Springboot实战——黑马点评之探店及关注
Wyuf1314 2024-09-30 14:39:09 阅读 65
黑马点评——达人探店及关注推送
1 探店业务实现
1.1 探店笔记发布
1)笔记blog字段属性
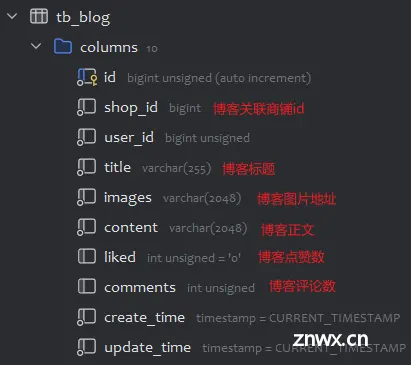
除此之外,在"搜索博客"接口实现中会涉及到向前端展示用户的部分信息,例如用户头像icon、用户昵称name、用户是否点赞该博客islike(用于对点赞按钮高亮作实现),在设计实体类时使用springboot注解<code>@TableField(exist = false)来标记这些前端展示字段并不属于数据库库表中的真实字段

2)上传博客接口实现
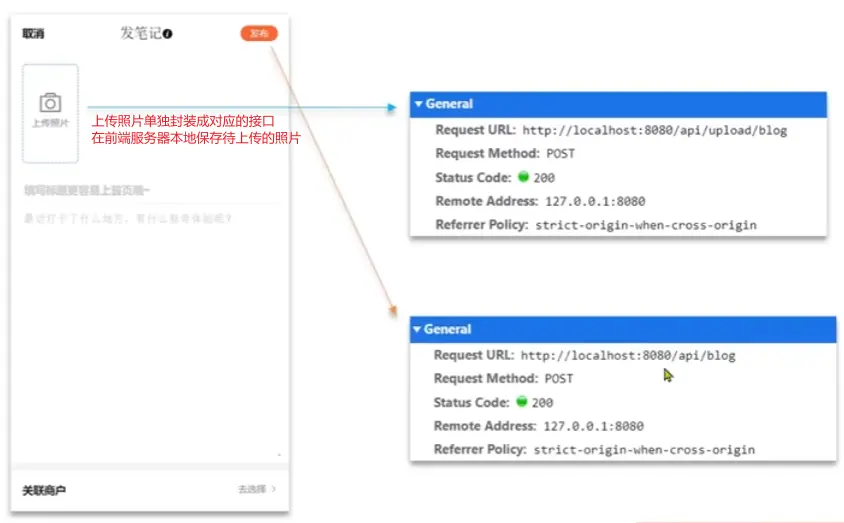
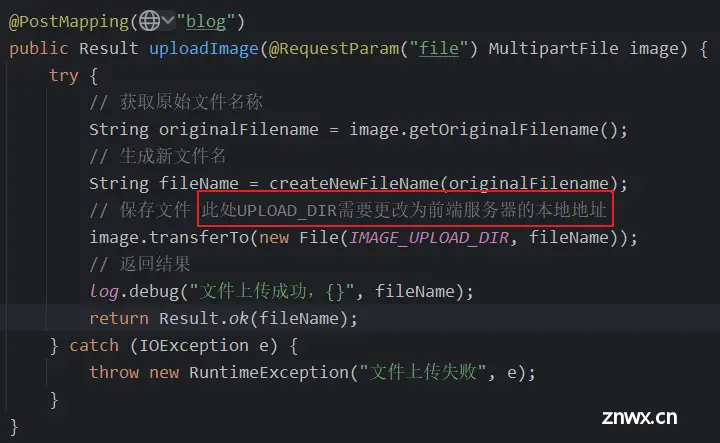
上传图片接口单独实现

3)索引博客接口实现
- <li>
采取分页对点赞靠前的博客索引(分页查找)
li>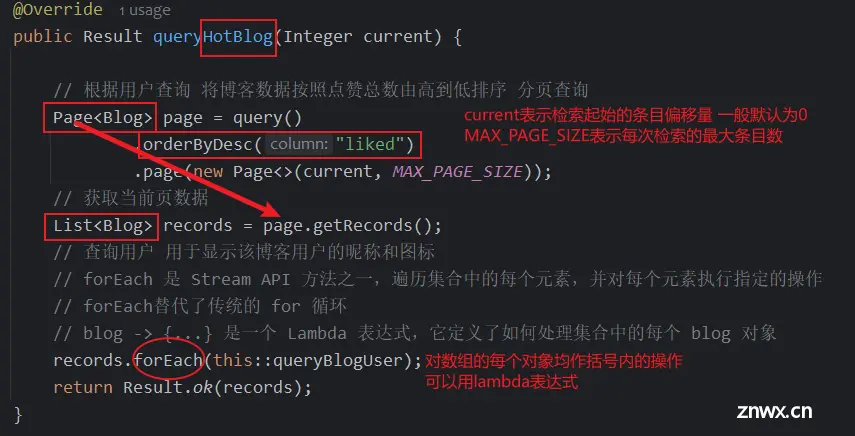
对特定博客id索引
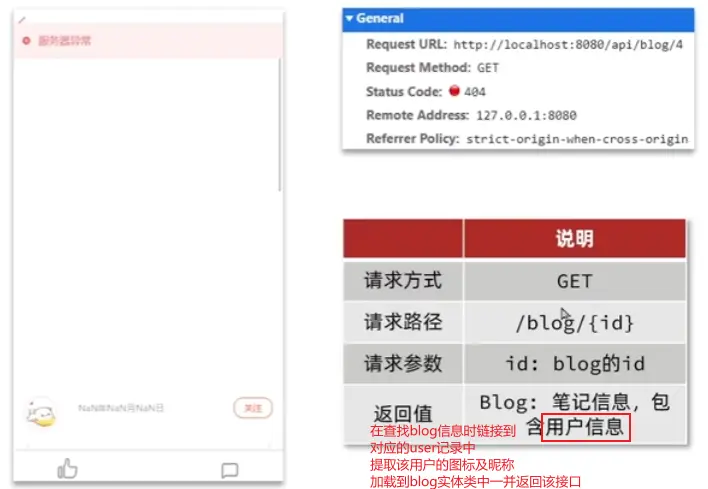
对检索到的博客发表用户作信息索引
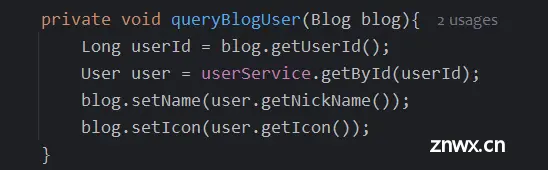
1.2 笔记点赞实现
1)最简单实现逻辑
将该博客的点赞数+1 即执行
<code>update tb_blog set liked=liked+1 where id=?
2)针对重复点赞避免逻辑完善

为了避免同一用户对同一博客重复点赞,采取Redis中的set集合(利用set集合元素的唯一性)来存储对某一博客点赞用户id的记录。
- <li>向set中存入记录值命令SADD
- 向set中检索某集合中是否存在某记录SISMEMBER
- 向set中删除某记录SREMOVE
结合以上数据结构,将点赞逻辑完善:
- 点赞前核验对应商铺Redis集合中是否存在当前登录用户id
- 如果当前登录用户存在则将点赞数+1且将用户id存入Redis中(首次/再次点赞)
- 如果不存在则点赞数-1且将用户id移除(取消点赞)
两种查询blog的业务也要做isLike判断来返回给前端,进而实现点赞按钮的高亮判断:
- 核验,如果存在则返回isLike=true,点赞按钮高亮
- 如果不存在则返回isLike=false,点赞按钮不亮
3)特定博客的点赞排行榜显示
在查看用户博客时应该在对应位置将点赞的用户信息(头像及昵称)同步显示出来,简单的实现逻辑是按用户点赞时间从早到晚来排行显示,即越早点赞的用户显示越在前排。
所以该功能对应的数据结构需要满足:
- 检索效率高
- 元素具有唯一性
- 元素可排序,并且是按加入的时间戳排序
考虑Redis中的三种集合数据结构:
- list:链表,可以按加入集合的先后排序,但元素不具有唯一性,检索时需要遍历整个链表
- set:集合,不能将元素排序,但元素具有唯一性,检索时底层使用哈希,检索速度较快
- sortedSet:可排序集合,value中除放入元素本身外,排序原则按照第二字段score大小来排序,检索速度同set
综上所述,应该选择sortedSet来实现点赞列表缓存
- 向sortedSet中插入点赞记录及时间戳score:ZADD
- 在sortedSet中查找某条点赞记录是否存在:ZSCORE,该命令本意是返回对应value的score,如果没有score也就是该value不存在,则返回null
- 从sortedSet中排序score在a-b(集合元素的下标为a-b)范围的value:ZRANGE
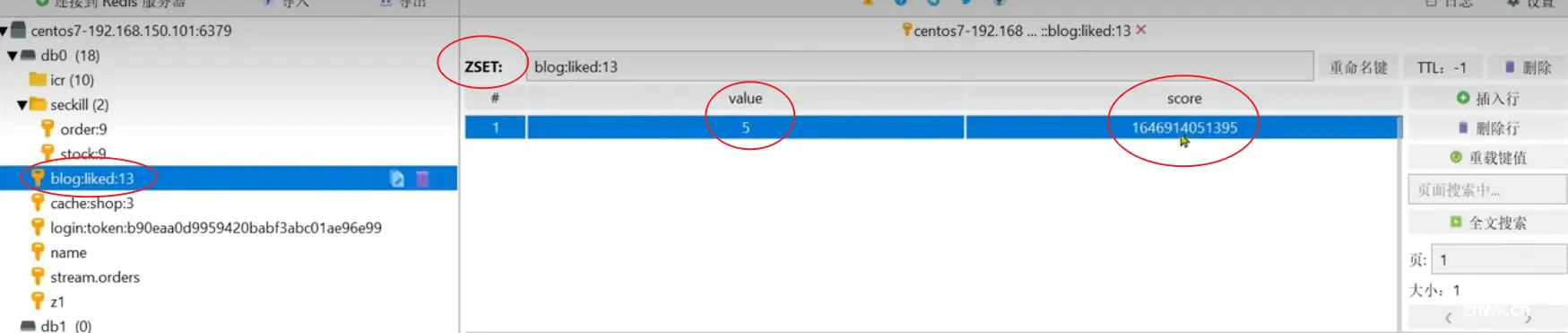
所以,将ZSet缓存逻辑替换了上述的Set缓存逻辑,也就是更改增删改的Redis命令语句即可实现优化了。
so,使用sortedSet优化后的点赞排行榜实现逻辑变成:
使用<code>range(key,begin,end)即可返回与key对应的value集合中从下标为begin到end的按时间戳排好序的记录,提取其中的userid,即可以查询到user列表返回前端了。
BUT,这么实现有个问题:
返回的用户列表为想要返回的(begin,end)列表的倒序
原因在于:从Redis中查找返回的Zset中的idsList是正确顺序的,但是当通过listByIds去数据库中查找对应用户信息时使用了
<code>select icon,nick_name from tb_user where id IN(a,b,c,...)
其中(a,b,c...)原本是正确的顺序,但查找的信息结果却是倒序的了
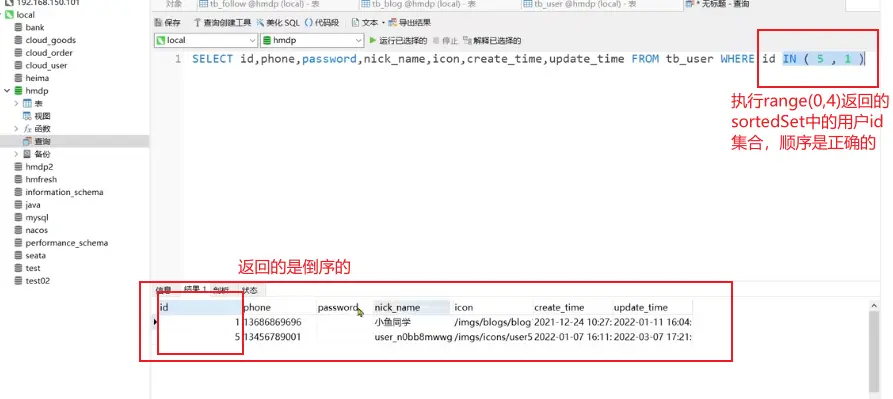
此处若将sql语句修改为
<code>select icon,nick_name from tb_user where id IN(a,b,c,...) ORDER BY FIELD(id,a,b,c,...)
即 指定返回的顺序按id指定的顺序
学习一段代码:
// 从set集合中提取出用户ids
List<Long> ids = rangeLikeSet.stream().map(Long::valueOf).collect(Collectors.toList());
// 【优化点】:解决mysql语句中in list返回的记录中默认按id的从小到大顺序的问题code>
String idStr = StrUtil.join(",",ids);
List<UserDTO> userDTOs = userService.query()
.in("id",ids).last("ORDER BY FIELD(id,"+ idStr +")").list()
.stream()
.map(user -> BeanUtil.copyProperties(user,UserDTO.class))
.collect(Collectors.toList());
2 关注及推送业务实现
关注与被关注是多-多的关系,借用中间表单来记录
2.1 建立中间表单来记录
1)用户-被关注用户表
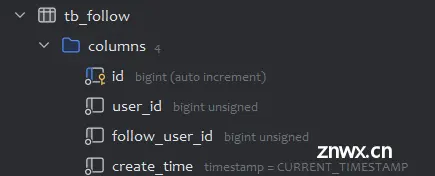
实现关注功能时,需要考虑前端服务器的关注按钮高亮判断
需要实现两个接口:
- <li>“isFollow接口”用来检索关注关系是否存在,如果存在则返回true,该接口通过返回值来判断按钮是否高亮
- “follow接口”用来实现关注或者取关,除了传入用户id外还需要传入isFollow的返回布尔值来判断是关注还是取关
2)用户间的共同关注列表
检索共同关注即检索用户关注列表中的交集,这就需要Redis缓存set数据结构来实现。
在实现关注功能时,同时将关注关系存入数据库和Redis-set中,求共同关注时使用Intersect方法来求用户Id交集
3)关注推送实现
几种推送方式对比
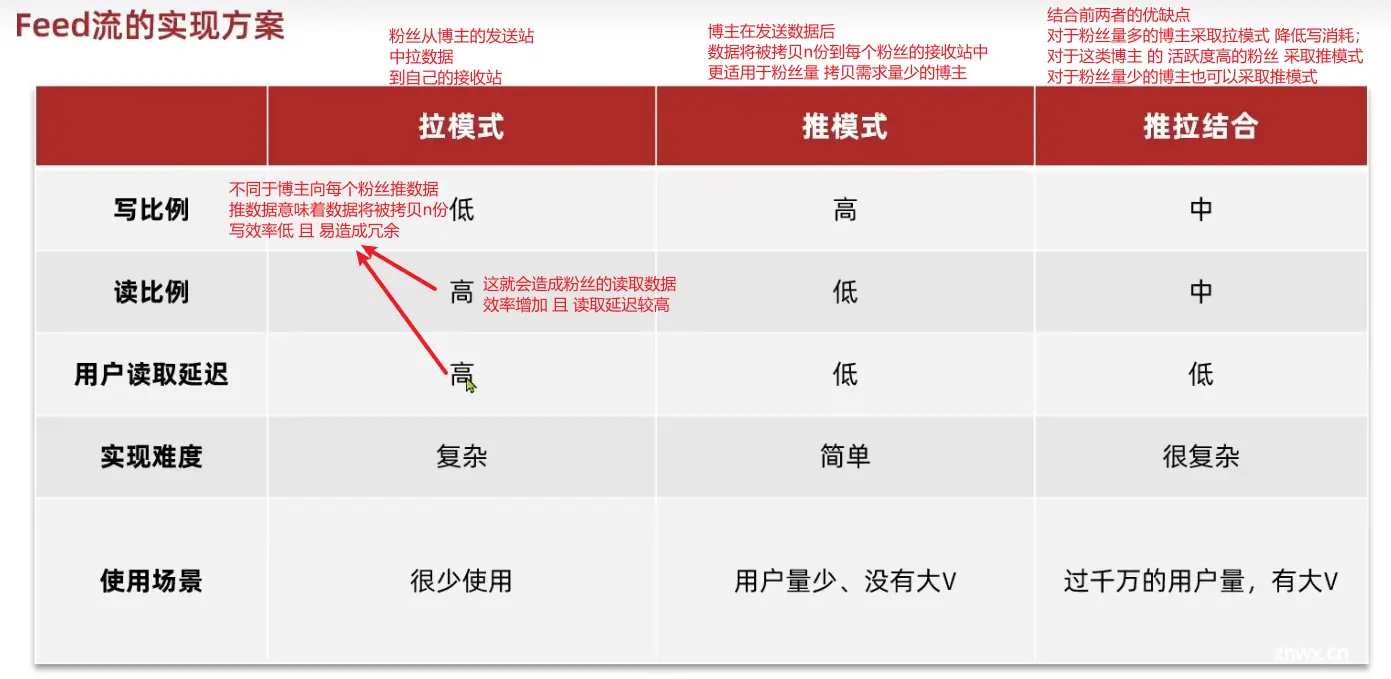
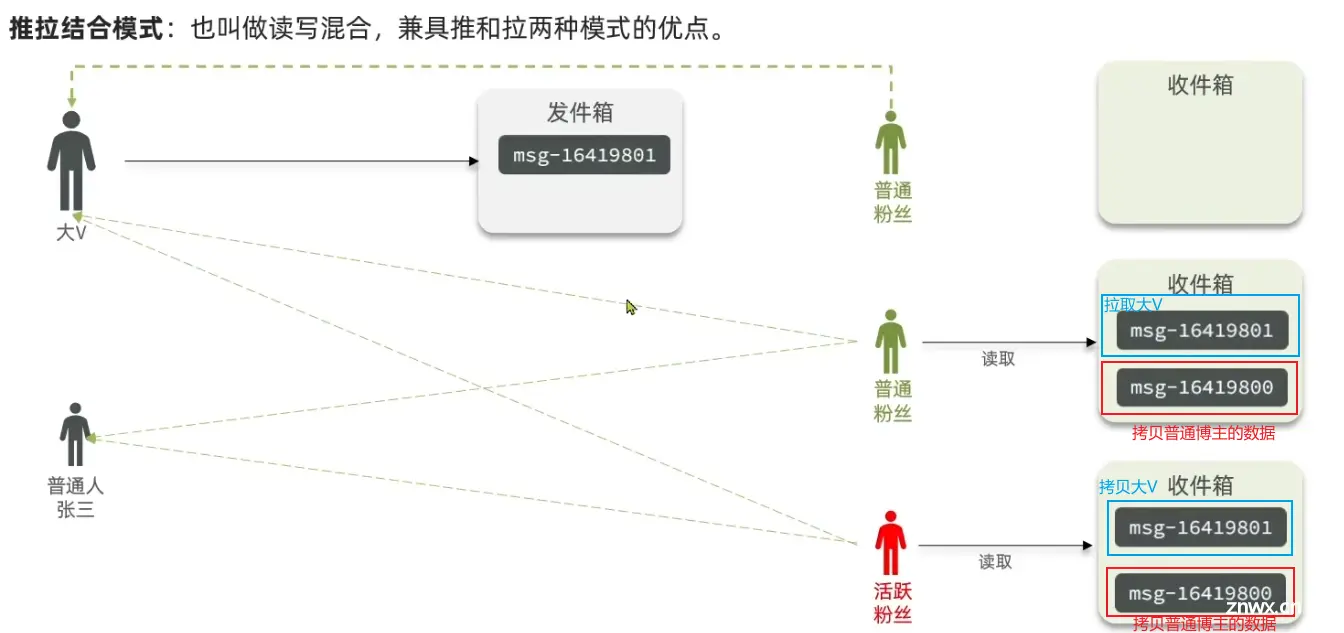
接口实现需求:
(先来实现最基本的推送功能)
- <li>推送缓存数据结构:使用Redis的sortedSet
- 推送博客:用户发布博客成功同时将博客序列号id存入所有关注该用户的粉丝sortedSet中,即可实现“推送”
- 粉丝浏览博客:粉丝从缓存中分页查询“推送”过来的博客信息
【粉丝端的博客内容应该是可以支持按时间戳排序且支持分页查询的。】
考虑两种可以实现的数据结构:链表以及排序集
链表list:头插法或尾插法均可以实现按发布时间排序,分页查询时传入current、maxsize分别计算出偏移量以及每页返回的记录数,找到起始的下标即可实现分页查询了。
问题:链表分页查询每次都要从链表起始位置计算,如果期间有新博客插入,将会计算有误,一些已被查询返回的博客将被再次查到,如下图所示
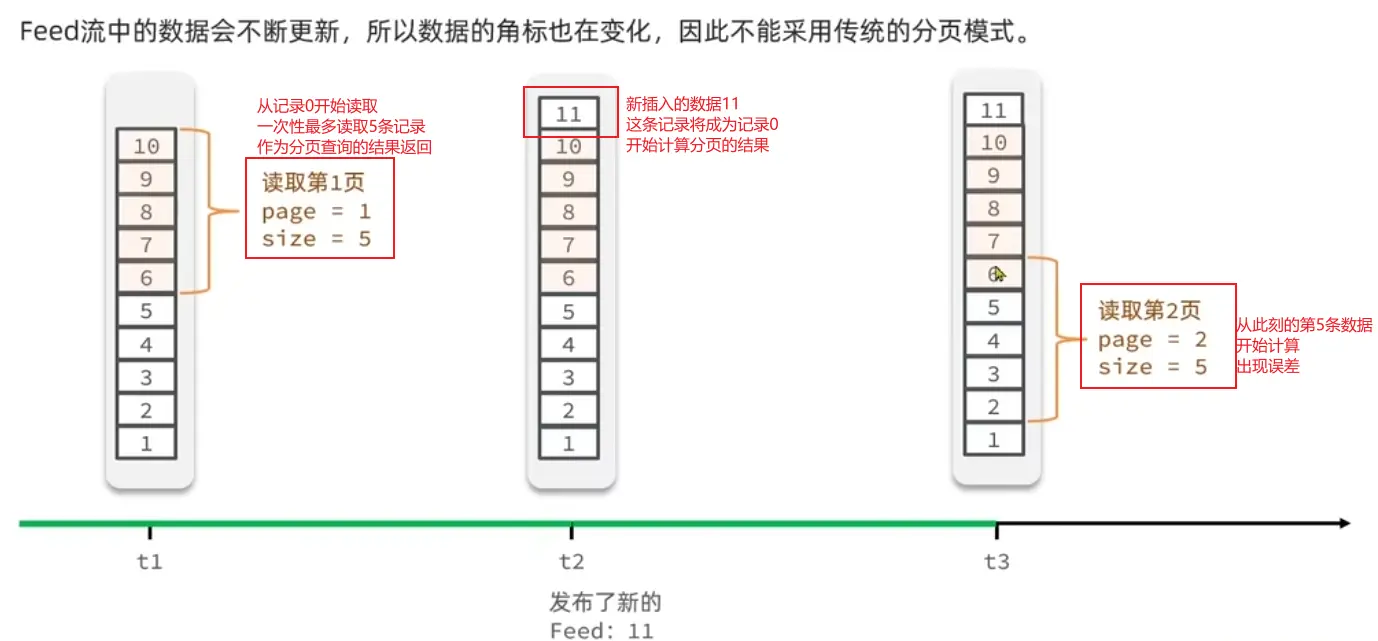
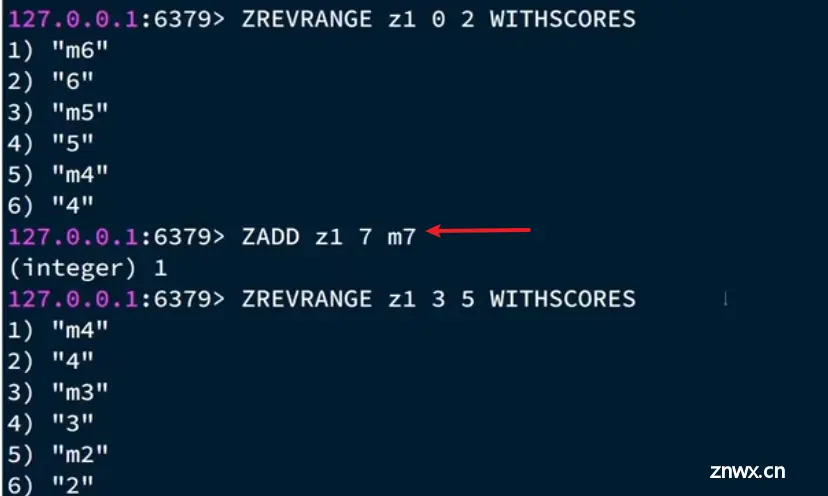
排序集sortedSet:将时间戳作为score值插入即可实现排序,分页查询类似上述的查询方法
优于链表的理由:分页查询时可以依据上一次查询到的最后一个下标,继续下一轮的分页查询,不会因为新插入的数据改变查询顺序
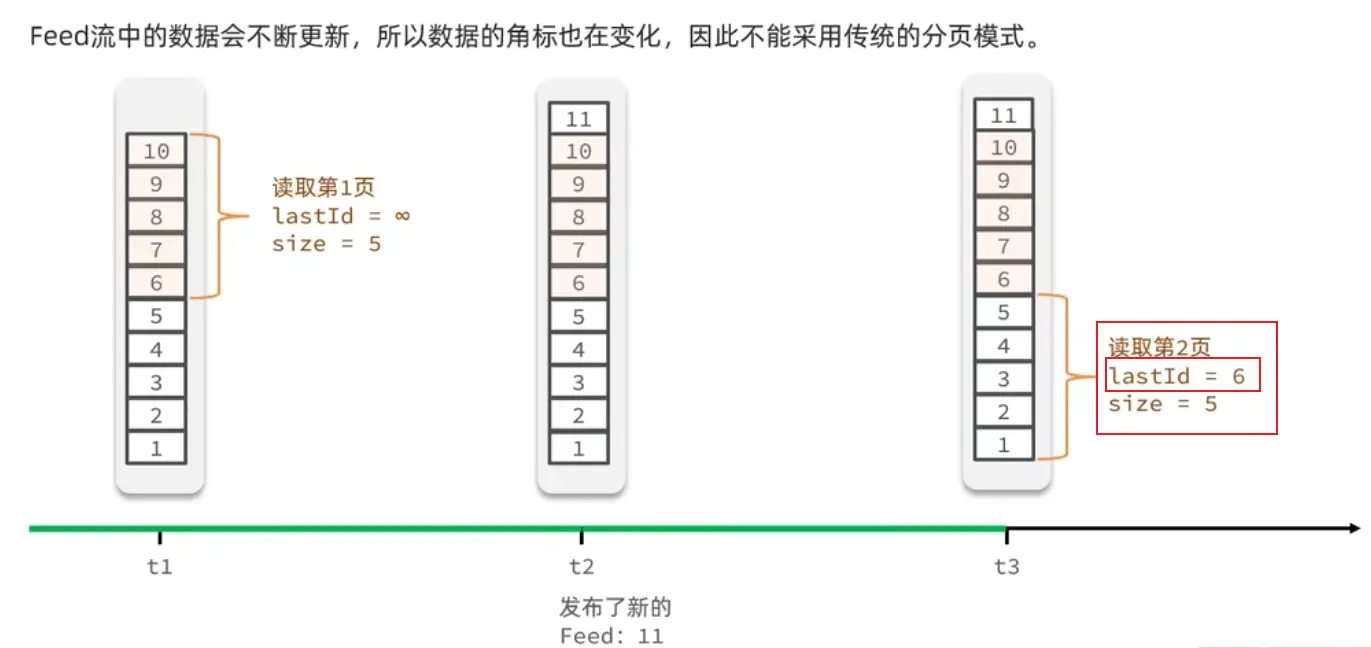

滚动分页实现:

基于上述分页查询的利弊分析得到:
sortedSet中的按score范围查询的方法<code>ZREVRANGEBYSCORE,需要两个可变参数:
1 上一次查询出来记录的最后一条score值;
2 上一次查询出来最小时间戳score值相同的记录总数offSet
这两个指标可以由每次分页查询结果返回给前端
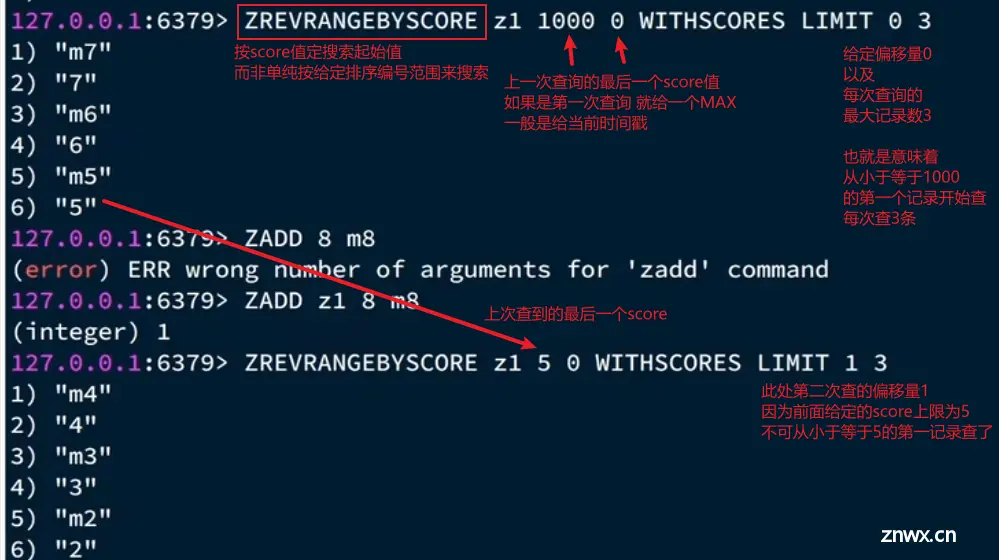
使用到sortedSet中的reversescorerange,该方法接收五个参数:
- <li>关键字key
- score的最大范围maxId,如果按score从大到小排列顺序返回的话,该参数意味着 此次查询从小于等于上一次查询的最小score 的记录开始查询,即maxId从上一次查询结果中返回
- score的最小范围minId,默认给一个最小边界值,如果是时间戳的表示,就给score默认为0
- 查询偏移量offSet,意思是从maxId往下查的记录应该从小于等于maxId的第几个记录开始查,尤其是当上一次查询的记录中有多个score相同的最小记录,就要统计该记录的数目,以防下一次查询时多次查到该值
- 查询记录数count,每次查询出的最大记录数目,一般是给定的常量
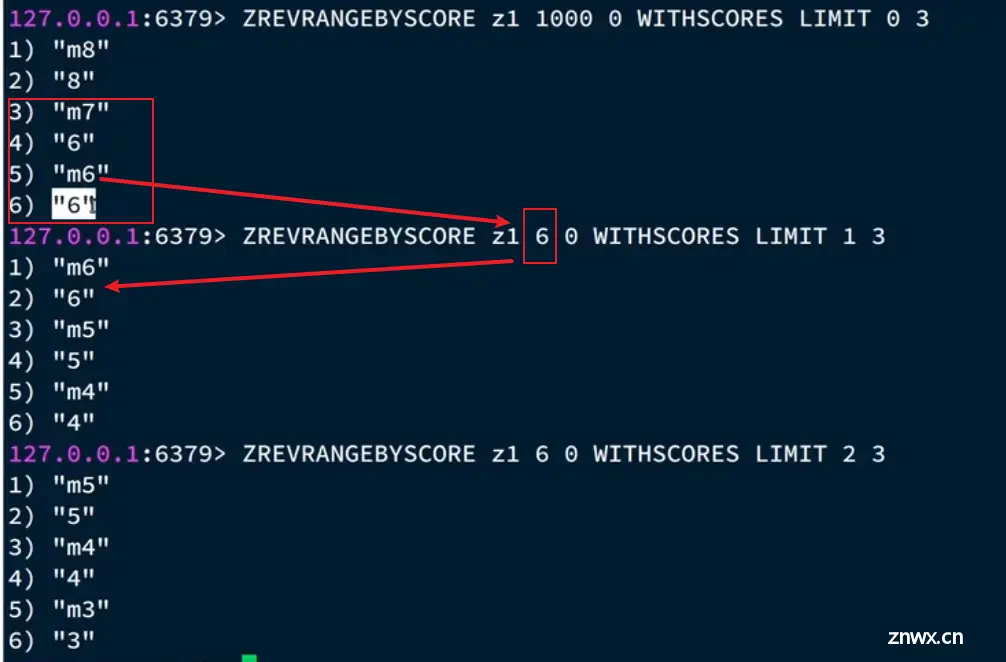
综上所述,每次查询返回给前端用于下一次查询的参数:
1)maxId
2)offSet
实现接口需要明确以下几个问题:
Q:分页查询是从哪里查?
A:从博主向粉丝的推送序列sortedSet中查,sortedSet的关键字是粉丝用户id,内容是(博客标识id,发布时间戳score),分页查询出的结果是由内容构成的元组序列。
Q:查询的结果要怎么向需要返回的结果转换
A:该接口返回的结果是博客本身、minTime、offSet,这三项内容可以封装到一个通用实体类ScrollResult中;博客序列由博客标识id到数据库中批量查找返回(前提是要提取出元组序列中的标识id);minTime直接在遍历元组序列时迭代赋值score即可获得;offSet初始值赋为1,遍历到score=minTime时则加1。
注意两点:
- 在获得待返回博客序列时注意将用户信息以及点赞判断两个方法加入。
- 从数据库中取出的Id序列为(a,b,c,...)的博客顺序有误,需要手动加ORDER BY(a,b,c,...)来限制顺序
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。