掌控数据流:深入解析 Java Stream 编程
CSDN 2024-06-10 14:35:06 阅读 98
Java 8 引入了一种新的抽象称为流(Stream),它可以让你以一种声明的方式处理数据。Java 8 Stream API 可以极大提高 Java 程序员的生产力,使代码更简洁,更易读,并利用多核架构进行外部迭代。这里将详细介绍 Java 8 中的 Stream 流。
文章目录
1、Stream 流概述1.1、Stream 流简介1.2、Streaml 流组成1.3、Streaml 流示例1.4、Stream 流的特点 2、Stream 流的具体组成与操作2.1、数据源(Source)2.1.1、集合2.1.2、数组2.1.3、文件2.1.4、其他 2.2、中间操作(Intermediate Operations)2.2.1、`filter(Predicate<T>)` 方法2.2.2、`map(Function<T,R>)` 方法2.2.3、`flatMap(Function<T,Stream<R>>)` 方法2.2.4、`distinct()` 方法2.2.5、`sorted()` 方法2.2.6、`peek(Consumer<T>)` 方法 2.3、终端操作(Terminal Operations)2.3.1、`forEach(Consumer<T>)` 方法2.3.2、`collect(Collectors)` 方法2.3.3、`reduce(BinaryOperator<T>)` 方法2.3.4、`match(Predicate<T>)` 方法2.3.5、`count()` 方法2.3.6、`findFirst()` 方法 3、利用 Stream 的并行处理3.1、并行流的创建3.2、并行执行的工作原理3.3、使用并行流的示例3.4、并行流的注意事项
1、Stream 流概述
1.1、Stream 流简介
Stream 流是 Java8 提供的新功能,它允许你以一种声明的方式处理数据集合(通过查询表达式)。它可以表达复杂的过滤、映射、归约等数据处理操作。简而言之,流不是数据结构,而是关于算法和计算的。它们可以让你重新思考数据处理的方式。
Stream 流是对集合(Collection)对象功能的增强,与 Lambda 表达式结合,可以提高编程效率、简洁性和程序可读性。使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。
1.2、Streaml 流组成
Java Stream API 的构成主要可以分为三个部分:数据源(Source)、中间操作(Intermediate Operations)和终端操作(Terminal Operations)。这种构造允许流(Streams)在处理大量数据时提供高效率和易于管理的方式,特别适用于利用现代多核处理器的并行计算能力。
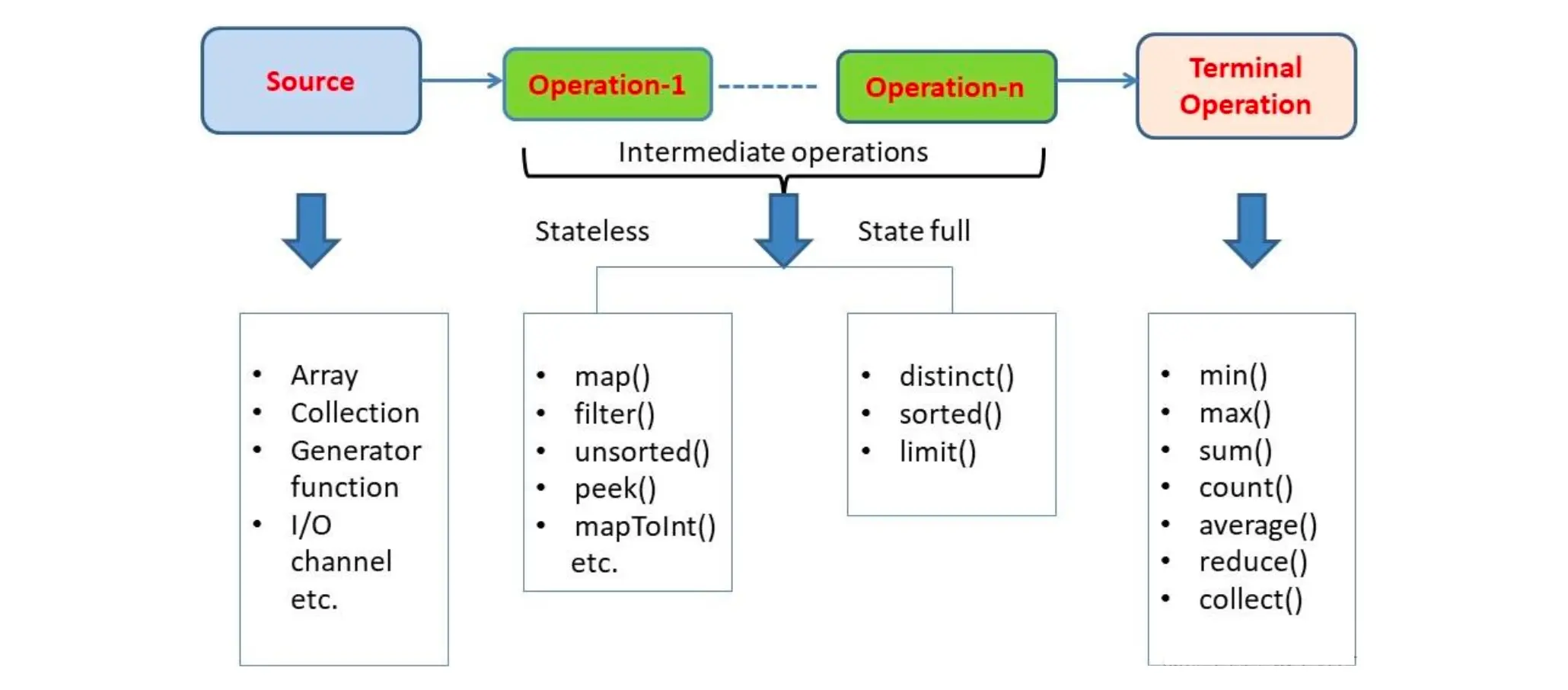
下面解释每个组成部分:
数据源(Source):Stream 的起点,可以从集合、数组、文件或生成函数等获取数据;中间操作(Intermediate Operations):对数据执行一个或多个操作,如过滤、映射、排序等,且这些操作是惰性的,仅在需要时执行;终端操作(Terminal Operations):结束流的操作,触发实际计算,并产生最终结果或副作用,如集合转换、总结统计或者逐个输出。
1.3、Streaml 流示例
这里是一个使用 Java Stream API 的例子,展示从数据源创建流,应用中间操作,并通过终端操作输出结果:
import java.util.Arrays;import java.util.List;import java.util.stream.Collectors;public class StreamExample { public static void main(String[] args) { List<String> myList = Arrays.asList("apple", "banana", "cherry", "date"); List<String> result = myList.stream() // 将 myList 转换为 Stream .filter(s -> s.startsWith("b")) // 中间操作:过滤掉不以 'b' 开头的字符串 .map(String::toUpperCase) // 中间操作:将字符串转大写 .sorted() // 中间操作:排序 .collect(Collectors.toList()); // 终端操作:收集到 List System.out.println(result); // 输出:[BANANA] }}
1.4、Stream 流的特点
以下是 Stream 流的几个核心特点,通过这些特点,Java Stream API 不仅使代码更加简洁,而且提高了处理大量数据的效率和简便性,尤其是在需要并行操作时。这些特性极大地推广了 Java 在函数式编程领域的应用。
不存储数据:Stream 不是数据结构,它不直接存储数据,而是按需从数据源(如集合或数组)获取数据;只能遍历一次:Stream 设计为只能遍历一次,即它们是单次使用的。一旦你启动一个终端操作来遍历流,这个流就已经被消费掉了,不能再次被遍历;惰性执行:Stream 的中间操作都是惰性化的,意味着它们会延迟执行,并且只有在必需时才会执行。实际的计算会延迟到一个终端操作触发时才开始;并行能力:Stream 支持并行处理,这使得你可以透明地将操作并行化处理而无需写任何特定的并行代码—流库会为你处理。这可以大幅提高性能,特别是在利用多核处理器的时候;可消费性(Consumable):由于信息只能遍历一次,流一旦被消费(即遍历过一次),就不可再次使用或"重启"。如果需要再次遍历同一数据源,你需要重新生成流;内部迭代:Stream API 使用内部迭代,操作由 Stream 库内部实现,而不是在用户代码中显式实现。这与使用迭代器显示迭代(外部迭代)的集合操作不同;优化操作:流的操作可以优化成更少的步骤。例如,filter 和 map 可以合并成一个单一的过程,减少迭代的次数;功能强大的流操作:Stream API 提供了丰富的方法进行复杂的数据处理,如 filter, map, reduce, collect, sorted 等。
2、Stream 流的具体组成与操作
Java Stream API 的构成主要可以分为三个部分:数据源(Source)、中间操作(Intermediate Operations)和终端操作(Terminal Operations)。这种构造允许流(Streams)在处理大量数据时提供高效率和易于管理的方式,特别适用于利用现代多核处理器的并行计算能力。下面详细解释每个组成部分:
2.1、数据源(Source)
数据源是 Java Stream API 的起点,它为流提供原始数据用于后续处理。数据源的种类可以包括集合、数组、文件以及其他各种生成流的方法,具体如下:
2.1.1、集合
集合是使用最广泛的流数据源之一,几乎所有的 Java 集合类(实现了 Collection 接口的类,如 List, Set 等)都可以通过调用 stream() 方法来创建一个流。例如:
List<String> myList = Arrays.asList("apple", "banana", "cherry");Stream<String> myStream = myList.stream();
2.1.2、数组
数组也可以轻松转换成流。Java 提供了一个便捷的方法 Arrays.stream(T[] array),允许从数组直接创建流。例如:
Integer[] myArray = { 1, 2, 3, 4, 5};Stream<Integer> arrayStream = Arrays.stream(myArray);
2.1.3、文件
文件是一个非常有用的数据源,特别是处理大量数据时。java.nio.file.Files 类的静态方法可以将文件中的数据行直接转换为流。常用的方法如 Files.lines(Path path),它返回一个由文件中各行组成的流:
Path path = Paths.get("data.txt");try (Stream<String> lines = Files.lines(path)) { lines.forEach(System.out::println);} catch (IOException e) { e.printStackTrace();}
2.1.4、其他
除了上述常见的数据源外,还可以使用诸如 Random.ints(), BufferedReader.lines() 等方法生成流。这些方法提供了一种便捷方式来创建具有特定属性的流,例如:
Random.ints():生成一个随机整数流。BufferedReader.lines():从文本读取器中逐行读取文本为流。
Random random = new Random();IntStream randomInts = random.ints(5, 10, 100); // 生成一个有5个10到100之间的随机整数的流BufferedReader reader = new BufferedReader(new FileReader("data.txt"));Stream<String> lineStream = reader.lines();lineStream.forEach(System.out::println);
以上方法展示了从不同类型的数据源创建流的方式,使得 Java Stream API 在数据处理方面极具灵活性和强大能力。通过合理利用这些数据源,开发者可以在Java中更加高效地进行数据操作和分析。
2.2、中间操作(Intermediate Operations)
中间操作是 Java Stream API 中非常关键的部分,它们对流中的元素进行处理,并且这些操作是惰性的。这意味着实际的计算并不会立即执行,直到遇到一个终端操作。下面详细介绍各种中间操作:
2.2.1、filter(Predicate<T>) 方法
filter(Predicate<T>):通过设置的条件(谓词)测试流中的每一个元素,仅保留返回 true 的元素。这是实现流的条件过滤的基础操作。例如,从一组人名中筛选出以字母 “J” 开头的名字:
List<String> names = Arrays.asList("John", "Jane", "Adam", "Jesse");Stream<String> filteredNames = names.stream() .filter(name -> name.startsWith("J"));
2.2.2、map(Function<T,R>) 方法
map(Function<T,R>):将流中的每个元素 T 映射/转换成另一个元素 R(可以是不同类型)。这个操作基于给定的函数来应用。例如,将字符串转换为其长度:
List<String> words = Arrays.asList("hello", "stream", "Java");Stream<Integer> lengths = words.stream() .map(String::length);
2.2.3、flatMap(Function<T,Stream<R>>) 方法
flatMap(Function<T,Stream<R>>):用于将流中的每个元素 T 转换成一个流,然后将所有创建的单个流中的元素合并成一个流(即 “扁平化” 流)。这个操作通常用于处理嵌套的流结构。例如,将句子分解为单词:
List<String> sentences = Arrays.asList("Java 8 Streams", "Introducing flatMap");Stream<String> wordsStream = sentences.stream() .flatMap(sentence -> Arrays.stream(sentence.split(" ")));
2.2.4、distinct() 方法
distinct():去除流中的重复元素,确保流中的所有元素都是唯一的。这通常依赖于元素的 equals() 方法来判断相等性:
Integer[] numbers = { 2, 3, 3, 2, 1, 3, 5};Stream<Integer> uniqueNumbers = Arrays.stream(numbers).distinct();
2.2.5、sorted() 方法
sorted():对流中的元素进行排序。如果流的元素类型已经实现了 Comparable 接口,那么就可以直接调用 sorted()。也可以提供一个自定义的 Comparator:
Stream<String> sortedNames = names.stream() .sorted();Stream<String> sortedByLength = names.stream() .sorted(Comparator.comparingInt(String::length));
2.2.6、peek(Consumer<T>) 方法
peek(Consumer<T>):此操作会接受一个元素并对其执行某些操作,同时返回一个包含所有原始元素的新流。peek 主要用于调试,因为它允许你查看流的元素而不会实际改变它:
List<Integer> numberList = Arrays.asList(1, 2, 3, 4, 5);List<Integer> peekedNumbers = numberList.stream() .peek(num -> System.out.println("from stream: " + num)) .collect(Collectors.toList());
每种中间操作都提供了流处理的强大功能,使得 Java 的函数式编程更加高效和直观。这些操作的惰性特性意味着它们可以组合使用,创建复杂的查询表达式,而实际的执行将延迟到需要结果的时候,通常是在终端操作发生时。这种方式不仅优化了性能,也提高了处理的灵活性。
2.3、终端操作(Terminal Operations)
终端操作是 Stream API 的最终组成部分,用于完成流的处理并生成结果。这些操作一旦执行,流就会被消费并关闭。终端操作不仅触发流的计算,也是产生实际结果的步骤。下面详细介绍各种终端操作:
2.3.1、forEach(Consumer<T>) 方法
forEach(Consumer<T>):对流中的每个元素执行一个操作,通常用于输出。这是进行副作用操作(如打印)的标准方式。例如,打印出所有开始字母为"J"的名字:
Stream<String> names = Stream.of("John", "Jane", "Jake", "Adam");names.forEach(name -> { if(name.startsWith("J")) { System.out.println(name); }});
2.3.2、collect(Collectors) 方法
collect(Collectors):是最常用的终端操作之一,用于将流转换成不同类型的结果,如 List, Set 或 Map 等。这是通过 Collector 类的各种方法实现的,如 toList(), toSet(), toMap() 等。例如,收集所有名字到一个列表:
Stream<String> names = Stream.of("John", "Jane", "Jake", "Adam");List<String> list = names.collect(Collectors.toList());
2.3.3、reduce(BinaryOperator<T>) 方法
reduce(BinaryOperator<T>):通过特定的操作来合并流中所有元素,输出一个汇总的结果。这个操作是通过一个二元函数(接受两个同类型元素,返回一个同类型元素的结果)来实现的。例如,计算一系列数的总和:
Stream<Integer> numbers = Stream.of(1, 2, 3, 4);Integer sum = numbers.reduce(0, (a, b) -> a + b); // 结果为 10
2.3.4、match(Predicate<T>) 方法
这类操作包括 anyMatch, allMatch, 和 noneMatch,用于判断流中的元素是否满足某些条件。它们返回一个布尔值:
anyMatch(Predicate<T>):流中至少有一个元素符合提供的条件时返回 true;allMatch(Predicate<T>):流中所有元素均符合提供的条件时返回 true;noneMatch(Predicate<T>):流中没有任何元素符合提供的条件时返回 true。
例如,检查数字中是否存在负值:
Stream<Integer> numbers = Stream.of(-1, -2, 3, 4);boolean hasNegative = numbers.anyMatch(n -> n < 0); // 结果为 true
2.3.5、count() 方法
count():返回流中的元素数量。这是一个简单直接的操作,常用于计数:
Stream<String> names = Stream.of("John", "Jane", "Jake", "Adam");long count = names.filter(name -> name.startsWith("J")).count(); // 计算名字以 "J" 开头的数量
2.3.6、findFirst() 方法
findFirst():返回流中的第一个元素,作为 Optional 类型返回,这样可以安全地处理空流的情况:
Stream<String> names = Stream.of("John", "Jane", "Jake", "Adam");Optional<String> first = names.filter(name -> name.startsWith("J")).findFirst();
通过这些终端操作,Java Stream API 提供了强大的工具集来在单个流上执行复杂的聚合操作,生成结果或侧效(如通过 forEach 打印)。这些操作是执行流计算的触发点,之后流将不再可用。
3、利用 Stream 的并行处理
Java Stream API 的并行处理能力是其最强大的特性之一,它可以显著提高大数据集处理的效率,特别是在多核心处理器的系统上。并行流利用 Java 的 Fork/Join 框架来分解任务和利用多线程优势,让你轻松实现多线程环境的数据处理。
3.1、并行流的创建
并行流可以通过在任何数据源上调用 .parallelStream() 方法来创建,或者通过已有流对象调用 .parallel() 方法转化成并行流。
List<String> myList = Arrays.asList("a1", "a2", "b1", "c2", "c1");// 从集合直接创建并行流Stream<String> parallelStream = myList.parallelStream();// 将现有流转换为并行流Stream<String> anotherParallelStream = myList.stream().parallel();
3.2、并行执行的工作原理
当一个流转换为并行流时,内部的迭代操作会自动分配到多个可用的核心上,不需要编写特定的多线程代码。这是通过以下步骤实现的:
分解(Decomposition):流中的任务会被分解成多个子任务,通常是采用递归方式分解,直到分解到可以顺利处理的程度;
执行(Execution):这些子任务被分配到属于 Fork/Join 池的不同线程上执行。Fork/Join 池是一种专门设计来有效处理并行工作的线程池;
合并(Combining):所有子任务的结果最后会被合并或聚合成最终结果。
3.3、使用并行流的示例
以下是使用并行流进行操作的示例,我们比较一下执行求和操作的并行与非并行方式:
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 非并行流求和long startTime = System.currentTimeMillis();int sum = integers.stream() .reduce(0, Integer::sum);long endTime = System.currentTimeMillis();System.out.println("非并行流求和结果:" + sum + ",执行时间:" + (endTime - startTime) + "ms");// 并行流求和startTime = System.currentTimeMillis();sum = integers.parallelStream() .reduce(0, Integer::sum);endTime = System.currentTimeMillis();System.out.println("并行流求和结果:" + sum + ",执行时间:" + (endTime - startTime) + "ms");
3.4、并行流的注意事项
虽然并行流可以提高执行效率,但在使用时还是需要注意以下几点:
任务分解的开销:并行处理不一定总是加快速度,尤其是在小数据集上。任务分解和线程管理本身也有开销,如果处理的数据量不够大,这种开销可能会抵消并行执行的时间节省;
线程安全和非干扰:在使用并行流时,需要确保操作具有线程安全性,并且不会干扰原始数据源,特别是当原始数据源是可变的时候;
合适的任务类型:并行流主要适合于可分解的计算密集型任务。对于涉及 I/O、同步控制或需要顺序依赖的任务,并行流可能不适合;
合适的数据结构:并行流的效率在大部分情况下依赖于数据源的类型。例如,ArrayList、数组或范围很大的数值流的分解效率高于 LinkedList 的分解。
并行流提供了一个高级工具,可以极大地提升多核环境下的数据处理能力。正确使用时,它能有效地缩短处理时间,但前提是对使用场景和数据类型有适当的选择和判断。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。