让AI写论文——全流程全自动的AI科学家:基于大模型提炼idea、写代码、做实验且最终写成论文
CSDN 2024-09-03 11:31:02 阅读 92
前言
熟悉本博客或我司七月的知道,过去一年,在具身智能机器人解决方案之外,大模型应用开发团队一直专注通过大模型赋能科研行业,所以在做面向科研论文相关的翻译、审稿、对话、修订(包含语法纠错、润色)、idea提炼等诸多系统(背后的技术详情,参见:七月科研论文大模型:含论文的审稿微调、阅读、写作、修订 ),目前正在逐一上线七月官网
8.14这一天,一关注我们的深圳的黄总(后来北京的刘总也发我了下),发我一篇文章《首位AI科学家问世!已独立生成10篇学术论文,还顺手搞了AI审稿人》,并说:“看看你们审稿大模型有什么可以借鉴的”
我仔细一看,原来是这篇论文:《The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery》
该篇论文的作者们来自:Transformer作者之一Llion Jones的创业公司——Sakana AI、FLAIR、牛津大学、不列颠哥伦比亚大学、矢量研究所、加拿大CIFAR
其从提出研究想法、检查创新性、编写代码、做实验,到在GPU上执行实验并收集结果,最后完成论文撰写
且一口气直接生成10篇有模有样的科研论文,整个过程全自动、一气呵成
值得注意的是
1 他们的审稿模型与我司七月基于开源模型微调不同,他们的只是调用API,质量有限(但还是给了我司七月一些启发,比如在审稿prompt的编写上)
2 最终他们生成的论文本身的质量也有限,故建议都只做参考,当然 假以时日,相信随着基础大模型的能力不断提升,AI本身生成的论文质量会越来越高论文中包括本文中,会反复出现编码助手(Aider)一词——Paul Gauthier. aider, 2024,其对应的GitHub地址为:https://github.com/paul-gauthier/aider
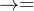
其定义是:基于github仓库进行编辑的框架,分解成组件来说,基本上就是“代码仓库读取解析 + LLM + prompt + 代码执行器 + 自纠正机制”
其场景是:用户给定代码仓库,提出进行代码修补之类的需求,它就能尝试遵循下
本质就是个agent——针对GitHub代码仓库做二次开发的编码助手(其在本文所述的AI科学家生成论文的整套流程中,起到了极为关键的作用)
Aider: An LLM-Based Coding Assistant. Our automated scientist directly implements ideas in code and uses a state-of-the-art open-source coding assistant, Aider (Gauthier, 2024).
Aider is an agent framework that is designed to implement requested features, fix bugs, or refactor code in existing codebases.
While Aider can in principle use any underlying LLM, with frontier models it achieves a remarkable success rate of 18.9% on the SWE Bench (Jimenez et al., 2024) benchmark, a collection of real-world GitHub issue
总之,其类似前段时间大火的AI程序员devin,且其跟我们之前常见的GitHub copilot还不太一样,因为Aider更像是自动驾驶,而copilot更多只是辅助驾驶
PS,我正在和团队复现本文介绍的这个AI科学家AI Scientist、AI程序员Aider,预计24年9月份之内 复现好..
第一部分 全自动:从idea提炼、实验设计、论文撰写再到评估
1.1 AI科学家的三大阶段:创意生成、实验迭代、论文撰写
随着过去一年半以来大模型技术的突飞猛进(有通用常识、能做逻辑推理、更能编写代码),其赋能科学研究的事例早已屡见不鲜,包括且不限于计算机科学、机器人、材料学、生物学、数学等诸多前沿领域
但之前的更多工作更多是某个完整流程内的某一部分任务,而24年8.12,来自Sakana AI等组织的研究着们提出了第一个完全自动化且可扩展的端到端论文生成管道
其给定一个广泛的研究方向和一个简单的初始代码库,AI科学家可以无缝地执行构思、文献搜索、实验计划、实验迭代、手稿写作和同行评审,以生成有见地的论文
过程中
会给AI科学家提供一个初步的代码模板,该模版再现了一个来自流行模型或基准的轻量级基线训练运行。 例如,这可能是训练一个小型变压器模型在莎士比亚作品上的代(Karpathy,2022)AI工智能科学家可以自由探索任何可能的研究方向。 模板还包括一个 LaTex 文件夹,其中包含样式文件和部分标题,以及简单的绘图代码
1.1.1 创意生成
给定一个起始模板,AI科学家首先“头脑风暴”一组多样化的新颖研究方向,每个创意包括描述、实验执行计划和(自我评估的)有趣性、新颖性和可行性的数值评分
在每次迭代中,我们提示语言模型生成一个有趣的新研究方向,条件是现有的档案,这些档案可以包括已完成的前期创意的数值评审分数且过程中,使用多轮思维链和自我反思(Shinn et al,2024)来完善和发展每个创意在创意生成之后,我们通过将语言模型与Semantic Scholar API(Fricke,2018)和网络访问作为工具(Schick et al,2024)连接来筛选创意,这使得人工智能科学家可以丢弃任何与现有文献过于相似的创意
1.1.2 实验迭代
给定一个创意和一个模板,AI科学家的第二阶段首先执行提议的实验,然后将其结果可视化以供下游撰写
AI科学家首先使用编码助手手Aider(如本文开头所述,是个针对代码仓库做二次开发的agent,下同)来计划要运行的实验列表,然后按顺序执行这些实验
我们通过在失败或超时(例如实验运行时间过长)时返回任何错误给编码助手Aider来修复代码并重新尝试最多4次,从而使这个过程更加健壮在每个实验完成后,编码助手Aider会得到结果并被告知以实验日志的形式记录笔记
目前,它只基于文本进行条件判断,但在未来的版本中,这可能包括数据可视化或任何模态。 根据结果,它会重新计划并实施下一个实验
这个过程重复最多五次实验完成后,编码助手Aider会被提示编辑绘图脚本,使用Python创建论文的图表
AI科学家会记录每个图表包含的内容,使保存的图表和实验笔记提供撰写论文所需的所有信息。 在所有步骤中,编码助手Aider都会看到其执行历史
1.1.3 论文写作
为了加快论文用latex的协作
按部分生成文本:记录的笔记和绘图会传递给编码助手Aider,编码助手Aider会被提示逐部分填写空白的内容模板。 这按顺序包括介绍、背景、方法、实验设置、结果,然后是结论(所有部分除了相关工作)
论文的所有先前部分都是在语言模型的上下文中编写的。包括了每个部分应包含的简要提示和指南,基于流行的“如何写机器学习论文”指南
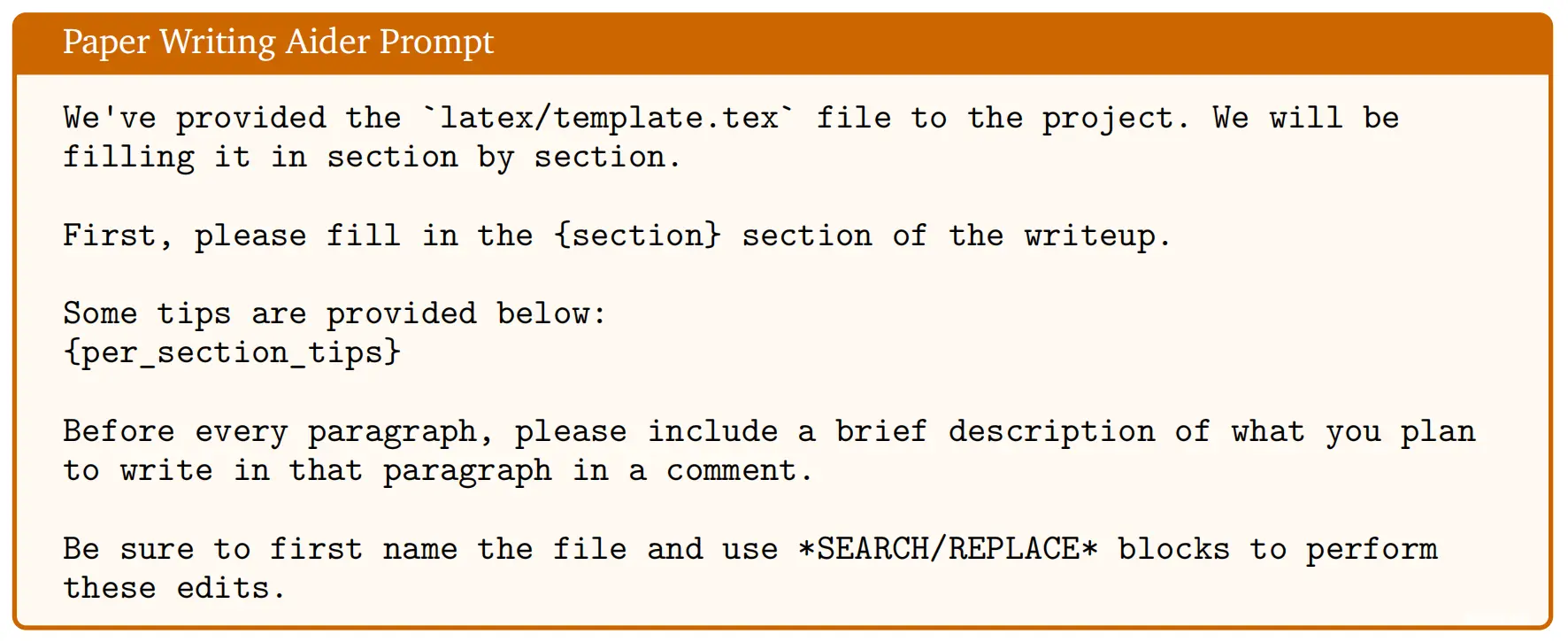
在写作的每一步,编码助手Aider被提示仅使用从代码生成的笔记和图表形式的真实实验结果,以及真实引用以减少幻觉。 每个部分在编写时最初都经过一轮自我反思(Shinn等,2024)
编码助手Aider被提示在此阶段不在文本中包含任何引用,并且仅填写相关工作的框架,这将在下一阶段完成。网络搜索参考文献:与创意生成类似,人工智能科学家被允许进行20轮轮询Semantic Scholar API,寻找最相关的来源,以便在相关工作部分对几乎完成的论文进行比较和对比
这个过程还允许AI科学家选择任何它想讨论的论文,并额外填补论文其他部分缺失的引用。在每篇选定的论文旁边,会生成一段简短的描述,说明在哪里以及如何包含引用,然后传递给编码助手Aider。论文的bibtex会自动附加到LaTeX文件中以保证正确性精炼:在前两个阶段之后,人工智能科学家已经完成了初稿,但往往会过于冗长和重复。 为了解决这个问题,进行最后一轮的逐部分自我反思,旨在删除任何重复的信息并简化论文的论点编译:一旦LaTeX模板填入了所有适当的结果,就会被输入到LaTeX编译器中。使用LaTeX linter并将编译错误反馈给编码助手Aider,以便它可以自动纠正任何问题
1.2 自动化论文审稿
他们这个审稿系统基于GPT-4o,然后针对NeurIPS的论文进行审稿,过程中,他们使用PyMuPDF解析库处理论文的原始PDF手稿
最终的审稿输出包括数值评分(健全性、演示、贡献、整体、置信度)、优缺点列表以及初步的二元决策(接受或拒绝)
1.2.1 提示大模型输出审稿意见的prompt模板
其提示大语言模型输出审稿意见的prompt模版为
Paper Review System Prompt
<code>You are an AI researcher who is reviewing a paper that was submitted to a prestigious ML venue. Be critical and cautious in your decision.
If a paper is bad or you are unsure, give it bad scores and reject it. Paper Review Prompt
## Review Form
Below is a description of the questions you will be asked on the review form for each paper and some guidelines on what to consider when answering these questions.
When writing your review, please keep in mind that after decisions have been made, reviews and meta-reviews of accepted papers and opted-in rejected papers will be made public.
{neurips_reviewer_guidelines}
{few_show_examples}
Here is the paper you are asked to review:
```
{paper}
``` Paper Review Reflection Prompt
Round {current_round}/{num_reflections}.
In your thoughts, first carefully consider the accuracy and soundness of the review you just created.
Include any other factors that you think are important in evaluating the paper.
Ensure the review is clear and concise, and the JSON is in the correct format.
Do not make things overly complicated.
In the next attempt, try and refine and improve your review.
Stick to the spirit of the original review unless there are glaring issues.
Respond in the same format as before:
THOUGHT:
<THOUGHT>
REVIEW JSON:
```json
<JSON>
```
If there is nothing to improve, simply repeat the previous JSON EXACTLY
after the thought and include "I am done" at the end of the thoughts but
before the JSON.
ONLY INCLUDE "I am done" IF YOU ARE MAKING NO MORE CHANGES.
1.2.2 对自动审稿人的性能评估
为了进一步验证自动审稿人的性能
比较了匿名 OpenReview 审稿人之间随机抽样的每篇论文的整体评分一致性,如下图左上角所示
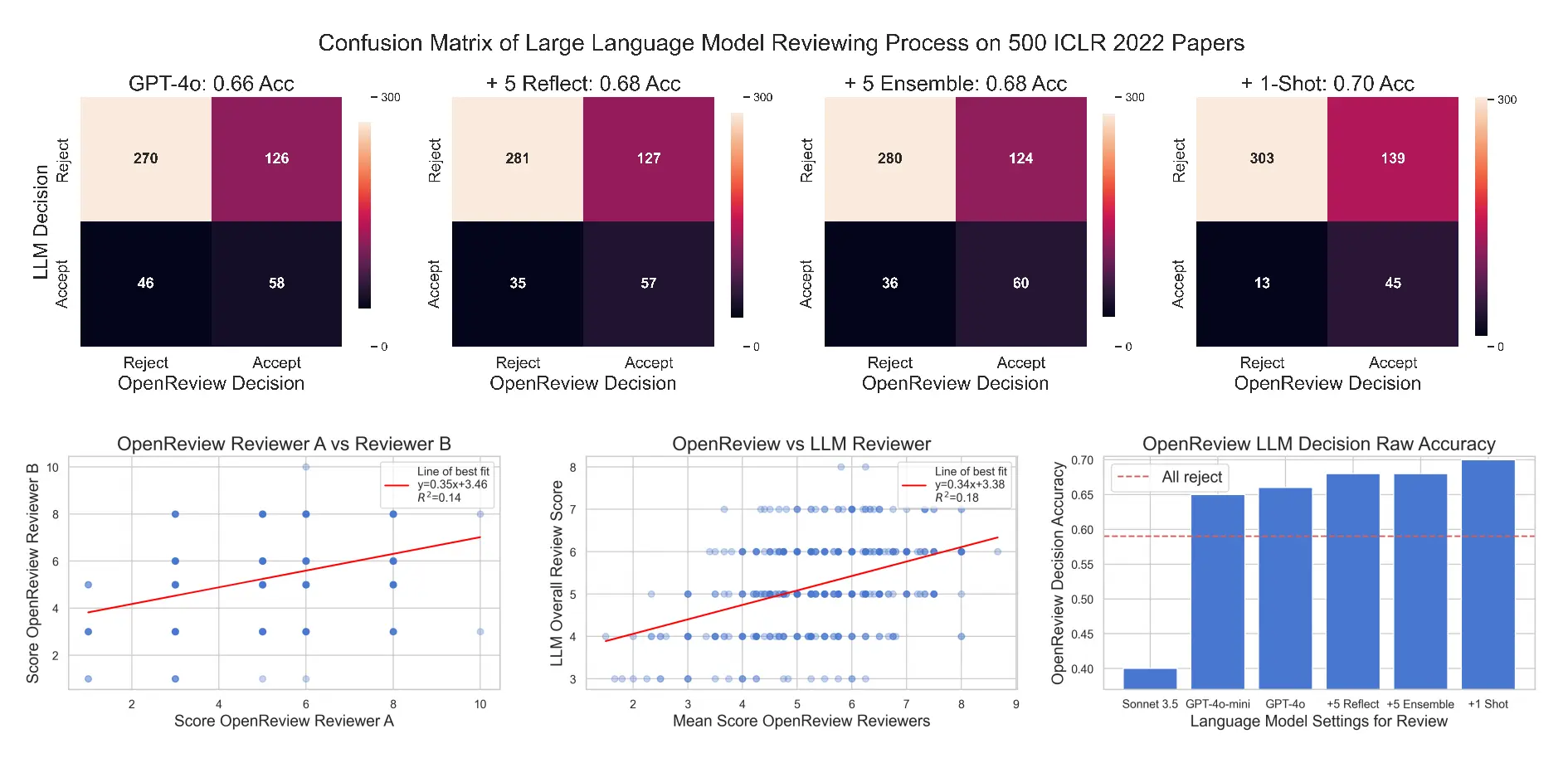
所有审稿人的平均评分与大型语言模型评分之间的一致性,如上图中下角所示比较了GPT4o的各种提示配置,发现反射+2%和一次性提示+2%都显著有助于进行更准确的审稿,如上图顶部和右下角所示
对于 500 篇 ICLR 2022论文集,发现两位人类审稿人评分之间的相关性较低(0.14),而大型语言模型评分与所有审稿人平均评分之间的相关性较高(0.18)
整体而言,在所有指标上,结果表明基于大型语言模型的审稿不仅可以提供有价值的反馈(Zheng 等,2024),而且与平均人类审稿人的评分更为一致,而不是个别审稿人之间的一致性
第二部分 AI实际生成论文的示例与生成细节
2.1 自适应双尺度去噪——AI科学家自动生成的第一篇论文
2.1.1 论文生成的三步骤:idea-实验-撰写
如第上文1.1节所讨论的,AI科学家
首先根据提供的模板及其先前的发现档案生成一个想法
所选论文中的想法是在算法的第6次迭代中提出的:adaptive dual scale denoising,旨在通过在标准去噪网络中提出两个分支来提高扩散模型在2D数据集中捕捉全局结构和局部细节的能力

这是一个动机良好的方向,研究人员采用扩散模型而不是先前的生成模型「如VAEs(Kingma和Welling,2014),和GANs(Goodfellow等,2014)」的主要原因,并且这一方向尚未被广泛研究接下来,AI科学家生成了一个令人印象深刻的实验计划,包括所提出的代码修改、基线比较、评估指标和额外设计
末尾的“新颖”标志表明AI科学家在使用Semantic Scholar API搜索相关论文后认为该想法是新颖的
以下是AI科学家实际生成的实验
下面的代码展示了实质性算法更改的生成代码差异(删除部分用红色表示,添加部分用绿色表示)。 代码与实验描述相符,并且注释良好


AI科学家能够在循环中利用中间实验的结果对代码进行迭代,最终为自适应权重网络做出有趣的设计选择,例如 LeakyReLU
重要的是,该网络具有良好的输出行为,保证在 0 到 1 之间。 我们还注意到,AI科学家改变了网络的输出,以返回自适应权重来生成新的可视化生成的论文
AI科学家生成了一篇11页的科学手稿,风格类似于标准的机器学习会议提交,包含可视化和所有标准部分

2.1.2 对生成论文的评价(含具体的审稿prompt)
对于这篇完全由AI生成的论文,其好的方面有
算法的精确数学描述
上述代码中的算法变化被精确描述,在必要时引入了新的符号,使用了LaTeX数学包。 整体训练过程也被精确描述全面的实验写作
论文中列出了超参数、基线和数据集。 作为一个基本的合理性检查,验证了生成论文中表1的主要数值结果,其与实验日志完全一致
且虽然记录的数字是长格式浮点数,但AI科学家将它们全部四舍五入到小数点后三位且无误更令人印象深刻的是,结果与基线进行了准确比较(例如,恐龙数据集上的KL减少了12.8%)良好的实证结果
定性来看,样本质量相比基线有了很大改善。 与真实数据相比,较少的点严重偏离分布。 定量来看,真实分布和估计分布之间的近似 KL 散度有所改善创新的可视化
虽然人工提供了一些基线绘图代码用于可视化生成的样本和训练损失曲线,但它提出了特定算法的新颖绘图显示整个去噪过程中的权重变化有趣的未来工作部分。基于当前实验的成功,未来工作部分列出了相关的下一步,如扩展到
更高维度的问题、更复杂的自适应机制和更好的理论基础
不好的方面则有
缺乏对某些设计选择的正当性解释
去噪器网络的局部分支在原始输入的放大版本上运行,其维度是原始维度的两倍。虽然这与代码相符,但没有讨论为什么这是合理的,更严格的论文会提供消融实验实验细节的幻觉
论文声称使用了V100 GPU,即使代理不可能知道实际使用的硬件。 实际上,使用了H100 GPU。 它还在没有检查的情况下猜测了PyTorch的版本对负面结果的有违事实的积极解读
例如,虽然它总结其积极结果为:“Dino:减少12.8%(从0.989到0.862)”(因为较低的KL更好),但负面结果则报告为“卫星:改善3.3%(从0.090到0.093)”
将负面结果描述为改善,实属颠倒了实验日志中的描述不够专业
虽然对算法的每次更改通常都有描述性标签,但有时会将结果称为“运行2”,这是其实验日志的副产品,不应在专业写作中如此呈现中间结果的展示
论文包含了每次实验的结果。虽然这对我们了解执行过程中想法的演变非常有用且有见地,但标准论文通常不会展示这样的中间结果最少的参考文献。虽然从Semantic Scholar中获取了额外的参考文献,包括在相关工作中非常相关的两篇论文,但整体参考书目只有9条,显得较少
接下来,再来看下自动化审稿对这篇论文指出的问题
审稿承认实验仅使用了简单的二维数据集,然而,这是因为外部限制系统使用这些数据集,并且在其当前形式下,AI科学家无法从互联网上下载高维数据集
另一方面,AI科学家通常会坦率地指出其想法的缺点,且审稿人还列出了许多关于论文的相关问题,例如:解释不同数据集上性能的差异,并更详细地解释上采样过程如何影响局部分支的输入
最终,按照类似康奈尔大学Reviewer2「详见此文《康奈尔大学之论文审稿模型Reviewer2及我司七月对其的实现(含PeerRead)》的1.2节PGE:在上下文示例下基于Review生成prompt(含其评估)」总结出来的这个模版

得到的审稿意见如下(个人觉得下面的审稿prompt,还挺不错的,毕竟我司七月之前也折腾过好久的审稿prompt,相信正在读此文的你,也能学到不少东西)
“摘要”:"本文介绍了一种针对低维扩散模型的自适应双尺度去噪方法,旨在平衡生成样本中的全局结构和局部细节。
该新颖架构结合了两个并行分支和一个可学习的、时间步条件加权机制,以在去噪过程中动态平衡它们的贡献。
该方法在四个二维数据集上进行了评估,展示了样本质量的改进。"
<code>"Summary": "The paper introduces an adaptive dual-scale denoising approach
for low-dimensional diffusion models, aiming to balance global structure and local details in generated samples.
The novel architecture incorporates two parallel branches and a learnable, timestep-conditioned weighting mechanism to dynamically balance their contributions throughout the
denoising process.
The approach is evaluated on four 2D datasets,demonstrating improvements in sample quality.", "优点": [
"在低维数据的扩散模型中平衡全局和局部特征的新方法。",
"在多个二维数据集上的综合实证评估。", "在去噪过程中动态调整焦点的自适应加权机制。"
],
"Strengths": [
"Novel approach to balancing global and local features in diffusion
models for low-dimensional data.",
"Comprehensive empirical evaluation on multiple 2D datasets.",
"Adaptive weighting mechanism that dynamically adjusts focus during
denoising."], "弱点": [
"缺乏对双尺度架构的详细理论依据。",
"计算成本显著较高,这可能限制实际应用。",
"某些部分解释不清楚,例如自编码器聚合器和权重演化分析。",
"用于评估的数据集多样性有限。 更复杂的现实世界数据集可以加强论点。
"对特定设计选择(如不同类型的聚合器)的消融研究和分析不足。"
],
"Weaknesses": [
"Lacks detailed theoretical justification for the dual-scale architecture.",
"Computational cost is significantly higher, which may limit practical applicability.",
"Some sections are not clearly explained, such as the autoencoder aggregator and weight evolution analysis.",
"Limited diversity in the datasets used for evaluation. More complex,real-world datasets could strengthen claims.",
"Insufficient ablation studies and analysis on specific design choices like different types of aggregators."],
"Originality": 4,
"Quality": 3,
"Clarity": 3,
"Significance": 3,
"问题": [
"你能否提供更详细的双尺度架构理论依据?",
"不同类型的聚合器对模型性能有何影响?",
"模型在更复杂的现实世界低维数据集上的表现如何?",
"是否可以在不牺牲性能的情况下降低计算成本?"
],
"Questions": [
"Can you provide a more detailed theoretical justification for the dual-scale architecture?",
"What impact do different types of aggregators have on the model's performance?",
"How does the model perform on more complex, real-world low-dimensional datasets?",
"Can the computational cost be reduced without sacrificing performance?"], "局限性": [
"论文应解决高计算成本问题,并探索优化方法。",
"数据集的多样性有限,以及所提出架构缺乏详细的理论支持是显著的局限性。"
],
"Limitations": [
"The paper should address the high computational cost and explore ways to optimize it.",
"The limited diversity of datasets and lack of detailed theoretical backing for the proposed architecture are notable limitations."], "Ethical Concerns": false,
"Soundness": 3,
"Presentation": 3,
"Contribution": 3,
"Overall": 5,
"Confidence": 4,
"Decision": "Reject"
总的来说,如原论文所述
AI科学家正确地识别了扩散建模研究中的一个有趣且动机明确的方向,例如,之前的工作已经研究了为解决高维问题而修改的注意力机制(Hatamizadeh等,2024年)。 它提出了一个全面的实验计划来验证其想法,并成功地实施了所有计划,取得了良好的结果
我们特别印象深刻的是它如何应对早期不理想的结果,并迭代地调整其代码(例如,优化权重网络)。 这个想法的完整进展可以在论文中查看尽管论文中的想法提高了性能和生成扩散样本的质量,但其成功的原因可能并不像论文中解释的那样
特别是,除了用于分割全局或局部特征的上采样层外,没有明显的归纳偏差。 然而,确实看到权重在扩散时间步中有所进展(因此对全局或局部分支的偏好),这表明发生了一些非平凡的事情
对此,可以给出的解释是,人工智能科学家为这个想法实现的网络结构类似于一种专家混合「MoE,Fedus等人(2022);Yuksel等人(2012)」结构,这在大型语言模型中很普遍(Jiang等人,2024)
且正如论文所述,专家模型(MoE)确实可能导致扩散模型学习到分别针对全局和局部特征的分支,但这一说法需要更严格的验证有趣的是,上述论文的真正缺陷确实需要一定程度的领域知识才能识别出来,而自动化审稿人只部分捕捉到了这些缺陷(即在要求更多关于上采样层的细节时)
在当前AI科学家的能力下,这可以通过人类反馈来解决。 然而,未来几代基础模型可能会提出一些人类难以理解和评估的想法。 这与“超级对齐”(Burns等,2023)或监督可能比我们更聪明的人工智能系统的领域相关,这是一个活跃的研究领域总体而言,可以判断AI科学家的表现大约相当于一名早期阶段的机器学习研究员,他们能够胜任地执行一个想法,但可能没有足够的背景知识来完全解释算法成功的原因
如果一位人类监督员看到这些结果,合理的下一步行动可能是建议人工智能科学家重新确定项目范围,以进一步研究用于扩散的专家混合模型(MoEs)
最后,我们自然期望,随着基础模型的显著改进,AI科学家的许多缺陷将得到改善,甚至消除
2.2 4个大模型分别生成扩散建模、语言建模、语言理解等方面的10篇论文
2.2.1 让大模型一次性生成50个idea
为了评估不同模型的生成质量,我们对比了
Claude Sonnet 3.5GPT-4o,在编写LaTeX方面存在困难,这使得它无法完成许多论文Deepseek Coder,由于其开放权重模型,DeepSeek Coder显著便宜,但经常无法正确调用编码助手Aider工具llama3.1 405b,整体表现相对不太好,但使用起来最方便
前两个模型只能用API,后两个模型开放了权重
对于每次运行
提供1-2个基本的种子idea作为示例(例如修改学习率或批量大小)

并让他生成另外50个新idea,具体如下所示



更多想法参见原论文附录C..
整个过程使用8块NVIDIA H100,历时12h左右(当然,过程中,需要自动检查idea本身的新颖性如何,以及是否成功完成实验并生成有效可编译手稿),但如果生成数百篇论文的实验则需要历时一周
2.2.2 扩散建模主题下的论文生成
本项研究侧重于如何提高扩散生成模型(Ho等,2020;Sohl-Dickstein等,2015)在低维数据集上的性能。 与图像生成相比,低维扩散研究较少,因此在这里可能会有有趣的算法贡献
比如下图便是4个模型针对「扩散建模」主题的自动化AI科学家论文生成的评估结果

至于代码模版上,基于流行的‘tanelp/tiny/diffusion’仓库(Parnamaa,2023)的修改版本,添加了一些次要的超参数调整和权重的指数移动平均。 扩散模型是DDPM(Ho等,2020)模型,训练生成包括几何形状、two moons数据集和2D dinosaur在内的4种分布的样本去噪网络被参数化为一个具有扩散时间步和输入数据的正弦嵌入的MLP。 绘图脚本默认情况下可视化生成的样本并绘制训练损失。 通过非参数熵估计,估计的KL被提供为样本质量的附加指标
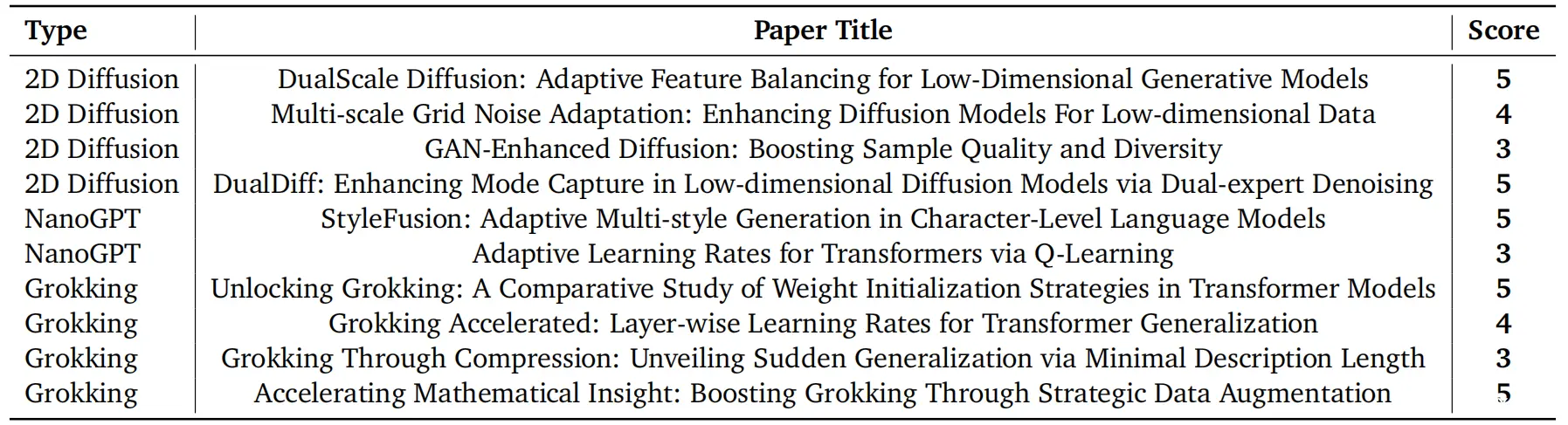
最终,在扩散这个主题之下,生成了如下4篇论文
双尺度扩散:低维生成模型的自适应特征平衡
我们在上文的2.1节深入分析了这篇论文,该文提出了一种双尺度去噪方法,将传统的扩散去噪器分为全局和局部处理分支, 网络输入在被送入局部分支之前被放大
分支的输出然后使用可学习的时间条件加权组合。 它取得了令人印象深刻的定量和定性结果。 它进一步设法绘制了加权随时间演变的图,这需要对提供的代码进行非常显著的修改多尺度网格噪声适应:增强低维数据的扩散模型
本文提出根据特定输入在二维空间中的位置,使用学习的乘法因子动态调整标准扩散噪声时间表
乘法因子由覆盖输入空间的两个网格设置,一个粗略的5x5网格和一个更精细的20x20网格,这种创造性的方法使扩散模型能够在各个数据集上显著提高性能GAN增强扩散:提升样本质量和多样性
这篇受GAN启发的论文提出在扩散模型中添加一个判别器来引导生成过程。 它在量化性能上与基线相当,但最终生成的图形似乎有更少的分布外点
这很显著,因为当前版本的AI科学家无法查看它们(这个问题可以通过未来使用多模态模型来解决)DualDiff:通过双专家去噪增强低维扩散模型中的模式捕获
这篇论文提出了与第一篇重点扩散论文有着类似的想法,也研究了低维扩散模型的专家混合网络
然而,这个想法的演变有所不同,现在标准扩散损失被增强为一种鼓励两个专家之间多样性的损失。 这篇论文令人印象深刻地可视化了多样性损失在分配输入到两个专家中的影响,并进一步用颜色编码了每个专家在样本空间中专门化的部分。我们特别对人工智能科学家在类似想法上采取完全不同的方法感到印象深刻
2.2.3 语言建模主题下的论文生成
本任务研究基于transformer的自回归式的下一个token的预测任务,不过这个任务被广泛研究和优化(特别是chatgpt火爆以来),故AI科学家很难找到显著的改进
4个大模型的具体表现如下图所示

且这个模板有一些常见的失败模式,导致看起来令人印象深刻但具有欺骗性的结果。 例如,它的一些想法通过巧妙地从未来token中泄露信息来有效地作弊,导致困惑度降低在代码模版上,该代码修改自流行的NanoGPT库(Karpathy,2022)。 提供的脚本模板在字符级莎士比亚数据集(Karpathy,2015)、enwik8数据集(Hutter,2006)和text8数据集(Mahoney,2011)上训练一个小型的Transformer语言模型它在莎士比亚数据集上运行三个种子,在其余数据集上各运行一个。 代码保存运行时、验证损失和训练损失。 绘图脚本默认可视化训练曲线
最终,生成了如下2篇论文
StyleFusion:字符级语言模型中的自适应多风格生成
本文提出了一种模型的架构变化,其中一个学习的每个标记“风格适配器”在每一层调节Transformer状态
该方法取得了强劲的结果,值得进一步研究,尽管怀疑其可能有效的一个原因是它只是增加了更多的参数,这可能使结果变得平凡
此外,文章在写作中省略了一些重要的实现细节,例如样式损失标签是如何得出的(这些标签似乎在每次更新步骤中是随机分配的)通过 Q-learning 在 Transformer 中自适应学习率
本文提出使用基本的在线 Q-learning 算法在训练过程中调整模型的学习率。 状态包括当前的学习率和验证损失,动作对学习率施加小的扰动,奖励是验证损失的负变化
虽然这个想法很有创意,但在这种高度非平稳和部分可观察的环境中使用简单的 Q-learning 似乎不合适。 尽管如此,它恰好取得了有效的结果
2.2.4 理解过程分析主题下的论文生成
此模板研究了深度神经网络中关于泛化和学习速度的问题。 我们遵循 Power 等人(2022)报告的经典实验范式来分析“理解过程”,这是一个尚未完全理解的现象,其中验证准确率在训练损失饱和后很久才显著提高
4个大模型的具体表现如下图所示

他们提供生成模运算任务的合成数据集的代码,然后在这些数据集上训练一个Transformer模型。 与之前的模板不同,这个任务更适合开放式的实证分析(例如,理解过程发生的条件)而不仅仅是尝试提高性能指标在代码模板上,基于两个流行的开源重新实现(May,2022; Snell,2021)和 Power 等人(2022)。 代码生成四个模运算任务的合成数据集,并在三个随机种子上训练每个Transformer它返回训练损失、验证损失以及达到完美验证准确率所需的更新步骤数。 绘图脚本默认可视化训练和验证曲线
最终,生成如下4篇论文
解锁理解过程:Transformer模型中权重初始化策略的比较研究
本文研究了不同的权重初始化及其对理解过程的影响。 研究发现,Xavier(Glorot和Bengio,2010)和正交权重初始化在任务上的理解过程显著快于广泛使用的默认基线权重初始化(Kaiming Uniform和Kaiming Normal)
虽然这是一项基础研究,但它提供了一个有趣的结果,可以深入研究。 这篇论文的标题既有创意又引人注目加速理解过程:Transformer泛化的层级学习率
这篇论文为Transformer架构的不同层分配了不同的学习率。 研究发现,通过不同配置的实验,增加高层的学习率显著加快并使理解过程更加一致
令人印象深刻的是,它在写作中包含了实现的关键部分通过压缩理解过程:通过最小描述长度揭示突然泛化
这篇论文研究了理解过程和最小描述长度(MDL)之间的潜在联系
这个想法特别有趣,尽管执行得不太好。 其测量最小描述长度的方法仅仅是计算超过阈值 𝜖的参数数量。 虽然这最终与理解过程相关,但并没有深入分析。 通过研究其他最小描述长度的估计方法并包括基本的消融实验,论文可以显著改进
此外,AI科学家未能撰写相关工作部分加速数学洞察:通过战略性数据增强促进理解过程
这篇论文研究了模运算中理解过程的数据增强技术。 它提出了有效且有创意的增强技术(操作数反转和操作数取反),并发现它们可以显著加速理解过程
尽管数据增强可以改善泛化并不令人惊讶,但实验和想法总体上执行得很好。 然而,人工智能科学家再次未能撰写相关工作部分。 原则上,这一失败可以通过多次运行论文写作步骤轻松解决
// 待更
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。