Roofline模型(一):概念、基本公式、图像分析
YoYo鹿鸣_HPC 2024-06-16 10:31:02 阅读 81
目录
Roofline模型引入:什么是较好的性能评价模型?什么是roofline模型?怎样使用roofline模型分析性能?(DRAM) roofline model简化模型(DRAM) roofline model基本公式(DRAM) roofline model图像使用roofline模型分析性能示例有哪些低于roofline的原因?
Roofline模型
参考文献:
Samuel Williams, Roofline Performance Modeling for HPC and Deep Learning Applications, https://crd.lbl.gov/assets/Uploads/S21565-Roofline-1-Intro.pdf
YouTube English Presentation:Roofline Hackathon 2020 part 1 and 2 - YouTube
引入:什么是较好的性能评价模型?
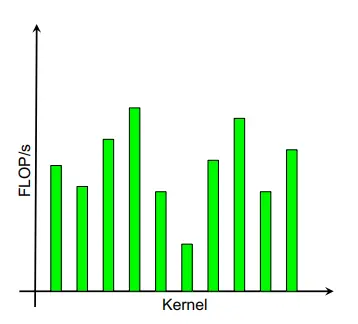
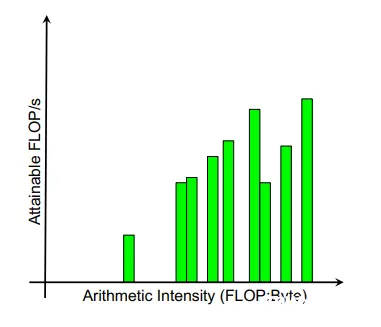
1、假设在GPU上对内核的循环测试进行性能分析,我们对不同的loop nest得到了随机的flop rates,有的很高,有的很低,这意味着只用GFLOP/s去评价性能可能有失偏颇
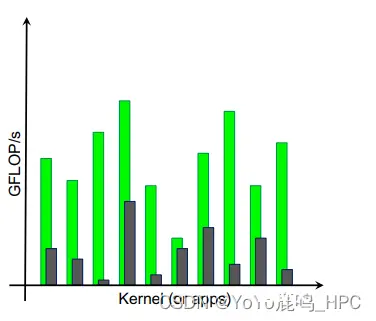
2、假设我们把某CPU代码移植到了Nvida GPU或者是AMD GPU中,将原CPU代码作为baseline(绿色),去对比移植后的代码性能(灰色)提升了多少,然后发现在有的循环中提升了非常多(例如第三根柱子、最后一根柱子),有的循环中只提升了一点点(例如第6根柱子),也不能很好的评价性能。
那么什么是“好的”性能?(GPU为例)
两个基本评价标准:
1、能够在吞吐量有限的情况下运行
not sensitive to Amdahl effects, D2H/H2D transfers, launch overheads, etc…
对于阿达姆效应不敏感、不会有连续的性能瓶颈;没有频繁的主机(Host)与设备内存(Device)之间的数据交换,保持尽量少的数据交换,使时间尽可能花在GPU计算上;启动开销尽量小,避免启动一堆很小的kernel(例如一个kernel只计算几微秒),把时间浪费在launch kernel上
2、充分利用GPU的计算以及访存带宽能力
总之,我们需要一个定量的性能评价模型,而不是定性的类似“性能不错”这样的评价。例如,达到了GPU计算峰值的80%、利用了70%的访存带宽等。
什么是roofline模型?
roofline模型是一个面向吞吐量的性能模型关注“率(rates)”而不是时间(time),例如flop rate(GFLOP/s)、bytes per second rate(GB/s)与架构无关,可以应用于CPU、GPU、DCU、Google TPU、FPGA等等怎样使用roofline模型分析性能?
(DRAM) roofline model简化模型
首先我们对代码运行的计算机架构进行简单建模:
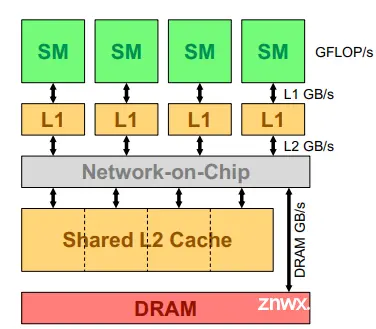
首先假设当数据位于Cache中时(local data),SM通常可以达到计算能力峰值(此处举例为GFLOP/s)。然假设在某数据并行程序中,所有的SMs运行时都是负载均衡的,将它们合并,进行进一步简化:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u8V4Qwj4-1673586721407)(C:\Users\dly2211480\AppData\Roaming\Typora\typora-user-images\image-20230113094915163.png)]
最后假设有足够的Cache空间以及访存带宽,即性能不会因为Cache空间不足以及访存带宽不够而被影响,基于此将模型再次简化:
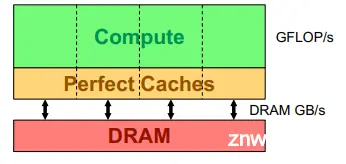
对于简化后的模型来说,能够影响性能的只有我们写的代码能算多快以及在主机端和设备端之间传输数据的速度有多快。我们将上面的模型叫做DRAM roofline model。
(DRAM) roofline model基本公式
假设数据传输时间和运算时间可以完美重叠,那么我们的代码耗时应为:
Time = max { #FP ops / Peak GFLOP/s #Bytes / Peak GB/s \text { Time }=\max \left\{\begin{array}{l} \text { \#FP ops } / \text { Peak GFLOP/s } \\ \text { \#Bytes } / \text { Peak GB/s } \end{array}\right. Time =max{ #FP ops / Peak GFLOP/s #Bytes / Peak GB/s
#FP ops / Peak GFLOP/s \text { \#FP ops } / \text { Peak GFLOP/s } #FP ops / Peak GFLOP/s 是理论计算时间,即浮点操作数量除以峰值计算速度, #Bytes / Peak GB/s \text { \#Bytes } / \text { Peak GB/s } #Bytes / Peak GB/s 是理论访存时间,即需要从DRAM中存入以及读取的数据总量的Bytes除以DRAM峰值带宽。
前面提到roofline模型主要关注“率”,因此对上面公式进行变形,得到:
#FP ops Time = min { Peak GFLOP/s (#FP ops / #Bytes) ∗ Peak GB/s \frac{\text { \#FP ops }}{\text { Time }}=\min \left\{\begin{array}{l} \text { Peak GFLOP/s } \\ \text { (\#FP ops } / \text { \#Bytes) } * \text { Peak GB/s } \end{array}\right. Time #FP ops =min{ Peak GFLOP/s (#FP ops / #Bytes) ∗ Peak GB/s
即:
GFLOP/s = min { Peak GFLOP/s A I ∗ Peak GB/s \text { GFLOP/s }=\min \left\{\begin{array}{l} \text { Peak GFLOP/s } \\ A I^* \text { Peak GB/s } \end{array}\right. GFLOP/s =min{ Peak GFLOP/s AI∗ Peak GB/s
上面的公式就是roofline模型的基本公式,其中AI(Arithmetic Intensity)=FLOPs/Bytes=计算量/访存量,表示计算密度。当代码的计算量远大于访存量,我们说他是计算密集型的,当访存量远大于计算量,则说他是访存密集型的。
(DRAM) roofline model图像
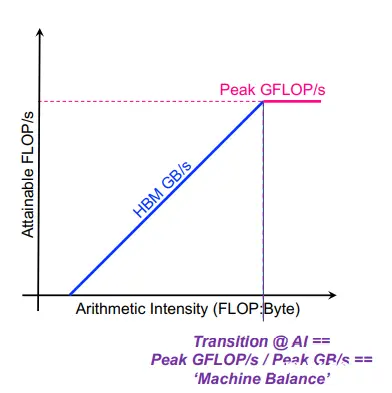
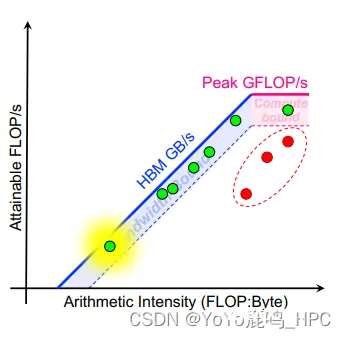
根据 GFLOP/s = min { Peak GFLOP/s A I ∗ Peak GB/s \text { GFLOP/s }=\min \left\{\begin{array}{l} \text { Peak GFLOP/s } \\ A I^* \text { Peak GB/s } \end{array}\right. GFLOP/s =min{ Peak GFLOP/s AI∗ Peak GB/s ,以AI(计算密度)为横坐标,FLOP/s(可达到的浮点性能)为纵坐标,可得出roofline模型图像(因图像长得像屋顶所以叫roofline模型)。蓝色段中,性能受限于理论带宽(即斜率,Peak GB/s),在粉色段中,性能受限于浮点计算峰值性能(Peak GFLOP/s)。图中的转折点的横坐标 称作“Machine Balance”,其表征了硬件架构的特点,而Arithmetic Intensity(计算密度)表征了我们的代码/应用的特点。
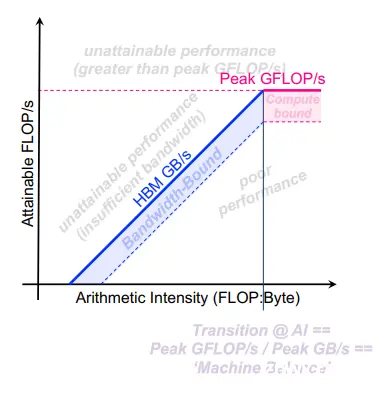
我们大致可以把图像分为5个区域,粉色线以上和蓝色线以左的区域是程序无论如何都无法达到的性能,因为它意味着超过了计算机的峰值计算性能/访存带宽。淡蓝色区域(计算密度小于Machine Balance点)是性能较好的访存密集型程序,这部分程序的访存带宽利用率较高(可能50%或更高),评价访存密集型程序的指标主要选用访存带宽;淡粉色区域(计算密度大于Machine Balance点)是性能较好的计算密集型程序,有较好的数据重用率与数据局部性,这部分程序的浮点性能较高(可能50%或更高),评价计算密集型程序的指标主要选用浮点性能。最后就是可能带宽与浮点性能都低于50%峰值性能的poor performance,如果程序性能处于这个部分,需要考虑优化算法提高性能,达到粉色或者蓝色区域。
使用roofline模型分析性能示例
对于文章一开始的性能分析图(随机输出kernel性能),我们将其重新组织,计算每个kernel的计算密度,并以计算密度为横坐标,重新排列得到:
将其与roofline模型相比较:
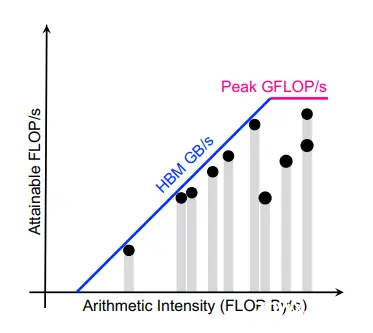
那些贴近于roofline的kernel较好的利用了计算资源(绿色点点),而那些远离roofline的kernel(红色点点)则是我们重点需要去优化、提高计算资源利用率的。这里需要注意,对比FLOP/s很低的kernel(例如第一个绿点),红点虽然看起来FLOP/s更高,但是比绿点更有优化性价比。因为绿点已经很接近roofline模型了,无法突破机器能提供的最大资源,可能需要费很大的劲儿才能提高一点点(如果不改变计算密度的话);而红点离roofline还有较远距离,可通过不断优化访存函数、计算函数来提高访存带宽/浮点计算性能利用率。除此之外,如果想要提高FLOP/s很低但是又比较接近roofline的kernel,可以通过改进计算方法/减少数据传输时间来提高计算密度(例如提高空间局部性、提高cache命中率、改进数据结构、数据类型)。
有哪些低于roofline的原因?
见下篇:Roofline模型(二):有哪些性能低于roofline的原因?
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。