字符串
cnblogs 2024-09-30 10:09:00 阅读 96
字符串基操
常用字符串
<code>import string
# 获取所有的小写字母
variable = string.ascii_lowercase # abcdefghijklmnopqrstuvwxyz
# 获取所有的大写字母
variable = string.ascii_uppercase # ABCDEFGHIJKLMNOPQRSTUVWXYZ
# 获取所有的小写和大写字母
variable = string.ascii_letters # abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
# 获取八进制数字
variable = string.octdigits # 01234567
# 获取十进制数字
variable = string.digits # 0123456789
# 获取十六进制数字
variable = string.hexdigits # 0123456789abcdefABCDEF
# 获取所有的标点字符
variable = string.punctuation # !"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~
# 获取所有可打印字符
variable = string.printable # 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c
# 获取所有的空白字符
variable = string.whitespace
大小写转换
st = "hello PYTHON coders"
# 将字符串的第一个字母变成大写,其余字母变为小写
variable = st.capitalize() # 输出:Hello python coders
# 返回一个满足标题格式的字符串。即所有英文单词首字母大写,其余英文字母小写
variable = st.title() # 输出:Hello Python Coders
# 将字符串中的大小写字母同时进行互换
variable = st.swapcase() # 输出:HELLO python CODERS
# 将字符串中的所有大写字母转换为小写字母
variable = st.lower() # 输出:hello python coders
# 将字符串中的所有大写字母转换为小写字母。也可以将非英文语言中的大写转换为小写
variable = st.casefold()
# 将字符串中的所有小写字母转换为大写字母
variable = st.upper() # 输出:HELLO PYTHON CODERS
字符串替换
st = "Hello Python Coders"
# 把st中的 e 替换成 E,如果 count 指定,则替换不超过 count 次,返回一个新的字符串,原字符串没有改变
variable = st.replace('e', 'E') # HEllo Python CodErs
variable = st.replace('e', 'E', 1) # HEllo Python Coders
# 制表符替换,将字符串中的 \\t 替换为一定数量的空格。默认tabsize=8
variable = st.expandtabs(tabsize=8)
字符串倒序
st = "hello Python coders"
# 将字符串倒序,反转字符串,注意:这得到的是一个新的字符串
variable = st[::-1]
字符串统计
st = "Hello Python Coders"
# 统计字符串里某个字符出现的次数,可以选择字符串索引的起始位置和结束位置
variable = st.count('o')
# 统计 [0, 10) 区间字母 o 出现的次数
variable = st.count('o', 0, 10)
# 获取字符串的长度
print(len(st)) # 输出: 19
字符串切片
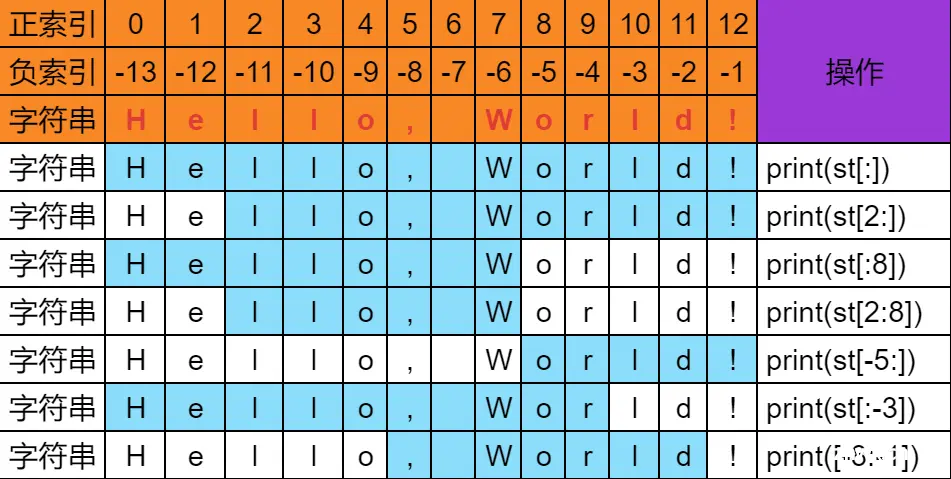
字符串切割
<code># 从左边开始切割且只切割一次,根据指定的分隔符将字符串进行分割。从字符串左边开始索引分隔符sep,索引到则停止索引
st.partition('l')
# 从右边开始切割且只切割一次,根据指定的分隔符将字符串进行分割。从字符串右边(末尾)开始索引分隔符sep,索引到则停止索引
st.rpartition('l')
# 常用切割从左到右,拆分字符串。通过指定分隔符sep对字符串进行分割,并返回分割后的字符串列表
st.split(' ')
# 常用切割从右到左,拆分字符串。 rsplit()函数是从字符串右边(末尾)开始分割
st.rsplit('l')
# 按照换行符分割,按照('\\n','\\r',\\r\\n'等)分隔,返回列表,默认不包含换行符,keepends=True则保留换行符
st.splitlines()
字符串清理
variable = st.lstrip() # 删除字符串左边的空格或指定字符(默认为空格)
variable = st.rstrip() # 删除字符串右边的空格或指定字符(默认为空格)
variable = st.strip() # 删除字符串两端的空格或指定字符(默认为空格),不会去除字符串中间对应的字符
variable = "00000003210Runoob01230000000".strip('0') # 去除首尾字符 0,输出:3210Runoob0123
字符串对齐
字符串中间对齐
st = "hello python coders"
# 返回长度为width,两边用(单字符)填充的字符串,若字符串的长度大于width,则直接返回字符串
variable = st.center(42, '*') # 输出:***********hello python coders************
字符串左对齐
st = "hello python coders"
# 返回原字符串左对齐,并使用(单字符)填充(默认为空格)至指定长度的新字符串
variable = st.ljust(42, '*') # 输出:hello python coders***********************
字符串右对齐
st = "hello python coders"
# 返回原字符串右对齐,并使用(单字符)填充(默认为空格)至指定长度的新字符串
variable = st.rjust(42, '*') # 输出:***********************hello python coders
字符串填充对齐
st = "hello python coders"
# 返回指定长度的字符串,使原字符串右对齐,前面用0填充到指定字符串长度
variable = st.zfill(42) # 输出:00000000000000000000000hello python coders
字符串查找
使用 find() 方法从左往右查找
st = "hello python coders"
# 查找字符串中指定的子字符串sub第一次出现的位置,可以规定字符串的索引查找范围。若无则返回 -1
variable = st.find('e') # 输出:1
variable = st.find('e', 3) # 输出:16
variable = st.find('e', 3, 10) # 输出:-1
使用 rfind() 方法从右往左查找
st = "hello python coders"
# 查找字符串中指定的子字符串sub最后一次出现的位置,可以规定字符串的索引查找范围。若无则返回 -1
variable = st.rfind('e') # 输出:16
variable = st.rfind('e', 6) # 输出:16
variable = st.rfind('e', 6, 10) # 输出:-1
variable = st.rfind('e', 0, 10) # 输出:1
使用 index() 方法从左往右查找
st = "hello python coders"
# 查找字符串中第一次出现的子字符串的位置,可以规定字符串的索引查找范围[star, end)。若无则会报错
variable = st.index('e') # 输出:1
variable = st.index('e', 2) # 输出:16
variable = st.index('e', 2, 8) # 报错
使用 rindex() 方法从右往左查找
st = "hello python coders"
# 查找字符串中最后一次出现的子字符串的位置,可以规定字符串的查找范围[star, end)。若无则会报错
variable = st.rindex('e') # 输出:16
variable = st.rindex('e', 3) # 输出:16
variable = st.rindex('e', 0, 5) # 输出:1
variable = st.rindex('e', 2, 8) # 报错
字符串拼接
使用 “+” 号拼接
str1 = "Hello, "
str2 = "World!"
result = str1 + str2
print(result) # 输出: Hello, World!
使用 join() 方法拼接
str_list = ["Hello", "World", "!"]
result = "".join(str_list)
print(result) # 输出: HelloWorld!
字符串格式化
st = "hello Python coders"
print(f"{st}") # 输出:hello Python coders
print(f"{st=}") # 输出:st='hello Python coders'code>
test = 'My name is {}'
# 格式化字符串,在字符串中使用大括号作为占位符
print(f"{test.format('jack')}") # 输出:My name is jack
people = {"name": "john", "age": 33}
name_age = 'My name is {name}, i am {age} old!'
# 仅使用于字符串格式中可变数据参数来源于字典等映射关系数据时可以使用这种方式
print(f"{name_age.format_map(people)}") #输出:My name is john, i am 33 old!
字符串去重
通过for循环实现去重
name = '王李张李陈王杨张吴周王刘赵黄吴杨'
newname = ''
for char in name:
if char not in newname:
newname += char
print(newname)
通过while循环实现去重
name = '123241536718965'
newname = ''
length = len(name) - 1
while True:
if length >= 0:
if name[length] not in newname:
newname += name[length]
length -= 1
else:
break
print(newname)
利用集合的特性实现去重
name = '王李张李陈王杨张吴周王刘赵黄吴杨'
newname = list(set(name))
# 保持索引顺序不变
newname.sort(key=name.index)
print(''.join(newname))
在原字符串上删除实现去重
name = '王李张汪李陈王杨张吴周王刘赵黄吴杨'
for s in name:
if s in name[1:]:
name = name[1:]
else:
name = name[1:] + name[0]
print(name)
利用字典的特性实现去重
name = '王李张李陈王杨张吴周王刘赵黄吴杨'
# 使用fromkeys()方法把字符串转成字典
mylist = list({}.fromkeys(name).keys())
print(''.join(mylist))
字符串判断
判断以什么开头或以什么结尾
st = "hello python coders"
# 判断字符串是否以指定字符或子字符串开头
variable = st.startswith('h') # 输出:True
# 判断字符串是否以指定字符或子字符串结尾
variable = st.endswith('a') # 输出:False
判断字符串大小写
# 检测字符串中的字母是否全由大写字母组成
variable = st.isupper()
# 检测字符串中的字母是否全由小写字母组成
variable = st.islower()
判断字符串是否是有效标识符
# 判断str是否是有效标识符。str为符合命名规则的变量,则返回True,否则返回False
variable = st.isidentifier()
判断字符串是否只由空格组成
# 检测字符串是否只由空格组成。若字符串中只包含空格,则返回 True,否则返回 False
variable = st.isspace()
判断字符串是否只由字母组成
# 检测字符串是否只由字母组成,字符串中至少有一个字符且所有字符都是字母则返回True,否则False
variable = st.isalpha()
判断字符串是否只由字母和数字组成
# 检测是否由字母和数字组成,str中至少有一个字符且所有字符都是字母或数字则返回True,否则False
variable = st.isalnum()
判断字符串是否只包含十进制字符
# 检查字符串是否只包含十进制字符。字符串中若只包含十进制字符返回True,否则返回False
variable = st.isdecimal()
# 检测字符串是否只由数字组成.字符串中至少有一个字符且所有字符都是数字则返回True,否则返回False
variable = st.isdigit()
# 测字符串是否只由数字组成,字符串中只包含数字字符,则返回 True,否则返回 False
variable = st.isnumeric()
判断是否有打印后不可见字符
# 判断字符串中是否有打印后不可见的内容
variable = st.isprintable()
判断是否是标题格式的字符串
# 检测判断字符串中所有单词的首字母是否为大写,且其它字母是否为小写
variable = st.istitle()
判断是否为空或者都是ASCII字符组成
# 字符串为空或字符串中的所有字符都是 ASCII,则返回 True,否则返回 False
variable = st.isascii()
常见的处理字符串需求
删除字符串中的所有数字
# 将字符串中的数字移除
message = ''.join(list(filter(lambda x: x.isalpha(), 'abc123def4fg56vcg2')))
print(message)
判断两个字符串是否为异序词
异序词是通过重新排列不同单词或短语的字母而形成的单词或短语。如果两个字符串的 Counter 对象相等,那么它们就是相同字母异序词对。
from collections import Counter
s1, s2, s3 = "acbde", "abced", "abcda"
c1, c2, c3 = Counter(s1), Counter(s2), Counter(s3)
if c1 == c2:
print('1和2是异序词')
if c1 == c3:
print('1和3是异序词')
else:
print('1和3不是异序词')
按照拼音顺序对中文汉字进行排序
from xpinyin import Pinyin # 导入汉字转拼音模块
def my_sort(wordlist): # 指定要排序的列表
pin = Pinyin() # 创建汉字转拼音对象
temp = [] # 保存转换结果的空列表
for item in wordlist: # 遍历品牌名称列表
temp.append((pin.get_pinyin(item), item)) # 将汉字的拼音和汉字放到一个元组中,再添加到列表中
temp.sort() # 对列表进行排序
result = [] # 保存排序后的列表
for i in range(len(temp)): # 遍历排序后的列表
result.append(temp[i][1]) # 取出汉字保存到新列表中
return result # 返回排序后的列表
print(my_sort(['华为', '小米' , '苹果', '三星' ])) # 调用函数时指定一个品牌名称列表
常用算法对字符串进行加密
import hashlib
str = input('请输入要加密的字符串:')
#MD5加密(返回32位16进制表示字符串)
md5 = hashlib.md5()
md5.update(str.encode('utf-8'))
print('MD5加密:',md5.hexdigest())
#SHA1加密(返回40位16进制表示字符串)
sha1 = hashlib.sha1()
sha1.update(str.encode('utf-8'))
print('SHA1加密:',sha1.hexdigest())
#SHA256加密(返回64位16进制表示字符串)
sha256 = hashlib.sha256()
sha256.update(str.encode('utf-8'))
print('SHA256加密:',sha256.hexdigest())
# 采用哈希算法计算后的MD5加密
import hmac
pwd = str.encode('utf-8')
key = 'id'.encode('utf-8')
h = hmac.new(key, pwd, digestmod='MD5')code>
print('更安全的MD5加密:', h.hexdigest())
简单加密
in_str = 'hello'
out_str = '12345'
sm = st.maketrans(in_str, out_str)
print(f"制作翻译表,常与translate()函数连用。即:返回用于translate方法翻译的转换表:{st.maketrans(in_str, out_str)}")
print(f"str.translate方法翻译的转换表。:{st.translate(sm)}")
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。