2025计算机视觉领域顶会新方向!
沃恩智慧 2024-10-22 11:01:01 阅读 83
作为计算机视觉领域的顶级学术会议CVPR,每年评选出的一篇或多篇最佳论文,不仅为计算机视觉领域的顶级学术荣誉,更代表了将对未来技术或行业发展产生重要影响的里程碑式研究成果。
今年的CVPR最佳论文近乎“万里挑一”。CVPR 2024 今年一有效投稿 11532 篇,接收 2719篇。根据最新公示的组委会安排,今年的 Oral 部分有 24 篇将有资格角逐今年的最佳论文。
为了帮助大家对这批计算机领域的重要论文进行复习,沃恩智慧整理了2024 年的 CVPR 24篇入选最佳论文,这些论文也都下载好了。
关注公号《沃的顶会》
回复“最佳论文24”即可全部领取

2024年最佳论文列表
视觉与图形
Objects as Volumes: A Stochastic Geometry View of Opaque Solids
概述:论文提出了一种不透明固体表示为体积的理论。从不透明固体作为随机指示函数的随机表示出发,证明了使用指数体积输运来模拟此类固体的条件。该论文还导出了作为潜在指示函数概率分布函数的体积衰减系数的表达式。
单视图 3D
Repurposing Diffusion-Based lmage Generators for Monocular Depth Estimation
概述:论文介绍了Marigold,一种基于稳定扩散的仿射不变单目深度估计方法,它保留了丰富的先验知识。仅使用合成训练数据,即可在几天内在单个GPU上对估计器进行微调。它在广泛的数据集上提供了最先进的性能,包括在特定情况下超过20%的性能提升。

Comparing the Decision-Making Mechanisms by Transformers and CNNs via Explanation Methods
概述:为了深入了解不同视觉识别主干的决策,该论文提出了两种方法,即子解释计数和交叉测试,在数据集范围内系统地应用深度解释算法,并比较解释的数量和性质产生的统计数据。这些方法从组合性和析取性两个属性方面揭示了网络之间的差异。变形金刚(Transformers)和ConvNeXt(ConvNeXt)被发现更具成分性,因为它们在构建决策时共同考虑了图像的多个部分。
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
概述:论文提出了MMMU:一种新的基准,旨在评估大规模多学科任务的多模式模型,这些任务需要大学水平的学科知识和深思熟虑的推理。与现有的基准不同,MMMU专注于利用特定领域的知识进行高级感知和推理,挑战模型执行类似于专家所面临的任务。对14种开源LMM以及专有的GPT-4V(vision)和Gemini的评估突出了MMMU带来的巨大挑战。即使是先进的GPT-4V和Gemini Ultra也只能分别达到56%和59%的准确率,这表明还有很大的改进空间。
关注公号《沃的顶会》
回复“最佳论文24”即可全部领取
基于医学和物理学的视觉
EventPS. Real-Time Photometric Stereo Using an Event Camera
概述:本文介绍了一种使用事件摄像机实现实时光度立体的新方法EventPS。EventPS利用事件摄像机的特殊时间分辨率动态范围和低带宽特性,仅根据辐射变化估计表面法线,显著提高了数据效率。大量实验验证了EventPS与基于框架的对等软件相比的有效性和效率。该文的算法在真实场景中以超过30 fps的速度运行,在对时间敏感的高速下游应用程序中释放EventPS的潜力。
MemSAM: Taming Segment Anything Model for Echocardiography Video Segmentation
概述:论文提出了一种新的超声心动图视频分割模型,通过将SAM应用于医学视频来解决超声视频分割中的一些长期挑战,模型的核心技术是时间感知和噪声弹性提示方案。使用一个时空包含空间和时间信息的存储器,用于提示当前帧的分割,从而将所提出的模型称为MemSAM。要解决针对散斑噪声的挑战,进一步提出了一种记忆增强机制,该机制利用了预测的掩码,以在存储内存之前提高内存质量。
Correlation-aware Coarse-to-fine MLPs for Deformable Medical lmage Registration
概述:论文提出了第一个用于可变形医学图像配准的基于相关感知MLP的配准网络(CorrMLP)。该文的CorrMLP在一种新的粗到精注册体系结构中引入了一个相关感知的多窗口MLP块,该块捕获细粒度的多范围依赖,以执行相关感知的粗到细注册。对七个公共医疗数据集的大量实验表明,CorrMLP优于最先进的可变形注册方法。
自主导航和自我中心视觉
Producing and Leveraging Online Map Uncertainty in Trajectory Prediction
概述:该论文扩展了多种最先进的在线地图估计方法,以额外估计不确定性和展示如何将在线地图ping与轨迹预测更紧密地集成。并发现结合不确定性可使训练速度提高50%收敛性和高达15%的预测性能在真实世界的nuScenes驾驶数据集上。
关注公号《沃的顶会》
回复“最佳论文24”即可全部领取
3D
SpiderMatch: 3D Shape Matching with Global Optimality and Geometric Consistency
概述:该论文提出一种新颖的基于路径的形式主义3D形状匹配。更具体地说是考虑一种替代形状离散化,其中一个3D形状(源形状)表示为SpiderCurve,即长的自相交曲线,在表面上追踪3D形状。然后,将3D形状匹配问题处理为在蜘蛛曲线和目标3D形状的乘积图中找到最短路径。该方法引入确保全局几何一致匹配的一组新颖约束,实验证明它可以有效地求解为globa。
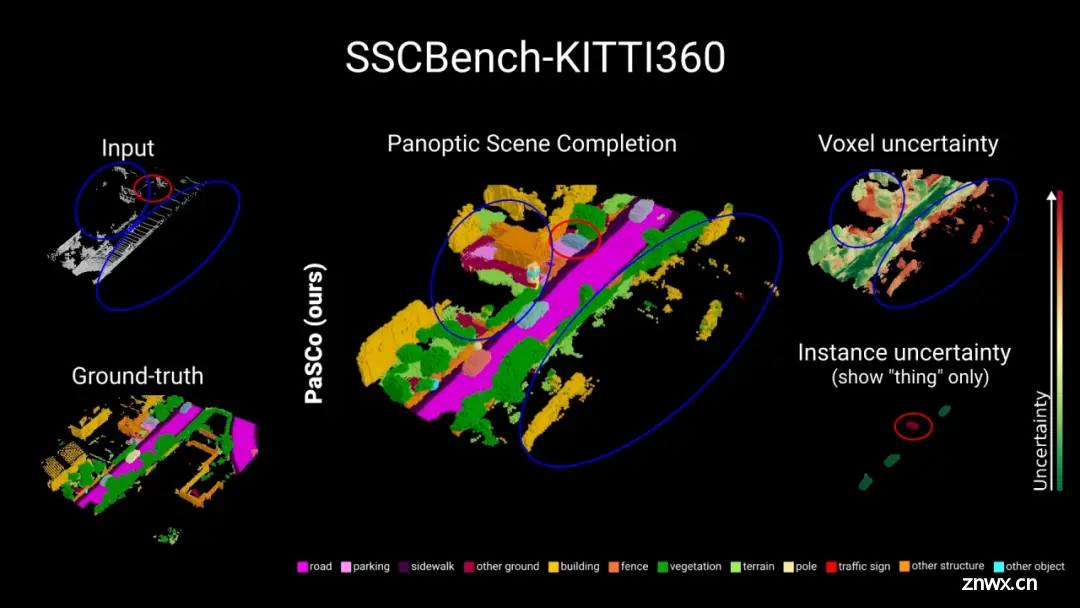
PaSCo: Urban 3D Panoptic Scene Completion with Uncertainty Awareness
概述:该论文提出了全景场景补全(PSC)任务,该任务使用实例级信息扩展了最近流行的语义场景补全任务,以产生对3D场景的更丰富理解。鉴于SSC文献忽略了对机器人应用至关重要的不确定性,该论文提出了一种有效的集合来估计PSC的体素和实例不确定性。这是通过建立在多输入多输出(MIMO)策略的基础上实现的,同时提高了性能,并为很少的额外计算提供了更好的不确定性。

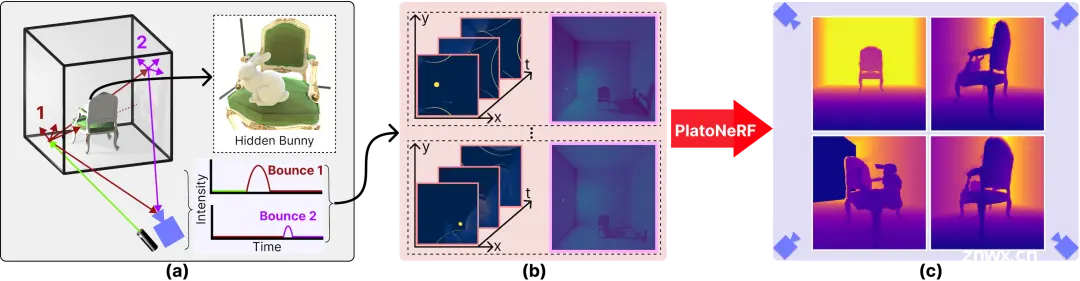
PlatoNeRF: 3D Reconstruction in Plato's Cave via Single-View Two- Bounce Lidar
概述:该论文使用NeRF对两个反弹光路进行建模,使用激光雷达瞬态数据进行监督。通过利用激光雷达测量的NeRF和双反射光的优势,证明了可以在没有数据先验或依赖受控环境照明或场景反照率的情况下重建可见和遮挡的几何结构。此外,还展示了在传感器空间和时间分辨率的实际约束下改进的泛化能力。
行动和动作
Temporally Consistent Unbalanced Optimal Transport for Unsupervised Action Segmentation
概述:论文提出了一种新的方法,在解决最佳传输问题的基础上,对长而未修剪的视频进行动作分割。通过在Gromov-Wasserstein问题之前对时间一致性进行编码,能够从视频帧和动作类之间的噪声亲和力/匹配代价矩阵中解码时间一致性分段。与以前的方法不同,该方法不需要知道视频的动作顺序即可获得时间一致性。此外,得到的(融合)Gromov-Wasserstein问题可以在GPU上通过投影镜下降的几次迭代有效地解决。评估了分割方法和无监督学习管道,为无监督视频动作分割任务产生了最先进的结果。
关注公号《沃的顶会》
回复“最佳论文24”即可全部领取
数据和评估
Rich Human Feedback for Text-to-lmage Generation
概述:该论文通过(i)标记与文本不真实或不对齐的图像区域,以及(ii)注释文本提示符中的哪些单词在图像上被误传或丢失,来丰富反馈信号。在18K生成的图像(RichHF-18K)上收集如此丰富的人类反馈,并训练多模式变压器来自动预测丰富的反馈。论文表明,可以利用预测的丰富人类反馈来改进图像生成,例如,通过选择高质量的训练数据来微调和改进生成模型,或者通过创建带有预测热图的遮罩来修复问题区域。
BioCLlP: A Vision Foundation Model for the Tree of Life
概述:该论文策划并发布了TreeOfLife-10M,这是最大、最多样化的生物图像ML-rady数据集。然后开发了BioCLIP,这是生命树的基础模型,利用TreeOfLife-10M捕捉到的独特生物学特性,即植物、动物和真菌图像的丰富性和多样性,以及丰富的结构化生物学知识的可用性。在不同的细粒度生物分类任务上对提出的方法进行了严格的基准测试,发现BioCLIP始终且显著优于现有基准(绝对值为16%至17%)。
多视角和传感器融合 3D
Grounding and Enhancing Grid-based Models for Neural Fields
概述:许多当代研究使用基于网格的模型来表示神经场,但仍然缺少对基于网格模型的系统分析,阻碍了这些模型的改进。因此,本文介绍了基于网格模型的理论框架。该框架指出,这些模型的近似和泛化行为是由网格切线核(GTK)决定的,而网格切线核是基于网格模型的固有属性。拟议框架有助于对各种基于网格的模型进行一致和系统的分析。此外,引入的框架推动了一种新的基于网格的模型——乘法傅里叶自适应网格(MultFAGrid)的开发。数值分析表明,MulFAGrid具有较低的泛化界,表明其具有鲁棒泛化性能。实证研究表明,MulFAGrid在各种任务中都取得了最先进的性能,包括2D图像拟合、3D符号距离场(SDF)重建和新颖的视图合成,显示出卓越的表示能力。
NeRF-HuGS: Improved Neural Radiance Fields in Non-static Scenes Using Heuristics-Guided Seqmentation
概述:神经辐射场(NeRF)因其在新颖视图合成和三维场景重建方面的卓越表现而得到广泛认可。该论文提出了一种新的范式,即“启发式引导分割”(HuGS),它通过将手工启发式和最先进的分割模型的优点和谐地结合在一起,显著增强了静态场景与瞬时分心物的分离,从而显著地超越了先前解决方案的限制。大量实验表明,对于在非状态场景中训练的NeRF,该方法在缓解瞬态干扰因素方面具有优越性和鲁棒性。
关注公号《沃的顶会》
回复“最佳论文24”即可全部领取
Mip-Splatting: Alias-free 3D Gaussian Splatting
概述:该论文引入了一个3D平滑滤波器,该滤波器基于输入视图产生的最大采样频率限制3D高斯基元的大小,消除了放大时的高频伪影。此外,用2D Mip滤波器代替2D膨胀,该滤波器模拟2D盒滤波器,有效缓解了混叠和膨胀问题。经评估,包括单尺度图像训练和多尺度测试等场景,验证了该方法的有效性。

pixelSplat. 3D Gaussian Splats from lmage Pairs for Scalable Generalizable 3D Reconstruction
概述:该论文引入了pixelSplat,这是一种前馈模型,它学习从成对图像中重建由三维高斯基元参数化的三维辐射场。该模型具有实时和内存高效的渲染功能,可用于可扩展的训练以及推理时的快速3D重建。该论文以现实世界RealEstate10k和ACID数据集上的宽基线新视图合成为基准,在重建可解释和可编辑的3D辐射场的同时,超越了最先进的光场变换器,并将渲染速度提高了2.5个数量级。
低样本、自监督、半监督学习
MLP Can Be A Good Transformer Learner
概述:该论文介绍了一种新的策略,该策略在熵考虑的指导下,通过选择性删除非必要的注意层来简化视觉变换器并减少计算负载。我们发现,对于底部块中的注意层,其后续的MLP层,即两个前馈层,可以产生相同的熵。同时,伴随的MLP被低估了,因为与顶层块中的MLP相比,它们表现出更小的特征熵。因此,我们建议通过将无信息注意层退化为相同的映射,将其集成到后续对应层中,从而在某些变换块中仅产生MLP。在ImageNet-1k上的实验结果表明,该方法可以去除DeiT-B 40%的注意层,在不影响性能的情况下提高吞吐量和内存限制。
地位视觉和遥感
Task-Driven Wavelets using Constrained Empirical Risk Minimization
概述:该论文介绍一种卷积神经网络(CNN)其中所述卷积滤波器被严格约束为小波。这允许筛选器更新为任务优化小波。我们的主要贡献在于通过受约束的经验风险最小化框架,从而提供了一种精确的机制来加强这些结构约束。虽然我们的工作是以理论为基础的,但我们通过在医学成像,特别是在各种器官周围的轮廓预处理任务中,实现了卓越的性能与基线方法相比。
关注公号《沃的顶会》
回复“最佳论文24”即可全部领取
Image Processing GNN: Breaking Rigidity in Super-Resolution
概述:该论文利用图的灵活性,提出了图像处理GNN(IPG)模型来打破在以前的SR方法中占主导地位的刚性。首先,SR是不平衡的,因为大多数重建工作集中在一小部分细节丰富的图像部分。因此,论文作者通过分配更高的学位来利用学位灵活性节点度以细化丰富的图像节点。然后为了构造SR有效聚合的图,将图像视为像素节点集而不是补丁节点。最后,他们认为本地和全球信息对于SR性能。为了通过柔性图有效地从局部和全局尺度收集像素信息,搜索附近区域内的节点连接来构建局部图。图形的灵活性提高了SR性能IPG模型。在各种数据集上的实验结果表明拟议的IPG优于最先进的基线。
图像&视频合成
Generative Image Dynamics
概述:论文提出了一种在场景运动之前对图像空间建模的方法。在傅里叶域之前对这种密集的长期运动进行建模:给定一幅图像,训练模型使用频率协调的扩散采样过程来预测光谱体积,可以将其转换为跨越整个视频的运动纹理。与基于图像的渲染模块一起,这些轨迹可用于许多下游应用程序,例如将静态图像转换为无缝循环视频,或通过将光谱体积解释为图像空间模式库,允许用户与真实图像中的对象进行真实交互,近似于物体动力学。
Analyzing and lmproving the Training Dynamics of Diffusion Models
概述:论文提出了在不改变其高级结构的情况下,识别并纠正了流行的ADM扩散模型架构中训练不均衡和无效的几个原因。我们修改将ImageNet-512合成中先前记录的FID 2.41提高到1.81,这是使用快速确定性采样实现的。作为一个独立的贡献,我们提出了一种在事后(即完成训练后)设置指数移动平均(EMA)参数的方法。这允许在不需要执行多次训练的情况下精确调整EMA长度,并揭示了其与网络架构、训练时间和指导的惊人互动。
多模态学习
EGTR: Extracting Graph from Transformer for Scene Graph Generation
概述:论文提出了一个轻量级的单阶段SGG模型,该模型从DETR解码器的多头部自关注层中学习的各种关系中提取关系图。通过充分利用自关注副产品,可以使用浅关系提取头有效地提取关系图。通过关系平滑,模型根据连续课程进行训练,该课程在训练开始时侧重于目标检测任务,并随着目标检测性能的逐步提高而执行多任务学习。此外,提出了一个连接预测任务,该任务预测对象对之间是否存在关系,作为关系提取的辅助任务。我们证明了方法对于可视基因组和开放图像V6数据集的有效性和效率。
】
关注公号《沃的顶会》
回复“最佳论文24”即可全部领取!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。