【AI模型系列】火力全开!百度文心3.5三大维度、20项指标国内问鼎!
颜淡慕潇 2024-06-19 15:31:02 阅读 85
目录
写在前面
详细介绍
综合性能评估结果
安全合规方面
写在前面
近日,清华大学新闻与传播学院沈阳团队发布《大语言模型综合性能评估报告》(下文简称“报告”)。
报告显示百度文心一言在三大维度20项指标中综合评分国内第一,超越ChatGPT,其中中文语义理解排名第一,部分中文能力超越GPT-4。
详细介绍
清华大学新闻与传播学院教授、博士生导师沈阳表示:“今年3月,百度在全球大型科技公司中率先发布了大语言模型文心一言,让中国第一时间参与到世界前沿科技竞争中。我们在这次评测中也看到了文心一言各方面能力的进步,特别是在中文语义理解方面,表现惊艳。国产大模型的快速发展,让技术落地更可期。”
综合性能评估结果
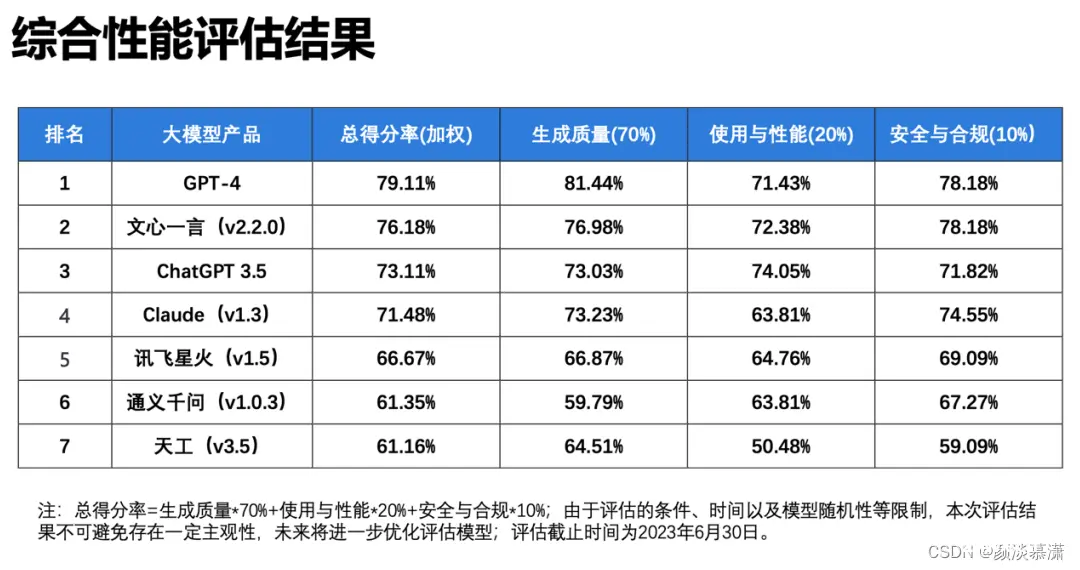
据了解,报告本次评估选取了GPT-4、ChatGPT 3.5、文心一言、通义千问、讯飞星火、Claude、天工7个大语言模型,围绕生成质量、使用与性能、安全与合规三大维度,全面考察大语言模型上下文理解、中文语义理解、误导信息识别、逻辑推理、内容安全性、隐私保护等20项指标。综合来看,文心一言语义理解能力突出,特别是具备更好的中文理解能力,更懂中国文化,同时时效性强、内容安全把握细微,这源于其知识增强、检索增强和对话增强的技术创新。
在生成质量方面,基于对语义理解、输出表达、适应泛化的综合评测,文心一言得分率76.98%,仅次于GPT-4,遥遥领先于包括ChatGPT在内的其他大语言模型。
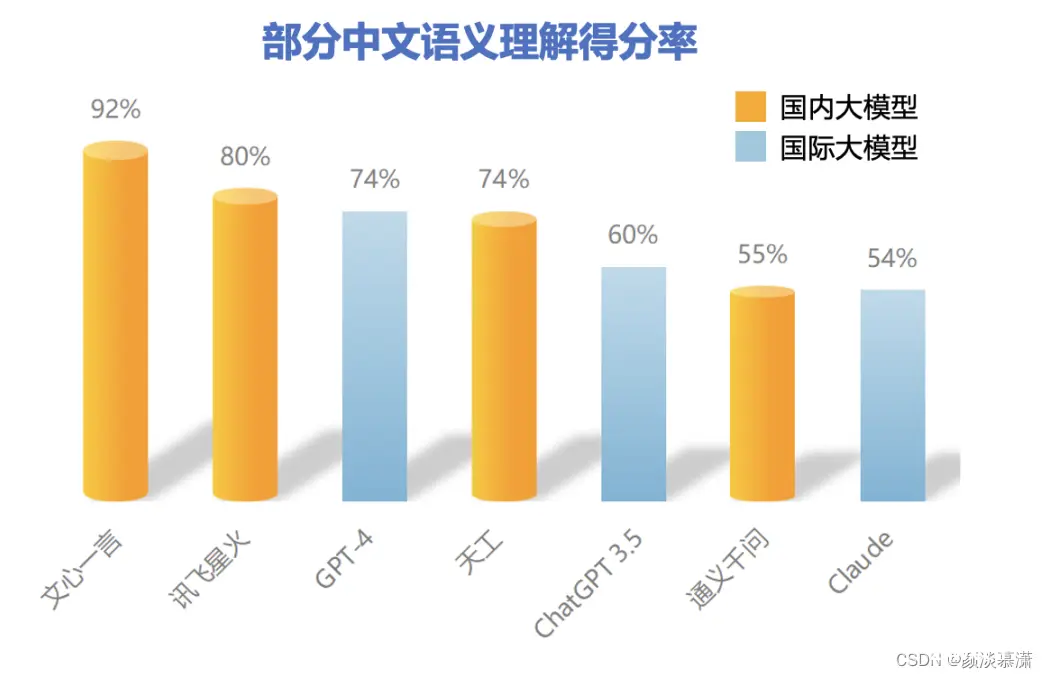
其中,在部分中文语义理解方面,文心一言以92%的得分率排名榜首,超越讯飞星火、GPT-4。凭借知识增强的核心特色,文心一言对本土语言特性把握更精准,同时由于训练语料中包含大量本土文本,对本土文化理解也更深刻,能够更好处理与本土文化相关的主题和背景,如诗歌、方言等,具备更强的国内落地空间。
安全合规方面
在安全合规方面,基于对内容安全性、偏见和公平性、隐私保护等综合评测,文心一言得分率78.18%,与GPT-4并列排名第一,远超其他大语言模型。报告显示,文心一言内容安全性好,注重用户隐私保护和版权保护。
据了解,百度在“芯片-框架-模型-应用”人工智能四层技术栈全面布局,其自研深度学习平台飞桨有力支撑了文心大模型的高效训练和推理,截至目前飞桨已凝聚750万名开发者。飞桨与文心协同优化,文心大模型3.5最新版本实现了基础模型升级、精调技术创新、知识点增强、逻辑推理增强等,模型效果提升50%,训练速度提升2倍,推理速度提升30倍。
当下,推进行业大模型应用落地成为大势所趋。百度文心大模型此前已联合国家电网、浦发银行、泰康、吉利等企业单位,合作发布了11个行业大模型。目前文心大模型拥有中国最大的产业应用规模,15万家企业申请接入文心一言测试,在超过400个场景中已取得相当不错的测试效果。
上一篇: 009-Wsl-Ubuntu部署Dify-【AI超车B计划】
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。