深度解析C++中函数重载与引用
Yui_ 2024-09-07 12:35:01 阅读 88
🌈个人主页:Yui_
🌈Linux专栏:Linux
🌈C语言笔记专栏:C语言笔记
🌈数据结构专栏:数据结构
🌈C++专栏:C++
文章目录
1. 函数重载1.1 函数重载概念1.2 C++支持函数重载的原理--名字修饰(name Mangling)
2. 引用2.1 引用的概念2.2 引用的特性2.3 常引用2.4 使用场景2.5 传值、传引用效率比较2.6 引用和指针的区别
1. 函数重载
在中文语境中有些词语它就是一词多义的,人们通过上下文来判断词语的意思,即该词被重载了。
就比如说:以前有个笑话,我们国家有两个体育项目大家根本不用看,也不用担心。一个是乒乓球,一个是足球。前者"谁也赢不了"后者"谁也赢不了"。
1.1 函数重载概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些函数的形参列表(参数个数或者类型或者类型顺序)不同,常用来处理功能类似数据类型不同的问题。
<code>#include <iostream>
using namespace std;
//1.参数类型不同
int add(int left,int right)
{ -- -->
cout<<"int add(int left,int right)"<<endl;
return left+right;
}
double add(double left,double right)
{
cout<<"double add(double left,double right)"<<endl;
return left+right;
}
//2.参数个数不同
void test()
{
cout<<"test()"<<endl;
}
void test(int a)
{
cout<<"test(int a)"<<endl;
}
//3.参数类型顺序不同
void test2(int a,char b)
{
cout<<"test2(int a,char b)"<<endl;
}
void test2(char b,int a)
{
cout<<"test2(char b,int a)"<<endl;
}
int main()
{
add(1,2);
add(1.1,2.2);
test();
test(100);
test2(10,'a');
test2('a',10);
return 0;
}
1.2 C++支持函数重载的原理–名字修饰(name Mangling)
为什么C++支持函数重载,而C语言不支持函数重载呢?
在C/C++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接。


实际项目中通常是由多个头文件和多个源文件构成的,而通过C语言阶段学习的编译链接,我们可以知道,【当前a.cpp中调用了b.cpp中定义的Add函数时】,编译后链接前,a.o的目标文件中没有Add的函数地址,因为Add是在b.cpp中定义的,所以Add的地址在b.o中。那么怎么办呢?所以链接阶段就是专门处理这种问题的,链接器看到a.o调用Add,但是没有Add的地址,就会到b.o的符号表中找Add的地址,然后链接到一起。那么链接时,面对Add函数,链接器会使用哪个名字去找呢?这里每个编译器都有自己的函数名修饰规则。由于windows下vs的修饰规则过于复杂,而Linux下g++的修饰规则简单易懂,下面我们使用了g++演示这个修饰后的名字。通过下面我们可以看到gcc的函数修饰后名字不变。而g++的函数修饰后变成【__Z+函数长度+函数名+类型首字母】
采用C语言编译器编译后的结果:
<code>//file.c中的代码
#include <stdio.h>
int Add(int a,int b)
{ -- -->
return a+b;
}
void test(int a,double b,int*p)
{
//...
}
int main()
{
Add(10,20);
test(1,2,0);
return 0;
}
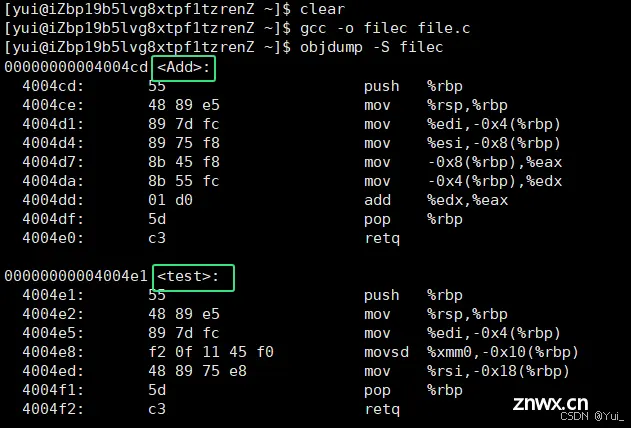
结论:在Linux下,采用gcc编译完成后,函数名字的修饰没有发生改变。
采用C++编译器编译后结果:
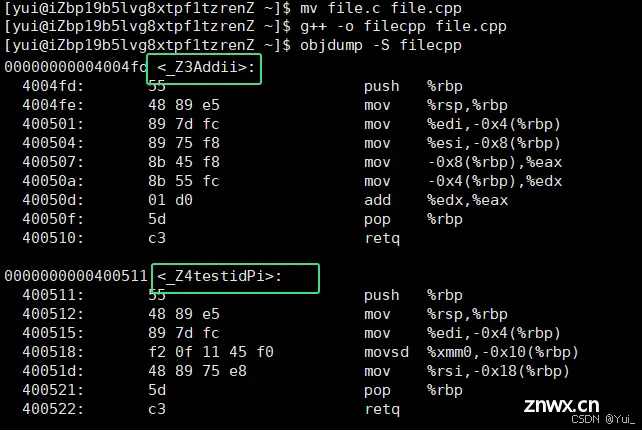
结论:在Linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中。
windows下名字修饰规则
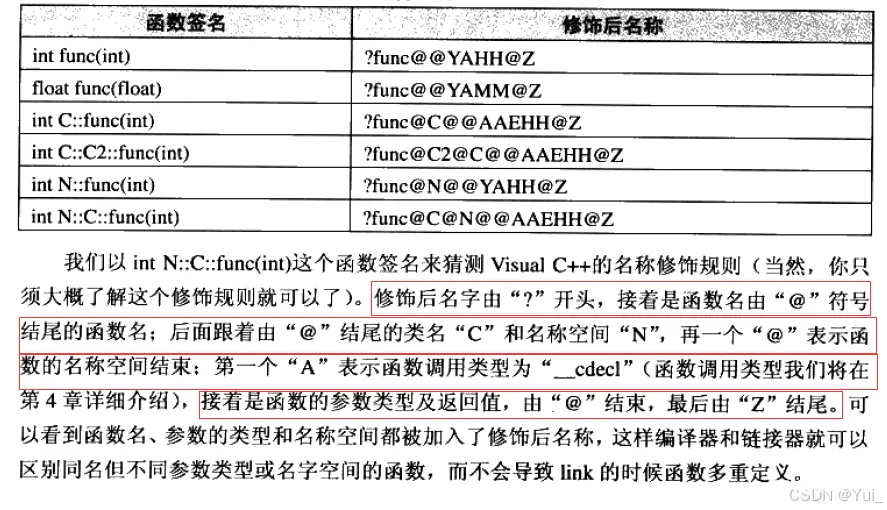
总结:对比Linux会发现,Windows下vs编译器对函数名字修饰规则相对复杂难懂,但道理类似。
6. 通过这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修饰规则来区分地,只要参数不同,修饰出来地名字就不一样,那么就可以支持重载了。
7. 如果两个函数函数名和参数是一样的,返回值不同是不构成重载的,因为调用时编译器没办法区分。
2. 引用
2.1 引用的概念
引用不是新定义一个变量,而是给已存在变量取一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
就像外号一样,尽管名字不同但人都是一个人。
语法:
<code>类型& 引用变量名(对象名) = 引用实体
#include <cstdio>
void test()
{ -- -->
int a = 10;
int& ra = a;//定义引用类型
printf("%p\n", &a);
printf("%p\n", &ra);
}
int main()
{
test();
return 0;
}
//打印结果:
/*
009EFDE0
009EFDE0
*/
注意:引用类型必须和引用实体是同种类型的。
2.2 引用的特性
引用在定义时必须初始化。一个变量可以有多个引用。引用一旦引用一个实体,就不能再引用其他实体。
void test()
{
int a = 10;
//int& ra;//引用在定义时必须初始化,否则报错
int& ra = a;
int& rra = a;
printf("%p\n", &a);
printf("%p\n", &ra);
printf("%p\n", &rra);
}
//打印结果:
/*
00AFF9A0
00AFF9A0
00AFF9A0
*/
2.3 常引用
void testconstref()
{
const int a = 10;
//int& ra = a;//该语句编译时会出错,a为常量
const int& ra = a;
//int& b = 10;//该语句编译时会出错,10为常量
const int& b = 10;
double d = 3.14;
//int& rd = d;该语句编译时会出错,类型不同
const int& rd = d;
}
2.4 使用场景
做参数
void Swap(int& left,int& right)
{
int temp = left;
left = right;
right = temp;
}
做返回值
int& Count()
{
static int n = 0;
n++;
//...
return n;
}
观察下来代码,会输出什么结果?
#include <iostream>
using namespace std;
int& add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = add(2, 3);
add(4, 5);
cout << "add(2,3) is :" << ret << endl;
return 0;
}
//打印结果
/*
add(2,3) is :9
*/
函数运行时,系统需要给函数开辟独立的栈空间,用来保存函数的形参,局部变量以及一些寄存器信息等。
函数运行结束后,该函数对应的栈空间就被系统回收了。
空间被回收指该栈空间暂时不能使用,但是内存还在,比如:上课申请教室,上完课之后教师归还给学校,但是教室本身还在,不能说归还后,教室就消失了。
注意:如果函数返回了,出了函数作用域,如果返回对象还在(没有还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。
2.5 传值、传引用效率比较
以值作为参数或者返回类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时拷贝,因此用值作为参数或者返回类型,效率是非常低下的,尤其是当参数或返回类型非常大时,效率就更低。
演示:效率对比,值和引用作为参数类型的性能对比
#include <iostream>
#include <ctime>
using namespace std;
struct A
{
int a[10000];
};
void TestFunc(A a)
{
}
void TestFunc2(A& a)
{
}
int main()
{
A a;
//以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
{
TestFunc(a);
}
size_t end1 = clock();
//以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
{
TestFunc2(a);
}
size_t end2 = clock();
//分别计算两个函数运行结束后的时间
cout << "Testfunc(A) time:" << end1 - begin1 << endl;
cout << "Testfunc2(A&) time:" << end2 - begin2 << endl;
return 0;
}
//打印结果
/*
Testfunc(A) time:12
Testfunc2(A&) time:0
(单位毫秒)
*/
演示:值和引用的作为返回类型的性能对比
#include <iostream>
#include <ctime>
using namespace std;
struct A
{
int a[10000];
};
struct A a;
//值返回
A TestFunc()
{
return a;
}
//引用返回
A& TestFunc2()
{
return a;
}
int main()
{
//以值作为函数的返回类型
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
{
TestFunc();
}
size_t end1 = clock();
//以引用作为函数的返回类型
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
{
TestFunc2();
}
size_t end2 = clock();
//分别计算两个函数运行结束后的时间
cout << "Testfunc(A) time:" << end1 - begin1 << endl;
cout << "Testfunc2(A&) time:" << end2 - begin2 << endl;
return 0;
}
//打印结果
/*
Testfunc(A) time:25
Testfunc2(A&) time:1
*/
结论:通过上述的代码可以清楚的发现,传值和传引用在作为传参以及返回值类型上效率相差很大。
2.6 引用和指针的区别
在语法层面上呢,引用就是一个别名,没有独立空间,和其被引用体共用一块空间。
#include <iostream>
using namespace std;
int main()
{
int val = 100;
int& rval = val;
cout<<"&val = "<<&val<<endl;
cout<<"&rval = "<<&rval<<endl;
return 0;
}
//打印结果
/*
&val = 003AFB98
&rval = 003AFB98
*/
但是呢,在底层方面实际是由空间的,因为引用是按照指针方式来实现的。
#include <iostream>
using namespace std;
int main()
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20
return 0;
}
反汇编:
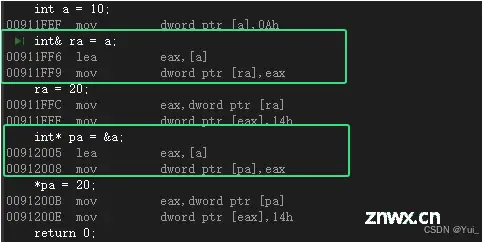
可以看到操作是类似的。
引用和指针的不同点:
引用概念上定义一个变量的别名,指针存储一个变量地址。引用在定义时必须初始化,指针就没有要求。引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以再任何时候指向任何一个同类型实体。没有NULL引用,但是又NULL指针再sizeof中含义不同:引用结果为引用类型的大小,但是指针始终是地址空间所占字节数个(根据所在平台确定,如32位平台占4个字节)引用自加即引用的实体加1,指针自加即指针向后偏移一个类型的大小。由多级指针,但是没有多级引用。访问实体方式不同,指针需要显示解引用,引用编译器自己处理。引用比指针使用起来相对安全。
上一篇: FFmpeg开发笔记(五十一)适合学习研究的几个音视频开源框架
下一篇: 【C语言必学知识点七】你知道如何实时改变申请好的内存空间的大小吗?你知道什么是动态内存管理吗?你知道如何进行动态内存管理吗?
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。