实现分布式锁的常用三种方式
创作小达人 2024-09-19 09:05:03 阅读 89
分布式锁概述
我们的系统都是分布式部署的,日常开发中,秒杀下单、抢购商品等等业务场景,为了防⽌库存超卖,都需要用到分布式锁。
分布式锁其实就是,控制分布式系统不同进程共同访问共享资源的一种锁的实现。如果不同的系统或同一个系统的不同主机之间共享了某个临界资源,往往需要互斥来防止彼此干扰,以保证一致性。
业界流行的分布式锁实现,一般有这3种方式:
基于数据库实现的分布式锁
基于Redis实现的分布式锁
基于Zookeeper实现的分布式锁
分布式锁:基于数据库实现
主要有两种方式:
1、悲观锁
2、乐观锁
A. 悲观锁(排他锁)
利用select … where xx=yy for update排他锁
注意:这里需要注意的是where xx=yy,xx字段必须要走索引,否则会锁表。有些情况下,比如表不大,mysql优化器会不走这个索引,导致锁表问题。
核心思想:以「悲观的心态」操作资源,无法获得锁成功,就一直阻塞着等待。
注意:该方式有很多缺陷,一般不建议使用。
实现:
创建一张资源锁表:
<code>
CREATE TABLE `resource_lock` (
`id` int(4) NOT NULL AUTO_INCREMENT COMMENT '主键',
`resource_name` varchar(64) NOT NULL DEFAULT '' COMMENT '锁定的资源名',
`owner` varchar(64) NOT NULL DEFAULT '' COMMENT '锁拥有者',
`desc` varchar(1024) NOT NULL DEFAULT '备注信息',
`update_time` timestamp NOT NULL DEFAULT '' COMMENT '保存数据时间,自动生成',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_resource_name` (`resource_name `) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的资源';code>
注意:resource_name 锁资源名称必须有唯一索引
使用事务查询更新:
@Transaction
public void lock(String name) {
ResourceLock rlock = exeSql("select * from resource_lock where resource_name = name for update");
if (rlock == null) {
exeSql("insert into resource_lock(reosurce_name,owner,count) values (name, 'ip',0)");
}
}
使用 for update 锁定的资源。如果执行成功,会立即返回,执行插入数据库,后续再执行一些其他业务逻辑,直到事务提交,执行结束;如果执行失败,就会一直阻塞着。
可以在数据库客户端工具上测试出来这个效果,当在一个终端执行了 for update,不提交事务。在另外的终端上执行相同条件的 for update,会一直卡着
虽然也能实现分布式锁的效果,但是会存在性能瓶颈。
优点:
简单易用,好理解,保障数据强一致性。
缺点:
1)在 RR 事务级别,select 的 for update 操作是基于间隙锁(gap lock) 实现的,是一种悲观锁的实现方式,所以存在阻塞问题。
2)高并发情况下,大量请求进来,会导致大部分请求进行排队,影响数据库稳定性,也会耗费服务的CPU等资源。
当获得锁的客户端等待时间过长时,会提示:
[40001][1205] Lock wait timeout exceeded; try restarting transaction
高并发情况下,也会造成占用过多的应用线程,导致业务无法正常响应。
3)如果优先获得锁的线程因为某些原因,一直没有释放掉锁,可能会导致死锁的发生。
4)锁的长时间不释放,会一直占用数据库连接,可能会将数据库连接池撑爆,影响其他服务。
5)MySql数据库会做查询优化,即便使用了索引,优化时发现全表扫效率更高,则可能会将行锁升级为表锁,此时可能就更悲剧了。
6)不支持可重入特性,并且超时等待时间是全局的,不能随便改动。
B. 乐观锁
所谓乐观锁与悲观锁最大区别在于基于CAS思想,表中添加一个时间戳或者是版本号的字段来实现,update xx set version=new_version where xx=yy and version=Old_version,通过增加递增的版本号字段实现乐观锁。
不具有互斥性,不会产生锁等待而消耗资源,操作过程中认为不存在并发冲突,只有update version失败后才能觉察到。
抢购、秒杀就是用了这种实现以防止超卖。
实现:
创建一张资源锁表:
CREATE TABLE `resource` (
`id` int(4) NOT NULL AUTO_INCREMENT COMMENT '主键',
`resource_name` varchar(64) NOT NULL DEFAULT '' COMMENT '资源名',
`share` varchar(64) NOT NULL DEFAULT '' COMMENT '状态',
`version` int(4) NOT NULL DEFAULT '' COMMENT '版本号',
`desc` varchar(1024) NOT NULL DEFAULT '备注信息',
`update_time` timestamp NOT NULL DEFAULT '' COMMENT '保存数据时间,自动生成',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_resource_name` (`resource_name `) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='资源';code>
为表添加一个字段,版本号或者时间戳都可以。通过版本号或者时间戳,来保证多线程同时间操作共享资源的有序性和正确性。
伪代码实现:
Resrouce resource = exeSql("select * from resource where resource_name = xxx");
boolean succ = exeSql("update resource set version= 'newVersion' ... where resource_name = xxx and version = 'oldVersion'");
if (!succ) {
// 发起重试
}
实际代码中可以写个while循环不断重试,版本号不一致,更新失败,重新获取新的版本号,直到更新成功。
优点:
实现简单,复杂度低
保障数据一致性
缺点:
性能低,并且有锁表的风险
可靠性差
非阻塞操作失败后,需要轮询,占用CPU资源
长时间不commit或者是长时间轮询,可能会占用较多的连接资源
分布式锁:基于Redis实现
原理与实现
Redis提供了多种命令支持实现分布式锁,其中最常用的是SETNX(Set if Not eXists)和GETSET结合使用,或者使用更高级的SET命令配合NX(Only set the key if it does not already exist)和PX或EX(为key设置过期时间)选项。
优点:
性能高效,Redis本身为内存数据库,操作速度快。
实现简单,通过几个命令即可完成锁的获取与释放。
支持自动过期,降低死锁风险。
缺点:
单点问题,依赖单一Redis实例可能成为瓶颈。
网络分区可能导致锁的不一致状态。
示例代码(伪代码):
import redis.clients.jedis.Jedis;
public class RedisDistributedLock {
private Jedis jedis;
private static final String LOCK_SUCCESS = "OK";
private static final Long RELEASE_SUCCESS = 1L;
public RedisDistributedLock(Jedis jedis) {
this.jedis = jedis;
}
public boolean lock(String lockKey, int expireTime) {
String result = jedis.set(lockKey, "locked", "NX", "PX", expireTime * 1000);
return LOCK_SUCCESS.equals(result);
}
public boolean unlock(String lockKey) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, 1, lockKey, "locked");
return RELEASE_SUCCESS.equals(result);
}
}
代码注解:上例中,lock方法尝试使用NX(只在键不存在时设置)和PX(设置过期时间,单位毫秒)参数设置锁,返回OK表示成功获取锁。unlock方法使用Lua脚本确保解锁操作的原子性,只有当锁的持有者与当前客户端匹配时才执行删除操作。
分布式锁:基于Zookeeper实现
在学习Zookeeper分布式锁之前,我们复习一下Zookeeper的节点哈。
Zookeeper的节点Znode有四种类型:
持久节点:默认的节点类型。创建节点的客户端与zookeeper断开连接后,该节点依旧存在。
持久节点顺序节点:所谓顺序节点,就是在创建节点时,Zookeeper根据创建的时间顺序给该节点名称进行编号,持久节点顺序节点就是有顺序的持久节点。
临时节点:和持久节点相反,当创建节点的客户端与zookeeper断开连接后,临时节点会被删除。
临时顺序节点:有顺序的临时节点。
Zookeeper分布式锁实现应用了临时顺序节点。这里不贴代码啦,来讲下zk分布式锁的实现原理吧。
zk获取锁过程
当第一个客户端请求过来时,Zookeeper客户端会创建一个持久节点locks。如果它(Client1)想获得锁,需要在locks节点下创建一个顺序节点lock1.如图
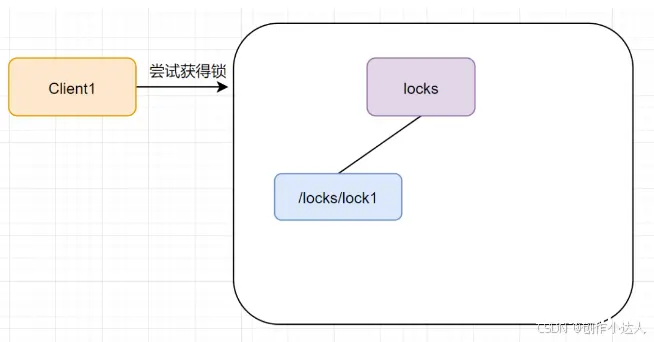
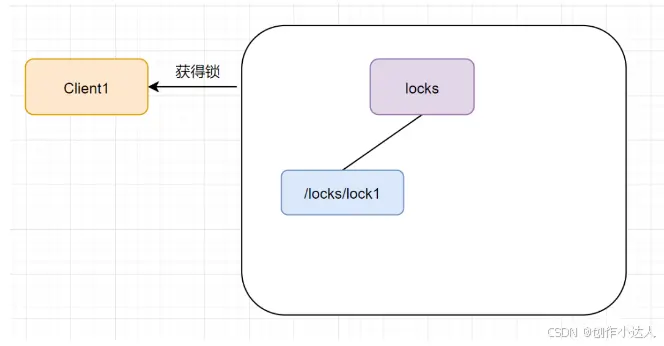
接着,客户端Client1会查找<code>locks下面的所有临时顺序子节点,判断自己的节点lock1是不是排序最小的那一个,如果是,则成功获得锁。
这时候如果又来一个客户端client2前来尝试获得锁,它会在locks下再创建一个临时节点<code>lock2
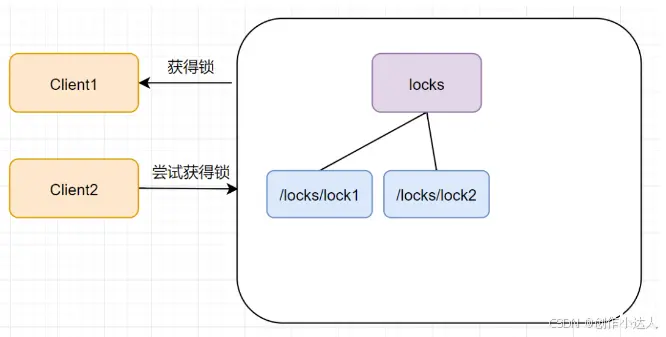
客户端client2一样也会查找locks下面的所有临时顺序子节点,判断自己的节点lock2是不是最小的,此时,发现lock1才是最小的,于是获取锁失败。获取锁失败,它是不会甘心的,client2向它排序靠前的节点lock1注册Watcher事件,用来监听lock1是否存在,也就是说client2抢锁失败进入等待状态。

此时,如果再来一个客户端Client3来尝试获取锁,它会在locks下再创建一个临时节点lock3
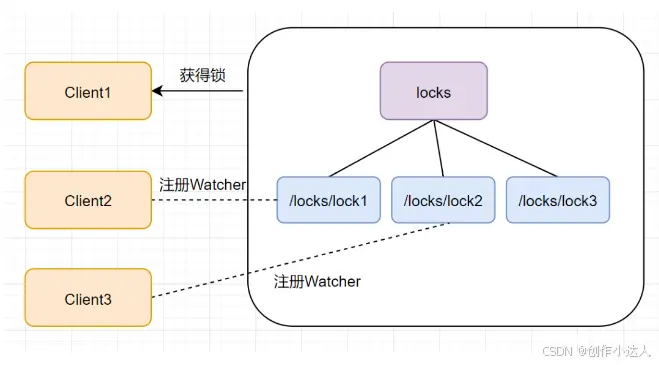
同样的,client3一样也会查找locks下面的所有临时顺序子节点,判断自己的节点lock3是不是最小的,发现自己不是最小的,就获取锁失败。它也是不会甘心的,它会向在它前面的节点lock2注册Watcher事件,以监听lock2节点是否存在。
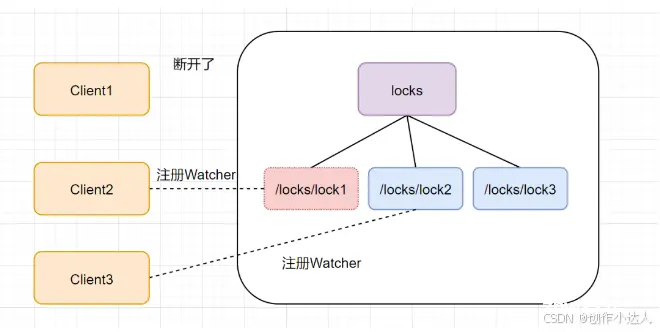
释放锁
我们再来看看释放锁的流程,Zookeeper的客户端业务完成或者发生故障,都会删除临时节点,释放锁。如果是任务完成,Client1会显式调用删除lock1的指令

如果是客户端故障了,根据临时节点得特性,lock1是会自动删除的

lock1节点被删除后,Client2可开心了,因为它一直监听着lock1。lock1节点删除,Client2立刻收到通知,也会查找locks下面的所有临时顺序子节点,发下lock2是最小,就获得锁。
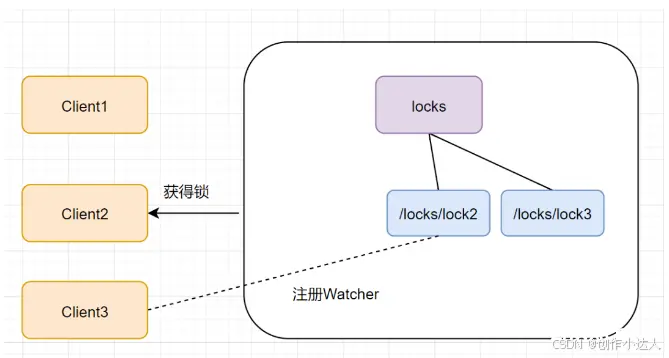
同理,Client2获得锁之后,Client3也对它虎视眈眈,啊哈哈~
Zookeeper设计定位就是分布式协调,简单易用。如果获取不到锁,只需添加一个监听器即可,很适合做分布式锁。
Zookeeper作为分布式锁也缺点:如果有很多的客户端频繁的申请加锁、释放锁,对于Zookeeper集群的压力会比较大。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。