【计网】从零开始学习http协议 --- 通过http实现客户端交互
CSDN 2024-10-13 08:05:01 阅读 95

我希望自己也是一颗星星:
如果我会发光,就不必害怕黑暗。
如果我自己是那么美好,
那么一切恐惧就可以烟消云散。
--- 王小波 《黑铁时代》---
从零开始学习http协议
1 完善http请求2 设计http应答3 完成http服务5 Http版本与状态码
1 完善http请求
上一篇文章中我们对浏览器发送的请求进行了一个初步的处理,获取到了一些基础信息。
其中我们得到的<code>URL是十分重要的,这是客户端请求的文件的路径,当然是在网络根目录的之下的路径。网络根目录需要由我们自己来进行设置,可以设置任何位置!这里我将其与源代码放在了同一路径下:
<code>wwwroot就是网络根目录,URL的路径是基于网络根目录的,我们在http请求中加入一个成员变量
std::string _path
初始化时就将其先设置为wwwroot的路径,为了代码的优雅我们可以设置通过静态常量prefixpath来储存这个路径。之后获取到url之后,就可以在_path后面加入url的内容!
这样我们会得到这样的效果:

这样就能保证服务器可以正确的寻找到客户所需要的资源文件!
2 设计http应答
我们现在可以通过<code>HttpRequest获取浏览器请求的信息,可以获取到最关键的信息是:客户端所需的资源路径:URL!接下来我们就要通过网络根目录中的资源返回给客户端。
http的应答与响应的结构很相似,是以下面的字符串构成:
状态行:储存应答基础信息,错误码,错误信息,HTTP版本应答报头:储存必要的一些信息,正文的长度,服务器类型、设置Cookie…空行:将正文分割出来正文:这是客户端最终获取到的数据!
我们设计应答可以先将四大部分分割为小部分:
错误码 int _code错误信息 std::string _descHTTP版本响应报头
后面我们可以通过这些小部分组装为状态行和应答报头,这样我们可以搭建起基础的框架:
class HttpResponse
{
private:
public:
HttpResponse() : _blank_line(base_sep), _version(httpversion)
{
}
std::string Serialize()
{
}
~HttpResponse()
{
}
private:
// 基础变量
std::string _version; // HTTP版本
int _code; // 错误码
std::string _desc; // 错误信息
std::unordered_map<std::string, std::string> _kv_headers; // 响应报头
// 四大部分
std::string _status_line; // 请求行
std::vector<std::string> _resp_headers; // 响应报头
std::string _blank_line; // 分割行
std::string _resp_body_text; // 正文
};
首先我们先编写设置基础信息的接口,可以让我们通过外部将错误码,错误信息,报头,正文进行添加!其中这些具体的信息如何进行设计,我们待会在通过httpserver类内进行设计,现在我们在知道可以通过这些接口设置好我们的成员变量就可以!
void AddCode(int code, const std::string &desc)
{
_code = code;
_desc = desc;
}
void AddHeader(const std::string &k, const std::string &v)
{
_kv_headers[k] = v;
}
void AddBody(const std::string &bodytext)
{
_resp_body_text = bodytext;
}
成员变量设置好了,那么就可以来进行序列化了,将我们的信息进行整合,变成一个完整的字符串!!!注意每个部分之间都是有base_sep间隔符分开的!
std::string Serialize()
{
// 构建状态行
_status_line = _version + space_sep + std::to_string(_code) + space_sep + _desc + base_sep;
// 构建响应报头
for (auto &kv : _kv_headers)
{
_resp_headers.push_back(kv.first + line_sep + kv.second + base_sep);
}
// 进行序列化
std::string res = _status_line;
for (auto &line : _resp_headers)
{
res += line;
}
res += _blank_line;
res += _resp_body_text;
return res;
}
这样我们的http应答就完成了,可以通过序列化得到字符串,后续可以发送给客户端了!
3 完成http服务
http请求和应答我们都已经写好了,接下来就应该通过HttpServer来进行处理:
根据字符串反序列化获取http请求根据http请求中的path路径将正文的数据读取到字符串中。这里使用文件流的方法快速的对文件进行读取根据实际情况设置http应答,然后进行序列化返回
std::string GetFileContent(const std::string &path)
{
std::ifstream in(path, std::ios::binary);
if (!in.is_open())
return std::string();
// 获取文件大小!
in.seekg(0, in.end);
int filesize = in.tellg();
in.seekg(0, in.beg);
// 开始读取!
std::string content;
content.resize(filesize);
in.read((char *)content.c_str(), filesize);
in.close();
return content;
}
std::string HandlerHelperRequest(std::string &Requeststr)
{
//获取http请求
HttpRequest hreq;
hreq.Deserialize(Requeststr);
// hreq.Print();
// hreq.Url();
std::string path = hreq.Path();//得到http请求资源路径!
// 读取正文
std::string content = GetFileContent(path);
LOG(DEBUG, "content.size: %d \n", content.size());
if (content.empty())
return std::string();
// 进行序列化
HttpResponse resp;
resp.AddCode(200, "OK");
resp.AddHeader("Content-Length", std::to_string(content.size()));
resp.AddBody(content);
std::string resstr = resp.Serialize();
return resstr;
这样我们就可以成功地将http应答返回给客户端了,这里我通过AI设计了一个前端页面,我们可以来看一下效果:
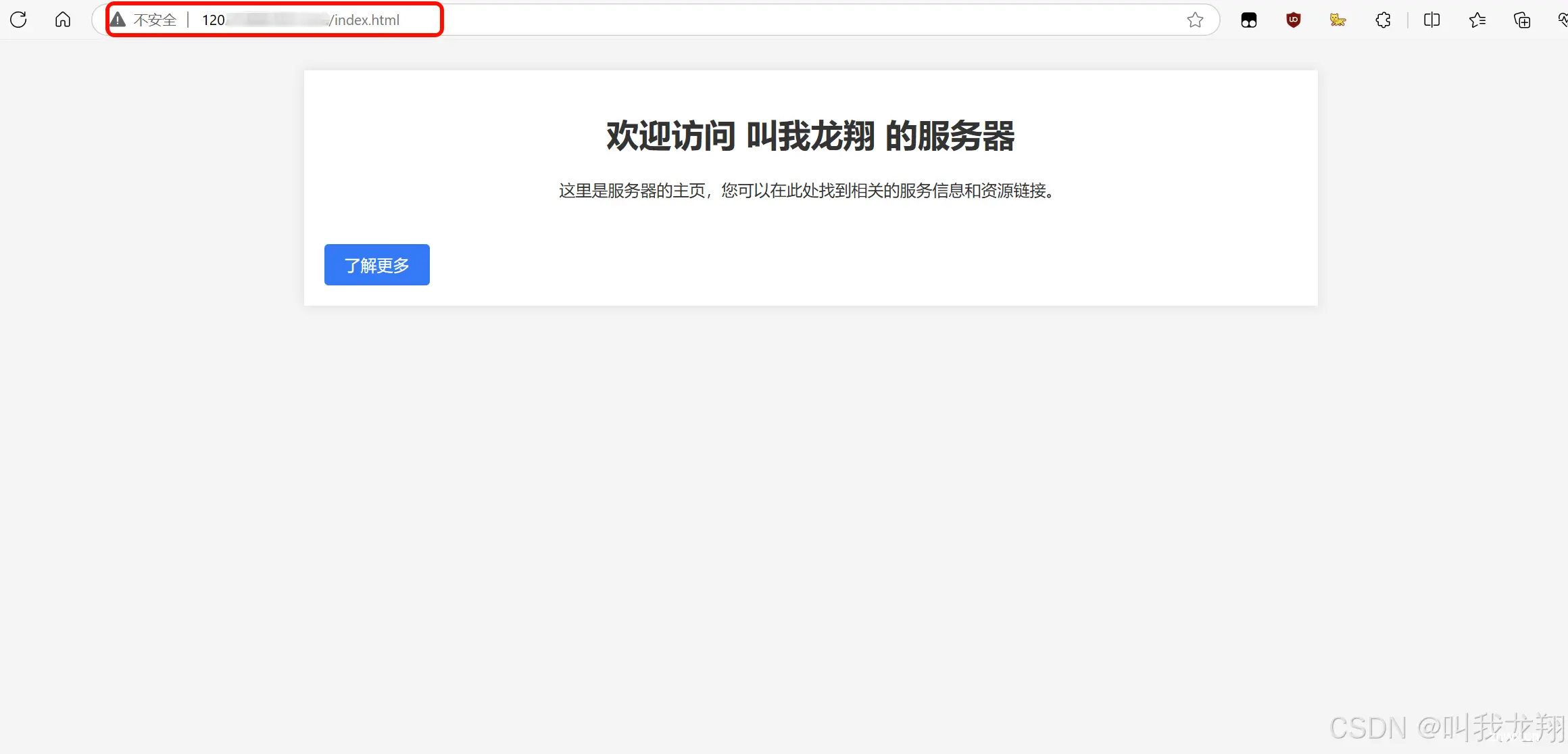
很好,我们的浏览器成功的获取到了我们返回了资源!需要注意的一点是这里浏览器可以成功的识别我们的正文纯属运气好,因为资源是由很多种类的,我们没有明确我们的资源的类型,但是浏览器自动识别出来类型,后续我们会学习具体的报文属性!
获得一个完整的网页,浏览器先要得到html,根据html的标签,检测出我们是否还要获取其他资源,浏览器会继续发起请求!!!
我们可以多设置几个网页,在网页内我们可以通过链接来进行我们网页的跳转!
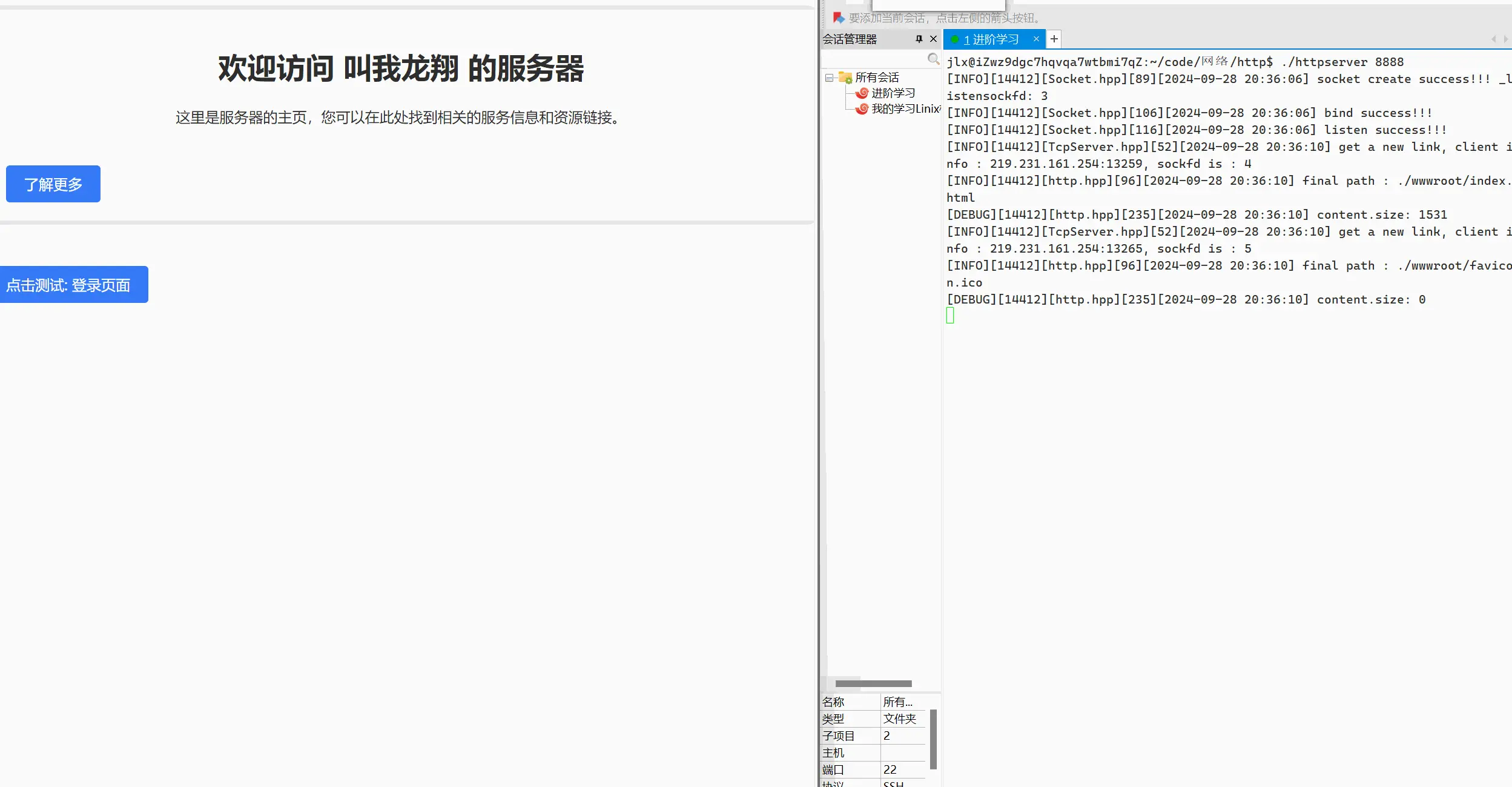
可以看到,每次进入新的网页都会产生新的请求!这样一个完整的网页服务就构建出来了!
现在我们来将http报头中加上资源属性<code>Content-Type。那么应该怎么进行填写呢?每一个文件都是通过其后缀来进行识别而,在网络上怎样告诉呢?
首先我们先要明确我们的文件类型然后根据文件类型转换成Http中的Content-Type!
所以这就需要Content-Type对照表,下面举几个例子:
| 文件扩展名 | Content-Type | 描述 |
|---|---|---|
.html | text/html | HTML文档 |
.css | text/css | CSS样式表 |
.js | application/javascript | JavaScript脚本 |
.json | application/json | JSON数据 |
.txt | text/plain | 纯文本文件 |
.xml | text/xml 或 application/xml | XML文件 |
.pdf | application/pdf | PDF文档 |
.zip | application/zip | ZIP压缩文件 |
.gif | image/gif | GIF图像 |
.jpg | image/jpeg | JPEG图像 |
.png | image/png | PNG图像 |
.svg | image/svg+xml | SVG图像 |
.mp3 | audio/mpeg | MP3音频文件 |
.mp4 | video/mp4 | MP4视频文件 |
| … | … | … |
所以我可以在httpserver中维护一个哈希表-mini_type,来手动加几个Content-Type对照。每次请求都从path中解析出来一个资源后缀_suffix。通过在path中总后往前寻找.就不可以快速的找到文件后缀!找到说明有后缀,进行处理,否则就是默认后缀!之后再通过哈希映射添加到相应报头中!
这样我们就可得到对应的报头结构了:
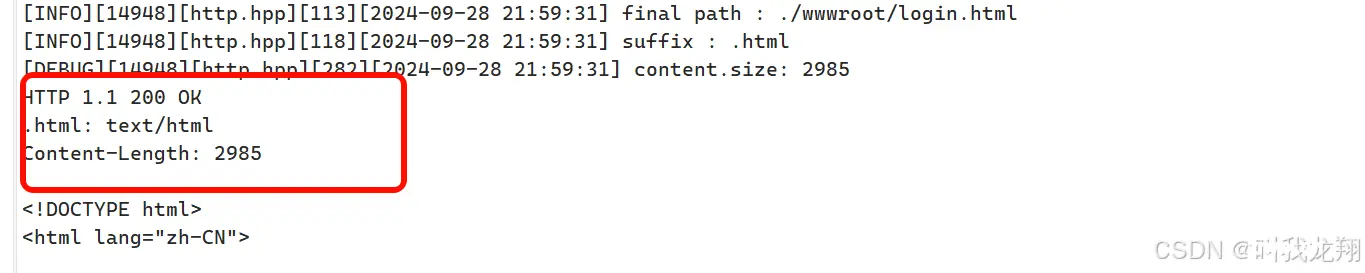
还有一些其他常用的header:
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;User-Agent: 声明用户的操作系统和浏览器版本信息;referer: 当前页面是从哪个页面跳转过来的;Location: 搭配 3xx 状态码使用, 告诉客户端接下来要去哪里访问;\Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;后续会详细讲解!
这些我们可以在请求的序列化字符串中查看:
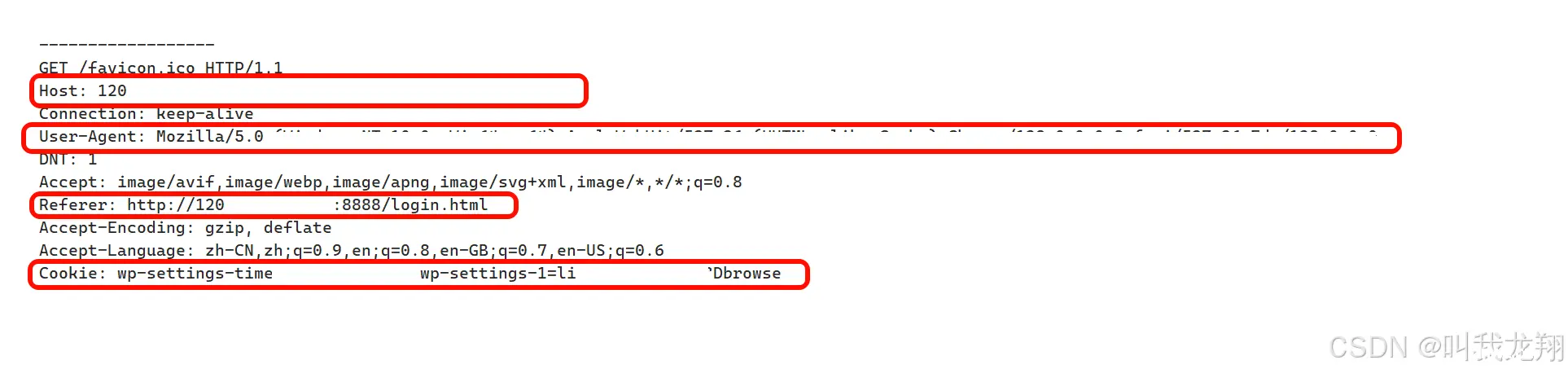
在实际的服务中,如果像我们这样每次都要进行打开新的连接,才能到下一个界面,那么这样反复的打开网页,再加上现在的网页有高精度图片,视频,音频等一系列大资源,这样是十分耗费传输性能的!所以就有了长连接,一次获取网页会直接进行该网页内的数据全部获取才会关闭连接,这样一个连接就将所有的资源请求到了,对传输性能的使用更加高效!线程池的使用就是使用长连接,一直使用一个连接,这就是长连接!
5 Http版本与状态码
http版本在我们编写响应报头时,我们不需要考虑。那这个http版本到底有什么作用呢?我们来举一个例子:
现在的微信可谓是功能齐全,但是在早期时肯定是没有这些功能的。
加入现在要退出微信新的功能 — 朋友圈实况图片,那么新版本功能上线需要后端做相应的改变优化:既要满足新版本的数据处理,也要支持旧版本的数据处理。因为不是所有人都会更新微信客户端,那么为了识别是新客户端还是客户端发送的请求,就需要版本报头!
网络服务的http版本也是同样的道理!浏览器和服务端需要互相告诉各自的版本号,进而做到对应的处理!这就是http版本的作用!
http的状态码是服务器做出应答时根据数据处理的情况返回给浏览器,有以下几种状态码:
| 状态码范围 | 类别 | 状态码意义 |
|---|---|---|
| 1xx | 信息性状态码 | 表示请求已被服务器接收,继续处理 |
| 2xx | 成功状态码 | 表示请求已成功被服务器接收、理解并接受 |
| 3xx | 重定向状态码 | 表示需要客户端采取进一步操作才能完成请求 |
| 4xx | 客户端错误状态码 | 表示请求包含语法错误或无法完成请求 |
| 5xx | 服务器错误状态码 | 表示服务器在处理请求时发生了错误 |
我们比较熟悉的是:<code>404 503 ...,这些具体的状态码也有不同含义:
| 状态码 | 状态码意义 | 应用样例 |
|---|---|---|
| 100 | Continue | 上传大文件时, 服务器告诉客户端可以继续上传 |
| 200 | OK | 访问网站首页, 服务器返回网页内容,请求成功 |
| 201 | Created | 已创建资源 |
| 204 | No Content | 无内容 |
| 301 | Moved Permanently | 永久重定向 |
| 302 | Found | 临时重定向 |
| 304 | Not Modified | 未修改(使用缓存) |
| 400 | Bad Request | 错误请求 |
| 401 | Unauthorized | 未授权 |
| 403 | Forbidden | 权限不够,禁止访问 |
| 404 | Not Found | 访问不存在的网页,未找到资源 |
| 405 | Method Not Allowed | 请求方法不被允许 |
| 500 | Internal Server Error | 服务器内部错误 |
| 502 | Bad Gateway | 使用代理服务器时, 代理服务器无法从上游服务器获取有效响应 |
| 503 | Service Unavailable | 服务不可用 |
3xx系列的比较场景,平时我们微信支付成功自动的跳转都是重定向的效果!
好了!这样我们就完成了通过http实现客户端交互的工作,下一篇文章我们继续深入探索http协议的细节!!!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。