AI 推理成本高居不下,如何突破算力垄断?
AI科技大本营 2024-06-17 11:01:04 阅读 99

算力成本高昂、大模型参数越来越大、多模态模型让推理成本再提高 2 个数量级、推理效率低、业务场景丰富但落地链路长等一系列现实问题,成为制约 AI 应用广泛落地的关键因素。如何降低算力成本,迎接推理算力爆发时代的到来?刚刚结束的 2024 全球机器学习技术大会上,王闻宇先生以《如何做到算力基建和推理优化的“软硬兼施”与创新突破》为题,对 AI 推理成本高企的原因进行深度剖析,并给出两个降低推理成本的有效方法。
作者 | 王闻宇
责编 | 王启隆
出品丨AI 科技大本营(ID:rgznai100)

当前,AI 推理面临的首要问题是高昂的成本:
以 GPT-4 当前的推理价格为例,如果我们做一个粗略的估算,假设日活跃用户达到 10 亿,每人每天使用 7,000 个token(包含上下文信息),并且不考虑目前百万级脱壳的费用,每天产生的费用将高达 2.1 亿美金。若按 365 天计算,年费用将达到惊人的 600 亿美金。

GPT-4 推理价格估算 = 用户数 x 每用户生成 Token 数 x 单位 Token 推理价格 https://openai.com/pricing
这一数字相当于超过了 40 座世界第一高楼迪拜的哈利法塔(Burj Khalifa)的造价。更值得注意,这还只是今天的情况,还未考虑到多模态应用等更广泛的普及场景,因此实际使用量可能远超这一数字。
600 亿美金的概念意味着,如果 AI 推理市场的体量再放大十倍,其规模将接近甚至超过当前整个云计算产业的总收入。这表明 AI 推理在未来市场的发展潜力巨大,远远超过现有的云计算产业。因此,从商业角度看,AI 推理无疑是一个具有巨大潜力和前景的市场。
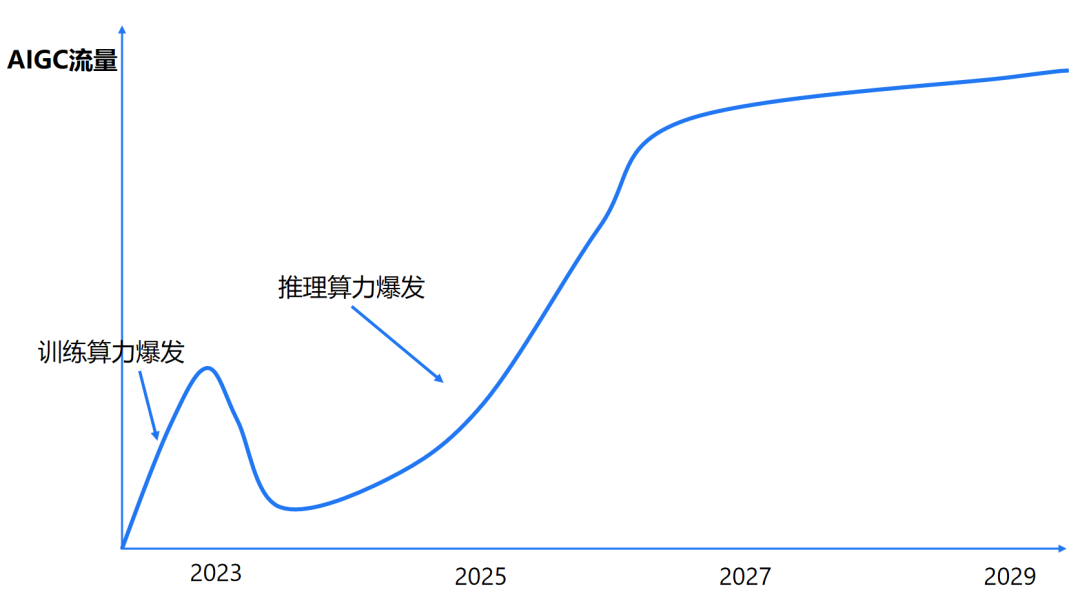

AI 推理成本高昂的原因分析
挑战 1:生产资料昂贵
导致 AI 推理成本高昂的原因有多种,其中生产资料成本是重要因素之一。例如,某些顶级芯片制造商的产品毛利率超过了 70%。
当然,成本不仅仅局限于 GPU,电力消耗也是重要成本因素,特别是在电费较高的地区,电力成本可以显著影响总体运营成本。
挑战 2:LLM 参数还在越来越大
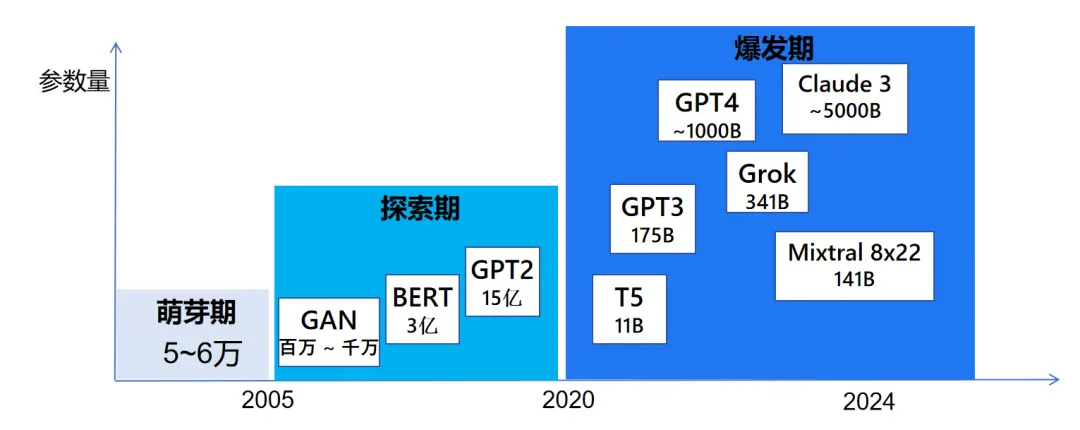
近年来,随着技术的不断进步,大型模型的参数规模也在迅速扩张。例如,今年 Mixtral 推出了具有 8*22 141B 参数的模型,Grok 发布了拥有 341B 参数的模型。Llama3 也公开了 400B 参数的模型,而传说中的 GPT-5 的参数规模更是将迈上新的台阶,尽管具体数值尚未揭晓。更大的模型意味着更高的计算需求,从而推高了推理成本。
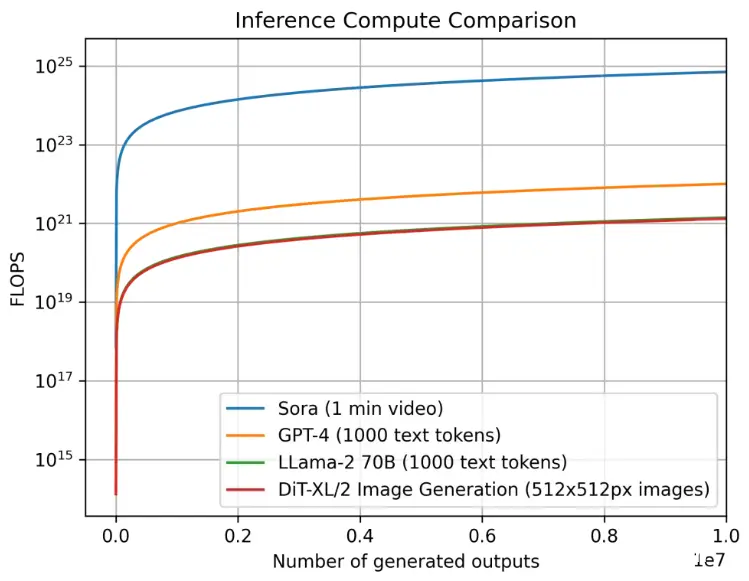
随着多模态技术的发展,尤其是音视频数据的处理,进一步增加了推理的复杂度。虽然据说 Sora 只有 10B 的参数量(没有得到官方的证明),但是音视频的生成具有长序列特性(对比 LLM 的 Token 数量大得多得多), 这种长序列特性会使得计算量和显存会大大增加,这最终也会使得推理成本的增长更是呈现指数级上升的趋势。
挑战 1:生产资料昂贵
导致 AI 推理成本高昂的原因有多种,其中生产资料成本是重要因素之一。例如,某些顶级芯片制造商的产品毛利率超过了 70%。
当然,成本不仅仅局限于 GPU,电力消耗也是重要成本因素,特别是在电费较高的地区,电力成本可以显著影响总体运营成本。
挑战 2:LLM 参数还在越来越大
近年来,随着技术的不断进步,大型模型的参数规模也在迅速扩张。例如,今年 Mixtral 推出了具有 8*22 141B 参数的模型,Grok 发布了拥有 341B 参数的模型。Llama3 也公开了 400B 参数的模型,而传说中的 GPT-5 的参数规模更是将迈上新的台阶,尽管具体数值尚未揭晓。更大的模型意味着更高的计算需求,从而推高了推理成本。
挑战 3:推理效率低
大模型系统的推理效率低下是行业普遍存在的问题,这主要是由于算法和硬件两方面原因导致的。
首先在算法层面,由于大模型自回归推理的特性,计算量随着文本生成长度平方增长,意味着生成的文本序列越长,推理的速度越慢。
其次经典的 GPU 硬件架构需要在推理过程中频繁进行数据传输和搬运,这会显著限制推理效率。比如在推理过程中,大量的数据通信发生在各级缓存层之间,不仅消耗 GPU 的算力,而且系统需要花费大量时间等待数据的搬运工作完成。
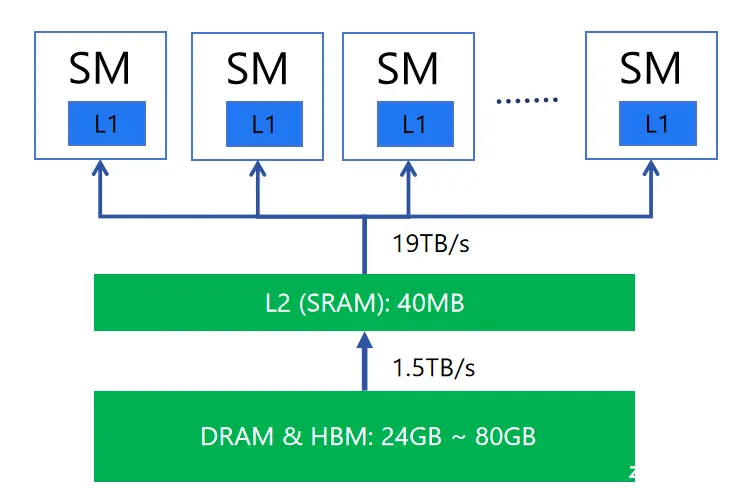
挑战 4:业务场景丰富,落地链路长
业务场景丰富和落地链路长会间接导致推理成本过高。
当业务场景变得越来越多时,为了满足各种复杂和多样的需求,通常需要设计和训练更为复杂和庞大的模型。这些模型往往需要更高的计算资源和存储资源,导致推理过程中所需的计算成本增加。
落地链路长通常意味着从模型训练到实际部署应用的过程中,需要经过多个阶段和环节,包括数据预处理、模型训练、模型优化、模型部署等。这些环节都可能涉及到计算和存储资源的消耗,导致推理成本增加。
降低推理云成本两个有效思路
思路 1:分布式云,充分动员市场,降低生产资料成本
分布式云方面,充分动员市场的社会、经济、技术三大驱动力,以获得更便宜的生产资料,包括 GPU 卡与电力能源等。
以 GPU 为例,虽然高端 GPU 的价格昂贵,但是中低端 GPU/旧 GPU 便宜。我们可以通过分布式云的方式,利用其强大的市场动员能力,将大量中低端 GPU 汇聚起来(如 RTX 4090 等),形成一个庞大的分布式 GPU 算力网络,从而降低算力成本。同时,通过合理的能源管理和调度,可以降低能源消耗和散热成本,进一步降低推理成本。
传统的大型数据中心虽然具备强大的处理能力,但其成本高昂,不仅包括硬件设备的购置和维护,还包括能源的消耗和散热的需求。分布式云通过建立在全球各个位置小型数据中心或边缘计算节点,充分利用各地的廉价能源和算力资源,降低整体成本。
思路 2:AI 推理加速,提效降本
虽然生产资料的成本是能通过分布云的方式降低,但是下降空间都是有限的。其实降低推理成本,还有一个大杀器,用得好,其降本空间更大,这就是推理加速技术。
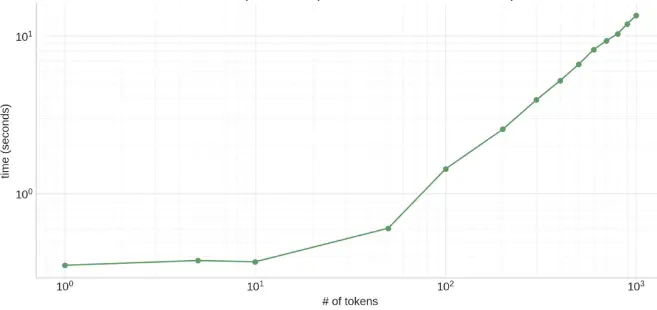
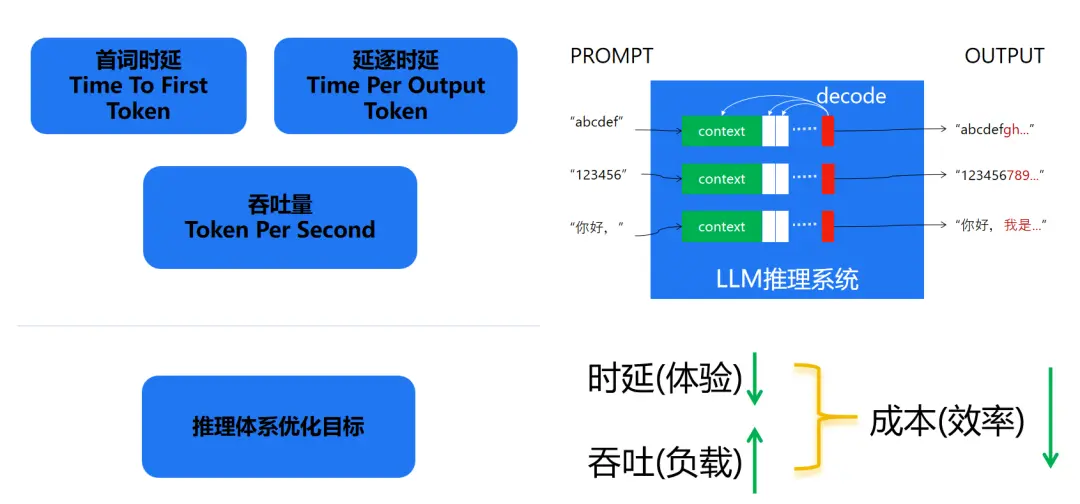
那么什么叫推理加速技术,拿 LLM 来举例,我们重点关注以下三个指标:
Time To First Token (TTFT): 首 Token 延迟,即从输入到输出第一个 token 的延迟。在在线的流式应用中,TTFT 是最重要的指标,因为它决定了用户体验。
Time Per Output Token (TPOT): 每个输出 token 的延迟(不含首个Token)。在离线的批处理应用中,TPOT 是最重要的指标,因为它决定了整个推理过程的时间。
Throughput:吞吐量,即每秒针对所有请求生成的 token 数。以上三个指标都针对单个请求,而吞吐量是针对所有并发请求的。

这是为了确保用户能够更快地获得系统的反馈,从而提升用户体验。同时,我们还努力增加系统的吞吐量,这意味着系统能够在单位时间内处理更多的数据,让系统推理的效率更高。
降低时延和增加吞吐量不仅关乎用户体验,更直接关系到推理成本。优化后的系统能够更高效地利用计算资源,如 CPU、GPU 和内存,从而降低单位推理任务的成本。这种成本降低不仅体现在硬件资源的消耗上,还体现在时间成本上,因为更高效的推理过程意味着更短的任务完成时间。
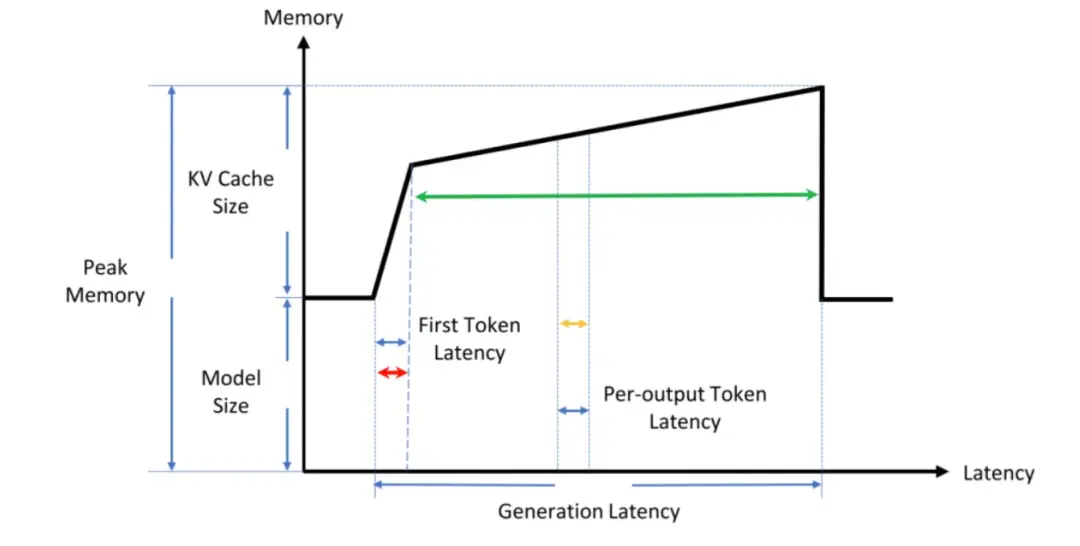
当同样的 GPU,如果更短的时间能够完成一个任务,就说明单位时间内能完成更多的任务,这样单任务的时间变短了,生产资料不变,那就说明单任务的推理成本降低了(例如,之前 10s 生成一张图片,现在 1s 生成一张图片,相当于 10s 生成了 10 张图片,也就时每张图片的推理成本降低了 10 倍)。
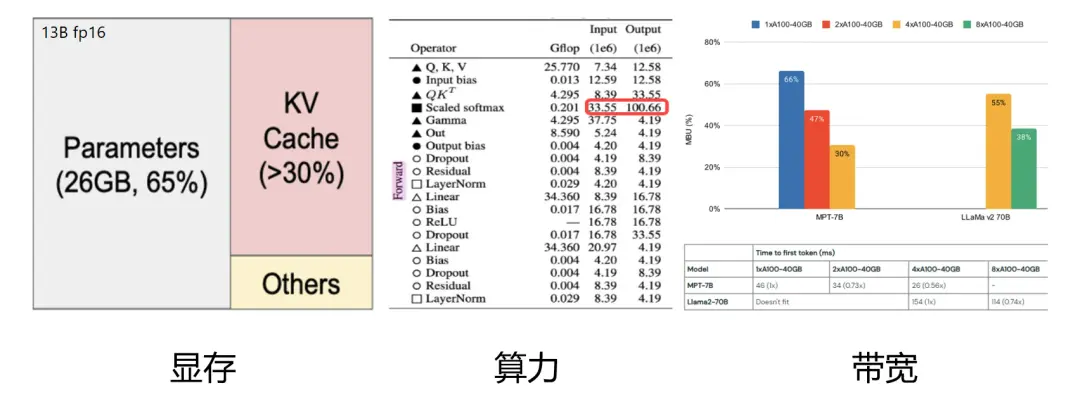
推理加速的本质在于解决制约性能的三要素:显存、算力和带宽。
想象一下,如果有一块固定的显存,能不能像打理家务一样精打细算,让这块显存存下更多的东西?这就是一个值得考虑的点。同样的,对于算力,我们是不是也能在运行时更精细地管理,让更多的计算任务同时跑起来呢?说到带宽,其实它就像是数据在显卡和其他存储设备之间传递的“道路”。如果我们能想办法减少数据在这条“道路”上的拥堵,比如降低通信量,那也是一种优化的思路。

推理优化实践:算法、系统、硬件的协同创新
针对制约性能的显存、算力和带宽三要素,我们进行了诸多推理优化实践,形成了算法、系统、硬件的协同创新,结合了一些最新的研究,探索了一些有效的方法。总体上可以分为算法优化、统一推理框架以及硬件适配这三个层次的综合优化。
无损优化系列
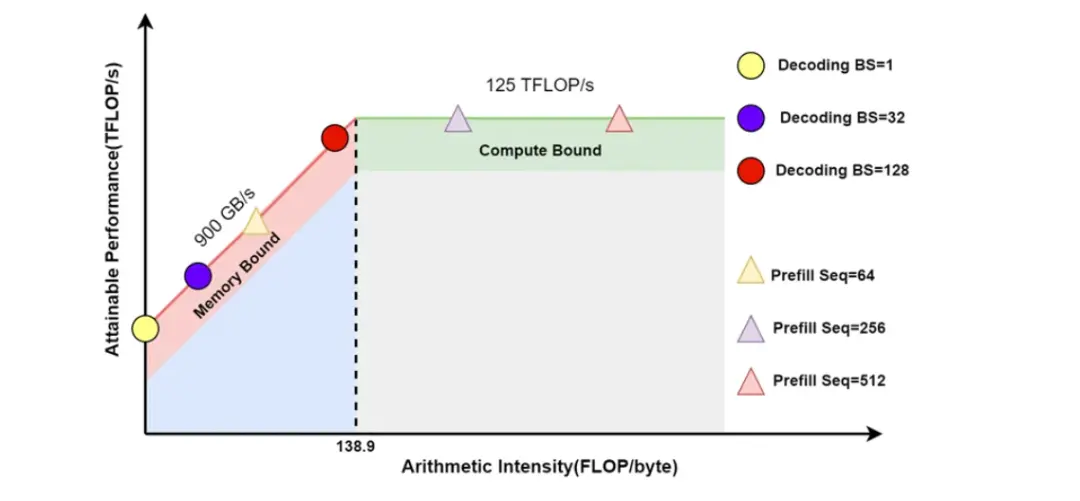
当前主流 LLM 基本都是 Decoder Only 的 Transformer 模型,其推理过程可以分为两个阶段。
Prefill:根据输入 Tokens(I,like,natural,language) 生成第一个输出 Token(Processing),通过一次 Forward 就可以完成,在 Forward 中,输入 Tokens 间可以并行执行(类似 Bert 这些 Encoder 模型),因此执行效率很高,通常都会位于 Compute Bound 区域。
Decoding:从生成第一个 Token(Processing) 之后开始,采用自回归方式一次生成一个 Token,直到生成一个特殊的 Stop Token(或者满足用户的某个条件,比如超过特定长度) 才会结束,假设输出总共有 N 个 Token,则 Decoding 阶段需要执行 N-1 次 Forward,这 N-1 次 Forward 只能串行执行,效率很低,通常都会位于 Memory Bound 区域。
无损优化的本质,从一定程度上讲,是将 Memory Bound 转化为 Compute Bound。
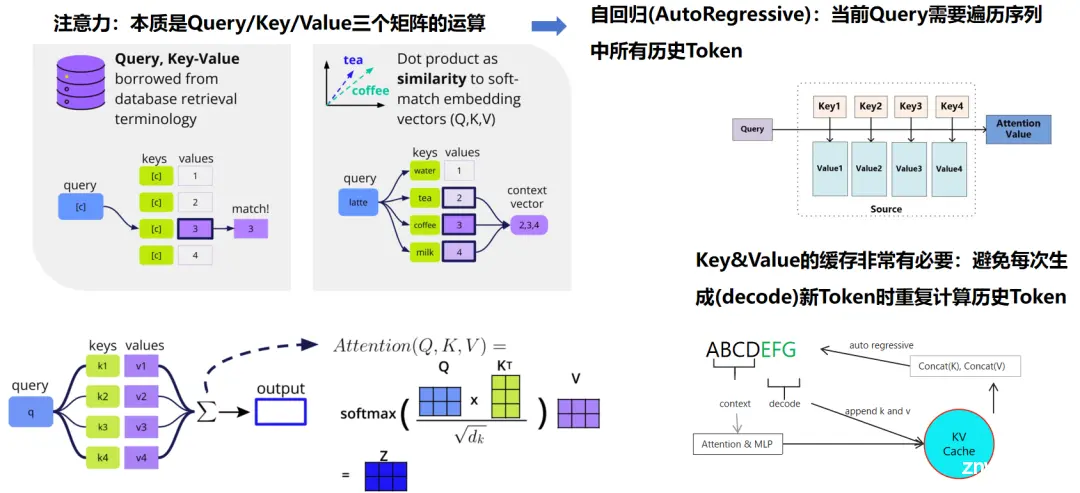
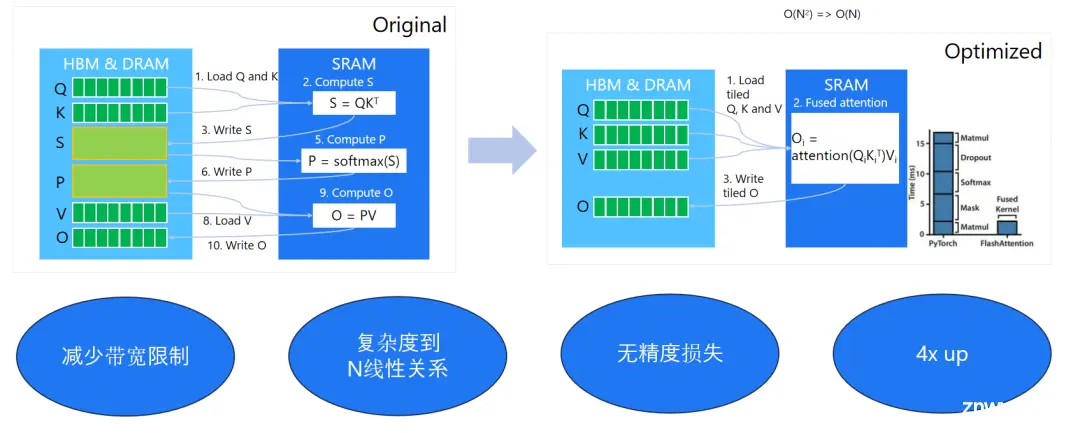
方法 1:算子融合,重点优化注意力计算和 KV-Cache
算子融合主要是针对 Transformer 模型中的两大核心组件——注意力(Attention)机制与前馈神经网络(FFN)进行优化,旨在显著提升推理速度。在此优化策略中,我们引入了一项被称为“KV 缓存”(KV-Cache)的关键技术,该技术使得 AI 模型在执行期间无需频繁重载数据,大幅度提升了运行效率。
具体而言,算子融合等同于将原本分离的运算步骤整合为单一的综合性操作,从而规避了数据在各操作间传输的开销,并允许这些操作直接在 GPU 的共享内存中高效执行。这一转变有效减少了 GPU 与外部存储器之间的数据交换需求,进而增强了整体处理效能。尤其在配备非高速 HBM 内存的高端显卡如 RTX 4090 上,此类优化显得尤为关键,因为这类硬件配置在没有高速内存支持的情况下,更依赖于高效的内存使用策略。
在实施算子融合策略时,我们侧重于注意力计算及其伴随的 KV-Cache。KV-Cache 的概念根植于 Attention 机制,该机制涉及 Query、Key 和 Value 三个基本元素。其中,通过 Query 与 Key 的矩阵乘积并经由 Softmax 函数处理后,选择相应的 Values 进行后续计算。鉴于在 Attention 计算过程中,Key 和 Value 会被反复访问,采用 KV-Cache 策略能够保留这些中间结果,避免了重复加载的耗时操作,从而在每个计算周期内显著增强了数据处理与传输的效率,这是 KV-Cache 技术的核心所在。
对于比较耗时的注意力计算,其涉及多次矩阵场乘和 Softmax 计算,如果可以将这些算子融合为一个大算子,同时减少慢速片外显存到高速的片上显存的传输次数,则可以将复杂度从平方降低到线性,让推理效率大幅提升,这是面向注意力计算的算子融合算法的核心思想。
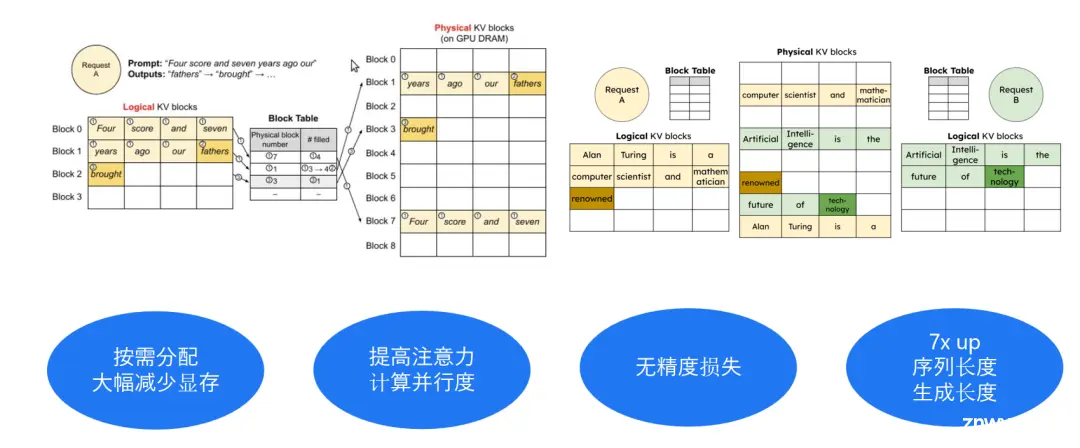
方法 2:以虚拟内存的方式管理显存,减少显存碎片,提升显存使用效率
传统的推理方案中,系统由于无法精确估算每个生成的序列需要多少显存,非常简单粗暴的按配额为每个序列预分配一大段存储空间,这种做法一方面造成大量的显存空间浪费,另一方面也限制了并发处理序列的最大数量。因此,我们在推理过程中借鉴操作系统的“虚拟内存”概念,实现了动态显存管理技术,把逻辑和物理内存分开,用一个指针的方式去映射。
当处理多个序列时,这种方式能更灵活地利用显存碎片,让显存使用得更高效。这就像是把一堆小碎片重新组合起来,变成有用的东西一样。总的来说,这些技术都是为了让 AI 模型运行得更快、更高效。
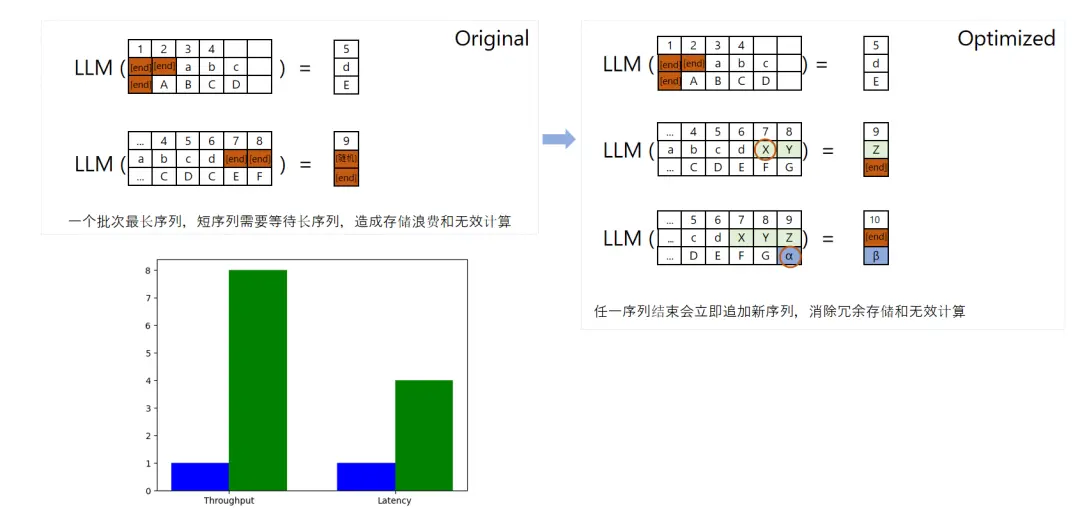
方法 3:Continuous Batching,减少无效显存占用,提高显存利用率
当我们进行模型训练时,我们通常会分配一个固定的内存区域给模型。但问题是,用户输入的数据长度可能各不相同。有些人可能只输入几个字,而有些人可能会输入一大段文字。如果我们不进行优化,那么当较短的输入完成后,剩余的内存空间就会被浪费掉。
为了解决这个问题,我们采用了“Continuous Batching”方案。简单来说,就是当一个输入序列结束后,我们不会让剩余的内存空间闲置,而是会接着填充下一个输入序列的数据。这样一来,内存的使用就更加高效了。但这个方法也有个缺点,那就是在处理序列对齐时可能会增加一些额外的开销。所以,是否使用这个方法,还需要根据具体的应用场景来决定。
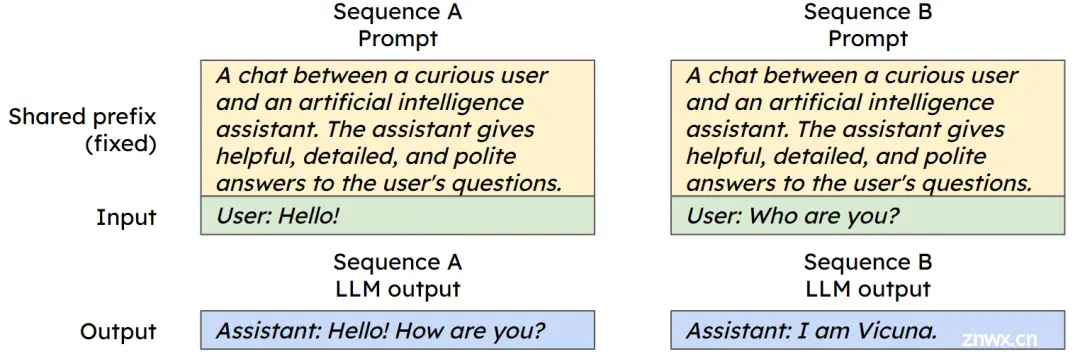
与此同时,我们创新了“共享 Context”概念,用以减少计算量和显存开销减少计算量和显存开销。在实际应用中,很多时候用户会使用相同的提示词或问题来咨询。
为了避免重复存储这些相同的内容,我们可以将它们放在共享内存中。这样,当有多个用户使用相同的提示词时,我们就可以直接从共享内存中读取,而不需要重复加载,从而节省了内存和计算资源。

以上这些方法都属于基础的推理加速技术,它们的特点是不会对模型本身造成任何损害。但仅仅依靠这些无损的优化方法,我们可能无法达到理想的加速效果。所以,在实际应用中,我们还需要结合其他更高级的技术来进一步提升推理速度。
有损优化系列
我们在提升推理速度时,真正的挑战并不在之前提到的无损优化上,而是在接下来要讲的有损优化上。那么,什么是有损优化呢?
所谓有损优化是针对模型的结构特点,对模型进行压缩,通过小型化减少推理过程中的计算负载和数据传输量,进而提高推理效率。模型压缩可能会导致轻微的精度损失,但这些损失是可控且可接受的,带来的推理效率提升非常显著,本质是用少量的精度损失换取更大的推理加速。
方法 1:量化
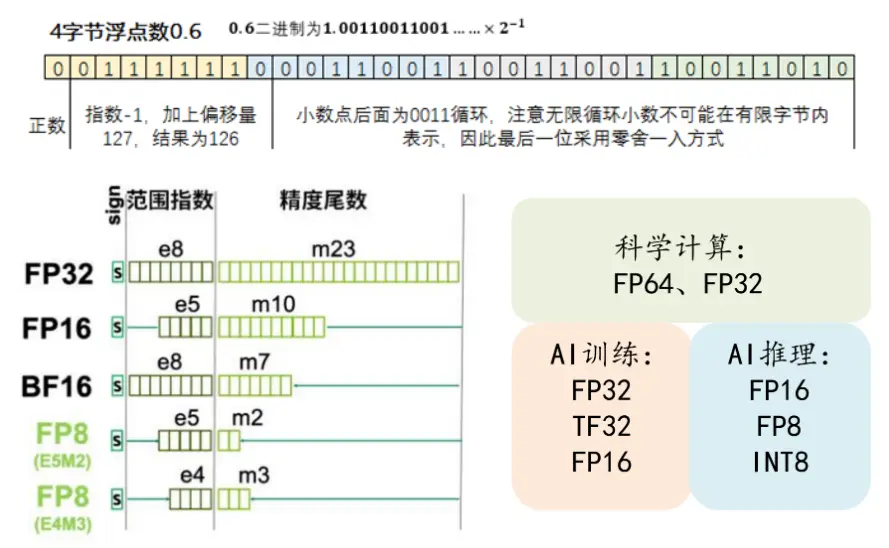
首先,我们要理解 AI 模型中的浮点数。在 AI 模型中,浮点数是由符号位、指数位和小数位组成的。我们经常听到的 FP32、FP16、FP8,其实就是在这些位数上做了不同的取舍。这些浮点数的位数越来越少,其实是 AI 硬件发展的一个趋势。
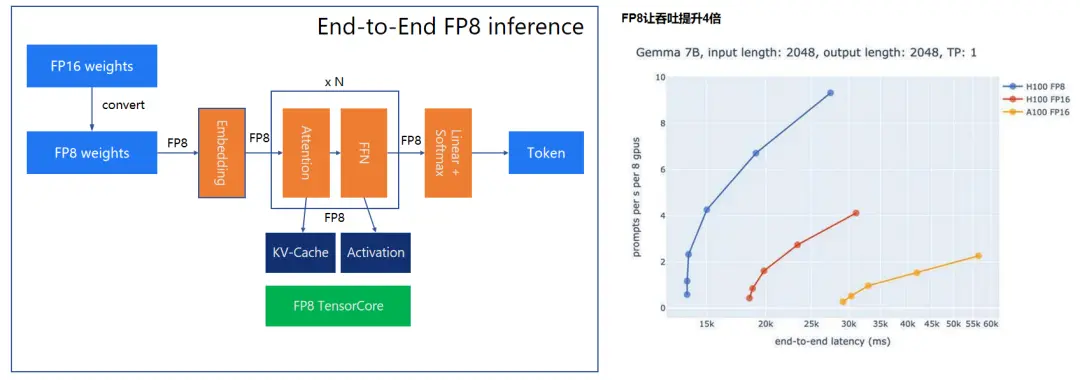
下面这个图展示的是英伟达最近几代 GPU 的架构,从 Ampere 架构到今天的 Hoper/Ada Lovelace 和 Blackwell 架构,你可以看到它们的浮点运算能力在逐渐增强,从 FP16->FP8->FP6/FP4,为什么要这么做呢?其实,这就是在进行能够更好地做量化。

量化就是将模型本身浮点数类型(FP16)转换成整数(INT8/INT4等)或者更低位数类(FP8 等)的方法,从而提高计算速度。
我们经常听到的 INT8 量化就是这样一种技术。但是,INT8 量化的一个问题在于,它不能对所有的内容都进行量化。对于一些复杂的操作,如 SoftMax 操作,可能需要先还原到 FP16 或 FP32 再进行计算。
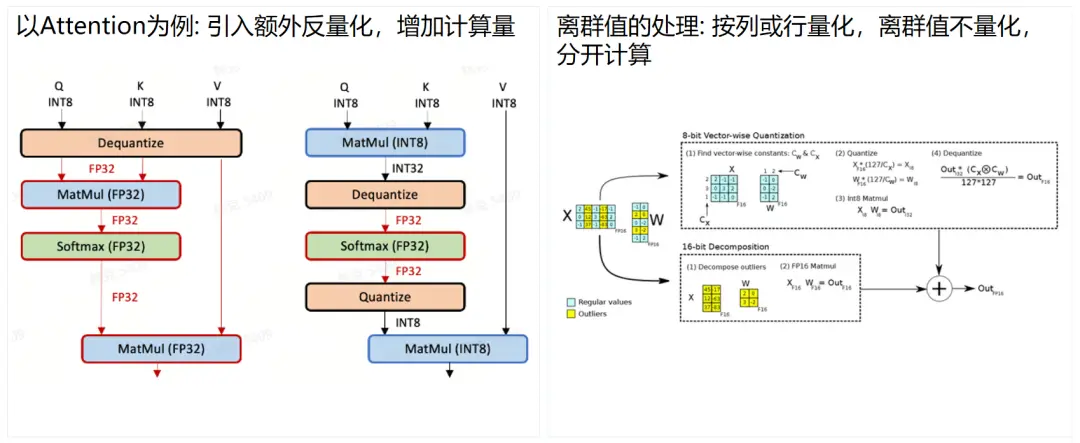
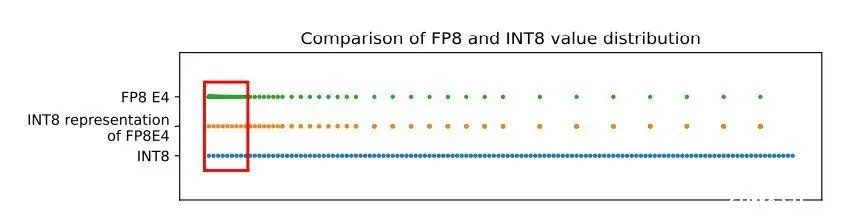
传统的显卡,包括一些国产显卡,在量化时主要使用 INT8,并结合反复的量化和反量化来达到最终的效果。但是,INT8 有一个问题,就是当有大量接近于零的数据时,它们可能会被直接清零,导致精度损失。
FP8 和 INT8 的值分布
而 FP8 则不同。即使在数据接近于零的情况下,FP8 也能很好地保持精度,不会出现直接清零的情况。这就是为什么现在的 4090 显卡以及 A100 等显卡会成为大家的主力选择。它们能够更好地支持 FP8 等低位数的浮点数运算,从而在保持精度的同时,提高计算速度。

FP8 和 INT 的量化对比
现在 A100 和 B100 等高性能计算平台之所以成为大家的主力,主要是因为它们支持全内容量化,特别是 FP8 全链路量化。这种量化方式能在保持精度损失在可接受的 1% - 2% 范围内,显著提升计算速度,有时甚至能达到 4 倍以上的加速效果。这种优化对于需要高效推理的 AI 应用来说,是极具吸引力的。
FP8:全链路量化,存储和计算的全面提升
方法 2:稀疏化的硬件优化
除了全链路量化,稀疏化也是另一种重要的优化技术。对 Transformer 来说,其注意力层的精确计算导致了序列长度二次的运算和内存复杂性,稀疏化可以理解为将矩阵中接近于零的值直接置为零,从而降低计算量。
其中,有一种叫做 HyperAttention 的方法,寻找对角矩阵 D , 一个矮胖矩阵 S, 将有价值的数据集中在斜对角线上,从而通过稀疏化计算实现约等于序列长度一次的运算和内存复杂性。
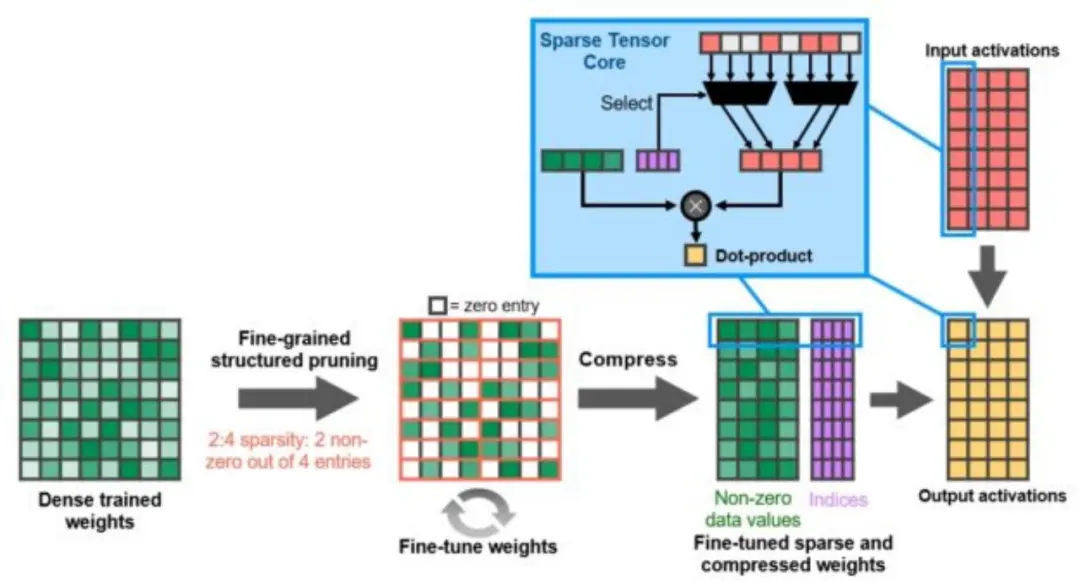
稀疏化的硬件优化
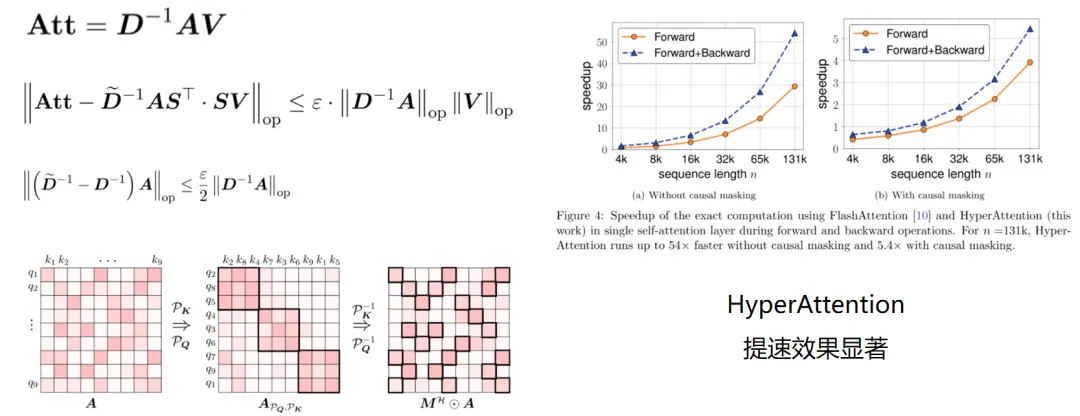
稀疏化加速
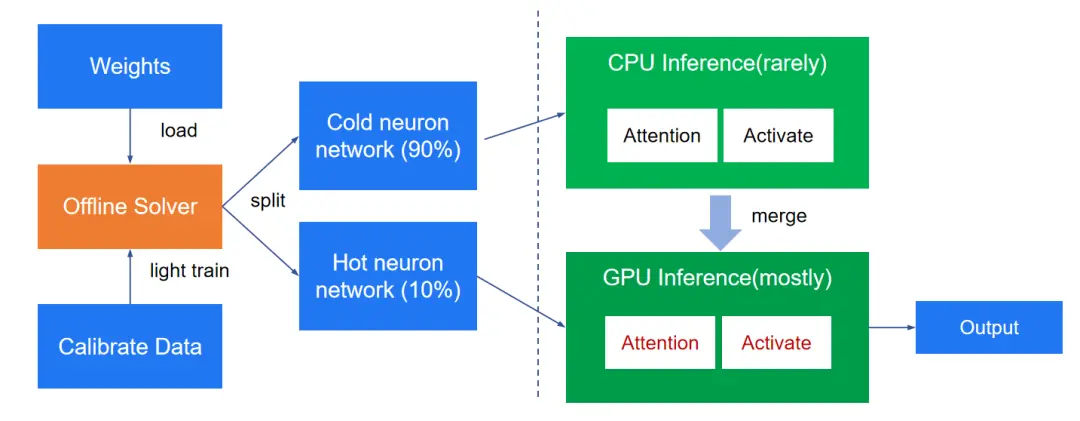
除了 HyperAttention 这种 attention 的近似方法之外,激活稀疏和 KV 缓存稀疏也是非常有效的优化方法,通过激活稀疏的预测方法,可以将热的神经元放入 GPU,冷的神经元放入 CPU,再通过实时预测的方法,动态计算当前输入对应的热神经元,不计算当前输入的冷神经元,从而大大降低神经元的计算量。
稀疏化计算:权重稀疏,减少计算量
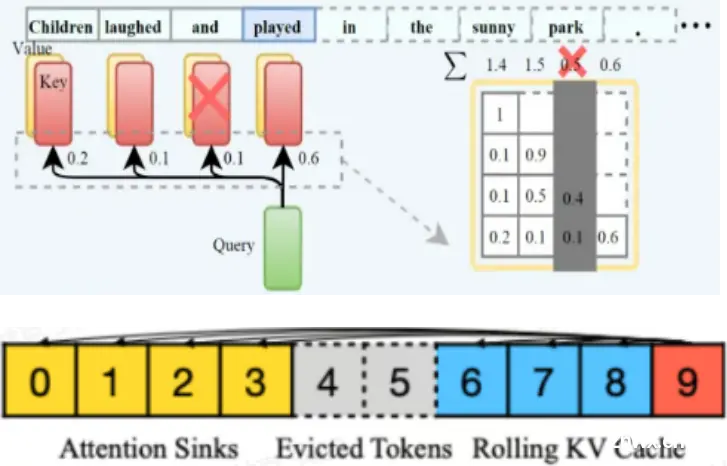
KV 缓存存储的是历史 token 列表,大模型的推理当中,实际只有少部分的热 token 对最终的输出起到决定作用,KV 缓存稀疏正是基于这门一种策略,通过计算不同 token 的累积贡献度,删除掉贡献度最低的 token,从而降低 KV 的输入长度,最终达到加速的目的。
稀疏化计算:KV Cache 稀疏,减少存储,支持长窗口
在有限长度的 KV Cache 中,驱逐与 Query 相关度低的 KV 值。永久保留 KV Cache 中靠前的 KV 值, Decoding 时用较少的 KV 实现较长 KV 的效果。
总的来说,这些推理加速方案为我们提供了更多的选择和可能性,让我们能够根据不同的应用场景和需求来定制最优的 AI 计算解决方案。
但这些原理听起来简单,但在实际应用中却需要针对每个模型进行细致的分析和优化。因为不同的模型对优化的敏感度和需求是不同的。而且,在进行有损优化后,还需要通过评测工具来评估精度损失和性能提升之间的平衡。只有当精度损失在可接受的范围内,且性能提升显著时,这样的优化方案才是有效的。

开发者正在迎接新一轮的技术浪潮变革。由 CSDN 和高端 IT 咨询和教育平台 Boolan 联合主办的 2024 年度「全球软件研发技术大会」秉承干货实料(案例)的内容原则,将于 7 月 4 日-5 日在北京正式举办。大会共设置了 12 个大会主题:大模型智能应用开发、软件开发智能化、AI 与 ML 智能运维、云原生架构……详情👉:http://sdcon.com.cn/
上一篇: 推荐收藏!字节AI Lab-NLP算法(含大模型)面经总结!
下一篇: Android应用程序中使用 Gemini Pro AI开发——2年工作经验如何淘汰10年工作经验的Android开发?
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。