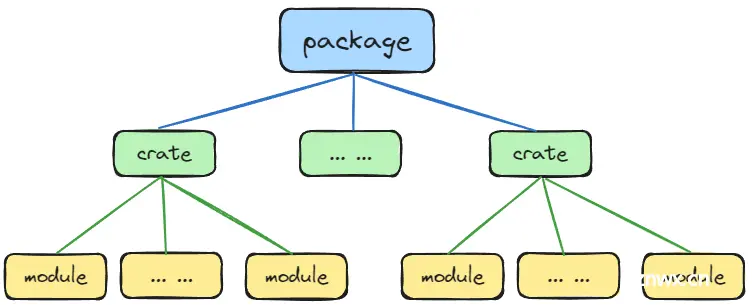
对于一般的项目来说,常见的代码组织形式是一个crate+多个module。
如果功能复杂,业务比较多的话,可以将独立的功能或者业务封装成<code>crate,变成一个package包含多个crate+多个module。
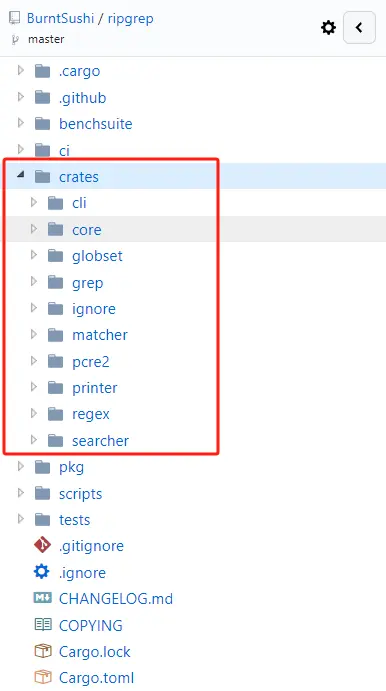
比如官方推荐用来学习Rust的项目 ripgrep(https://github.com/BurntSushi/ripgrep)。
就是多crate的项目,每个crate中有自己的Cargo.toml配置。
2. 模块(module)
<code>package,crate和module三种组织代码的方式中,最常用的就是module。
下面主要介绍Rust中module的定义和引用方式。
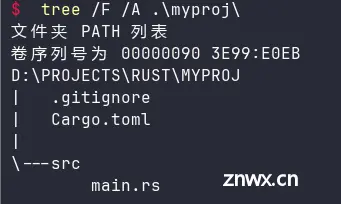
首先,我们创建一个演示用的项目。
$ cargo new myproj
Creating binary (application) `myproj` package
默认项目的目录结构如下:
2.1. 同文件中的模块
<code>Rust的模块不一定要定义在单独的文件中,同一个文件中可以定义多个不同的模块。
这一点和有些按照文件和目录来区分模块的语言是不一样的。
比如,下面在main.rs中定义了两个模块data和compute:
mod data {
pub fn fetch_data() -> Vec<u32> {
vec![1, 2, 3]
}
}
mod compute {
pub fn square_data(data: &Vec<u32>) -> Vec<u32> {
let mut new_data: Vec<u32> = vec![];
for i in data {
new_data.push(i.pow(2));
}
new_data
}
}
use compute::square_data;
use data::fetch_data;
fn main() {
let data = fetch_data();
println!("fetch data: {:?}", data);
let new_data = square_data(&data);
println!("square data: {:?}", new_data);
}
引用同一文件中的模块很简单,直接use模块和对应的方法即可。
use compute::square_data;
use data::fetch_data;
执行效果如下:

也许你会有这样的疑问,既然都在同一个文件中,为什么还要定义模块,直接定义两个函数不就可以了,
这样<code>main函数中直接就可以使用,还省得去引用模块。
因为对于一些代码比较短,但是通用性高的功能函数(比如简单的字符串转换,日期格式转换),
每个函数都创建一个模块文件的话,略显繁琐,统一在一个文件中定义反而更加清爽简洁。
以后如果模块中的功能越来越多,越来越复杂,再将此模块重构到一个单独的文件中也不迟。
2.2. 同目录中的模块
同文件中的模块引用非常简单,但是当模块中的代码逐渐增多之后,就需要考虑用一个单独的文件来定义模块。
比如,将上面代码中模块data和compute中的函数分别放入不同的文件。
文件结构如下:
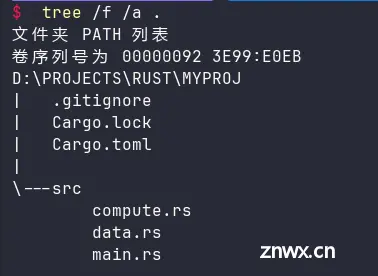
其中 src 目录下的3个文件中的内容分别为:
pub fn fetch_data() -> Vec<u32> {
vec![1, 2, 3]
}
// compute.rs 文件
pub fn square_data(data: &Vec<u32>) -> Vec<u32> {
let mut new_data: Vec<u32> = vec![];
for i in data {
new_data.push(i.pow(2));
}
new_data
}
// main.rs
mod compute;
mod data;
use compute::square_data;
use data::fetch_data;
fn main() {
let data = fetch_data();
println!("fetch data: {:?}", data);
let new_data = square_data(&data);
println!("square data: {:?}", new_data);
}
注意这里与上一节同文件中模块的几点不同。
首先,在模块的文件data.rs和compute.rs中,直接定义函数即可,
不用加上 mod data{}这样的模块名,因为文件名data和compute会自动作为模块的名字。
其次,在main.rs文件中引用不同文件的模块时,
需要先定义模块(相当于导入了data.rs和compute.rs),
mod compute;
mod data;
然后在 use 其中的函数。
use compute::square_data;
use data::fetch_data;
2.3. 不同目录中的模块
最后在看看不同目录中的模块如何引用。
当项目功能逐渐增多和复杂之后,一个功能模块就不止一个文件了,所以就需要将模块封装到不同的目录中。
比如一个普通的Web系统,其中日志模块,数据库模块等等都会单独封装到不同的目录中。
重新修改示例中的文件,代码改为如下的结构:
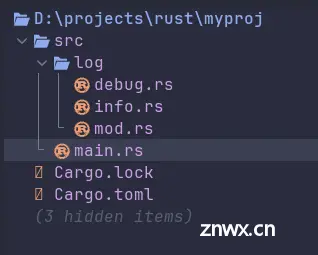
封装一个日志模块,其中有2个输出日志的代码文件(<code>debug.rs和info.rs),分别输出不同级别的日志。
然后在代码中引用日志模块并输出日志。
各个文件的代码分别如下:
// debug.rs 文件
pub fn log_msg(msg: &str) {
println!("[DEBUG]: {}", msg);
}
// info.rs 文件
pub fn log_msg(msg: &str) {
println!("[INFO]: {}", msg);
}
// main.rs 文件
mod log;
use crate::log::debug;
use crate::log::info;
fn main() {
debug::log_msg("hello");
info::log_msg("hello");
}
注意,除了上面这3个文件,在log文件夹中还有个mod.rs文件,
这个文件至关重要,其中的内容就是定义log文件夹中有哪些模块。
// mod.rs 文件
pub mod debug;
pub mod info;
有了这个文件,log文件夹才会被Rust当成是一个模块,才可以在main.rs中引用mod log;。
执行效果如下:

接下来,再增加一个<code>database模块,让database模块引用log模块中的函数,
也就是兄弟模块间的引用。
文件目录结构变为:
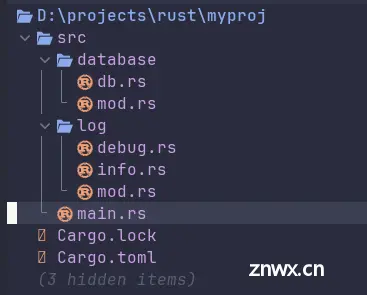
新增的<code>database模块中两个文件中的代码如下:
// db.rs
use crate::log::debug;
use crate::log::info;
pub fn create_db() {
debug::log_msg("start to create database");
info::log_msg("Create Database");
debug::log_msg("success to create database");
}
// mod.rs
pub mod db;
main.rs中的代码如下:
// main.rs
mod database;
mod log;
use crate::database::db;
fn main() {
db::create_db();
}
执行结果如下:

这里有一点需要注意,<code>database模块的db.rs中直接引用了log模块中的函数,
需要在main.rs中定义mod log;。
虽然main.rs中没有直接使用log模块中的内容,仍然需要定义mod log;
否则database模块中的db.rs无法引用log模块中的函数。
2.4. 模块的相对和绝对引用
Rust模块的引用有两种方式,相对路径的引用和绝对路径的引用。
上面的示例中都是绝对引用,比如:use crate::log::debug;,use crate::database::db;。
绝对引用以crate开头,可以把crate理解为的代码的根模块。
相对引用有两个关键字,self和super,self表示同级的模块,super表示上一级的模块。
比如,上面示例中main.rs和db.rs文件中的模块也可以改为相对引用:
//main.rs
// use crate::database::db;
use self::database::db;
//db.rs
// use crate::log::debug;
// use crate::log::info;
use super::super::log::debug;
use super::super::log::info;
3. 包(crate)
crate是Rust编译和发布的最小单元,一般项目都是单crate多module的,
如果项目中某些模块通用型强,可能会单独发布给其他项目用,那么把这些模块封装成crate也是不错的想法。
用Rust时间不长,还没有实际用到多crate的情况,感兴趣的话可以参考ripgrep项目(https://github.com/BurntSushi/ripgrep)。
4. 总结
本文重点介绍了Rust中模块(module)的定义和引用方式,目的为了让我们在使用Rust时能够合理的组织和重构自己的代码。
上一篇: 大数据技术之Scala语言,只需一篇文章即可,教你学会什么是Scala,教你如何使用Scala
下一篇: Java多线程-----Thread类的基本用法,线程的状态及其转化 ✧*(ˊᗜˋ*) ✧*
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。