用亚马逊云科技Graviton高性能/低耗能处理器构建AI向量数据库(下篇)
CSDN 2024-09-17 16:31:01 阅读 87
简介:
今天小李哥将介绍亚马逊推出的云平台4代高性能计算处理器Gravition,并利用该处理器构建生成式AI向量数据库。利用向量数据库,我们可以开发和构建多样化的生成式AI应用,如RAG知识库,特定领域知识的聊天机器人等。我们今天将手把手带大家在亚马逊云科技上,搭建一个目前大热的Milvus开源向量数据库,并利用VectorDBBench软件对向量数据库进行基准测试,了解Graviton如何提升AI向量数据库的性能、优化成本。
在本系列上偏中,我们介绍了如何在云平台上创建Graviton芯片基础设施,并在Graviton芯片服务器上安装Milvus开源向量数据库。在本系列下篇中,我们将利用数据库基准测试软件VectorDBBench,比较不同芯片服务器上的向量数据库性能,并查看、分析基准测试结果。

方案所需基础知识
什么是Graviton4代芯片?
Amazon Graviton 4 处理器由亚马逊云科技定制设计的第四代高性能、低功耗处理器,旨在为 Amazon 计算服务中的工作负载提供最佳性价比,相对于传统计算类工作负载(Graviton2)提供高达40%的性价比提升。与常见的 x86 处理器相比,基于 Graviton 4 的 EC2 实例具有以下特性:
每个 vCPU 独占一个物理核心的计算资源,而非通过 SMT 技术获得一个线程;每个 vCPU 拥有更大的 L1/L2 Cache 容量;更快的内存带宽和更低的内存延时。Graviton 处理器支持众多 Linux 操作系统,包括 Red Hat Enterprise Linux、SUSE 和 Ubuntu 等。Graviton 兼容众多云原生服务和开源软件,兼容亚马逊云科技上的开发工具,数据库,容器,分析,无服务器等服务,拥有丰富的应用生态。
最新发布的第 4 代 Graviton 处理器(基于 Arm Neoverse-V2,ARMv9.0-a);主频提升,L2 缓存翻倍,L3 缓存容量提升,支持 SVE2; 内存:12*DDR5-5600(前代采用 8*DDR5-4800),内存带宽提升 75%;

什么是Milvus开源向量数据库?
Milvus 是全球最流行的开源向量数据库之一。Milvus 是一个高度灵活、可靠且速度极快的云原生开源向量数据库。它为 embedding 相似性搜索和 AI 应用程序提供支持,并努力使每个组织都可以访问向量数据库。 Milvus 可以存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的十亿级别以上的 embedding 向量。
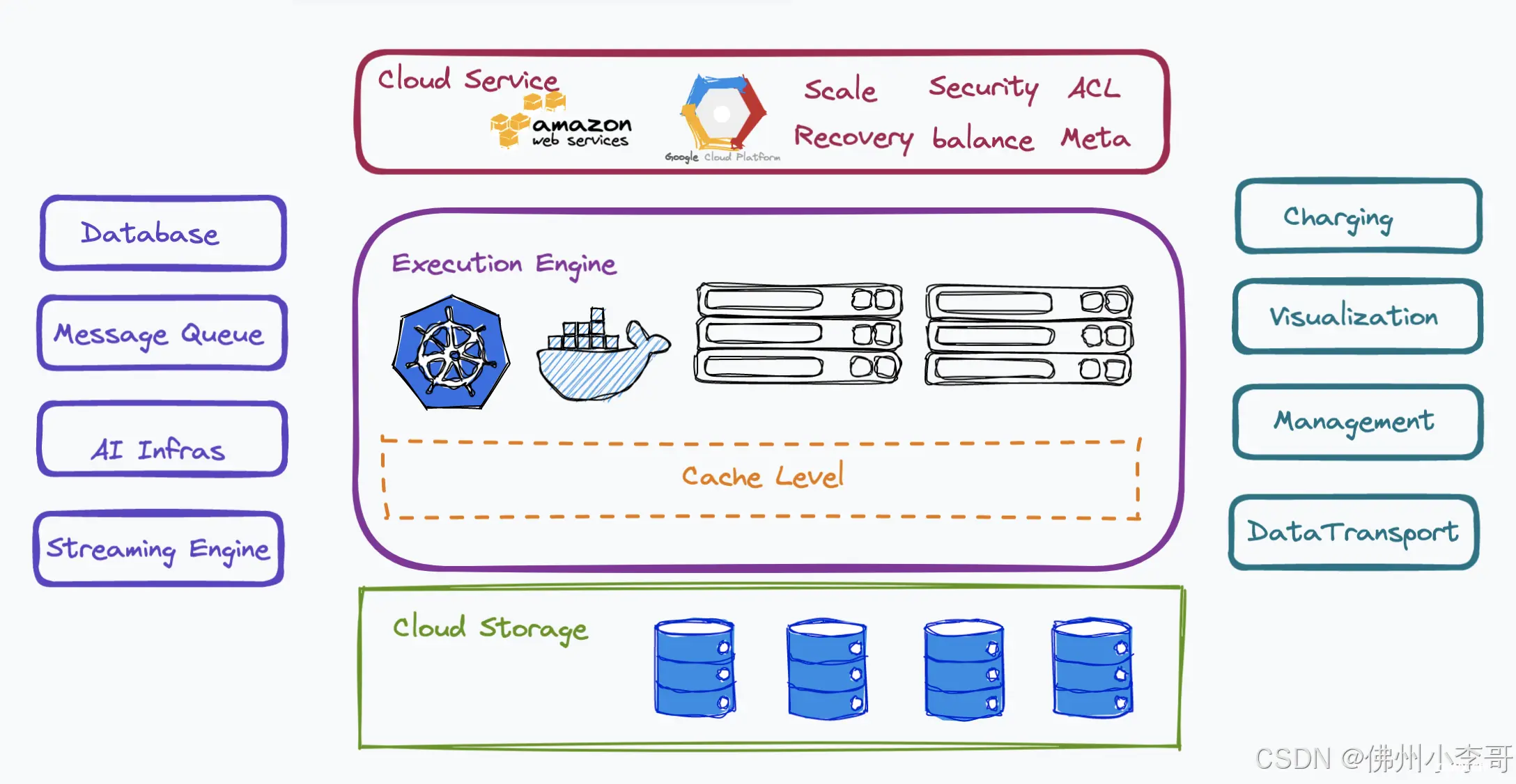
什么是VectorDBBench基础测试软件?
VectorDBBench 是一个开源的向量数据库基准测试工具,专为评估向量数据库系统的性能而设计。它能够帮助用户测试和比较不同的向量数据库,以确定最适合其特定用例的数据库系统。通过 VectorDBBench,开发者可以基于实际的向量数据库性能做出明智的决策,提供性能对比参数有查询每秒(QPS)、延迟、成本等关键指标,基于综合对比结果,可以帮助开发者选择最合适的开源向量数据库。
本实践包括的内容
1. 创建安装开源向量数据的云基础设施(Intel芯片服务器)
2. 安装向量库基准测试软件VectorDBBench
3. 对运行在Graviton和Intel芯片服务器上的Milvus开源数据库进行基础测试,并比较测试结果
项目实操步骤
创建Intel基础设施服务器
1. 首先我们进入亚马逊云科技控制台,进入EC2服务
2. 点击Launch Instance创建一台EC2服务器
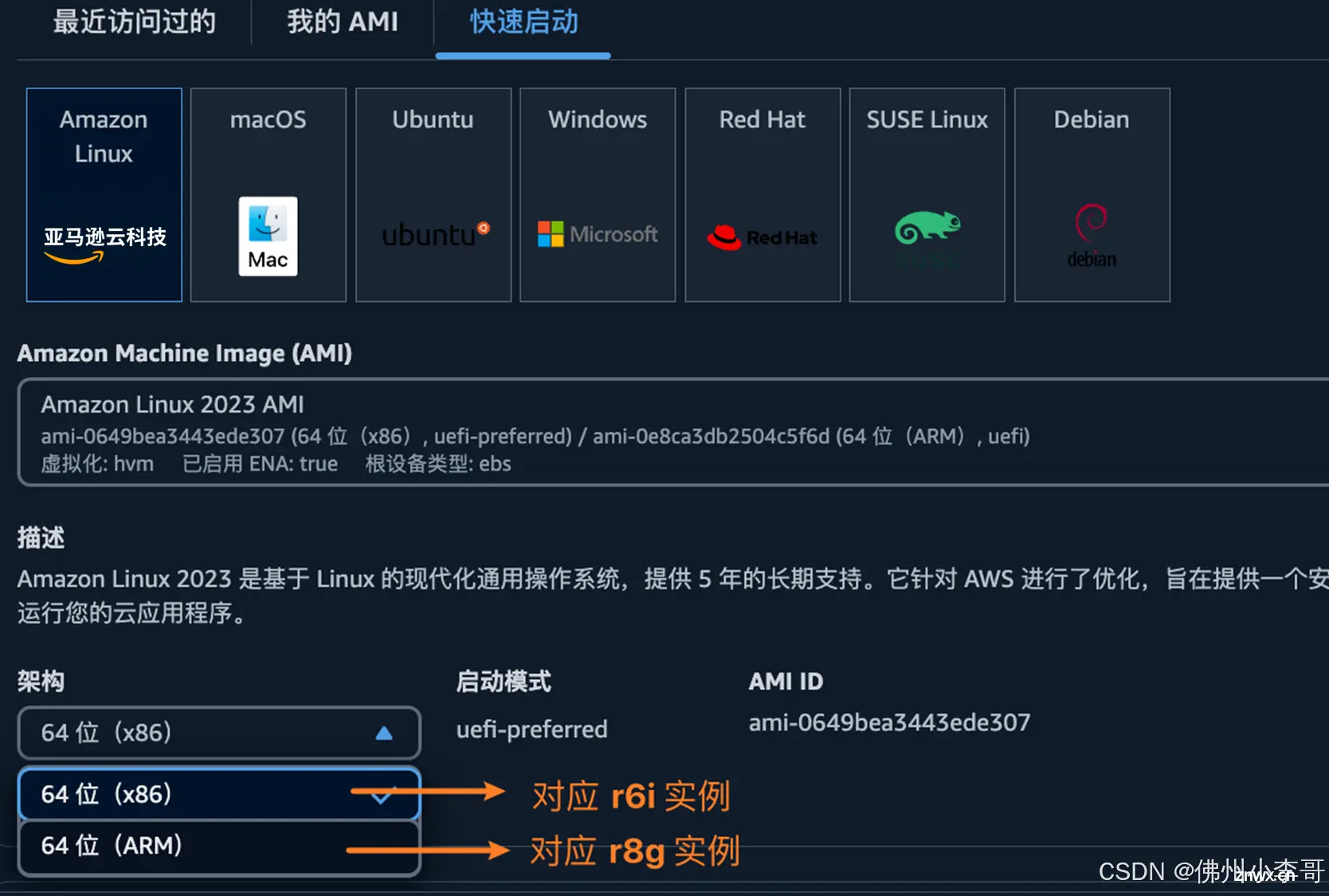
3. 在芯片架构处,我们选择实例类型为r6i.xlarge(4vCPU和32GiB内存)实例用于创建Intel芯片服务器。
4.创建SSH登录秘钥对
5. 为密钥对命名,并选择pem类型,点击右下角创建。
6. 运行以下命令为密钥对授权,用于SSH登录服务器
<code>chmod 400 test-only.pem
7. 为EC2服务器添加VPC和子网配置
8. 选择配置防火墙安全组,在防火墙入站规则中添加允许SSH从0.0.0.0/0 IP范围访问
9.并选择服务器存储,我们选择gp3类型的80GiB的磁盘存储。
通过SSH连接进入服务器
10. 通过以下命令SSH登录到EC2服务器中,将创建好的EC2服务器IP地址替换到命令中“EC2实例公网 IP 地址”字段
<code>ssh -i /path/key-pair-name.pem ec2-user@EC2实例公网 IP 地址
安装VectorDBBench自动化测试软件
11. 在控制台中运行以下命令,安装Python必要依赖,并通过Pip安装VectorDBBench测试软件,并通过nohup后台运行该软件
sudo su - root
## 安装 Python 3.11
dnf install -y python3.11 python3.11-pip python3.11-devel
python3.11 -V
## 安装 VectorDBBench
pip3.11 install vectordb-bench
which init_bench
## 设置一个临时文件目录
mkdir -p /mnt/vectordb_bench
ln -s /mnt/vectordb_bench /tmp/vectordb_bench
## 修改超时时间
sed -i "s/OPTIMIZE_TIMEOUT_DEFAULT = 30 \* 60/OPTIMIZE_TIMEOUT_DEFAULT = 300 \* 60/g" /usr/local/lib/python3.11/site-packages/vectordb_bench/__init__.py
sed -i "s/OPTIMIZE_TIMEOUT_768D_1M = 30 \* 60/OPTIMIZE_TIMEOUT_768D_1M = 300 \* 60/g" /usr/local/lib/python3.11/site-packages/vectordb_bench/__init__.py
## 启动 benchmark 工具,提示可以进入 Web 页面
nohup init_bench &
## 查看 Web 页面地址
tail nohup.out
12. 安装成功后会在控制台得到如下输出,External URL的键值记录了该测试软件的网页管理平台,我们复制URL在浏览器中打开
执行基准测试
13. 打开URL后我们可以看到软件的操作控制台,我们在控制台上点击“Run Your Test”按钮进入基准测试开始配置测试
14. 选择数据库类型为“Milvus”,在uri部分填入我们在上篇中安装Milvus服务器的私有IP地址,db_label填写“r8g.xlarge”
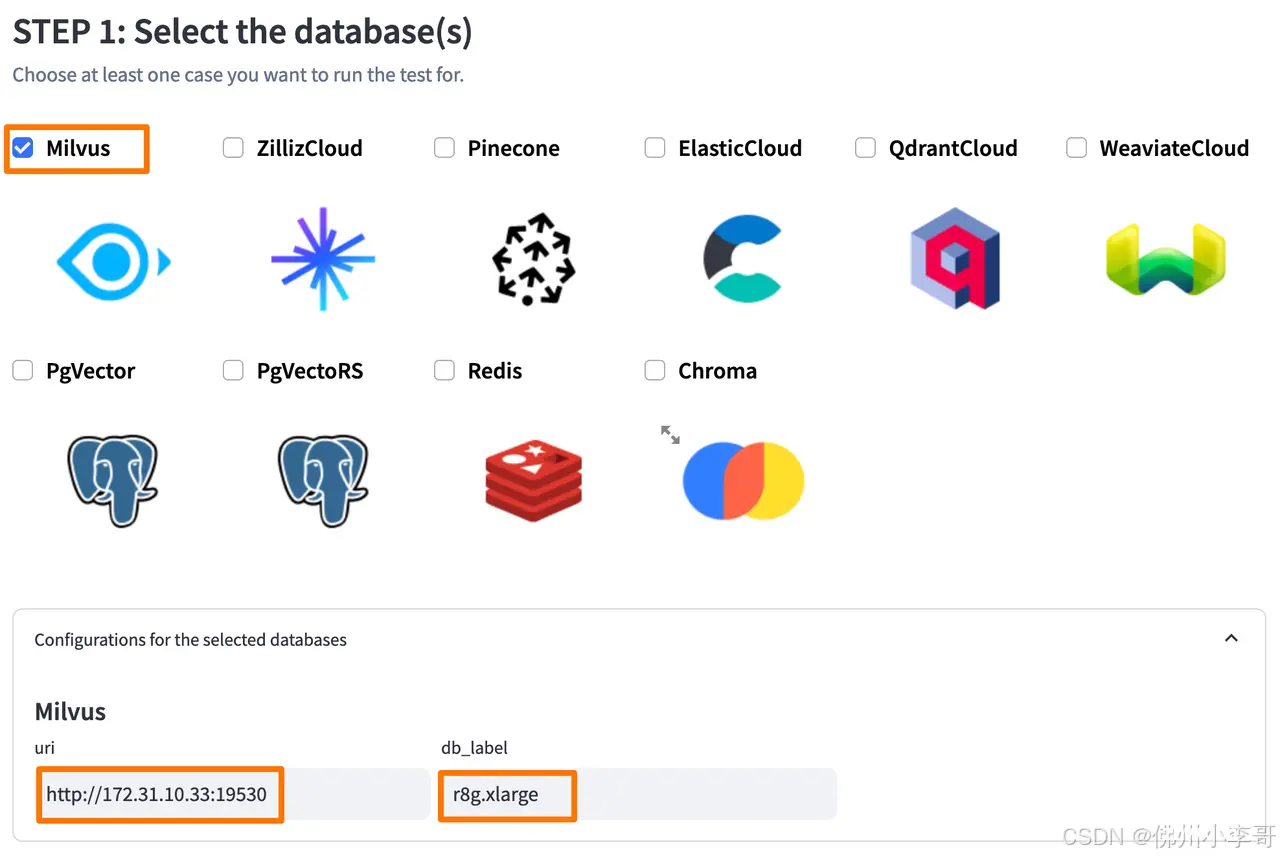
15. 选择基准测试场景,我们选择一百万(1M)向量数量的数据集,向量维度为768。768是 BERT等NLP预训练模型常用的隐藏层维度之一。
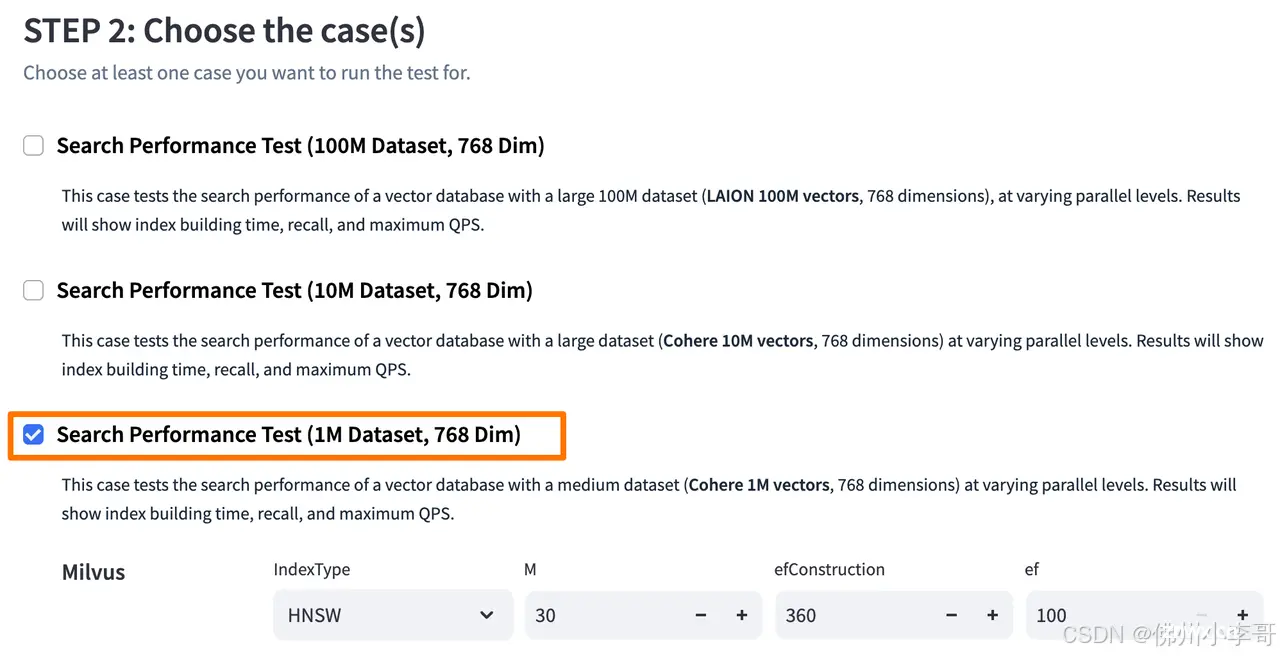
16. 我们填写测试任务标签为“r8g.xlarge”,对应着Graviton4芯片服务器。作为对比我还要运行另外一个对Intel芯片服务器的测试,标签名起名为”r6i.xlarge“。再点击“Run Your Test”开始测试。

17. 我们回到安装VectorDBBench软件的服务器控制台中,输入以下命令输出软件的测试运行应用日志。
<code>tail -f nohup.out
输出以下结果,展示基准性能测试的测试进度
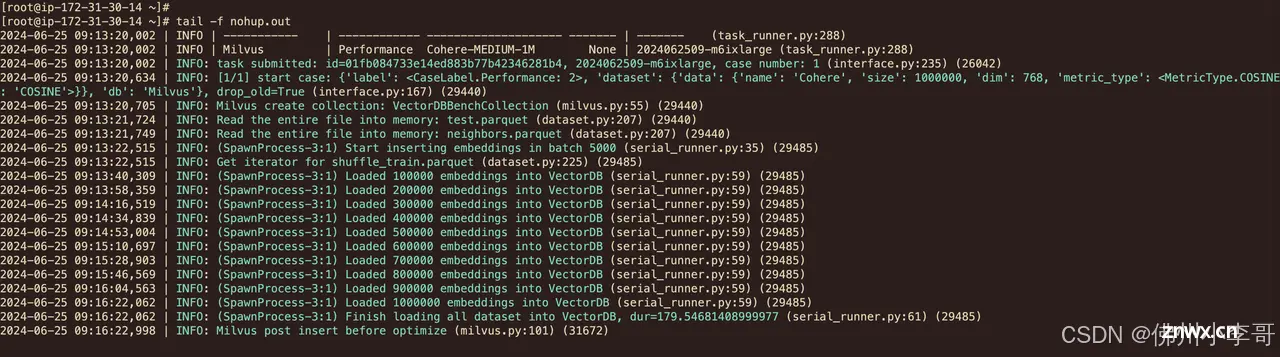
结果展示
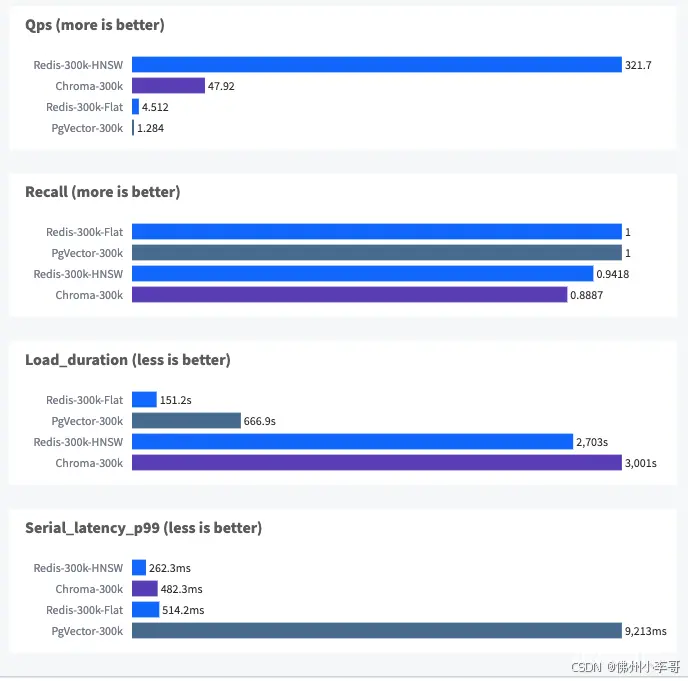
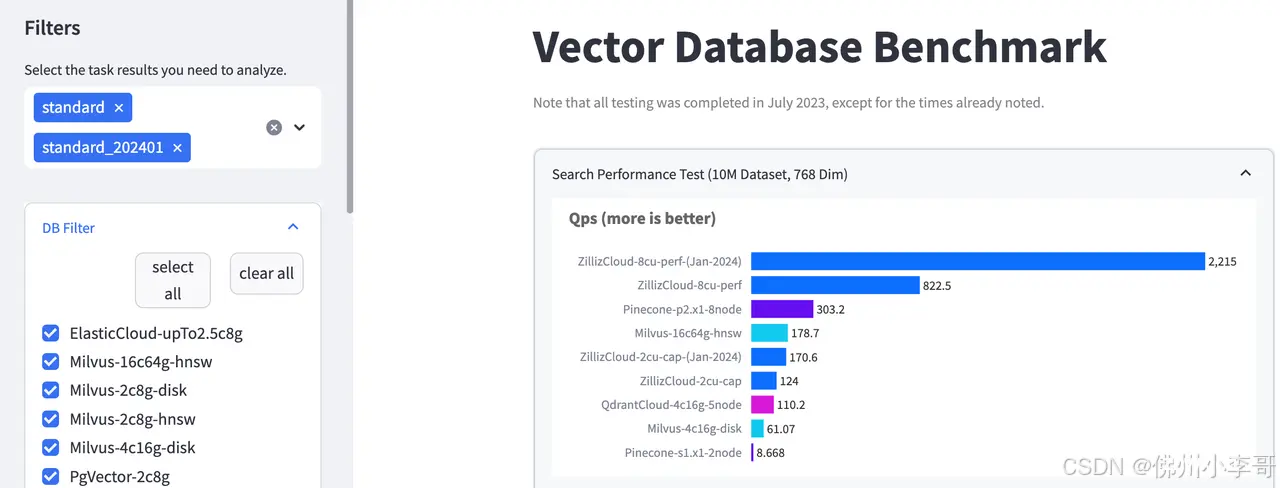
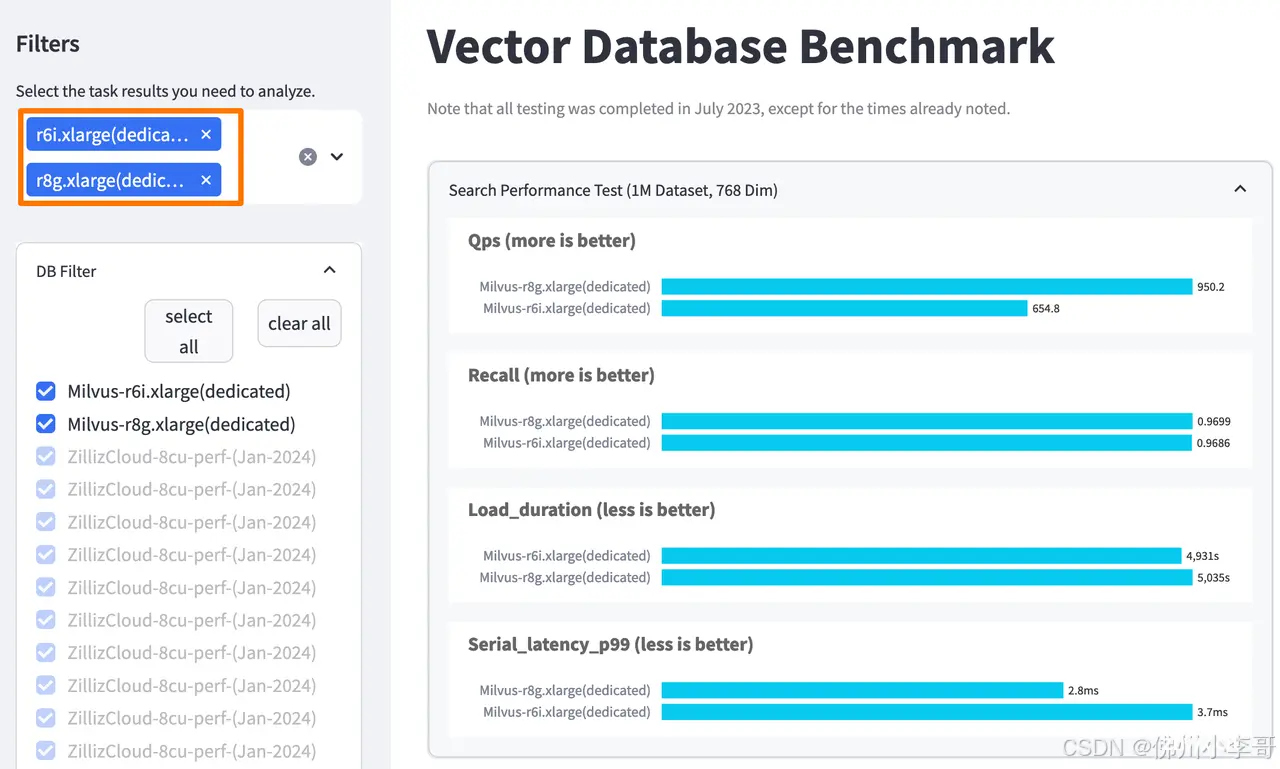
18. 在测试完成后,我们在VectorDBBench的网页操作控制台添加我们刚运行的两个测试标签r6i.xlarge(Intel)和r8g.xlarge(Graviton4),页面会自动添加数据显示结果。可以得到以下结论:基于 Graviton4的r8g.xlarge实例上的向量数据库基准测试结果中,关键参数每秒查询数据:QPS=819,相比 r6i.xlarge Intel芯片服务器的QPS=665.3提升了23% 。
以上就是利用亚马逊云科技自研Graviton4代芯片构建高性能、低成本AI向量数据库的下篇内容。欢迎大家关注小李哥的亚马逊云科技AI服务深入调研系列,关注小李哥未来不要错过更多国际前沿的AWS云开发/云架构方案。
上一篇: 【论文精读】 | 基于图表示的视频抑郁症识别的两阶段时间建模框架
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。