【人工智能】基于分类算法的学生学业预警系统应用
ༀ慕斯冰淇淋༻ 2024-06-27 16:01:02 阅读 79
基于分类算法的学业预警(题目)
如果感兴趣的朋友,数据集见我的资源 源代码25需要私聊,可小刀
一、背景介绍
党的二十大报告指出:“我们要坚持教育优先发展、科技自立自强、人才引领驱动,加快建设教育强国、科技强国、人才强国,坚持为党育人、为国育才,全面提高人才自主培养质量,着力造就拔尖创新人才,聚天下英才而用之”。学生是祖国的未来,如何培养出优秀的接班人是学校管理部门常思的一个问题,即如何激发每一个学生的学习潜能,为中华民族的伟大复兴贡献一份力量。大多数高校往往是用学生的历史考试成绩,计算概率或计数,从而对相应学生提出预警,但没考虑到在学生的学习过程中进行预警提示,以避免考试不及格,本文将坚持以人为本原则,以对学生和家长、学校、社会负责为出发点,以学习过程预警机制为研究视角,探索预警机制。
人工智能学习干预系统旨在聚集并量化优秀教师的宝贵经验,以数据和技术来驱动教学,最大化地减小教师水平地差异,提高整体教学效率和效果。通过对学习者的学习过程、学习日志、学习结果进行多维分析,综合判断学生的学习情况,能够提前发现存在失败风险的学生,对其进行系统干预和人工干预。学生失败风险需要分析学生历史学习情况,分析学生在班级中的学习情况,分析学生和标准学习过程的偏离,从横向纵向多维度进行分析。
二、选题原理介绍
本课题主要使用机器学习中比较常见的算法,包括常用的随机森林、支持向量机(SVM)、逻辑回归、Adaboost,借助机器学习,以研究大学生综合素养的预警机制并比较不同算法之间的优劣性。
2.1 随机森林
随机森林(Random For-est,简称RF)是一种集成学习算法,通过构建多个决策树来完成分类和回归任务,在RF中,每个决策树都使用一个随机选择的特征子集进行训练,从而减少特征之间的相关性,提高模型的泛化能力。此外,每个决策树的节点也使用一个随机选择的样本子集来进行训练,进一步降低模型的方差。当需要对新的数据样本进行分类或预测时,RF中的每个决策树都会对其进行预测,最终的预测结果是所有决策树预测结果的平均值(回归)或投票结果(分类)。RF在处理高维和复杂数据以及高噪声数据时表现良好。它的训练速度相对较快,且不易出现过拟合。因此,RF在图像分类、医学诊断和金融风险评估等各种应用中都被广泛应用。一个完整的随机森林结构如下图所示:
2.2 支持向量机(SVM)
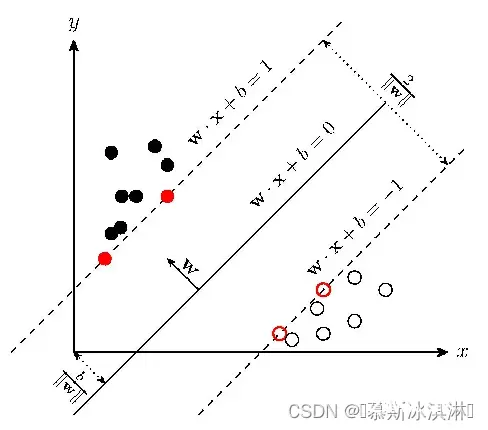
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。如下图所示, w*x + b = 0即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
2.3 逻辑回归
逻辑回归(Logistic Regression)是一种常用的分类算法,尤其适用于二分类问题。逻辑回归的核心思想是通过对数几率函数(logistic function)将线性回归的输出映射到概率空间,从而实现分类。
逻辑回归是一种线性分类算法,它通过对数几率函数将线性回归的输出映射到概率空间,从而实现分类。逻辑回归模型的优点在于简单易懂、计算效率高、可解释性强。逻辑回归模型使用对数几率函数(logistic function)作为激活函数,将线性回归的输出映射到概率空间。对数几率函数的数学表达式为:
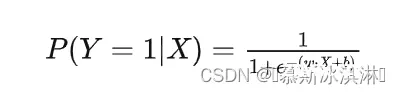
其中, P(Y=1|X) 表示给定输入特征 X 时,数据点属于正类的概率; w 是权重向量; b 是偏置项; e 是自然对数的底数。逻辑回归模型的损失函数是交叉熵损失(cross-entropy loss),数学表达式为:

其中,N是数据点的数量, Y_i 是第 i 个数据点的真实标签, hat{Y_i} 是第 i 个数据点的预测概率。逻辑回归模型的参数优化通常采用梯度下降法(Gradient Descent),通过不断迭代更新权重和偏置项,使损失函数最小化。
2.4 Adaboost
AdaBoost是Adaptive Boosting(自适应增强)的缩写,它的自适应在于:被前一个基本分类器误分类的样本的权值会增大,而正确分类的样本的权值会减小,并再次用来训练下一个基本分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或预先指定的最大迭代次数再确定最后的强分类器。
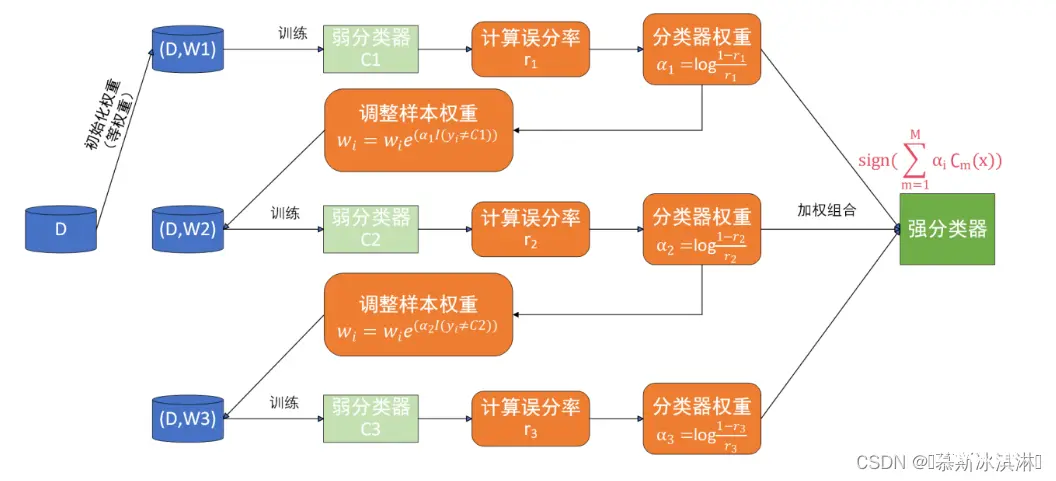
从上图来看,AdaBoost算法可以简化为3个步骤:
首先,是初始化训练数据的权值分布D1。假设有N个训练样本数据,则每一个训练样本最开始时,都会被赋予相同的权值:w1 = 1/N。
训练弱分类器Ci。具体训练过程:如果某个训练样本点,被弱分类器Ci准确地分类,那么再构造下一个训练集中,它对应的权值要减小;相反,如果某个训练样本点被错误分类,那么它的权值就应该增大。权值的更新过的样本被用于训练下一个弱分类器,整个过程如此迭代下去。
最后,将各个训练得到的弱分类器组合成一个强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。
换而言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
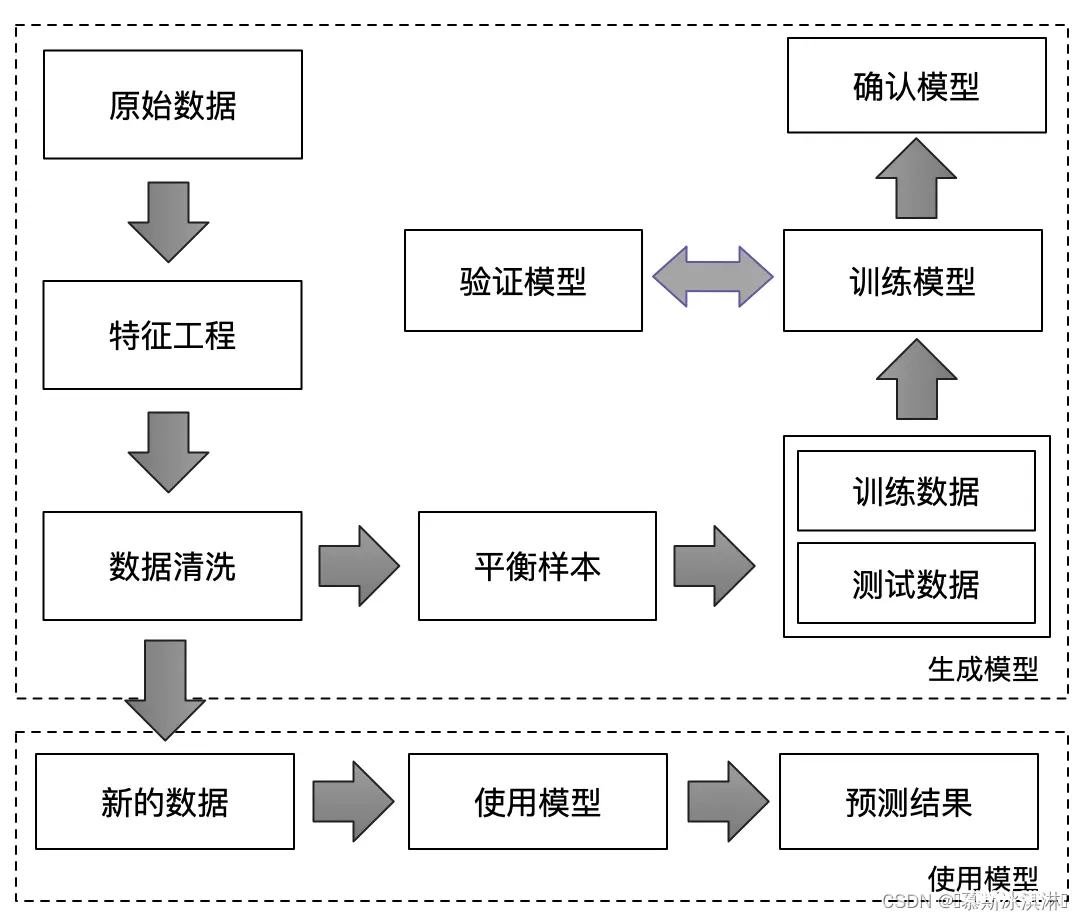
2.5学习失败风险预测流程
三、算法实现
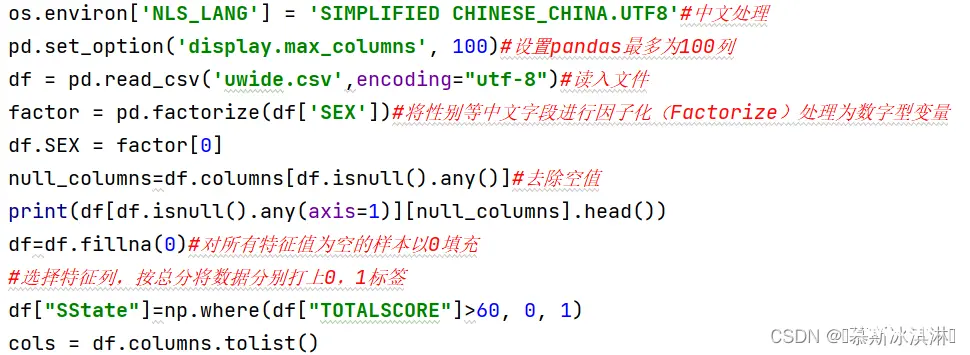
3.1 数据预处理、数据探查及特征选择、数据集划分及不平衡处理、样本生成及标准化处理

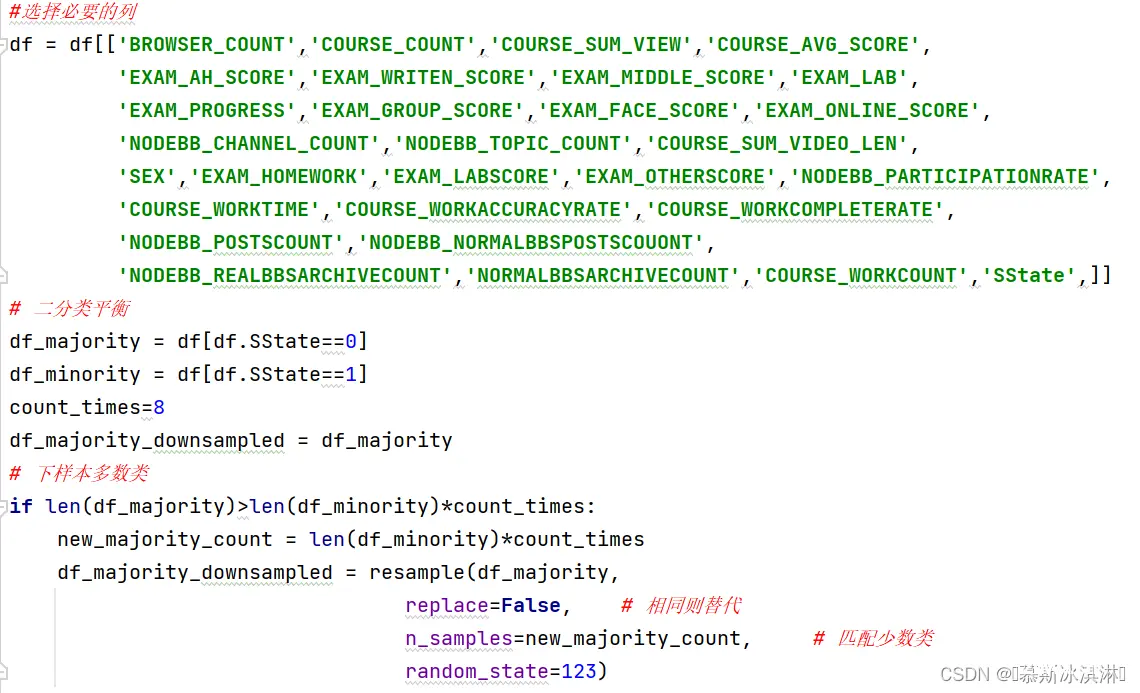
3.2 随机森林算法和网格搜索

3.3 支持向量机算法及其性能指标
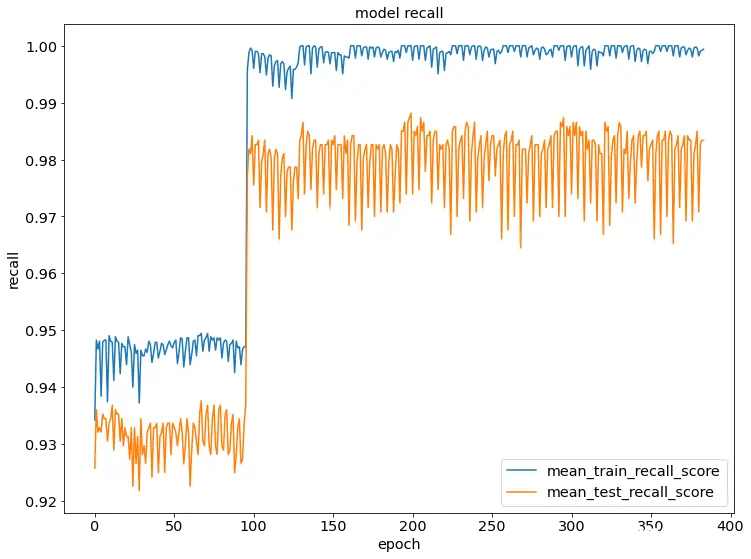
3.4 逻辑回归算法及其性能指标
在逻辑回归算法中,参数C的取值为1.0,最大迭代次数(max_iter)为100,采用L2作为正则化项。
3.5 AdaBoost算法

在AdaBoost算法中,评估器(base_estimator)采用决策树分类器(DecisionTreeClassifier),树的最大深度为3。子树即评估器数量(n_estimators)为500,学习率为0.5,采用算法(algorithm)为SAMME。
四、运行结果分析
网格优化随机森林分类器模型得到混淆矩阵和预测结果如下:
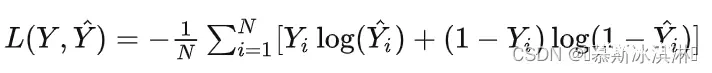
由上图知,最佳的随机森林参数为最大树深度为15,最多特征数为5个,最小样本分拆量为3个,子树数量为150个,预测结果表所示
| 表4.1 模型预测混淆矩阵
| ||
| 分类
| 预测及格
| 预测不及格
|
| 实际及格
| 300
| 13
|
| 实际不及格
| 7
| 49
|
实现本模型的ROC曲线绘制,将测试集划分为3部分,即fold 0、fold 1、fold 2, 绘制其ROC曲线,并分别计算它们的AUC值。
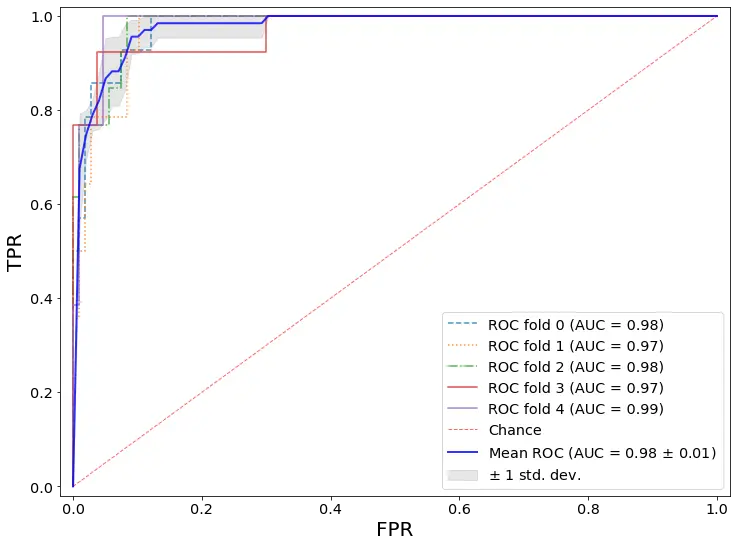
图4.1 随机森林模型ROC曲线
在图4.1中,横坐标表示FPR,纵坐标表示TPR,实线部分为平均ROC曲线,其下面积用AUC的值表示,随机森林算法的AUC均值可达0.98.可以看到,平均ROC曲线效果较好。
为了将迭代计算随机森林评估器的准确率和查合率,将3份数据的平均准确率和平均查全率变化趋势可视化,如图4.2所示。

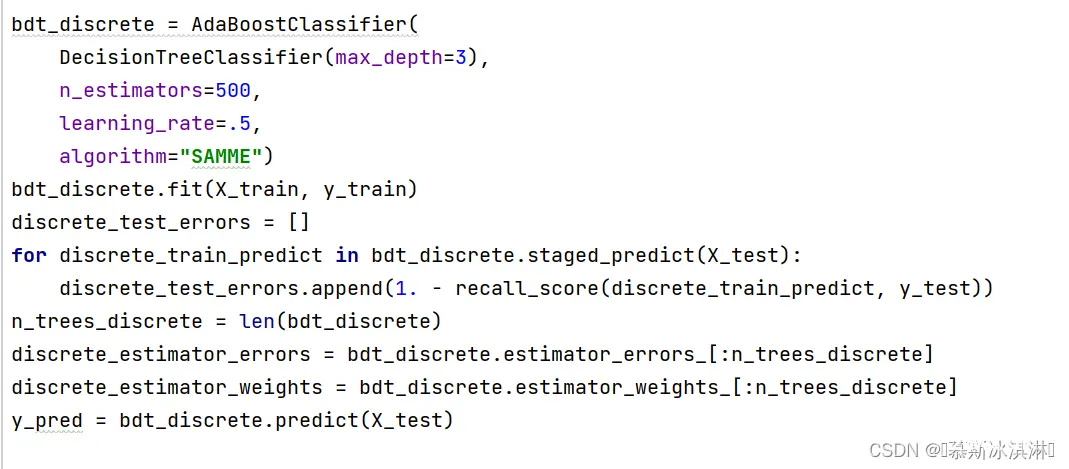
图4.2 准确率和查全率随训练过程变化
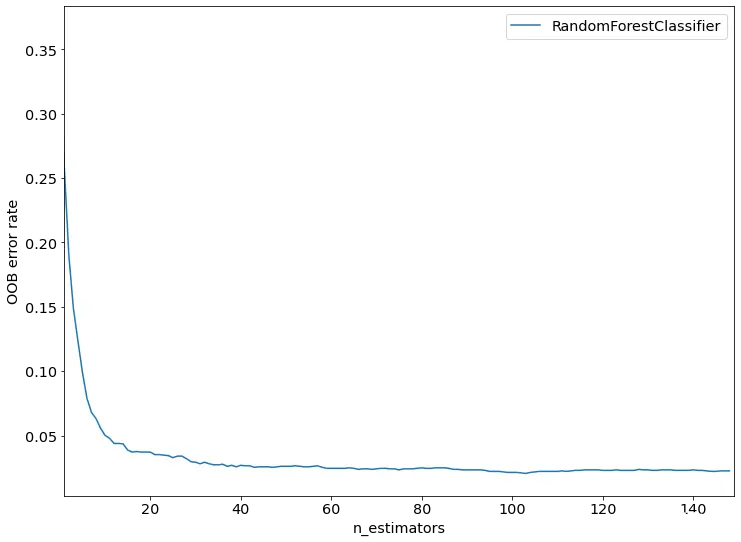
为了评估随机森林的模型性能,绘制其袋外误差(OOB error rate)曲线,如下图4.3所示。
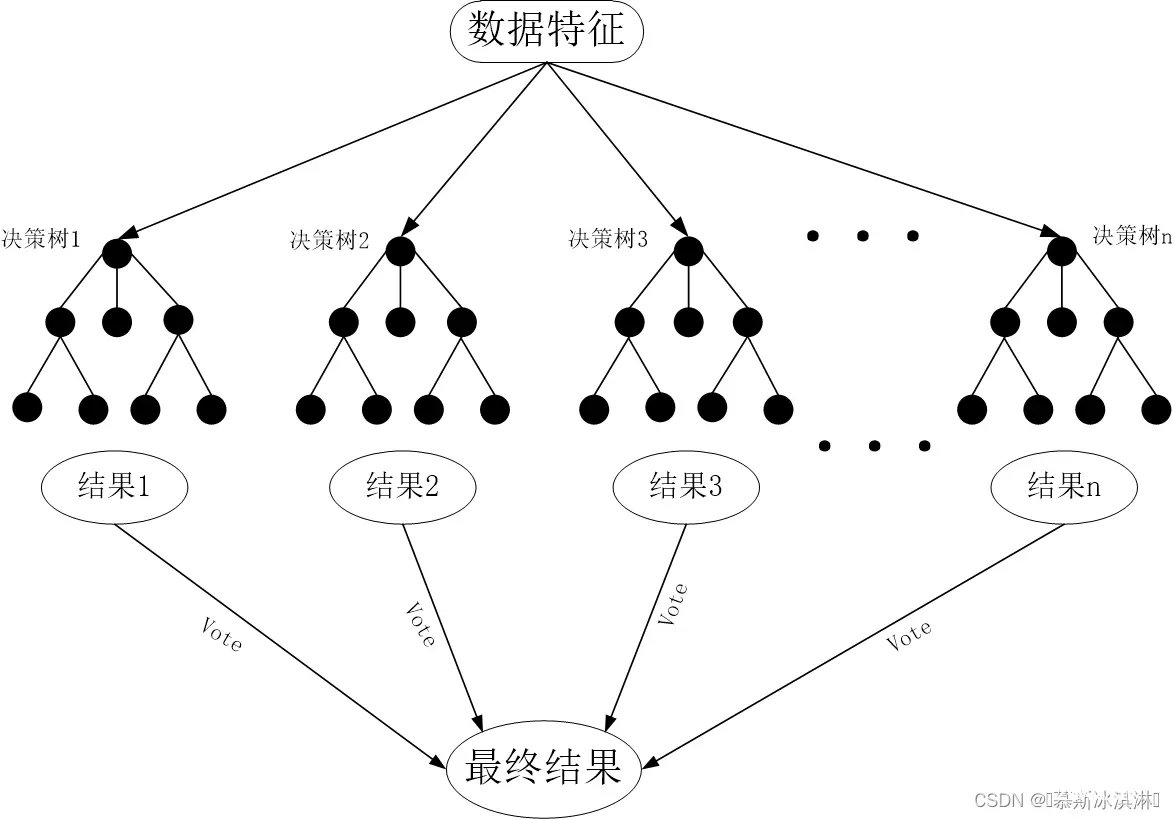
图4.3随机森林模型OOB错误率曲线
可以从上图(图4.3)看到随着评估器的增加,模型的误差逐渐下降,在超过100个评估器之后,基本达到最低值,其后下降趋势放缓,并趋于稳定。
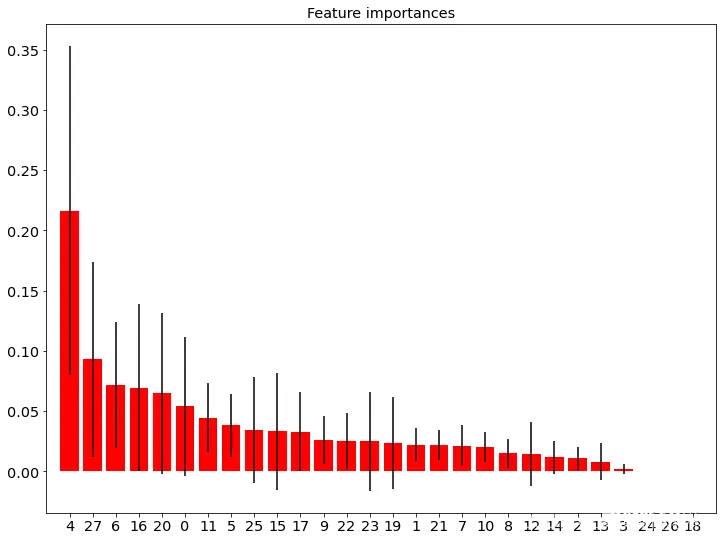
模型的目标是找到不及格学生,即标识存在学习失败风险的学生,所以在网格搜索过程中,优化指标选择为查全率(Recall)作为参数确认依据,使得训练之后得到分类模型尽可能识别不及格学生的特征。classifier是随机森林的最优子树,其feature_importances_属性表示重要的特征列表,按列(X.shape[1])遍历输入特征,输出其特征列号及重要度的值,如下图:
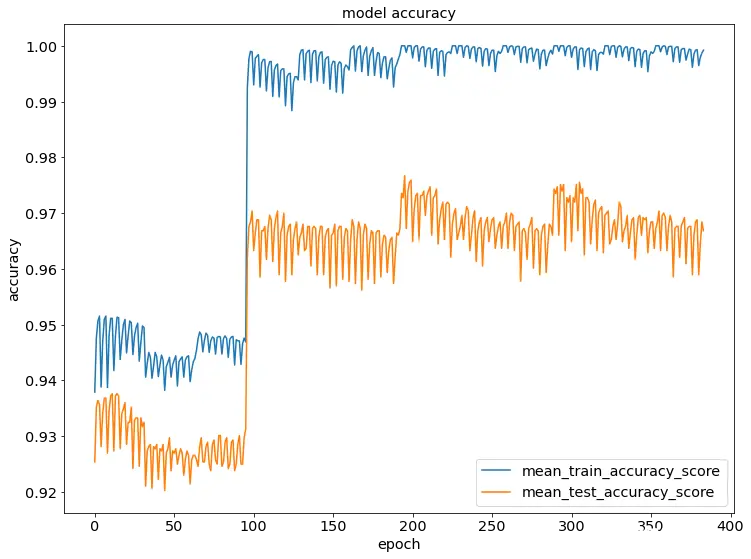
图 4.4 输入特征重要性分析
由上图(图4.4)可知,模型中前3个特征分别是课程实践平均成绩,形考成绩,作业答题数、浏览次数。
计算不同算法在准确率、查全率、F1值、AUC值指标。
| 表4.2 不同算法结果比较
| ||||
| 算法
| 准确率
| 查全率
| F1值
| AUC值
|
| SVM
| 0.892026578
| 0.820895522
| 0.628571429
| 0.860915051
|
| 逻辑回归
| 0.892026578
| 0.835820896
| 0.632768362
| 0.938624634
|
| AdaBoost
| 0.945182724
| 0.805970149
| 0.765957447
| 0.975282466
|
| 随机森林
| 0.943521595
| 0.805970149
| 0.76056338
| 0.97669131
|
由表4.2可知,可以看到随机森林算法在查全率上不如逻辑回归算法和支持向量机算法,F1值次于AdaBoost,但是其准确率和AUC值最高,达到94.35%,具有较强的实用价值,所以最终我们认为采用随机森林算法和AdaBoost算法作为模型均可获得良好的效果。
五、总结
此次选题的启发来源是在步入大三时,见到很多学生被辅导员谈话,谈及其学业预警的情况,故而想到做这一个题目。想要在平时就对学生行为进行分析并及时提醒,避免在毕业时面临毕业预警问题。同时,在本学期学习到很多机器学习的算法,想弄清楚是否每一种算法的优缺点以及哪种算法能够有较好的预测效果。
本课题介绍了学习失败预警通过多种分类算法的实现,使用的分类算法有:随机森林算法、支持向量机算法、逻辑回归和AdaBoost算法,在没有开始实验前,本以为AdaBoost集成算法会是其中最好的算法,但通过比对以上多种算法的运行结果后,对于学习失败预警较好的两种算法是AdaBoost算法和随机森林算法。
在本课题代码实现时,在随机森林在测试阶段遇到了数据编码问题、数据类型错误和数据
本课题所应用的分类算法只是机器学习中的一部分,随着机器学习算法和技术的不断发展,也许对于学习失败预警的实现会有更好算法。学习失败预警通过对现有的数据进行数据预处理和分类操作,然后对进行预测处理得到预警数据集,该数据集可以准确地反映出学生的学习状态,有效的促进学生的学习积极性和自觉性,提高教师的教学质量。
六、参考文献
[1]丁世飞 史忠植.人工智能导论.中国工息出版社,电子公工业出版社,2021(09):16-21.
[2]薛薇.Python机器学习数据建模与分析.机械工业出版社,2023.
[3]CSDN开放平台.https://blog.csdn.net. 2023.
[4]赵卫东 董亮.Python机器学习案例(第二版).清华大学出版社, 2022.
[5] 赵卫东 董亮.机器学习[M].北京:人民邮电出版社,2018.
[6]周志华.机器学习[M].北京:清华大学出版社,2016.
[7] Miroslav Kubat.机器学习导论[M].王勇,仲国强,孙鑫,译.北京:机械工业出版社,2016.
上一篇: 翻译: 详细图解Transformer多头自注意力机制 Attention Is All You Need
下一篇: 【工具】创客贴会员|创客贴截止2024年6月所有AI功能效果实测(热门推荐和图片编辑部分)
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。