AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
CSDN 2024-06-11 15:31:03 阅读 67
系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
目录
系列篇章💥一、HuggingFace介绍二、HuggingFace核心模块之Models1、Multimodal(多模态大模型)2、Computer Vision(计算机视觉任务)3、Natural Language Processing(自然语言处理)4、Audio(音频模型)5、其他模型 三、HuggingFace核心模块之datasets四、HuggingFace核心模块之docs五、HuggingFace组件使用代码样例
一、HuggingFace介绍
在HuggingFace的官方网站上,你可以发现一个丰富的开源宝库,其中包含了众多机器学习爱好者上传的精选模型,供大家学习和应用。此外,你也可以将自己的模型分享至社区,与他人共同进步。HuggingFace因其开放和协作的精神被誉为机器学习界的GitHub。在这里,用户能够轻松获取到Transformers库里各式各样的组件资源,助力各类机器学习项目的实现和发展。
1)HuggingFace的核心库是Transformers,这个库集成了各种预训练模型、分词器和相应的工具。通过这个库,用户可以方便地加载和使用这些模型,进行文本分类、命名实体识别、情感分析等任务。
2)HuggingFace还提供了许多微调模型,这些模型针对特定任务进行了优化。用户可以直接使用这些模型,或者在其基础上进一步微调,以适应特定的应用场景。
3)HuggingFace的datasets库汇集了大量多样化的数据集资源,这为训练和评估AI大模型提供了便利。用户可以通过这个库轻松地下载和使用各种数据集,无需自己收集和整理数据。
总的来说,HuggingFace为AI大模型的学习提供了强大的支持,使得从数据准备到模型训练和部署的整个过程变得更加简单和高效。
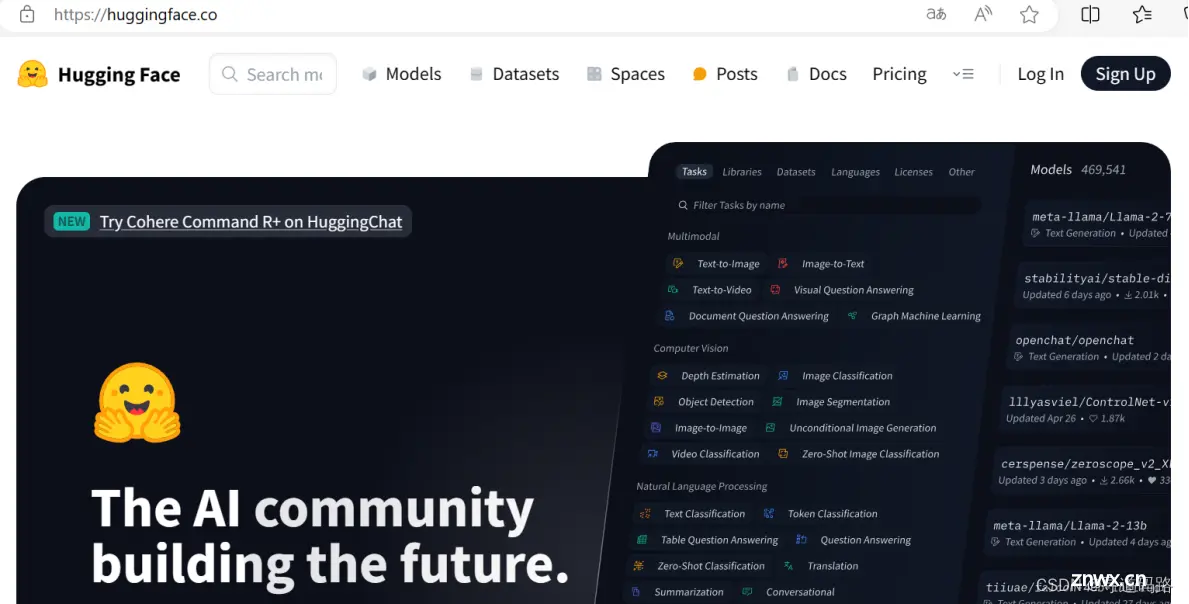
下面主要说明介绍平时AI大模型开发过程中经常使用到的三个菜单模块。
二、HuggingFace核心模块之Models
Models模块提供有各种类型的大模型,可以远程拉取或者下载到本地进行机器学习使用。
1、Multimodal(多模态大模型)

1)Image-Text-to-Text(图文转文本):能够处理图像和文本输入,并生成相关文本输出的多模态模型
2)Visual Question Answering(视觉问答):能够回答关于所提供图像的问题,这需要模型同时理解图像内容和问题文本。
3)Document Question Answering(文档问答):是一种基于自然语言处理技术,用于分析和理解文档内容以回答用户提出的问题的系统。
2、Computer Vision(计算机视觉任务)
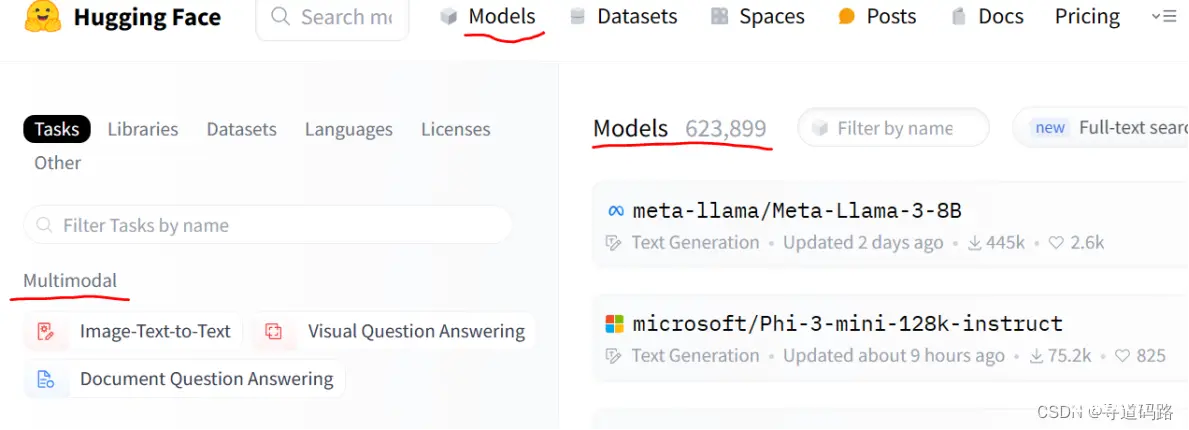
1)lmage Classification(图像分类):此任务的目标是将图像分配到预定义的类别中,例如区分图片中是猫还是狗。这通常涉及到识别图像中的全局特征,并使用这些特征来预测所属类别。
2)lmage Segmentation(图像分割):在图像分割中,目标是将图像划分成多个区域或对象。这些区域通常对应于图像中的不同物体或场景的不同部分,例如将一幅风景画中的树木、天空和草地区分开来。
3)Image-to-Text(图像到文本的任务):该任务的目的是描述或解释给定的图像内容,通常用于自动图像标注或辅助视觉障碍人士理解图片。
4)lmage-to-Image(图像到图像的任务):涉及将输入图像转换为具有特定风格或内容的输出图像,同时保留其识别特征。这包括风格转换、图像修复、图像上色等。
5)lmage-to-Video(图像到视频的任务):这个领域不如其他计算机视觉任务那么发达,但它涉及到从单一图像创建视频序列,通常需要结合深度学习和视频处理技术。
6)zero-Shot lmage Classification(零样本图像分类):这是一种特殊类型的图像分类,其中模型需要识别它未见过类的图像。它依赖于模型对类别之间关系的理解,以及利用未见类别的语义属性进行分类。
7)Unconditional lmage Generation(无条件图像生成):在此任务中,系统生成全新的图像,而不是基于现有图像。这通常是通过学习大量图像数据集的分布来实现的。
8)Object Detection(目标检测):与图像分类不同,目标检测不仅需要识别图像中的对象是什么,还要确定它们在图像中的位置。这通常涉及到定位对象的边界框。
9)Video Classification(视频分类):类似于图像分类,但在处理视频时,需要考虑时间维度,识别视频中的动作或者活动类型。
10)**Depth Estimation(深度估计,估计拍摄者距离图像各处的距离) **:这个任务旨在估计图像中每个像素的深度值,从而可以推断出场景中各个对象与观察者之间的距离。
3、Natural Language Processing(自然语言处理)

1)Translation (机器翻译):机器翻译模型能够将一种语言的文本自动翻译成另一种语言。这通常涉及到复杂的算法和大规模的双语数据集来训练模型,以便它能够理解上下文并产生流畅、准确的翻译。
2)Fill-Mask (填充掩码,预测句子中被遮掩的词):在预训练语言模型如BERT时常用的任务,其中句子中的一部分单词被掩码遮盖,模型的目标是预测被遮盖的单词。这有助于模型学习双向语境表示。
3)Token Classification (词分类):这种模型对输入文本中的每个单词或标记进行分类,通常用于命名实体识别、情感分析等任务,可以给每个词赋予一个或多个类别标签。
4)Sentence Similarity (句子相似度): 句子相似度模型旨在评估两个句子之间的语义相似程度。它们广泛用于信息检索、自然语言推理等领域。
5)Question Answering (问答系统):问答系统能够回答自然语言形式的问题。这通常需要理解问题的语义,并在给定的数据源中查找或生成答案。
6)Summarization (总结,缩句): 摘要或缩写模型的目的是从较长的文本中生成简短而准确的摘要。这可以是抽取式摘要,直接选取原文的关键部分,或是生成式摘要,重新组织和创造新的句子。
7) Zero-Shot Classification (零样本分类):零样本分类是在未见过的类别上进行分类的任务,无需直接的训练数据。它依赖于模型对类别描述的理解以及跨类别的关系推断能力。
8)Text Classification (文本分类):文本分类是将整个文本或文档分配到一个或多个类别的任务。常见的应用包括垃圾邮件检测、新闻分类、情感分析等。
9)Text2Text (文本到文本的生成):文本到文本的生成模型涉及将一种形式的文本作为输入,并生成另一种形式的文本作为输出。例如,可以将新闻报道转换为摘要,或者将一种语言的文本翻译成另一种语言。
10)Text Generation (文本生成):文本生成是创建自然语言文本的过程,不局限于已有的输入。典型的应用包括诗歌、故事创作,或者根据一定提示生成响应的文本。
11)Conversational (聊天):聊天模型设计用于进行对话,可以是与人类用户或另一个AI系统。它们通常需要理解和回应自然语言对话中的上下文。
12)Table Question Answering:表问答系统能够回答与表格数据相关的问题。这可能涉及预测表格中被遮掩的单词,或者使用表格数据来回答问题,判断句子是否被表格数据支持。
4、Audio(音频模型)
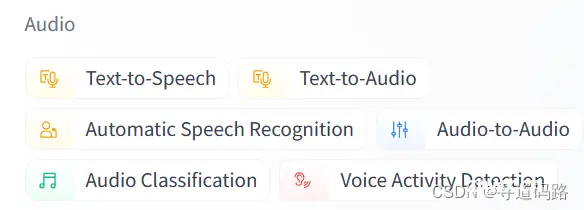
1)**Text-to-Speech (TTS) **: 这种模型将文本信息转换为听起来类似人声的音频输出。这通常涉及自然语言处理和数字信号处理技术,目的是创造自然听起来的合成语音。
2)Text-to-Audio(文本到语音): 类似于Text-to-Speech,这也是将文本转换成音频,但可能更泛指各种将文字信息转换为任何形式的音频输出的过程,包括非语音内容。
3) Automatic Speech Recognition (语音识别): 这是将人类语音转换为机器可读的文本格式的过程,通常用于语音识别系统,如智能助手和语音转文本服务。
4) Audio-to-Audio(语音到语音): 这指的是一种音频处理任务,其中输入是一种形式的音频信号,经过处理后输出为另一种形式的音频信号。这可能涉及到声音的修改、转换或增强。
5) Audio Classification(语音分类): 这个任务涉及对不同类别的音频样本进行分类,例如区分环境中的不同声音(如车辆噪音、动物叫声等)。
6)Voice Activity Detection (声音检测、检测识别出需要的声音部分): VAD是检测音频中哪些部分包含语音活动,哪些部分是静音或其他非语音活动的过程。这是语音处理中的一个重要步骤,常用于识别对话中的停顿和说话者变换。
5、其他模型

1)Tabular Classification(表分类): 在表格数据上进行分类任务,使用结构化数据(通常是行和列形式的表格)来预测离散标签或类别。
2)Tabular Regression(表回归): 使用表格数据进行回归分析,根据数值特征预测连续变量的值。
3)Reinforcement Learning (强化学习): 这是一种机器学习范式,其中算法通过与环境的交互学习如何采取最佳行动以最大化累积奖励。它不同于监督学习和非监督学习,因为它不依赖于预先标记的数据集,而是通过试错法自主学习。
4)Robotics(机器人): 虽然机器人技术本身不是机器学习模型,但强化学习在机器人领域有着广泛的应用,例如用于导航、操作和决策制定。
5)Graph Machine Learning(图机器学习): 图机器学习是指应用机器学习方法来分析和推断图结构数据的任务。图数据由节点(实体)和边(关系)组成,可以用来表示社交网络、分子结构、知识图谱等复杂结构。图机器学习模型旨在从这些图中提取有用的信息和模式。
三、HuggingFace核心模块之datasets
在datasets菜单模块中,对于我们常用的大模型,都有提供相应的数据集,可供研究学习。
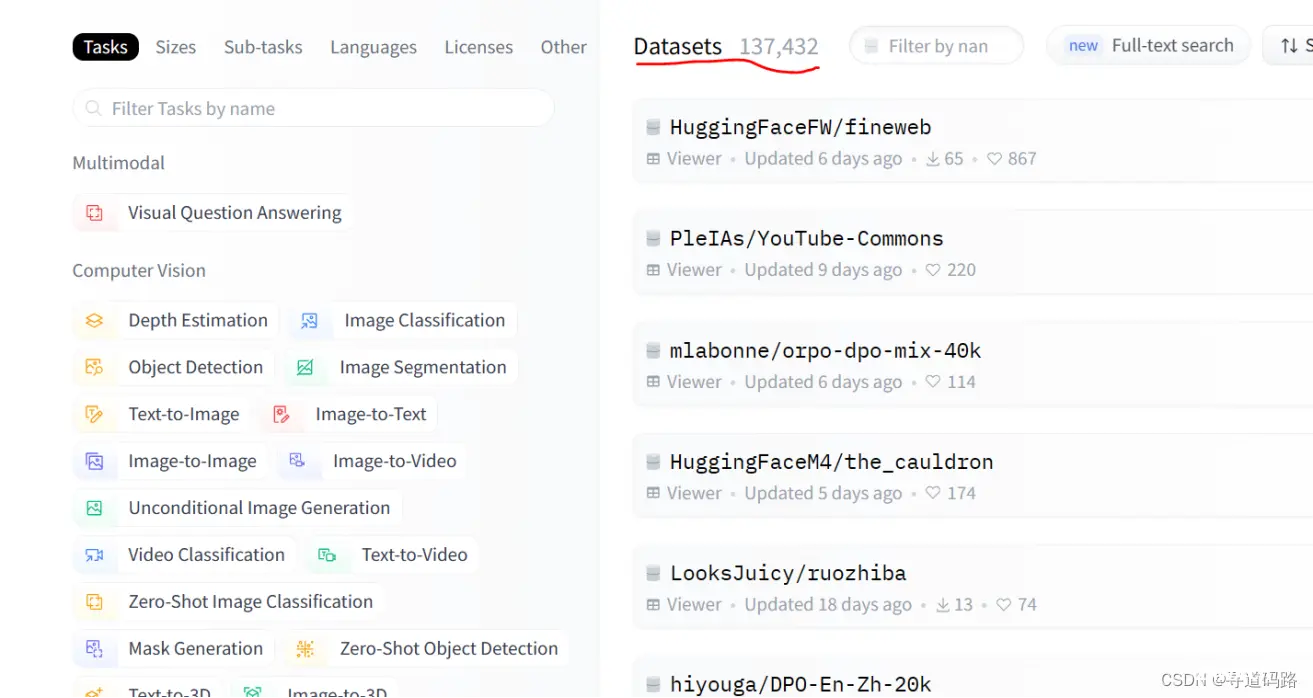
四、HuggingFace核心模块之docs
Hugging Face官网的docs模块放置的是官方文档。
这些文档为用户提供了关于如何使用Hugging Face提供的库和模型的详细说明,包括但不限于安装指导、快速开始指南、教程、API参考等。具体如下:
安装:指导用户如何安装必要的库和工具,以便开始使用Hugging Face的平台和模型。快速开始:提供简要的入门指南,帮助用户迅速理解和实践基本功能。教程:更深入的指导,包括如何使用pipeline进行推理、使用AutoClass编写可移植代码以及数据预处理等。调优:介绍如何对预训练模型进行微调,以适应特定的任务或数据集。 API参考:详细列出了库中各种类和方法的功能、参数和使用示例
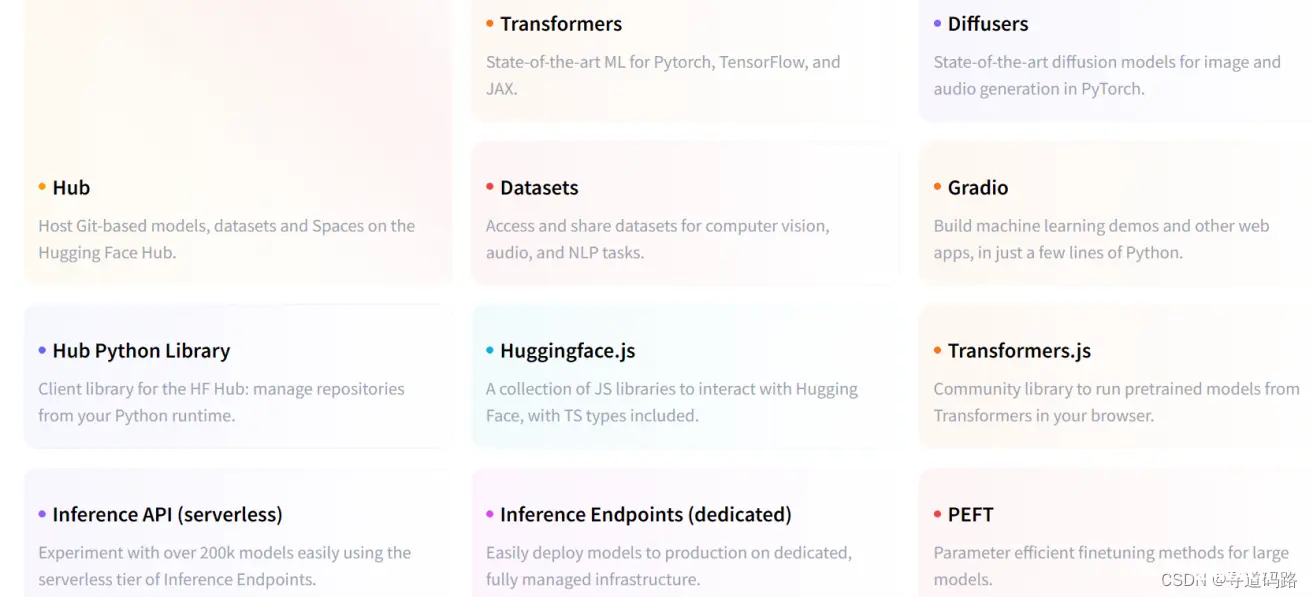
Hub:Hub是Hugging Face推出的一种服务,用于托管基于Git的模型、数据集和Spaces(可能是一个共享空间,供用户存储和协作)。
1)Transformers:这是一套先进的机器学习库,支持Pytorch、TensorFlow和JAX框架,专注于Transformer模型。
2)Diffusers:Diffusers提供了用于图像和音频生成的先进扩散模型,基于PyTorch框架。
3)Datasets:这个服务允许用户访问和分享计算机视觉、音频和自然语言处理任务的数据集。
4)Gradio:Gradio是一个工具,使用户可以用几行Python代码构建机器学习演示和其他网络应用程序。
5)PEFT:PEFT提供了一系列参数高效的微调方法,适用于大模型。
五、HuggingFace组件使用代码样例
1、安装依赖
pip install transformerspip install tokenizerspip install datasets
2、从HuggingFace拉取下载大模型:
from transformers import AutoModel, AutoTokenizer# 指定模型名称model_name = "bert-base-uncased"# 自动加载分词器和模型tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModel.from_pretrained(model_name)
3、从HuggingFace下载使用数据集:
from datasets import load_dataset# 指定数据集名称dataset_name = "imdb"# 加载数据集dataset = load_dataset(dataset_name)

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
上一篇: Unity 工具“常用插件九大分类汇总”(UI/VR/AR/建模/Shader/动画/网络/AI/资源/数据/区块链等)
下一篇: 【数据库】数据库的介绍、分类、作用和特点,AI人工智能数据如何存储
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。