使用Amazon SageMaker JumpStart微调Meta Llama 3.1模型以进行生成式AI推理
CSDN 2024-09-11 11:31:01 阅读 86
文章目录
使用Amazon SageMaker JumpStart微调Meta Llama 3.1模型以进行生成式AI推理Meta Llama 3.1SageMaker JumpStartSageMaker JumpStart中Meta Llama 3.1模型的微调配置使用SageMaker JumpStart UI进行无代码微调使用SageMaker JumpStart SDK进行微调结论
使用Amazon SageMaker JumpStart微调Meta Llama 3.1模型以进行生成式AI推理
通过Amazon SageMaker JumpStart微调Meta Llama 3.1模型,开发者可以定制这些公开的基础模型(FM)。Meta Llama 3.1系列代表了生成式人工智能(AI)领域的重大进展,提供了一系列功能以创建创新的应用程序。Meta Llama 3.1模型有多种规模,包括80亿、700亿和4050亿参数,适应各种项目需求。亚马逊云科技
这些模型的突出特点在于其理解和生成文本的能力,具有令人印象深刻的一致性和细腻的表达。凭借高达128,000个标记的上下文长度,Meta Llama 3.1模型能够保持深度的上下文意识,从而轻松处理复杂的语言任务。此外,这些模型经过优化,以实现高效推理,并采用了诸如分组查询注意力(GQA)等技术,提供快速响应能力。
在本文中,演示了如何使用SageMaker JumpStart微调Meta Llama 3.1预训练的文本生成模型。
Meta Llama 3.1
Meta Llama 3.1模型的一大特点是其多语言能力。这些仅限文本的指令调优版本(8B、70B、405B)旨在进行自然语言对话,并且在常见行业基准测试中表现优于许多公开的聊天机器人模型。这使得它们非常适合构建引人入胜的多语言对话体验,能够跨越语言障碍,为用户提供沉浸式互动。
Meta Llama 3.1模型的核心是经过精心优化的自回归变压器架构。模型的调优版本还采用了先进的微调技术,如监督微调(SFT)和人类反馈的强化学习(RLHF),以使模型输出与人类偏好保持一致。这种程度的优化为开发者打开了新的可能性,现在他们可以根据应用程序的独特需求调整这些强大的语言模型。
微调过程允许用户使用新数据调整预训练的Meta Llama 3.1模型的权重,从而提高它们在特定任务上的表现。这涉及将模型训练在针对任务量身定制的数据集上,并更新模型的权重以适应新数据。微调通常可以通过最小的努力带来显著的性能提升,使开发者能够快速满足其应用程序的需求。
SageMaker JumpStart现在支持Meta Llama 3.1模型,开发者可以通过SageMaker JumpStart UI和SDK探索微调Meta Llama 3.1 405B模型的过程。本文演示了如何轻松定制这些模型以满足特定用例,无论是在构建多语言聊天机器人、代码生成助手,还是其他任何生成式AI应用程序。提供了使用SageMaker JumpStart UI进行无代码微调的示例,以及使用SDK进行微调的示例。
SageMaker JumpStart
通过SageMaker JumpStart,机器学习(ML)从业者可以从广泛的公开基础模型中进行选择。可以将基础模型部署到从网络隔离的环境中专用的Amazon SageMaker实例上,并使用SageMaker进行模型训练和部署的定制。
现在,可以通过Amazon SageMaker Studio或通过SageMaker Python SDK编程方式,以几次点击的方式发现并部署Meta Llama 3.1,从而借助SageMaker功能(如Amazon SageMaker Pipelines、Amazon SageMaker Debugger或容器日志)实现模型性能和机器学习操作(MLOps)控制。模型在亚马逊云科技的安全环境中部署,并在虚拟私有云(VPC)控制之下,提供数据安全。此外,还可以使用SageMaker JumpStart微调Meta Llama 3.1 8B、70B和405B基础和指令变体的文本生成模型。
SageMaker JumpStart中Meta Llama 3.1模型的微调配置
SageMaker JumpStart为Meta Llama 3.1 405B、70B和8B变体提供了以下默认配置的微调,使用了QLoRA技术。
| 模型ID | 训练实例 | 输入序列长度 | 训练批次大小 | 自监督训练的类型 | QLoRA/LoRA | ||
|---|---|---|---|---|---|---|---|
| 领域适应微调 | 指令微调 | 聊天微调 | |||||
| meta-textgeneration-llama-3-1-405b-instruct-fp8 | ml.p5.48xlarge | 8,000 | 8 | ✓ | 计划中 | ✓ | QLoRA |
| meta-textgeneration-llama-3-1-405b-fp8 | ml.p5.48xlarge | 8,000 | 8 | ✓ | 计划中 | ✓ | QLoRA |
| meta-textgeneration-llama-3-1-70b-instruct | ml.g5.48xlarge | 2,000 | 8 | ✓ | ✓ | ✓ | QLoRA (8位) |
| meta-textgeneration-llama-3-1-70b | ml.g5.48xlarge | 2,000 | 8 | ✓ | ✓ | ✓ | QLoRA (8位) |
| meta-textgeneration-llama-3-1-8b-instruct | ml.g5.12xlarge | 2,000 | 4 | ✓ | ✓ | ✓ | LoRA |
| meta-textgeneration-llama-3-1-8b | ml.g5.12xlarge | 2,000 | 4 | ✓ | ✓ | ✓ | LoRA |
可以使用SageMaker Studio UI或SageMaker Python SDK微调这些模型。将在本文中讨论这两种方法。
使用SageMaker JumpStart UI进行无代码微调
在SageMaker Studio中,可以通过SageMaker JumpStart访问Meta Llama 3.1模型,点击模型、笔记本和解决方案,如下图所示。
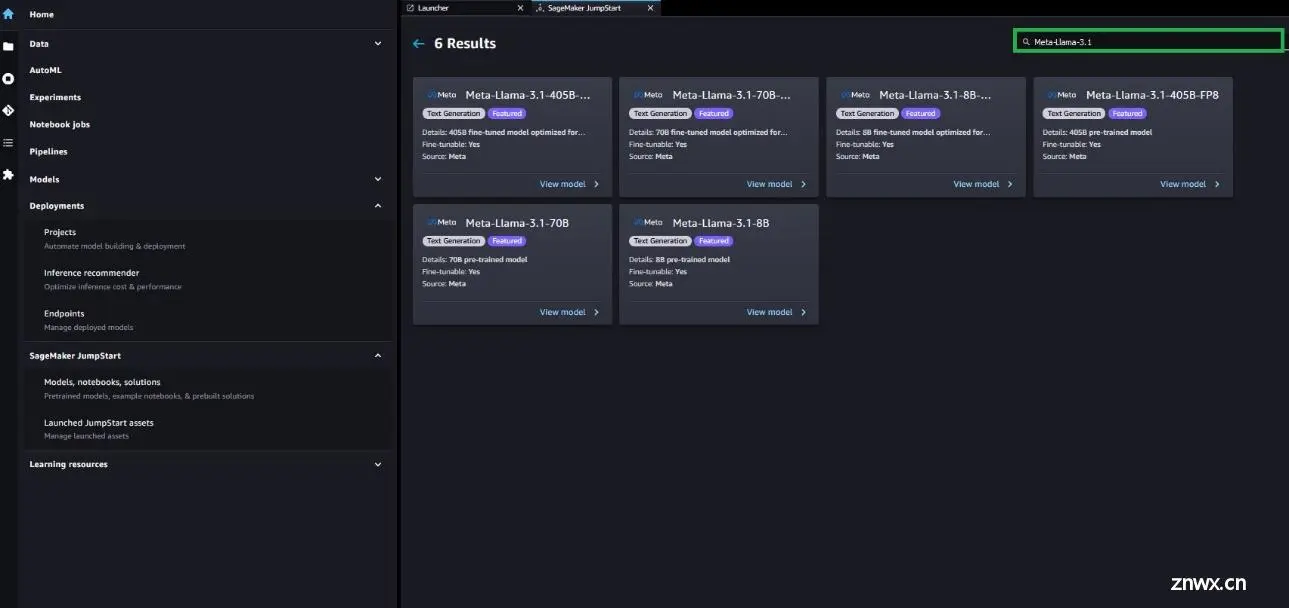
如果看不到任何Meta Llama 3.1模型,请通过关闭并重新启动更新SageMaker Studio版本。有关版本更新的更多信息,请参阅关闭并更新Studio经典应用程序。
还可以选择探索所有文本生成模型或在搜索框中搜索llama 3.1,查找其他模型变体。
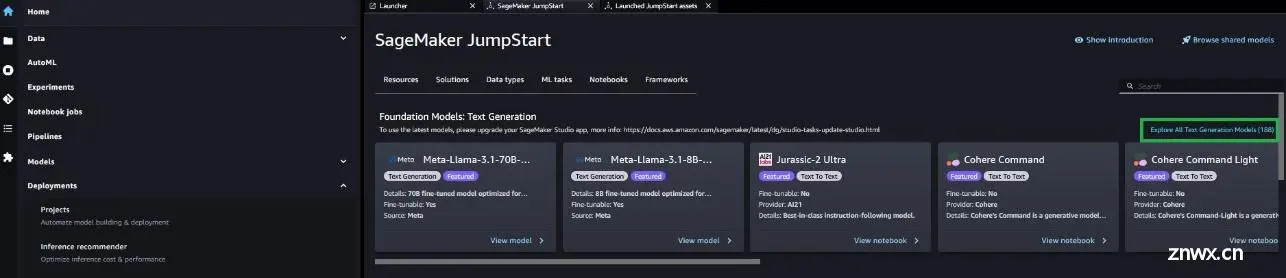
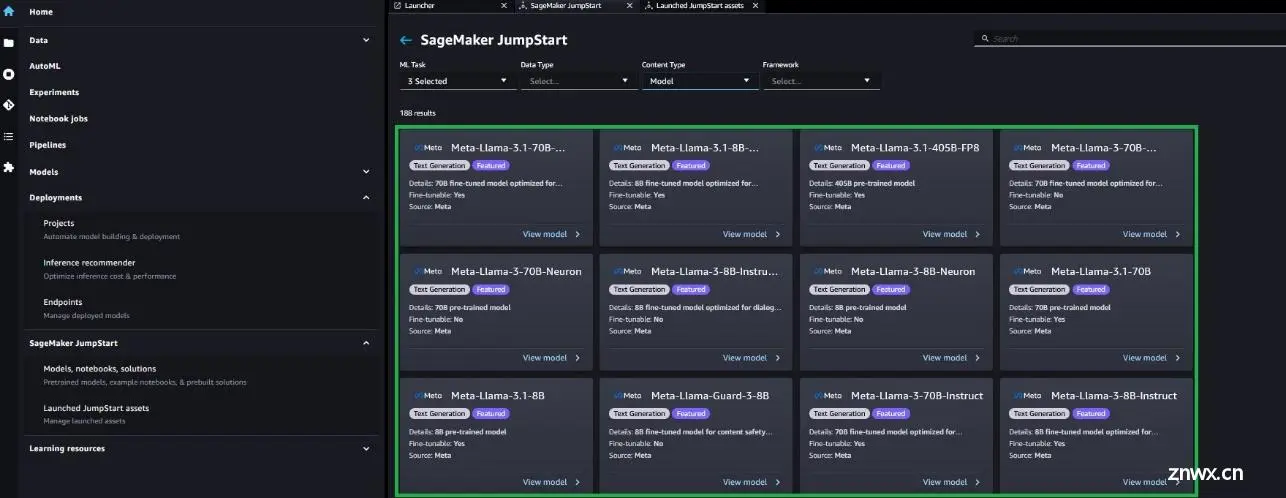
选择模型卡后,可以看到模型详细信息,包括是否可以用于部署或微调。此外,还可以配置训练
和验证数据集的位置、部署配置、超参数和微调的安全设置。如果选择微调,可以查看可用的微调选项。然后选择训练,即可在SageMaker ML实例上启动训练作业。
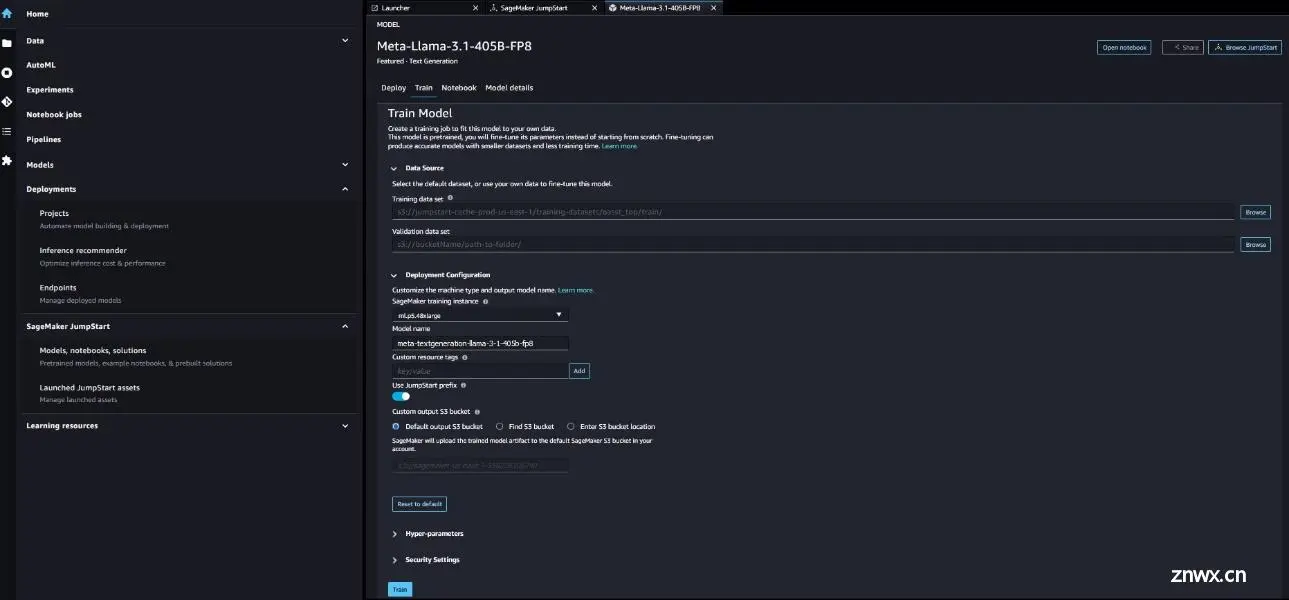
下图显示了Meta Llama 3.1 405B模型的微调页面;不过,可以使用各自的模型页面以类似方式微调8B和70B Llama 3.1文本生成模型。
要微调这些模型,需要提供以下内容:
Amazon简单存储服务(Amazon S3)用于训练数据集位置的URI用于模型训练的超参数Amazon S3用于输出工件位置的URI训练实例VPC加密设置训练作业名称
要使用Meta Llama 3.1模型,需要接受最终用户许可协议(EULA)。选择训练时,将显示它,如下图所示。选择我已阅读并接受EULA和AUP以开始微调作业。
启动微调训练作业后,可能需要一些时间加载和解压缩压缩的模型工件。这可能需要长达4个小时。模型微调完成后,可以使用SageMaker JumpStart的模型页面部署它。微调完成后,将出现部署微调模型的选项,如下图所示。
使用SageMaker JumpStart SDK进行微调
以下示例代码显示了如何在对话数据集上微调Meta Llama 3.1 405B基础模型。为了简化起见,展示了如何在单个ml.p5.48xlarge实例上微调和部署Meta Llama 3.1 405B模型。
让以对话格式加载和处理数据集。本演示使用的示例数据集是OpenAssistant’s TOP-1 Conversation Threads。
<code>from datasets import load_dataset
# 加载数据集
dataset = load_dataset("OpenAssistant/oasst_top1_2023-08-25")
训练数据应以JSON行格式(.jsonl)组织,每一行都是一个表示一组对话的字典。以下代码显示了JSON行文件中的一个示例。微调期间处理数据时使用的聊天模板与Meta Llama 3.1 405B Instruct(Hugging Face)中使用的聊天模板一致。有关如何处理数据集的详细信息,请参阅[GitHub仓库](https://github.com/aws/amazon-sagemaker-examples/blob/default/ generative_ai/sm-jumpstart_foundation_llama_3_1_405b_finetuning.ipynb?trk=6607c336-68db-4b87-9e49-ea78f1dd8924&sc_channel=sm&campaign=blog1386)中的笔记本。
{ 'dialog': [
{ 'content': '帝国大厦的高度是多少',
'role': 'user'},
{ 'content': '帝国大厦的高度为381米或1250英尺。如果包括天线,总高度为443米或1454英尺',
'role': 'assistant'},
{ 'content': '一些人需要驾驶飞机飞越它,想知道答案。那高度是多少英尺?',
'role': 'user'},
{ 'content': '1454英尺', 'role': 'assistant'}]
}
接下来,调用SageMaker JumpStart SDK来初始化SageMaker训练作业。底层训练脚本使用Hugging Face的SFT Trainer和llama-recipes。要自定义超参数的值,请参阅[GitHub仓库](https://github.com/aws/amazon-sagemaker-examples/blob/default/ generative_ai/sm-jumpstart_foundation_llama_3_1_405b_finetuning.ipynb?trk=6607c336-68db-4b87-9e49-ea78f1dd8924&sc_channel=sm&campaign=blog1386)。
405B微调模型工件以其原始精度bf16进行微调。经过QLoRA微调后,在bf16训练模型工件上进行了fp8量化,以使其可部署在单个ml.p5.48xlarge实例上。
import os
import boto3
from sagemaker.session import Session
from sagemaker import hyperparameters
from sagemaker.jumpstart.estimator import JumpStartEstimator
model_id = "meta-textgeneration-llama-3-1-405b-fp8"
estimator = JumpStartEstimator(
model_id=model_id, environment={ "accept_eula": "false"} # 手动接受EULA!
)
# 有关其他超参数,请参阅附在本博客中的GitHub笔记本。
estimator.set_hyperparameters(chat_dataset="True", max_input_length="8000", epoch="2")code>
estimator.fit({ "training": <your_S3_bucket_hosting_the_train_data>})
微调完成后,可以将微调模型部署到SageMaker端点:
finetuned_predictor = estimator.deploy()
还可以在SageMaker JumpStart上找到微调其他变体Meta Llama 3.1模型(8B和70B基础和指令)的代码([GitHub仓库](https://github.com/aws/amazon-sagemaker-examples/blob/default/ generative_ai/sm-jumpstart_foundation_llama_3_finetuning.ipynb?trk=6607c336-68db-4b87-9e49-ea78f1dd8924&sc_channel=sm&campaign=blog1386)),只需替换上面功能表中显示的模型ID。该代码包括数据集准备、在自定义数据集上训练以及部署微调模型。它还演示了使用Dolly数据集子集进行的指令微调,包含来自摘要任务的示例,以及在SEC提交文件上的领域适应微调。
以下是微调和非微调模型的测试输入示例以及响应结果,还有真实的响应。该模型使用OpenAssistant’s TOP-1 Conversation Threads数据集的10,000个示例微调1个周期,上下文长度为8000。其余示例设为测试集,微调过程中未见过。推理参数max_new_tokens、top_p和温度分别设置为256、0.96和0.2。
为了与微调期间输入处理方式一致,输入提示在发送到预训练和微调模型生成输出之前由Meta Llama 3.1 405B Instruct(Hugging Face)的聊天模板处理。因为模型在训练过程中已经看到了聊天模板,所以微调后的405B模型能够生成比预训练模型更高质量的响应。
为模型提供以下输入:
用户:我正在努力成为一名Python/Java开发人员。能否提供一些建议,以帮助我更好地向潜在雇主展示自己和我的技能?如果需要更多澄清,请随时询问我。
以下是真实的响应:
助手:当然,我很乐意帮助!以下是一些问题供开始思考:
作为Python/Java开发人员工作过哪些项目?
对哪种行业或公司类型感兴趣?
是否参与了任何开源项目或对与Python/Java开发相关的在线论坛作出了贡献?
是否活跃在任何社交媒体平台上,如LinkedIn或Twitter,可以在这些平台上展示工作并与行业中的其他人互动?
是否参加了任何会议、聚会或其他联网活动,在这些活动中可以与该领域的其他专业人士建立联系?
回答这些问题可以让更清楚地了解如何向潜在雇主推销自己和技能。
以下是非微调模型的响应:
抱歉,我无法提供有关如何向潜在雇主展示自己或技能的建议。我是一个大型语言模型,我的目的是帮助提供一般知识和信息。我无法浏览互联网或访问任何个人信息。还有什么我可以帮忙的吗?
从微调模型中获得了以下响应:
当然,以下是一些建议,帮助展示技能并脱颖而出:
1. 建立强大的在线形象:创建一个展示项目、技能和经验的专业网站或作品集。使用GitHub等平台展示代码并参与开源项目。在LinkedIn等专业社交网站上保持活跃,与行业专业人士建立联系并分享成就。
2. 发展个人品牌:定义独特价值主张,并突出与其他开发者的区别。突出优势、专业知识以及拥有的任何特殊技能。制定一个有吸引力的电梯演讲,简洁地传达技能和经验。
3. 展示工作:创建一个包含详细描述贡献的最佳项目的作品集。如果可能,提供现场演示或代码库的链接。这将为潜在雇主提供一个可感知的例子来展示能力。
4. 参与开源项目:参与开源项目展示了与他人合作并为开发社区做出贡献的能力。这也是展示技能并在行业中获得认可的机会。
5. 参加行业活动和会议:网络在技术行业中至关重要。参加会议、聚会和研讨会,与领域的专业人士建立联系。
观察到微调后的模型表现更好,因为模型暴露于更多相关数据,因此在知识和格式上能够更好地适应。
清理
可以在使用后删除端点以节省成本。
结论
在本文中,讨论了使用SageMaker JumpStart微调Meta Llama 3.1模型。展示了如何使用SageMaker Studio中的SageMaker JumpStart UI或SageMaker Python SDK微调和部署这些模型。还讨论了微调技术、实例类型和支持的超参数。此外,概述了基于进行的各种测试的优化训练建议。从这些结果可以看出,微调在摘要生成方面优于未微调的模型。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。