基于AI的ISP(图像信号处理)相关研究
生活需要深度 2024-06-16 09:31:02 阅读 92
文主要为阅读ICCV 2023 一篇Tutorial的笔记(Part 3):
原文连接:ICCV 2023 Tutorial: Understanding the In-Camera Rendering Pipeline and the role of AI/Deep Learning (yorku.ca)
第三部分主要是基于AI(主要是基于深度学习)的去替代传统ISP流程中的某些环节,或者尝试直接代替传统ISP整个流程的一些研究现状以及面临的问题。
对于ISP不了解的可以看看前面部分:
Part1: 色彩、色彩恒常性、色温、色彩空间—相关知识 - 知乎 (zhihu.com)
Part2: 相机图像信号处理流程(ISP) - 知乎 (zhihu.com)
3. 基于AI替代传统ISP的某个环节
ISP流程中AI可以取得比较好效果的环节:
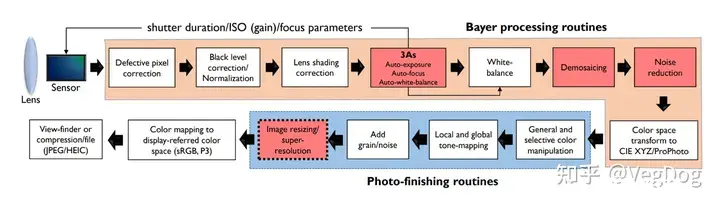
3.1 超分辨率(Super-resolution)

基于ML方法
在深度学习(DL)普及之前就已经有很多机器学习的方法解决了超分辨率的问题,主要用以下方式:
手动设计特征工程条件随机场K临近支持向量机
早期的一个机器学习的方法;

DL的方法开始使用:
基于CNN的方法

更深层的网络:
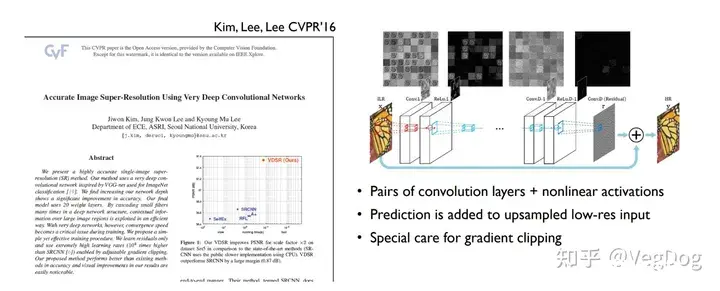

基于GAN的方法

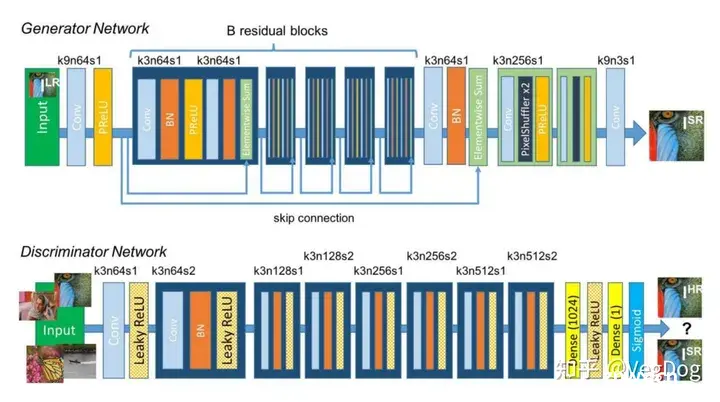
3.2 白平衡(illumination estimation)

白平衡问题本质上是给定一个图片,去估计环境光照以及传感器对于当时的环境光照的响应。
基于ML的方法
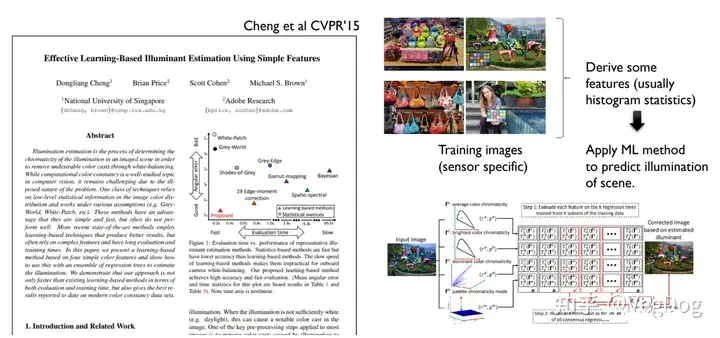
基于DL方法
这个方法的思路应该是训练网络去估计图片中最可能是中性灰度的区域以及这些区域中像素对应的置信度,然后进行加权平均去估计最终的结果。
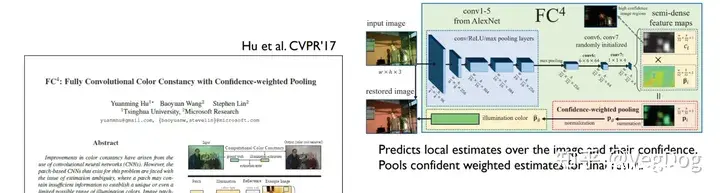
还提到一篇基于两个相机去做白平衡的,最终取得很好的效果,而且网络也比较轻量级

3.3 去马赛克(Demosaicing)
主要任务就是估计某个采集了单一颜色光强度的传感器的剩下两个通道的强度值,来得到每个像素都有3通道的最终图片。
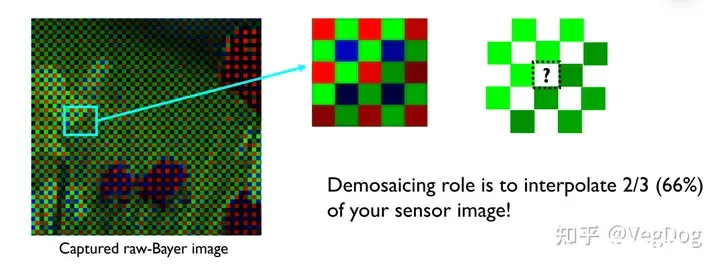
基于DL的方法

这篇里面网络结构和超分的网络比较类似,同时可以直接100%人为的合成数据。

这个文章里基于两个原因,提出了后面的网络:
高频区域(即细节变化比较多的区域)更难进行去马赛克拜尔阵列排布中,绿色像素所占的比例更多
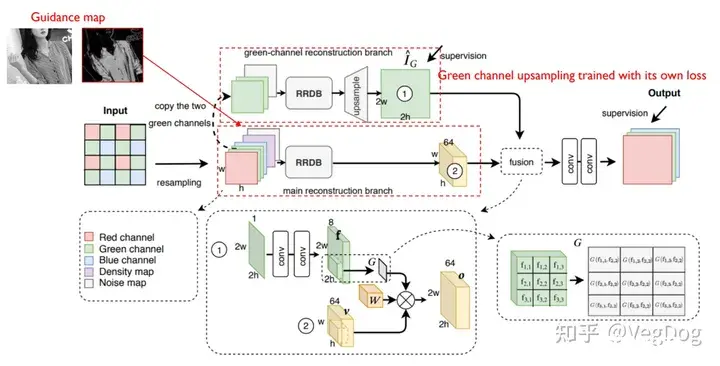
大概思路是先将GG通道(因为G通道采样率是RG两倍)与Noise通道拿出来,输入到RRDB网络中,然后上采样,先得到一个预估的G map,然后与main reconstruction branch提取到的特征做一个fusion,然后输入到最后一部分网络中得到恢复结果。
效果:

3.4 降噪(Noise reduction)
07年提出的一种基于非局部均值的方法效果很好,但是很慢
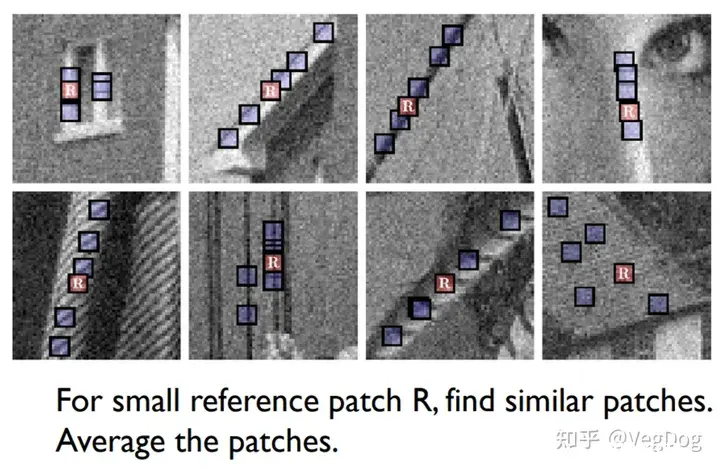
思路是对于需要去噪的R区域,在全图寻找相似的区域,然后去做均值后去修补R区域
基于DL的方法

网络在现在看来比较常规,比较值得提的是其最终是去预测噪声而不是直接得到降噪后的图像
结果:

20年的NTIRE降噪榜单:
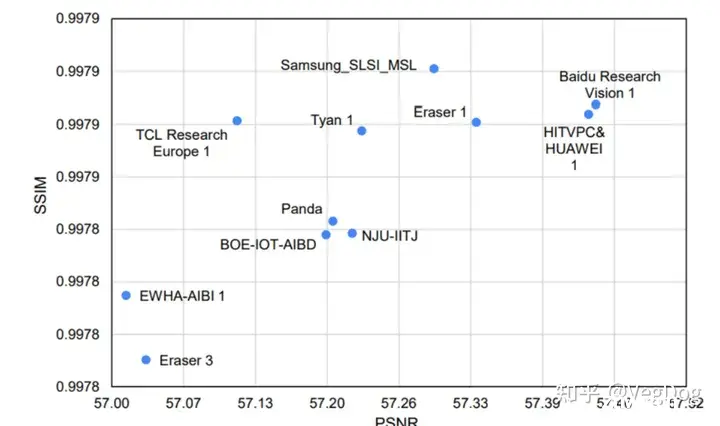
3.5 基于多帧(multi-frame)去替代传统ISP
多帧融合渲染相关:
目前主要用在暗光增强和HDR很多ISP也开始支持多帧渲染超分辨率也可以做,但是文章省略
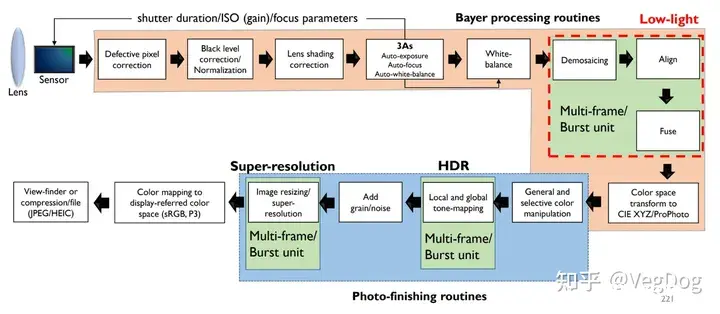
暗光增强
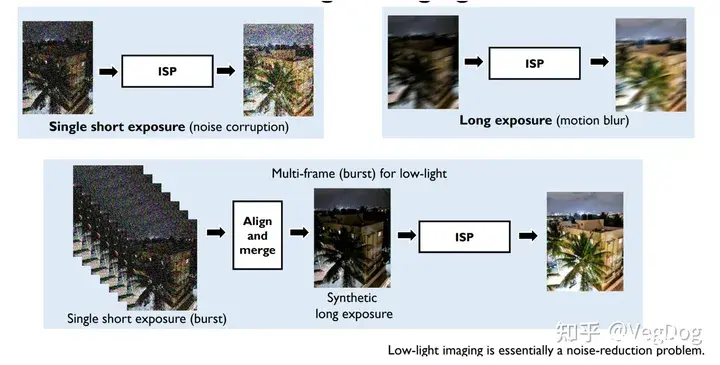
这里提到暗光增强本质上是一个降噪问题,我的理解是其实靠提高ISO本身就可以放大采集到的信号,只不过噪声也会随之增大,如果解决了这个过程中的噪声,其实也就可以对暗光环境进行增强。
使用的方法是先对多帧图片对齐后进行融合,然后再经过ISP,多帧融合效果相当于长曝光,既得到了更多的光信号,又不会产生通过长曝光拍摄单帧时出现的抖动模糊现象。
早期三星的SAIT提出了很多方法,比如Laplacian金字塔、全局对齐、局部融合、多时融合等方法

Hassinoff et al SIGGRAPH'16 (Google) 提出基于双边滤波的方法,且直接在Bayer/原图上进行。 同时文章提到降噪与融合也可上采样到更多位宽(10bit to 12 bit )。

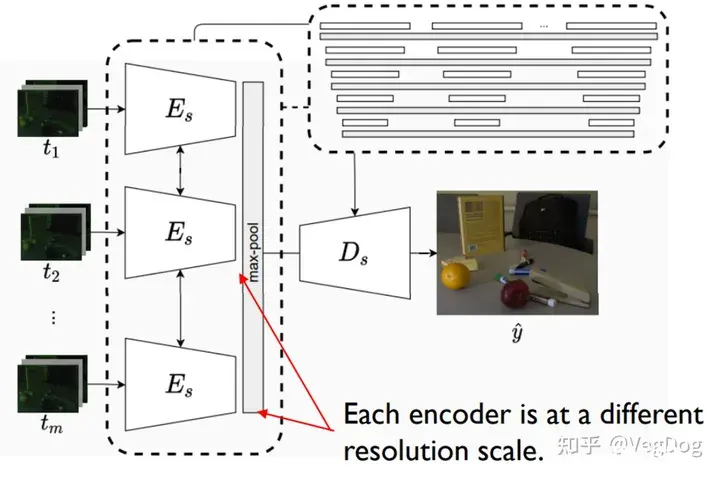
这篇文章提出一个多尺度的encoder-decoder结构,将多帧Raw格式图像分别输入给不同的Encoder,这些Encoder提取不同尺度的特征后最终通过 �� 直接输出增强后的图像且格式直接为sRGB。

大名鼎鼎的Google pixel,同样也针对Raw格式图像,结合多帧图像以及相机的抖动信息去马赛克和超分:
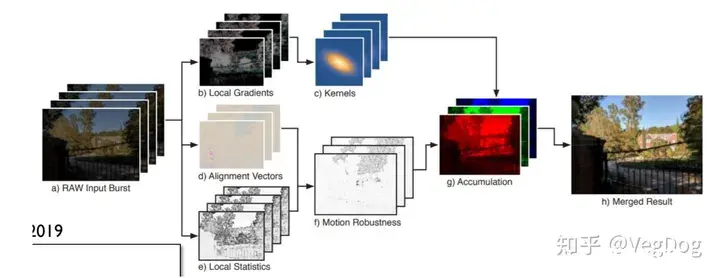
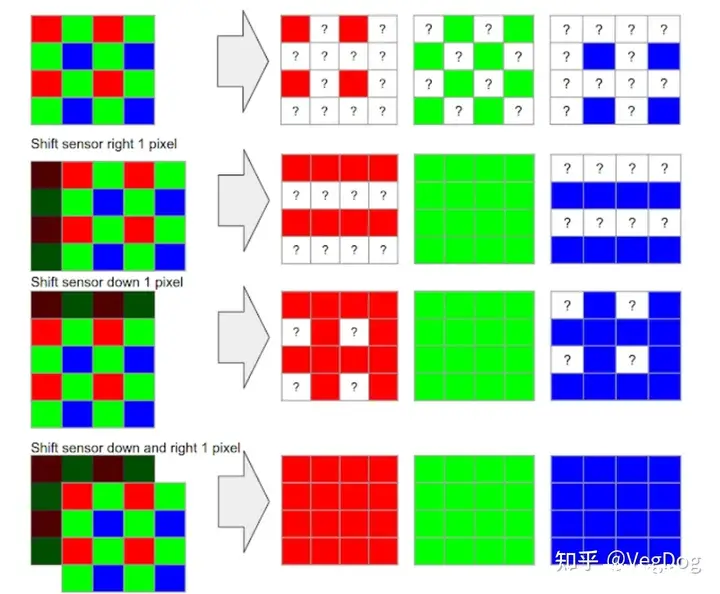
同时通过分析抖动数据,可以恢复拜尔阵列,也就是demosaicing
HDR(High dynamic range)
通过多帧不同曝光下的照片进行融合,恢复更多高光和暗部的信息。

图像曝光融合(Exposure fusion):

得到不同曝光图像的拉普拉斯金字塔,然后以对比度和饱和度作为指导信息去确定融合的权重,因为在过曝和死黑的区域的像素值接近0和255,梯度很小比较平滑,而饱和度同样是接近于0的。
效果:

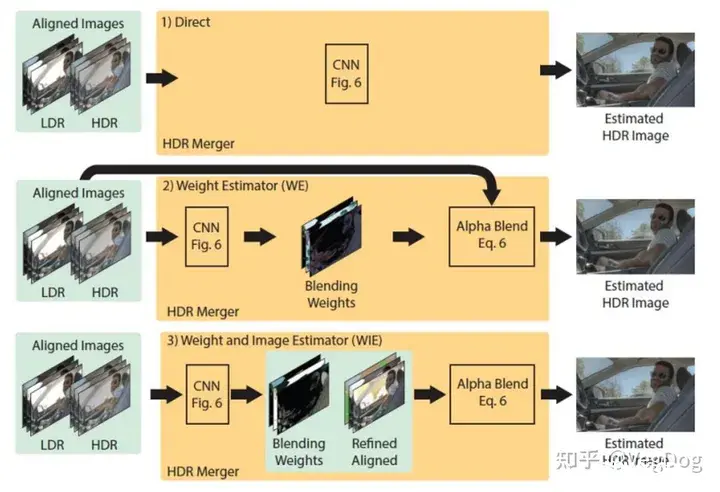
Kalantari and Ramanoorthi SIGGRAPH'17:

提出三种思路:
第一种是直接去预测最终的HDR图像第二种是预测一个融合的权重,然后根据这个权重去对多帧进行融合第三种在第二种的基础上还得到了对齐和不对齐的区域,融合过程中对齐进行考虑
结果发现第二种效果最好,在多帧间有小范围移动时候第三种最好。
4. 直接用End-to-End的端到端网络代替传统ISP
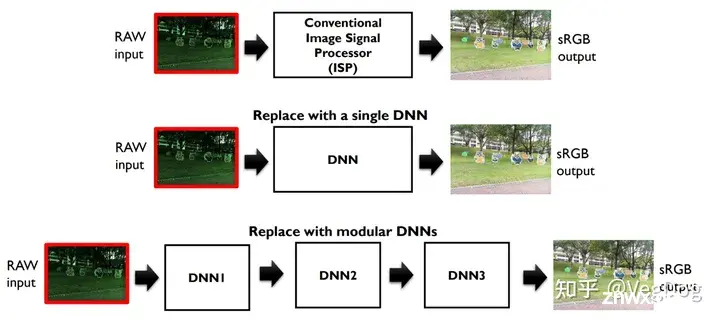
4.1 One stage DNN 网络

发布于CVPR'17,这篇文章想做的是将sRGB图像反向渲染,得到原始的RAW图像,解决了ISP辐射标定过程中的场景场景依赖问题。
但是这个网络也可以反向使用,输入Raw得到sRGB图像。(但是由于主要关注radiometric calibration问题常常被忽略。
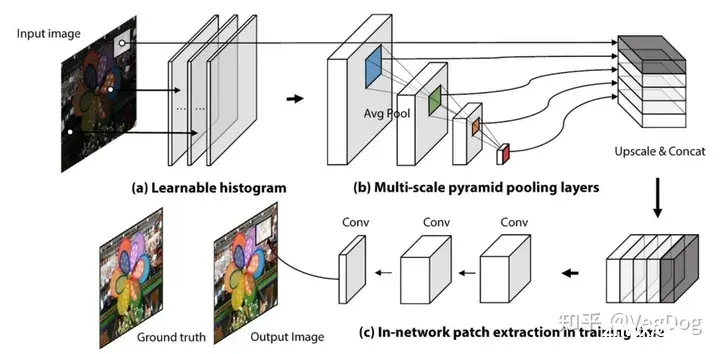
这个方法应该是一块一块的去处理输出的,而不是对整个图像直接处理,有一个可学习的直方图映射模块,而且是需要对每个相机进行训练的。
效果:

CVPRW'19:
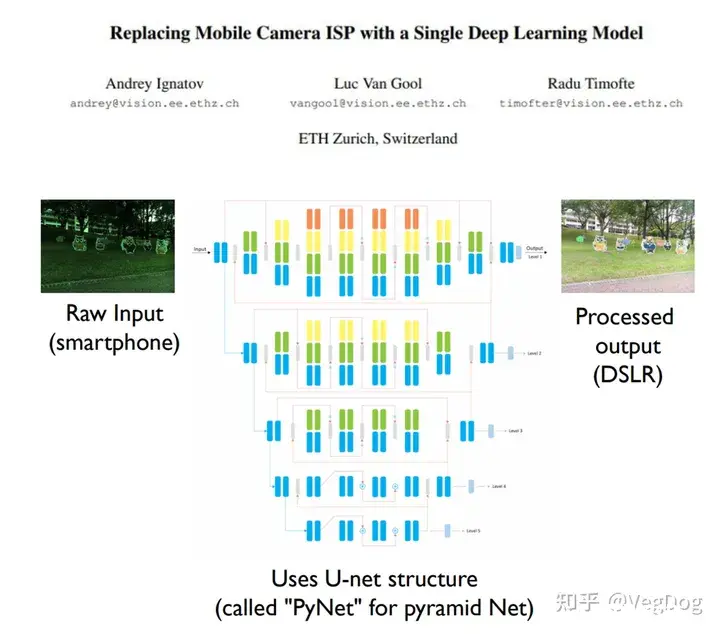
文章提出U-net结构的网络去代替整个ISP流程,效果还是非常好的。

CVPR 2018:"Learning to see in the dark“
一篇详细解读:Learning to See in the Dark-笔记 - 知乎 (zhihu.com)

短曝光会很多噪声,而长曝光容易导致模糊,这篇文章使用短曝光的图片以及对应的长曝光的图片(无抖动模糊)制作了一个数据集,网络也是一个基于U-net的结构。
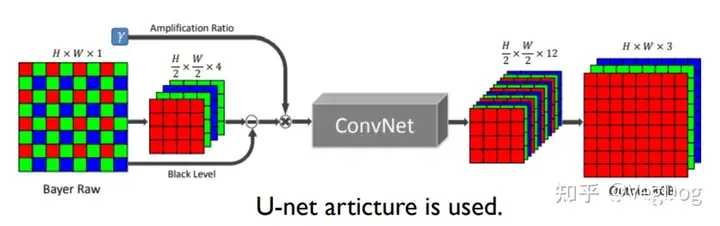
文章里也提到了,比起网络结构更关键的是数据集的制作设计部分。
Arxv 2021:CRISPnet

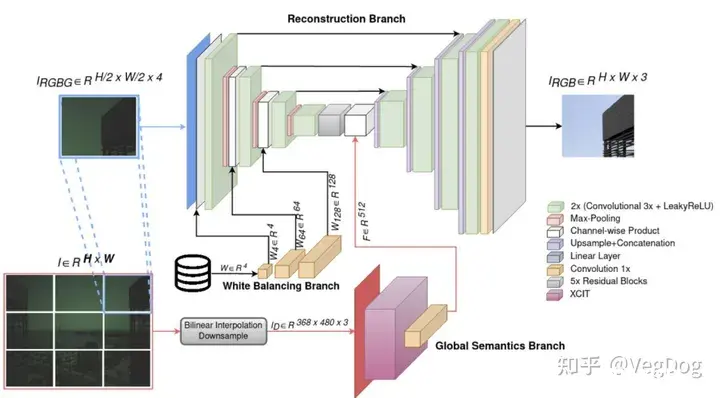
简单看了下原文:2203.10562.pdf (arxiv.org)
之前的工作很多关注于结构的重建,这篇还加入了对色彩还原的关注:
所以网络主要分为三个部分:
主干网络即Reconstruction Branch 主要负责重建图片,并且融合白平衡和全局的信息White Balance Branch 主要将Raw格式中各个通道的白平衡数据注入到不同尺度的特征中,帮助更好的恢复色彩主干网络是先将图片分区后一个patch一个patch输入、恢复的,所以缺少全局信息,Global Semantics Branch 就是先把图片下采样到更小的尺寸,提取全局特征信息。
效果:

4.2 Two stage DNN网络
CameraNet:
结构就是个常见Encoder-Decoder 结构,同尺度特征之间引入通道
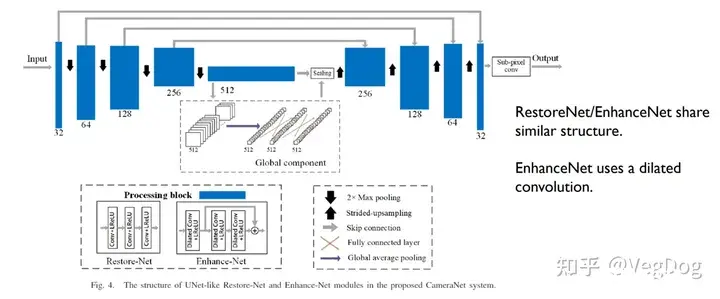
效果:看起来要比One Stage的好不少

4.3 Three Stage DNN 网络

2022 夜间摄影挑战赛冠军,冠军来自小米团队:FlexISP

第一个阶段降噪,第二个阶段进行自动白平衡,第三个阶段将Raw格式转化为sRGB
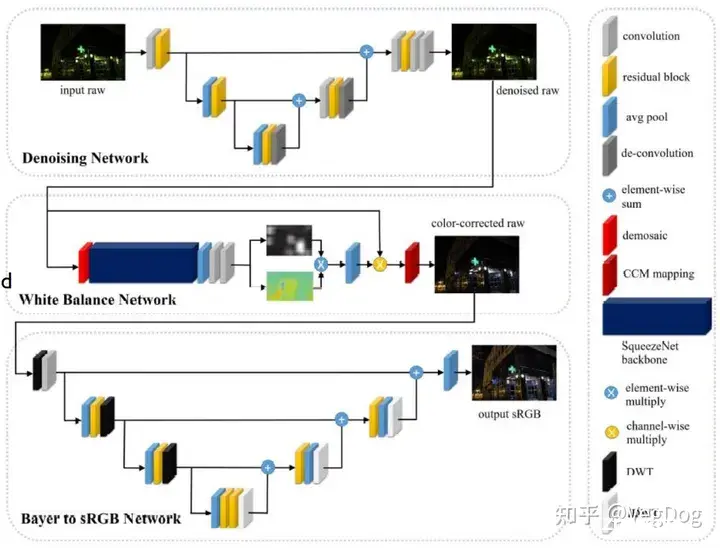
效果:

Raw格式提取为比特流(Raw to bit)

ECCV 2022的文章,原文:[2208.07639] RAWtoBit: A Fully End-to-end Camera ISP Network (arxiv.org)
这篇文章不仅实现了Raw到sRGB的基于深度学习的ISP流程,还在此之外直接实现了最终图片的压缩,可以说是真正的end-to-end了。
此外文章还展示了知识蒸馏技术在这个bit压缩编码过程中是最佳的策略。

基于DNN的ISP方法的关键点和挑战
训练数据的问题
目前来说,这些方法其实还不是通用的方法,需要针对每一个传感器进行单独训练,而无法直接迁移。而智能手机可能会有三四个镜头传感器,那么怎么去获取这么多的训练数据,其实是一个很大的问题数据的捕获也很复杂,在数据集的准备过程中需要非常小心。例如前面的HDR和暗光增强部分,当去准备数据集的时候涉及到长曝光时需要三脚架之类的设备确保没有运动模糊,耗时耗力,涉及多帧融合相关的又得保证每帧之间尽量没有差异。 训练网络需要的数据集数量又是很夸张的,所以这个过程很困难。而且还有个问题就是费力采集到的这些数据也只是针对特定型号传感器的,其他镜头是无法使用的可调性
这算是DL 方法的老问题了,就是可解释性与调整性差传统的ISP中,当我们想实现某一方向或者功能的调整,可以直接去调整对应的环节。而对于深度学习的方法,往往只能调整数据,可调整性很差。
在传统的ISP流程中,调整ISP流程中的参数来获得预期的效果而基于DL的方法中通过调整网络来达到目的,究竟哪种更优其实现在还很难下定论。

两百多页终于看完,对于很多CV研究者,在研究过程中明确自己所使用的色彩空间,声明自己使用的色彩空间是很重要的。(例如python 、matlab的很多API中其实默认的色彩空间是NTSC,而很多研究者根本没有意识到这一点,甚至使用了错误的公式)
Part1: 色彩、色彩恒常性、色温、色彩空间—相关知识 - 知乎 (zhihu.com)
Part2: 相机图像信号处理流程(ISP) - 知乎 (zhihu.com)
Part3:基于AI的ISP(图像信号处理)相关研究 - 知乎 (zhihu.com)
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。