SWE-Agent 这是针对本地模型的新人工智能一个开源项目
CSDN 2024-06-17 08:01:02 阅读 61
完全自主的编码代理,可以解决 GitHub 问题。 它在编码基准测试中的得分几乎与 Devin 一样高。 这是完整的评论和教程。
SWE-agent 将 LM(例如 GPT-4)转变为软件工程代理,可以修复真实 GitHub 存储库中的错误和问题。
🎉 在完整的 SWE-bench 测试集上,SWE-agent 修复了 12.29% 的问题,这是完整测试集上最新的结果。
我们通过设计简单的以 LM 为中心的命令和专门构建的输入和输出格式来实现这些结果,使 LM 更容易浏览存储库、查看、编辑和执行代码文件。 我们将此称为代理计算机接口 (ACI),并构建 SWE 代理存储库,以便轻松迭代存储库级编码代理的 ACI 设计。
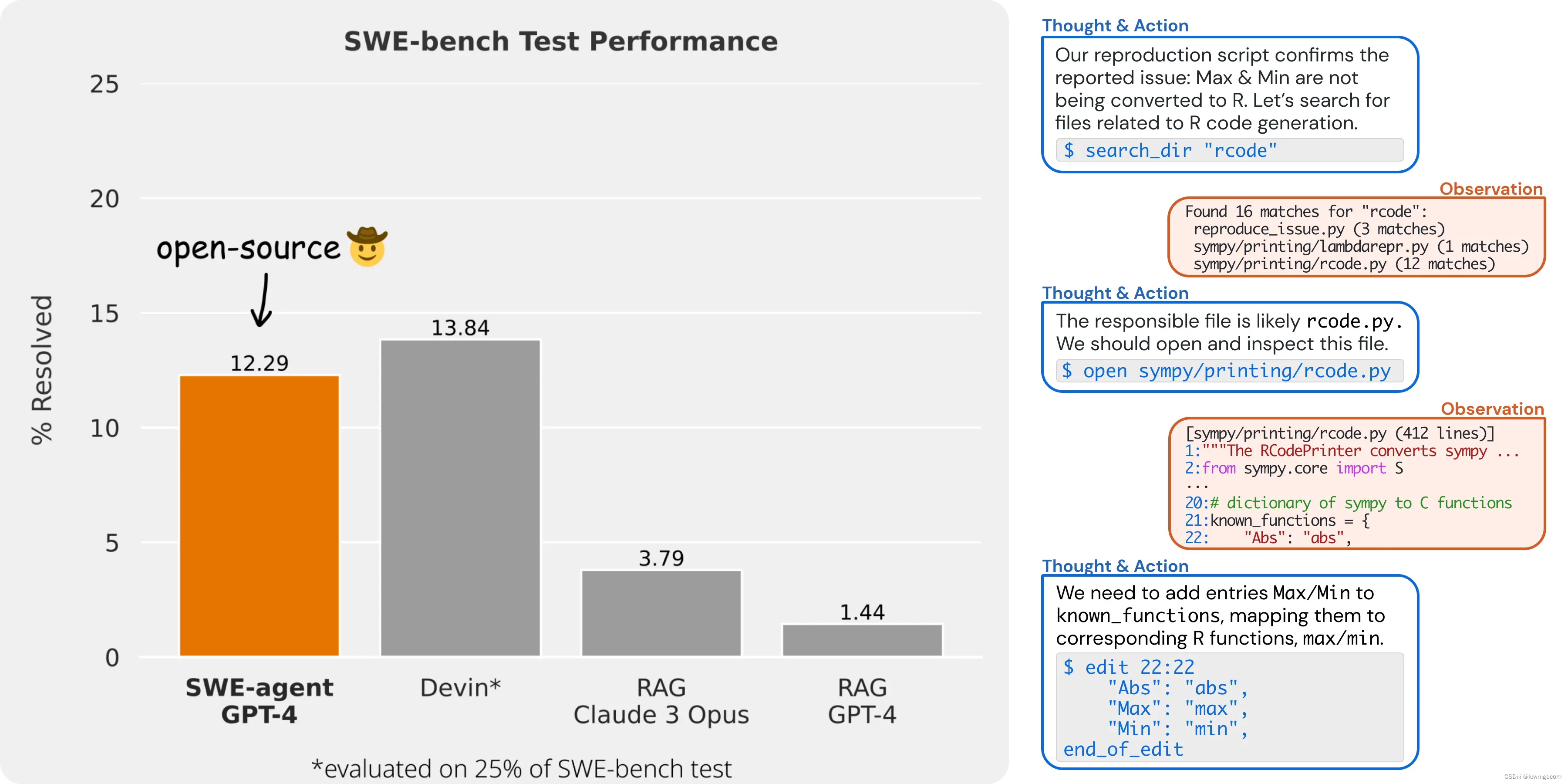
Agent-Computer Interface 代理计算机接口 (ACI)
我们通过设计简单的以 LM 为中心的命令和反馈格式来实现这些结果,使 LM 更容易浏览存储库、查看、编辑和执行代码文件。 我们将其称为代理计算机接口 (ACI),并构建 SWE 代理存储库,以便轻松迭代存储库级编码代理的 ACI 设计。
就像典型的语言模型需要良好的提示工程一样,良好的 ACI 设计在使用代理时会带来更好的结果。 正如我们在论文中所示,没有经过良好调整的 ACI 的基线代理的表现比 SWE 代理差得多。
SWE-agent 包含我们发现在代理-计算机界面设计过程中非常有用的功能:
我们添加了一个在发出编辑命令时运行的 linter,并且如果代码语法不正确,则不会让编辑命令通过。我们为代理提供了一个专门构建的文件查看器,而不仅仅是 cat 文件。 我们发现此文件查看器在每轮仅显示 100 行时效果最佳。 我们构建的文件编辑器具有用于上下滚动以及在文件中执行搜索的命令。我们为代理提供了专门构建的全目录字符串搜索命令。 我们发现该工具简洁地列出匹配项非常重要 - 我们只需列出至少有一个匹配项的每个文件。 事实证明,向模型显示有关每场比赛的更多上下文对于模型来说太混乱了。当命令的输出为空时,我们会返回一条消息,指出“您的命令已成功运行,但未产生任何输出”。请阅读我们的论文了解更多详细信息。
@misc{yang2024sweagent, title={SWE-agent: Agent Computer Interfaces Enable Software Engineering Language Models}, author={John Yang and Carlos E. Jimenez and Alexander Wettig and Shunyu Yao and Karthik Narasimhan and Ofir Press}, year={2024},}
Setup 设置
安装 Docker,然后在本地启动 Docker。安装 Miniconda,使用
conda env create -fenvironment.yml 创建 swe-agent 环境 使用
使用
conda activate swe-agent 激活。
运行
./setup.sh 创建 swe-agent docker 镜像。
在此存储库的根目录下创建一个keys.cfg 文件并填写以下内容:
GITHUB_TOKEN: 'GitHub Token Here (required)'OPENAI_API_KEY: 'OpenAI API Key Here if using OpenAI Model (optional)'ANTHROPIC_API_KEY: 'Anthropic API Key Here if using Anthropic Model (optional)'TOGETHER_API_KEY: 'Together API Key Here if using Together Model (optional)'AZURE_OPENAI_API_KEY: 'Azure OpenAI API Key Here if using Azure OpenAI Model (optional)'AZURE_OPENAI_ENDPOINT: 'Azure OpenAI Endpoint Here if using Azure OpenAI Model (optional)'AZURE_OPENAI_DEPLOYMENT: 'Azure OpenAI Deployment Here if using Azure OpenAI Model (optional)'AZURE_OPENAI_API_VERSION: 'Azure OpenAI API Version Here if using Azure OpenAI Model (optional)'
请参阅以下链接,获取有关获取 Anthropic、OpenAI 和 Github 令牌的教程。
Usage 用途
SWE-agent 管道有两个步骤。 第一个 SWE 代理接受输入 GitHub 问题并返回尝试修复它的拉取请求。 我们称该步骤为推理。 第二步(目前仅适用于 SWE-bench 基准测试中的问题)是评估拉取请求以验证它确实解决了问题。
注意:目前,少数存储库存在已知问题,无法为arm64 / aarch64 架构计算机正确安装。 我们正在努力修复,但如果您想在整个 SWE-bench 上运行和评估,最简单的方法是使用 x86 机器。
Inference 推论
对任何 GitHub 问题进行推理:使用此脚本,您可以在任何 GitHub 问题上运行 SWE-agent!
python run.py --model_name gpt4 \ --data_path https://github.com/pvlib/pvlib-python/issues/1603 \ --config_file config/default_from_url.yaml
SWE-bench 上的推理:在 SWE-bench Lite 上运行 SWE-agent 并生成补丁。
python run.py --model_name gpt4 \ --per_instance_cost_limit 2.00 \ --config_file ./config/default.yaml
如果您想从 SWE-bench 运行单个问题,请使用 --instance_filter 选项,如下所示:
python run.py --model_name gpt4 \ --instance_filter marshmallow-code__marshmallow-1359 请参阅 script/ 文件夹以获取其他有用的脚本和详细信息。有关如何定义自己的配置的详细信息,请参阅 config/ 文件夹!有关基于配置的工作流程背后的逻辑的详细信息,请参阅 sweagent/agent/ 文件夹。有关 SWEEnv 环境(接口 + 实现)的详细信息,请参阅 sweagent/environment/ 文件夹。有关 run.py 输出的详细信息,请参阅 trajectories/文件夹。
Evaluation 评估
此步骤仅适用于 SWE 基准集中的问题。 要评估生成的拉取请求:
cd evaluation/./run_eval.sh <predictions_path>
将 <predictions_path> 替换为模型预测的路径,该路径应从推理步骤生成。 <predictions_path> 参数应类似于 ../trajectories/<username>/<model>-<dataset>-<hyperparams>/all_preds.jsonl
有关评估如何工作的详细信息,请参见评估/文件夹
上一篇: 算法金 | 一文看懂人工智能、机器学习、深度学习是什么、有什么区别!
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。