【C++】string类模拟实现
zxctscl 2024-06-22 09:05:09 阅读 79
个人主页 : zxctscl
如有转载请先通知
文章目录
1. 前言2. 构造函数和析构函数3. 遍历3.1 下标+[]3.2 迭代器 4. Modifiers4.1 `push_back`和`append`4.2 +=4.3 insert4.4 erase4.5 swap 5.Capacity5.1 resize5.2 clear 6. 深浅拷贝6.1 浅拷贝(值拷贝)6.2 深拷贝 7. String operations7.1 find7.2 substr 8. relational operators (string)8.1 运算符重载8.2 赋值 9. Non-member function overloads9.1 流插入和流提取9.2 getline 10. 附string类实现代码
1. 前言
在之前的两篇博客中已经分享关于string类的使用,有需要可以点击链接看看【C++】string类初步介绍和链接: 【C++】string进一步介绍,这次要分享用C++代码来实现string类。
2. 构造函数和析构函数
要写string就得先定义string类,它里面的成员变量有:
private:char* _str;size_t _size;size_t _capacity;
在写构造函数的时候,先写一个无参的构造函数:
string():_str(nullptr),_size(0),_capacity(0){ }
空串的时候开了一个空间给"\0",就不能给_str初始化为空,就得得new一个chark
string():_str(new char[1]),_size(0),_capacity(0){ _str[0] = '\0';}

再写一个带参的构造函数:
string(const char* str):_str(str){ }
像这样就是错的,这里不能修改,不能把常量字符串给str,不能扩容。
这里的构造函数就得自己开空间,把数据拷贝过去:开空间的时候得多开一个,因为capacity不包括"\0":
string(const char* str):_str(new char[strlen(str)+1]),_size(strlen(str)),_capacity(strlen(str)){ strcpy(_str, str);}
但是这里的strlen调用了3次,strlen不能多调。
所以这里修改为:
string(const char* str):_size(strlen(str)){ _capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);}
得注意,初始化列表的顺序要和定义的顺序一样。

将无参和带参的合二为一,实现一个缺省的构造:
string(const char* str=nullptr):_size(strlen(str)){ _capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);}
当传一个无参的时候,就会报错:
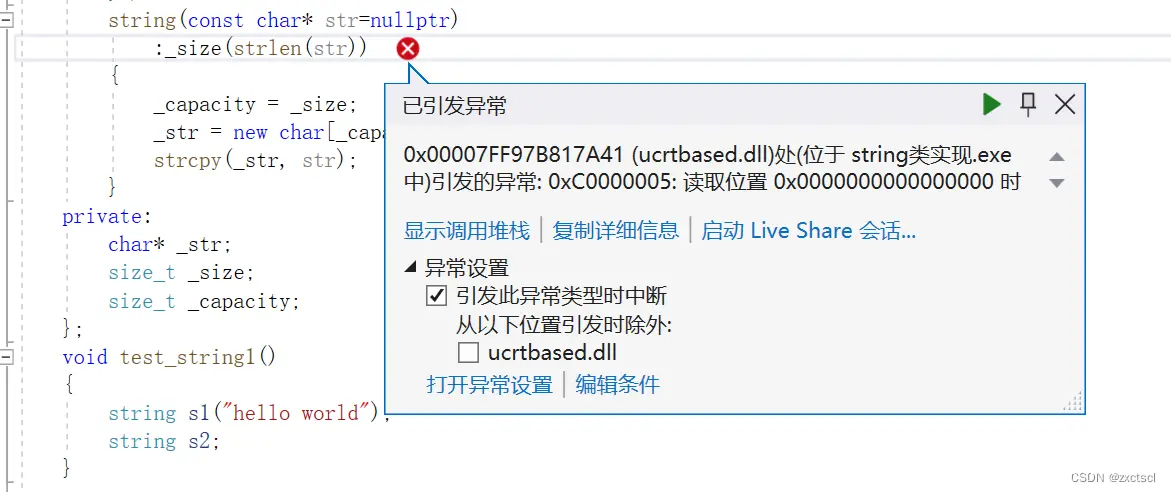
但注意这样写有个问题:str不能为空,str对指针指向的位置进行解引用,遇到"\0"才结束。但这里出现了空指针,不能这么写。
修改一下:
string(const char* str='\0'):_size(strlen(str)){ _capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);}
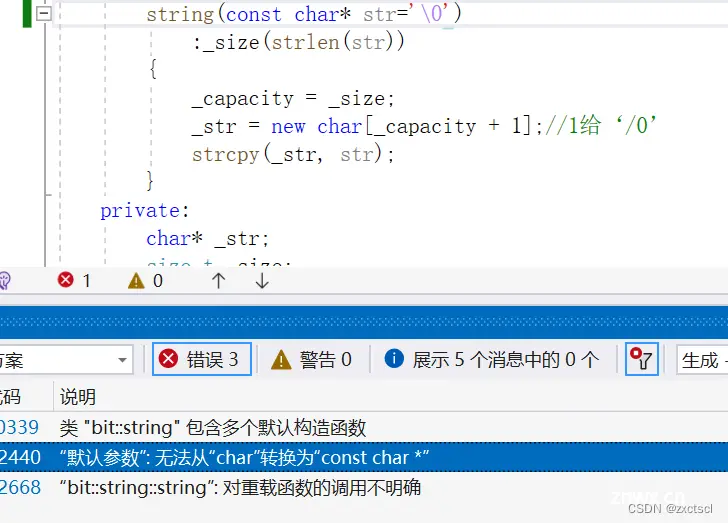
这里char类型不能给char*,没办法转。
所以这里得修改为:
string(const char* str="\0"):_size(strlen(str)){ _capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);}
这样就没有问题:
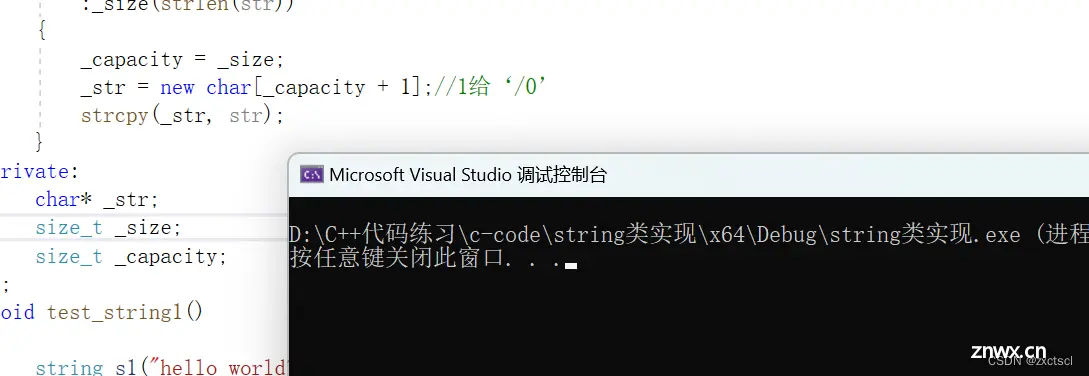

但是这样写就会多一个"\0",因为字符串默认会有一个"\0"结束,所以这里最终修改为这样:
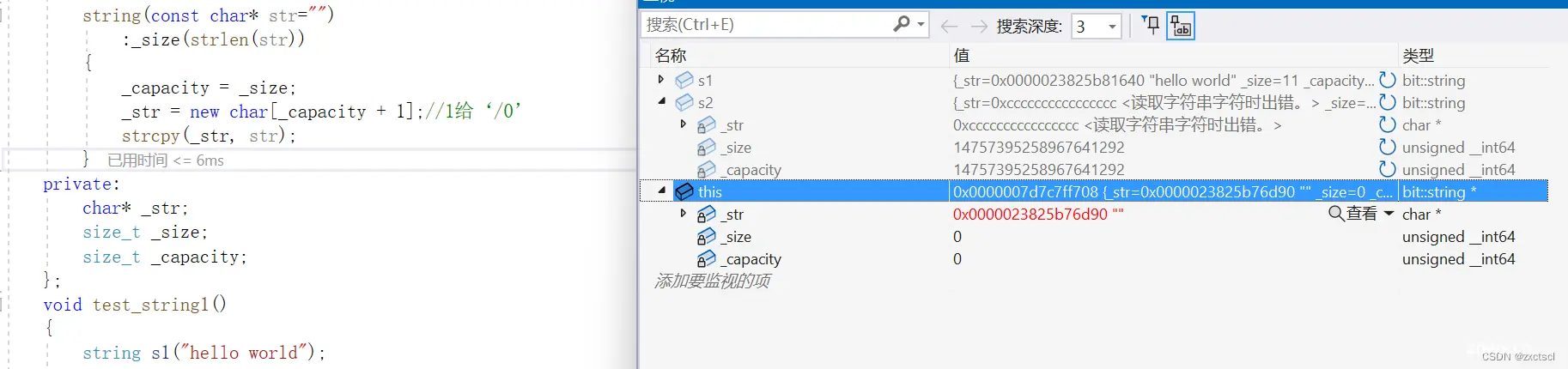
string(const char* str=""):_size(strlen(str)){ _capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);}
效果和上面加"\0"是一样的:

析构函数:
~string(){ delete[]_str;_str = nullptr;_size = _capacity = 0;}
3. 遍历
3.1 下标+[]
先遍历一下:
void test_string1(){ string s1("hello world");string s2;for (size_t i = 0; i < s1.size(); i++){ cout << s1[i] << " ";}cout << endl;}
这里用到了size,就得先写一个size()来返回字符串的长度:
size_t size() const{ return _size;}
用到了[],就得重载一个[],返回pos位置,指向的空间在堆上,出来作用域还在,就传引用:
char& operator[](size_t pos){ return _str[pos];}
这里还可以检查一下是否越界:
char& operator[](size_t pos){ assert(pos < _size);return _str[pos];}

如果存在const对象:
const string s3("xxxx");for (size_t i = 0; i < s3.size(); i++){ cout << s3[i] << " ";}cout << endl;
在调[]时候,const对象就不能调用非const:
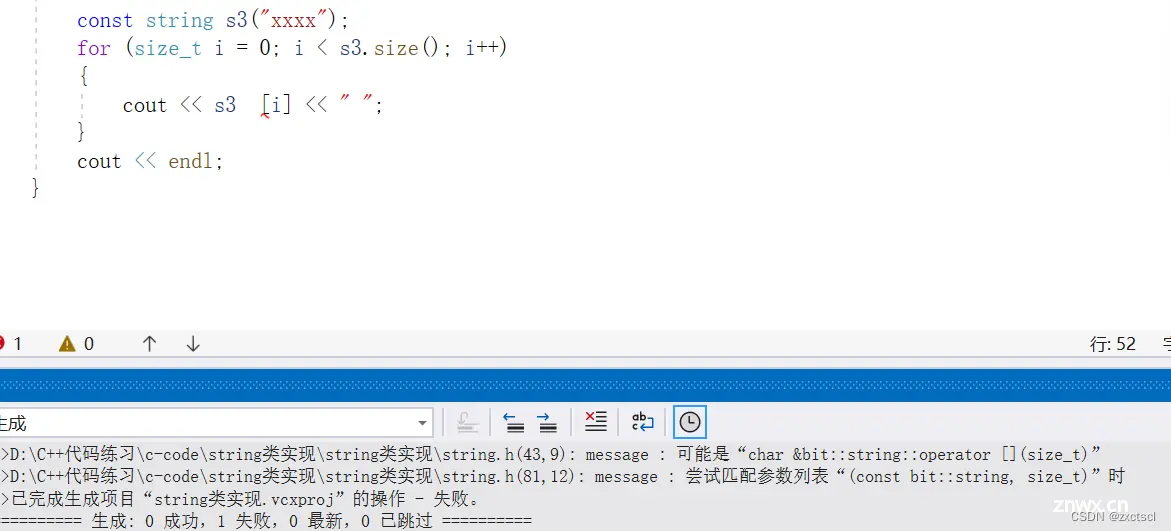
在库里面,发现[]有两种,一种是const,另一种是非const:

所以就在写一个const对象的[]运算符重载:
const char& operator[](size_t pos)const{ assert(pos < _size);return _str[pos];}
这样就没有问题了:
3.2 迭代器
void test_string2(){ string s3("hello world");string::iterator it3 = s3.begin();while (it3 != s3.end()){ cout << *it3 << " ";++it3;}cout << endl;for (auto ch : s3){ cout << ch << " ";}cout << endl;}
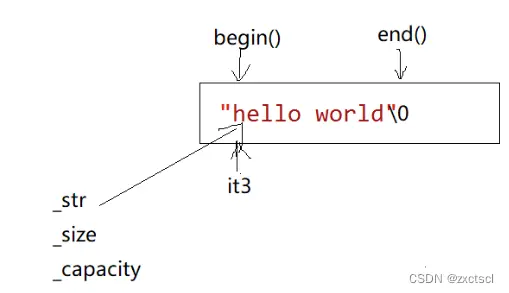
要遍历这个字符串,就要实现一个迭代器,迭代器底层就像指针:
typedef char* iterator;iterator begin(){ return _str;}iterator end(){ return _str+_size;}
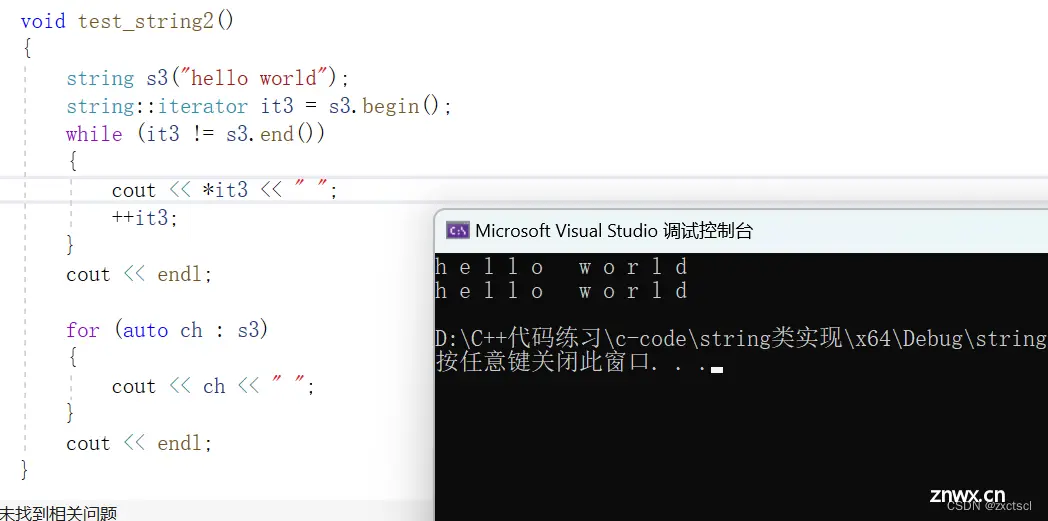
这里就像指针一样实现:
begin()返回的位置就是str的位置,end()位置就是str+size。
这里会发现范围for直接就能实现:它会自动取s3里面的数据赋值给ch,自动迭代,自动加加。它里面其实调用的就是begin和end:
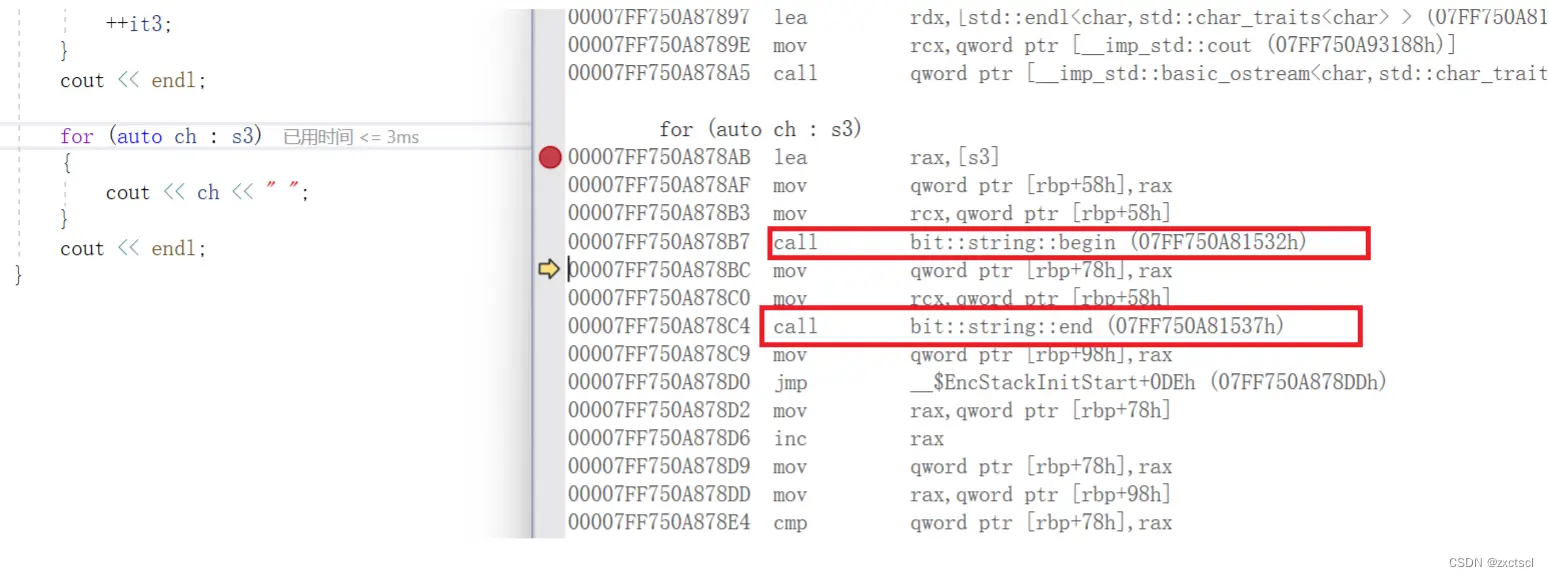
但是如果将iterator里面的的begin换成Begin,范围for就不能用了:
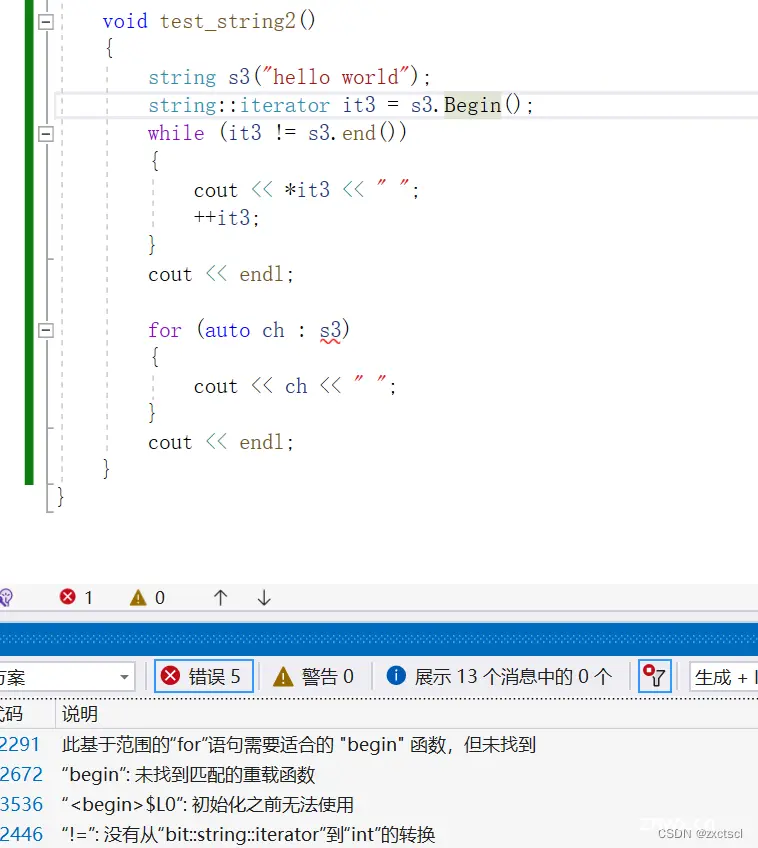
范围for只会按照规则去替换,只要iterator改变一下就不能用了。

当是const对象的时候,范围for就不能用:
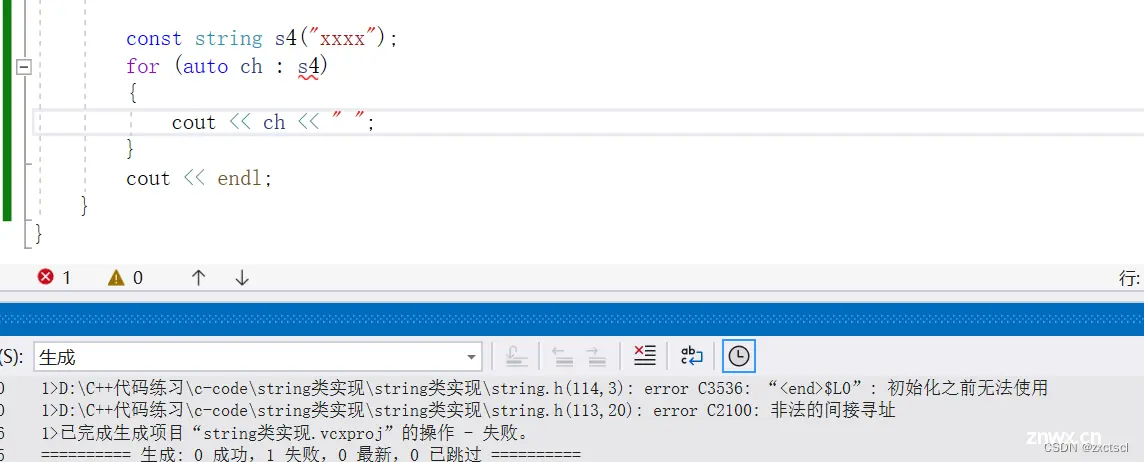
这里就得先写一个const的iterator:
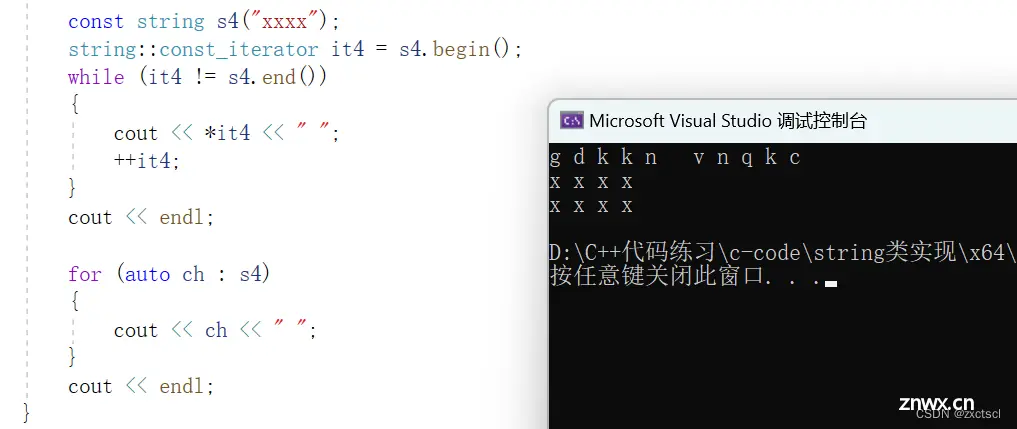
typedef const char* const_iterator;const_iterator begin()const{ return _str;}const_iterator end()const{ return _str + _size;}void test_string2(){ const string s4("xxxx");string::const_iterator it4 = s4.begin();while (it4 != s4.end()){ cout << *it4 << " ";++it4;}cout << endl;for (auto ch : s4){ cout << ch << " ";}cout << endl;}
这是就可以:
4. Modifiers
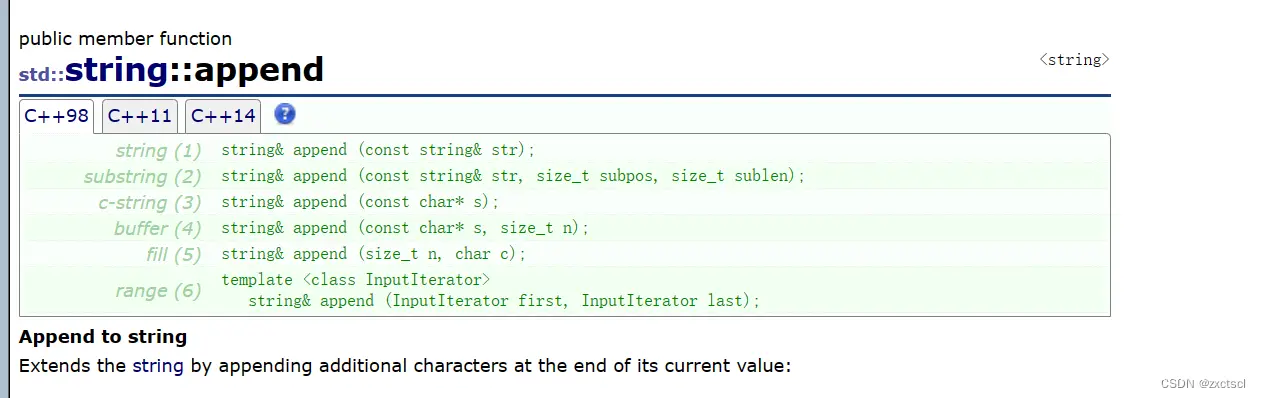
4.1 push_back和append
实现push_back,和append
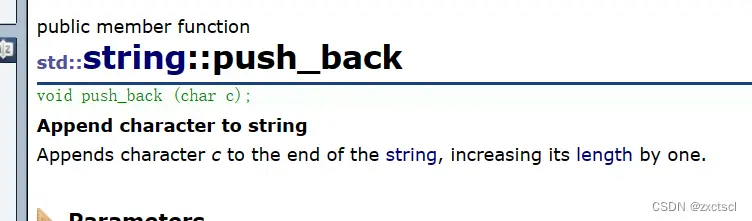
那么就得考虑扩容的问题,就得通过字符串的长度来看
先写一个reserve用来扩容:
先开一个新空间,然后拷贝数据,释放旧空间,然后让指针指向这个新空间,这时候_capacity也得修改

void reserve(size_t n){ if (n > _capacity){ char* tmp = new char[n+1];strcpy(tmp, _str);delete[]_str;_str = tmp;}_capacity = n;}

然后实现push_back,先判断要不要扩容,然后插入字符,在把++_size,这里得在最后加上’\0’,因为插入的位置把’\0’占了。代码实现:
void push_back(char ch){ if (_size == _capacity){ reserve(_capacity==0?4:2 * _capacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}

插入一个字符串,同样先判断是否要扩容,这里直接计算出插入这个字符串,需要多大的空间,就开多大的空间。然后用strcpy把字符串拷贝过去,最后_size += len:
void append(const char* str){ size_t len = strlen(str);if (_size + len > _capacity){ reserve(_size + len);}strcpy(_str + _size, str);_size += len;}
4.2 +=
再实现一下+=:+=字符就复用push_back,+=字符串就复用append:
string& operator+=(char ch){ push_back(ch);return *this;}string& operator+=(const char* str){ append(str);return *this;}
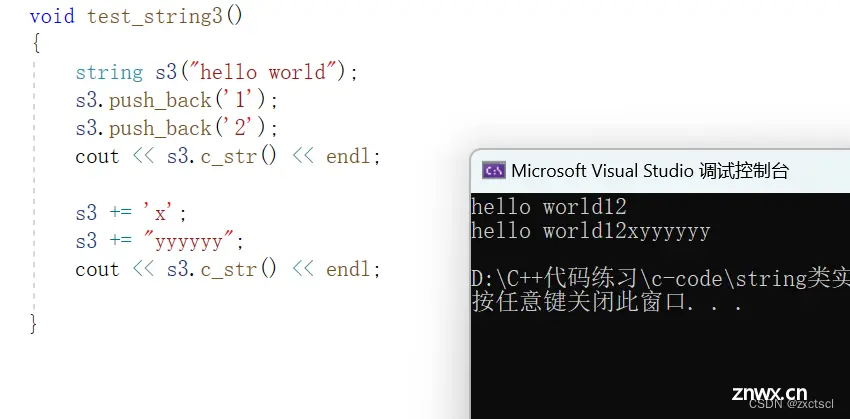
用代码来看看效果:
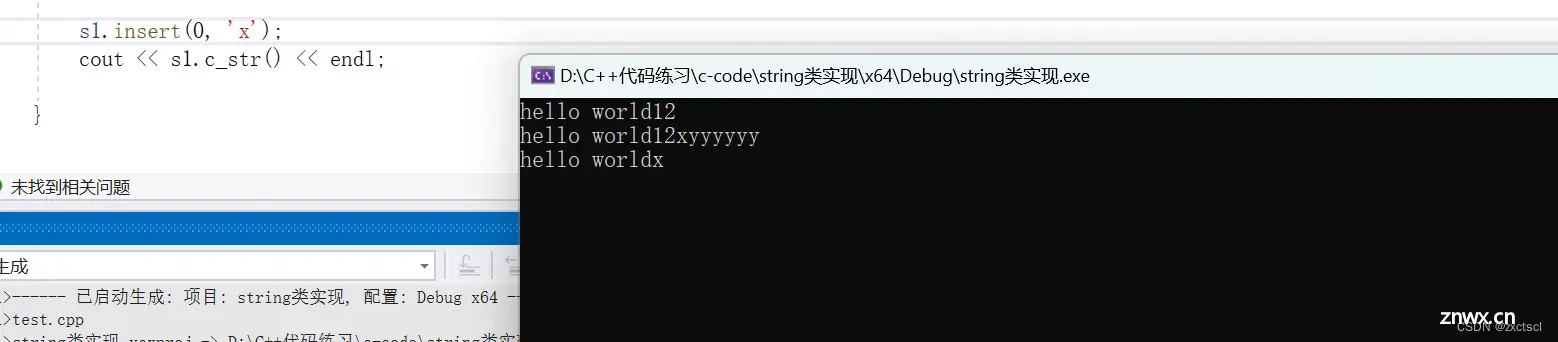
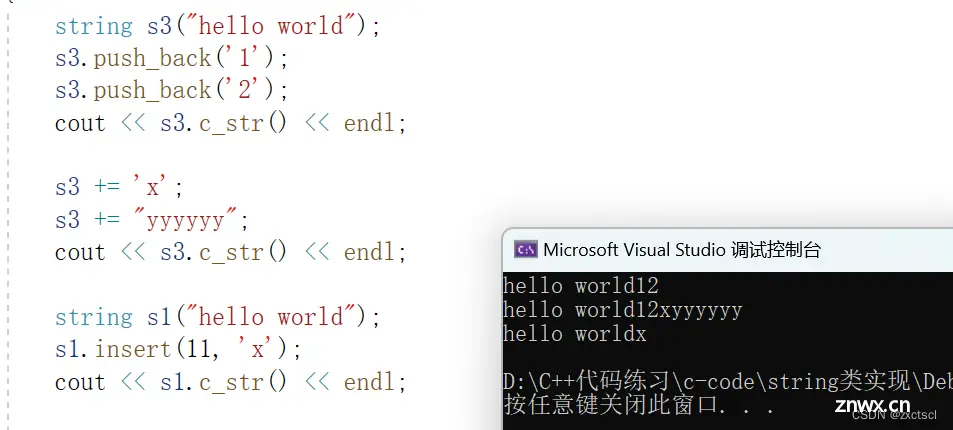
void test_string3(){ string s3("hello world");s3.push_back('1');s3.push_back('2');cout << s3.c_str() << endl;s3 += 'x';s3 += "yyyyyy";cout << s3.c_str() << endl;}
4.3 insert
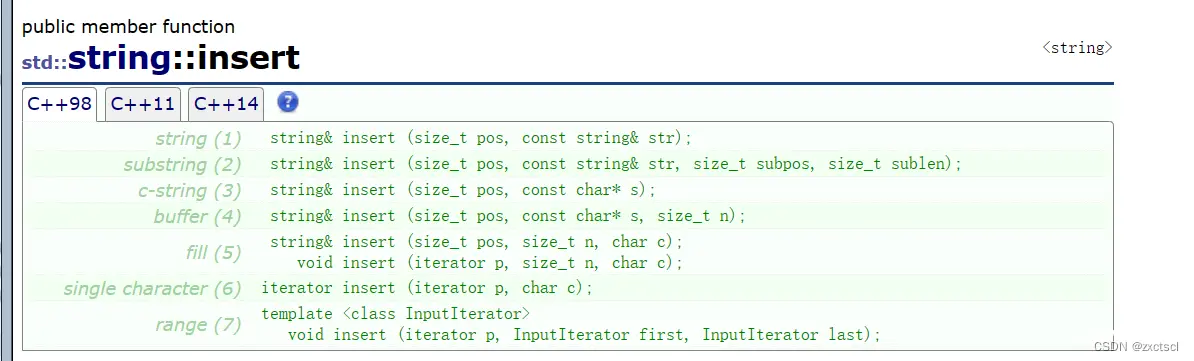
在pos位置插入一个字符,得先做一个检查看这个pos是否在范围内

把pos位置之后的数据往后挪,把pos空出来,再插入一个字符,然后把pos位置插入字符,在++_size。
void insert(size_t pos,char ch){ assert(pos <= _size);if (_size == _capacity){ reserve(_capacity == 0 ? 4 : 2 * _capacity);}size_t end = _size;while (end >= pos){ _str[end + 1] = _str[end];--end;}_str[pos] = ch;++_size;}
但是当pos=0时候就会有问题:循环是小于0结束,但是end不会小于0
怎么修改呢?
把循环条件改为大于,然后将_str[end ] = _str[end-1],但是这里得把end放在size+1的位置:
void insert(size_t pos,char ch){ assert(pos <= _size);if (_size == _capacity){ reserve(_capacity == 0 ? 4 : 2 * _capacity);}size_t end = _size+1;while (end > pos){ _str[end ] = _str[end-1];--end;}_str[pos] = ch;++_size;}
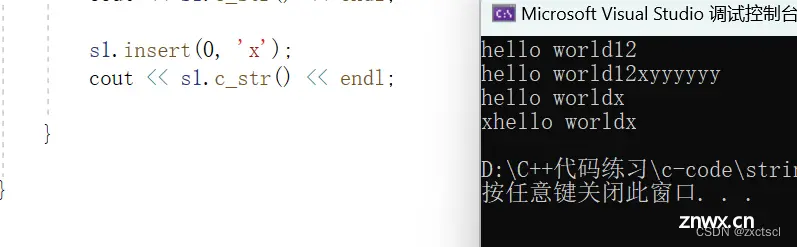

在pos位置插入一个字符串,也同样是先判断越界assert(pos <= _size);
如果空间不够,得扩容:
if (_size + len > _capacity){ reserve(_size + len);}
这里挪动数据的结尾是size_t end = _size + len,在挪动数据的时候判断条件得注意;end > pos + len - 1
void insert(size_t pos, const char* str){ assert(pos <= _size);size_t len = strlen(str);if (_size + len > _capacity){ // 扩容reserve(_size + len);}size_t end = _size + len;while (end > pos + len - 1){ _str[end] = _str[end - len];end--;}strncpy(_str + pos, str, len);_size += len;}
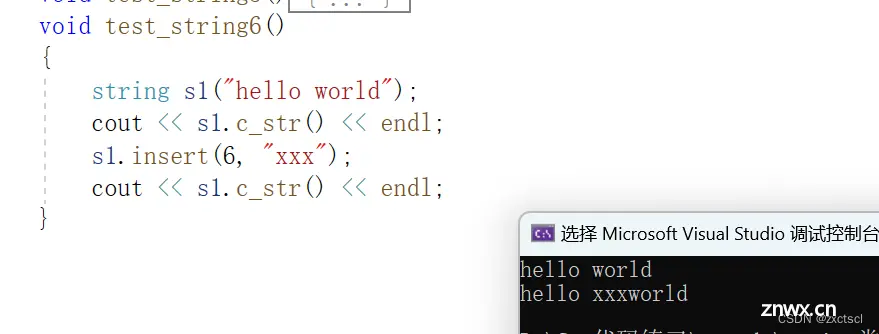

用insert来复用一下push_back和append
void push_back(char ch){ /*if (_size ==_capacity){reserve(_capacity==0?4:2 * _capacity);}_str[_size] = ch;++_size;_str[_size] = '\0';*/insert(_size, ch);}void append(const char* str){ /*size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}strcpy(_str + _size, str);_size += len;*/insert(_size, str);}
4.4 erase
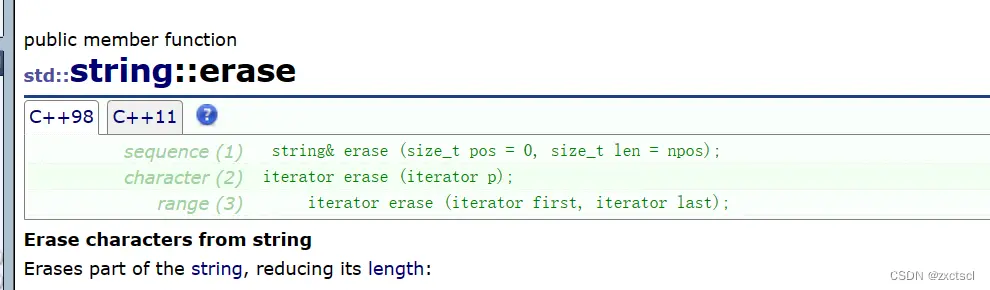
得先检查,看看pos是否越界:assert(pos<_size);
如果给的是npos就全部删除,就把pos位置直接给"\0",如果给的len比size要大,那么也全部删除:
if (len == npos || pos + len >= _size){ _str[pos] = '\0';_size = pos;}
但是这里会存在一个问题pos+size可能会溢出。
为了解决这个问题就修改为:
if (len == npos || len >= _size-pos){ _str[pos] = '\0';_size = pos;}

如果只删除部分,就直接把pos+len位置拷贝过去覆盖就行。
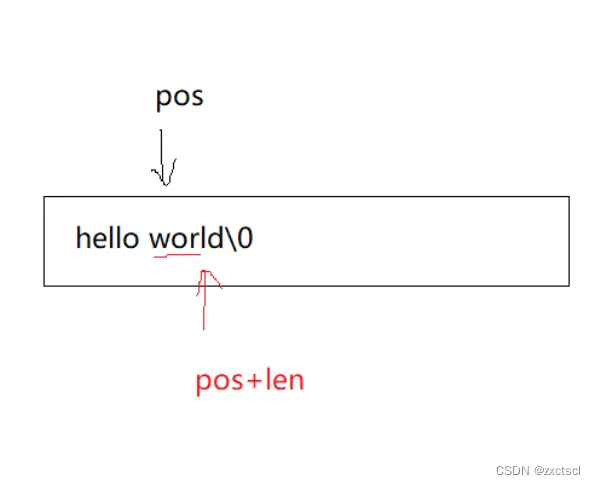
void erase(size_t pos, size_t len = npos){ assert(pos<_size);if (len == npos || len >= _size-pos){ _str[pos] = '\0';_size = pos;}else{ strcpy(_str + pos, _str + pos + len);_size -= len;}}
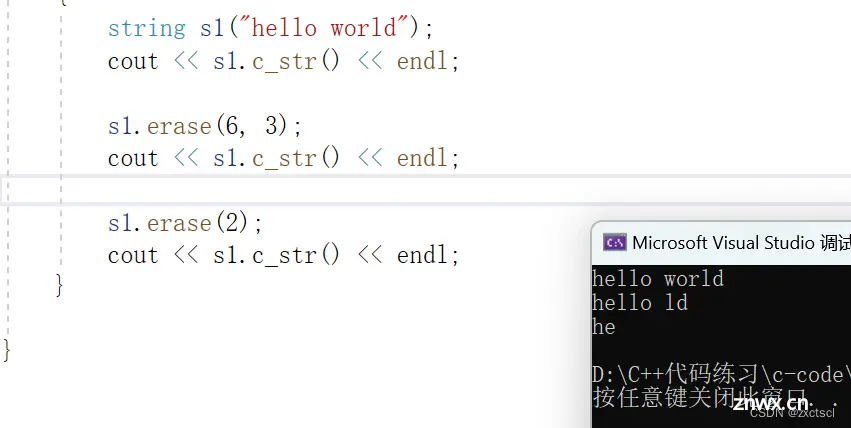
4.5 swap

这里交换使用了三次拷贝加一次析构,代价太大。
实现一下简单的交换,直接将将两个字符串内容交换就行,使用库函数里面的swap来实现:
void swap(string& s){ std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}
这里必须加上std,编译器在实现的时候先在局部找,再到全局。不加,在局部的时候就找到了,然后去调用发现参数会不匹配
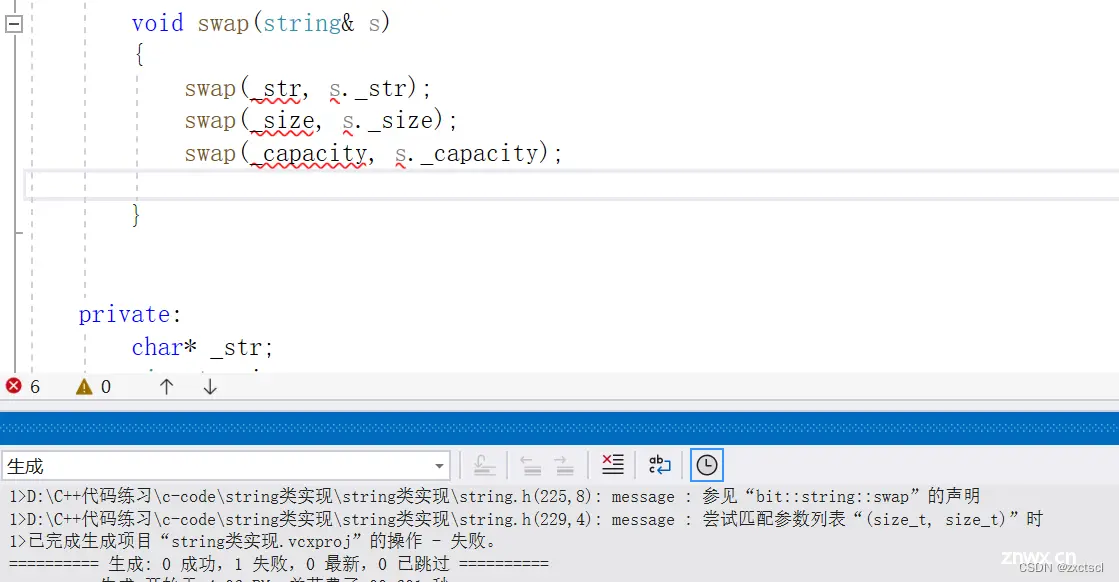
加上就没有问题
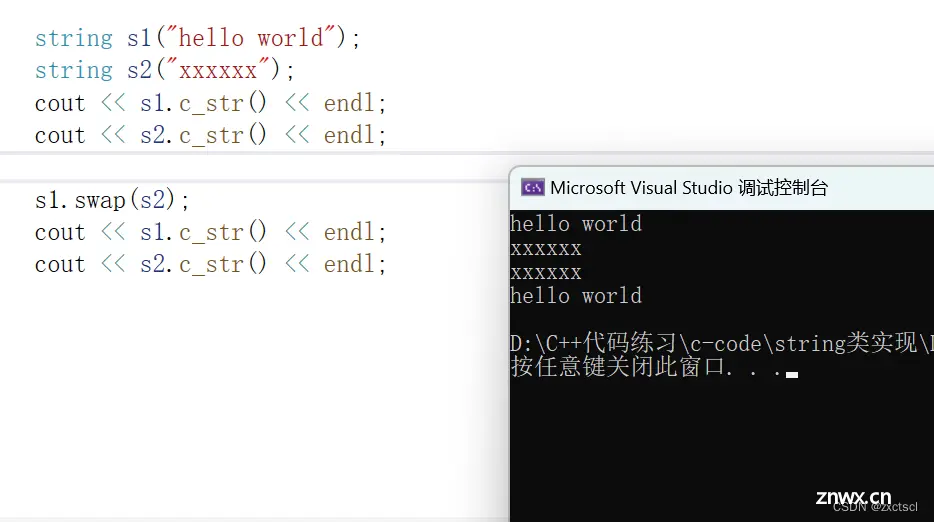
void swap(string& s){ std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}void test_string6() { string s1("hello world");string s2("xxxxxx");cout << s1.c_str() << endl;cout << s2.c_str() << endl;s1.swap(s2);cout << s1.c_str() << endl;cout << s2.c_str() << endl;}
5.Capacity
5.1 resize
调整字符串大小(resize)

将字符串大小调整为 n 个字符的长度。
如果 n 小于当前字符串长度,则当前值将缩短为其第一个 n 个字符,从而删除第 n个字符之外的字符。
如果给的n小于_size就直接把n位置设为’\0’,在把_size改为n:
if (n < _size){ _str[n] = '\0';_size = n;}
2.如果 n 大于当前字符串长度,则通过在末尾插入所需数量的字符来扩展当前内容,以达到 n 的大小。如果指定了 c,则新元素将初始化为 c 的副本,否则,它们是值初始化的字符(空字符)。
不管空间够不够,先 reserve(n);在将末尾插入字符
reserve(n);for (size_t i = _size; i < n; i++){ _str[i] = ch;}_str[n] = '\0';_size = n;
所以resize实现出来就是:
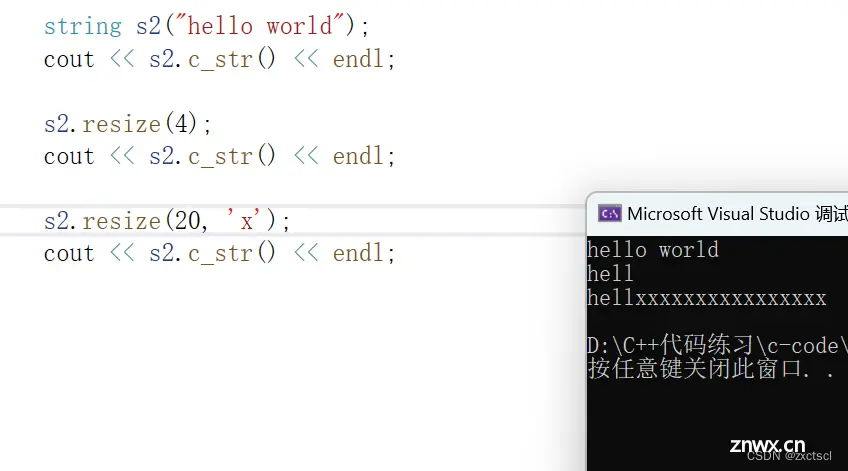
void resize(size_t n, char ch = '\0'){ if (n < _size){ _str[n] = '\0';_size = n;}else{ reserve(n);for (size_t i = _size; i < n; i++){ _str[i] = ch;}_str[n] = '\0';_size = n;}}void test_string4(){ string s2("hello world");cout << s2.c_str() << endl;s2.resize(4);cout << s2.c_str() << endl;s2.resize(20, 'x');cout << s2.c_str() << endl;}
5.2 clear
直接把_size设为0,然后把_str[_size] 位置赋一个 ‘\0’;
void clear(){ _size = 0;_str[_size] = '\0';}
6. 深浅拷贝
6.1 浅拷贝(值拷贝)
void test_string5(){ string s1("hello world");cout << s1.c_str() << endl;string s2(s1);cout << s2.c_str() << endl;}
用s1拷贝构造一个s2,会出现:
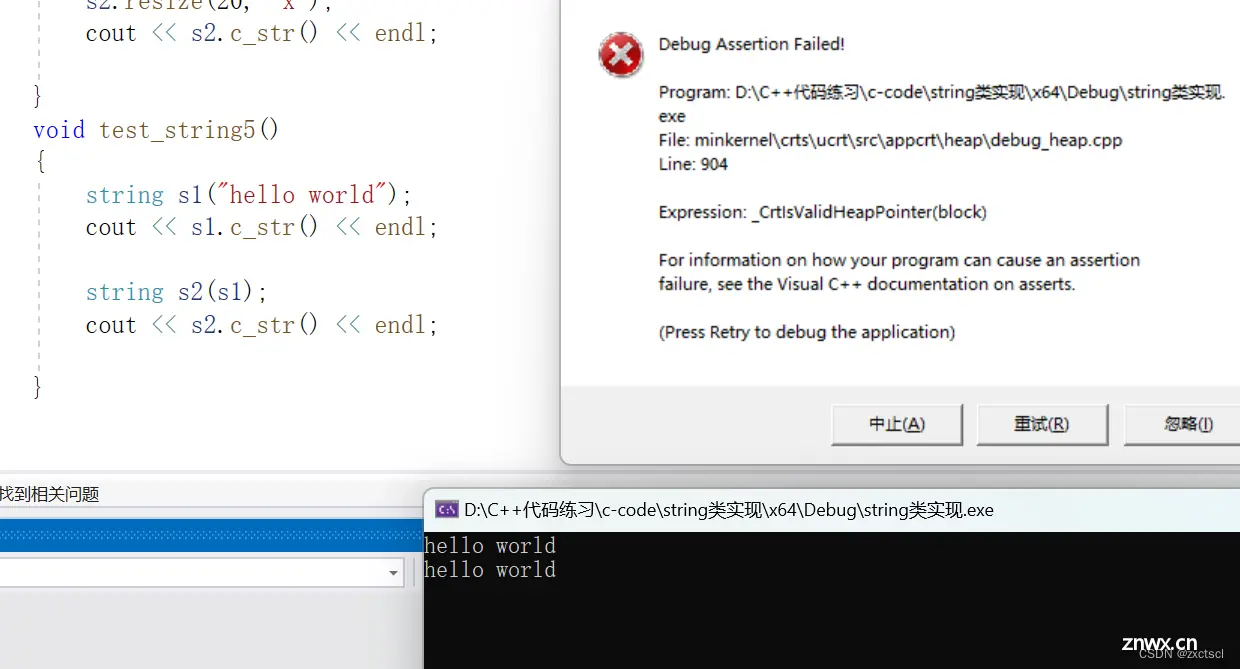
它们指向的是同一个空间,会出现析构两次的情况。而且当修改其中一个时,另一个也会被修改。
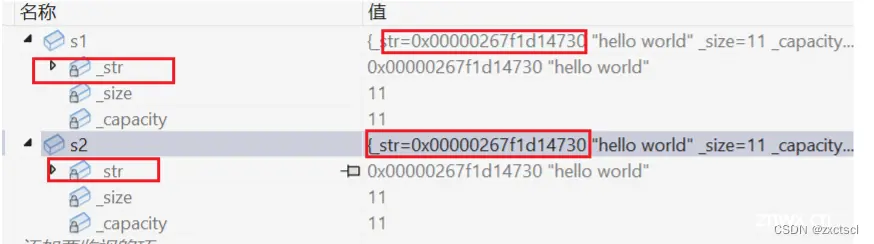
6.2 深拷贝
要想拷贝构造之后,修改其中一个,另外一个不被一起修改,就使用深拷贝。
传统写法:自己动手。就自己和拷贝的字符串开同样大小的空间,然后在把值拷过来。
string(const string& s){ _str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}
这一次两个字符的空间就不一样了:


用现代写法:就是借助他人之手。先用s构造一个tmp:string tmp(s._str);,再把交换一下。
这样被交换的就只是一个临时拷贝,不想要的空间随着栈帧的结束被销毁。
让tmp拷贝构造和s1的相同,然后让s2和tmp交换,这个时候s2就拿到了和s1相同的值:
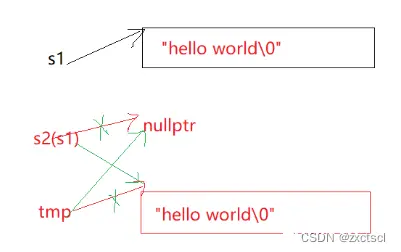
string(const string& s){ string tmp(s._str);swap(tmp);}
7. String operations
7.1 find
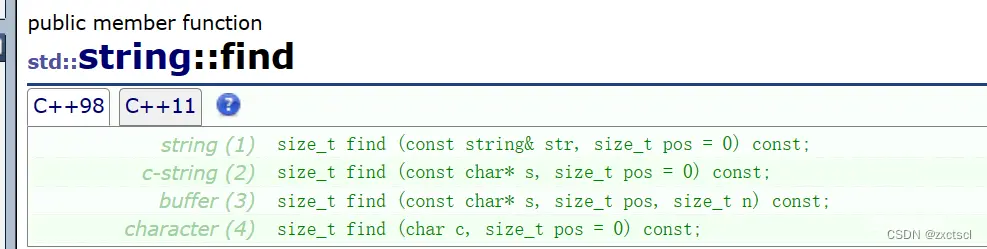
查找一个字符,找到就返回下标,没有找到就返回npos,这里加了const,这样const对象和非const对象都可以调用:
size_t find(char ch,size_t pos=0)const{ assert(pos < _size);for (size_t i = pos; i < _size; i++){ if (_str[i] == ch)return i;}return npos;}

还可以查找一个子串:这里用到了库里面的strstr

先判断一下是否越界,然后用strstr匹配字串,如果没有匹配到就返回空,如果找到了,要返回下标,就用指针-指针来得到下标:
size_t find(const char* sub, size_t pos = 0)const{ assert(pos < _size);const char* p = strstr(_str+pos, sub);if (p){ return p - _str;}else{ return npos;}}
7.2 substr
取字串
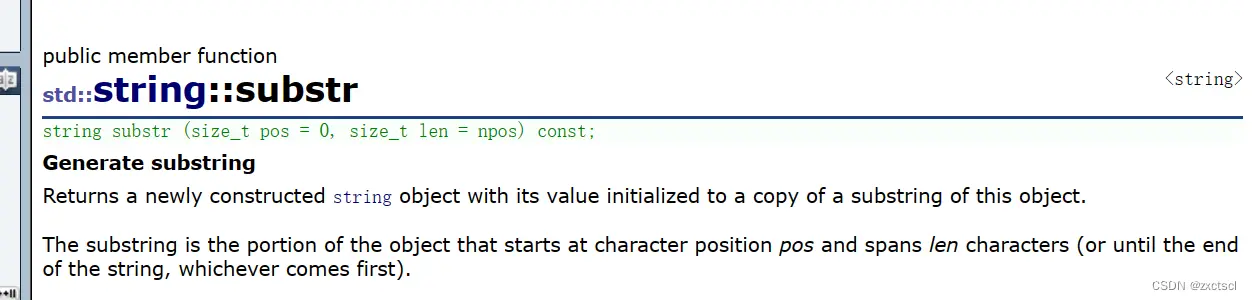
如果len大于剩下的长度,那么就有多少就取多少:
if (len >= _size - pos){ for (size_t i = 0; i < _size; i++){ sub += _str[i];}}
当小于_size时候就从pos位置取到pos+len位置:
else{ for (size_t i = 0; i < pos+len; i++){ sub += _str[i];}}
实现出来就是这样:
string substr(size_t pos = 0, size_t len = npos){ string sub;if (len >= _size - pos){ for (size_t i = 0; i < _size; i++){ sub += _str[i];}}else{ for (size_t i = 0; i < pos+len; i++){ sub += _str[i];}}return sub;}
举个例子看看:
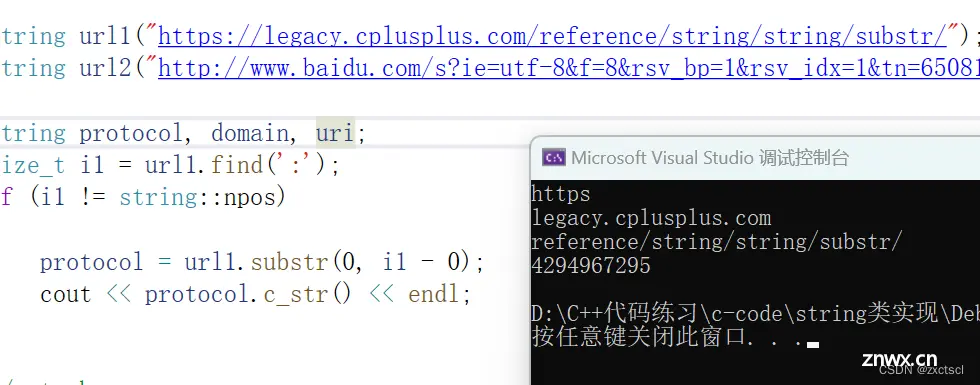
void test_string7(){ string url1("https://legacy.cplusplus.com/reference/string/string/substr/");string url2("http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=65081411_1_oem_dg&wd=%E5%90%8E%E7%BC%80%20%E8%8B%B1%E6%96%87&fenlei=256&rsv_pq=0xc17a6c03003ede72&rsv_t=7f6eqaxivkivsW9Zwc41K2mIRleeNXjmiMjOgoAC0UgwLzPyVm%2FtSOeppDv%2F&rqlang=en&rsv_dl=ib&rsv_enter=1&rsv_sug3=4&rsv_sug1=3&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=1588&rsv_sug4=6786");string protocol, domain, uri;size_t i1 = url1.find(':');if (i1 != string::npos){ protocol = url1.substr(0, i1 - 0);cout << protocol.c_str() << endl;}// strcharsize_t i2 = url1.find('/', i1 + 3);if (i2 != string::npos){ domain = url1.substr(i1 + 3, i2 - (i1 + 3));cout << domain.c_str() << endl;uri = url1.substr(i2 + 1);cout << uri.c_str() << endl;}// size_t i3 = url1.find("baidu");cout << i3 << endl;}
8. relational operators (string)
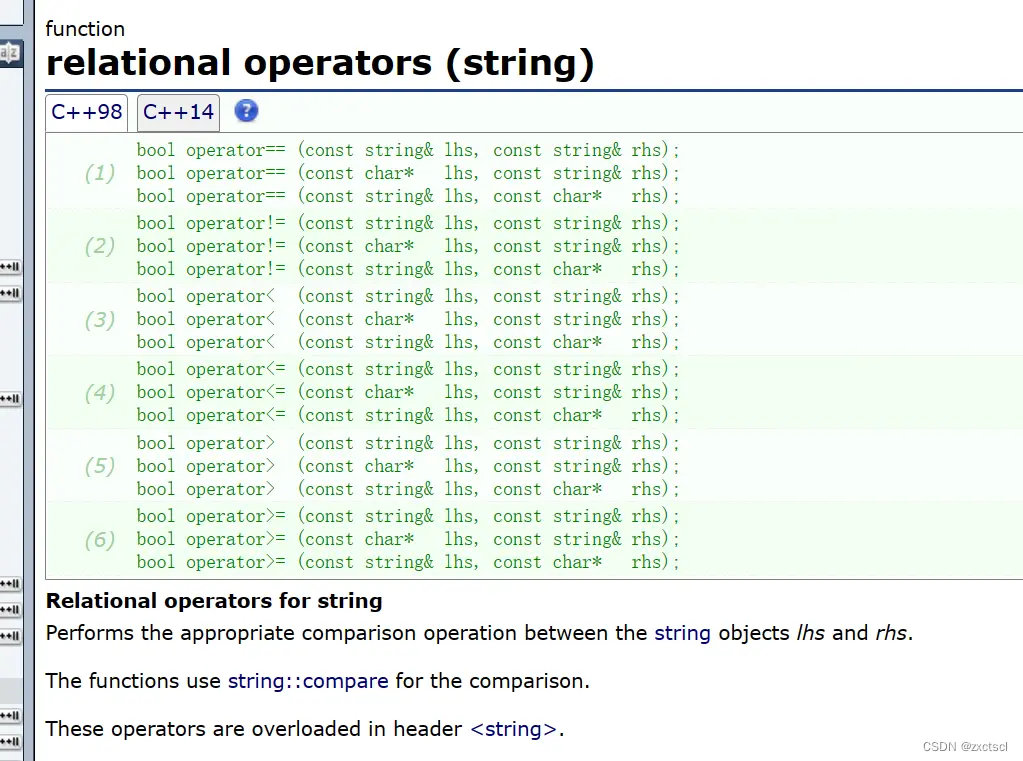
8.1 运算符重载
判断字符串是否相等,直接复用库里面的strcmp,让它们去比较:
bool operator==(const string& s){ int ret = strcmp(_str, s.c_str());return ret == 0;}
来测试一下:

但是像这样就不支持
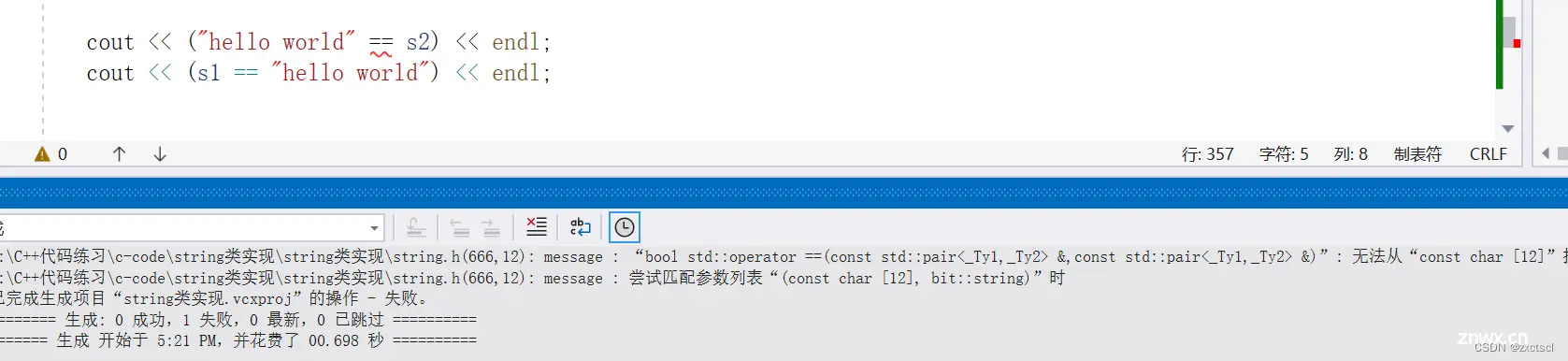
所以把它重载为全局的:
bool operator==(const string& s1, const string& s2){ int ret = strcmp(s1.c_str(), s2.c_str());return ret == 0;}
这样就没有问题
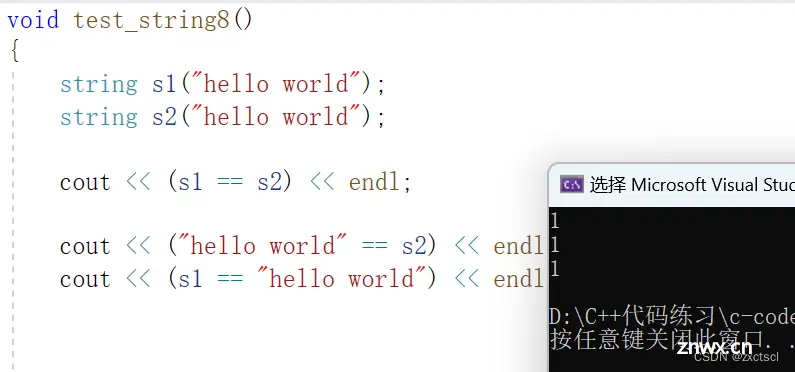

剩下的运算符重载
同样将剩下的全部重载为全局的
bool operator<(const string& s1, const string& s2){ int ret = strcmp(s1.c_str(), s2.c_str());return ret < 0;}

<=就复用<和==就可以:
bool operator<=(const string& s1, const string& s2){ return s1 < s2 || s1 == s2;}

就把<=取反就行:
bool operator>(const string& s1, const string& s2){ return !(s1 <= s2);}

就把<取反就行:
bool operator>(const string& s1, const string& s2){ return !(s1 < s2);}

就把==取反就行:
bool operator!=(const string& s1, const string& s2){ return !(s1 == s2);}
8.2 赋值
传统赋值:
让s1=s3,就得先开一个空间tmp,然后把s3的值拷贝到tmp里面,再把s1的空间释放delete[] _str;,再让_str = tmp;,最后返回this。
string& operator=(const string& s){ char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;_size = s._size;_capacity = s._capacity;return *this;}

现代写法:想让s1=s3
先用s拷贝构造一个ss。再把ss和s1交换就行,出来作用域ss就销毁了,这时候就把交换到的s1的值就给销毁了。
string& operator=(const string& s){ string ss(s);swap(ss);return *this;}
可以直接传值传参,直接调拷贝构造,ss就是s3构造出来的
string& operator=(string ss){ swap(ss);return *this;}
9. Non-member function overloads
9.1 流插入和流提取
流插入就是把字符一个一个打印出来就行,不需要访问私有成员
ostream& operator<<(ostream& out, const string& s){ for (auto ch : s){ out << ch;}return out;}

流提取默认等于空格和换行就结束
istream& operator>>(istream& in, string& s){ char ch;in >> ch;while (ch != ' ' && ch != '\n'){ s += ch;in>>ch;}return in;}
这里会陷入死循环
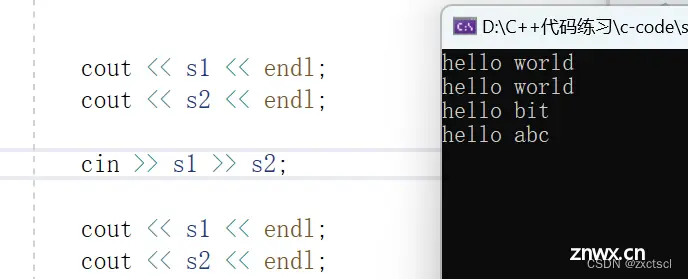
这里一个一个字符读的时候空格和换行拿不到。
这里的io流在istream类里面:

在istream类有:

所以这里得用get来取字符:
流提取是一个覆盖,在提取之前先清空,就用clear,再用get来获取字符:
istream& operator>>(istream& in, string& s){ s.clear();char ch;ch = in.get();while (ch != ' ' && ch != '\n'){ s += ch;ch = in.get();}return in;}
这个时候测试就没有问题:
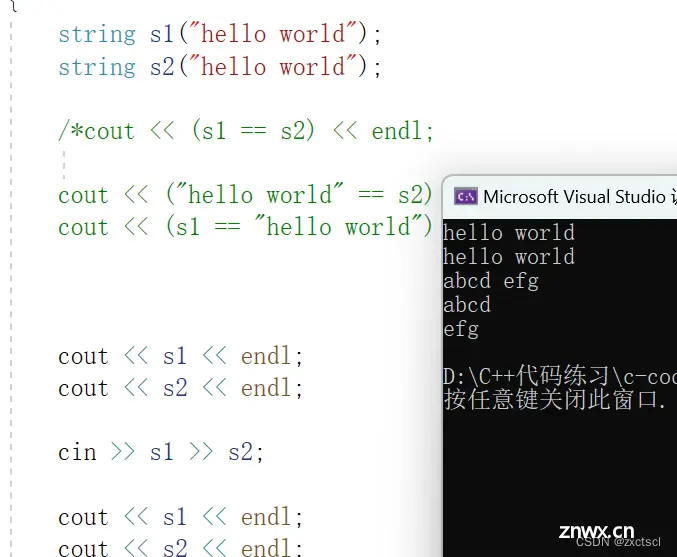

这里得考虑扩容会消耗,如果用reserve的话,不知道会开多少空间,可以会浪费也可能会不够。
事先给了一个字符数组char buff[128];,如果给的少就按照有效字符来开空间:
if (i > 0){ buff[i] = '\0';s += buff;}
如果给的等于127,那么又开127,然后也是按照有效字符来开空间,不够就加,以128为中间值。
if (i == 127){ buff[127] = '\0';s += buff;i = 0;}
实现出来就是:
istream& operator>>(istream& in, string& s){ s.clear();char ch;//in >> ch;ch = in.get();char buff[128];size_t i = 0;while (ch != ' ' && ch != '\n'){ buff[i++] = ch;// [0,126]if (i == 127){ buff[127] = '\0';s += buff;i = 0;}ch = in.get();}if (i > 0){ buff[i] = '\0';s += buff;}return in;}
按有效字符来开的空间:

9.2 getline

获取一行,和流提取是一样的,直接把判断空格的删除就行:
istream& getline(istream& in, string& s){ s.clear();char ch;ch = in.get();char buff[128];size_t i = 0;while (ch != '\n'){ buff[i++] = ch;// [0,126]if (i == 127){ buff[127] = '\0';s += buff;i = 0;}ch = in.get();}if (i > 0){ buff[i] = '\0';s += buff;}return in;}
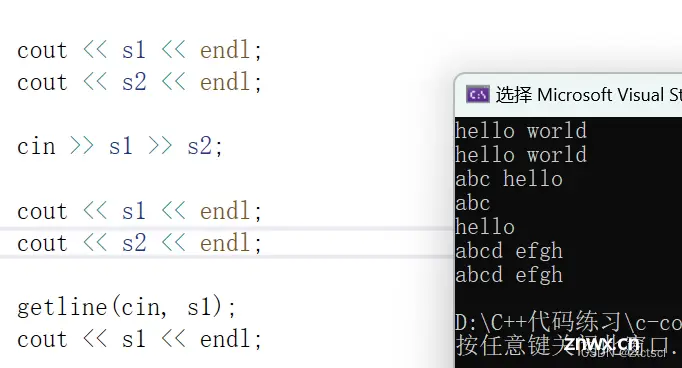
10. 附string类实现代码
#pragma once#include<assert.h>namespace bit{ class string{ public:typedef char* iterator;typedef const char* const_iterator;const_iterator begin() const{ return _str;}const_iterator end() const{ return _str + _size;}iterator begin(){ return _str;}iterator end(){ return _str + _size;}/*string():_str(new char[1]),_size(0),_capacity(0){_str[0] = '\0';}string(const char* str):_size(strlen(str)),_str(new char[strlen(str)+1]),_capacity(strlen(str)){strcpy(_str, str);}*/const char* c_str() const{ return _str;}//string(const char* str = "\0")string(const char* str = ""):_size(strlen(str)){ _capacity = _size;_str = new char[_capacity + 1];strcpy(_str, str);}// s2(s1)/*string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}*/// s2(s1)string(const string& s){ string tmp(s._str);swap(tmp);}string& operator=(string tmp){ // 现代写法swap(tmp);return *this;}// s1 = s3;/*string& operator=(const string& s){char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;_size = s._size;_capacity = s._capacity;return *this;}*/~string(){ delete[] _str;_str = nullptr;_size = _capacity = 0;}// 遍历size_t size() const{ return _size;}size_t capacity() const{ return _capacity;}char& operator[](size_t pos){ assert(pos < _size);return _str[pos];}const char& operator[](size_t pos) const{ assert(pos < _size);return _str[pos];}void resize(size_t n, char ch = '\0'){ if (n <= _size){ _str[n] = '\0';_size = n;}else{ reserve(n);for (size_t i = _size; i < n; i++){ _str[i] = ch;}_str[n] = '\0';_size = n;}}void reserve(size_t n){ if (n > _capacity){ char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void push_back(char ch){ // 扩容2倍/*if (_size == _capacity){reserve(_capacity == 0 ? 4 : 2 * _capacity);}_str[_size] = ch;++_size;_str[_size] = '\0';*/insert(_size, ch);}void append(const char* str){ // 扩容/*size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}strcpy(_str + _size, str);_size += len;*/insert(_size, str);}string& operator=(string ss){ swap(ss);return *this;}string& operator+=(char ch){ push_back(ch);return *this;}string& operator+=(const char* str){ append(str);return *this;}void insert(size_t pos, char ch){ assert(pos <= _size);// 扩容2倍if (_size == _capacity){ reserve(_capacity == 0 ? 4 : 2 * _capacity);}/*int end = _size;while (end >= (int)pos){_str[end + 1] = _str[end];--end;}*/size_t end = _size + 1;while (end > pos){ _str[end] = _str[end - 1];--end;}_str[pos] = ch;++_size;}void insert(size_t pos, const char* str){ assert(pos <= _size);size_t len = strlen(str);if (_size + len > _capacity){ // 扩容reserve(_size + len);}size_t end = _size + len;while (end > pos + len - 1){ _str[end] = _str[end - len];end--;}strncpy(_str + pos, str, len);_size += len;}void erase(size_t pos, size_t len = npos){ assert(pos < _size);if (len == npos || len >= _size - pos){ _str[pos] = '\0';_size = pos;}else{ strcpy(_str + pos, _str + pos + len);_size -= len;}}void swap(string& s){ std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}size_t find(char ch, size_t pos = 0) const{ assert(pos < _size);for (size_t i = pos; i < _size; i++){ if (_str[i] == ch)return i;}return npos;}size_t find(const char* sub, size_t pos = 0) const{ assert(pos < _size);const char* p = strstr(_str + pos, sub);if (p){ return p - _str;}else{ return npos;}}string substr(size_t pos = 0, size_t len = npos){ string sub;//if (len == npos || len >= _size-pos)if (len >= _size - pos){ for (size_t i = pos; i < _size; i++){ sub += _str[i];}}else{ for (size_t i = pos; i < pos + len; i++){ sub += _str[i];}}return sub;}void clear(){ _size = 0;_str[_size] = '\0';}private:char* _str = nullptr;size_t _size = 0;size_t _capacity = 0;public:static const int npos;};const int string::npos = -1;void swap(string& x, string& y){ x.swap(y);}bool operator==(const string& s1, const string& s2){ int ret = strcmp(s1.c_str(), s2.c_str());return ret == 0;}bool operator<(const string& s1, const string& s2){ int ret = strcmp(s1.c_str(), s2.c_str());return ret < 0;}bool operator<=(const string& s1, const string& s2){ return s1 < s2 || s1 == s2;}bool operator>(const string& s1, const string& s2){ return !(s1 <= s2);}bool operator>=(const string& s1, const string& s2){ return !(s1 < s2);}bool operator!=(const string& s1, const string& s2){ return !(s1 == s2);}ostream& operator<<(ostream& out, const string& s){ for (auto ch : s){ out << ch;}return out;}/*istream& operator>>(istream& in, string& s){s.clear();char ch;ch = in.get();while (ch != ' ' && ch != '\n'){s += ch;ch = in.get();}return in;}*/istream& operator>>(istream& in, string& s){ s.clear();char ch;//in >> ch;ch = in.get();char buff[128];size_t i = 0;while (ch != ' ' && ch != '\n'){ buff[i++] = ch;// [0,126]if (i == 127){ buff[127] = '\0';s += buff;i = 0;}ch = in.get();}if (i > 0){ buff[i] = '\0';s += buff;}return in;}//istream& operator>>(istream& in, string& s)//{ //s.clear();//char ch;////in >> ch;//ch = in.get();//s.reserve(128);//while (ch != '\n' && ch != ' ')//{ //s += ch;//ch = in.get();//}//return in;//}/*istream& getline(istream& in, string& s){s.clear();char ch;ch = in.get();while (ch != '\n'){s += ch;ch = in.get();}return in;}*/istream& getline(istream& in, string& s){ s.clear();char ch;//in >> ch;ch = in.get();char buff[128];size_t i = 0;while (ch != '\n'){ buff[i++] = ch;// [0,126]if (i == 127){ buff[127] = '\0';s += buff;i = 0;}ch = in.get();}if (i > 0){ buff[i] = '\0';s += buff;}return in;}void test_string1(){ string s1("hello world");string s2;cout << s1.c_str() << endl;cout << s2.c_str() << endl;for (size_t i = 0; i < s1.size(); i++){ s1[i]++;}cout << endl;// s1[100];for (size_t i = 0; i < s1.size(); i++){ cout << s1[i] << " ";}cout << endl;const string s3("xxxx");for (size_t i = 0; i < s3.size(); i++){ //s3[i]++;cout << s3[i] << " ";}cout << endl;// 越界检查是一种抽查//int a[10];// a[10];// a[11];// //a[10] = 1;// a[15] = 1;}void test_string2(){ string s3("hello world");for (auto ch : s3){ cout << ch << " ";}cout << endl;string::iterator it3 = s3.begin();while (it3 != s3.end()){ *it3 -= 1;cout << *it3 << " ";++it3;}cout << endl;const string s4("xxxx");string::const_iterator it4 = s4.begin();while (it4 != s4.end()){ //*it4 += 3;cout << *it4 << " ";++it4;}cout << endl;for (auto ch : s4){ cout << ch << " ";}cout << endl;}void test_string3(){ string s3("hello world");s3.push_back('1');s3.push_back('2');cout << s3.c_str() << endl;s3 += 'x';s3 += "yyyyyy";cout << s3.c_str() << endl;string s1("hello world");s1.insert(11, 'x');cout << s1.c_str() << endl;s1.insert(0, 'x');cout << s1.c_str() << endl;}void test_string4(){ string s1("hello world");cout << s1.c_str() << endl;s1.erase(6, 3);cout << s1.c_str() << endl;s1.erase(6, 30);cout << s1.c_str() << endl;s1.erase(3);cout << s1.c_str() << endl;string s2("hello world");cout << s2.c_str() << endl;s2.resize(5);cout << s2.c_str() << endl;s2.resize(20, 'x');cout << s2.c_str() << endl;}void test_string5(){ string s1("hello world");cout << s1.c_str() << endl;string s2(s1);cout << s2.c_str() << endl;s1[0] = 'x';cout << s1.c_str() << endl;cout << s2.c_str() << endl;string s3("xxxxx");s1 = s3;cout << s1.c_str() << endl;cout << s3.c_str() << endl;}void test_string6(){ string s1("hello world");cout << s1.c_str() << endl;s1.insert(6, "xxx");cout << s1.c_str() << endl;string s2("xxxxxxx");cout << s1.c_str() << endl;cout << s2.c_str() << endl;swap(s1, s2);s1.swap(s2);cout << s1.c_str() << endl;cout << s2.c_str() << endl;}void test_string7(){ string url1("https://legacy.cplusplus.com/reference/string/string/substr/");string url2("http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=65081411_1_oem_dg&wd=%E5%90%8E%E7%BC%80%20%E8%8B%B1%E6%96%87&fenlei=256&rsv_pq=0xc17a6c03003ede72&rsv_t=7f6eqaxivkivsW9Zwc41K2mIRleeNXjmiMjOgoAC0UgwLzPyVm%2FtSOeppDv%2F&rqlang=en&rsv_dl=ib&rsv_enter=1&rsv_sug3=4&rsv_sug1=3&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=1588&rsv_sug4=6786");string protocol, domain, uri;size_t i1 = url1.find(':');if (i1 != string::npos){ protocol = url1.substr(0, i1 - 0);cout << protocol.c_str() << endl;}// strcharsize_t i2 = url1.find('/', i1 + 3);if (i2 != string::npos){ domain = url1.substr(i1 + 3, i2 - (i1 + 3));cout << domain.c_str() << endl;uri = url1.substr(i2 + 1);cout << uri.c_str() << endl;}// size_t i3 = url1.find("baidu");cout << i3 << endl;}void test_string8(){ string s1("hello world");string s2("hello world");/*cout << (s1 == s2) << endl;cout << ("hello world" == s2) << endl;cout << (s1 == "hello world") << endl;*/cout << s1 << endl;cout << s2 << endl;cin >> s1 >> s2;cout << s1 << endl;cout << s2 << endl;getline(cin, s1);cout << s1 << endl;}void test_string9(){ string s1;cin >> s1;cout << s1.capacity() << endl;}void test_string10(){ string s1("hello world");string s2(s1);cout << s1 << endl;cout << s2 << endl;}}
有问题请指出,大家一起进步!!!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。