G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment
三月七꧁ ꧂ 2024-09-04 12:01:02 阅读 58
文章目录
题目摘要方法实验分析相关工作结论
题目
G-EVAL:使用GPT-4进行NLG评估,具有更好的人类一致
论文地址:https://arxiv.org/abs/2303.16634
项目地址:https://github.com/nlpyang/geval
摘要
自然语言生成(NLG)系统生成的文本质量难以自动测量。传统的参考指标,如BLEU和ROUGE,已被证明与人类判断的相关性相对较低,特别是对于需要创造力和多样性的任务。最近的研究建议使用大型语言模型(llm)作为NLG评估的无参考指标,其优点是适用于缺乏人类参考的新任务。然而,这些基于LLM的评估器仍然比中等大小的神经评估器具有更低的人类对应性。在这项工作中,我们提出了G-EVAL,这是一个使用具有思维链(CoT)和表单填充范式的大型语言模型的框架,用于评估NLG输出的质量。我们实验了两个生成任务,文本摘要和对话生成。我们发现,以GPT-4为骨干模型的G-EVAL与人类总结任务的Spearman相关性为0.514,大大优于之前的所有方法。我们还建议对基于LLM的评估者的行为进行分析,并强调基于LL,的评估者对LLM生成的文本有偏见的潜在担忧。
评估自然语言生成系统的质量是一个具有挑战性的问题,大型语言模型可以生成高质量的语言,不同的文本往往难以区分来自人类书写的文本。传统的自动指标,如BLEU、ROUGE 和METEOR被广泛使用但它们与人类判断的相关性相对较低,特别是对于开放式生成任务。此外,这些指标需要相关的参考输出,为新任务收集这些输出的成本很高。最近的研究建议直接使用llm作为无参考NLG评估器。我们的想法是使用LLM在没有任何参考目标的情况下,根据候选输出的生成概率对其进行评分,假设LLM已经学会了为高质量和流畅的文本分配更高的概率。然而,使用llm作为NLG评估器的效度和信度尚未得到系统的研究。此外,元评价表明,这些基于LLM的评估器与中等规模的神经评估器相比,人类的对应程度仍然较低。因此,需要一个更有效和可靠的框架来使用llm进行NLG评估。
在本文中,我们提出了G-EVAL,这是一个使用具有思维链(CoT)的LLM的框架,用于评估表单填充范式中生成文本的质量。通过只提供任务介绍和评估标准作为提示,我们要求LLM生成详细评估步骤的CoT。然后,我们使用提示符和生成的CoT来评估NLG输出。计算器输出被格式化为表单。此外,输出评级令牌的概率可用于改进最终指标。我们在两个NLG任务:文本摘要和对话生成的三个元评价基准上进行了广泛的实验。结果表明,在与人类评价的相关性方面,G-EVAL可以大大优于现有的NLG评价器。最后,我们对基于LLM的评估者的行为进行了分析,并强调了基于LLM的评估者对LLM生成的文本存在偏见的潜在问题。
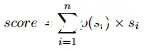
G-EVAL的总体框架。我们首先向LLM输入任务介绍和评估标准,并要求它生成详细评估步骤的CoT。然后,我们使用提示和生成的CoT来评估表单填充范式中的NLG输出。最后,我们使用输出分数的概率加权和作为最终分数。
综上所述,本文的主要贡献有:
在与人类质量判断的相关性方面,基于LLM的度量标准通常优于基于参考和无参考的基线度量标准,特别是对于开放式和创造性的NLG任务,例如对话响应生成。基于llm的度量对指令和提示很敏感,并且思维链可以通过提供更多的上下文和指导来提高基于llm的评估者的性能。基于llm的度量可以通过各自的令牌概率重新加权离散分数来提供更细粒度的连续分数。基于LLM的指标有一个潜在的问题,即更喜欢LLM生成的文本而不是人类编写的文本,如果基于LLM的指标被用作自我改进的奖励信号,这可能会导致LLM的自我强化
方法
G-EVAL 是一个基于提示的评估器,包含三个主要组件:
包含评估任务定义和所需评估标准的提示思路链 (CoT),即 LLM 生成的一组中间指令,描述详细的评估步骤评分函数,调用 LLM 并根据返回标记的概率计算分数。
NLG 评估提示提示是一种自然语言指令,用于定义评估任务和所需的评估标准。例如,对于文本摘要,提示可以是:您将获得一份为新闻文章撰写的摘要。您的任务是根据一个指标对摘要进行评分。请确保您仔细阅读并理解这些说明。请在审阅时保持此文档打开,并在需要时参考。
提示还应包含针对不同 NLG 任务的定制评估标准,例如连贯性、简洁性或语法。例如,为了评估文本摘要中的连贯性,我们在提示中添加了以下内容:评估标准:连贯性(1-5)- 所有句子的总体质量。我们将此维度与 DUC 的结构和连贯性质量问题保持一致,即“摘要应该结构良好且组织良好。摘要不应该只是一堆相关信息,而应该从一个句子构建到另一个句子,形成关于某个主题的连贯信息。”用于 NLG 评估的自动思路链思路链 (CoT) 是 LLM 在文本生成过程中生成的一系列中间表示。对于评估任务,有些标准需要比简单定义更详细的评估说明,而为每个任务手动设计这样的评估步骤非常耗时。我们发现 LLM 可以自行生成这样的评估步骤。 CoT 可以为 LLM 评估生成的文本提供更多的上下文和指导,也可以帮助解释评估过程和结果。例如,为了评估文本摘要中的连贯性,我们在提示中添加一行“评估步骤:”,让 LLM 自动生成以下 CoT:
仔细阅读新闻文章,找出主要话题和关键点。阅读摘要并将其与新闻文章进行比较。检查摘要是否涵盖了新闻文章的主要话题和关键点,以及是否以清晰和合乎逻辑的顺序呈现它们。根据评估标准,按 1 到 5 的等级为连贯性分配分数,其中 1 为最低,5 为最高。
评分函数评分函数使用设计的提示、自动 CoT、输入上下文和需要评估的目标文本调用 LLM。与使用生成目标文本的条件概率作为评估指标的 GPTScore (Fu et al, 2023) 不同,G-EVAL 直接使用填表范式执行评估任务。例如,为了评估文本摘要中的连贯性,我们将提示、CoT、新闻文章和摘要连接起来,然后调用 LLM 根据定义的标准为每个评估方面输出 1 到 5 的分数。但是,我们注意到这种直接评分函数有两个问题:对于某些评估任务,一个数字通常主导分数的分布,例如 1 - 5 范围内的 3。这可能导致分数的方差小,与人类判断的相关性低。LLM 通常只输出整数分数,即使提示明确要求小数值。这导致评估分数中出现许多平局,无法捕捉到生成的文本之间的细微差别。
为了解决这些问题,我们建议使用 LLM 输出标记的概率来规范化分数,并将它们加权求和作为最终结果。形式化地,给定提示中预先定义的一组分数(比如从 1 到 5)S = {s1, s2, …, sn},每个分数的概率 p(si) 由 LLM 计算,最终分数为:

该方法获得更细粒度、连续的分数,可以更好地反映生成文本的质量和多样性。
实验
我们在三个基准 SummEval、Topical-Chat 和 QAGS 上对我们的评估器进行了元评估,这三个基准分别针对两个 NLG 任务,即摘要和对话响应生成。我们使用 OpenAI 的 GPT 系列作为我们的 LLM,包括 GPT-3.5 (text-davinci-003) 和 GPT-4。对于 GPT-3.5,我们将解码温度设置为 0 以增加模型的确定性。对于 GPT-4,由于它不支持输出 token 概率,我们设置“n = 20、temperature = 1、top p = 1”以采样 20 次来估计 token 概率。我们使用 G-EVAL-4 来表示 G-EVAL 与 GPT-4作为骨干模型,G-EVAL-3.5 表示以 GPT-3.5 为骨干模型的 G-EVAL。
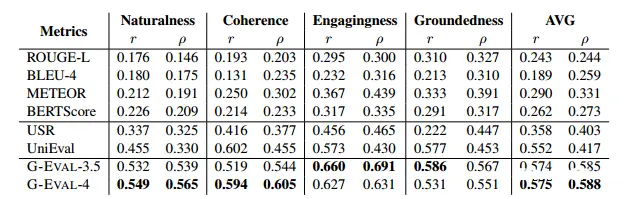
表 1:SummEval 基准上不同指标的汇总级 Spearman (ρ) 和 Kendall-Tau (τ) 相关性。不带概率的 G-EVAL(斜体)不应被视为与 τ 上的其他指标的公平比较,因为它会导致得分出现许多平局。这会导致更高的 Kendall-Tau 相关性,但不能公平地反映真实的评估能力。
我们采用三个元评估基准来衡量 G-EVAL 与人类判断之间的相关性。 SummEval 是一个比较不同摘要评估方法的基准。它对每个摘要的四个方面给出人工评分:流畅性、连贯性、一致性和相关性。 它建立在 CNN/DailyMail 数据集上。Topical-Chat是一个试验台,用于对使用知识的对话响应生成系统的不同评估者进行元评估。我们遵循在四个方面使用其人工评分:自然性、连贯性、参与度和扎实性。 QAGS 是评估摘要任务中幻觉的基准。旨在测量两个不同摘要数据集上摘要的一致性维度。
我们将 G-EVAL 与各种取得最佳性能的评估器进行比较。BERTScore 根据 BERT的上下文嵌入来测量两个文本之间的相似性。MoverScore 通过添加软对齐和新聚合方法来改进 BERTScore,以获得更稳健的相似度度量。BARTScore是一个统一的评估器,它使用预训练的编码器-解码器模型 BART 的平均似然进行评估。它可以根据源和目标的格式预测不同的分数。FactCC 和 QAGS 是两个用于衡量生成摘要的事实一致性的评估器。FactCC 是一个基于 BERT 的分类器,可预测摘要是否与源文档一致。QAGS 是一个基于问答的评估器,它从摘要中生成问题并检查是否可以在源文档中找到答案。USR 是一种从不同角度评估对话响应生成的评估器。它有多个版本,为每个目标响应分配不同的分数。UniEval是一个统一的评估器,可以评估文本生成的不同方面评估任务作为问答任务。它使用预训练的 T5 模型将评估任务、源文本和目标文本编码为问题和答案,然后计算 QA 分数作为评估分数。它还可以通过更改问题格式来处理不同的评估任务。
GPTScore 是一个使用 GPT-3 等生成式预训练模型评估文本的新框架。它假设生成式预训练模型将根据给定的指令和上下文分配更高的高质量生成文本概率。与 G-EVAL 不同,GPTScore 将评估任务表述为条件生成问题而不是填表问题。使用摘要级 Spearman 和 Kendall-Tau 相关性评估不同的摘要指标。表 1 的第一部分显示了比较模型输出和参考文本之间的语义相似度的指标结果。这些指标在大多数维度上表现不佳。第二部分显示了使用神经网络从人类对摘要质量的评分中学习的指标结果。这些指标的相关性比基于相似度的指标高得多,表明它们对于摘要评估更可靠。在表 1 的最后一部分对应于基于 GPT 的评估器,GPTScore 也使用 GPT 来评估摘要文本,但依赖于 GPT 对给定目标的条件概率。G-EVAL 在 SummEval 基准上大大超越了所有以前最先进的评估器。与 G-EVAL-3.5 相比,G-EVAL-4 在 Spearman 和 Kendall-Tau 相关性上实现了更高的人类对应性,这表明 GPT-4 的较大模型尺寸有利于摘要评估。 G-EVAL 在多个维度上也优于 GPTScore,证明了简单填表范式的有效性。我们使用Topical-chat 基准来衡量不同评估者对对话响应质量的评分与人类评分的一致性。我们计算对话每一轮的 Pearson 和 Spearman 相关性。表 2 显示基于相似度的指标与人类具有良好的一致性在回答的吸引力和扎实程度上,UniEval 的预测结果在各个方面都与人类判断最为一致。
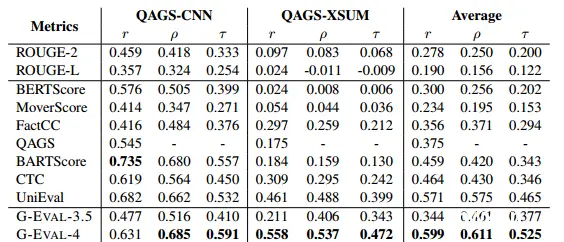
如上一节所示,G-EVAL 在 Topical-Chat 基准上也大幅超越了之前所有最先进的评估器。值得注意的是,G-EVAL-3.5 可以取得与 G-EVAL-4 相似的结果。这表明这个基准对 G-EVAL 模型来说相对容易。高级 NLG 模型经常会产生与上下文输入不匹配的文本,最近的研究发现,即使是强大的 LLM 也存在幻觉问题。这促使最近的研究设计评估器来衡量摘要中的一致性方面。我们测试了 QAGS 元评估基准,其中包括两个不同的摘要数据集:CNN/DailyMail 和 XSum,BARTScore 在更具提取性的子集(QAGS-CNN)上表现良好,但在更具抽象性的子集(QAGS-Xsum)上的相关性较低。UniEval 在两个数据子集上都具有良好的相关性。平均而言,G-EVAL-4 在 QAGS 上的表现优于所有最先进的评估器,在 QAGS-Xsum 上的优势较大。另一方面,G-EVAL-3.5 在这个基准上表现不佳,这表明一致性方面对 LLM 的容量很敏感。这个结果与表 1 一致。
分析
G-EVAL 会更喜欢基于 LLM 的输出吗?使用 LLM 作为评估器的一个担忧是,它可能更喜欢 LLM 本身生成的输出,而不是高质量的人工编写的文本。为了研究这个问题,我们对摘要任务进行了一项实验,我们比较了 LLM 生成的摘要和人工编写的摘要的评估分数。他们首先要求自由撰稿人为新闻文章撰写高质量的摘要,然后要求注释者比较人工编写的摘要和 LLM 生成的摘要(使用 GPT-3.5、text-davinci-003) 。

数据集可分为三类:1)人类评委评分高于 GPT-3.5 摘要的人类编写摘要,2)人类评委评分低于 GPT-3.5 摘要的人类编写摘要,3)人类评委对人类编写摘要和 GPT-3.5 摘要的评分同样好。我们使用 GEVAL-4 评估每个类别中的摘要,并比较平均分数。2 结果如图 2 所示。我们可以看到,当人类评委也更喜欢人类编写的摘要时,G-EVAL-4 会给人类编写的摘要更高的分数,而当人类评委更喜欢 GPT-3.5 摘要时,它会给出较低的分数。然而,即使人类评委更喜欢人类编写的摘要,G-EVAL-4 总是给 GPT-3.5 摘要比人类编写的摘要更高的分数。我们提出了造成这种现象的两个潜在原因:1. 高质量系统的 NLG 输出本质上很难评估。原始论文的作者发现,在判断人工编写和 LLM 生成的摘要时,注释者之间的一致性非常低,Krippendorff 的 alpha 为 0.07。
G-EVAL 可能对 LLM 生成的摘要有偏见,因为该模型在生成和评估过程中可以共享相同的评估标准概念。我们的工作应该被视为对这个问题的初步研究,需要更多的研究来充分理解基于 LLM 的行为评估者减少其对 LLM 生成文本的固有偏见。我们强调这种担忧,因为如果评估分数被用作进一步调整的奖励信号,基于 LLM 的评估器可能会导致 LLM 的自我强化。这可能会导致 LLM 过度拟合它们自己的评估标准,而不是 NLG 任务的真正评估标准。思路链的影响我们比较了有和没有思路链 (CoT) 的 G-EVAL 在 SummEval 基准上的性能。表 1 显示,在所有维度上,带有 CoT 的 G-EVAL-4 都比没有 CoT 的 G-EVAL-4 具有更高的相关性,尤其是在流畅性方面。这表明 CoT 可以为 LLM 评估生成的文本提供更多的背景和指导,也可以帮助解释评估过程和结果。概率归一化的影响我们比较了有和没有概率归一化的 G-EVAL 在 SummEval 基准上的性能。表 1 显示,在 KendallTau 相关性上,G-EVAL-4 的概率为在SummEval上不如没有概率的G-EVAL-4。我们认为这与Kendall-Tau相关性的计算有关,该相关性基于一致和不一致对的数量。没有概率的直接评分会导致许多平局,这些平局既不被视为一致也不被视为不一致。这可能会导致更高的Kendall-Tau相关性,但不能反映模型评估生成文本的真实能力。另一方面,概率归一化可以获得更细粒度、连续的分数,更好地捕捉生成文本之间的细微差别。这反映在有概率的G-EVAL-4具有更高的Spearman相关性,该相关性基于分数的排序。 我们比较了不同模型大小的G-EVAL在SummEval和QAGS基准上的性能。表 1 和表 3 显示,除了 Topical-Chat 基准上的参与度和接地气性之外,G-EVAL-4 在大多数维度和数据集上的相关性都高于 G-EVAL-3.5。 这表明,更大的模型尺寸可以提高 G-EVAL 的性能,特别是对于更具挑战性和更复杂的评估任务,例如一致性和相关性。
相关工作
基于 Ngram 的指标基于 Ngram 的指标是指通过测量生成文本和参考文本之间的词汇重叠来评估 NLG 模型的分数。BLEU是机器翻译评估中最广泛使用的指标,它计算修改后的 n-gram 精度和简洁性的几何平均值惩罚。ROUGE 是一种面向召回率的摘要评估指标,它测量生成的摘要和一组参考摘要之间的 n-gram 重叠度。研究表明,最近 60% 以上的 NLG 论文仅依靠 ROUGE 或 BLEU 来评估他们的系统。然而,这些指标无法衡量内容质量或捕获句法错误,因此不能准确反映 NLG 系统的可靠性。基于嵌入的指标基于嵌入的指标是指通过基于单词或句子嵌入测量生成的文本和参考文本之间的语义相似性来评估 NLG 模型的分数。WMD是一种基于词嵌入测量两个文本之间距离的指标。
BERTScore基于 BERT的上下文嵌入来测量两个文本之间的相似性。MoverScore 通过添加软对齐和新的聚合方法来改进BERTScore,以获得更稳健的相似度度量。提出了一种指标,通过基于句子嵌入计算生成的文本和参考文本之间的相似度来评估多句文本。任务特定的评估器任务特定的指标是指通过根据特定任务要求衡量生成文本的质量来评估 NLG 模型的分数。例如,摘要任务需要评估生成的摘要的一致性,maries和对话响应生成任务需要评估生成的响应的连贯性。但是,这些指标不能推广到其他 NLG 任务,并且它们无法衡量生成文本的整体质量。
统一评估器最近,已经开发了一些评估器,通过改变输入和输出内容或它们使用的模型变体从多个维度评估文本质量。UniEval 是一个统一的评估器,可以将文本生成的不同方面作为 QA 任务进行评估。通过改变问题格式,它可以处理不同的评估任务。基于LLM的评估器提出了GPTScore,这是一个使用生成式预训练模型(如GPT-3)评估文本的新框架。它假设生成式预训练模型将按照给定的指令和上下文分配更高的高质量生成文本概率。对使用ChatGPT作为NLG评估器进行了初步调查。提出使用GPT模型来评估机器翻译任务。
结论
在本文中,我们提出了G-EVAL,这是一个使用带有思路链(CoT)的LLM来评估生成文本质量的框架。我们对两个NLG任务,文本摘要和对话生成进行了广泛的实验,并表明G-EVAL可以胜过最先进的评估器并实现更高的人机对应性。我们还提出了对 LLM 评估者行为的初步分析,并强调了 LLM 评估者对 LLM 生成的文本存在偏见的潜在问题。我们希望我们的工作能够激发更多关于使用 LLM 进行 NLG 评估的研究,并提高人们对使用 LLM 作为评估者的潜在风险和挑战的认识。
上一篇: 运动规划-动态避让基础算法
下一篇: AI:228-保姆级基于SCConv的YOLOv8改进 | 轻量化空间与通道重构卷积助力精细化目标检测
本文标签
G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。