AI核实身份--金融场景凭证--篡改检测--Datawhale组队学习
神迹小卒 2024-10-22 16:31:02 阅读 70
AI核实身份–金融场景凭证–篡改检测–Datawhale
10月10日:TASK1:BaseLine
1.比赛任务
在本任务中,要求参赛者设计算法,找出凭证图像中的被篡改的区域[1]。
2.环境
2.1魔搭Notebook[2]
交互式建模 PAI-DSW
PAI-DSW是为算法开发者量身打造的云端深度学习开发环境,
内置JupyterLab、WebIDE及Terminal,
无需任何运维配置即可编写、调试及运行Python代码。
8核 32GB 显存24G
预装 ModelScope Library
预装镜像 ubuntu22.04-cuda12.1.0-py310-torch2.3.0-1.18.0
2.2 ModelScope Library[4]
ModelScope Library 是由阿里巴巴达摩院(DAMO Academy)推出的一个开源的 AI 模型库平台,旨在为开发者提供一个集成多种人工智能模型的平台。它允许用户访问和使用各种预训练的模型,涵盖了计算机视觉、自然语言处理、语音处理等多个领域。
主要特点包括:
模型集成:ModelScope 提供了各种预训练模型,这些模型可以直接用于推理或进一步微调,以适应特定的应用需求。多领域支持:ModelScope 支持多种 AI 领域,包括但不限于:
计算机视觉(如图像分类、目标检测)自然语言处理(如文本生成、机器翻译、问答系统)语音处理(如语音识别、语音合成) 用户友好:提供了简单的 API,便于开发者将这些模型集成到自己的应用中。开源:ModelScope 是一个开源项目,允许开发者贡献自己的模型和优化现有模型。基于云的推理:除了本地推理,ModelScope 还支持基于云的推理服务,使得开发者可以在云端利用大规模计算资源来处理数据。
3.数据集
训练集数据总量为100w
提供篡改后的凭证图像及其对应的篡改位置标注
标注文件以csv格式给出
csv文件中包括两列
内容示例如下:
Path Polygon
9/9082eccbddd7077bc8288bdd7773d464.jpg [[[143, 359], [432, 359], [437, 423], [141, 427]]]
测试集分为A榜和B榜
分别包含10w测试数据
测试集中数据格式与训练集中一致
但不包含标注文件
4. 理解Baseline
4.1环境准备
<code>!apt update > /dev/null;
!apt install aria2 git-lfs axel -y > /dev/null;
!pip install ultralytics==8.2.0 numpy pandas opencv-python Pillow matplotlib > /dev/null
!axel -n 12 -a http://mirror.coggle.club/seg_risky_testing_data.zip;
!unzip -q seg_risky_testing_data.zip;
!axel -n 12 -a http://mirror.coggle.club/seg_risky_training_data_00.zip;
!unzip -q seg_risky_training_data_00.zip;
数据集很大,推荐拆开来跑
更新包管理器apt,并且忽略输出
安装aria2下载器,git大文件下载,axel下载器,并默认yes,忽略输出
安装YOLO8.2版本,多维数组和矩阵操作库,数据分析和数据操作的库,CV库,图像处理库,数据可视化的库
12个并行下载测试数据,会断点续传的,等它下完就好了
解压,-q 静默解压,不输出详细信息
12个并行下载训练数据
解压
4.2 处理图像数据及其对应的注释信息
import os, shutil
import cv2
import glob
import json
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
training_anno = pd.read_csv('http://mirror.coggle.club/seg_risky_training_anno.csv')
train_jpgs = [x.replace('./', '') for x in glob.glob('./0/*.jpg')]
os操作系统级别的功能,shutil文件功能
cv2:OpenCV 的 Python 接口
glob查找符合特定模式的文件路径
json:用于将注释数据中的多边形(可能用于分割或目标检测)从字符串形式转换为 Python 的数据结构(如字典或列表)
pandas :它能够方便地处理 CSV 文件和结构化数据
使用 pandas 读取一个 CSV 文件,该文件位于远程服务器,存储了训练数据的注释信息
使用 glob 获取当前目录 ./0/ 下所有 .jpg 格式的文件,去除文件路径中的 ./ 前缀,只保留文件名。
Example:
./0/image1.jpg
./0/image2.jpg
./0/image3.jpg
从
[‘./0/image1.jpg’, ‘./0/image2.jpg’, ‘./0/image3.jpg’]
变为
[‘0/image1.jpg’, ‘0/image2.jpg’, ‘0/image3.jpg’]
过滤数据。
它将 training_anno 数据中的 Path 列
与 train_jpgs(即本地图像文件名)进行匹配,
training_anno = training_anno[training_anno['Path'].isin(train_jpgs)]
保留注释文件中与本地实际存在的图像文件对应的行
training_anno['Polygons'] = training_anno['Polygons'].apply(json.loads)
字符串转为列表
‘[[[143, 359], [432, 359], [437, 423], [141, 427]]]’
[
[
[143, 359], # 第一个顶点
[432, 359], # 第二个顶点
[437, 423], # 第三个顶点
[141, 427] # 第四个顶点
]
]
training_anno.head()
展示 training_anno DataFrame 的前五行数据
training_anno.shape
返回数据框的维度(行数和列数)
np.array(training_anno['Polygons'].iloc[4], dtype=np.int32)
将第四行转化为数组
array([[[143, 359],
[432, 359],
[437, 423],
[141, 427]]], dtype=int32)
4.3图像上绘制注释中提供的多边形轮廓
idx = 23
img = cv2.imread(training_anno['Path'].iloc[idx])
选择第 23 行的图像
OpenCV 读取第 23 行 Path 列中对应的图像路径
如 ‘9/9082eccbddd7077bc8288bdd7773d464.jpg’
plt.figure(figsize=(12, 6))
plt.subplot(121)
plt.imshow(img)
plt.title("Original Image")
plt.axis('off')
设置 Matplotlib 图像的画布大小,宽为 12 英寸,高为 6 英寸
创建一个 1 行 2 列的子图,并选择第一个子图(第 1 列)
显示图像 img
为第一个子图设置标题为
关闭坐标轴
plt.subplot(122)
img = cv2.imread(training_anno['Path'].iloc[idx])
polygon_coords = np.array(training_anno['Polygons'].iloc[idx], dtype=np.int32)
选择第二个子图(第 2 列)
再次读取第 23 行的图像(因为图像数据会在绘制时修改,所以重新加载)
读取第 23 行 Polygons 列中的多边形数据并将其转换为 NumPy 数组
for polygon_coord in polygon_coords:
cv2.polylines(img, np.expand_dims(polygon_coord, 0), isClosed=True, color=(0, 255, 0), thickness=2)
img= cv2.fillPoly(img, np.expand_dims(polygon_coord, 0), color=(255, 0, 0, 0.5))
遍历 polygon_coords 中的每个多边形坐标(在当前例子中只有一个多边形)
在图像 img 上绘制多边形轮廓,
将二维的多边形坐标转为三维形状,这是 cv2.polylines 所需的格式。
多边形是闭合的
使用绿色绘制轮廓
设置多边形轮廓线的宽度为 2 个像素
填充多边形内部
填充颜色为红色,0.5 表示透明度
plt.imshow(img)
plt.title("Image with Polygons")
plt.axis('off')
右侧子图中显示绘制了多边形的图像
设置标题为 “Image with Polygons”
关闭坐标轴
4.4基本信息
training_anno.info()
显示 DataFrame 的基本信息。它会输出关于 DataFrame 的列数、每列的数据类型、每列包含的非空值数量以及 DataFrame 总体占用的内存
example
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100 entries, 0 to 99
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Path 100 non-null object
1 Polygons 100 non-null object
dtypes: object(2)
memory usage: 1.7+ KB
4.5删除目录,创建新的目录结构
if os.path.exists('yolo_seg_dataset'):
shutil.rmtree('yolo_seg_dataset')
os.makedirs('yolo_seg_dataset/train')
os.makedirs('yolo_seg_dataset/valid')
删除整个目录以及其所有子文件和子目录
创建新的目录结构
yolo_seg_dataset/
│
├── train/ # 用于存放训练集的图像和标签文件
│
└── valid/ # 用于存放验证集的图像和标签文件
4.6 归一化处理
def normalize_polygon(polygon, img_width, img_height):
return [(x / img_width, y / img_height) for x, y in polygon]
将图像数据和其对应的多边形标注进行归一化处理,并按照某种格式保存到一个新的数据集中
函数接受一个多边形的坐标列表(polygon),并将这些坐标根据图像的宽度(img_width)和高度(img_height)进行归一化处理
归一化的目的是将绝对像素坐标转换为相对坐标,使得每个坐标值介于 0 和 1 之间
分别将 x 和 y 坐标值转化为相对宽度和高度的比例。
最终,返回一个新的列表,其中每个坐标点的 x 和 y 值都在 0 到 1 之间
for row in training_anno.iloc[:10000].iterrows():
使用 pandas 的 iterrows() 方法遍历 training_anno 数据框中的前 10000 行,
每次循环会返回一个索引和对应的行数据(即 row)。
row[1]:指每一行的具体数据,其中 Path 是图像路径,Polygons 是多边形的坐标数据
shutil.copy(row[1].Path, 'yolo_seg_dataset/train')
这行代码将每一行中的 Path对应的图像文件复制到 ‘yolo_seg_dataset/train’ 目录下
img = cv2.imread(row[1].Path)
img_height, img_width = img.shape[:2]
使用 OpenCV 读取图像文件,将图像数据存储在 img 变量中
获取图像的高度和宽度,img.shape 返回的是 (高度, 宽度, 通道数),
[:2] 则只取前两个值,即图像的尺寸。
txt_filename = os.path.join('yolo_seg_dataset/train/' + row[1].Path.split('/')[-1][:-4] + '.txt')
with open(txt_filename, 'w') as up:
从图像路径中提取图像文件名,并去掉文件扩展名
例如,如果图像路径是 ‘9/9082eccbddd7077bc8288bdd7773d464.jpg’,提取到的文件名为 ‘9082eccbddd7077bc8288bdd7773d464’。
拼接生成一个对应的标签文件名,
文件路径形如 yolo_seg_dataset/train/9082eccbddd7077bc8288bdd7773d464.txt
open(txt_filename, ‘w’):以写模式打开标签文件,后续将归一化后的多边形数据写入该文件。
for polygon in row[1].Polygons:
normalized_polygon = normalize_polygon(polygon, img_width, img_height)
normalized_coords = ' '.join([f'{ coord[0]:.3f} { coord[1]:.3f}' for coord in normalized_polygon])
up.write(f'0 { normalized_coords}\n')
遍历每一行中的 Polygons 列
调用前面定义的 normalize_polygon() 函数,将多边形的绝对坐标归一化到 [0, 1] 范围。
例如,假设多边形的坐标是 [[143, 359], [432, 359], [437, 423], [141, 427]],
归一化后,假设图像尺寸为 800x600,
则结果类似于 [(0.179, 0.598), (0.540, 0.598), (0.546, 0.705), (0.176, 0.712)]。
这一行将归一化后的坐标转化为字符串,
每个坐标 x 和 y 保留三位小数,
并用空格分隔。
例如,[(0.179, 0.598), (0.540, 0.598)]
转换为字符串 ‘0.179 0.598 0.540 0.598’。
将多边形的归一化坐标写入标签文件,
每行的格式是 类别标签 归一化坐标。
这里的 0 是类别标签,
表示这是第 0 类目标
例如,写入的内容可能是:0 0.179 0.598 0.540 0.598 0.546 0.705 0.176 0.712
4.7 验证集
for row in training_anno.iloc[10000:10150].iterrows():
shutil.copy(row[1].Path, 'yolo_seg_dataset/valid')
img = cv2.imread(row[1].Path)
img_height, img_width = img.shape[:2]
txt_filename = os.path.join('yolo_seg_dataset/valid/' + row[1].Path.split('/')[-1][:-4] + '.txt')
with open(txt_filename, 'w') as up:
for polygon in row[1].Polygons:
normalized_polygon = normalize_polygon(polygon, img_width, img_height)
normalized_coords = ' '.join([f'{ coord[0]:.3f} { coord[1]:.3f}' for coord in normalized_polygon])
up.write(f'0 { normalized_coords}\n')
将 training_anno 数据框的
第 10000 行到第 10150 行的数据
处理成一个验证集(validation set)。
它将图像文件复制到指定的目录,
并将每个图像的多边形标注归一化,
保存为与图像同名的 .txt 文件。
这些 .txt 文件格式与 YOLO目标检测模型的标签格式类似。
4.8 配置文件
with open('yolo_seg_dataset/data.yaml', 'w') as up:
data_root = os.path.abspath('yolo_seg_dataset/')
up.write(f'''
path: { data_root}
train: train
val: valid
names:
0: alter
''')
定义训练和验证数据集的路径以及类别名称
以写模式打开或创建 data.yaml 文件
up 是文件对象
获取数据集的绝对路径
将指定的字符串内容写入 data.yaml 文件。使用三重引号(‘’')可以方便地写入多行字符串
f:格式化字符串,{data_root} 会被替换为之前定义的 data_root 变量的值(即 yolo_seg_dataset/ 的绝对路径)。
/home/user/project/
│
├── yolo_seg_dataset/
│ ├── train/
│ ├── valid/
│ └── data.yaml
path: /home/user/project/yolo_seg_dataset/
train: train
val: valid
names:
0: alter
数据集根目录为 /home/user/project/yolo_seg_dataset/。
训练数据位于 yolo_seg_dataset/train/。
验证数据位于 yolo_seg_dataset/valid/。
类别 0 的名称是 alter。
4.9下载 字体文件和 YOLOv8 的预训练模型
!mkdir -p /root/.config/Ultralytics/
!wget http://mirror.coggle.club/yolo/Arial.ttf -O /root/.config/Ultralytics/Arial.ttf
!wget http://mirror.coggle.club/yolo/yolov8n-v8.2.0.pt -O yolov8n.pt
!wget http://mirror.coggle.club/yolo/yolov8n-seg-v8.2.0.pt -O yolov8n-seg.pt
创建一个名为 /root/.config/Ultralytics/ 的目录。
如果该目录已经存在,-p 选项会确保不抛出错误并跳过创建
配置文件目录,通常用于存放 YOLO 模型的相关配置文件或资源(如字体文件)
字体文件 Arial.ttf
YOLOv8n(YOLOv8 nano 版本)的预训练模型
YOLOv8n 是 YOLOv8 的一个轻量化版本(nano)
YOLOv8n-seg(YOLOv8 nano 分割版)的预训练模型文件的下载链接。
可以使用它来执行图像分割任务,例如在图像上对特定区域进行分割
4.10 训练 YOLOv8 模型
from ultralytics import YOLO
model = YOLO("./yolov8n-seg.pt")
results = model.train(data="./yolo_seg_dataset/data.yaml", epochs=10, imgsz=640)code>
导入 YOLO 库
加载本地的 YOLOv8n-seg 预训练模型文件 yolov8n-seg.pt
调用 YOLO 模型的 train 方法在自定义数据集上进行训练
设置训练的轮数为 10 轮。这意味着数据集将被迭代 10 次进行训练
在每一轮中,模型会对整个训练集进行一次学习,经过 10 轮后模型将完成训练
设置训练时输入图像的尺寸为 640x640。
YOLO 模型通常会将输入图像调整为正方形尺寸,
以便模型进行训练。
640 表示图像的宽和高都会调整为 640 像素。
4.11 处理测试图像
from ultralytics import YOLO
import glob
from tqdm import tqdm
model = YOLO("./runs/segment/train/weights/best.pt")
test_imgs = glob.glob('./test_set_A_rename/*/*')
导入 YOLO 类
导入 glob 和 tqdm
查找符合特定模式的文件路径
处理大量数据时显示一个动态的进度条,帮助你了解任务的执行进度
加载了一个已经训练好的 YOLOv8 模型
训练过程中生成的最优权重文件。
通常,YOLO 模型训练完成后会保存模型权重到 runs/segment/train/weights/ 目录,
best.pt 是训练过程中性能最好的模型。
使用 glob 查找 test_set_A_rename 目录下的所有测试图像
4.12获取每张图像的分割结果
Polygon = []
for path in tqdm(test_imgs[:10000]):
results = model(path, verbose=False)
result = results[0]
if result.masks is None:
Polygon.append([])
else:
Polygon.append([mask.astype(int).tolist() for mask in result.masks.xy])
初始化 Polygon 列表
存储每张图像的分割多边形坐标
在处理每张图像后,模型的分割结果(如果有)将被转换为整数坐标并添加到该列表中
遍历前 10000 张测试图像
对每张图像进行推理
path 是当前测试图像的路径。
verbose=False:禁止输出详细日志信息。
results 是模型的输出,通常包含模型对该图像的所有预测结果,包括分割掩码、检测框等。
获取第一个推理结果
检查是否存在分割掩码
result.masks is None:检查该图像是否有分割结果。
如果 masks 是 None,说明模型没有检测到任何目标。
Polygon.append([]):如果没有分割掩码,
将一个空列表 [] 添加到 Polygon 中,
表示该图像没有分割结果。
处理分割掩码
result.masks.xy 是分割掩码的多边形坐标,
表示检测到的目标的边界。
result.masks 中的 xy 通常是二维浮点坐标列表,
表示每个多边形的顶点
将每个掩码的多边形坐标从浮点数转换为整数,并转化为 Python 列表。
将处理后的多边形坐标添加到 Polygon 列表中,表示该图像的分割结果。
4.13 创建提交文件
import pandas as pd
submit = pd.DataFrame({
'Path': [x.split('/')[-1] for x in test_imgs[:10000]],
'Polygon': Polygon
})
submit = pd.merge(submit, pd.DataFrame({ 'Path': [x.split('/')[-1] for x in test_imgs[:]]}), on='Path', how='right')code>
submit = submit.fillna('[]')
submit.to_csv('track2_submit.csv', index=None)
创建一个提交文件 track2_submit.csv,
该文件包含图像的文件名和对应的多边形分割结果。
它从 test_imgs 列表中获取图像路径,
并结合之前生成的 Polygon 列表,
最终将数据导出为 CSV 文件。
假设 test_imgs[:10000] 包含以下 3 张图像路径
['./test_set_A_rename/folder1/image1.jpg',
'./test_set_A_rename/folder1/image2.jpg',
'./test_set_A_rename/folder2/image3.jpg']
Polygon 列表
[
[[[100, 200], [150, 200], [150, 250], [100, 250]]], # 对应 image1.jpg 的分割结果
[], # 对应 image2.jpg,没有分割结果
[[[200, 300], [250, 300], [250, 350], [200, 350]]] # 对应 image3.jpg 的分割结果
]
submit DataFrame 如下
Path Polygon
0 image1.jpg [[[100, 200], [150, 200], [150, 250], [100, ...
1 image2.jpg []
2 image3.jpg [[[200, 300], [250, 300], [250, 350], [200, ...
合并 DataFrame,确保包含所有图像
将两个 DataFrame 合并,
确保输出的 submit 包含所有测试图像文件名,
即使某些图像没有对应的多边形结果
按 Path 列进行合并。
执行右连接
右连接的作用:假设有些图像(超过前 10000 张)没有出现在原 submit DataFrame 中,这一步将确保所有测试集中的图像都在最终结果中,哪怕它们没有对应的分割结果
填充空值
fillna(‘[]’):将 DataFrame 中的所有 NaN 值(即没有对应分割结果的图像)
替换为空列表 ‘[]’,
以便在输出中保持格式一致。
保存为 CSV 文件
输出 track2_submit.csv 文件
5.改进
5.1.增加训练集
def normalize_polygon(polygon, img_width, img_height):
return [(x / img_width, y / img_height) for x, y in polygon]
for row in training_anno.iloc[:10000].iterrows():
shutil.copy(row[1].Path, 'yolo_seg_dataset/train')
img = cv2.imread(row[1].Path)
img_height, img_width = img.shape[:2]
txt_filename = os.path.join('yolo_seg_dataset/train/' + row[1].Path.split('/')[-1][:-4] + '.txt')
with open(txt_filename, 'w') as up:
for polygon in row[1].Polygons:
normalized_polygon = normalize_polygon(polygon, img_width, img_height)
normalized_coords = ' '.join([f'{ coord[0]:.3f} { coord[1]:.3f}' for coord in normalized_polygon])
up.write(f'0 { normalized_coords}\n')
4.6归一化处理时候,只用了10000条数据进行训练,实在是太少,
所以取消限制,使用全部训练数据进行训练
def normalize_polygon(polygon, img_width, img_height):
return [(x / img_width, y / img_height) for x, y in polygon]
for row in training_anno.iterrows(): # 移除了 iloc[:10000]
shutil.copy(row[1].Path, 'yolo_seg_dataset/train')
img = cv2.imread(row[1].Path)
img_height, img_width = img.shape[:2]
txt_filename = os.path.join('yolo_seg_dataset/train/' + row[1].Path.split('/')[-1][:-4] + '.txt')
with open(txt_filename, 'w') as up:
for polygon in row[1].Polygons:
normalized_polygon = normalize_polygon(polygon, img_width, img_height)
normalized_coords = ' '.join([f'{ coord[0]:.3f} { coord[1]:.3f}' for coord in normalized_polygon])
up.write(f'0 { normalized_coords}\n')
5.2 调大批量大小
批量大小(batch size),即每次训练迭代中同时处理的训练样本数量。
batch调大点
results = model.train(data="./yolo_seg_dataset/data.yaml", epochs=50, imgsz=640, batch=128)code>
5.3 调大训练次数
从10变为epochs=40
from ultralytics import YOLO
model = YOLO("./yolov8n-seg.pt")
results = model.train(data="./yolo_seg_dataset/data.yaml", epochs=40, imgsz=640,batch=128)code>
5.4调整训练集
用模型预测所有数据
Polygon = []
for path in tqdm(test_imgs):
results = model(path, verbose=False)
result = results[0]
if result.masks is None:
Polygon.append([])
else:
Polygon.append([mask.astype(int).tolist() for mask in result.masks.xy])
6.解决问题
6.1数据集太大,LINUX下载失败
使用 PowerShell 下载文件:
Windows 自带 PowerShell,可以使用 Invoke-WebRequest 命令进行文件下载。打开 PowerShell,然后运行以下命令:
powershell
Invoke-WebRequest -Uri "http://mirror.coggle.club/seg_risky_testing_data.zip" -OutFile "seg_risky_testing_data.zip"
这会把数据集下载到当前目录下。
或者
分开不同的行进行下载
6.2 debug:第二步
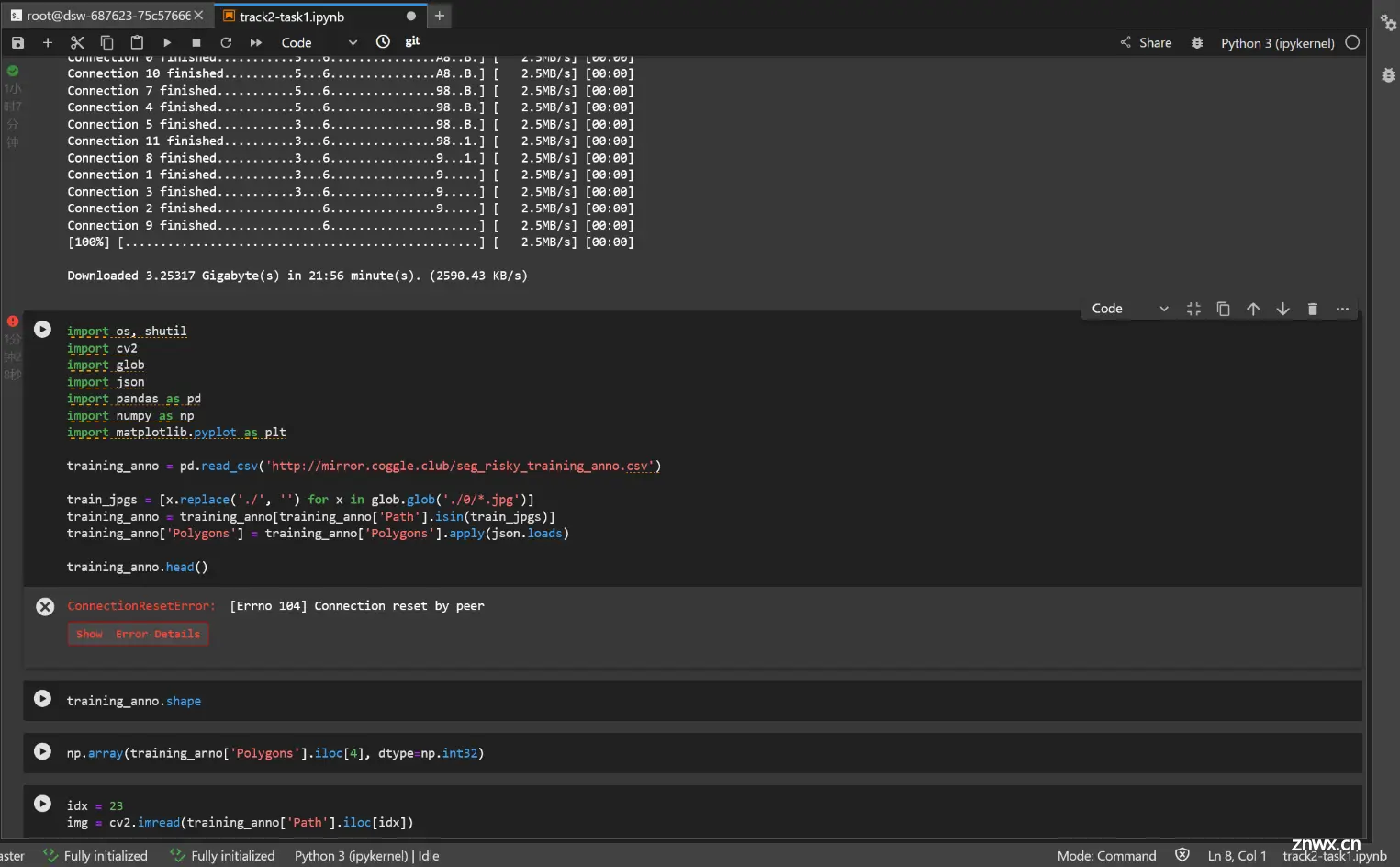
这个bug我知道,你先把http://mirror.coggle.club/seg_risky_traininganno.csv’这个w文件下下来,
然后training_anno = pd.read_csv(‘./seg_risky_traininganno.csv’)
http://mirror.coggle.club/seg_risky_training_anno.csv
<code># training_anno = pd.read_csv('http://mirror.coggle.club/seg_risky_training_anno.csv')
training_anno = pd.read_csv('./seg_risky_training_anno.csv')
6.3 训练数据集中某些标注的坐标不符合要求,坐标超出了规范化范围[0, 1]
不用理
6.4 notebook崩溃
导致文件全部清空
改为本地跑[5]
6.5 DataLoader 线程由于内存不足或资源分配问题崩溃
{
“name”: “”,
“message”: “”,
“stack”: “在当前单元格或上一个单元格中执行代码时 Kernel 崩溃。
请查看单元格中的代码,以确定故障的可能原因。
单击此处了解详细信息。
有关更多详细信息,请查看 Jupyter log。”
}
内存不足问题
崩溃的主要原因是 DataLoader 线程被系统强制终止,这通常是因为系统内存或 GPU 内存不足,尤其是在使用大量数据时(例如 batch size 较大时)。
解决方案:
减小批量大小:尝试将 batch 参数减小,例如从 128 减小到 32 或 16。较大的批次可能导致显存占用过多而崩溃。
减少 DataLoader 工作线程数:num_workers 参数控制了 DataLoader 中使用的 CPU 线程数,默认值较高(例如 8),你可以将其减少到 2 或 4,以降低内存占用。
<code>results = model.train(data="./yolo_seg_dataset/data.yaml", epochs=40, imgsz=640, batch=32, workers=2)code>
2.调整 CUDA 配置
减少 GPU 占用:如果你的 GPU 内存不足,除了减小批量大小,还可以使用 half=True 来启用混合精度训练,减少显存占用:
results = model.train(data="./yolo_seg_dataset/data.yaml", epochs=40, imgsz=640, batch=32, half=True)code>
3.最终改为
from ultralytics import YOLO
model = YOLO("./yolov8n-seg.pt")
results = model.train(data="./yolo_seg_dataset/data.yaml", epochs=30, imgsz=640,batch=32,workers=2,half=True)code>
4.又崩溃
batch改为8
results = model.train(data=“./yolo_seg_dataset/data.yaml”, epochs=30, imgsz=640,batch=8,workers=2,half=True)
5.今晚截止,没时间了
epochs=10
6.CPU才40%
workers=4
7.比赛结果
7.1Baseline结果
7.2改进后结果
额,好像没用

7.3找到零分的原因了
Baseline生成数据格式不标准,导致零分
baseline格式
[
[
[0,0],
[1,0],
[0,1],
[1,1],
[0,0],
[1,0],
[0,1],
[1,1]
]
]
官方要求数据格式
[
[
[0,0],
[1,0],
[0,1],
[1,1]
],
[
[0,0],
[1,0],
[0,1],
[1,1]
]
]
10月12日:Task2-改进
1.使用所有的数据集训练模型,从比赛页面下载所有的图片。[3]
闷大了,差不多45G
2、切换不同的模型预训练权重。[3]
直接上YOLOv8x-seg 失败,太久了
https://docs.ultralytics.com/models/yolov8

3.结果
换成yolov11n,在所有训练集上,只跑了一个epoch,就花了7h
<code>from ultralytics import YOLO
model = YOLO("/root/dw_AI_defense_track2/yolo11n-seg.pt")
results = model.train(data="/root/dw_AI_defense_track2/yolo_seg_dataset/data.yaml", epochs=1, imgsz=512,batch=4, workers=4,save_period=1)code>
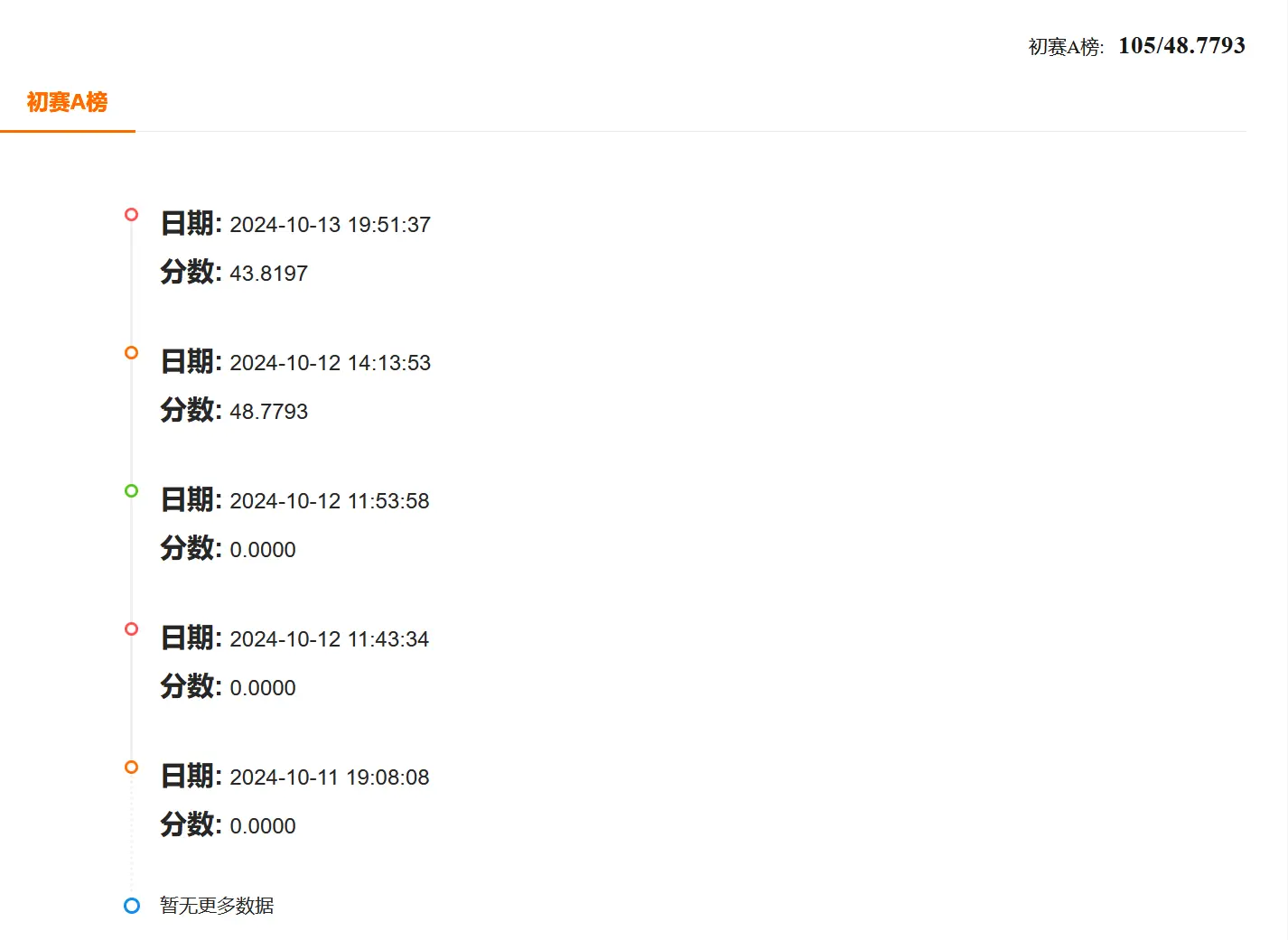
4.找到为什么原来0分的真正原因了!
在使用的YOLO yolo11n-seg.pt 模型中,返回的是多边形的坐标,而不仅仅是一个矩形框的四个角点坐标。
原因是这是一个分割(segmentation)模型,而不是仅仅用于物体检测的模型。
代码中,模型 results 返回的是一个包含 masks 的对象,
result.masks.xy 返回的是每个检测到的物体掩膜的轮廓坐标。
这些坐标通常表示物体轮廓的顶点,因此是一个多边形,而不一定是一个简单的矩形。
因此可能会有超过四个坐标点,这是正常的。
但是比赛要求一定是四个点,传多个点上去当然零分
所以使用 OpenCV 来对多边形坐标进行处理,获取最小外接矩形的四个顶点
<code>import cv2
import numpy as np
from tqdm import tqdm
Polygon = []
for path in tqdm(test_imgs):
results = model(path, verbose=False)
result = results[0]
if result.masks is None:
Polygon.append([])
else:
rects = []
for mask in result.masks.xy:
# Convert mask coordinates to a numpy array of type int
contour = np.array(mask, dtype=np.int32)
# Get the bounding rectangle for the contour
x, y, w, h = cv2.boundingRect(contour)
# Calculate the four vertices of the rectangle
rect = [[x, y], [x, y + h], [x + w, y + h], [x + w, y]]
rects.append(rect)
Polygon.append(rects)
Reference
[1] 赛事链接:全球AI攻防挑战赛—赛道二:AI核身之金融场景凭证篡改检测
https://tianchi.aliyun.com/competition/entrance/532267/introduction
[2] 魔搭Notebook
https://www.modelscope.cn/my/mynotebook/preset
[3] Datawhale Baseline 指导文档
https://datawhaler.feishu.cn/wiki/KovEwSWRjisOzfkPgpGcB2Sin5y
[4] ChatGPT4.o
https://chatgpt.com
[5] Window11安装ubuntu22.05-cuda12.1.0
https://blog.csdn.net/aiqq136/article/details/142856947
10月17日 TASK3 总结
1.数据集增强
1.1增强技术
翻转
旋转
缩放
颜色调整
1.2库
Albumentations
Imgaug
TensorFlow的 ImageDataGenerator
1.3参数
hsv_h
色调
hsv_s
饱和度
颜色强度
hsv_v
亮度
degrees
随机旋转
translate
平移
scale
缩放
shear
剪切
perspective
透视变换
flipud
上下翻转
fliplr
左右翻转
bgr
RGB变BGR
mosaic
合成四张图像
mixup
混合两张图像和标签
copy_paste
复制物体粘贴到另一个图像
auto_augment
自定义
erasing
擦除随机部分
2.YOLO 模型训练参数
通常,在初始训练时期,
学习率从低开始,
逐渐增加以稳定训练过程。
但是,由于您的模型已经从以前的数据集中学习了一些特征,
因此立即从更高的学习率开始可能更有益。
在 YOLO 中绝大部分参数都可以使用默认值。
imgsz:
训练时的目标图像尺寸,
所有图像在此尺寸下缩放。
save_period:
保存模型检查点的频率(周期数),
-1 表示禁用。
device: 用于训练的计算设备,
可以是单个或多个 GPU,CPU 或苹果硅的 MPS。
optimizer:
训练中使用的优化器,
如 SGD、Adam 等,或 ‘auto’ 以根据模型配置自动选择。
momentum:
SGD 的动量因子
或 Adam 优化器的 beta1。
weight_decay:
L2 正则化项。
warmup_epochs:
学习率预热的周期数。
warmup_momentum:
预热阶段的初始动量。
warmup_bias_lr:
预热阶段偏置参数的学习率。
box:
边界框损失在损失函数中的权重。
cls:
分类损失在总损失函数中的权重。
dfl:
分布焦点损失的权重。
3.设置 YOLO 模型预测行为和性能
YOLO模型的预测结果通常包括多个组成部分,
每个部分提供关于检测到的对象的不同信息。
同时 YOLO 能够处理
包括单独图像、
图像集合、
视频文件
或实时视频流在内的多种数据源,
也能够一次性处理多个图像或视频帧,
进一步提高推理速度。
属性
cls
类别概率,表示当前预测结果属于类别0的概率
conf
置信度,模型对其预测结果的置信度
data
包含边界框坐标和置信度以及类别概率的原始数据。
id
没有分配唯一的对象ID。
is_track
预测结果不是来自跟踪的对象。
orig_shape
输入图像的原始尺寸,这里是500x500像素。
shape
预测结果张量的形状,表示一个边界框的六个值。
xywh
归一化的边界框坐标,中心坐标和宽高。
xywhn
归一化的边界框坐标(无偏移)。
xyxy
原始边界框坐标,左上角和右下角坐标。
xyxyn
归一化的原始边界框坐标。
如果需要减少误报,可以提高conf阈值
如果需要提高模型的执行速度,可以在支持的硬件上使用half精度
如果需要处理视频数据并希望加快处理速度,可以调整vid_stride来跳过某些帧
conf
默认0.25
置信度阈值,
用于设置检测对象的最小置信度。
低于此阈值的检测对象将被忽略。
调整此值有助于减少误报。
iou
默认0.7
非最大值抑制(NMS)
的交并比(IoU)阈值。
较低的值
通过消除重叠的边界框
来减少检测数量,
有助于减少重复项。
imgsz
推理时定义图像的大小。
可以是单个整数(如640),
用于将图像大小调整为正方形,
或(height, width)元组。
合适的尺寸可以提高检测精度和处理速度。
augment
启用预测时的数据增强(TTA),
可能通过牺牲推理速度来提高检测的鲁棒性。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。