向量数据库PGVECTOR,AI浪潮下崛起的新秀!
CSDN 2024-06-29 13:01:03 阅读 50
📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前服务于工业互联网
擅长主流Oracle、MySQL、PG、高斯及Greenplum运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
📣 1.序言📣 2.向量数据库📣 3.向量插件PGVECTOR📣 4.PGVECTOR安装📣 5.PGVECTOR实践✨ 5.1 知识检索✨ 5.2 距离定位
📣 6.优势和不足📣 7.总结
向量数据库因为可以为大模型提供记忆而需求倍增,随着AI的热潮开始崭露头角,本文也聚焦于被 AI 炒火了的向量数据库,介绍什么是向量数据库,以及以插件形式存在的 pgvector,与PostgreSQL 强强联合,成为AI浪潮下的崛起新星。
📣 1.序言
自从OpenAI推出了全新的对话式通用人工智能工具——ChatGPT,ChatGPT 表现出了非常惊艳的语言理解、生成、知识推理能力,ChatGPT 的横空出世拉开了大语言模型产业和生成式AI产业蓬勃发展的序幕,大模型作为新一代的AI处理器,提供了数据处理能力;而向量数据库提供了存储能力,成为大模型时代的重要基座。
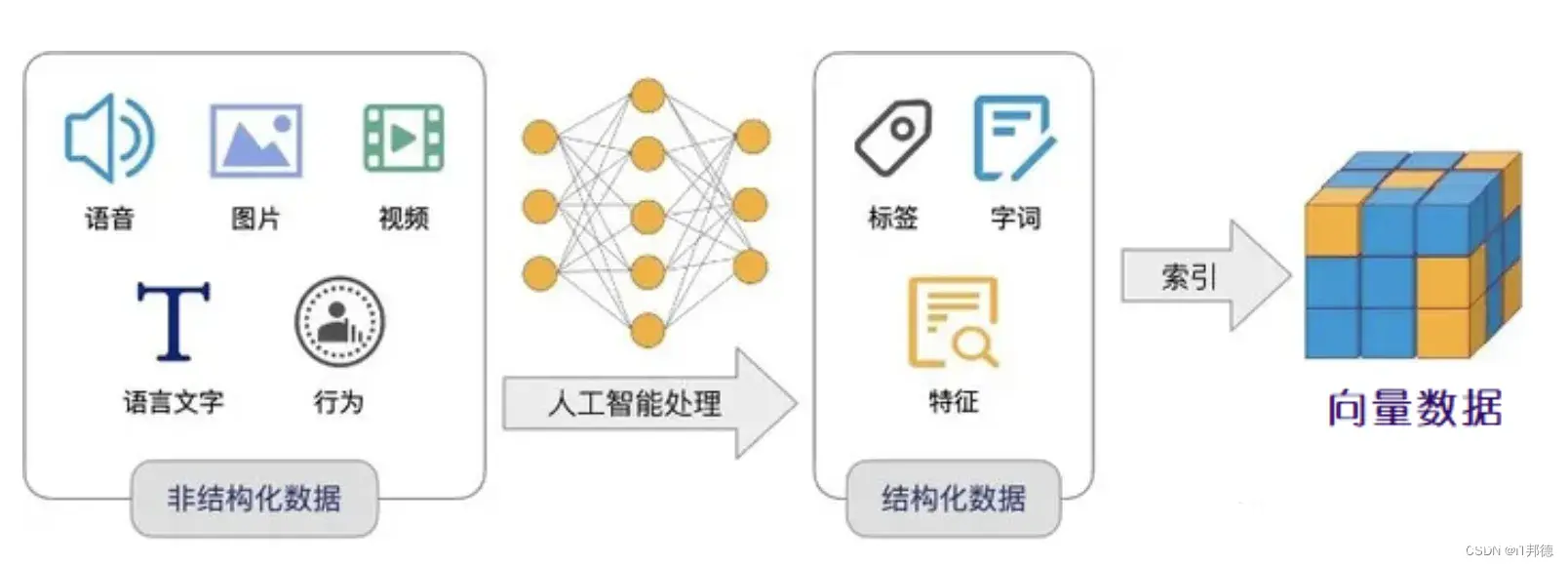
📣 2.向量数据库
数据库有事务处理(OLTP)与数据分析(OLAP)两大核心场景,向量数据库自然也不例外。典型的事务处理场景包括:知识库,问答,推荐系统,人脸识别,图片搜索,等等等等。知识问答:给出一个自然语言描述的问题,返回与这些输入最为接近的结果;以图搜图:给定一张图片,找出与这张图片在逻辑上最接近的其他相关图片。
这些功能说到底都是一个共同的数学问题:向量最近邻检索(KNN):给定一个向量,找到距离此向量最近的其他向量。
向量数据库的主要应用场景:
1.人脸识别
向量数据库可以存储大量的人脸向量数据,
并通过向量索引技术实现快速的人脸识别和比对。
2.图像搜索
向量数据库可以存储大量的图像向量数据,
并通过向量索引技术实现快速的图像搜索和相似度匹配。
3.音频识别
向量数据库可以存储大量的音频向量数据,
并通过向量索引技术实现快速的音频识别和匹配。
4.自然语言处理
向量数据库可以存储大量的文本向量数据,
并通过向量索引技术实现快速的文本搜索和相似度匹配。
5.推荐系统
向量数据库可以存储大量的用户向量和物品向量数据,
并通过向量索引技术实现快速的推荐和相似度匹配。
6.数据挖掘
向量数据库可以存储大量的向量数据,
并通过向量索引技术实现快速的数据挖掘和分析。
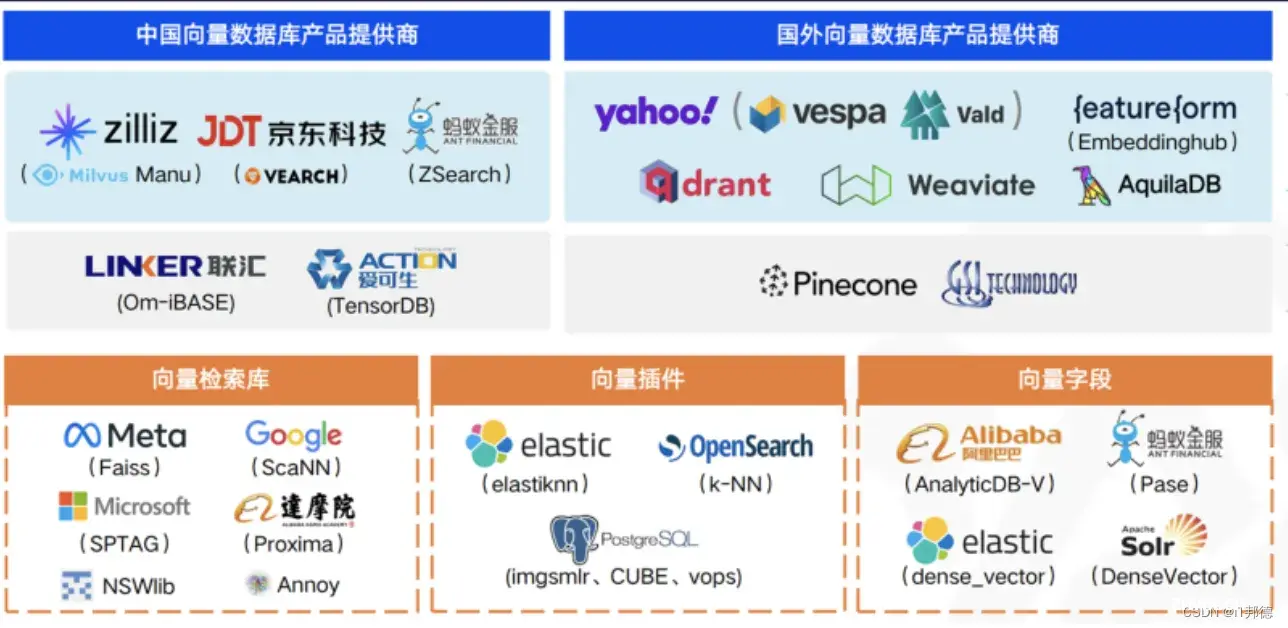
📣 3.向量插件PGVECTOR
在所有现有向量数据库中,pgvector是一个独特的存在 —— 它选择了在现有的世界上最强大的开源关系型数据库 PostgreSQL 上以插件的形式添砖加瓦,而不是另起炉灶做成另一个专用的“数据库” pgvector有着优雅简单易用的接口,不俗的性能表现,更是继承了PG生态的超能力集合。
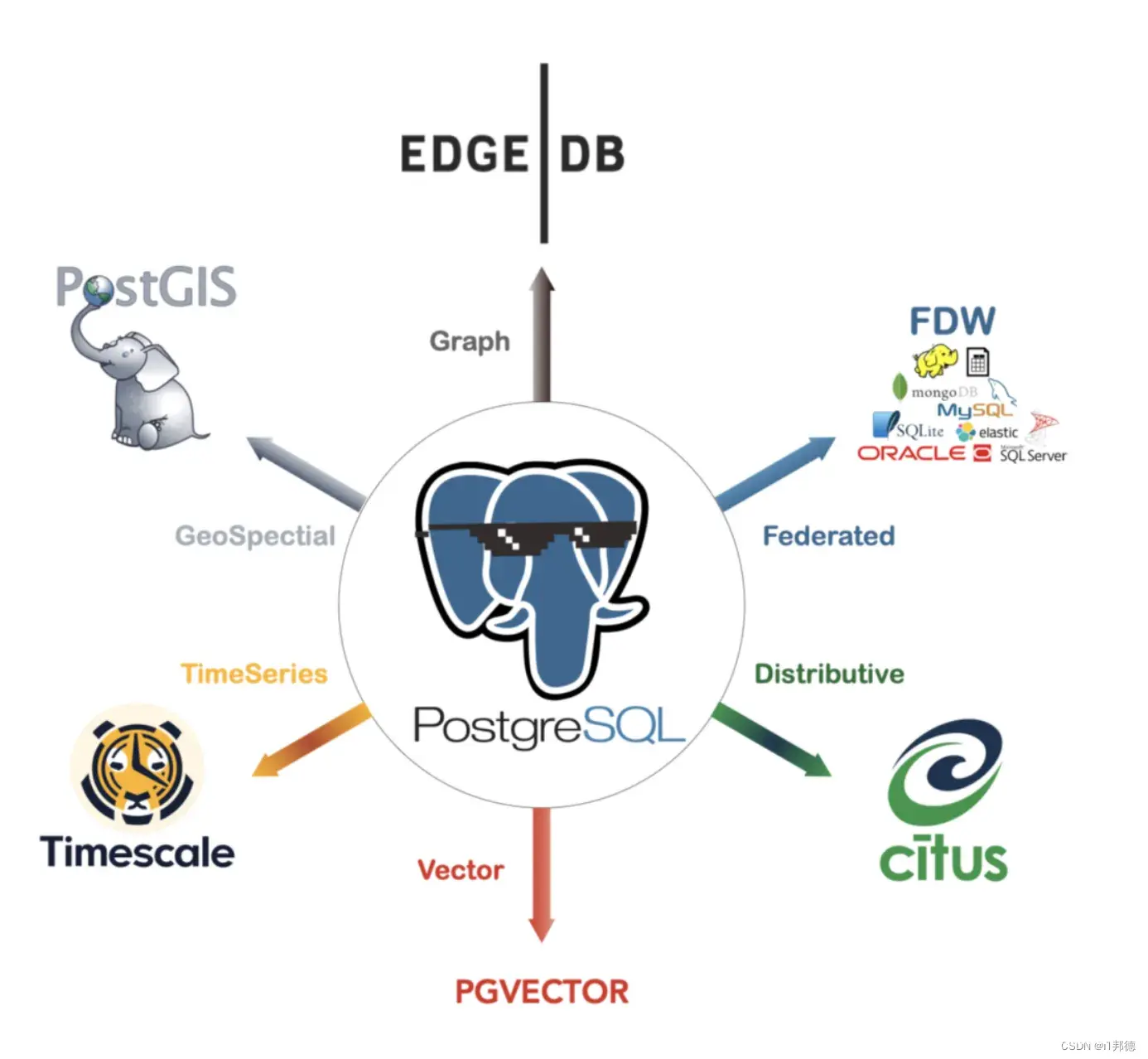
pgvector 是一个基于 PostgreSQL 的扩展,为用户提供了一套强大的功能,用于高效地存储、查询和处理向量数据。它具有以下特点:
直接集成:pgvector 可以作为扩展直接添加到现有的 PostgreSQL 环境中,方便新用户和长期用户获得矢量数据库的好处,无需进行重大系统更改。
支持多种距离度量:pgvector 内置支持多种距离度量,包括欧几里德距离、余弦距离和曼哈顿距离。这样的多功能性使得可以根据具体应用需求进行高度定制的基于相似性的搜索和分析。
索引支持:pgvector 扩展为矢量数据提供高效的索引选项,例如 k-最近邻 (k-NN) 搜索。即使数据集大小增长,用户也可以实现快速查询执行,并保持较高的搜索准确性。
易于查询语言访问:作为 PostgreSQL 的扩展,pgvector 使用熟悉的 SQL 查询语法进行向量操作。这简化了具有 SQL 知识和经验的用户使用矢量数据库的过程,并避免了学习新的语言或系统。
积极的开发和支持:pgvector 经常更新,以确保与最新的 PostgreSQL 版本和功能兼容,并且开发者社区致力于增强其功能。用户可以期待一个受到良好支持的解决方案,满足其矢量数据的需求。
稳健性和安全性:通过与 PostgreSQL 的集成,pgvector 继承了相同级别的稳健性和安全性功能,使用户能够安全地存储和管理其矢量数据。
📣 4.PGVECTOR安装
1.配置yum源
yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
2.编译安装
# 先安装git(如果已安装,跳过)
yum install -y git
# 切换到/tmp目录,下载源码包,我这里选择是目前最新版本0.5.1
cd /tmp
git clone --branch v0.6.0 https://github.com/pgvector/pgvector.git
# 进入/tmp/pgvector目录,进行编译安装
cd pgvector
make & make install
3.安装vector扩展
# 创建demo数据库
create database demo;
# 切换到demo数据库
\c demo
# 安装vector扩展
CREATE EXTENSION vector;
# 创建测试表
CREATE TABLE test (id bigserial PRIMARY KEY, embedding vector(3));
# 插入测试数据
INSERT INTO test (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
# 按与给定向量相似度(L2 distance)排序,显示前5条
SELECT * FROM test ORDER BY embedding <-> '[3,1,2]' LIMIT 5;
📣 5.PGVECTOR实践
✨ 5.1 知识检索
用一个简易的 Python 小脚本,
就可以制作一个全文模糊检索的命令行小工具
# !/usr/bin/env python3
from text2vec import SentenceModel
from psycopg2 import connect
model = SentenceModel('shibing624/text2vec-base-chinese')
def query(question, limit=64):
vec = model.encode(question) # 生成一个一次性的编码向量,默认查找最接近的64条记录
item = 'ARRAY[' + ','.join([str(f) for f in vec.tolist()]) + ']::VECTOR(768)'
cursor = connect('postgres:///').cursor()
cursor.execute("""SELECT id, txt, vec <-> %s AS d FROM sentences ORDER BY 3 LIMIT %s;""" % (item, limit))
for id, txt, distance in cursor.fetchall():
print("%-6d [%.3f]\t%s" % (id, distance, txt))
✨ 5.2 距离定位

📣 6.优势和不足
优点:
高效查询:向量数据库使用特殊的数据结构和索引方法来优化查询效率,可以快速地查询和计算相似度,支持高效的数据查询。
支持高维度向量:向量数据库可以支持高维度的向量数据,可以存储和查询大规模的向量数据。
支持复杂查询:向量数据库可以支持复杂的查询操作,如范围查询、布尔查询、聚合查询等,可以满足不同类型的查询需求。
支持高并发:向量数据库通常采用多线程或分布式架构来支持高并发的查询请求,可以满足大规模数据查询的需求。
可扩展性强:向量数据库可以根据需要进行扩展,可以扩展到多台服务器上,可以支持大规模的向量数据存储和查询。
应用场景广泛:向量数据库在机器学习、图像识别、自然语言处理等领域得到广泛应用,可以满足各种不同的应用场景需求。
缺点:
存储成本高:向量数据通常需要较大的存储空间,因此存储成本相对较高。
查询效率受向量维度影响:向量维度越高,查询效率越低。
数据更新困难:向量数据的更新操作相对复杂,需要重新计算相似度等数据。
适用场景有限:向量数据库适用于存储和查询大规模的向量数据,对于其他类型的数据则不太适用。
技术门槛较高:向量数据库的技术门槛较高,需要具备一定的数学和计算机技术知识。
📣 7.总结
向量数据库是一个非常有前景和潜力的行业,相信未来随着AI技术的不断发展,向量数据库也必将迎来更加广阔的发展空间。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。