Jina AI 发布 Reader-LM-0.5B 和 Reader-LM-1.5B:为网络数据处理提供多语种、长语境和高效小语言模型,彻底改变 HTML 到 Markdown 的转换方式
吴脑的键客 2024-10-04 08:01:04 阅读 85
Jina AI 发布的 Reader-LM-0.5B 和 Reader-LM-1.5B 标志着小语言模型 (SLM) 技术的一个重要里程碑。这些模型旨在解决一个独特而具体的挑战:将开放网络中原始、嘈杂的 HTML 转换为干净的标记符格式。这项任务看似简单,却面临着复杂的挑战,尤其是在处理现代网络内容中的大量噪音(如页眉、页脚和侧边栏)时。Reader-LM 系列旨在高效地应对这一挑战,重点关注成本效益和性能。

背景和目的
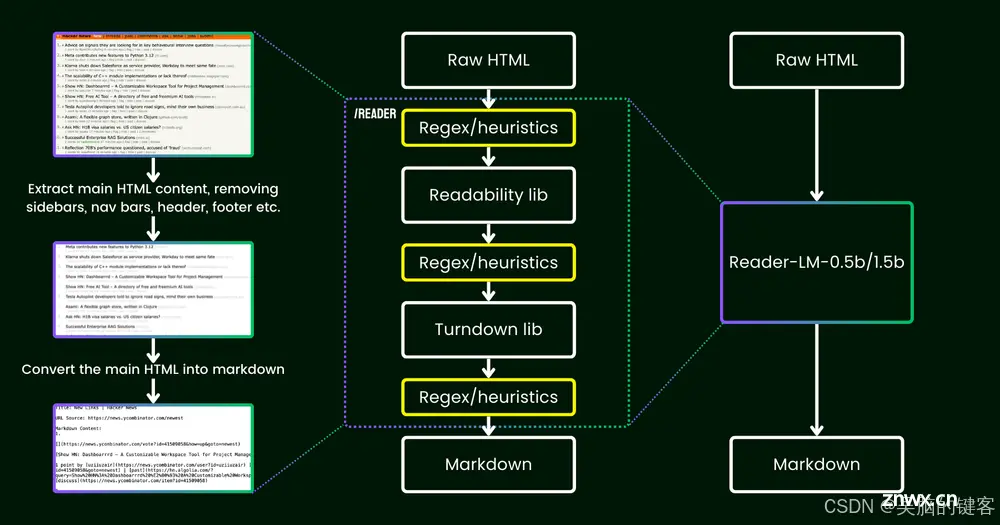
2024 年 4 月,Jina AI 推出了 Jina Reader,这是一个可以将任何 URL 转换为适合大型语言模型(LLM)的标记符的 API。该 API 依赖 Mozilla 的可读性软件包等工具来提取网页的主要内容,然后使用 regex 和 Turndown 库将清理后的 HTML 转换为 markdown。然而,这种方法也面临着一些问题,例如内容过滤不正确以及难以转换复杂的 HTML 结构。随着用户反馈的不断涌现,Jina AI 意识到用更多的 regex 模式和启发式方法对现有管道进行修补并不是一个可持续的解决方案。
为了克服这些限制,Jina AI 提出了一个重要问题:能否使用语言模型端到端解决这个问题?语言模型可以更高效地处理 HTML 到标记符的转换任务,尤其是在参数少于十亿的情况下,使其可以在边缘运行,而不是依赖于人工编辑的规则。
Reader-LM 模型介绍
Jina AI 发布了两个小型语言模型:Reader-LM-0.5B 和 Reader-LM-1.5B。这两个模型经过专门训练,可以将原始 HTML 转换为标记符,而且都是多语言模型,支持多达 256K 字节的上下文长度。这种处理大型上下文的能力至关重要,因为现代网站的 HTML 内容通常包含比以往更多的噪音,内联 CSS、JavaScript 和其他元素都会使标记数大幅增加。
大型语言模型以计算要求高而著称,而像 Reader-LM 这样的小型语言模型则旨在提供高效的性能,而无需昂贵的基础设施。Reader-LM-0.5B 和 Reader-LM-1.5B 在 HTML 到标记符的转换这一特定任务中的表现优于许多大型模型,而体积却只有它们的几分之一。
结构和规格
Reader-LM 模型旨在处理长文本输入,并执行从 HTML 到 markdown 的选择性复制。这项任务比典型的 LLM 功能(如文本生成或代码编写)更简单。这种选择性复制行为主要侧重于识别相关内容,跳过不必要的元素(如侧边栏和标题),并以 markdown 语法格式化剩余内容。
型号规格
Reader-LM-0.5B:拥有 4.94 亿个参数,具有 24 层、896 个隐藏尺寸和 14 个查询头。它结构紧凑,但能高效处理选择性复制任务。Reader-LM-1.5B:这个较大的模型有 15.4 亿个参数、28 层、1536 个隐藏大小和 12 个查询头。它的性能优于较小的模型,尤其是在处理更复杂的 HTML 结构时。
这两种型号都支持高达 256K 标记的上下文长度,这对于处理网络上常见的冗长、嘈杂的 HTML 内容至关重要。它们处理多语言内容的能力使其成为通用的全球应用工具。
绩效与基准
阅读器-LM-0.5B 和阅读器-LM-1.5B 的性能已经过与几个大型语言模型的严格评估,包括 GPT-4o、Gemini-1.5-Flash、LLaMA-3.1-70B 和 Qwen2-7BInstruct。这些模型通过 ROUGE-L(用于摘要和问题解答任务)、Token Error Rate(TER,用于测量幻觉内容的比率)和 Word Error Rate(WER,用于评估生成的标记符与原始 HTML 之间的不匹配情况)等指标进行了测试。
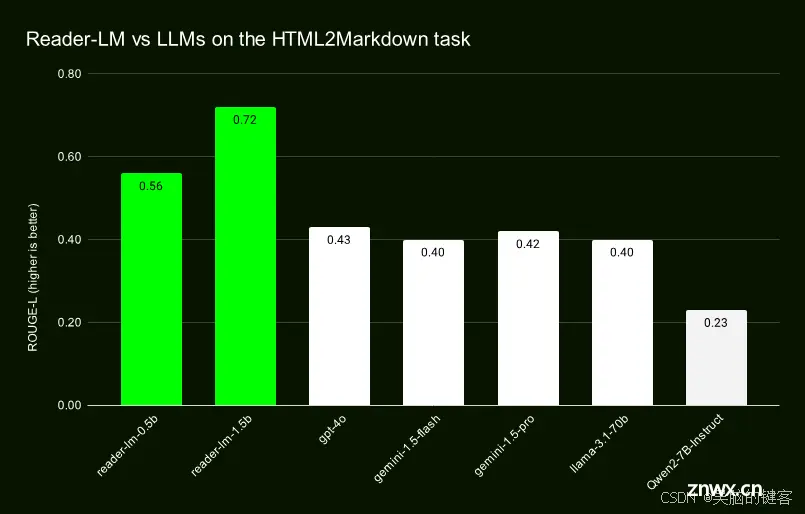
在这些评估中,Reader-LM 模型在从 HTML 生成干净、准确的降价方面优于许多大型模型。例如,Reader-LM-1.5B 的 ROUGE-L 得分为 0.72,WER 为 1.87,TER 为 0.19,明显优于 GPT-4o 和其他被测模型。Reader-LM-0.5B 虽然规模较小,但也取得了具有竞争力的结果,尤其是在结构保留任务中,这对于将 HTML 转换为标记符至关重要。
| ROUGE-L | WER | TER | |
|---|---|---|---|
| reader-lm-0.5b | 0.56 | 3.28 | 0.34 |
| reader-lm-1.5b | 0.72 | 1.87 | 0.19 |
| gpt-4o | 0.43 | 5.88 | 0.50 |
| gemini-1.5-flash | 0.40 | 21.70 | 0.55 |
| gemini-1.5-pro | 0.42 | 3.16 | 0.48 |
| llama-3.1-70b | 0.40 | 9.87 | 0.50 |
| Qwen2-7B-Instruct | 0.23 | 2.45 | 0.70 |
定性研究
我们通过目测输出的标记符进行了定性研究。 我们选取了 22 个 HTML 源,包括新闻文章、博客文章、登陆页面、电子商务页面和论坛帖子,使用多种语言: 我们选择了 22 种 HTML 源,包括新闻文章、博客帖子、登陆页面、电子商务页面和论坛帖子,语言包括英语、德语、日语和中文。 我们还将 Jina Reader API 作为基线,它依赖于 regex、启发式和预定义规则。
评估的重点是产出的四个关键方面,每个模式的评分从 1 分(最低)到 5 分(最高)不等:
标题提取: 评估每个模型如何使用正确的 markdown 语法识别文档的 h1、h2…、h6 标题并将其格式化。主要内容提取: 评估模型在准确转换正文、保留段落、格式化列表和保持表述一致性方面的能力。丰富的结构保持: 分析每种模式如何有效地保持文档的整体结构,包括标题、小标题、要点和有序列表。Markdown 语法用法: 评估每个模型正确转换 HTML 元素(如 <code><a>超链接,<strong>粗体和<em> 斜体转换成相应的markdown标记符。
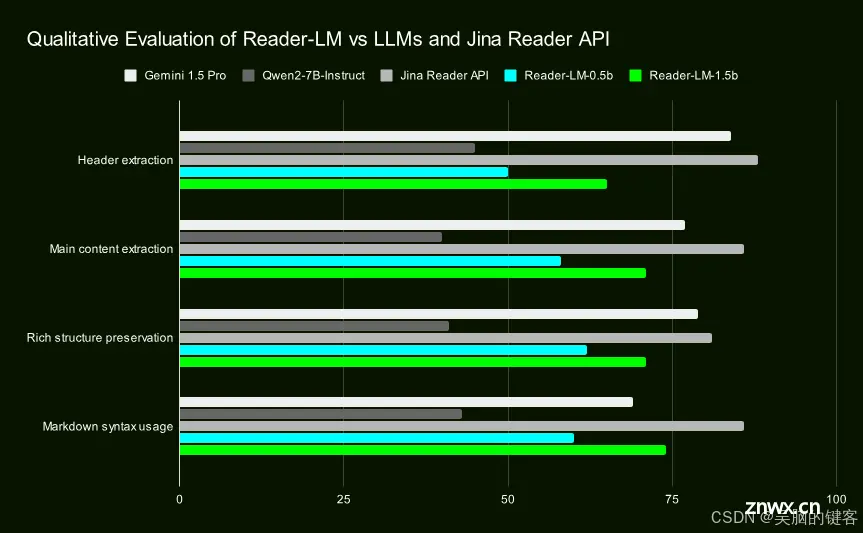
Reader-LM-1.5B 在所有方面都表现出色,尤其是在结构保持和标记符语法使用方面。 虽然它的性能并不总是优于 Jina Reader API,但与 Gemini 1.5 Pro 等大型机型相比,它的性能还是有竞争力的,因此它是大型 LLM 的高效替代品。 Reader-LM-0.5B 虽然体积较小,但仍能提供稳定的性能,尤其是在结构保护方面。
训练与开发
训练 Reader-LM 模型需要准备高质量的原始 HTML 数据对和相应的标记符。Jina AI 使用其现有的 Jina Reader API 生成了这些数据,并使用 GPT-4o 生成的合成 HTML 作为补充,用于训练目的。最终的训练数据集包含约 25 亿个标记。
模型的训练分为两个阶段:
简短 HTML:这一阶段涉及多达 32K 标记和 15 亿个训练标记。长而难的 HTML:在这一阶段,序列扩展到 128K 标记和 12 亿个训练标记。这一阶段的主要创新是使用 “之字形环形关注机制”,从而改进了长文本处理。
尽管 HTML 到标记符的转换非常复杂,但我们对模型进行了优化,以有效地处理这项任务,同时避免不必要的计算开销。它们利用对比搜索等技术,防止标记符退化和标记符生成过程中的重复循环。
<code>pip install transformers<=4.43.4
jinaai/reader-lm-0.5b
# pip install transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "jinaai/reader-lm-0.5b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
# example html content
html_content = "<html><body><h1>Hello, world!</h1></body></html>"
messages = [{ "role": "user", "content": html_content}]
input_text=tokenizer.apply_chat_template(messages, tokenize=False)
print(input_text)
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)code>
outputs = model.generate(inputs, max_new_tokens=1024, temperature=0, do_sample=False, repetition_penalty=1.08)
print(tokenizer.decode(outputs[0]))
jinaai/reader-lm-1.5b
# pip install transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "jinaai/reader-lm-1.5b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
# example html content
html_content = "<html><body><h1>Hello, world!</h1></body></html>"
messages = [{ "role": "user", "content": html_content}]
input_text=tokenizer.apply_chat_template(messages, tokenize=False)
print(input_text)
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)code>
outputs = model.generate(inputs, max_new_tokens=1024, temperature=0, do_sample=False, repetition_penalty=1.08)
print(tokenizer.decode(outputs[0]))
实际应用
Reader-LM 专为个人和企业环境的实际应用而设计。使用 Google Colab 可以轻松测试模型,而生产环境则可以利用 Azure 和 AWS 等平台,这些平台很快就会提供模型。Reader-LM 采用 CC BY-NC 4.0 许可,并为寻求内部部署解决方案的公司提供商业使用选项。
这些模型非常适合在生产环境中自动从开放网络中提取和清理数据。通过将原始 HTML 转换为简洁的标记符,Reader-LM 实现了高效的数据处理,使下游 LLM 更容易从网络内容中总结、推理和生成见解。此外,Reader-LM 的多语言功能还使其适用于各个行业和地区。
结论
Reader-LM-0.5B 和 Reader-LM-1.5B 的发布代表了小语言模型技术的飞跃,专门为 HTML 到标记符的转换而量身定制。这些模型满足了从嘈杂且往往令人难以承受的网络内容中高效、经济地提取数据的关键需求,而这正是现代互联网的特点。Reader-LM 模型体积小巧,支持长文本和多语言功能,为希望优化数据工作流程的开发人员和企业提供了强大的工具。
资料
https://jina.ai/news/reader-lm-small-language-models-for-cleaning-and-converting-html-to-markdown/
下一篇: Xinference 安装使用(支持CPU、Metal、CUDA推理和分布式部署)
本文标签
彻底改变 HTML 到 Markdown 的转换方式 Jina AI 发布 Reader-LM-0.5B 和 Reader-LM-1.5B:为网络数据处理提供多语种、长语境和高效小语言模型
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。