【面试精讲】Java有哪些垃圾回收器?工作原理都是什么?它们有什么区别?
小 明 2024-06-29 09:05:03 阅读 99
【面试精讲】Java有哪些垃圾回收器?工作原理都是什么?它们有什么区别?
目录
本文导读
一、垃圾回收器概览
Serial GC工作原理概览
Parallel GC工作原理概览
CMS回收器工作原理概览
G1回收器工作原理概览
2、选择适合的垃圾回收器
二、串行垃圾回收器(Serial GC)
工作原理
工作流程模拟代码示例:
三、并行垃圾回收器(Parallel GC)
工作原理
工作流程模拟代码示例
四、并发标记清除垃圾回收器(CMS GC)
工作原理
工作流程模拟代码示例
五、G1回收器(G1 GC)
工作原理
工作流程模拟代码示例
总结
博主v:XiaoMing_Java
本文导读
在Java世界中,垃圾回收(Garbage Collection, GC)是自动内存管理的一部分,它帮助开发者免于直接处理内存分配和释放,从而避免了许多内存泄漏和指针错误。随着Java技术的演进,出现了多种垃圾回收器,它们各有特点,适用于不同的场景和需求。
本文将深入探讨Java中的Serial、Parallel Scavenge、CMS、G1主要垃圾回收器,它们的工作原理以及它们之间的区别。
其中 CMS 收集器是 JDK 8 之前的主流收集器, JDK 9 之后的默认收集器为 G1
一、垃圾回收器概览
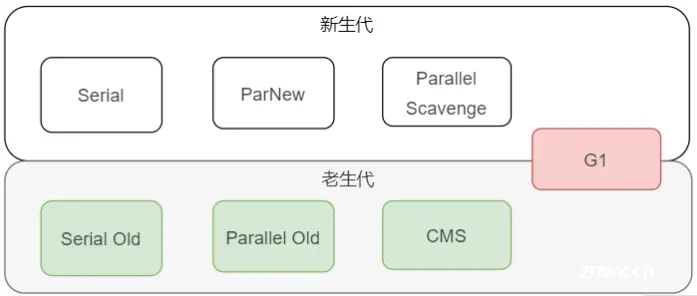
在Java虚拟机(JVM)中每种回收器都有其独特的工作原理和使用场景,主要的垃圾回收器包括:
串行垃圾回收器(Serial GC):这是最基本的GC实现,它在进行垃圾回收时会暂停所有应用线程("Stop-The-World"),因此它适用于单核服务器或者用于客户端应用中。并行垃圾回收器(Parallel GC):并行回收器在垃圾收集阶段同样会暂停所有应用线程,但它在垃圾回收时使用多个线程并行工作,因此在多核服务器上性能较好。它是JVM的默认垃圾回收器。并发标记清除(CMS)垃圾回收器:CMS回收器的目标是减少应用暂停时间。它在回收大部分垃圾时应用线程可以继续工作。它的缺点是会产生较多的内存碎片。G1垃圾回收器:G1是一个面向服务器的垃圾回收器,旨在在具有大量内存的多核机器上,实现高吞吐量和低暂停时间。它通过将堆划分为多个区域(Region)来实现。ZGC(Z Garbage Collector):这两个是最新的垃圾回收器,旨在实现几乎没有暂停时间的垃圾收集。它们适用于需要极低暂停时间及大堆内存的应用。
Serial GC工作原理概览
使用单个线程进行垃圾回收,它在进行垃圾回收时会停止所有用户线程,直到垃圾回收完成。
Parallel GC工作原理概览
并行回收器在进行垃圾收集时,多个垃圾收集线程并行工作,以提高垃圾收集的效率。它主要用于在垃圾收集时减少系统暂停的时间。
CMS回收器工作原理概览
CMS回收器分为几个阶段,其中大部分阶段都可以与应用线程同时运行,只有在初始标记和重新标记阶段才需要暂停所有应用线程。
G1回收器工作原理概览
G1回收器通过将堆内存划分为多个区域,并在这些区域中进行增量式的垃圾回收来实现高效的垃圾回收。它旨在提供一种更灵活的垃圾回收方式,以达到低暂停时间和高吞吐量的平衡。
2、选择适合的垃圾回收器
选择哪种垃圾回收器取决于应用的需求:
对于需要低延迟的应用,可以考虑使用CMS、G1或ZGC和Shenandoah。
如果应用运行在单核或者内存较小的环境中,串行回收器Serial GC可能是最佳选择。
对于追求吞吐量的应用,可以考虑使用并行回收器Parallel GC或G1回收器。
二、串行垃圾回收器(Serial GC)
串行垃圾回收器(Serial GC)是Java中最古老且简单的垃圾回收器之一,它针对单线程环境设计,适用于小型数据处理和具有较小内存的JVM实例。由于它是单线程工作的,因此串行GC在执行垃圾收集时会暂停所有应用线程,这种暂停被称为“Stop-The-World”(STW)事件。
工作原理
串行垃圾回收器在年轻代采用标记-复制(Mark-Copy)算法,在老年代采用标记-整理(Mark-Sweep-Compact)算法。这两种算法的基本概念如下:
标记-复制:首先标记出所有可达的对象,然后将所有存活的对象复制到另一个区域,最后清空原始区域中的所有对象。标记-整理:先标记所有存活的对象,然后移动对象压缩堆空间,最后清除掉剩余的垃圾对象。
工作流程模拟代码示例:
public class SerialGCSimulator {
// 模拟堆内存结构
private static class Heap {
Object[] youngGen; // 年轻代
Object[] oldGen; // 老年代
public Heap(int youngSize, int oldSize) {
youngGen = new Object[youngSize];
oldGen = new Object[oldSize];
}
// ... 其他堆操作方法 ...
}
// 标记过程
private void mark(Object obj, boolean[] reachable) {
// 假设通过某种方式可以获取对象引用,并标记为可达
// 在实际的JVM中,这一过程会从根集合开始,遍历所有可达对象
if (obj != null) {
int index = findIndexOf(obj);
reachable[index] = true;
}
}
// 复制过程
private void copy(boolean[] reachable, Object[] fromSpace, Object[] toSpace) {
int toIndex = 0;
for (int i = 0; i < fromSpace.length; i++) {
if (reachable[i]) {
toSpace[toIndex++] = fromSpace[i]; // 复制可达对象
fromSpace[i] = null; // 清除原位置上的对象引用
}
}
}
// 整理过程
private void compact(Object[] generation) {
int toIndex = 0;
for (Object obj : generation) {
if (obj != null) {
generation[toIndex++] = obj; // 移动对象,压缩空间
}
}
// 清除剩余的垃圾对象
for (int i = toIndex; i < generation.length; i++) {
generation[i] = null;
}
}
// 运行垃圾回收模拟
public void runGC(Heap heap) {
// 假设知道每个对象是否可达
boolean[] youngReachable = new boolean[heap.youngGen.length];
boolean[] oldReachable = new boolean[heap.oldGen.length];
// 模拟标记过程
for (Object obj : heap.youngGen) {
mark(obj, youngReachable);
}
for (Object obj : heap.oldGen) {
mark(obj, oldReachable);
}
// 模拟复制过程(年轻代)
Object[] newYoungGen = new Object[heap.youngGen.length];
copy(youngReachable, heap.youngGen, newYoungGen);
heap.youngGen = newYoungGen;
// 模拟整理过程(老年代)
compact(heap.oldGen);
// 垃圾回收完成
}
private int findIndexOf(Object obj) {
// 实现省略...
return 0;
}
// 主函数,运行垃圾回收模拟
public static void main(String[] args) {
Heap heap = new Heap(256, 1024); // 创建一个假设的堆
SerialGCSimulator gcSimulator = new SerialGCSimulator();
gcSimulator.runGC(heap); // 执行一次垃圾回收
}
}
三、并行垃圾回收器(Parallel GC)
并行垃圾回收器也称为吞吐量优先回收器,它使用多个线程来缩短垃圾回收的停顿时间。这种回收器特别适合多CPU环境,因为它能够并行利用多个CPU核心完成垃圾回收工作,以提高应用程序的吞吐量。
工作原理
并行GC在不同代区采用的算法如下:
年轻代:所有存活对象都会被复制到一个空闲区域,而后清理整个年轻代空间。老年代:采用标记-压缩算法,首先标记所有存活的对象,然后将所有存活的对象向一端移动,并清理掉剩余的空间。
工作流程模拟代码示例
public class ParallelGCSimulator {
// 模拟堆内存结构
private static class Heap {
Object[] youngGen; // 年轻代
Object[] oldGen; // 老年代
public Heap(int youngSize, int oldSize) {
youngGen = new Object[youngSize];
oldGen = new Object[oldSize];
}
// 标记过程
private void mark(Object obj, boolean[] reachable) {
// 省略具体实现,仅模拟标记对象
if (obj != null) {
int index = findIndexOf(obj);
reachable[index] = true;
}
}
// 复制过程
private void copy(boolean[] reachable, Object[] fromSpace, Object[] toSpace) {
int toIndex = 0;
for (int i = 0; i < fromSpace.length; i++) {
if (reachable[i]) {
toSpace[toIndex++] = fromSpace[i]; // 复制可达对象
fromSpace[i] = null; // 清除原位置上的对象引用
}
}
}
// 压缩过程(老年代)
private void compact(Object[] generation) {
// 省略具体实现,仅模拟压缩过程
}
// 运行并行垃圾回收模拟
public void runGC() {
// 年轻代使用标记-复制算法
// 假设知道每个对象是否可达
boolean[] youngReachable = new boolean[youngGen.length];
for (Object obj : youngGen) {
mark(obj, youngReachable);
}
Object[] newYoungGen = new Object[youngGen.length];
copy(youngReachable, youngGen, newYoungGen);
youngGen = newYoungGen;
// 老年代使用标记-压缩算法
boolean[] oldReachable = new boolean[oldGen.length];
for (Object obj : oldGen) {
mark(obj, oldReachable);
}
compact(oldGen);
}
private int findIndexOf(Object obj) {
// 省略具体实现...
return 0;
}
}
public static void main(String[] args) {
Heap heap = new Heap(256, 1024); // 创建一个假设的堆
heap.runGC(); // 执行一次垃圾回收,模拟并行GC工作
}
}
四、并发标记清除垃圾回收器(CMS GC)
CMS垃圾回收器主要目标是获取最短回收停顿时间,通常用于互联网公司或者用户界面较为丰富的应用程序中。CMS回收器试图尽可能减少应用程序的停顿时间,特别是对老年代的垃圾回收进行了优化。
工作原理
CMS GC的工作过程分为以下四个主要阶段:
初始标记(Initial Mark):标记GC Roots能直接关联到的对象。这个阶段需要暂停所有线程(STW),但是非常快速。并发标记(Concurrent Mark):从GC Roots开始遍历整个对象图,找出所有存活的对象。这个阶段可以并发执行,不需要暂停应用线程。重新标记(Remark):修正并发标记期间由于程序运行导致的变动。这步是STW的,但通常通过算法优化(如Card Marking)来缩短时间。并发清除(Concurrent Sweep):清除不再使用的对象。这个阶段可以与应用线程并发执行。
工作流程模拟代码示例

public class CMSimulator {
// 堆内存的简单表示
private Object[] oldGen; // 老年代
// 构造方法
public CMSimulator(int size) {
oldGen = new Object[size];
}
// 初始标记
private void initialMark() {
// STW事件,快速扫描GC Roots直接引用的对象
// 省略实现...
}
// 并发标记
private void concurrentMark() {
// 应用线程可以并发运行
// 遍历对象图,标记所有可达对象
// 省略实现...
}
// 重新标记
private void remark() {
// STW事件,通常使用三色标记和写屏障技术来优化
// 省略实现...
}
// 并发清除
private void concurrentSweep() {
// 应用线程可以并发运行
// 清理未标记(即不可达)的对象
// 省略实现...
}
// 执行CMS垃圾回收
public void runCMS() {
initialMark();
concurrentMark();
remark();
concurrentSweep();
}
public static void main(String[] args) {
CMSimulator cmSimulator = new CMSimulator(1024); // 创建CMS模拟器
cmSimulator.runCMS(); // 开始执行CMS垃圾回收
}
}
五、G1回收器(G1 GC)
G1垃圾回收器是一种服务器端的垃圾回收器,旨在兼顾高吞吐量与低延迟。它通过划分内存为多个相同大小的区域(Region),尝试以增量方式来处理这些区域,从而最大限度减少单次垃圾收集的停顿时间。
工作原理
G1回收器主要分为以下阶段:
初始标记(Initial Mark):此阶段标记所有从GC Roots直接可达的对象。这个阶段是STW的。并发标记(Concurrent Mark):此阶段G1会遍历堆中的对象图,找出活着的对象。这个阶段应用线程可以并发运行。最终标记(Final Mark):此阶段处理在并发标记期间变化的对象引用。这个阶段也是STW的,但通常比初始标记快很多。筛选回收(Evacuation):此阶段G1会复制存活对象到新的区域,同时回收那些只包含垃圾对象的区域。这个阶段同样STW,但是G1会努力控制这个阶段的时间,来达成用户设定的暂停时间目标。
工作流程模拟代码示例
public class G1GCSimulator {
// 模拟Heap的Region划分
private static class Heap {
List<Object[]> regions;
public Heap(int regionCount, int regionSize) {
regions = new ArrayList<>(regionCount);
for (int i = 0; i < regionCount; i++) {
regions.add(new Object[regionSize]);
}
}
// ... 其他Heap操作方法 ...
}
// 标记过程和G1中复杂的回收逻辑在模拟代码中无法完全体现
// 下面是简化的演示过程
// 初始标记
private void initialMark(Heap heap) {
// STW事件,标记直接可达对象
// ... 标记逻辑 ...
}
// 并发标记
private void concurrentMark(Heap heap) {
// 应用线程并发执行,G1遍历对象图
// ... 标记逻辑 ...
}
// 最终标记
private void finalMark(Heap heap) {
// STW事件,处理变化的对象引用
// ... 标记逻辑 ...
}
// 筛选回收
private void evacuation(Heap heap) {
// STW事件,选择部分Region进行回收
for (Object[] region : heap.regions) {
// 假设有一个方法来决定是否需要回收这个Region
if (shouldCollect(region)) {
// 回收并移动对象到其他Region
for (int i = 0; i < region.length; i++) {
if (isMarked(region[i])) {
moveToNewRegion(region[i]);
}
region[i] = null; // 回收对象
}
}
}
}
// 运行G1垃圾回收模拟
public void runGC(Heap heap) {
initialMark(heap); // 初始标记
concurrentMark(heap); // 并发标记
总结
Java的垃圾回收器提供了多种选择,以满足不同应用的性能和延迟需求。理解每种垃圾回收器的工作原理和特点,可以帮助开发者为他们的应用选择最合适的垃圾回收策略,优化应用性能,提升用户体验。
如果本文对你有帮助 欢迎 关注 、点赞 、收藏 、评论, 博主才有动力持续创作!!!
博主v:XiaoMing_Java
📫作者简介:嗨,大家好,我是 小明 ,互联网大厂后端研发专家,2022博客之星TOP3 / 博客专家 / CSDN后端内容合伙人、InfoQ(极客时间)签约作者、阿里云签约博主、全网 6 万粉丝博主。
🍅 文末获取联系 🍅 👇🏻 精彩专栏推荐订阅收藏 👇🏻
专栏系列(点击解锁)
学习路线(点击解锁)
知识定位
🔥Redis从入门到精通与实战🔥
Redis从入门到精通与实战
围绕原理源码讲解Redis面试知识点与实战
🔥MySQL从入门到精通🔥
MySQL从入门到精通
全面讲解MySQL知识与企业级MySQL实战 🔥计算机底层原理🔥
深入理解计算机系统CSAPP
以深入理解计算机系统为基石,构件计算机体系和计算机思维
Linux内核源码解析
围绕Linux内核讲解计算机底层原理与并发
🔥数据结构与企业题库精讲🔥
数据结构与企业题库精讲
结合工作经验深入浅出,适合各层次,笔试面试算法题精讲
🔥互联网架构分析与实战🔥
企业系统架构分析实践与落地
行业最前沿视角,专注于技术架构升级路线、架构实践
互联网企业防资损实践
互联网金融公司的防资损方法论、代码与实践
🔥Java全栈白宝书🔥
精通Java8与函数式编程
本专栏以实战为基础,逐步深入Java8以及未来的编程模式
深入理解JVM
详细介绍内存区域、字节码、方法底层,类加载和GC等知识
深入理解高并发编程
深入Liunx内核、汇编、C++全方位理解并发编程
Spring源码分析
Spring核心七IOC/AOP等源码分析
MyBatis源码分析
MyBatis核心源码分析
Java核心技术
只讲Java核心技术
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。