狗都能看懂的Q-Learning强化学习算法讲解
热血厨师长 2024-08-20 12:31:01 阅读 72
文章目录
Q-Learning推导TrickTarget NetworkExplorationReplay Buffer
Tips for Q-LearningDouble DQNDueling DQNPrioritized ReplyMulti-StepNoisy NetDistributional Q-functionRainbow
Continuous Actions
Q-Learning
在之前Value-Based的博文中介绍了几种Critic的方法,已经对Q-Learning的概念有一个初步的讲解了。这里我们简单再回顾一下。
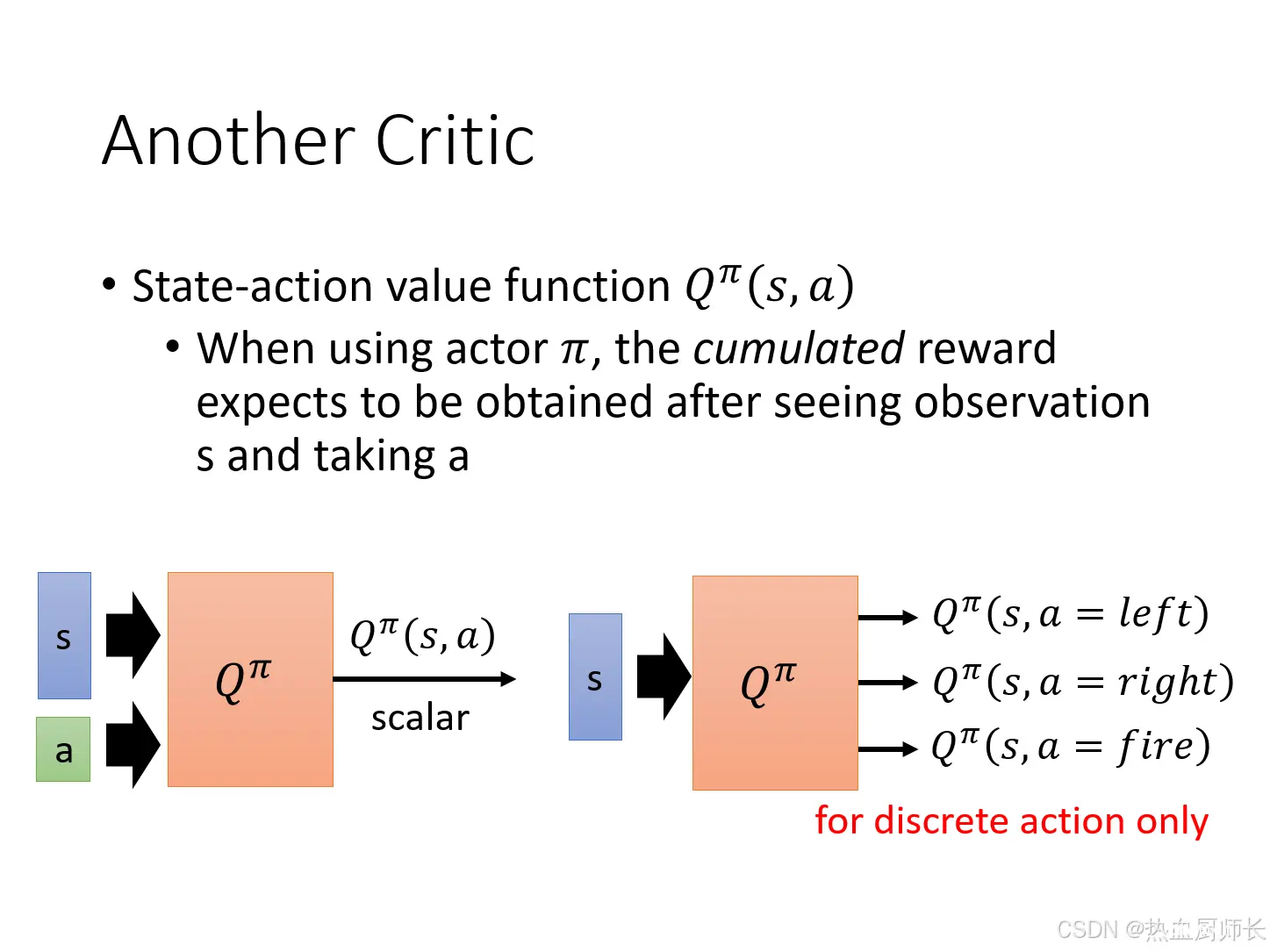
假设我们现在的任务是每一个action都是可以穷举的(对应上图右边的情况),那么每一次我们都可以计算出
V
π
(
s
t
)
V^\pi(s_t)
Vπ(st),使得每次都可以选最好的一个action。这个就是Q-Learning的思想。输入state和action到
Q
π
Q^\pi
Qπ中,得到不同action的预测期望值。但如果没办法穷举所有的可能,而是一个离散型的任务,就只能用一个网络预测出实际的action,再输入到
Q
π
Q^\pi
Qπ的预测网络中去(对应上图左边的情况)。

完整的Q-Learning如上图所示:
初始的
π
\pi
π先和环境做互动,经过TD或者MC的方法,计算reward得到数据。利用critic
V
π
(
s
)
V^\pi(s)
Vπ(s)得到
π
′
\pi'
π′,这里有一个前提,
V
π
′
(
s
)
>
V
π
(
s
)
V^\pi{'}(s) > V^\pi(s)
Vπ′(s)>Vπ(s),即新的策略
π
′
\pi'
π′在同样的state下,得到的期望值必须要比用策略
π
\pi
π高。利用argmax计算出得到最好的
π
′
\pi'
π′。重复1-3的过程,policy就会越来越好。
推导
接下来我们就需要证明为什么下面这个式子成立:
π
′
(
s
)
=
a
r
g
max
a
Q
π
(
s
,
a
)
V
π
′
(
s
)
≥
V
π
(
s
)
f
o
r
a
l
l
s
t
a
t
e
s
\pi'(s) = arg \max\limits_{a} \ Q^\pi(s,a) \\ V^{\pi'}(s) \quad \ge \quad V^{\pi}(s) \qquad for \ \ all \ \ state \ \ s
π′(s)=argamax Qπ(s,a)Vπ′(s)≥Vπ(s)for all state s
首先对于任意的任务,我们用
π
(
s
)
\pi(s)
π(s)计算出action,所以可以把
V
π
(
s
)
V^{\pi}(s)
Vπ(s)写做:
V
π
(
s
)
=
Q
π
(
s
,
π
(
s
)
)
V^{\pi}(s) = Q^\pi(s, \pi(s))
Vπ(s)=Qπ(s,π(s))
根据Q-Learning取最好的定义,那么有:
Q
π
(
s
,
π
(
s
)
)
≤
max
a
Q
π
(
s
,
a
)
=
Q
π
(
s
,
π
′
(
s
)
)
Q^\pi(s, \pi(s)) \quad \le \quad \max\limits_{a} \ Q^\pi(s, a) \quad = \quad Q^\pi(s, \pi'(s))
Qπ(s,π(s))≤amax Qπ(s,a)=Qπ(s,π′(s))
所以可以写成:
V
π
(
s
)
≤
Q
π
(
s
,
π
′
(
s
)
)
≤
V
π
′
(
s
)
V^{\pi}(s) \quad \le \quad Q^\pi(s, \pi'(s)) \quad \le \quad V^{\pi'}(s)
Vπ(s)≤Qπ(s,π′(s))≤Vπ′(s)
这里Q的上标还是
π
\pi
π,而不是
π
′
\pi'
π′,是指第一步按照
π
\pi
π的方向走,之后都按照
π
′
\pi'
π′给出的方向走,直到episode结束后得到reward小于等于
V
π
′
(
s
)
V^{\pi'}(s)
Vπ′(s),我们算其期望:
Q
π
(
s
,
π
′
(
s
)
)
=
E
[
r
t
+
1
+
V
π
(
s
t
+
1
)
∣
s
t
=
s
,
a
t
=
π
′
(
s
)
]
Q^\pi(s, \pi'(s)) = E[r_{t+1} + V^{\pi}(s_{t+1})|s_t=s,a_t=\pi'(s)]
Qπ(s,π′(s))=E[rt+1+Vπ(st+1)∣st=s,at=π′(s)]
这一项指在
s
t
s_t
st的时候采取
π
′
(
s
)
\pi'(s)
π′(s)给出的action,得到
r
t
+
1
r_{t+1}
rt+1(根据李宏毅老师课程说法,不同文献资料也有可能是
r
t
r_t
rt),环境跳转到
s
t
+
1
s_{t+1}
st+1,用
V
π
V^{\pi}
Vπ预估出
s
t
+
1
s_{t+1}
st+1剩下的reward,最后取一个期望值。
根据之前的定义,
Q
π
(
s
,
π
(
s
)
)
≤
Q
π
(
s
,
π
′
(
s
)
)
Q^\pi(s, \pi(s)) \le Q^\pi(s, \pi'(s))
Qπ(s,π(s))≤Qπ(s,π′(s))可以写出:
E
[
r
t
+
1
+
V
π
(
s
t
+
1
)
∣
s
t
=
s
,
a
t
=
π
′
(
s
)
]
≤
E
[
r
t
+
1
+
Q
π
(
s
t
+
1
,
π
′
(
s
t
+
1
)
)
∣
s
t
=
s
,
a
t
=
π
′
(
s
)
]
E[r_{t+1} + V^{\pi}(s_{t+1})|s_t=s,a_t=\pi'(s)] \quad \le \quad E[r_{t+1} + Q^\pi(s_{t+1}, \pi'(s_{t+1}))|s_t=s,a_t=\pi'(s)]
E[rt+1+Vπ(st+1)∣st=s,at=π′(s)]≤E[rt+1+Qπ(st+1,π′(st+1))∣st=s,at=π′(s)]
那么
Q
π
(
s
t
+
1
,
π
′
(
s
t
+
1
)
)
Q^\pi(s_{t+1}, \pi'(s_{t+1}))
Qπ(st+1,π′(st+1))可以写成:
E
[
r
t
+
2
+
V
π
(
s
t
+
2
)
]
E[r_{t+2} + V^{\pi}(s_{t+2})]
E[rt+2+Vπ(st+2)]
整合一下那么一直计算下去的话:
E
[
r
t
+
1
+
r
t
+
2
+
V
π
(
s
t
+
2
)
∣
.
.
.
]
≤
E
[
r
t
+
1
+
r
t
+
2
+
Q
π
(
s
t
+
2
,
π
′
(
s
t
+
2
)
)
∣
.
.
.
]
≤
V
π
′
(
s
)
E[r_{t+1} + r_{t+2} + V^{\pi}(s_{t+2})|...] \quad \le \quad E[r_{t+1} + r_{t+2} + Q^\pi(s_{t+2}, \pi'(s_{t+2}))|...] \quad \le \quad V^{\pi'}(s)
E[rt+1+rt+2+Vπ(st+2)∣...]≤E[rt+1+rt+2+Qπ(st+2,π′(st+2))∣...]≤Vπ′(s)
以上就是一些证明。
Trick
Q-Learning中也有不少可以用到的Trick,这里简单提及一下
Target Network
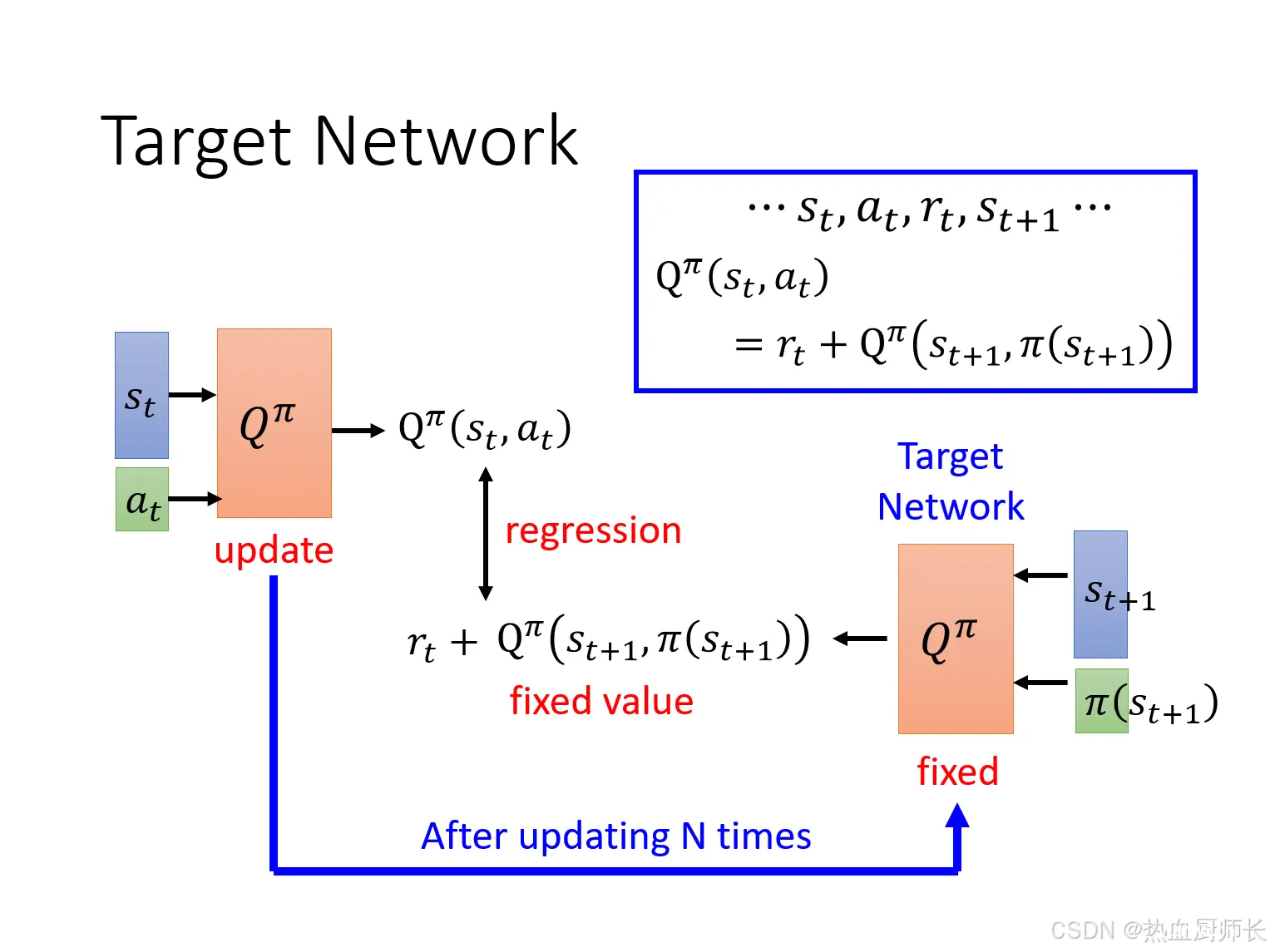
在Q-Learning中也有TD的概念,即如上图右上角的公式所示
Q
π
(
s
t
,
a
t
)
Q^\pi(s_t, a_t)
Qπ(st,at)与
Q
π
(
s
t
+
1
,
π
(
s
t
+
1
)
)
Q^\pi(s_{t+1}, \pi(s_{t+1}))
Qπ(st+1,π(st+1))之间差了一项
r
t
r_t
rt。实际训练中,我们需要固定住Target Network,让它只产生value,中间那一项就是一个regression问题了,然后只update左边的
Q
π
Q^\pi
Qπ。在训练了几次之后,再将右边的
Q
π
Q^\pi
Qπ换成左边的
Q
π
Q^\pi
Qπ。(一开始两边的
Q
π
Q^\pi
Qπ是一样的)
Exploration

Q-Learning和Policy Gradient不同的是,如果不加干预,它永远都只会选择当前action会得到reward最高的那个(如果
π
\pi
π是一个神经网络还好,带有一点随机性)。这样会导致
Q
π
Q^\pi
Qπ只会考虑当前最高分的action,那么得到都是固定几种路线的episode,这不是一个好的数据收集的方法。
所以提出一个可衰减的贪婪策略,即给定一个概率
ϵ
\epsilon
ϵ,会采取random action的方式替代
a
r
g
max
a
Q
π
(
s
,
a
)
arg \max\limits_{a} \ Q^\pi(s,a)
argamax Qπ(s,a)。但
ϵ
\epsilon
ϵ会随着时间的增加,逐渐降低,在一开始的时候随机探索,在模型接近收敛的时候,减少探索的几率。
当然也有其他策略,如Boltzmann Exploration,这个比较像Policy Gradient,这个action好,我们就增加它出现的机率,这里就不展开讲解了。
Replay Buffer
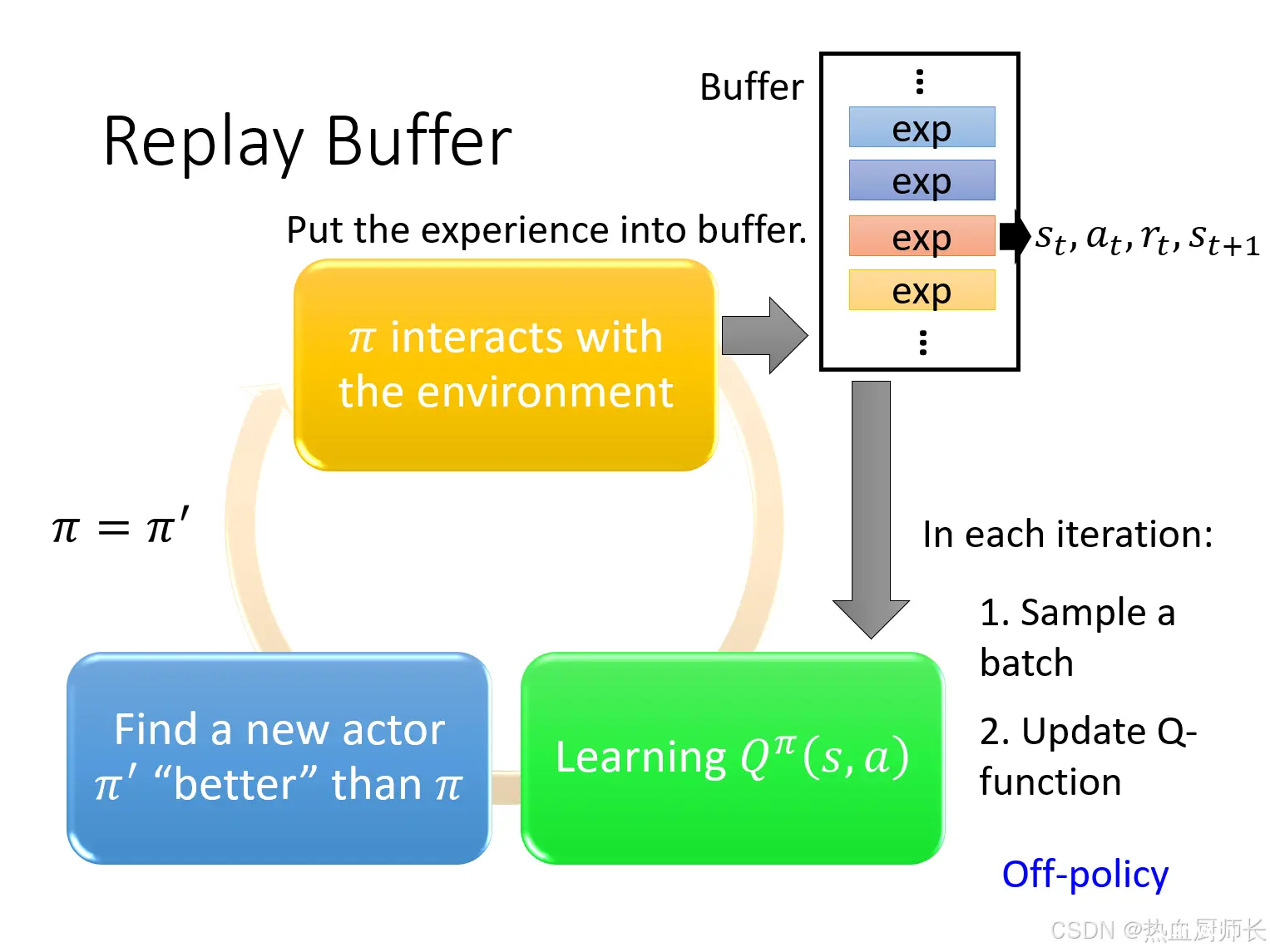
现在我们会有一个Policy和环境做互动,它会收集data,我们会将这些data放到buffer里面。每一个data记录的是,Policy在
s
t
s_t
st会采取
a
t
a_t
at得到
r
t
r_t
rt,环境再变成
s
t
+
1
s_{t+1}
st+1。Buffer其实就是一个队列,当队列满了之后就会丢弃掉旧数据。训练时会从Buffer里面挑出一个batch的数据,update旧的Q-function,找到更好的
Q
π
Q^\pi
Qπ,更新过去。
这里的每一个data都有可能来自于不同的Policy,所以带有Replay Buffer的Q-Learning其实是Off-policy的。不用担心来自于不同的Policy的data会影响Q-Learning的训练,不同Policy的data其实是更有泛化性的,就和有监督学习一样。
那么将几个trick合并到一起之后,我们一个经典的Q-Learning算法如下:

Tips for Q-Learning
Double DQN
Q-Learning在实践中,Q 值的高估是一个常见的问题。
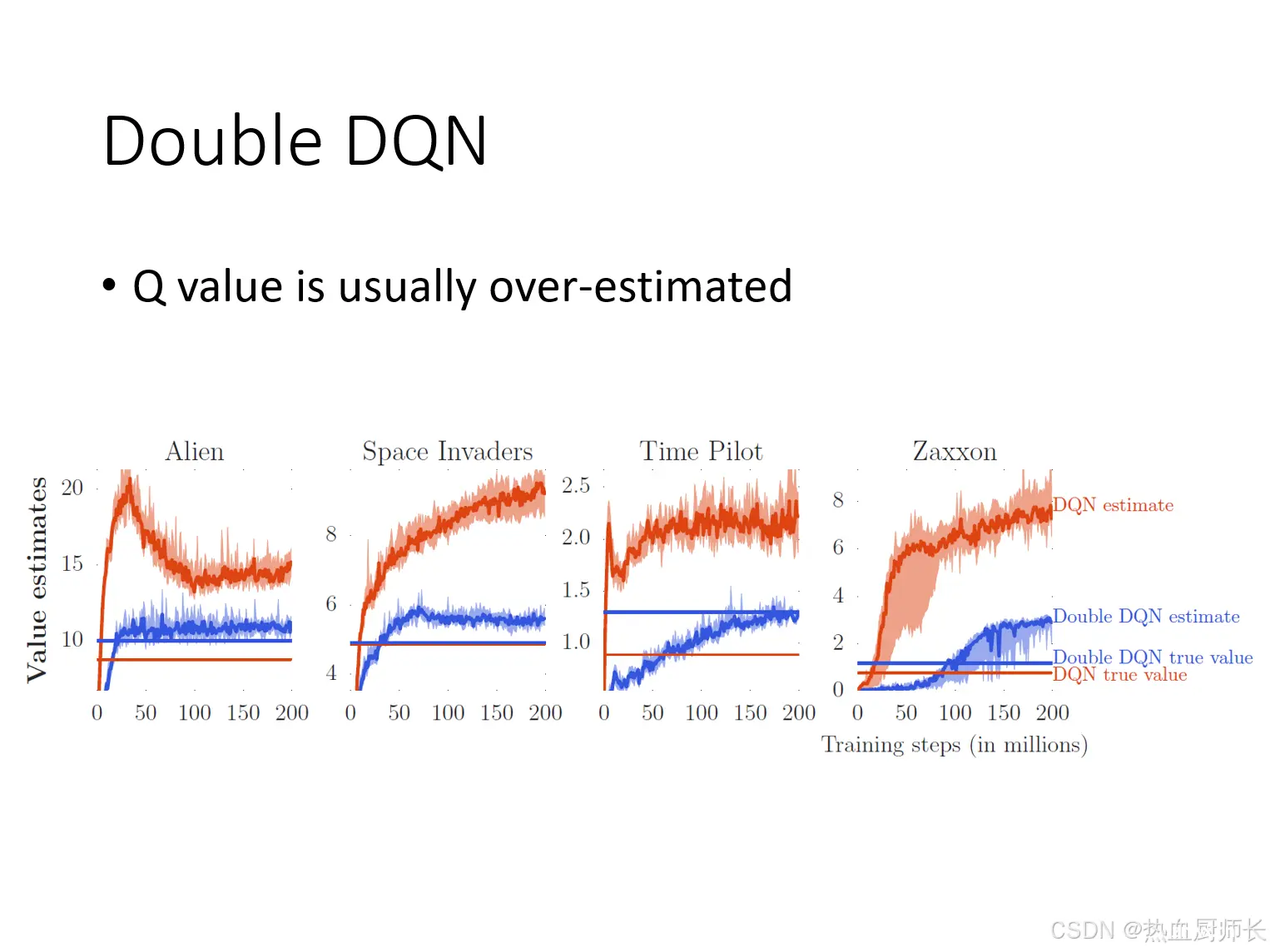
这是因为在DQN的更新过程中,使用了最大化操作来选择动作,这种最大化操作往往会导致过高的 Q 值估计。上面这张图展示了DQN的Q值曲线,横轴是训练步长,纵轴是评估的Q值,上方的红色的曲线代表DQN的评估的Q值,下方红色的直线代表实际会得到的Q值。可以看到,无论是哪个游戏都会有Q估值过高的情况。蓝色的线代表了Double DQN,而Double DQN则不会有这个情况。

为什么会被高估呢?其实这个现象也好解释,在DQN中,我们用的是
Q
π
Q^\pi
Qπ去获取target,而
Q
π
Q^\pi
Qπ本身也是要训练的对象,它是会有误差的。在最大化操作中,噪声和误差会被放大。
假设给它四个选型,实际的expect reward的是一样大的,但由于
Q
π
Q^\pi
Qπ的误差,DQN总是会选择被高估的那个。这样训练迭代下去,误差累积,也就导致Q值都是被高估的。

为了解决这个问题,Double DQN引入了第二个Q-Network,在 Double DQN 中:
使用当前的
Q
Q
Q来选择下一个动作
a
r
g
max
a
Q
(
s
t
+
1
,
a
)
arg \max\limits_{a} \ Q(s_{t+1},a)
argamax Q(st+1,a)使用目标
Q
′
Q'
Q′来评估选定动作的Q值
Q
′
(
s
t
+
1
,
a
r
g
max
a
Q
(
s
t
+
1
,
a
)
)
Q'(s_{t+1}, \ arg \max\limits_{a} \ Q(s_{t+1},a))
Q′(st+1, argamax Q(st+1,a))
分离了action的选择和Q值的评估,降低了一个DQN最大化引入的高估值偏差(要两个DQN同时高估Q值才会使得要优化的target值过高)。
Dueling DQN
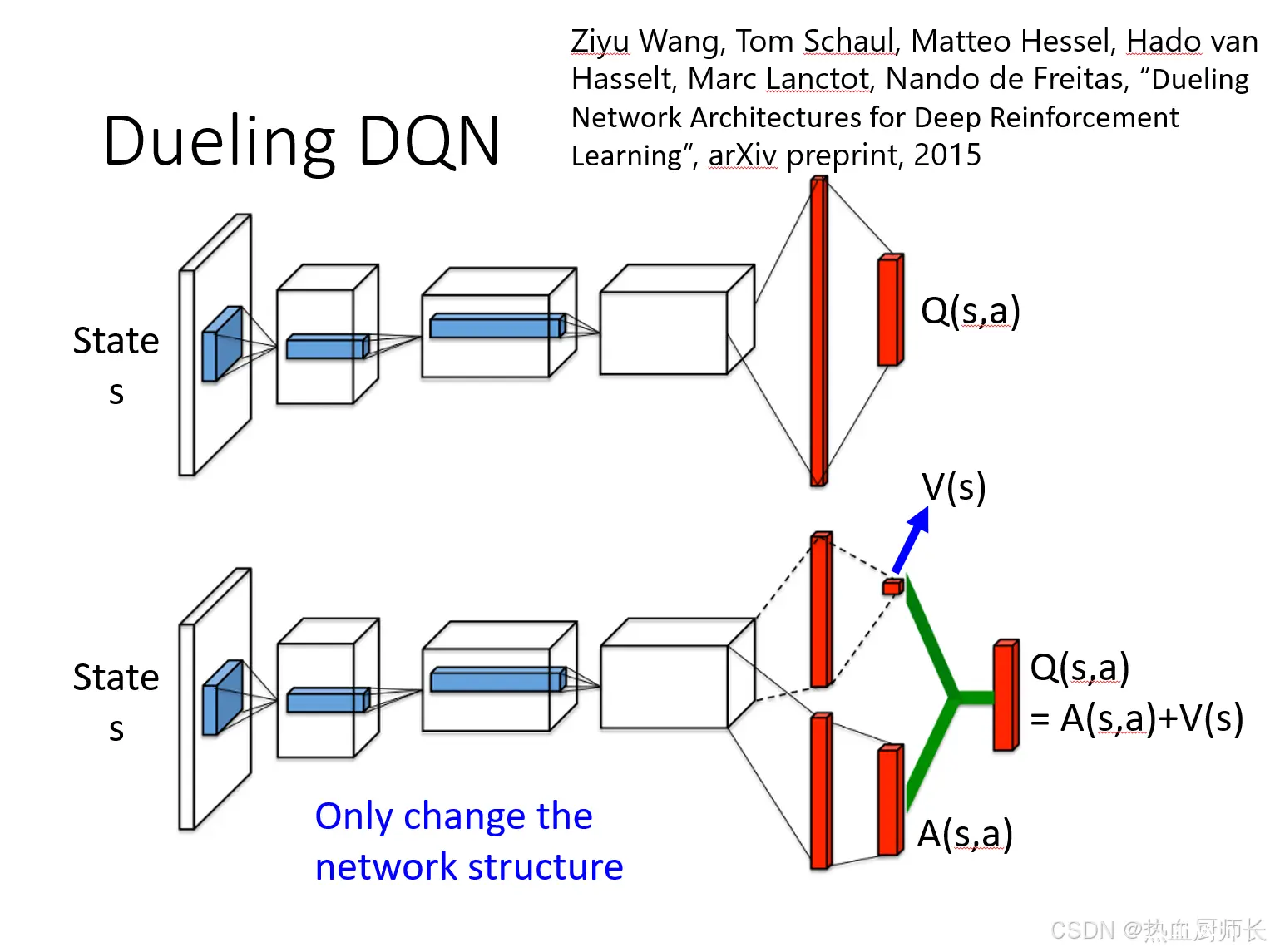
普通的DQN在架构上,input是state,output是每一个action的
Q
(
s
,
a
)
Q(s,a)
Q(s,a)。而Dueling DQN就是改了output的架构,
Q
(
s
,
a
)
Q(s,a)
Q(s,a)被拆成了两个output,一个是
V
(
s
)
V(s)
V(s),它是一个标量,另一个是
A
(
s
,
a
)
A(s,a)
A(s,a),它是vector,每一个action都有一个value。两个值相加才是原来的
Q
(
s
,
a
)
Q(s,a)
Q(s,a)。
这么做的好处是什么呢?我们拿一个例子具体分析一下
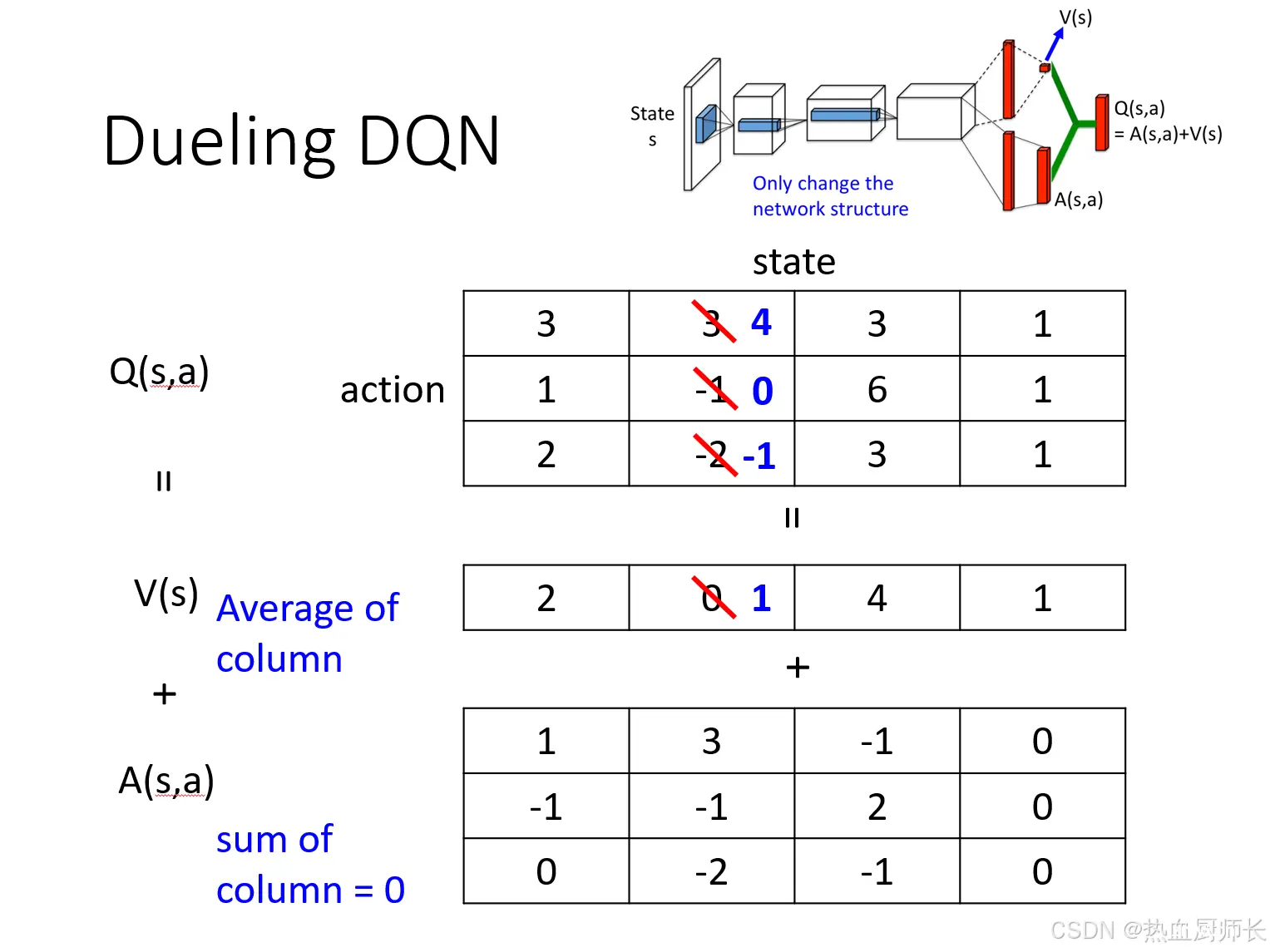
假设现在有一个
Q
(
s
,
a
)
Q(s,a)
Q(s,a)的output是上面第一个table,它可以被拆解为
V
(
s
)
V(s)
V(s)和
A
(
s
,
a
)
A(s,a)
A(s,a)。DQN的输出只有
Q
(
s
,
a
)
Q(s,a)
Q(s,a),直接估计Q值,可能导致在动作选择和价值评估过程中引入较大的误差。
如果且换到Dueling DQN,我们想针对性的只改前两个action的输出,不用直接修改
Q
(
s
,
a
)
Q(s,a)
Q(s,a),而是修改的是
V
(
s
)
V(s)
V(s),所以当我们把第二个state从0改成1,这样做的结果是改了所有的action的output。可能会出现一种情况,第三个action,我们根本没有sample到,但它的
Q
(
s
,
a
)
Q(s,a)
Q(s,a)就被降低了。这样就使得训练更有效率。
为了让model训练更加有效,而不是出现
V
(
s
)
V(s)
V(s)都为0,所以会对下面的
A
(
s
,
a
)
A(s,a)
A(s,a)做一个限制,所有的action加起来是为0。这样就相当于强迫model需要学习
V
(
s
)
V(s)
V(s)的值。
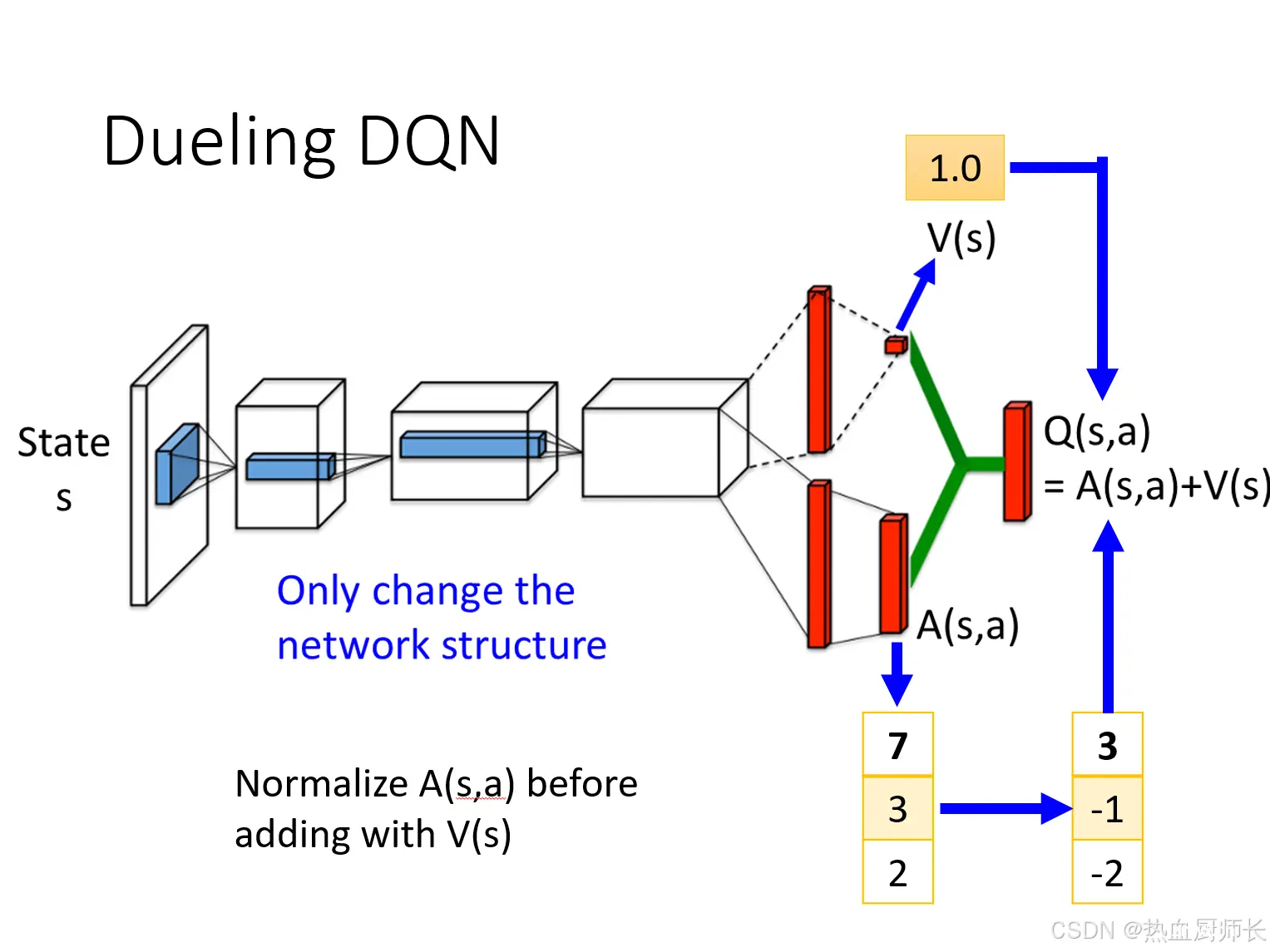
在实际训练中,我们会将上图中
A
(
s
,
a
)
A(s,a)
A(s,a)求和取平均,再减去这个平均值,[7,3,2]从归一化到[3,-1,-2],然后再加上
v
(
s
)
v(s)
v(s)。
Prioritized Reply
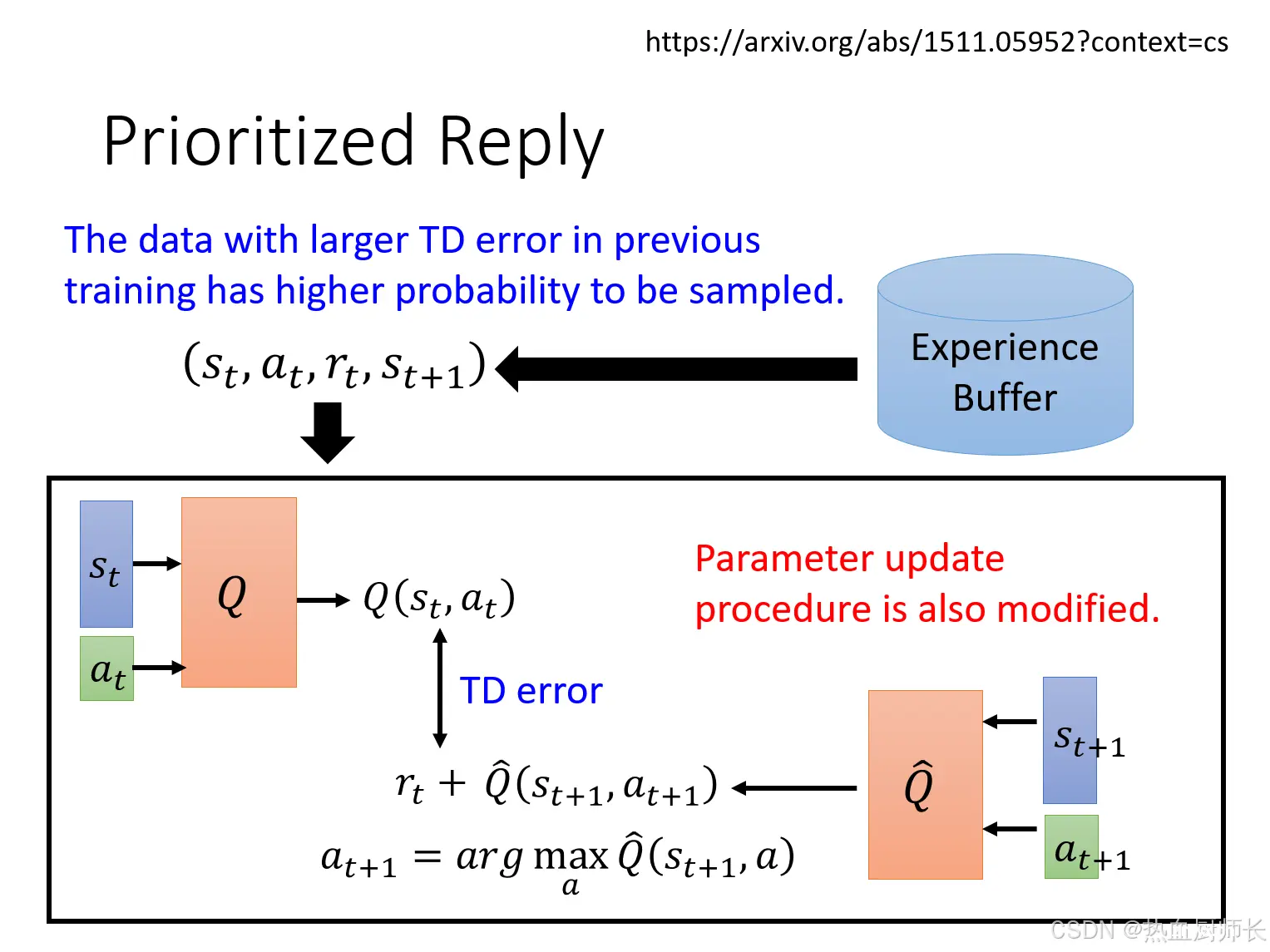
简单来说难例样本挖掘,原先的Replay Buffer中,Buffer中的每一个data experience被采样到的概率是相等的。然而,并非所有的经验对学习都是同等重要的。一些经验,特别是那些 TD 误差较大的data experience,可能包含更多的信息。因此,Prioritized Reply旨在更频繁地采样这些有价值的经验,以提高学习效率。
Multi-Step
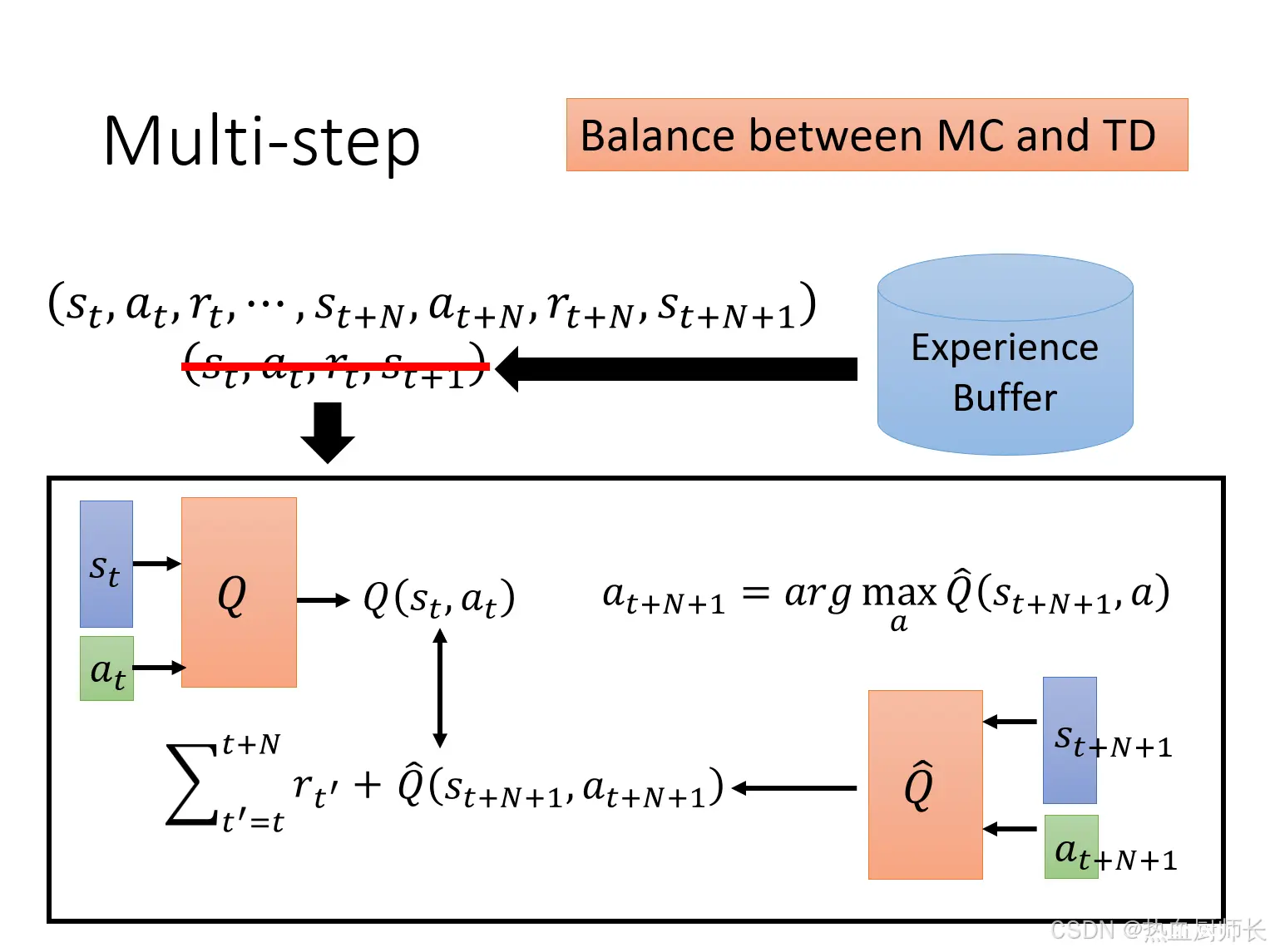
在标准的DQN中,更新Q值时使用的是单步TD误差,即利用一步之后的回报和估计的未来回报来更新当前Q值。Multi-Step方法则利用多步回报来更新Q值,能够更好地反映未来的回报,即使用了MC的误差。那存入到Buffer的data experience就不再是单步的经验,而是多步的experience。
Noisy Net

Noisy Net技术更好理解,是直接往model上添加高斯噪声。也是深度学习中比较常见通用的方法。

需要注意的一个点是,在一个episode中加的noisy是一样的,不能在每个step中变动。否则在同一个episode下,同一个policy在遇到同一个state的情况下,会输出不同的action。保持同一个 episode内的噪声一致,可以减少因策略变化过快而引入的方差,提高Q值估计的稳定性,从而提高学习效率。并且已经有Epsilon Greedy策略保证DQN去explore了,就不必破坏exlpore的一致性了。
Distributional Q-function
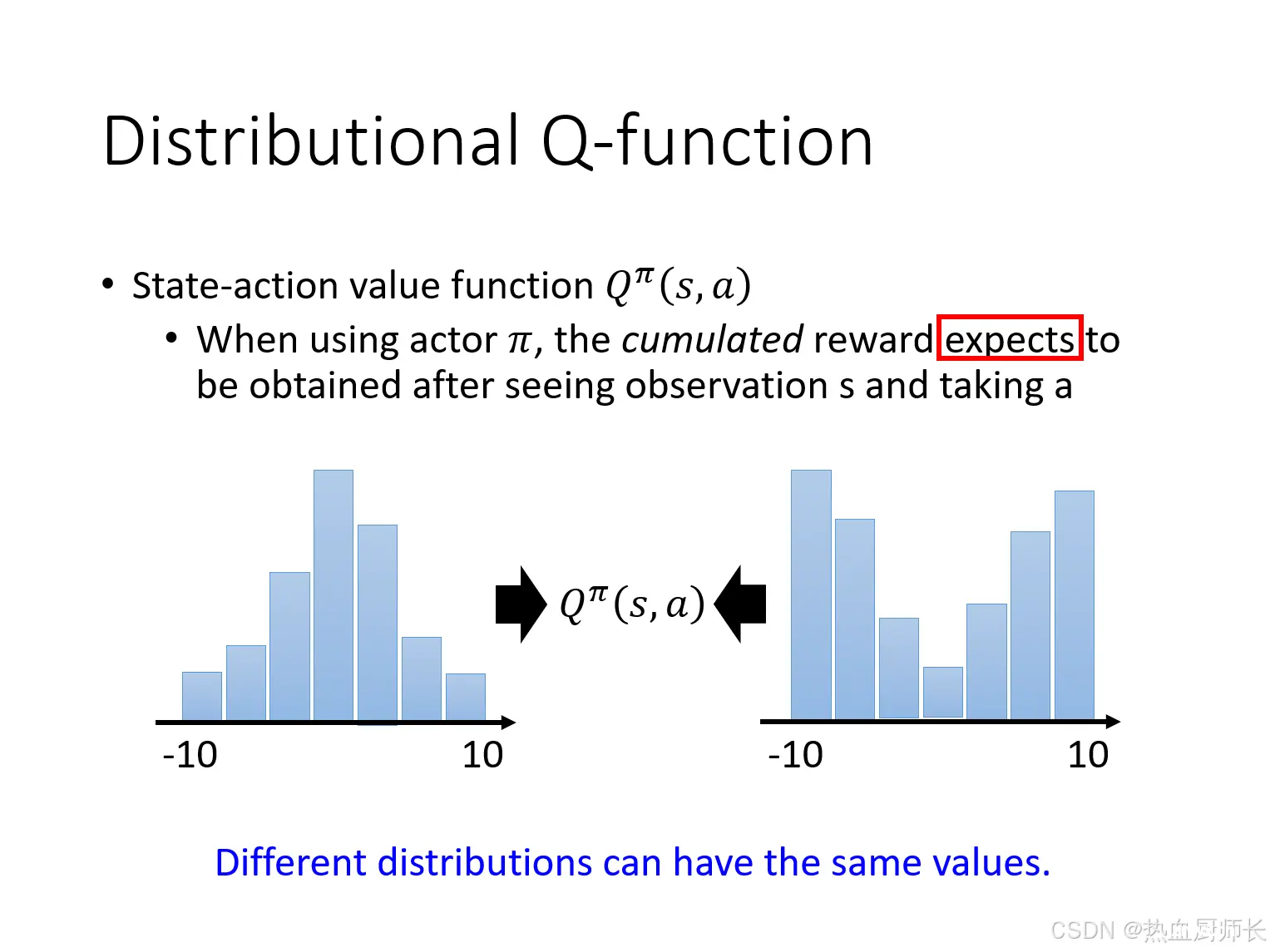
Distributional Q-function的作者指出,如果只是预测DQN只是预测Q值,忽略了回报的不确定性和分布信息。例如上图,两个不同的分布,计算出来的mean值是一样的。Distributional Q-function则不同,它预测了回报的整个分布,即给定state和action下,未来可能回报的概率分布。这意味着我们不仅知道最有可能的回报是多少,还知道回报的分布情况(如方差、bias等)。
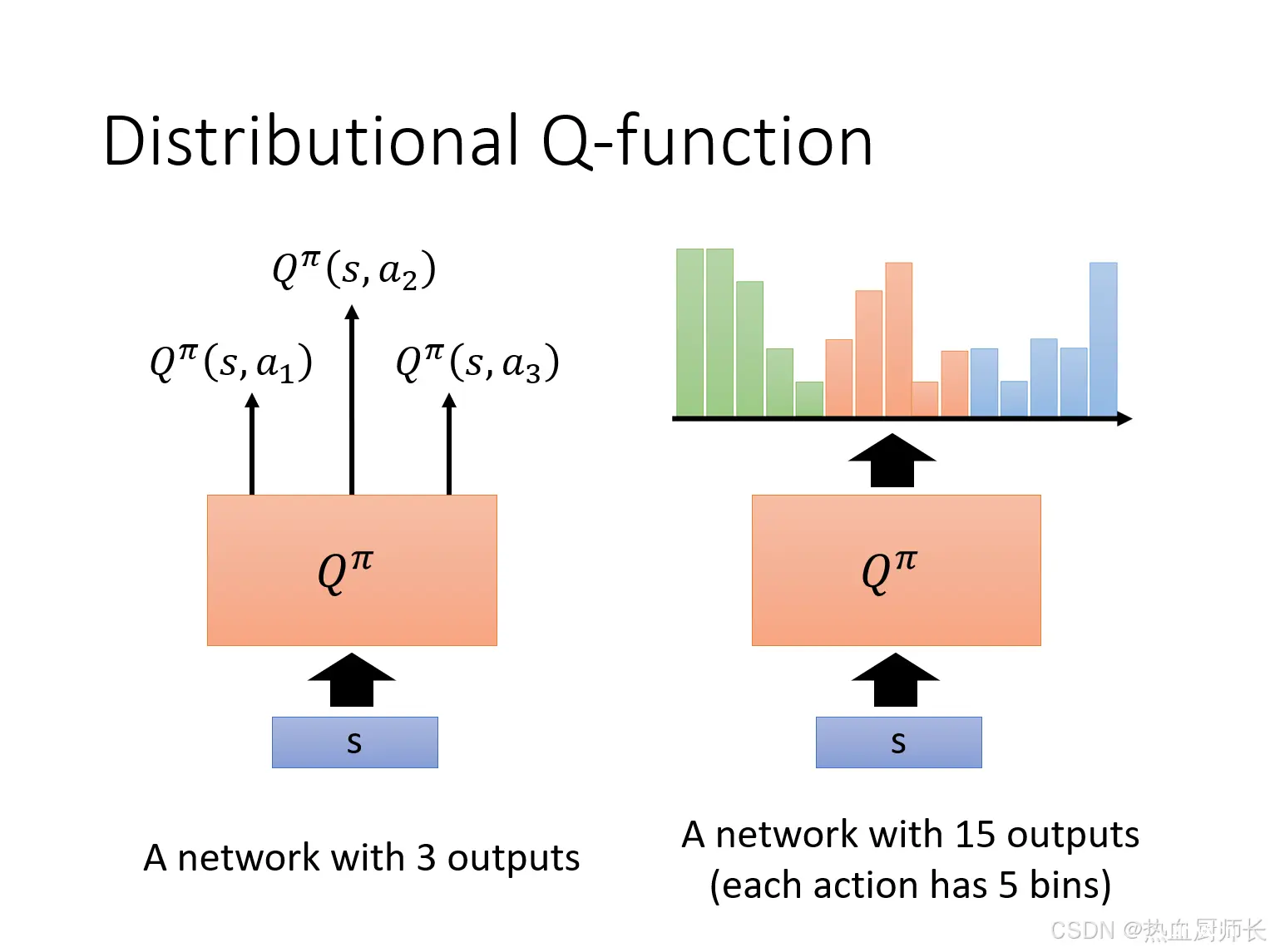
实际训练中,Distributional Q-function会将预测1个action,拆成预测n个bins。这样,原来
s
1
s_1
s1和
s
2
s_2
s2都是预测出来
a
1
a_1
a1,拆出来几个bins之后,有可能就会到同一个
a
1
a_1
a1的distribution中的不同bin里了。DQN通过学习实际的概率,可以使得训练更稳定。
Rainbow
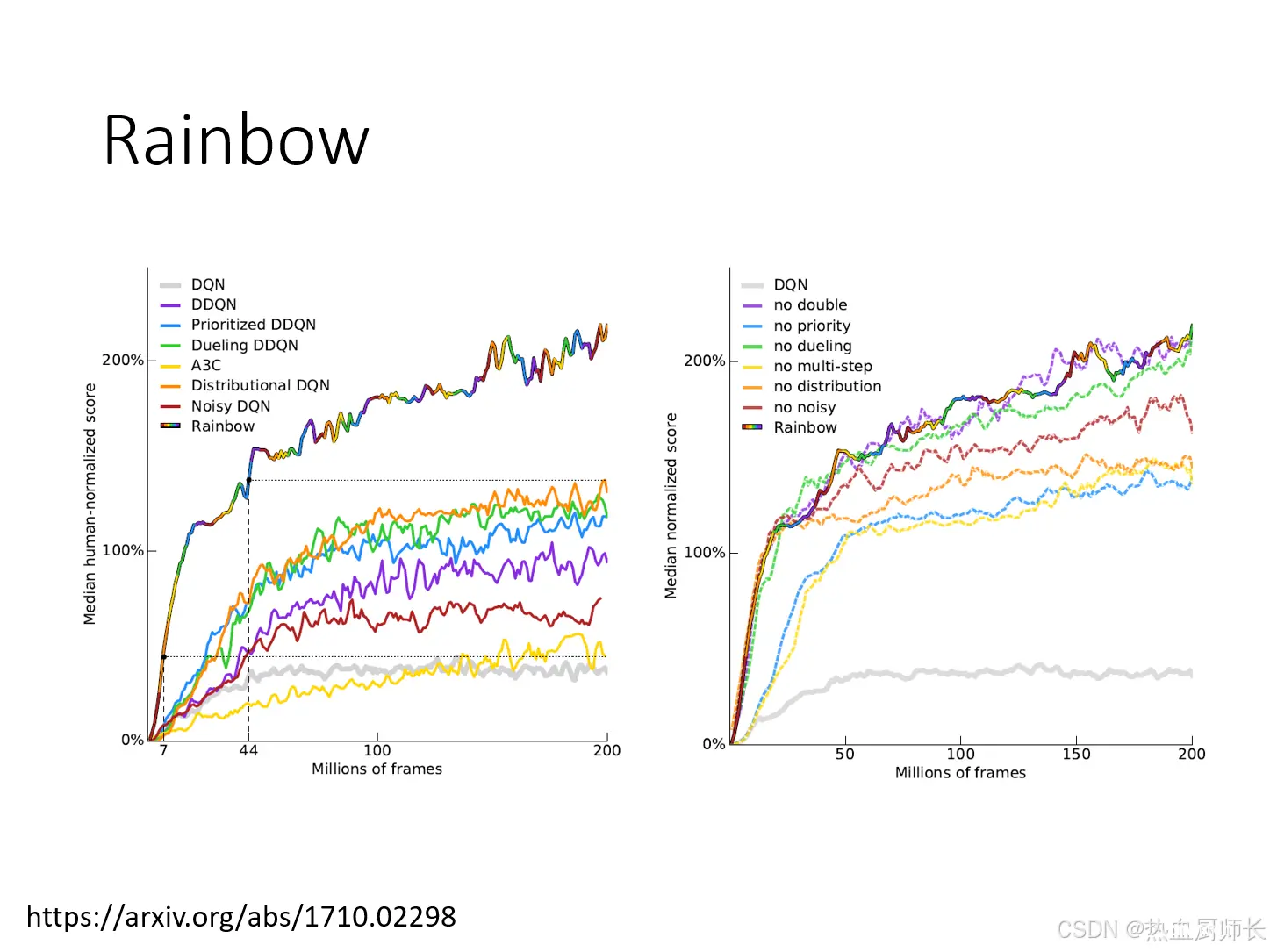
Rainbow的作者把几种方法叠加起来一起放到Q-Learning中训练。里面值得一提的是,A3C里面已经有类似Multi-Step将MC-TD结合到一起的方法了,所以就没有Multi-Step了。另外从右边的曲线上看,拿掉Double DQN之后,效果和Rainbow没什么差别。作者的解释是说Double DQN本身的作用是避免over-estimate。但加了Distributional DQN之后,就不会over-estimate。因为在预测Distribution的时候,预测的范围是有限的,不可能是无限高/无限低的,所以会人为的设置一个范围,这变相就限制了estimate的区间,所以实际上是有Double DQN的作用。
Continuous Actions

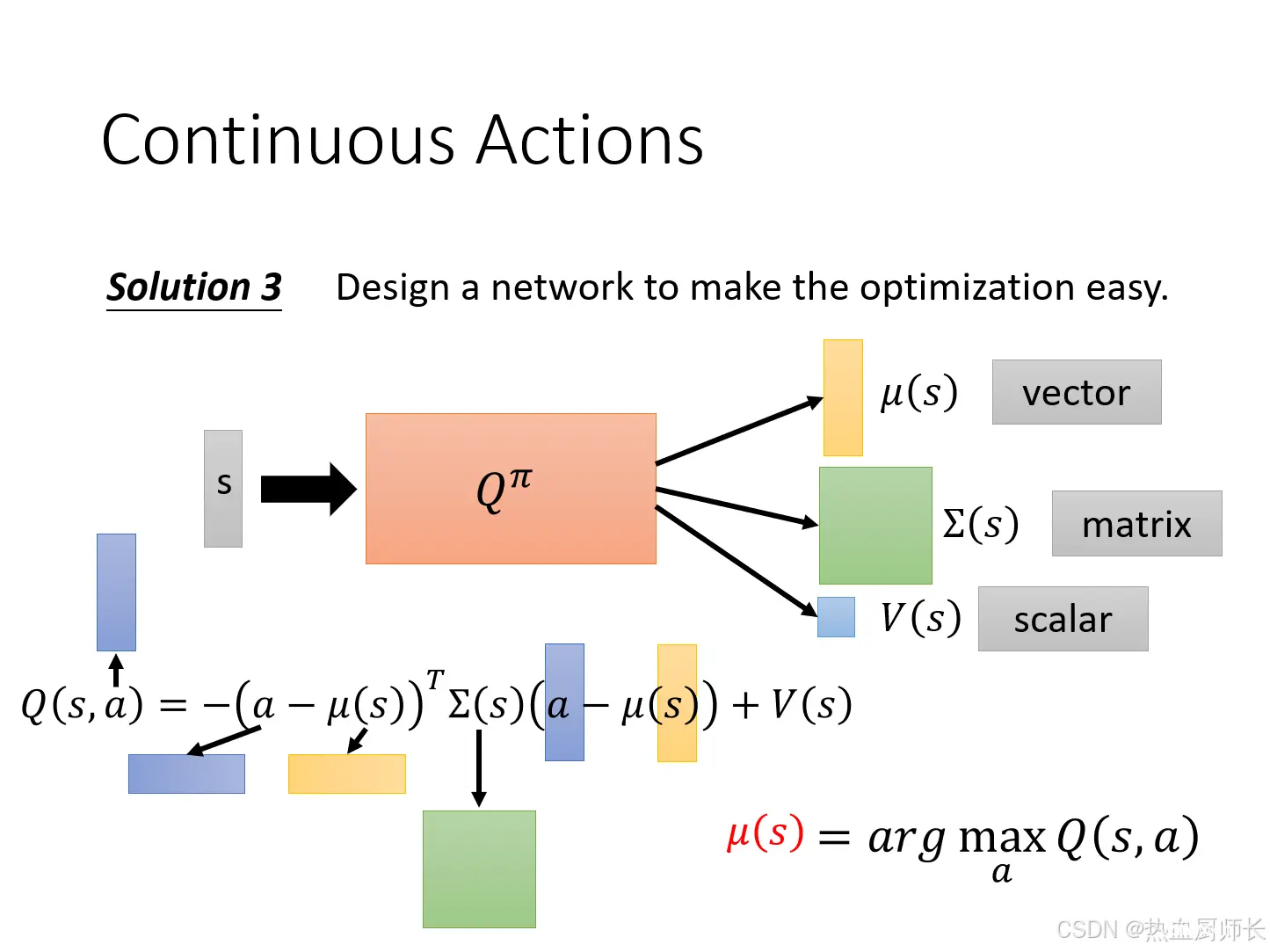
我们上面讨论的Q-Learning问题,大多都是action离散的,但很多问题的action是连续的,比如自动驾驶,机械臂控制。你需要转动多少度的方向盘和机械臂。这是没办法穷举的,这里面有几种方法:
有限采样,每次sample N次,把N个action丢进去计算,再选择最大的Q value。由于只是有限次数,没办法覆盖所有情况,所以不是一个很精确的方法。把action当作是model的参数,利用模型优化的方法去找最好的参数。特别设计一个Network架构,使得优化很容易。将
Q
π
Q^\pi
Qπ的输出变成三个
μ
(
s
)
\mu(s)
μ(s)、
∑
(
s
)
\sum(s)
∑(s)、
V
(
s
)
V(s)
V(s) ,然后通过上面的公式,输入a再计算出
Q
(
s
,
a
)
Q(s,a)
Q(s,a)。就是把向量转换成标量,和VAE中的重参数化差不多。因为
∑
(
s
)
\sum(s)
∑(s)其实是方差(在图片上没有体现),它一定是一个正值,所以当
a
=
μ
(
s
)
a = \mu(s)
a=μ(s)时,会取到最大值
V
(
s
)
V(s)
V(s)。不用Q-Learning。
以上就是李宏毅老师关于Q-Learning课程的全部内容了。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。