【AI语音基础】ASR基本知识
AI_Gump 2024-06-15 12:31:02 阅读 63
目录
背景
语音识别ASR原理
HMM隐马尔可夫链语音识别
端到端语音识别
识别衡量标准
参考1
参考2
参考3
参考4
背景
语音识别(Speech Recognition)也被称为自动语音识别(英语:Automatic Speech Recognition, ASR),将语音音频转换为文字的技术。
简单点说:把语音音频转化为文字。
语音识别ASR原理
新手语音入门(三): 语音识别ASR算法初探 | 编码与解码 | 声学模型与语音模型 | 贝叶斯公式 | 音素-云社区-华为云 (huaweicloud.com)

编码过程:语音识别的输入是声音,计算机无法直接处理,
需要编码过程将其转变为数字信息,并提取其中的特征进行处理。
编码时一般会将声音信号按照很短的时间间隔,切成小段,成为帧。
对于每一帧,可以通过某种规则(例如MFCC特征)提取信号中的特征,将其变成一个多维向量。向量中的每个维度都是这帧信号的一个特征。
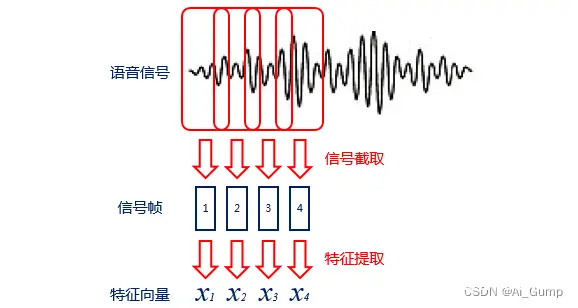
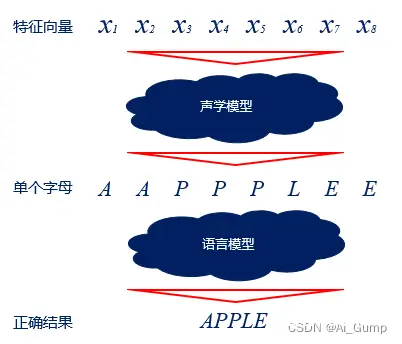
解码过程:解码过程则是将编码得到的向量变成文字的过程,需要经过两个模型的处理,一个模型是声学模型,一个模型是语言模型。
声学模型通过处理编码得到的向量,将相邻的帧组合起来变成音素,如中文拼音中的声母和韵母,再组合起来变成单个单词或汉字。语言模型用来调整声学模型所得到的符合逻辑的字词,使识别结果变得通顺。
已知一段音频信号,处理成声学特征向量Acoustic Feature Vector后表示为,X=[x1,x2,x3,…]X=[x1,x2,x3,…],其中xixi表示一帧特征向量;可能的文本序列表示为W=[w1,w2,w3,…]W=[w1,w2,w3,…],其中wiwi表示一个词,求W∗=argmaxwP(W∣X)W∗=argmaxwP(W∣X),这便是语音识别的基本出发点。并且由贝叶斯公式可知:

其中,P(X∣W)P(X∣W)称之为声学模型(Acoustic Model, AM), P(W)P(W)称之为语言模型(Language Model, LM),由于P(W)P(W)一般是一个不变量,可以省去不算。
许多研究将语音识别问题看做声学模型与语音模型两部分,分别求取P(X∣W)P(X∣W)和P(W)P(W)。
后来,基于深度学习和大数据的端对端(End-to-End)方法发展起来,直接计算P(W∣X)P(W∣X),把声学模型和语言模型融为了一体。
语音识别的问题可以看做是语音到文本的对应关系,语音识别问题大体可以归结为文本基本组成单位的选择上。单位不同,则建模力度也随之改变。

图中文本基本组成单位从大到小分别是:
整句文本,如“Hello
World”,对应的语音建模尺度为整条语音。
词,如孤立词“Good”、“World”、对应的语音建模尺度大约为每个词的发音范围。
音素,如将“world”进一步表示为“/wɘrld//wɘrld/”,其中的每个音标作为基本单位,对应的语音建模尺度则缩减为每个音素的发音范围。
三音素,即考虑上下文的音素,如将音素“/d//d/”进一步表示为“/l−d−sil,/u−d−l/,…/l−d−sil,/u−d−l/,…”,对应的语音建模尺度是每个三音素的发音范围,长度与单音素差不多。
隐马尔可夫模型状态,即将每个三因素都用一个三状态隐马尔可夫模型表示,并用每个状态作为建模粒度,对应的语音建模尺度将进一步缩短。
上面每种实现方法都对应着不同的建模粒度,大体可以分为以隐马尔可夫模型结构和端对端的结构。
HMM隐马尔可夫链语音识别
新手语音入门(四): 传统语音识别技术简介 | 隐马尔可夫链 | 声学/语言模型 | WFST解码-云社区-华为云 (huaweicloud.com)
隐马尔可夫链HMM模型自从1980年代被用于语音识别以来,一直都是实际语音识别系统的主流方法。
声学模型
P(X∣W)P(X∣W)对应的是声学模型,首先需要考虑的是,语音和文本的不定长关系使得二者的序列之间无法一一对应。隐马尔可夫链模型正好可以解决这个问题。

比如P(X│W)=P(x1,x2,x3∣w1,w2)P(X│W)=P(x1,x2,x3∣w1,w2)可以表示成上面隐马尔可夫链的形式,图中ww是HMM的隐含状态,xx是HMM的观测值,隐含状态数与观测值数目不受彼此约束,这便解决了输入输出的不定长问题,并有:
P(X│W)=P(w1)P(x1∣w1)P(w2∣w1)P(x2∣w2)P(w2∣w2)P(x3∣w2)P(X│W)=P(w1)P(x1∣w1)P(w2∣w1)P(x2∣w2)P(w2∣w2)P(x3∣w2)
其中,HMM的初始状态概率P(w1)P(w1)和状态转移概率(P(w2∣w1)P(w2∣w1)、P(w2∣w2))P(w2∣w2))可以用常规的统计方法从样本总计算出来,主要的难点在于HMM发射概率(P(x1∣w1)P(x1∣w1)、P(x2∣w2)P(x2∣w2)和P(x3∣w2)P(x3∣w2))的计算上,所以声学模型问题进一步细化到HMM发射概率(Emission Probabolity)的学习上。
GMM-HMM
高斯混合模型(Gaussion Mixture Model,GMM)是最常用的统计模型,给定充分的子高斯数,GMM可以拟和任意的概率分布,所以GMM成为首选的发射概率模型。
DNN-HMM
声学模型结构,语音特征作为DNN的输入,DNN的输出则用于计算HMM的发射概率。
语言模型
语言模型要解决的问题是如何计算P(W),常用的方法基于n元语法(n-gram Grammer)或RNN。
解码器
选择使得P(W∣X)=P(X∣W)P(W)P(W∣X)=P(X∣W)P(W)最大的WW,所以解码本质上式一个搜索问题,并可借助加权有限状态转换机(Weighted Finite State Transducer, WFST)统一进行最优路径搜索。
端到端语音识别
新手语音入门(五): 端到端语音识别技术简介 | 卷积神经网络 | CTC损失函数 | 注意力机制-云社区-华为云 (huaweicloud.com)
输入是一整段语音,输出是对应的文本,两端都能处理成规则的数学表示形式,只要数据足够,模型合适,我们也许能训练出一个好的端对端模型。
对于输入:
我们可以考虑将不同长度的数据转化为固定维度的向量序列。因此我们可以选择卷积神经网络(Convolutional Neural Network,CNN)进行转换,CNN通过控制池化层(Pooling Layer)的尺度来保证不同的输入转换后的维度相同。 输入分帧逐次进入模型,可以使用RNN,虽然输入时分开进入,但是累积的历史信息会在最后以固定维度一次性输出,这两个方法常常用于基于注意力(Attention)的网络结构。
对于输出,
先考虑输入长度不做处理的情况,因为语音识别中,真实输出的长度远小于输入的长度,可以引入空白标签充数,这是CTC(Connectionist Temporal Classification)损失函数常用的技巧。如果输出长度长于输入长度,则常规CTC就不合适了。另一种情况是前述固定输入为一个长度的向量,然后根据这个向量解码出一个文本序列,此时输出长度需要其他机制判断是否结束输出,比如引入结束符标签
两个端对端方法即上文提到的基于CTC损失函数和注意力机制的深度学习方法
CTC是一种2006年就应用于语音识别的损失函数,输入是一个序列,输出是一个序列,该损失函数使得模型输出的序列尽可能的拟合目标序列。RNN-T预测网络与编码器都使用LSTM,可以分别对历史输出y和历史语音特征(x,含当前时刻)进行信息累积。并通过一个全连接神经共同作用于新的输出,图中的p和h分别为预测网络和编码器的输出,形式为固定长度的向量。
Transformer, 如下图所示,其摆脱了循环神经网络和卷积神经网络的禁锢,以及使用了多注意力机制,加速了并行计算能力。
识别衡量标准
语音识别,计算字错率WER、句错率SER
参考1
AI产品经理需要了解的语音交互评价指标,来自hanniman
识别率
看纯引擎的识别率,以及不同信噪比状态下的识别率(信噪比模拟不同车速、车窗、空调状态等),还有在线/离线识别的区别。
实际工作中,一般识别率的直接指标是“WER(词错误率,Word Error Rate)”
定义:为了使识别出来的词序列和标准的词序列之间保持一致,需要进行替换、删除或者插入某些词,这些插入、替换或删除的词的总个数,除以标准的词序列中词的总个数的百分比,即为WER。
公式为:

Substitution——替换Deletion——删除Insertion——插入N——单词数目
3点说明
WER可以分男女、快慢、口音、数字/英文/中文等情况,分别来看。因为有插入词,所以理论上WER有可能大于100%,但实际中、特别是大样本量的时候,是不可能的,否则就太差了,不可能被商用。站在纯产品体验角度,很多人会以为识别率应该等于“句子识别正确的个数/总的句子个数”,即“识别(正确)率等于96%”这种,实际工作中,这个应该指向“SER(句错误率,Sentence Error Rate)”,即“句子识别错误的个数/总的句子个数”。不过据说在实际工作中,一般句错误率是字错误率的2~3倍,所以可能就不怎么看了。
参考2
https://www.cnblogs.com/yinlili/p/11393846.html,有具体案例
英文,因为最小单元是Word,语音识别应该用"字错误率"(WER),
中文,因为最小单元是字符,语音识别应该用“字符错误率”(CER)。
1.2、句错率(SER)
句错误率:Sentence Error Rate
解释:句子识别错误的的个数,除以总的句子个数即为SER
计算公式:(所有公式省了 * 100%)
SER = 错误句数 / 总句数
1.3、句正确率(S.Corr)
句正确率:Sentence Correct
计算公式:
S.Corr = 1 - SER = 正确句数 / 总句数
行业水平
英语-WER;
IBM:行业标准Switchboard语音识别任务,2016年 6.9%,2017年 5.5%
微软:行业标准Switchboard语音识别任务,2016年 6.3% -> 5.9%,2017年 5.1%,这个目前最低的。
说明:ICASSP2017上IBM说人类速记员WER是5.1%,一般认为5.9% 的字错率是人类速记员的水平。
中文-WER/CER:
小米:2018年 小米电视 2.81%
百度:2016年 短语识别 3.7%
中文-W.Corr:
百度:2016年 识别准确率 97%
搜狗:2016年 识别准确率 97%
讯飞:2016年 识别准确率 97%
Findyou部分数据来源:
微软WER 5.9%:https://arxiv.org/abs/1610.05256
微软WER 5.1%: https://www.microsoft.com/en-us/research/wp-content/uploads/2017/08/ms_swbd17-2.pdf
小米电视CER 2.81% :https://arxiv.org/pdf/1707.07167.pdf
国内百度等同时宣布识别准确率97% : 为什么百度、搜狗、讯飞的语音识别宣称的准确率都是 97%? - 知乎
参考3
新手语音入门(一):认识词错率WER与字错率CER | 编辑距离 | 莱文斯坦距离 | 动态规划
新手语音入门(一):认识词错率WER与字错率CER | 编辑距离 | 莱文斯坦距离 | 动态规划-云社区-华为云
1. 字/词错率的概念 1.1 词错率与字错率1.2 计算公式 2. 字错率的计算 2.1 编辑距离的概念2.2 编辑距离的求解
词错率(Word Error Rate, WER)是一项用于评价ASR性能的重要指标,用来评价预测文本与标准文本之间错误率,因此词错率最大的特点是越小越好。像英语、阿拉伯语语音转文本或语音识别任务中研究者常用WER衡量ASR效果好坏。
因为英文语句中句子的最小单位是单词,而中文语句中的最小单位是汉字,因此在中文语音转文本任务或中文语音识别任务中使用字错率(Character Error Rate, CER)来衡量中文ASR效果好坏。
计算公式是:
WER=S+D+IN=S+D+IS+D+CWER=NS+D+I=S+D+CS+D+I
假设有一个参考例句Ref和一段ASR系统转写语音后生成的预测文本Hyp。带入上面公式,S表示将Hyp转化为Ref时发生的替换数量,D表示将Hyp转化为Ref时发生的替换数量,I代表将Hypo转化为Ref时发生的插入数量,N代表Ref句子中总的字数或者英文单词数。C代表Hyp句子中识别正确的字数。即原参考句子总字数N = S+ D + C。
再说一句,根据维基百科里面的说法,N就是原样例文本总的字数。
参考4
为什么百度、搜狗、讯飞的语音识别宣称的准确率都是 97%? - 知乎
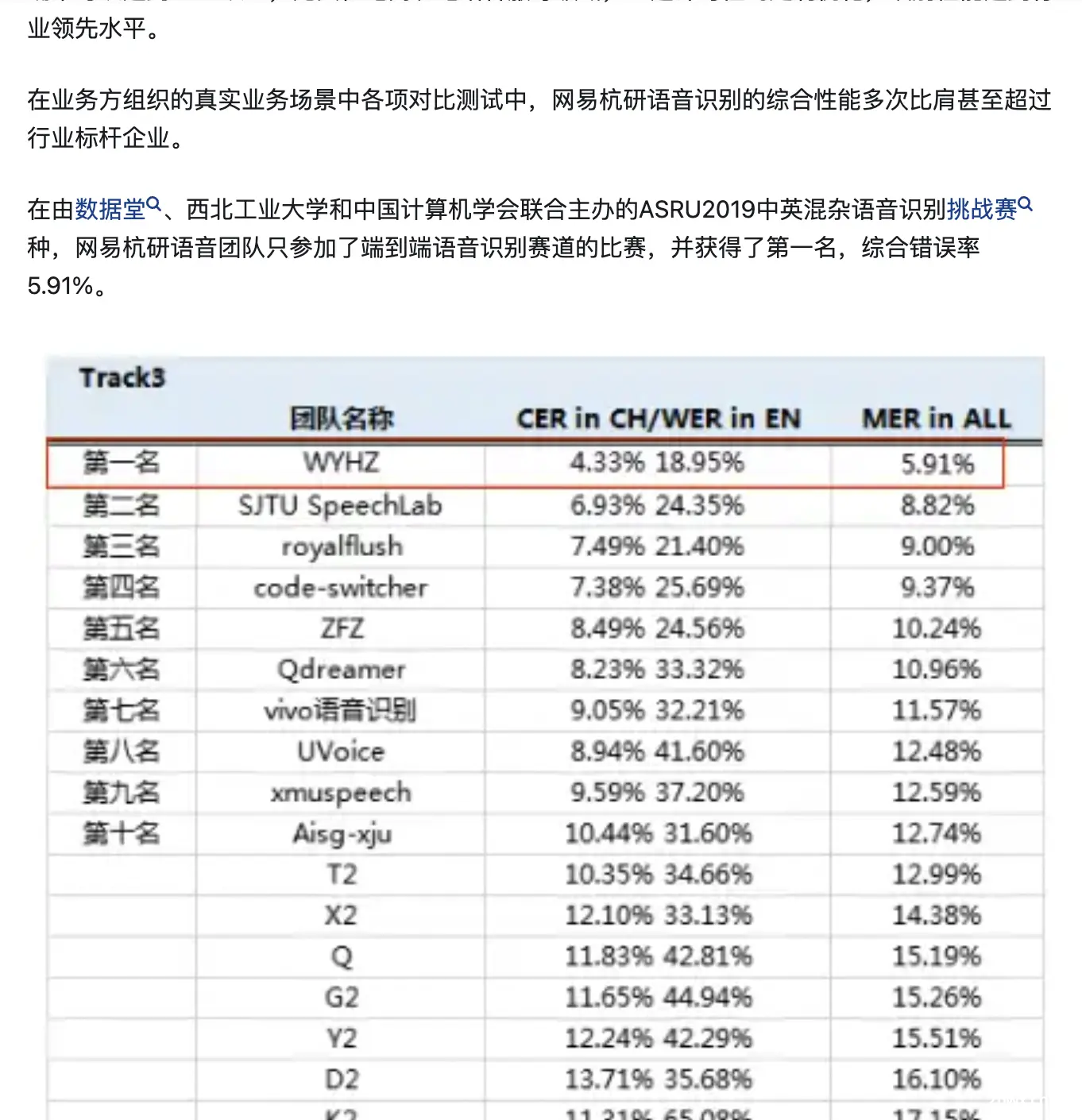
所有的测试结果是需要基于测试集:微软的5.9的WER是在NIST 2000 CTS上实现的。也就是94.1的识别率,这个是平了人类速记员的水平的。(ICASSP2017上IBM说人类速记员WER是5.1)
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。